SVM、KNN、ANN、MLP、DT、Keras、Tensorflow处理糖尿病数据集分类
目录
- 实验内容
- 算法原理与分析
-
- SVM原理
-
- 线性可分与不可分
- 函数间隔与几何间隔
- 超平面分析与几何间隔详解
- 二次最优化
- 软间隔最大化
- 拉格朗日对偶化
- 核函数
- KNN原理
-
- k近邻算法原理
- 距离加权最近邻算法
- 距离
- K值选取
- 消极学习与积极学习
- DT
-
- 树模型
- 训练与测试
- 特征切分的衡量标准
- 决策树算法
- 控制决策树的复杂度
- ANN
-
- 模型介绍
- 前向传播
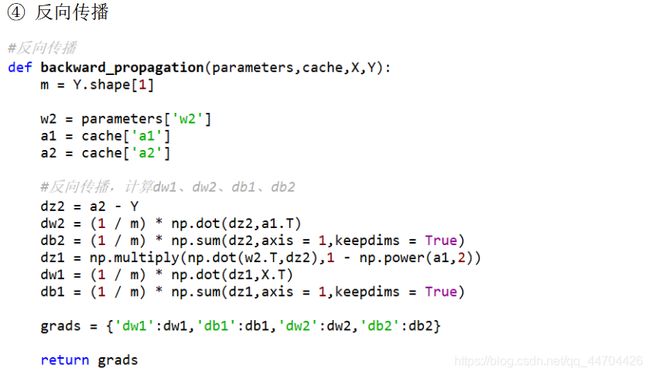
- 反向传播
- BP算法的特点与局限
- 实验设计
-
- 读取数据集
- 数据可视化
- 数据预处理
- 建立模型
-
- 使用python中sklearn库建立分类模型
- 使用Tensorflow建立分类模型
- 使用keras库建立分类模型
- 自制ANN和KNN模型
- 参数选择(模型评估)
-
- KNN调参
- SVM调参
- DT调参
- MLP调参
- 自制ANN调参
- Keras调参
- 数据预测
-
- 自制模型的预测
- 利用自带库的预测
- 实验结果与分析
- 模型总结
-
- SVM模型总结
- KNN模型总结
- MLP和ANN总结
- DT决策树总结
- 心得
- 参考文献
- PS
实验内容
针对提供的糖尿病数据集(diabetes.txt)中指定类别(0,1)完成分类
任务。
该糖尿病数据集来源于一个UCL机器学习数据库,其由768个数据点组成,各有9个属性:怀孕次数、血糖、血压、皮脂厚度、胰岛素、BMI身体质量指数、糖尿病遗传函数、年龄以及结果。
其中“结果”是要预测的属性,0表示未患糖尿病,1表示患有糖尿病。在这768个数据点中,有500个被标记为0,268个被标记为1。
要求使用提供样本的前60%作为训练样本,后40%作为测试样本,建立一个糖尿病的预测模型。注意训练模型时,不得使用测试样本,且样本的顺序不能变化。
可以采用任何分类算法及数据预处理方法。
算法原理与分析
SVM原理
SVM支持向量机,简单来说是一个有监督的二类分类器,其作为传统机器学习的一种通用的前馈神经网络,基本模型是在特征空间上找到最佳的分离超平面使得训练集上正负样本间隔最大,在引入了核函数之后SVM也可用来解决非线性问题。
线性可分与不可分
线性可分:二维空间可以用一条直线将两类样本分开;高维空间则可以用一个高维函数分隔开。
线性不可分:通过高斯核函数将其映射到高维空间,将非线性转换为线性可分。
函数间隔与几何间隔

超平面分析与几何间隔详解
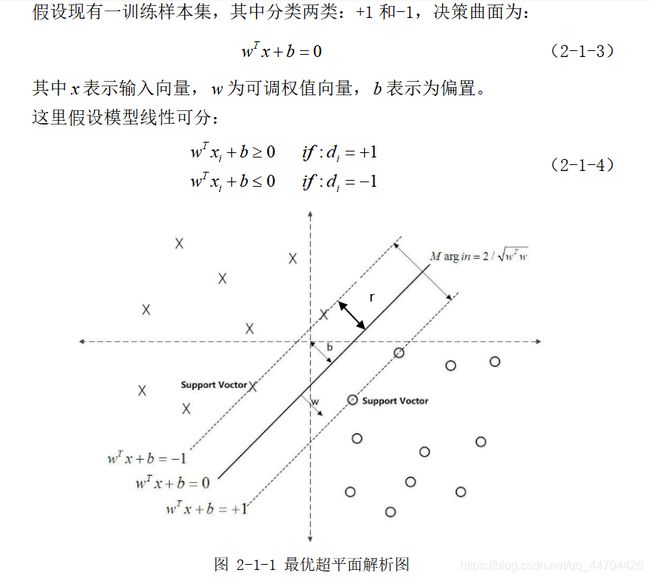


二次最优化

软间隔最大化

拉格朗日对偶化

核函数

KNN原理
k近邻算法原理


距离加权最近邻算法

距离
相似性一般用空间内两个点的距离来衡量,关于距离的度量方法常用的有:欧几里得距离、明考斯基距离,曼哈顿距离、马氏距离等。
K值选取
K值,即选取的临近点个数,若K值过小,一旦有噪声成分存在将会对预测产生较大影响,K值的减小意味着整体模型变复杂,容易出现过拟合现象;若K值过大,就相当于用较大邻域中的训练实例进行预测,学习的近似误差会增大,这时与目标数据点较远实例也会产生作用,使预测发生错误,K值的增大意味着整体的模型变得简单。K的取值尽量要取奇数,一般情况下,K值会倾向选取较小的值,可以使用交叉验证法来选取最优K值。
消极学习与积极学习
(1)积极学习(Eager Learning)
这种学习是指在进行判断之前,先利用训练数据进行训练得到一定的模型或者目标函数,等到需要时就可以直接拿来进行决策,如神经网络、SVM、决策树以及贝叶斯分类。该学习方式考虑到了所有的训练样本,是一个全局的近似,需耗费训练一定训练时间,但其决策时间基本为0。
(2)消极学习(Lazy Learning)
这种学习只是简单地将训练样本存储起来,等到出现需要分类的新实例时分析其与所存储样例的关系后确定新实例的目标函数值,不存在之前的训练过程,如KNN算法、局部加权回归等。因其决策时虽需要计算所有样本与新实例的距离,但只用到了几个局部的训练数据,所以是一个局部近似,由于每次决策需要求一次与所有样本的距离,因此该方法需要足够大的存储空间且决策过程较慢。
DT
树模型
决策树是一种从根节点逐步走到叶子节点的决策,既可以应用于分类也可以用于回归,叶子节点为最终的决策结果。
训练与测试
训练阶段是根据给定的数据集构造出一棵树,从根节点开始选择最有价值的特征切分节点;测试阶段则是根据构造出来的决策树模型走一遍。
特征切分的衡量标准

决策树算法

控制决策树的复杂度
通常来说,构造决策树直到所有叶节点都是纯叶子节点,这会导致模型非常复杂,并且对训练数据高度拟合。纯叶子节点的存在说明这棵树在训练集上的精度是100%,训练集中的每个数据点都位于分类正确的叶节点中。防止过拟合有两种常见的策略:
(1)预剪枝:及早停止树的生长,通过限制树的最大深度、限制叶子节点的最大数目或者规定一个节点中数据点的最小数目来防止其继续划分。
(2)后剪枝:先构造树,随后删除或折叠信息量很少的节点。
ANN
模型介绍
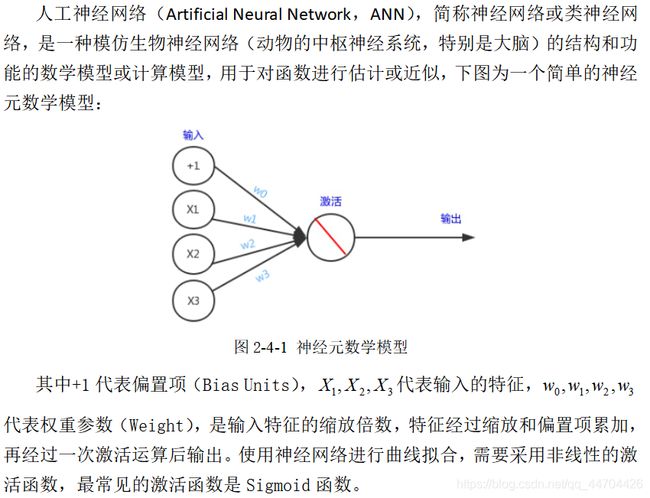
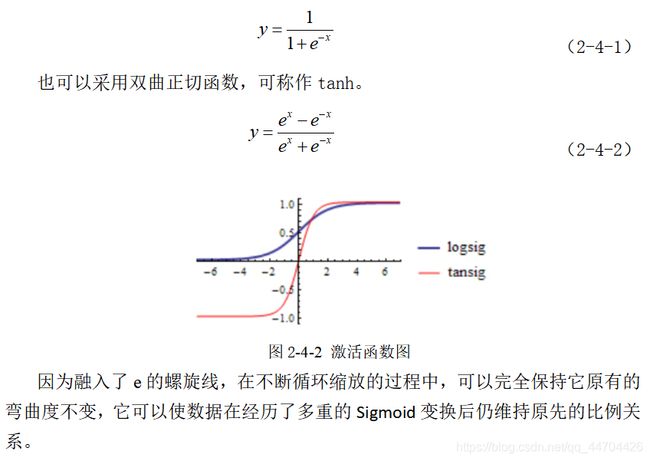
前向传播


反向传播

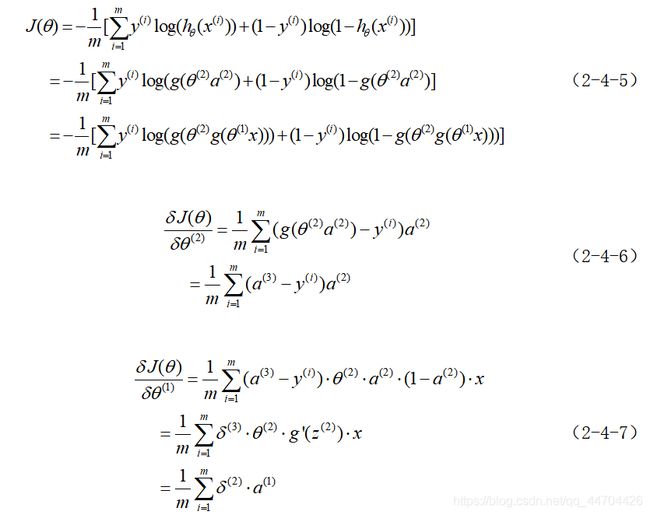
BP算法的特点与局限
需要一定量的历史数据(特征),通过历史数据的训练来学习从而进行分类、聚类、预测等,但其计算较复杂,速度比较慢,容易陷入局部最优解的局面。
实验设计
读取数据集

数据可视化
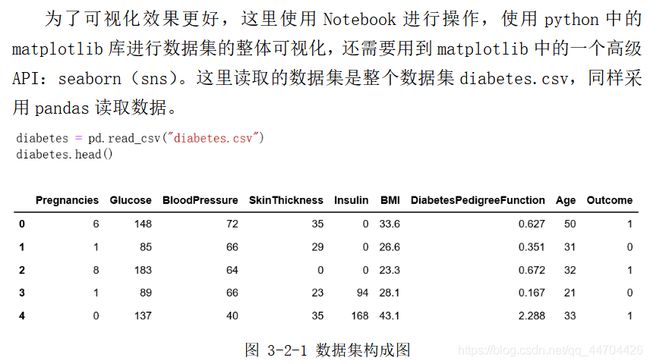
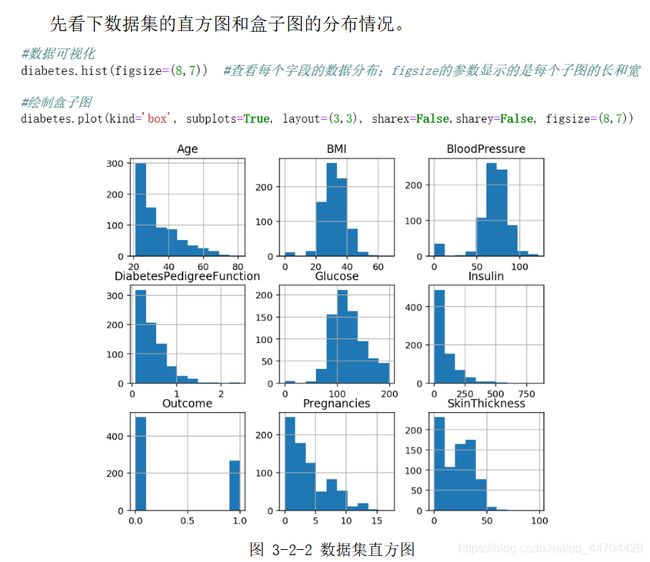
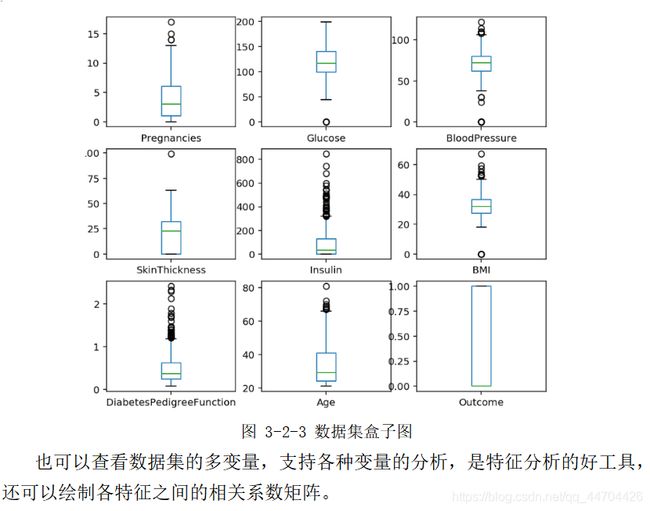
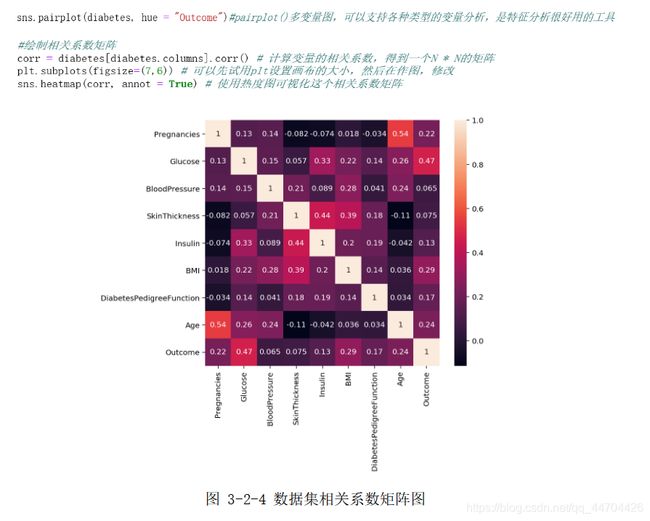
数据预处理
考虑到一些算法如神经网络和SVM对数据的缩放非常敏感,通常需要对特征进行调节,即对数据进行简单的按特征缩放和移动,从而使数据更加适合于这些算法。
其中涉及到python中sklearn库的StandardScaler和MinMaxScaler。
StandardScaler是使所有特征都位于同一量级,使每个特征的平均值为0、方差为1;MinMaxScaler是使所有的特征都位于0到1之间。
归一化通常用于数据分化比较大的场景,即有的数值很大,有的数值很小,通过数学函数将原始值进行映射,从而消除不同特征之间数值相差很大导致结果不同的因素,这样提高了迭代求解的收敛速度和精度,但同时数据也会失去原始的一些信息。
标准化即将每个特征的数值平均变为0,标准差变为1,使得不同度量之间的特征具有可比性,对目标函数的影响体现在几何分布上,而不是数值上,不改变原始的数据分布。这个方法被广泛应用在机器学习算法中,如SVM、逻辑回归和类神经网络,使每个特征都服从标准正态分布,从而消除每个特征分布不同导致结果不同的因素。

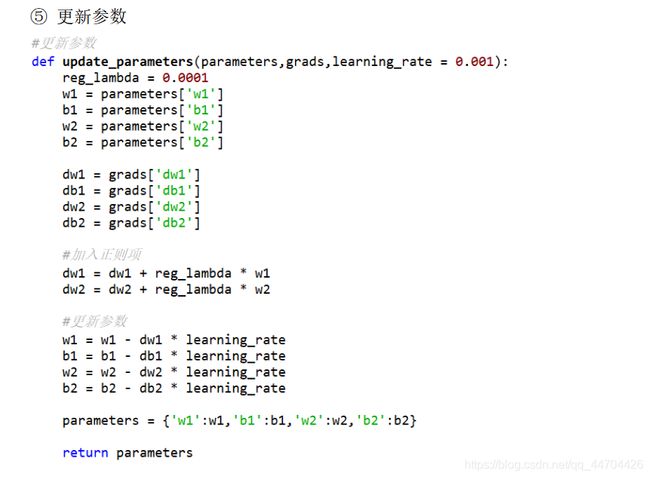
建立模型
使用python中sklearn库建立分类模型

使用Tensorflow建立分类模型


使用keras库建立分类模型


自制ANN和KNN模型




参数选择(模型评估)
KNN调参
这里KNN模型需要进行调整的是K的数值,即n_neighbors的个数,可以通过绘制训练精度和测试精度与不同K值得关系曲线图来找出最合适的K值。

从上面的曲线图可以看出,在实际进行KNN模型训练时,K值过小时,相当于使用较小的邻域进行预测,如果邻居恰好是噪声点,会导致过拟合。随着K值不断增大,模型的训练精确度先增后减,第一次到达最大精确值是K=3,随着K值超过8或者9后,因距离较远的样本也会对预测起作用,所以导致预测错误,模型训练精度开始呈下降趋势,因此这里选择K=9。
SVM调参
SVM的模型具有两个重要的参数:一个是正则化参数C,其默认为1,限制了每个点的重要性,即对误差的容忍度,C越高,说明越不能容忍出现误差,容易过拟合,C越小,容易欠拟合,因此C过大或过小,泛化能力变差;一个是gamma,默认其为特征个数的倒数,用于控制高斯核的宽度(这里的核函数一般选择“rbf”,即径向基函数),决定点与点之间“靠近”是指多大的距离,gamma越大,支持向量越少,存在训练准确率可以很高,而测试准确率不高的可能,就是通常说的过训练;gamma值越小,支持向量越多,则会造成平滑效应太大,无法在训练集上得到特别高的准确率,也会影响测试集的准确率。
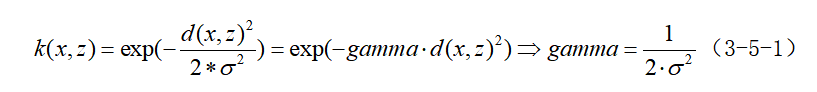 先采用交叉网格验证,在设定的参数对中,选择出最好的参数对,但因该实验要求中样本的顺序不可以变化,在确定一个大概的范围后,还需要进一步的再次调参。
先采用交叉网格验证,在设定的参数对中,选择出最好的参数对,但因该实验要求中样本的顺序不可以变化,在确定一个大概的范围后,还需要进一步的再次调参。
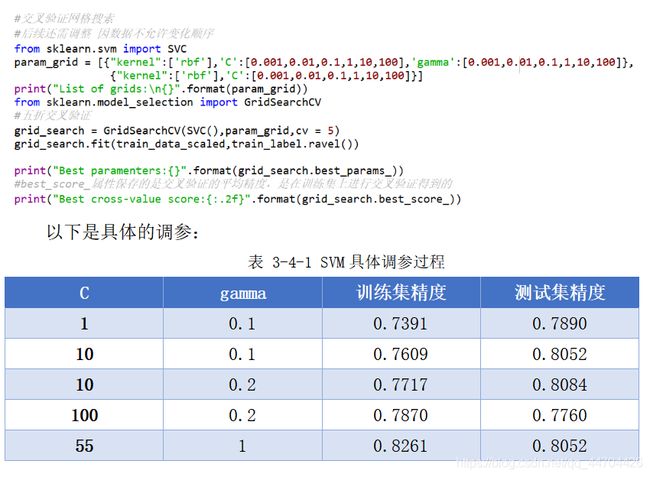
从表中可以看到起初时,测试集的精度略高于训练集,说明模型实际上还处于一个欠拟合的状态,需要进一步地增大C和gamma的值,即增大模型的复杂度,当增大到一定的程度时,又看到训练集的精度开始高于测试集,则开始趋向过拟合状态,因此将本次与上次的参数设定进行折中处理,最后选定的C为55,gamma的值为1。
DT调参
决策树主要考虑的便是树的层数即深度,若不限制树的深度,树的深度很大导致叶子节点都是纯的,足以让记住训练数据的所有标签,出现过拟合的情况,泛化能力不佳,因此需要采取剪枝操作,可以设置max_depth,默认是None,即自动扩大到纯节点,这里设置的max_depth为4.
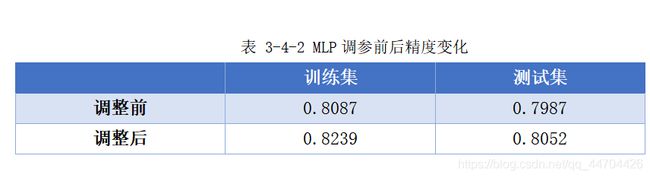
MLP调参
多层感知器的分类需要估计网络的复杂度,即层数和每层的单元个数,可以先设置1或2个隐层,然后逐步增加找到合适的值。
常用的调参方法:首先创建一个大到足以过拟合的网络,确保这个网络可以对任务进行学习,然后知道训练数据可以被学习之后,要么缩小网络,要么增大alpha来增强正则化,可以提高泛化性能。
其中参数solver:默认选项是“adam”,在大多数情况下效果都很好;“lbfgs”的鲁棒性相当好,但在大型模型或大型数据集上的时间会比较长;“sgd”许多深度学习研究人员都会用到。
经过增加神经元个数,增加迭代次数,设置适合学习率还有增大alpha参数值提高权值的正则化后,改变效果如下所示:
自制ANN调参
自制的神经网络需要对学习率、正则化系数、迭代次数参数进行调整。
根据上面MLP的先验经验,先设置隐藏层的节点个数为300个,表中是各情况下的预测精度。

由上表可知,最合适的学习率为0.001、正则系数0.0001,下面调整隐藏层节点的个数,增加复杂度使其更好地训练数据,从而更好地预测。
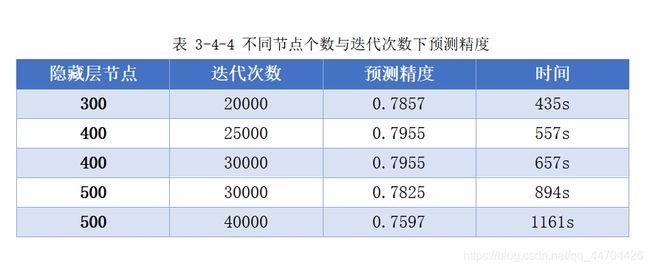
由上表可知选出的隐藏层节点个数为400,相应的迭代次数为25000。
以上的结果都是未加入数据预处理的,经过后续改进,加入数据标准化后,之前选出的各合适参数情况下的预测精度变为了0.8117,时间也缩短为364s。
Keras调参
利用Keras进行训练时,设置了三层dense,一层全连接层时,出现了过拟合情况,后来加入了在dense里面加入了正则项,并在每层dense后面添加了一个dropout层,有效地解决了过拟合情况,最终预测精度为0.7500。

数据预测
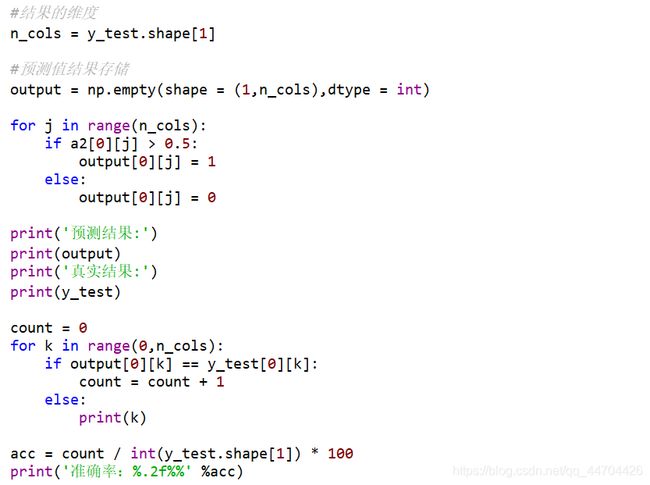
自制模型的预测
利用上面训练的模型进行预测,然后将预测的结果与真实样本实际分类值进行对比,正确个数与总个数的比即为预测的精度。
利用自带库的预测
通过python中的score函数,将预测的值和真实标签的值进行对比,最后再出相应的精度。

实验结果与分析
对于实验的结果这里用分类报告和混淆图来表现,利用的是sklearn中的库,调用代码如下所示:

分类报告中有精确率,召回率,f1率、各真实类别个数,预测精度、macro平均率和权重平均率。
准确率:被预测为正类样本中有多少是真正的正类,即P = TP/(TP+FP);
召回率:正类样本中有多少被预测为正类,即R = TP/(FN+TP);
f值,虽然准确率和召回率是非常重要的度量,但是仅查看二者之一无法提供完整的图景,将两种度量进行汇总的一种方法是f值,它是准确率与召回率的调和平均:F=2*(precision*recall) / (precision+recall),同时考虑了准确率和召回率,因此它对于不平衡的二分类数据集来说是一种比精度更好的度量。
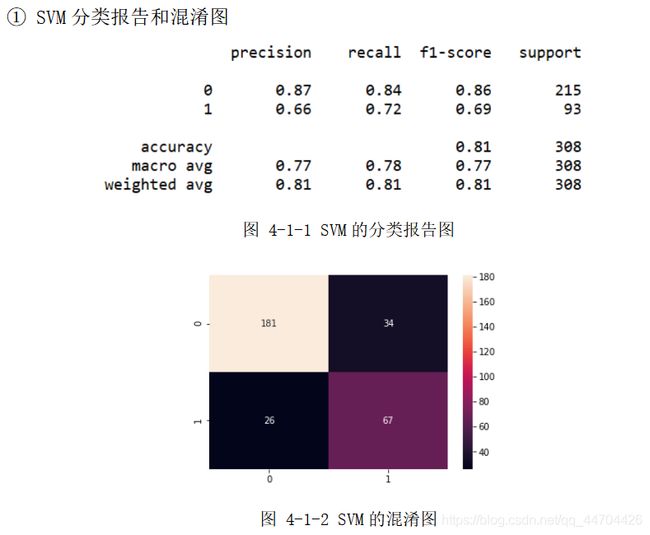
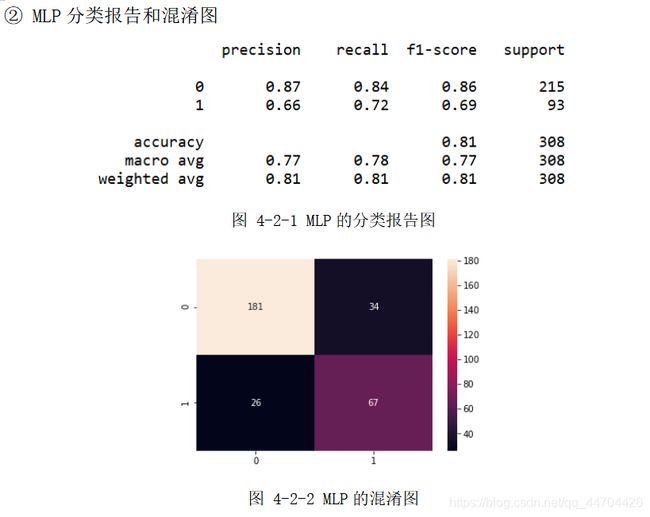
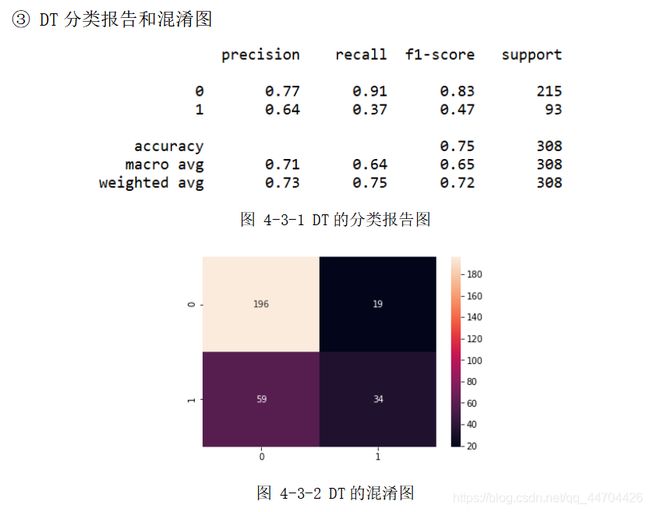
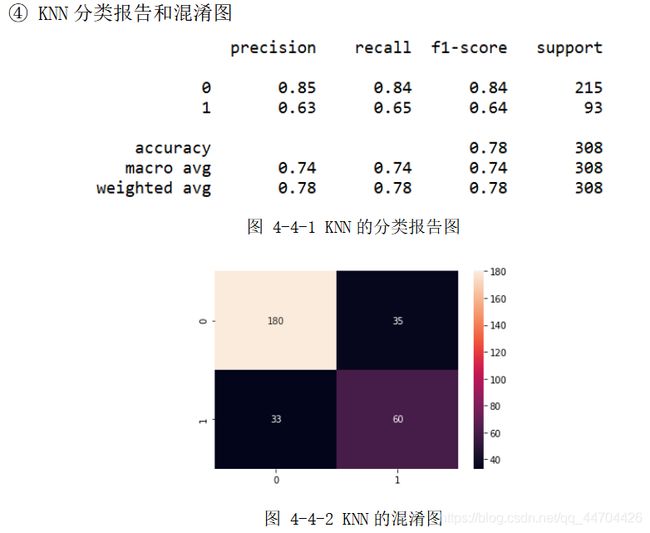
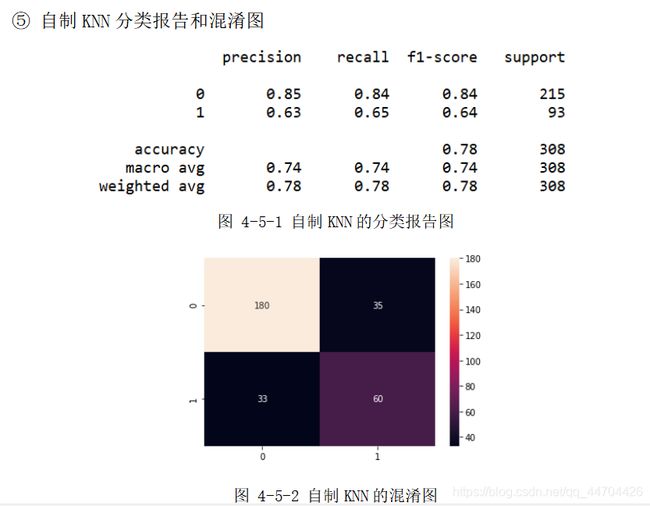
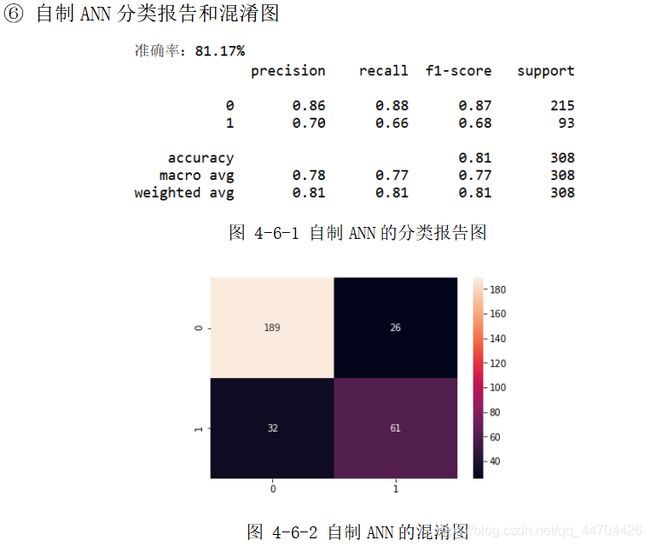
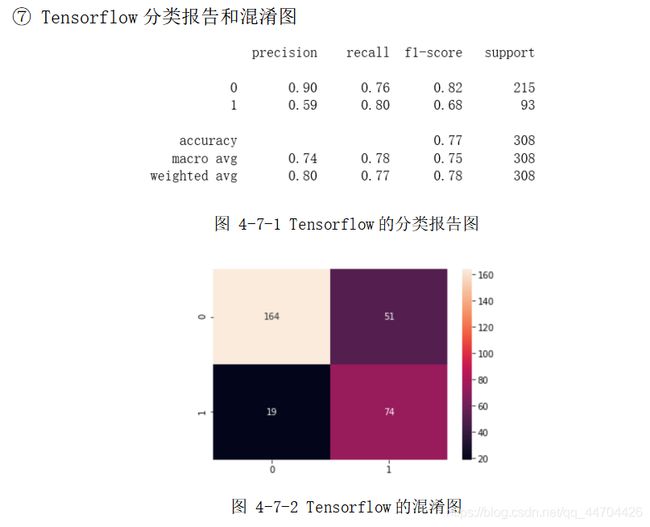

分析:经过前面的数据预处理和参数选择之后,根据上面的分类报告可以看出后40%的数据样本,即308个预测样本(其中215个分类为0,93个分类为 1)应用不同模型时的预测精度;
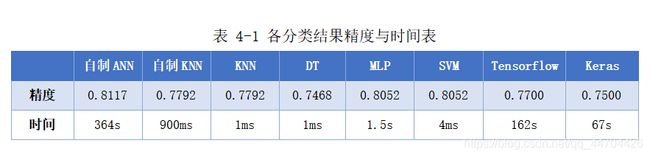
从表格中可以看到自制ANN的精度最高为81.17%,其次是SVM和MLP的80.52%,再接着是KNN的77.92%,Tensorflow的77%,最后是Keras的75%和DT的74.68%,在用时方面因ANN、MLP、Keras和Tensorflow都涉及到了网络,还有大量的迭代次数,因此单位都是s,而其他分类模型采用的是ms为单位,且用时最多的是自制的ANN,达到300s多,是因为其中应用的是自己写的梯度下降函数以及前、方向传播函数,算法还需进一步优化,综合来看可以选择SVM和MLP,不仅分类效果较好,用时还较少,效率高。
从上面的混淆图可以看到真实样本为0或1,实际被分类为0或1的样本个数,大体来说,0的正确分类率大于1被正确分类的比率,是因为在460个训练样本(285个0样本,175个1样本)和308个预测样本(215个0样本,93个1样本)中,0和1样本分布个数不均匀,1的个数大概只有0个数的一半,即样本概率分布不均匀,造成样本数量1的不足,训练模型时不能够更好地刻画1的分类特征。
由于这次分类中涉及到8个属性,却只有868个数据样本,样本数据较少,所以一定程度上限制了精度的提高。
模型总结
SVM模型总结
优点:SVM是非常强大的模型,在各种模型数据集上的表现都很好,SVM允许决策边界很复杂,即使数据只有几个特征,它在低维数据和高维上的表现都很好,但对样本个数的缩放表现不好,比如在样本数为10000的数据集上表现良好,但是如果数据增加到1000000甚至更大,在运行时间和内存使用方法可能会面临挑战。
缺点:预处理数据和调参都需要非常小心;SVM模型很难检查,即可能很难理解为什么会这么预测,而且也难以将模型向非专家进行解释。
KNN模型总结
优点:模型很容易理解,通常不需要经过过多的调节就可以得到不错的性能;可以用于非线性分类,训练的时间复杂度比SVM低;和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感;由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属的类别,因此对于类域的交叉或重叠较多的待分类样本集来说,KNN方法较其他方法更为适合;该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量比较小的类域采用这种算法比较容易产生误分类情况。
缺点:计算量大,尤其是特征数量非常多的时候;样本不平衡的时候,对稀有类别的预测准确率低;球、树之类的模型建立需要大量的内存;是消极学习方法,基本上不学习,导致预测时速度比起逻辑回归之类的算法慢且相比决策树模型,KNN模型的可解释性不强。
MLP和ANN总结
优点:能够获取大量数据样本中包含的信息,并构建无比复杂的模型。给定足够的计算时间和数据,并且仔细调节参数,神经网络通常可以打败其他机器学习算法(无论是分类任务还是回归任务)。
缺点:通常需要很长的训练时间,如果数据包含不同种类的特征还需要仔细地预处理数据。
DT决策树总结
优点:模型较容易理解,且树可以被可视化分类各过程;需要很少的数据准备,即不需要另外的数据处理,创建虚拟变量并删除空白值等;使用树的成本是用于训练树的数据点数量的对数;是一种能够查看多种信息的算法,分析具有多变量的数据集,能够解决多输出问题;使用白盒模型,若给定的情况在模型中是可观察的,则条件的解释很容易通过布尔逻辑来解释,相比之下,在黑盒模型(如,人工神经网络),结果可能更难以解释;可以使用统计测试来验证模型,说明了模型的可靠性,即使其假设受到数据生成的真实模型的某种程度的侵犯,也能很好地执行。
缺点:决策树学习者可以创建过于复杂的树,不能很好地概括数据,即过拟合。因此剪枝等机制,设置叶节点所需的最小样本数或设置树的最大深度是避免此问题所必需的;决策树可能不稳定,因为数据中的小变化可能会导致生成完全不同的树,可以通过在集合中使用决策树缓解;学习最优决策树的问题在最优化的几个方面甚至简单的概念下被认为是NP完全的,因此实际决策树学习算法基于启发式算法,例如在每个节点进行局部最优决策的贪心算法,这样的算法不能保证返回全局最优决策树,可以通过在集合学习器中训练多棵树来缓解,其中特征和样本随机地用替换采样;有些概念很难学,因为决策树不能很容易地表达它们,例如XOR,奇偶校验或多路复用器问题,如果某些类占主导地位,决策树学习者会创建偏向性树,因此建议在拟合决策树之前平衡数据集。
心得
对于本次分类实验,我经过上网查阅资料后,首先对python以及Tensorflow程序语言有了更进一步理解与应用,对其中一些具体的库的应用如keras,matplotlib,seaborn和sklearn有了更加熟练的掌握,不仅充分利用sklearn机器学习中已有的分类器,同时基于自己《人工智能》这门课上所学习的机器学习里的ANN和KNN原理,自己编写了相应的分类模型代码,然后先对各分类器的参数有了进一步了解,接着不断调整参数直到找到合适的参数,并通过调用时间函数,对算法性能做了一定的提高,最后通过分类报告以及混淆图对分类的结果进行了分析,并对各分类模型的优缺点进行了总结。
这里我将重点分享下我对欠拟合和过拟合的心得。
若测试集的准确率高于训练集的准确率,这种情况被称为欠拟合,一般是因为数据集太小或数据集切分为训练集或测试集时不均匀以及测试集的测试样本的概率问题,即没有很好地涵盖整个样本的特征表达。可以采取交叉验证方法来划分数据集,即每个数据样本既有作为训练集,又有作为测试集,交叉验证保证每个样本刚好在测试集中出现一次:每个样本位于一个折中,而每个折都在测试集中出现一次。因此,模型需要对数据集中所有样本的泛化能力都很好,才能让所有的交叉验证得分都很高。对数据进行多次划分,还可以提供模型对训练集选择的敏感性信息。根据每个折的得分成绩,可知模型应用于新数据时在最坏情况和最好情况下的可能表现。数据的使用更加高效。在比例划分数据时候,只有75%数据用于训练,25%数据用于评估,使用5交叉验证时,在每次迭代中可以使用80%的数据来拟合模型。但由于本次实验要求中,老师已经说明数据集前60%用于训练,后40%用于测试,且样本数据顺序不可以变化,因此不可以采用随机划分或交叉验证划分。
若训练集地准确率高于测试集的准确率,这种情况被称为过拟合,即模型的复杂度较高、训练的数据样本过少以及数据的噪声较大,可以进一步地增加训练的数据,可以采用交叉验证训练模型,降低模型复杂度(增加正则项:L1,L2),或添加dropout(神经网络中,让神经元一定的概率不工作)等。
本次分类实验只是机器学习中的很小一部分,由此可见机器学习、深度学习的应用之多、涉及之广,因此需要不断学习,不断动手实践,才可以很好地应用这些前沿知识。
参考文献
[1] Peter Hall,Byeong U.Park & Richard J. Samworth. Choice of Neighbor Order In Nearest Neighbor Classification,2008.
[2] N.S.Altman. An Introduction to Kernel and Nearest Neighbor Nonparametric Regression,1992.
[3] http://www.wildml.com/2015/09/implementing-a-neural-network-from-scratch/
[4] Ian Goodfellow, Yoshua Bengio, Aaron Courville, Deep Learning, MIT Press, 2016.
PS
以上便是针对糖尿病数据集的一次分类实验,以上为了方便显示公式什么的,先在word里面写了一遍,然后直接截图到这里~所以图比较多。
具体代码没有上传,因为py文件比较多~
想要代码参考的小伙伴可以在下方留言~
