前言
本篇文章我们有幸邀请到了东京大学在读博士生、云智慧智能研究院算法研究实习生房同学作为本期主讲人,为我们带来《分布迁移下的深度学习时间序列异常检测方法探究》的分享,下面就让我们一起来围观吧~
分布迁移问题
什么是分布迁移?监督式的机器学习与深度学习都基于一个假设:训练集与测试集的数据分布必须是一样的。如果分布不一样,就会导致在训练集上训练出来的模型在测试集上效果不好。下面举两个较典型的分布迁移例子:
- 类不均衡问题,如下图所示的二分类问题,目的是训练算法模型可以自动将猫与狗的照片进行分类。在图(a)训练集中猫的图片数量要远多于狗的图片数量(类不均衡),而在图(c)测试集中猫和狗的图片数大致是均衡的(类均衡),这就是一个类不均衡的分布迁移问题。
- label noise问题,通俗点理解就是数据标注错误,比如猫的图片标签却标成了狗。其实label noise问题在实际生活中也经常遇到,比如一些众包平台在实际打标的过程中出现的很多错误。label noise问题的训练集和测试集的分布也不一样,如图(b)训练集中存在一些标签错误的数据,但是在图(d)测试集中所有的数据都是打标正确的。

![]()
分布迁移是一个由来已久,且近些年非常普遍、重要且火热的研究问题。分布迁移问题在生活中普遍存在,并且对机器学习与深度学习算法是非常大的挑战。比如,用于自动驾驶的算法,训练集的数据可能是在晴天收集到的,因此算法模型就只在晴天的数据上进行训练。但部署此算法模型的汽车在驾驶中会遇到雨天的情况,而晴天与雨天收集到的数据的分布存在很大不同,因此该车在雨天行驶时就可能会导致非常严重甚至是车毁人亡的后果。

![]()

![]()

![]()
智能运维领域中广泛存在的分布迁移问题
- 运维数据和数据标签噪声。在对实际运维场景中的数据进行标注时,可能会存在打标错误的问题,并且数据本身也有可能存在噪声,这些潜在问题都可能会导致分布迁移,影响算法的效果。
- 不同运维数据的分布可能不同。一个算法模型可能需要在一种数据上进行训练,然后在另一种数据上检测其效果。若上述两种数据分布不同,则易于导致模型在后者效果不好。
- 历史数据与未来数据的分布迁移问题。算法在历史数据上训练得到算法模型及参数,然后用于未来数据。如果历史数据与未来数据的分布差异较大,则模型在未来数据上的表现可能较差。
- 数据收集过程中的分布迁移问题。 通过传感器收集数据的过程中,温度、湿度等环境因素会对所收集数据产生重要影响,这些影响很可能会改变算法的效果。
下图是Gartner Research 2020发表的中国技术发展的期望趋势图[1]。其中对未来智能运维(AIOps)平台的预期(红色标记)有所下降。这说明从业人员现阶段已经步入了智能运维的深水区,面临很多行业问题和挑战,比如分布迁移问题。解决此问题对于AIOps的发展有重要意义。
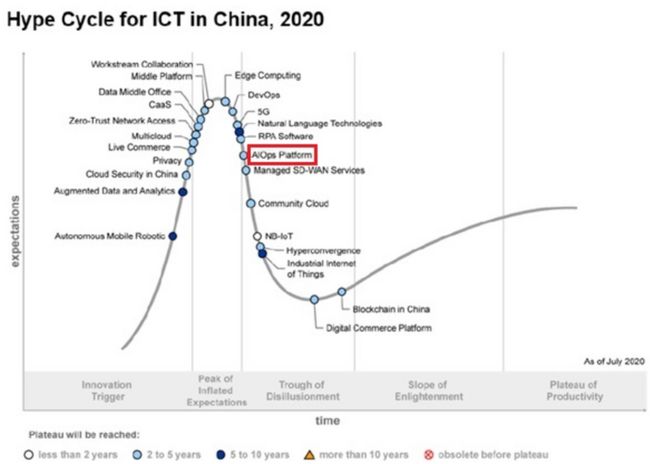
![]()
迁移学习的基本思路
迁移学习(transfer learning)是解决分布迁移问题的有效手段。下图阐述了其思路,左侧蓝框代表源域(Source domain),指大量有标数据的数据集,如MNIST数据集;右侧橙框代表目标域(Target domain),即研究关注的存在大量无标数据的数据集, 如SVHN数据集。此处任务(Task)是在SVHN数据集上的10分类问题。迁移学习的思路是算法模型通过在源域数据集上训练(手写数字数据MNIST的10分类问题)得到的可用知识,去解决目标域的问题(门牌号码数据SVHN的10分类问题)。

![]()
迁移学习分类
- 基于实例的迁移(Instance-level transfer)
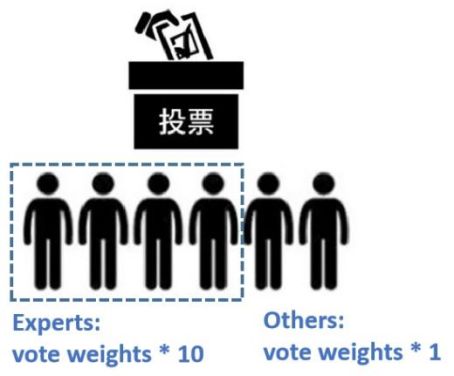
实例迁移的基本思路是给每个数据赋予不同的权重以缓解分布迁移的问题。如下图所示,通过投票的方式解决问题,专家权重较大,非专家权重较小。类似情况是,在模型训练过程中,权重越大表示这个数据点在迁移学习中越重要,因此这个数据对算法训练模型的贡献也会越大。
按重要性加权学习法(importance weighting)[2]是解决分布迁移非常经典的方法,很多分布迁移的工作均基于此方法。按重要性加权学习法主要有两个步骤:第一步计算权重(测试数据与训练数据分布的密度比),即每个训练数据的重要性程度。第二步是把第一步计算出的权重应用到分类中训练加权的分类器,权重大的数据会在分类任务中贡献更多。
![]()
- 基于特征的迁移(Feature-level transfer)
特征迁移希望算法模型学习到从源域到目标域不变的特征。一种方法是通过最大化域混淆损失使得算法模型分不清数据是来自源域还是目标域。另一种方法是基于对抗学习,下图是基于对抗学习的经典方法[3]:首先在源域上进行监督学习的训练。然后使用源域和目标域的无标签数据训练判别器,对数据进行二分类(是来源于源域还是目标域)。最后通过使用第二步中对目标域数据的特征提取器,即可以实现对于目标域数据的分类任务。
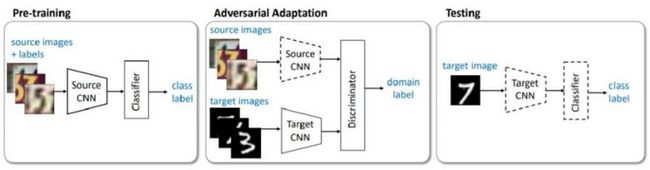
![]()
异常检测概念及分类
运维领域中的 时间 序列异常主要分为点异常(point anomaly)、上下文异常(contextual anomaly)与连续性异常(collective anomaly) 。比如心电图曲线数据,人们突然遇到心仪的男/女神时,产生的心动即点异常,如图(a);心律不齐的病人产生的异常表现是上下文异常,如图(b);死而复生的短暂休克是连续性异常,如图(c)所示。

![]()
基于深度学习的异常检测方法
深度学习是近些年兴起的数据驱动的算法。在大数据时代,各个领域应用场景的数据量巨大且形式复杂,故研究基于深度学习的算法是非常必要的。

- 基于生成模型
生成对抗神经网络( GAN )与 自编码器 ( Autoencoder )是两种典型的生成模型。下图是自编码器在异常检测领域的原理图[4]:先通过最小化重建损失(reconstruction loss)训练自编码器,从正常的数据中学到正常的模式;在测试阶段,当出现异常数据时,模型仍将它视作正常,此时对比输入与输出后得到的重建损失值非常高。于是重建损失值可用于检测数据是否异常。
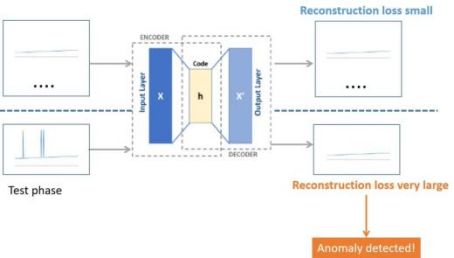
- 基于one class classification
One class classification[5]训练算法学习可包围住正常数据分布的最小超平面/超球面。 下图的神经网络通过非线性变换将原始数据映射到特征空间中,算法在此特征空间中学习上述超平面/超球面;在测试阶段通过计算数据与上述模型的距离来判定该数据是否异常。
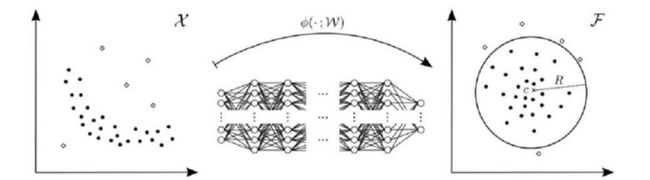
![]()
分布迁移下的深度学习时间序列异常检测方法探究
目前对于分布迁移下深度学习时间序列异常的检测研究较为有限。下图的研究思路中,首先对源域和目标域的数据进行预处理,随后在预处理后的源域数据上进行基于深度学习异常检测算法的训练,取得满意效果后,探究利用迁移学习方法把上述知识迁移到目标域的可行方案。
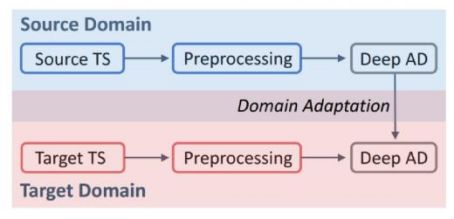
我们在未来研究中拟用如下三种数据集:
- 随机注入异常的人工有标数据,其特点是信噪比和数据量均可控;
- 模拟系统MicroSS产生的无标数据,其特点是模拟真实业务场景,且数据量大;
- 真实运维场景数据,其特点是数据种类丰富且具有重要商业价值。
基于以上描述,我们期待迁移学习研究工作在相关数据集上的探究,可为智能运维中的异常检测及其他场景落地赋能,并最终纾解运维从业人员的工作痛点。
参考文献
[1] K. Ji et al. Hype cycle for the Internet of Things, 2020. Gartner Research, 2020.
[2]H. Shimodaira. Improving predictive inference under covariate shift by weighting the log-likelihood function. Journal of Statistical Planning and Inference, 90(2):227–244, 2000.
[3] E. Tzeng et al. Adversarial discriminative domain adaptation. In CVPR , 2017.
[4]C. Zhou and R. Paffenroth. Anomaly Detection with Robust Deep Autoencoders. InKDD, 2017.
[5]Ruff et al. Deep One-Class Classification. In ICML, 2018.
写在最后
云智慧 AIOps 社区是由云智慧发起,针对运维业务场景,提供算法、算力、数据集整体的服务体系及智能运维业务场景的解决方案交流社区。该社区致力于传播 AIOps 技术,旨在与各行业客户、用户、研究者和开发者们共同解决智能运维行业技术难题,推动 AIOps 技术在企业中落地,建设健康共赢的AIOps 开发者生态。
飞鱼平台(FlyFish)是云智慧公司自主设计、研发的一款低门槛、高拓展性的低代码应用开发平台,为数据可视化开发场景提供了高效的一站式解决方案。飞鱼提供丰富的组件和应用模板库,可通过拖拉拽的形式完成数据可视化开发,零开发背景的用户也可完成数据可视化开发工作。同时,飞鱼也提供了灵活的拓展能力,支持组件开发、自定义函数与全局事件等配置,面向复杂需求场景能够保证高效开发与交付。
可视化编排平台-FlyFish:
Github地址: https://github.com/CloudWise-...
Gitee地址: https://gitee.com/CloudWise/f...

您可以添加小助手(xiaoyuerwie)备注:飞鱼。加入开发者交流群,可与业内大咖进行1V1交流!
也可通过小助手获取云智慧AIOps资讯,了解FlyFish最新进展!
