高速缓存
现在处理器的处理能力要远超于主内存的访问速率,一次主内存的读或写操作所需要的时间足够处理器执行几百条指令,为了弥补处理器和主内存处理能力之间的鸿沟,便在处理器和主内存之间引进了高速缓存.
高速缓存是一种读取速率远超主内存,但是容量远小于主内存的一种的一种存储部件,每个处理器都拥有自己的高速缓存.
- 在高速缓存中,相当于为访问程序的每一个变量存储一个副本,变量名为相当于内存地址,变量值相当于相应内存空间所存储的数据,但是高速缓存中并不每时每刻包含所有变量的副本.
高速缓存相当于用硬件实现的一个散列表(拉链法),其键(key)是一个内存地址,其值(value)是数据副本或要写入内存的数据.高速缓存的结构大致如下:

高速缓存是一个经典的拉链散列表结构,高速缓存包含若干桶,每个桶后面又包含若干个缓存条目,而一个缓存条目又可以分为:
TagData-Block和Flag三部分,Tag是用了来区分数据是在那个数据条目上,Flag是用来标识这个数据条目的状态.Data-Block也被叫做数据行是用来存储从主内存读取的数据或准备写入主内存的数据,一个数据行可能包含若干个变量的值.当处理器准备读取一条数据时,处理器会将相应的内存地址"解码"得到三个值:
- index - 用于确定桶编号
- tag - 用于确定缓存条目
- offset - 用于确定数据所在条目中的偏移量
若根据内存地址在高速缓存中找到这个数据就被称为缓存命中,否则处理器将会去主内存中去查找这条数据.
现在处理器一般会具有多个层次的高速缓存,相应的是 一级缓存(L1 Cache) 二级缓存(L2 Cache) 三级缓存(L3 Cache)等,一般一级缓存会被集成在处理器内核中,因此其访问速度非常高,一般情况下以及缓存的读取会在2-4个处理器时钟循环内完成,其中一部分用于存储指令(L1i),一部分用于存储数据(L1d),一般越靠近处理器核心的高速缓存,存取速率越高,制造成本越高,容量越小.
在linux系统可以使用
lscpu命令查看缓存层次
缓存一致性协议
MESI(Modified-Exclusive-Shared-Invalid)是一种广为使用的缓存一致性协议,X86处理器的缓存一致性协议就是基于MESI协议的,它对于访问的控制类似于读写锁,即对于同一地址的读操作时并发的,对于同一地址的写操作是独占的.
MESI协议将缓存条目的状态分为四种: Modified Exclusive Shared Invalid
- Invalid(无效的,记为I): 表示相应缓存行中不包含任何内存地址所对应的数据副本,该状态是缓存条目的初始状态.
- Shared(共享的,记为S): 表示相应的缓存行包含相应的内存地址所对应的数据副本,并且,其它处理器上的高速缓存中也可能有相同的内存地址对应的数据副本.所以一个缓存条目的状态是Shared,并且,如果其它处理器上也存在与这个给处理器相同的tag的缓存条目,那么这些缓存条目的状态也为Shared.处于这个状态的缓存条目,其缓存行中包含的数据是与主内存中包含的数据是一致的.
- Exclusive(独占的,记为E): 表示相应缓存行包含相应的内存地址对应的数据副本,并且,缓存行以独占的方式保留了内存地址所对应的数据副本,即,其它处理器中不存在这个内存地址所对应的数据副本,处于这个状态的缓存条目,其缓存行中包含的数据与主内存中包含的数据是一致的.
- Modified(更改过的,记为M): 表示相应缓存行包含相应的内存地址对应的更新结果,并且,由于MESI协议中规定任意时刻只能有一个处理器对同一个内存地址的数据做更改,所以其它处理器不存在这个内存地址所对应的数据副本,处于这个给状态的缓存条目,其缓存行中包含的数据是与主内存中包含的数据是不一致的.
MESI协议在这四种状态的基础上定义一组消息用于协调各个处理器之间的读写操作,比照HTTP协议,我们可以将MESI中的消息分为:请求消息 - 相应消息,处理器在执行内存的读写操作时会向总线发送相应的消息,其它处理器会拦截总线中的消息并在一定条件下往总线中回复相应的响应消息.
消息名 消息类型 描述 Read 请求 通知其它处理器、主内存当前处理器准备读取某个数据.该消息中包含准备读取消息的内存地址. Read Response 响应 该消息包含被请求读取的数据,可能来自于主内存也可能来自于其它拦截到读取消息的其他处理器. Invalidate 请求 通知其它处理器将各自高速缓存中的对应内存地址的缓存条目的状态置为I,即,通知这些处理器删除指定内存地址所对应的数据副本. Invalidate Acknowledge 响应 接收到Invalidate消息的处理器必须回复该消息,以表示它在高速缓存中删除了对应的数据副本. Read Invalidate 请求 该消息是由Read消息和Invalidate消息组成的复合消息,用于通知其它处理器,当前处理器准备更新一个数据(Read-Modify-Write),并请求器它处理器删除指定内存地址的对应的数据副本,收到这个消息的的处理器必须回复 Read Response消息和Invalidate Acknowledge消息 WriteBack 请求 该消息包含需要羞辱内存的数据信息和对应的内存地址 MESI读操作流程
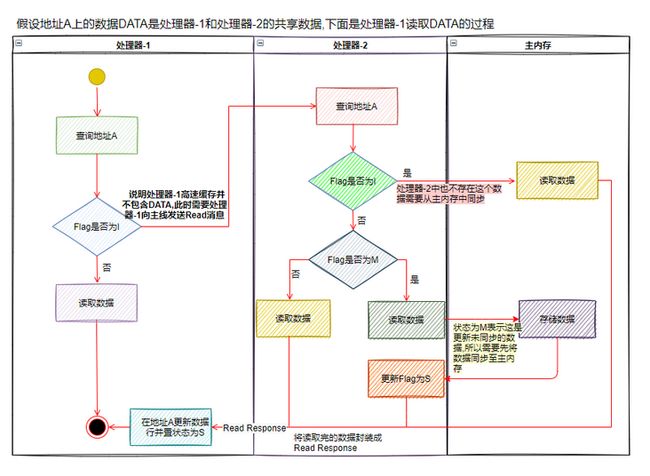
假设内存地址A上的数据DATA是处理器-1和处理器-2可能共享的数据。
下面讨论在处理器-1上读取数据DATA的实现。处理器-1会根据地址A找到对应的缓存条目,并读取该缓存条目的Tag和Flag值(缓存条目状态)。为讨论方便,这里我们不讨论Tag值的匹配问题。处理器-1找到的缓存条目的状态如果为M、E或者S,那么该处理器可以直接从相应的缓存行中读取地址A所对应的数据,而无须往总线中发送任何消息。处理器-1找到的缓存条目的状态如果为I,则说明该处理器的高速缓存中并不包含DATA的有效副本数据,此时处理器-1需要往总线发送Read消息以读取地址A对应的数据,而其他处理器处理器-2(或者主内存)则需要回复Read Response以提供相应的数据。
处理器-1接收到Read Response消息时,会将其中携带的数据(包含数据DATA的数据块)存入相应的缓存行并将相应缓存条目的状态更新为S。处理器-1接收到的Read Response消息可能来自主内存也可能来自其他处理器(处理器-2)。处理器-2会嗅探总线中由其他处理器发送的消息。处理器-2嗅探到Read消息的时候,会从该消息中取出待读取的内存地址,并根据该地址在其高速缓存中查找对应的缓存条目。如果处理器-2找到的缓存条目的状态不为I,则说明该处理器的高速缓存中有待读取数据的副本,此时处理器-2会构造相应的Read Response消息并将相应缓存行所存储的整块数据(而不仅仅是处理器-1所请求的数据DATA)“塞入”该消息。如果处理器-2找到的相应缓存条目的状态为M,那么处理器-2可能在往总线发送Read Response消息前将相应缓存行中的数据写入主内存。处理器-2往总线发送Read Response之后,相应缓存条目的状态会被更新为S。如果处理器-2找到的高速缓存条目的状态为I,那么处理器-1所接收到的Read Response消息就来自主内存。可见,在处理器-1读取内存的时候,即便处理器-2对相应的内存数据进行了更新且这种更新还停留在处理器-2的高速缓存中而造成高速缓存与主内存中的数据不一致,在MESI消息的协调下这种不一致也并不会导致处理器-1读取到一个过时的旧值。
MESI写操作流程

任何一个处理器执行内存写操作时必须拥有相应数据的所有权。在执行内存写操作时,处理器-1会先根据内存地址A找到相应的缓存条目。处理器-1所找到的缓存条目的状态若为E或者M,则说明该处理器已经拥有相应数据的所有权,此时该处理器可以直接将数据写入相应的缓存行并将相应缓存条目的状态更新为M。处理器-1所找到的缓存条目的状态如果不为E、M,则该处理器需要往总线发送Invalidate消息以获得数据的所有权。其他处理器接收到Invalidate消息后会将其高速缓存中相应的缓存条目状态更新为I(相当于删除相应的副本数据)并回复Invalidate Acknowledge消息。发送Invalidate消息的处理器(即内存写操作的执行处理器),必须在接收到其他所有处理器所回复的所有Invalidate Acknowledge消息之后再将数据更新到相应的缓存行之中。
处理器-1所找到的缓存条目的状态若为S,则说明处理器-2上的高速缓存可能也保留了地址A对应的数据副本,此时处理器-1需要往总线发送Invalidate消息。处理器-1在接收到其他所有处理器所回复的Invalidate Acknowledge消息之后会将相应的缓存条目的状态更新为E,此时处理器-1获得了地址A上数据的所有权。接着,处理器-1便可以将数据写入相应的缓存行,并将相应的缓存条目的状态更新为M。处理器-1所找到的缓存条目的状态若为I,则表示该处理器不包含地址A对应的有效副本数据,此时处理器-1需要往总线发送Read Invalidate消息。处理器-1在接收到Read Response消息以及其他所有处理器所回复的Invalidate Acknowledge消息之后,会将相应缓存条目的状态更新为E,这表示该处理器已经获得相应数据的所有权。接着,处理器-1便可以往相应的缓存行中写入数据了并将相应缓存条目的状态更新为M。其他处理器在接收到Invalidate消息或者Read Invalidate消息之后,必须根据消息中包含的内存地址在该处理器的高速缓存中查找相应的高速缓存条目。若处理器-2所找到的高速缓存条目的状态不为I,那么处理器-2必须将相应缓存条目的状态更新为I,以删除相应的副本数据并给总线回复Invalidate Acknowledge消息。可见,Invalidate消息和Invalidate Acknowledge消息使得针对同一个内存地址的写操作在任意一个时刻只能由一个处理器执行,从而避免了多个处理器同时更新同一数据可能导致的数据不一致问题。
写缓冲器和无效化队列
- MESI协议解决了缓存一致性问题,但是,当一个处理器在进行写操作时,必须等待其它处理器将对应的数据副本删除后并回复Invalidate Acknowledge/Read Response消息才能将数据写入高速缓存,为了解决性能问题,便引入了写缓冲器和无效化队列.
- 写缓冲器时处理器内部一个比高速缓存容量还小的私有存储部件,每个处理器都有自己的写缓冲器,写缓冲器内部可能包含多个条目,一个处理器不能读取另一个处理器的写缓冲器.
- 当处理器在进行写操作时,如果对应的缓存条目为I(或者S),处理器会先将写操作相关的数据(包含数据和待操作的内存地址)存入写缓冲器的相关条目当中,并发送Read Invalidate(Invalidate)消息,若其它所有处理器对应的条目状态全部也为I,那么,就发生了所谓的"写未命中",即Read请求会进行主内存读操作,这样是开销比较大的,所以处理器在收到主内存返回的相应内存地址对应的数据,将其写入写缓冲器后,就不再等待其它处理器回复Read Response /Invalidate Acknowledge消息而是继续执行其它指令,等到所有处理器的Read Response /Invalidate Acknowledge消息返回成功,那么写缓冲区再将数据写入高速缓存.
- 处理器在收到Invalidate消息后并不删除指定缓存条目中的数据,而是先将消息存入到无效化队列,然后回复Invalidate Acknowledge消息,以减少处理器的等待时间,然后再从无效化队列中读取消息删除相关数据,某些处理器并不拥有无效化队列(比如X86处理器)
存储转发
处理器在进行读操作的时候,由于对应内存地址的变量可能刚写完,还没有从写缓冲器同步到高速缓存中去,所以在处理读的时候,会先去写缓冲器中读取是否存在相应的条目,如果没有就去高速缓存中读取,但是一个处理器并不能读取其它处理器的写缓冲区.
内存重排序
写缓冲器和无效化队列都可能导致内存重排序.
写缓冲器可能导致StoreLoad重排序
Processor 0 Processor 1 X=1; //S1 Y=1; //S3 r1=Y; //L2 r2=X; //L4 如上表X、Y均为共享变量其初始值均为0,r1、r2为局部变量
当Processor 0执行到L2的时候,如果S3的操作的结果还处于写缓冲器之中,那么L2读取到Y的值还是初始值0,同样当Processor 1执行L4的时候S1的操作结果也还处于写缓冲器之中,那么r2读取到X的值也为初始值 0,对于此时的Processor 1看来S1是没有发生的,即Processor的执行顺序为L2→S1这就是所谓的StoreLoad重排序.
写缓冲器可能导致StoreStore重排序
Processor 0 Processor 1 data=1; //S1 ready=true; //S2 while(! ready) continue; //L3 print(data); //L4 如上表data和ready是共享变量,初始值为0和false,在执行之前它们在Processor 0处理器所对应的缓存条目状态分别为S(或者I)和E,在Processor 1上对应的缓存条目为S和I
- 当执行到S1时,Processor 0会先把S1的操作结果存到写缓冲器中,然后向其它处理器发出Invalidate请求....
- ready由于时Processor 0独享的数据,所以S2的结果被直接存入到了高速缓存当中
- L3通过缓存一致性协议成功读取到了ready的新值true
- L4由于S1的操作结果还没有从写缓冲器同步至高速缓存,所以读取的的data值还是一个旧值为0
就Processor 1感知到的顺序在Processor 0中ready的值已经改变,data还是初始值,即S2→S1,这就是StoreStore重排序.
无效化队列造成LoadLoad重排序
Processor 0 Processor 1 data=1; //S1 ready=true; //S2 while(! ready) continue; //L3 print(data); //L4 如上表data和ready是共享变量,初始值为0和false,在执行之前它们在Processor 0处理器所对应的缓存条目状态分别为S和E,在Processor 1上对应的缓存条目为S和I
- S1是对data变量做修改,Processor 0会先将S1的操作结果放入写缓冲器,然后向总线发送携有data内存地址信息的Invalidate请求,Processor 1拦截到这个请求后,回复一个Invalidate Acknowledge消息,然后,把请求放入无效化队列
- S2中ready是Processor 0独占的,所以Processor 0直接将ready修改为true存到高速缓存中
- L3通过缓存一致性协议从Processor 0中同步了ready的值,while条件为false进入L4
- L4中可能出现这种情况,由于1中的Invalidate请求还在Processor 1的无效化队列当中,此时L4还能直接从其高速缓存中读取data的值,但是此时data=0,还是初始值
就Processor 0感知到Processor 1中的L4读取的data是一个旧值,即执行顺序为L4→L3,这就是LoadLoad重排序
可见性问题
可见性问题是由写缓冲器和无效化队列造成的,而解决可见性问题的方法就是在共享变量的读写时加入内存屏障.
存储屏障 → 会将写缓冲器中的内容冲刷到高速缓存,以免最新的数据不能够被其它处理器读到.
加载屏障 → 会将无效化队列中的请求执行,以免所在处理器读到的是一个旧值.
基本内存屏障
- 处理器支持哪种内存重排序(LoadLoad重排序,LoadStore重排序,StoreLoad重排序,StoreStore重排序)就会提供能够禁止相应重排序的指令,这种指令被称作内存屏障(LoadLoad屏障,LoadStore屏障,StoreLoad屏障,StoreStore屏障).
- 屏障的具体作用是禁止指令之间的重排序,例如LoadStore屏障就是禁止这个屏障之前的读指令与这个屏障之后的写指令重排序.
LoadLoad屏障 → 解决LoadLoad重排序(上文提到过是由无效化队列造成的)
所以LoadLoad屏障的实现原理就是通过清空无效化队列中的Invalidate消息来删除高速缓存中的无效副本来保证不发生重排序的.
加载屏障的实现方式
StoreStore屏障 → 解决StoreStore重排序
通过对写缓冲器中的条目进行标记来实现的,通过来判断条目的提交顺序,如果处理器在进行写操作的过程中发现写缓冲器中的条目存在标记现象,那么即使这个写操作对应的高速缓存中的数据的条目状态为E或M,也会将写的数据存入写缓冲器而不是高速缓存.这样就会保障屏障之前的写操作肯定会在屏障之后的操作前面提交至高速缓存
StoreLoad屏障 → 很多处理器的基本屏障
StoreLoad屏障能够代替其它任何屏障的作用,它的主要操作是冲刷写缓冲器缓存 + 清空无效化队列,所以StoreLoad的屏障的开销也是最大的.
同步机制和内存屏障
获取屏障(Acquire Barrier)&释放屏障(Release Barrier)两种屏障是由基础屏障组成的复合屏障
获取屏障 →LoadLoad屏障和LoadStore屏障组合而成,它能阻止屏障前的任何读操作与屏障后的读写操作发生重排序.
释放屏障→LoadStore屏障和StoreStore屏障组合而成,它能阻止屏障后的任何写操作和屏障前的读写操作发生重排序,
volatile与存储屏障
volatile关键字写操作的屏障使用方式

volatile关键字读操作的屏障使用方式
然后实际情况在X86处理器(常用的pc机,英特尔处理器 & amd处理器→其新推出锐龙的zen架构其实也属于X86)下只支持StoreLoad重排序(LoadLoad这种重排序根本不会发生),所以在X86处理器中,LoadLoad屏障、LoadStore屏障、StoreStore屏障都是空指令.
Synchronized相关的存储屏障:与volatile相同基本都是由几种基础屏障组成,但是synchronized修饰的是代码块,所以它不区分读写情况,所需要的屏障更多,所以开销更大,但是最终在X86处理器中只会存在StoreLoad屏障.
虚拟机会在MonitorEnter指令之后的临界区开始的之前的地方插入一个加载屏障保证其它线程对于共享变量的更新能够同步到线程所在处理器的高速缓存当中.同时,也会在MonitorExit指令之后插入一个存储屏障,保证临界区的代码对共享变量的变更能及时同步.
虚拟机会在MonitorEnter指令之后插入一个获取屏障,在MonitorExit指令之前插入一个释放屏障.

final的内存屏障规则
final 的重排序规则会要求译编器在 final 域的写之后,构造函数 return 之前,插入一个 StoreStore 障屏。
读 final 域的重排序规则要求编译器在读 final 域的操作前面插入一个 LoadLoad 屏障。
由于 x86 处理器不会对写 - 写操作做重排序,所以在 x86 处理器中,写 final 域需要的 StoreStore 障屏会被省略掉。同样,由于 x86 处理器不会对存在间接依赖关系的操作做重排序,所以在 x86 处理器中,读 final 域需要的 LoadLoad 屏障也会被省略掉。也就是说在 x86 处理器中,final 域的读 写不会插入任何内存屏障!
虚拟机对内存屏障的优化
这些优化包含省略、合并等,比如两个连续的volatile写操作,虚拟机只会在最后一个写操作的后面加一个StoreLoad屏障,X86处理器对每个MonitorExit的实现就带有StoreLoad的效果,所以就不需要在它后面加StoreLoad屏障.