Python计算机视觉——基于BOW的图像检索
基于BOW的图像检索
- 一、图像检索概述
-
- 1.1 基于文本的图像检索(TBIR)
- 1.2 基于内容的图像检索(CBIR)
-
- 1.2.1 矢量空间模型(BOW表示模型、Bag of Words)
- 1.2.2 视觉单词
- 1.2.3 K − m e a n s K-means K−means 算法
- 1.3 Bag of features原理
-
- 1.3.1 Bag of features 图像检索流程
- 1.3.2 特征提取
- 1.3.3 学习特征词典
- 1.3.3 对输入特征集进行量化
- 1.3.4 单词的TF-IDF权重
- 1.3.5 倒排表
- 1.3.6 直方图匹配
- 二、Python实现过程
-
- 2.1 准备图片集
- 2.2 代码实现过程
-
- 2.2.1 提取SIFT特征、生成视觉词典
- 2.2.2 视觉词典进行量化生成数据库
- 2.2.3 图像检索
- 2.3 实验结果及分析
- 2.4 出现问题及解决
-
- 1、`ModuleNotFoundError: No module named 'pysqlite2'`
- 2、`TypeError: a bytes-like object is required, not 'str''`
- 3、`TypeError: 'cmp' is an invalid keyword argument for sort()''`
一、图像检索概述
从20世纪70年代开始,有关图像检索的研究就已开始,当时主要是 基于文本的图像检索技术 (Text-based Image Retrieval,简称 TBIR),利用文本描述的方式描述图像的特征,如绘画作品的作者、年代、流派、尺寸等。到90年代以后,出现了对图像的内容语义,如图像的颜色、纹理、布局等进行分析和检索的图像检索技术,即 基于内容的图像检索 (Content-based Image Retrieval,简称 CBIR)技术。
因此按描述图像内容方式的不同可以分为两类:
- 基于文本的图像检索(TBIR, Text Based Image Retrieval)
- 基于内容的图像检索(CBIR, Content Based Image Retrieval)
1.1 基于文本的图像检索(TBIR)
基于文本的图像检索方法始于上世纪70年代,它利用文本标注的方式对图像中的内容进行描述,从而为每幅图像形成描述这幅图像内容的关键词,比如图像中的物体、场景等,这种方式可以是人工标注方式,也可以通过图像识别技术进行半自动标注。在进行检索时,用户可以根据自己的兴趣提供查询关键字,检索系统根据用户提供的查询关键字找出那些标注有该查询关键字对应的图片,最后将查询的结果返回给用户。
这种基于文本描述的图像检索方式由于易于实现,且在标注时有人工介入,所以其查准率也相对较高。但是这种基于文本描述的方式所带来的缺陷也是非常明显的:
- 这种基于文本描述的方式需要人工介入标注过程,使得它只适用于小规模的图像数据,在大规模图像数据上要完成这一过程需要耗费大量的人力与财力
- 对于需要精确的查询,用户有时很难用简短的关键字来描述出自己真正想要获取的图像
- 人工标注过程不可避免的会受到标注者的认知水平、言语使用以及主观判断等的影响,因此会造成文字描述图片的差异
1.2 基于内容的图像检索(CBIR)
随着图像数据快速增长,针对基于文本的图像检索方法日益凸现的问题,在1992年美国国家科学基金会就图像数据库管理系统新发展方向达成一致共识,即表示索引图像信息的最有效方式应该是基于图像内容自身的。自此,基于内容的图像检索技术便逐步建立起来,并在近十多年里得到了迅速的发展。
| 基于内容的图像检索基本框架,红色箭头表示训练过程,灰色表示查询过程 |
|---|
 |
CBIR 利用计算机对图像进行分析,建立图像特征矢量描述(SIFT特征提取 )并存入图像特征库,当用户输入一张查询图像时,用相同的特征提取方法(SIFT)提取查询图像的特征得到查询向量,然后在某种相似性度量准则下计算查询向量到特征库中各个特征的相似性大小,最后按相似性大小进行排序并顺序输出对应的图片。
基于内容的图像检索技术将图像内容的表达和相似性度量交给计算机进行自动的处理,克服了采用文本进行图像检索所面临的缺陷,并且充分发挥了计算机长于计算的优势,大大提高了检索的效率,从而为海量图像库的检索开启了新的大门。
图像检索:基于内容的图像检索技术
1.2.1 矢量空间模型(BOW表示模型、Bag of Words)
矢量空间模型 是一个用于表示和搜索文本文档的模型。它基本上可以应用于任何对象类型,包括图像。该名字来源于用矢量来表示文本文档,这些矢量是由文本词频直方图构成的。矢量包括了每个单词出现的次数,而且在其他别的地方包含很多 0 元素。由于其忽略了单词出现的顺序及位置,该模型也被称为 BOW 表示模型(Bag of Words)。
通过单词计数来构建文档直方图向量 v v v,从而建立文档索引。通常,在单词计数时会忽略掉一些常用词,如 “这” “和” “是” 等,这些常用词称为 停用词 。由于每篇文档长度不同,故除以直方图总和将向量归一化成单位长度。对于直方图向量中的每个元素,一般根据每个单词的重要性来赋予相应的权重。通常,数据集(或语料库)中一个单词的重要性与它在文档中出现的次数成正比,而与它在语料库中出现的次数成反比。
最常用的权重是 tf-idf (term frequency-inverse document frequency,词频-逆向文档频率),单词 w w w 在文档 d d d 中的词频是: t f w , d = n w ∑ j n j tf_{w,d} = \frac{n_w} {\sum_j n_j} tfw,d=∑jnjnw n w n_w nw 是单词 w w w 在文档 d d d 中的出现的次数。为了归一化,将 n w n_w nw 除以整个文档中单词的总数。
逆向文档频率为: i d f w , d = log ∣ ( D ) ∣ ∣ { d : w ∈ d } ∣ idf_{w,d} = \log {\frac{|(D)|}{|\{ d:w\in d \}|}} idfw,d=log∣{d:w∈d}∣∣(D)∣ ∣ D ∣ |D| ∣D∣是在语料库 D D D 中文档的数目,分母是语料库中包含单词 w w w 的文档数 d d d。将两者相乘可以得到矢量 v v v 中对应元素的 t f − i d f tf-idf tf−idf 权重。
1.2.2 视觉单词
为了将文本挖掘技术应用到图像中,我们首先需要建立视觉等效单词,通常采用SIFT局部描述子技术。它的思想是将描述子空间量化成一些典型实例,并将图像中的每个描述子指派到其中的某个实例中。这些典型实例可以通过分析训练图像集确定,并被视为视觉单词。所有这些视觉单词构成的集合称为 视觉词汇 ,有时也称为 视觉码本 。对于给定的问题、图像类型,或在通常情况下仅需要呈现视觉内容,可以创建特定的词汇。
从一个训练图像集提取特征描述子,利用一些聚类算法可以构建出视觉单词。聚类算法中最常用的是 K − m e a n s K-means K−means 算法。视觉单词并不高端,只是在给定特征描述子空间中的一组向量集,在采用 K − m e a n s K-means K−means 进行聚类时得到的视觉单词是聚类质心。用视觉单词直方图来表示图像,则该模型便称为 BOW 模型。
1.2.3 K − m e a n s K-means K−means 算法
K − m e a n s K-means K−means 算法
最小化每个特征 x i x_i xi 与其相对应的聚类中心 m k m_k mk 之间的欧式距离 D ( X , M ) = ∑ c l i s t e r k ∑ p o i n t i i n c l i s t e r k ( x i − m k ) 2 D(X,M) = \sum_{clister k}\sum_{point i in clister k} {(x_i - m_k)^2} D(X,M)=clisterk∑pointiinclisterk∑(xi−mk)2
算法流程:
- 随机初始化 K 个聚类中心
- 重复下述步骤直至算法收敛:
- 对应每个特征,根据距离关系赋值给某个中心/类别
- 对每个类别,根据其对应的特征集重新计算聚类中心
- 聚类是实现 visual vocabulary /codebook的关键
- 无监督学习策略
- k-means 算法获取的聚类中心作为 codevector
- Codebook 可以通过不同的训练集协同训练获得
- 一旦训练集准备足够充分, 训练出来的码本( codebook)将具有普适性
- 码本/字典用于对输入图片的特征集进行量化
- 对于输入特征,量化的过程是将该特征映射到距离其最接近的 codevector ,并实现计数
- 码本 = 视觉词典
- Codevector = 视觉单词
1.3 Bag of features原理
Bag of Feature 是一种图像特征提取方法,它借鉴了文本分类的思路(Bag of Words),从图像抽象出很多具有代表性的「关键词」,形成一个字典,再统计每张图片中出现的「关键词」数量,得到图片的特征向量。

1.3.1 Bag of features 图像检索流程
图像检索流程
- 特征提取
- 学习 “视觉词典(visual vocabulary)”
- 针对输入特征集,根据视觉词典进行量化
- 把输入图像转化成视觉单词(visual words)的频率直方图
- 构造特征到图像的倒排表,通过倒排表快速索引相关图像
- 根据索引结果进行直方图匹配
1.3.2 特征提取
特征提取通常使用 SIFT局部描述子技术,具体过程与上述的视觉单词流程类似。
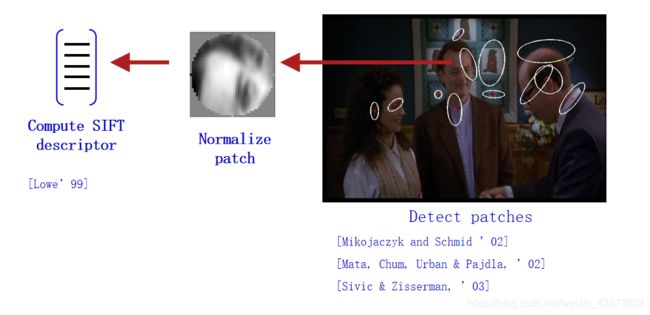

1.3.3 学习特征词典
在提取完图像特征后,下一步是学习特征词典,利用一些聚类算法可以构建出视觉单词,而聚类算法中最常用的是 K − m e a n s K-means K−means 算法。 K − m e a n s K-means K−means 算法具体流程在上述视觉单词模块中。
 |
 |
 |
|---|
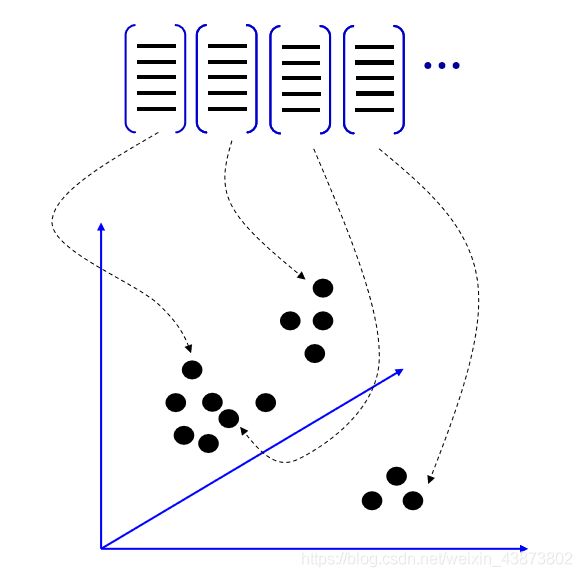
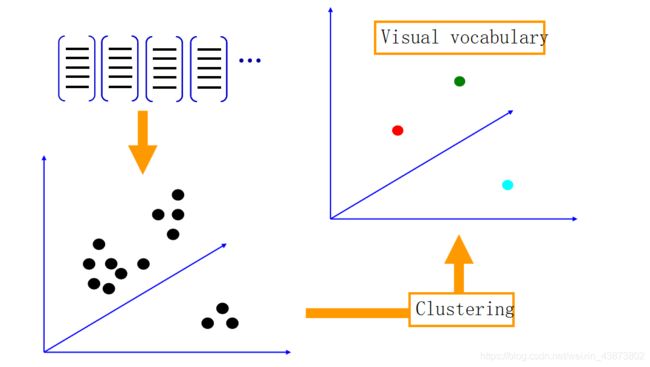
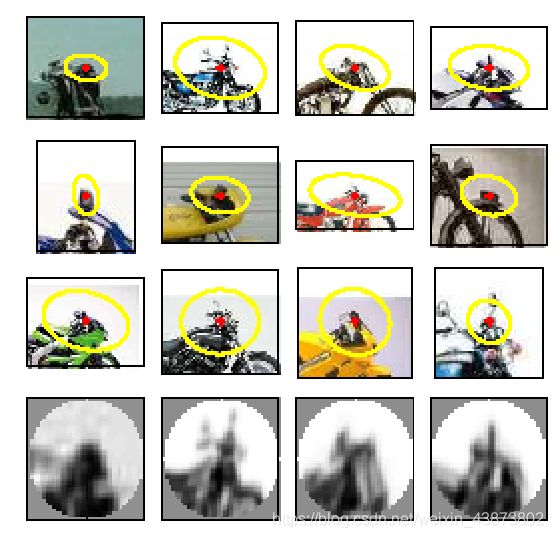
聚类后,就得到了这 k k k 个向量组成的词典,称为visual words(视觉单词)。所有这些视觉单词构成的集合称为 视觉词汇
视觉单词样例:
 |
 |
 |
|---|
1.3.3 对输入特征集进行量化
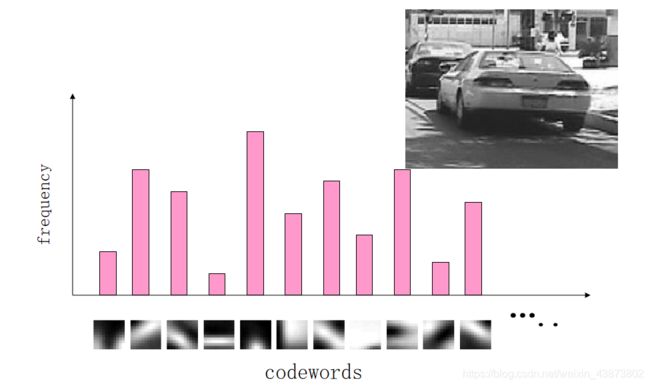
上一步训练得到的字典,是为了这一步对图像特征进行量化。对于一幅图像而言,我们可以提取出大量的「SIFT」特征点,但这些特征点仍然属于一种浅层(low level)的表达,缺乏代表性。因此,这一步的目标,是根据字典重新提取图像的高层特征。
具体做法是,对于图像中的每一个「SIFT」特征,都可以在字典中找到一个最相似的 visual word,这样,我们可以统计一个 k 维的直方图,代表该图像的「SIFT」特征在字典中的相似度频率。
我们匹配图片的「SIFT」向量与字典中的 visual word,统计出最相似的向量出现的次数,最后得到这幅图片的直方图向量。
1.3.4 单词的TF-IDF权重
在上述介绍中,在矢量空间模型中提到了单词权重,在文本检索中,不同单词对文本检索的贡献有差异,所以在将输入图像转换为频率直方图时需要根据TF-IDF赋予权值。具体流程在上述视觉单词模块中提及。
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
1.3.5 倒排表
倒排表是一种逆向的索引方法,构造倒排表可以快速索引图像。倒排索引,通过搜索要查询的关键字,查询到跟该关键字相关的所有文档。倒排表可以获得是各视觉单词出现在图像库的哪些图像中。
1.3.6 直方图匹配
最后,根据索引的结果进行直方图匹配,就完成了图像索引。

二、Python实现过程
2.1 准备图片集
本次实验准备了 129 张动物类型的图片集。
本次实验所有的图片均来自网络
2.2 代码实现过程
2.2.1 提取SIFT特征、生成视觉词典
import pickle
from PCV.imagesearch import vocabulary
from PCV.tools.imtools import get_imlist
from PCV.localdescriptors import sift
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from sqlite3 import dbapi2 as sqlite
#获取图像列表
imlist = get_imlist('./datasets/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#提取文件夹下图像的sift特征
for i in range(nbr_images):
sift.process_image(imlist[i], featlist[i])
#生成词汇
voc = vocabulary.Vocabulary('ukbenchtest')
voc.train(featlist, 888, 10) # 使用k-means算法在featurelist里边训练处一个词汇
# 注意这里使用了下采样的操作加快训练速度
# 将描述子投影到词汇上,以便创建直方图
#保存词汇
# saving vocabulary
with open('./BOW/vocabulary.pkl', 'wb') as f:
pickle.dump(voc, f)
print ('vocabulary is:', voc.name, voc.nbr_words)
2.2.2 视觉词典进行量化生成数据库
import pickle
from PCV.imagesearch import vocabulary
from PCV.tools.imtools import get_imlist
from PCV.localdescriptors import sift
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from sqlite3 import dbapi2 as sqlite # 使用sqlite作为数据库
#获取图像列表
imlist = get_imlist('./datasets/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
# load vocabulary
#载入词汇
with open('./BOW/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
#创建索引
indx = imagesearch.Indexer('testImaAdd.db',voc) # 在Indexer这个类中创建表、索引,将图像数据写入数据库
indx.create_tables() # 创建表
# go through all images, project features on vocabulary and insert
#遍历所有的图像,并将它们的特征投影到词汇上
for i in range(nbr_images)[:888]:
print(featlist[i])
locs,descr = sift.read_features_from_file(featlist[i])
indx.add_to_index(imlist[i],descr) # 使用add_to_index获取带有特征描述子的图像,投影到词汇上
# 将图像的单词直方图编码存储
# commit to database
#提交到数据库
indx.db_commit()
con = sqlite.connect('testImaAdd.db')
print (con.execute('select count (filename) from imlist').fetchone())
print (con.execute('select * from imlist').fetchone())
2.2.3 图像检索
# -*- coding: utf-8 -*-
#使用视觉单词表示图像时不包含图像特征的位置信息
import pickle
from PCV.localdescriptors import sift
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from PCV.tools.imtools import get_imlist
# load image list and vocabulary
#载入图像列表
imlist = get_imlist('./datasets/')
nbr_images = len(imlist)
#载入特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#载入词汇
with open('./BOW/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
src = imagesearch.Searcher('testImaAdd.db',voc)# Searcher类读入图像的单词直方图执行查询
# index of query image and number of results to return
#查询图像索引和查询返回的图像数
q_ind = 4
nbr_results = 2
# regular query
# 常规查询(按欧式距离对结果排序)
res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]] # 查询的结果
print ('top matches (regular):', res_reg)
# load image features for query image
#载入查询图像特征进行匹配
q_locs,q_descr = sift.read_features_from_file(featlist[q_ind])
fp = homography.make_homog(q_locs[:,:2].T)
# RANSAC model for homography fitting
#用单应性进行拟合建立RANSAC模型
model = homography.RansacModel()
rank = {}
# load image features for result
#载入候选图像的特征
for ndx in res_reg[1:]:
try:
locs, descr = sift.read_features_from_file(featlist[ndx])
except:
continue
# locs,descr = sift.read_features_from_file(featlist[ndx]) # because 'ndx' is a rowid of the DB that starts at 1
# get matches
matches = sift.match(q_descr,descr)
ind = matches.nonzero()[0]
ind2 = matches[ind]
tp = homography.make_homog(locs[:,:2].T)
# compute homography, count inliers. if not enough matches return empty list
# 计算单应性矩阵
try:
H,inliers = homography.H_from_ransac(fp[:,ind],tp[:,ind2],model,match_theshold=4)
except:
inliers = []
# store inlier count
rank[ndx] = len(inliers)
# sort dictionary to get the most inliers first
# 对字典进行排序,可以得到重排之后的查询结果
sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True)
res_geom = [res_reg[0]]+[s[0] for s in sorted_rank]
print ('top matches (homography):', res_geom)
# 显示查询结果
imagesearch.plot_results(src,res_reg[:6]) #常规查询
imagesearch.plot_results(src,res_geom[:6]) #重排后的结果
2.3 实验结果及分析
在使用 k-means 算法学习 “视觉词典(visual vocabulary)”,生成了维度分别为 (10,50,100,1000,5000)的视觉字典来进行对比。
| 不同维度的视觉字典 | 不同维度的数据库 |
|---|---|
 |
 |
用于查询的图片:

维度为10
| 常规查询结果 | 重排后的结果 |
|---|---|
 |
 |
维度为50
| 常规查询结果 | 重排后的结果 |
|---|---|
 |
 |
维度为100
| 常规查询结果 | 重排后的结果 |
|---|---|
 |
 |
维度为1000
| 常规查询结果 | 重排后的结果 |
|---|---|
 |
 |
维度为5000
| 常规查询结果 | 重排后的结果 |
|---|---|
 |
 |
结果分析:
输入一张猫的图像,在数据库中检索,检索的结果显不全是猫,并且不同维度检测的效果也都不同,检查结果中出现了狗、马、羊、袋鼠、大象等不同的动物。从检索的图像中查看,可以看出一些图片,像维度1000中的袋鼠,检测出来可能是因为这张图片和要检索的图片在提取SIFT特征时比较接近,因为要检索的图像中,猫的毛颜色比较统一,所以提取出的特征点分布在身体边缘、头部、脚这些轮廓较为明显的区域,并且其背景也造成了一些影响,同时可以发现,袋鼠哪一张图片,也是身体边缘的轮廓比较明显,所以在与袋鼠那张图片匹配时,就可能匹配上,出现上述的结果。
而不用维度的情况下,一般来说,随着维度的增加,检索的结果随着维度的增加效果越好,因为维度越大,其中所包含的信息就越多,但是当维度过于大的时候,就可能使得检索结果更差,因为此时计算量大,容易过拟合,而维度太小,就使得视觉单词无法覆盖所有可能出现的情况,使得检索效果不好。
同时,使用的图片对本次实验也有影响,一些图片背景比较复杂,就会导致特征点提取的时候提取到一些无关的特征点,所以可能使得实验检索的效果不好,因为这些特征点可能会导致匹配出现问题。
2.4 出现问题及解决
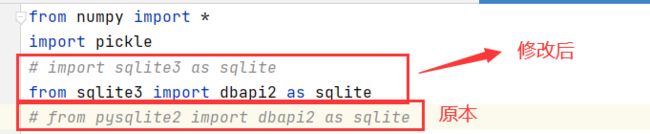
1、ModuleNotFoundError: No module named 'pysqlite2'
如果出现该的报错,按住Alt然后鼠标点击进入到imagesearch.py文件中报错的位置。
然后将from pysqlite2 import dbapi2 as sqlite修改为import sqlite3 as sqlite或者from sqlite3 import dbapi2 as sqlite
因为 python3 中已将 pysqlite2 取消了。

2、TypeError: a bytes-like object is required, not 'str''
如果出现该报错,同样的进入imagesearch.py文件中的报错位置,将其中的str删除掉,因为 python3和Python2.7在套接字返回值解码上有区别,


3、TypeError: 'cmp' is an invalid keyword argument for sort()''
如果出现该报错,同样的,需要点击进入imagesearch.py文件中的报错位置,这个报错的原因是因为 python3 中的sort函数sort(*, key=None, reverse=None)取消了cmp参数
所以我们需要先引入from functools import cmp_to_key
然后需要将原本的tmp.sort(cmp=lambda x,y:cmp(x[1],y[1]))修改为tmp.sort(key=cmp_to_key(lambda x, y: x[1] - y[1]))