学习 C 语言看这一篇就够了!吐血整理 C 语言所有知识点
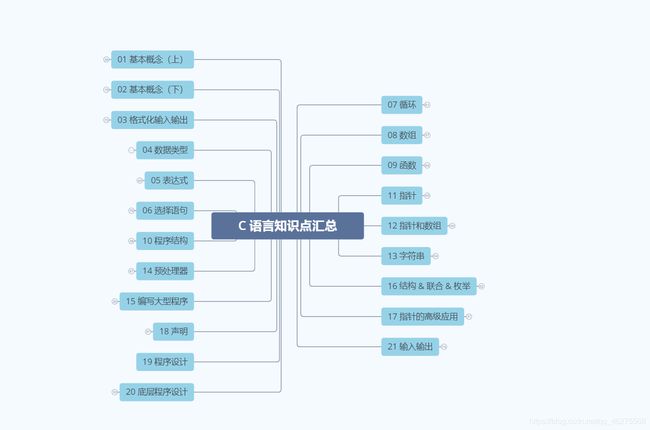
C 语言的知识点汇总
文中的图片上有我公众号的水印,我本来也不想加,因为图片是很早之前做的。本来也可以不用加,但是我感觉加上更有利于读者理解知识点,希望审核大大不要限流。
兄弟们,为了你们,我也是拼了,希望大家能给我点个赞,转发一下,希望更多人能获益。我也算没白码这么多字。
我们以 《C 语言程序设计 —— 现代方法》 这本书的目录为例,给大家列出主要的知识点。大部分知识点的文章都已经整理,后面还会继续更新。
下面是 C 语言 全部知识点 的汇总,6.4 M 的思维导图,太大了就不放在这里了,下载链接在文末。
拿到思维导图的朋友不要忘记回来给我 点个赞 ~花了 一天时间 整理的思维导图,不容易啊。

01概述
推荐阅读:
- C 语言概述
02基本概念
第一个 C 程序
#include将上述程序写在你的编译器里。
然后给文件命名,并以.c作为扩展名,例如main.c。
现在,编译并运行该程序。如果一切正常,输出的应该是:
Hello,World
编译和链接
C程序编译链接的过程:(知道即可)

集成开发环境
集成开发环境(integrated development enviroment,IDE):集成开发环境是一个软件包,我们可以在其中编辑,编译,链接,执行和调试程序。
IDE推荐:
-
CodeBlock
-
VS2019
简单程序的一般形式
1. 指令
**指令(directive):**我们把 预处理器 执行的命令称为 预处理器指令(preprocessor directive),简称指令。
指令的结尾不需要添加分号
#include的作用相当于把 头文件 stdio.h 中的所有内容都输入到该行所在的位置。
include 文件提供了一种方便的途径共享许多程序共有的信息。
stdio.h文件中包含了供编译器使用的输入和输出函数(如 printf())信息。
该文件名的含义为标准输入/输出头文件(stadard input&output .header)
**头文件(header)*在C程序顶部的信息集合。
**每次用到库函数,必须用#include指令包含相关的头文件。**省略必要的头文件可能不会对某一个特定程序造成影响,但是最好不要这样做。
2.函数
int main(void)
函数: 类似于其他编程语言的“过程”或“子例程”,它们是用来构建程序的构建块。
函数分两大类:第一种是程序员自己编写的函数;另一类则是C作为语言实现的一部分提供的函数,即库函数(library function)。因为它们属于一个由编译器提供的函数“库”。
main函数:C程序都是从main()函数“开始”执行。main()函数是程序的唯一入口。可以理解为程序是从main函数开始运行到main函数结尾结束。
返回类型:int是main函数的 返回类型。这表明 main函数返回的值是整型。
参数:()内包含的信息为函数的参数。示例中的void表示该例中没有传入任何参数。
返回值:前面我们讲到了返回类型,那么就应该有个返回值。示例中 return就代表返回,0是这个main函数的返回值。
3.语句
语句是程序运行时执行的命令
语句是带顺序执行的 C 程序段。任何函数体都是一条复合语句,继而为语句或声明的序列
C语言中的六种语句
-
标号语句
-
goto 语句的目标。 (标识符 : 语句)
-
switch 语句的
case标号。(case 常量表达式 : 语句) -
switch 语句的默认标号。 (default : 语句)
-
-
复合语句
复合语句,或称块,是花括号所包围的语句与声明的序列。
{声明(可选)| 语句 } -
表达式语句
典型的 C 程序中大多数语句是表达式语句,例如赋值或函数调用。
无表达式的表达式语句被称作空语句。它通常用于提供空循环体给 for 或 while 循环。
-
选择语句
选择语句根据表达式的值,选择数条语句之一执行。
-
if 语句
-
if 语句带
else子句 -
switch 语句
-
-
迭代语句
迭代语句重复执行一条语句。
-
while 循环
-
do-while 循环
-
for 循环
-
-
跳转语句
跳转语句无条件地转移控制流。
-
break 语句
-
continue 语句
-
return 语句带可选的表达式
-
goto 语句
-
4.打印字符串 printf() 函数
printf("Hello,World\n");
printf()是一个功能十分强大的函数。后面我们会进一步介绍
示例中我们只是用printf函数打印了出了一条字符串字面量(string literal) —— 用一对双引号引起来的一系列字符。
字符串,顾名思义就是一串字符。
printf函数不会自动换行到下一行打印,它只会在它最开始那一行一直打印直到程序迫使它换行。
\n表示printf函数打印完成后跳转到下一行
5.注释
//a simple C program
写注释可以让自己和别人更容易明白你写的程序。
C语言注释的好处是:可以写在任何地方。注释的部分会被编译器忽略。
两种注释符号
第一种:/* */
单行注释
/* 关注微信公众号:不会编程的程序圆 */
/* 看更多干货,获取第一时间更新 */
/* 码字不易,对你有帮助 点赞/转发/关注,鼓励一下作者 */
多行注释
/* 关注微信公众号:不会编程的程序圆
看更多干货,获取第一时间更新
码字不易,对你有帮助 点赞/转发/关注,鼓励一下作者 */
但是,上面这一种注释方式可能难以阅读,因为人不不容易发现注释结束的位置。
改进:
/*关注微信公众号:不会编程的程序圆
看更多干货,获取第一时间更新
码字不易,对你有帮助 点赞/转发/关注,鼓励一下作者
*/
更好的方法:将注释部分围起来
/*************************************************
* 关注微信公众号:不会编程的程序圆 *
* 看更多干货,获取第一时间更新 *
* 码字不易,对你有帮助 点赞/转发/关注,鼓励一下作者 *
*************************************************/
当然如果你嫌麻烦,也可以简化一下:
/*
* 关注微信公众号:不会编程的程序圆
* 看更多干货,获取第一时间更新
* 码字不易,对你有帮助 点赞/转发/关注,鼓励一下作者
*/
简短的注释可以放在同一行
printf("Hello World\n");/* 不会编程的程序圆 */
但是,如果你忘记了终止注释可能会导致你的编译器跳过程序的一部分,请思考下列:
printf("不会"); /* 关注我的公众号呦~
printf("编程");
printf("的"); /* 更多鼓励,更多干货!*/
printf("程序圆");
你可以在自己的编译器上自己敲一下,看看会输出什么。
由于第一条注释忘记输入结束标志,导致编译器将直到找到结束标志之前的程序都当成了注释!
第二种://
C99提供的新的注释方式。
//关注微信公众号:不会编程的程序圆
//看更多干货,获取第一时间更新
//码字不易,对你有帮助 点赞/转发/关注,鼓励一下作者
新的注释风格有两大优点:
- 这种注释会在行末自动终结,所以不用担心会出现未终止的注释意外吞噬部分程序的情况
- 每行前都有 // ,所以多行的注释更加醒目
综上所述,建议采用 // 这种注释方式
1. 类型
每一个变量都有类型(type)。类型用来描述变量的数据的种类,也称数据类型。
数值型变量的类型决定了变量所能存储的最大值与最小值,以及是否允许小数点后出现数字。
示例中只有一种数据类型:int
int(integer):即整型,表示整数。
数据类型还有很多,目前除了 int 以外,我们只再使用另一种:
float(floating-point): 浮点型,可以表示小数
2. 关键字
int 与float 都是C语言的关键字(keyword),关键字是语言定义的单词,不能用做其他用途。比如不能用作命名函数名与变量名。
关键字:斜体代表C99新增关键字
| auto | enum | unsigned | break | extern |
|---|---|---|---|---|
| return | void | case | float | short |
| volatile | char | for | signed | while |
| const | goto | sizeof | continue | if |
| static | default | struct | do | int |
| switch | double | long | typedef | else |
| register | union | |||
| restrict | inline | _Bool | _Complex | _Imaginary |
如果关键字使用不当(关键字作为变量名),编译器会将其视为语法错误。
保留标识符(reserved identifier):下划线开头的标识符和标准库函数名(如:printf())
C语言已经指定了这些标识符的用途或保留了它们的使用权,如果你使用它们作为变量名,即使没有语法错误,也不能随便使用。
3. 声明
声明(declaration):在使用变量(variable)之前,必须对其进行声明(为编译器所作的描述)。
声明的方式为:数据类型 + 变量名(程序员自己决定变量名,命名规则后面会讲)
示例中的 int weight完成了两件事情。第一,函数中有个变量名为 weight。第二,int 表明这个变量是整型。
编译器用这些信息为变量 weight 在内存中分配空间。
C99 前,如果有声明,声明一定要在语句之前。(就像示例那样,函数体中第一块是声明,第二块才是语句。)
C99 和 C11 遵循 C++ 的惯例,可以把声明放在任何位置。即可以使用时再声明变量。以后C程序中这种做法可能会很流行。但是目前不建议这样。
就书写格式而言,我建议将声明全部放在函数体头部,声明与语句之间空出一行。
4. 命名
weight,height 都是标识符,也就是一个变量,函数或其他实体的名称。因此,声明将特定标识符与计算机内存的特定位置联系起来,同时也就确定了存储在某位置的信息类型或数据类型。
命名规则:可以用小写字母,大写字母,数字和下划线(_)来命名。名称的第一个字符必须是字符或下划线,不能是数字
操作系统和C库经常使用一个下划线或两个下划线开始的标识符(如:_kcab),因此最好避免在自己的程序中使用这种名称。(避免与操作系统和c库的标识符重复)
C语言的名称区分大小写。即:star,Star,STAR 是不同的。
5. 赋值
赋值(assignment):变量通过赋值的方式获得值。
示例中,weight = 160;是一个 赋值表达式语句。意思是“把值 160 赋给 变量 weight”。
在执行 int weight;时,编译器在计算机内存中为变量 weight 预留的空间,然后在执行这行代码时,把值存储在之前预留的位置。可以给 weight 赋不同的值,这就是 weight 之所以被称为变量的原因。
注意:
-
该行表达式将值从右侧赋到左侧。
-
该语句以分号结尾。
-
=在计算机中不是相等的意思,而是赋值。我们在读weight = 160;时,我们应该这么读:“将 160 赋给 weight” -
==表示相等
6. printf() 函数
我们发现:首先引号内的 %d 和\n并没有被输出,%d的位置被替换成了一个整数。为什么会这样呢?
\n代表一个换行符(newline character)。对于 printf 函数来说,它的意思是:“在下一行的最左边开始新的一行”。也就是说换行符和在键盘上按下 Enter按键相同。既然如此,为何不在键入 printf() 参数时直接使用 Enter键呢?因为编辑器可能认为这是直接的命令,而不是存储在源代码中的指令。换句话说,如果直接按下 Enter键,编辑器会退出当前行并开始新的一行。但是,换行符会影响程序输出的(显示)格式。
换行符是一个转义序列(escape sequence)。转义序列用于难以表示或无法输入的字符。如,\t代表 Tab键,即制表符。\b代表 Backspace键,即退格键。我们在后面会继续讨论。
%d是一个占位符,其作用是指明 num 值的位置。d 代表 以十进制的格式。
7. 初始化
当程序开始执行时,某些变量会被自动设置为0,而大多数不会。没有默认值并且尚未在程序中被赋值的变量时未初始化的(uninitialized)。
如果试图访问未初始化的变量,可能会得到不可预知的值。在某些编译器中,可能会发生更坏的情况(甚至程序崩溃)。
我们可以用赋值的办法给变量赋初值,但还有更简洁的做法:在变量声明中加入初始值。
例如示例中的 int height = 180数值 180 就是一个初始化式(initializer)。
同一个声明中可以对任意数量的变量进行初始化。如:
int a = 10, b = 15, c = 20;
上述每个变量都拥有属于自己的初始化式。接下来的例子,只有 c 有初始化式,a,b没有。
int a, b, c = 20;
推荐阅读:
- 基本概念(上)
- 基本概念(下)
03格式化输入输出
printf 函数
printf()函数打印数据的指令要与待打印数据的类型相匹配。例如,打印整数时使用 %d,打印字符时使用 %c 。这些符号被称为转换说明(conversion specification),它们指定了如何把数据(以2进制形式)转换成可显示的形式。
例如:
printf("I am %d years old", 18);
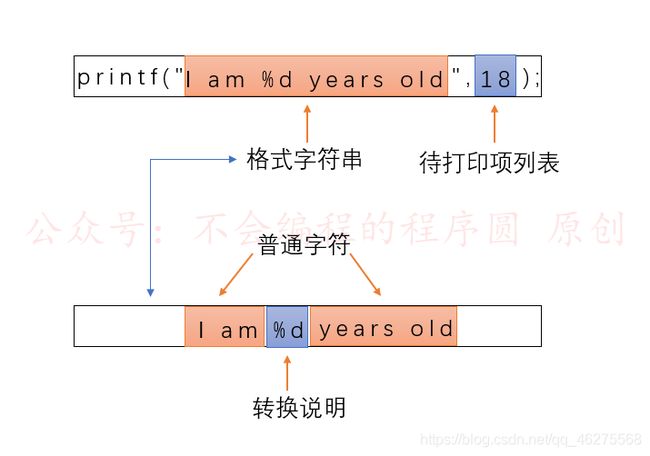
这是 printf()的格式:
printf(格式字符串,待打印项1,待打印项2,...);
待打印项都是要打印的的项。它们可以是变量,常量,甚至是在打印之前计算的表达式。上例中,只有一个待打印项: 18 。
格式字符串包含两种不同信息:
- 普通字符:以字符串中出现的形式打印出来。上例中,“I am” 与 " years old" 为普通字符
- 转换说明:用待打印项的值来替换。上例中,"%d" 为转换说明
printf 转换说明
转换说明这部分我做了很久,比较详细,配合下一章数据类型才能看懂大部分,剩下的就需要你在不断使用的过程中领悟了。

-
标志(可选,允许出现多于一个)
- 字段内左对齐(默认右对齐) + 在打印的数前加上 + 或 - (通常只有负数前面附上减号)例1 空格 在打印的非负数前前面加空格( + 标志优先于空格标志)例2 # 对象:八进制数,十六进制数,以g/G 转换输出的数 例3 0 用前导 0 在字段宽度内对输出进行填充。如果转换格式为d,i,o,u,x(X),而且指定了精度,可以忽略 0 例4 例 1:
printf("%d\n", 123); printf("%d\n", -123); printf("%+d\n", 123); printf("%+d\n", -123);123 -123 +123 -123例 2:
printf("% d\n", 123); printf("% d\n", -123); printf("% +d\n", 123);123 -123 +123例 3:
printf("%o\n", 0123); printf("%x\n", 0x123); printf("%#o\n", 0123); printf("%#x\n", 0x123); printf("%#g\n", 123.0); printf("%g\n", 123.0);123 123 0123 0x123 123.000 123例 4:
printf("%5d\n", 123); printf("%05d\n", 123); printf("%5.3d\n", 123);123 00123 123 -
最小字段宽度(可选)
如果数据项太小无法达到这个宽度,那么会对字段进行填充。(默认情况下会在数据项左侧添加空格,从而使字段宽度内右对齐)。
如果数据项过大以至于超过了这个宽度,那么会完整的显示数据项。
字段宽度可以是整数也可以是字符
*。如果是字符 * ,那么字段宽度由下一个参数决定。如果这个参数为负,它会被视为前面带 - 标志的正数。例5例 5:
printf("%5d\n", 123); printf("%2d\n", 123); printf("%*d\n", 5, 123); printf("%*d\n", -5, 123);123 123 123 123 -
精度(可选项)
如果转换说明是:
d,i,o,u,x,X, 那么精度表示最少位数(如果位数不够,则添加前导 0 )
a,A,e,E,f,F ,那么精度表示小数点后的位数
g,G,那么精度表示有效数字个数
s,那么精度表示最大字节数
精度是由小数点(.)后跟一个整数或 * 字符构成的。如果是 * ,那么精度由下一个参数决定(如果这个参数为负,效果与不指定精度一样。)如果只有小数点,那么精度为0 。例 6
例 6:
printf("%.4d\n", 123); printf("\n"); printf("%f\n", 123.0); printf("%.1f\n", 123.0); printf("\n"); printf("%g\n", 123.0); printf("%.5g\n", 123.0); printf("\n"); printf("%s\n", "Hello"); printf("%.2s\n", "Hello"); printf("\n"); printf("%.*d\n", 4, 123); printf("%.*d\n", -4, 123);0123 123.000000 123.0 123 123 Hello He 0123 123 -
长度修饰符(可选)。
长度修饰符表明待显示的数据项的长度大于或小于特定转换说明中的正常值。例7
长度修饰符 转换说明符 含义 hh (C99) d,i,o,u,x,X signed char, unsigned char h d,i,o,u,x,X short, unsigned short l d,i,o,u,x,X long, unsigned long ll (C99) d,i,o,u,x,X long long, unsigned long long L a,A,e,E,f,F,g,G long double z (C99) d,i,o,u,x,X size_t j (C99) d,i,o,u,x,X ptrdiff_t 例 7:
printf("%#hhX\n", 0xAABBCCDDEEFF1122);//这是一个占用内存为 8 个字节的十六进制数 printf("%#hX\n", 0xAABBCCDDEEFF1122); printf("%#X\n", 0xAABBCCDDEEFF1122); printf("%#lX\n", 0xAABBCCDDEEFF1122); printf("%#llX\n", 0xAABBCCDDEEFF1122);0X22 0X1122 0XEEFF1122 0XEEFF1122 0XAABBCCDDEEFF1122 -
转换说明符
由于参数提升(▶️),在实参传递给可变数量实参函数时,float 会转换为 double ,char 会转换为 int。例8
转换说明符 含义 d,i 把 int 类型转换为 十进制形式 o,u,x,X 把无符号整型转换为八进制(o),十进制(u),十六进制形式(x,X)。 f,F (F C99) 把 double 类型转换为 十进制形式,并把小数点放置在正确位置上。如果没有指定精度,那么小数点后显示6个数字。 e,E 把 double 类型转换为 科学计数法形式。如果没有指定精度,那么小数点后显示6个数字。 g,G 把double 类型转换为 f 形式或 e 形式。当数值的指数部分小于 -4,或大于等于精度时,会选择以 e 的形式显示。尾部的 0 不显示(除非用#标志),且小数点后跟有数字才会显示出来。 a,A (C99) 把 double 类型转换为十六进制科学计数法(p计数法)。 c 显示无符号字符的 int 类型值。 s 写出由实参指向的字符串。 p 把 void* 类型转换为可打印的形式。 n 相应的实参必须是指向 int 型对象的指针。在该对象中存储 …printf 函数已经输出的字符数量,不产生输出。 % 写字符 % 例 8:
printf("%i\n", 123); printf("%d\n", 123); printf("%o\n", 123); printf("%u\n", 123); printf("%x\n", 123); printf("%X\n", 123); printf("%f\n", 123.0); printf("%e\n", 123.0); printf("%g\n", 123.0); printf("%a\n", 123); printf("%c\n", 65); printf("%s\n", "123"); int* a = 2; printf("%p\n", a); printf("%%\n");输出:为了方便大家观看我已经将输出中的换行删除了
123 123 173 123 7b 7B 123.000000 1.230000e+02 123 0x1.e13430000007bp-1021 A 123 00000002 %printf() 返回值
返回值:传输到输出流(显示器)的字符数,若出现输出错误或编码错误(对于字符串和字符转换指定符)则为负值。
返回类型:
int使用场景:检查输出错误。(看输出的字符数是否正确)
#include输出:
Hello!
7
打印较长字符串
允许的换行方式:
printf("Hello %s\n",
XiaoHuang);//为了让读者知道该行未完,可以使用缩进
错误的换行方式:
printf("Hello
%s\n", XiaoHuang);
如果想在双引号括起来的格式字符串中换行,应该这样写:
-
printf("Hello"); printf (" %s\n", XiaoHuang); -
printf("Hello\ %s\n", XiaoHuang); -
printf("Hello" " %s\n", XiaoHuang);// ANSI C
方法1:使用多个 printf 语句
方法2:在要换行的地方加上反斜杠( \ )来断行。但是,下一行的代码必须从该行最左端开始,不然输出会包含你所缩进的空白字符。
方法3:ANSI C 引入的字符串连接。C 编译器会将多个字符串看作一个字符串。
scanf() 函数
我们从键盘输入的都是文本,因为键盘只能生成文本字符:字符,数字和标点符号。如果要输入整数 2014,就要键入2,0,1,4.如果要将其存储为数值而不是字符串,程序就必须要把字符依次转换成数值,这就是 scanf() 要做的。
scanf() 把输入的字符串转换成整数,浮点数,字符和字符串,而 printf() 正好与之相反,把整数,浮点数,字符,字符串转换成显示在屏幕上的文本。
scanf() 与 printf() 类似,也要使用 格式字符串 和 参数列表。scanf() 中的格式字符串表明字符输入流的目标数据类型。两个函数的主要区别在于参数列表中。printf() 函数使用变量,常量和表达式,而 scanf() 函数使用指向变量的指针(▶️)。这里不需要了解指针,只需要记住一下简单的两条:
用 scanf 读取
- 基本变量类型的值,在变量名前加上一个
& - 把字符串读入数组中,不要使用
&
下面的程序演示了这两条规则:
input.c —— 何时使用 &
#include⚠️
初学者在使用 scanf 时,在应该写 & 的时候容易忽略 & ,所以每次使用 scanf 的时候一定要格外小心。通常情况下,必要的地方缺少 & 会让程序崩溃(编译器没有警告),但是也有时候程序并不会崩溃,这时候找 bug 可能会让你头痛。
scanf 的 长度修饰符 和 转换说明符 与 printf 几乎相同。主要的区别如下:
-
长度修饰符 :(可选项)对于 float 与 double 类型,printf() 的转换说明都用
f; 而对于 scanf() ,float 保持不变,double 要在 f 前加长度修饰符 l ,即:lf。例 1例 1:
#includeint main(void) { double a = 3.0; scanf("%lf", &a); printf("%lf", a); return 0; } -
转换说明符 :
%[集合]匹配集合中的任意序列;%[^集合]匹配非集合中的任意序列。例 2例 2:
#includeint main(void) { char str[10];//字符串数组 scanf("%[123]", str); printf("%s", str); return 0; } //输入:123456abc123 //输出:123 int main(void) { char str[10];//字符串数组 scanf("%[^123]", str); printf("%s", str); return 0; } //输入:abc4123a //输出:abc4 -
字符
*:(可选项)字符 * 出现意味着赋值屏蔽(assignment suppression): 读入此数据项,但是不会将其赋值给对象。用 * 匹配的数据项不包含在 …scanf 函数返回的计数中。例 3例 3:
#includeint main(void) { int a = 0; scanf("%*d%d", &a); printf("%d", a); return 0; } 输入:1 2 输出:2 -
最大字段宽度:(可选项)最大字段宽度限制了输入项中的字符数量。如果达到最大值,那么次数据项的转换结束。转换开始跳过的空白不计。例 4
//输入:1234 Hello //先猜测一下输出 #includeint main(void) { int a = 0; char str[10]; scanf("%2d%3s", &a, str); printf("%d %s", a, str); return 0; } //输出:12 34
推荐阅读:
- 格式化输入/输出
04数据类型
关键字
C语言的数据类型关键字
| 最初 K&R 给出的关键字 | C90标准添加的关键字 | C99标准添加的关键字 |
|---|---|---|
| int | signed | _Bool (布尔型) |
| short | void | _Complex(复数) |
| long | _Imaginary(虚数) | |
| unsigned | ||
| char | ||
| float | ||
| double |
通过这些关键字创建的类型,按计算机的存储方式可分为两大基本类型:整数类型 和 浮点数类型
位,字节和字
位,字节和字
位(bit): 最小的存储单元,也称比特位。可以存储 0 或 1(或者说,位用于存储“开”或“关”)
字节(byte): 1 byte = 8 bit 既然 1 位可以表示 0 或 1,那么 1 字节就有 256 (2^8)种 0/1 组合,通过二进制编码(仅用 0/1 便表示数字),便可表示 0 ~ 255 的整数或一组字符。(以后会详细讲解)
字(word): 是设计计算机时给定的自然存储单位。对于 8 位 的微型计算机(如:最初的苹果机),1 字长 只有 8 位,从那以后,个人计算机的字长增至 16 位,32位,直至目前的 64位。计算机字长越大,其数据转移越快,允许访问的内存越多。
整数
整数 7 以二进制形式表示是:111 ,用一个字节存储可表示为:

浮点数
浮点数相比我们都不陌生,本节后面还会做更详细的介绍。现在我们介绍一种浮点数的表示方法:e记数法。
如 3.16E+007 表示 3.16 * 10^7(3.16乘以10的七次方)。007 表示 10^7;+ 表示 10 的指数 7 为正数。
其中,E 可以写成 e;表示正次数时,+ 号可以省略;007也可以省略为7。即:3.16e7。
浮点数和整数的存储方案是不同的。计算机将浮点数分成小数部分和指数部分来表示,而且分开存储这两部分。因此,虽然 7.0 和 7 在数值上相同,但它们的存储方式不同。下图演示了一个存储浮点数的例子。后面我们会做更详细的解释

整数与浮点数的区别:
- 整数没有小数部分,浮点数有小数部分
- 浮点数可以表示的范围比整数大
- 对于一些算术运算(如,两个很大的数相减),浮点数损失的精度更多
- 因为在任何区间内都存在无穷多个实数,所以计算机的浮点数不能表示区间内的所有值。浮点数通常只是实际值的近似值。(例如,7.0 可能被存储为浮点值 6.99999)
- 过去,浮点数运算比整数运算慢。不过现在许多CPU都包含了浮点数处理器,缩小了速度上的差距。
整数类型
有符号整数和无符号整数
有符号整数如果为零或正数,那么最左边的位(符号位,只表示符号,不表示数值)为 0 ;如果为负数,则符号位为 1。如:最大的 16 位整数(2个字节)的二进制表示形式是 01111111 11111111,对应的数值是 32767(即:2^15 - 1)
无符号整数 不带符号位(最左边的位是数值的一部分)。因此,最大的 16 位整数的二进制表示形式是:11111111 11111111(即:2^16 - 1)
默认情况下,C语言中的整型变量都是有符号的,也就是说最左位保留符号位。若要告诉编译器变量没有符号位,需要把他声明成 unsigned 类型。
整数的类型
short int
unsigned short int
int
unsigned int
long int
unsigned long int
32位机器整数类型
| 类型 | 最小值 | 最大值 |
|---|---|---|
| short | -32768( - 2^15 ) | 32767(2^15 -1 ) |
| unsigned short | 0 | 65535 (2^16 - 1) |
| int | - 2147483648(- 2^31) | 2147483647(2^31 - 1) |
| unsigned int | 0 | 4294967295 |
| long | - 2147483648 | 2147483647 |
| unsigned long | 0 | 4294967295 |
读/写整数
读写无符号整数:
unsigned int a;
-
十进制:
scanf("%u", &a);printf("%u", a); -
八进制
scanf("%o", &a);printf("%o", a); -
十六进制
scanf("%x", &a);printf("%x", a);
读写**短整型*数:在 d,u,o,x 前加上 h
short b
-
scanf("%hd", &b);printf("%hd", b);
读写长整数:在 d,u,o,x 前加上 l
long c
-
scanf("%ld", &c);printf("%ld", c);
读写长长整数: 在 d,u,o,x 前加上 ll
long long int d
-
scanf("%lld", &d);printf("%lld", d);
浮点类型
C语言提供了三种浮点类型,对应着不同的浮点格式:
float:单精度浮点数double:双精度浮点数long double:扩展精度浮点数
通常我们用到的是 double
读/写浮点数
-
float:
%e%f%g -
double:
%lf-
scanf("%lf", &varible); -
printf("%f", varible);lf格式串 只能在 scanf 中使用;在用 printf 输出 double 时,格式串可以使用e,f,g
-
-
long double:
%Lfscanf("%Lf", &varible);printf("%Lf", varible);
字符类型
字符类型(字符型):char 。
char 类型的值可以根据计算机的不同而不同,因为不同的计算机可能会有不同的字符集。
字符集:当今最常用的字符集是 ASCII (美国信息交换标准码)字符集。
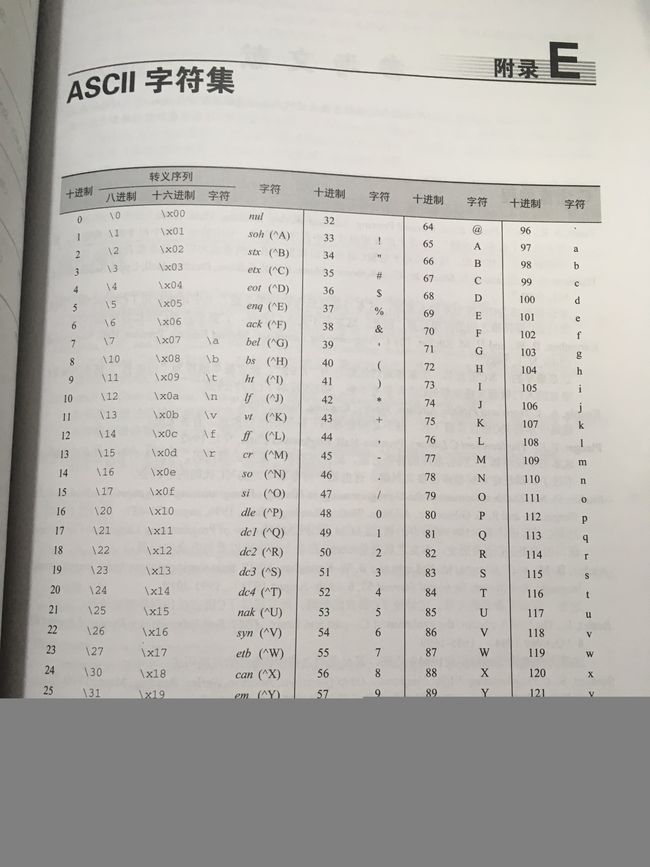
有符号字符 和 无符号字符
有符号字符signed char:取值范围:-128 ~ 127
无符号字符unsigned char: 取值范围:0 ~ 255
可移植性技巧:不要假设 char 类型默认为 signed 或 unsigned 。如果有区别,用 signed char 和 unsigned char 代替 char 。
算数类型
整数类型 和 浮点类型 统称为 算数类型。以下为 C89 中对算数类型的分类
- 整数类型
- 字符类型(char)
- 有符号整型(signed char, short int, int, long)
- 无符号整型(unsigned char, unsigned short int, unsigned int, unsigned long int)
- 枚举类型
- 浮点类型(float,double,long double)
转义序列
正如前面我们所看到的那样,字符常量通常是用单引号扩起来的单个字符。然而,一些特殊符号(如换行符)是无法采用上述方法书写的,因此它们不可见(非打印字符),或者无法从键盘输入。因此,为了使程序可以处理字符集中的每一个字符,C语言提供了一种特殊的表示法——转义序列(escape sequence)。
转义序列有两种:字符转义序列(character escape)和 数字转义序列(numeric escape)。
字符转义序列(粗体比较常用,需要注意)
| 名称 | 转义序列 | 名称 | 转义序列 |
|---|---|---|---|
| 换行符 | \n | 回退符 | \b |
| 水平制表符 | \t | 垂直制表符 | \v |
| 单引号 | \’ | 换页符 | \f |
| 双引号 | \" | 问号 | ? |
| 回车符 | \r | 报警(响铃)符 | \a |
| 反斜杠 | \\ |
类型定义
类型定义(type definition)
#include
typedef int int32;
int main(void) {
int32 a;
scanf("%d", &a);
printf("%d", a);
return 0;
}
编译器会把 int32 类型看作 int 类型,因此 a 就是一个普通的 int 型变量。
类型定义的优点
类型定义使得程序更容易理解(选择有意义的类型名)。例如,假设 cash_in 和 cash_out 用于存储美元数量。
typedef float Dollars
随后可以这样定义 cash_in 和 cash_out:
Dollars cash_in,cash_out;
上面的写法比这样写更有意义:
float cash_in,cash_out;
类型定义还可以使程序更容易修改 如果稍后觉得 Dollars 实际应该该外 double 类型的,
typedef double Dollars
如果没有定义Dollars ,则需要找到所有用 float 定义美金数量的地方,这显然不是一件容易的工作(对大型程序而言)。
类型定义的可移植性
类型定义时编写可移植性程序的重要工具。程序从一台计算机移动到另一台计算机可能引发的问题就是不同计算机上的类型取值范围可能不同。例如,如果 int i = 100000 这在 32 位机器上是没有问题的,但是在 16位机器上就会出错。
这时,在 32 位机器上我们可以这样定义:
typedef int Quantity;
Quantity a;
把程序转到 16 位机器上:
typedef long Quantity;
当然只这么做是不够的,Quantity 定义的变化可能影响类型变量的使用方式。至少我们需要改变 printf 和 scanf 中的格式串(%d 改为 %ld)。
sizeof 运算符
表达式(而非函数)sizeof(类型)的值是一个无符号整型,表示存储属于 类型名 的值所需要的字节数
在自己的计算机上敲一下下面的代码,看看你的机器上每个数据类型 sizeof 求出来的值,顺便复习一下本节的数剧类型
#include为什么要用 %u 这个格式呢?因为在我的机器上 sizeof 的值是 unsigned int 类型,每个机器可能不一样。
通常情况下,sizeof运算符也可以用于常量,变量,和表达式。
#include//输出
sizeof(1.) = 8 byte
sizeof(1) = 4 byte
sizeof(a) = 2 byte
sizeof(a + b) = 4 byte
sizeof(b + c) = 4 byte
与 sizeof(类型)不同的是, sizeof应用于表达式时可以省略括号。例如,可以用 sizeof i代替 sizeof(i) ;但是由于运算符优先级的问题,圆括号有时候还是需要的。编译器会将 sizeof i + j解释为 sizeof(i) + j。这是因为 sizeof 作为一元运算符 的优先级高于 二元运算符 + 。为了避免出现这种问题,建议还是保留圆括号。
推荐阅读:
- 数据类型
05表达式
一 算术运算符
1.概念
| 一元运算符(只需要 1 个操作数) |
|---|
| + 一元正号运算符 |
| - 一元负号运算符 |
二元运算符
| 加法类 | 乘法类 |
|---|---|
| + 加法运算符 | * 乘法运算符 |
| - 减法运算符 | / 除法运算符 |
| % 求余运算符 |
2. 运算符的优先级和结合性
当表达式包含多个运算符时,其含义可能不是一目了然的。我们的解决方法是:
- 用括号进行分组
- 了解运算符的优先级和结合性
运算符优先级
(operator precedence)
| 最高优先级 | + | - | (一元运算符) |
|---|---|---|---|
| * | / | % | |
| 最低优先级 | + | - | (二元运算符) |
二 赋值运算符
求出表达式的值后往往需要将其存储在变量中,以便将来使用。C语言的 = (简单赋值 simple assignment)运算符可以用于此目的。为了更新已经存储在变量中的值,C语言还提供了一种复合赋值(compound assignment)。
1. 简单赋值
表达式 v = e的赋值效果是求出表达式 e 的值,然后将此值赋值给 v。
例 2-1:
i = 5;// i is now 5
j = i;// j is now 5
k = 10 * i + j;// k is now 55
如果 v 与 e 的类型不同,那么赋值运算发生时会将 e 的值转化为 v 的类型:
例 2-2:
int i;
double j;
i = 72.99f;// i is now 72
f = 136;// f is now 136.0
在很多编程语言中,赋值是语句;然而在 C语言中,赋值就像 + 那样是运算符。
既然赋值是运算符,那么多个赋值语句可以串联在一起:
例 2-3:
i = j = k = m = 0;
运算符 = 是右结合的,所以,上面的语句等价于:
i = (j = (k = (m = 0)));
作用是先将 0 赋值给 m,再将 m 赋值给 k,再将 k 赋值给 j,再将 j 赋值给 i 。
! 注意
因为赋值运算符存在类型转换(本节后面会讲),串在一起赋值运算的结果可能不是预期的结果:
int i;
float j;
j = i = 33.3f;
//先将 33 赋值给 i,然后将 33.0 赋值给 j
2. 左值
赋值运算要求它的左操作数必须是左值(lvalue)。左值表示在计算机中的存储对象,而不是常量或计算的结果。左值是变量。
例 2-4:
12 = i;
i + j = 0;
-i = j;
以上三种表达式都是错误的。
3. 复合赋值
i = i + 2;
//等同于
i += 2;
上面的例子中 += 就是一种符合运算符,表示:将自身表示的数增加 2 后再赋值给自己。
与加法相似,所有赋值运算符的工作原理大体相同。
+=
-=
*=
/=
%=
4. 自增运算符和自减运算符
++
--
“自增”(加1)和“自减”(减1)也可以通过下面的方式完成:
i = i + 1;
j = j - 1;
复合赋值运算符可以简化上面的语句:
i += 1;
j -= 1;
而 C语言 允许用 ++ 和 – 运算符将这些语句缩的更短。比如:
i++;
j--;
或者:
++i;
--j;
这两种形式的写法的意义不同的:
-
++i(前缀(prefix)自增),意味着“立即自增 i ”int i = 1; printf("%d\n", ++i); printf("%d\n", i); //输出 2 2 -
i++(后缀(postfix)自增),意味着“先使用 i 的原始值,稍后再自增”。稍后是多久?C语言标准没有给出精确的时间,但是可以放心的假设 i 再下一条语句执行之前进行自增。int i = 1; printf("%d\n", i++); printf("%d\n", i); //输出 1 2
--运算符具有相同的特性。
后缀的 ++ 和 – 比一元的正号,负号优先级高,而且都是左结合的。
前缀的 ++ 和 – 与一元的正号,负号优先级相同,并且是右结合的。
比如:
int main(void) {
int i = 1;
printf("%d", -i++);
printf("%d", i);
}
//输出:
-1
2
5.表达式求值
部分C语言运算符表
| 优先级 | 类型名称 | 符号 | 结合性 |
|---|---|---|---|
| 1 | (后缀)自增 | ++ | 左结合 |
| (后缀)自减 | – | ||
| 2 | (前缀)自增 | ++ | 右结合 |
| (前缀)自减 | – | ||
| 一元正号 | + | ||
| 一元符号 | - | ||
| 3 | 乘法类 | * / % |
左结合 |
| 4 | 加法类 | + - |
左结合 |
| 5 | 赋值 | = *= /= -= += |
右结合 |
能理解下面这个表达式的意义,就算掌握了这一部分的表达式求值规则:
a = b += c++ - d + --e / -f
等价于:
a = ( b += ( (c++) - d + (--e) / (-f) ) )
06选择语句
一 逻辑表达式
包括 if 语句在内的某些 C 语句(while,for 等)都必须测试表达式的值是“真”还是“假”。
许多编程语言中,类似 i < j 这样的表达式都具有特殊的“布尔”类型或者“逻辑”类型(C++ 的 bool 和 Java 的 boolean)。这样的类型只有两个值,即真(true)和假(false)。
而在 C 语言中,诸如 i < j 这样的比较会产生整数:0(假)1(真)。
但是,非 0 的其他数也可以表示 真。在今天看来,这是 C 语言设计的弊端,它将布尔类型与整型混为一谈,让我们在变成过程中可能稍不小心就会给自己挖一个坑。
1. 关系运算符
C 语言的关系运算符(relational operator)和数学上的
>,<,≤,≥相对应,只是用在 C 语言的表达式中时产生的结果是 0 或 1 。例如,表达式 10 < 11 的值是 1,11 < 10 的值是 0 。
关系运算符也可以用于比较整数和浮点数,也允许比较不同类型的操作数。如:5.6 < 5 的值为 0 。
| 符号 | 含义 |
|---|---|
| < | 小于 |
| > | 大于 |
| <= | 小于等于 |
| >= | 大于等于 |
关系运算符的优先级低于算数运算符。例如:i + j < k - 1 的意思是 (i + j) < (k - 1)
关系运算符都是左结合的。
2. 判等运算符
**判等运算符(equality operator):**相等用
==表示 。注意不是=,=表示赋值。
注意:
一定要注意不要将 == 写成 = ,编译器可能会给你报错,但是如果没有,在你查错的时候,注意是不是 == 写错了的问题。
| 符号 | 含义 |
|---|---|
| == | 等于 |
| != | 不等于 |
和关系运算符一样,判等运算符是左结合的,也是产生 0(假) 或 1(真) 作为结果。
3. 逻辑运算符
逻辑运算符(logical operator)
| 符号 | 含义 |
|---|---|
| ! | 逻辑非(一元运算符) |
| && | 逻辑与(二元运算符) |
| || | 逻辑或(二元运算符) |
“短路”计算
&& 和 || 运算符都遵循“短路”原则。也就是说,这些运算符首先计算出左操作数的值,然后计算右操作数;如果表达式的值可以仅由左操作数推导出来,那么将不计算右操作数的值。如:
int i = 0, j = 1;
if (i && i++) {
; // 空语句
}
printf("%d\n", i); // i 的值没有增加,说明 i++ 没有计算
if (j || j++) {
;
}
printf("%d\n", j); // j 的值没有增加, 说明 j++ 没有计算
// 输出:
0
1
运算符 !的优先级和一元正负号优先级相同,运算符 && 和 || 的优先级低于判等运算符。
例如:i < j && k == m 等价于 (i < j) && (k == m)
运算符 ! 是右结合的,&& 和 || 是左结合的。
二 if 语句
1. if
if 语句允许程序通过测试表达式的值从两种选项中选择一种。if 语句的简单格式如下:
if(表达式){
语句
}
如果语句部分只有一条语句,也可以写成
if(表达式)
语句;
执行 if 语句时,先计算圆括号内表达式的值。如果表达式的值非零(C语言将非零值解释为真值),那么接着执行大括号内的语句。例如:
if(i > 0)
printf("正数\n");
为了判定 k < i < j,可以这样写:
if(i > k && i < j)
为了判定相反的情况,可以写成:
if(i <= k || i >= j)
例2-1: 程序:为了判定一个数是不是大于零的,如果是,我们就输出提示语,然后让这个数加 1
if(i > 0){
printf("是正数\n");
i++;
}
2. else 子句
if(表达式)
语句;
else
语句;
如果是复合语句(compound statement),需要加上花括号
加上花括号是一种好习惯。建议不管是不是复合语句,尽量都加上花括号。
例2-2:增加需求:如果这个数不是正数,那么输出提示语,然后让这个数减 1
if(i > 0){
printf("是正数\n");
i++;
}else{
printf("不是正数\n");
i--;
}
3. 嵌套的 if 语句
例2-3:找出 i,j,k 中的最大值,并将其保存到 max 中
if(i > j){
if(i > k){
max = i;
}else{
max = k;
}
}else{
if(j > k){
max = j;
}else{
max = k;
}
}
4. 级联式 if 语句
编程时常常需要判定一系列的条件,一旦其中某个条件为真就立刻停止。
如何做到呢?
例2-4 程序:判断 n 是大于 0 还是 等于 0 还是小于 0
使用 if else
if(n < 0){
printf("n < 0");
}else{
if(n == 0){
printf("n = 0");
}
else{
printf("n > 0");
}
}
使用 else if
if(n < 0){
printf("n < 0");
}
else if(n == 0){
printf("n == 0");
}
else{
printf("n > 0");
}
这样写可以避免 if else 嵌套,从而提高了书写和理解的难易度。
级联式 if 语句书写形式:
if(表达式){
语句;
}
else(表达式){
语句;
}
else{
语句;
}
5. “悬空 else”问题
请看下面的程序,思考 else 与 那个 if 匹配
if(y != 0)
if(x != 0)
printf("%.2f", x / y);
else
printf("Error: y is zero!");
如果此时 y = 0, x = 2 会输出什么?
如果 y = 2, x = 0 会输出什么?
虽然缩进格式按时 else 属于外层 if,但是 C 语言遵循的规则是else 子句应该属于离它最近且还未和其他 else 匹配的 if 语句。
所以,此例中 else 属于内层的 if 语句。为了避免这种问题,最好的办法就是加括号。
if(y != 0){
if(x != 0)
printf("%.2f", x / y);
}
else
printf("Error: y is zero!");
6. 条件表达式
条件运算符(conditional operator): C 语言运算符中唯一一个三元(ternary)(三个操作数)运算符。
格式:
[条件表达式]表达式 1 ? 表达式2 :表达式3 ;
例2-6
if(x > 0){
x++;
}
else{
x--;
}
上面的程序我们用条件运算符可以这么写:
x > 0 ? x++ : x--;
三 switch 语句
日常的编程中,常常需要把表达式和一系列值进行比较,从而找出当前匹配的值。
使用级联式 if 语句可以达到这个目的:
if(grade == 4)
printf("Excellent");
else if(grade == 3)
printf("Good");
else if(grade == 2)
printf("Average");
else if(grade == 1)
printf("Poor");
else if(grade == 0)
printf("Failing");
else
printf("Illegal grade");
C 语言提供了 switch 语句作为这类级联式 if 语句的替换。使用 switch 语句改写上面的程序:
switch(grade){
case 4: printf("Excellent");
break;
case 3: printf("Good");
break;
case 2: printf("Average");
break;
case 1: printf("Poor");
break;
case 0: printf("Failing");
break;
default:printf("Illegal grade");
break;
}
switch 语句常用格式:
switch(控制表达式){
case 常量表达式 : 语句
...
case 常量表达式 : 语句
default : 语句
}
-
控制表达式: 控制表达式只能用:整型,字符型的变量(C 语言把字符当成整数来处理),不能用浮点数 和 字符串。
-
分支标号: 每一个分支的开头都有一个标号,格式如下:
case 常量表达式;常量表达式(constant expression): 必须是整数或字符型,不能包含变量和函数调用。
5 是常量表达式,5 + 10 也是常量表达式;但是 10 + n 不是常量表达式(除非 n 是表示常量的宏)。
-
**语句:**每个分支标号后可以跟任意数量的语句。不需要用花括号把这些语句括起来。每组语句的最后一条通常是 break 语句。
-
break 的作用: 本节后面会详细讨论。
-
default 语句的作用: 控制表达式的值和所有的标号语句都不匹配的话,会执行 default 后面的语句。(default :默认的意思)
C 语言不允许有重复的分支标号,但对分支的顺序没有要求,特别是 default 分支不一定要放在最后。
case 后只可以跟随一个常量表达式。但是,多个分支标号可以放置在同一组语句前面 。如:
switch(grade){
case 4:
case 3:
case 2:
case 1: printf("Passing");
break;
case 0: printf("Failing");
break;
default:printf("Illegal grade");
break;
}
为了节省空间,可以将拥有相同语句的分支标号放在同一行:
switch(grade){
case 4: case 3: case 2: case 1:
printf("Passing");
break;
case 0: printf("Failing");
break;
default:printf("Illegal grade");
break;
}
switch 语句不要求一定有 default 分支。如果 default 不存在,而且控制表达式的值和所有的标号语句都不匹配的话,控制会直接传给 switch 语句后面的语句。
break 语句的作用
break 会使程序“跳出” switch 语句,继续执行 switch 后面的语句。
思考下面的 switch 语句:
switch(grade){
case 4: printf("Excellent");
case 3: printf("Good");
case 2: printf("Average");
case 1: printf("Poor");
case 0: printf("Failing");
default:printf("Illegal grade");
}
如果 grade 的值为 3,那么显示的信息是:
GoodAveragePoorFailingIllegal grade
07循环
一 while 语句
1. while 的基本用法
while 的基本格式如下:
while(控制表达式){
循环体
}
执行 while 语句时,首先计算控制表达式的值。如果值不为零,那么执行循环体,接着再次判定 控制表达式的真值,如果为真,再次执行循环体。直到控制表达式的真值为假,才会结束 while 语句。
例1-1: 倒计数程序
int i = 10;
while(i > 0){
printf("%d\n", i);
i--;
}
关于这个例子,我们可以对 while 进行深度思考:
-
while 循环终止时,控制表达式的值一定为假。
int i = 10; while(i > 0){ printf("%d\n", i); i--; } printf("%d", i); // i is now 0 -
可能根本不执行 while 循环体。
int i = 0; while(i > 0){ printf("%d\n", i); i--; } // Nothing is printed. -
while 语句常有多种写法
int i = 10; while(i > 0){ printf("%d\n", i--); // 将 i-- 写在 printf 内,简化循环 }
2. 无限循环
如果控制表达式的值始终非零,while 循环将无法终止。
while(1){
printf("Hello World\n");
}
除非循环体内有控制循环的语句(break,return,goto)或者调用了导致程序终止的函数,非则上面的循环永远不会结束。
二 do 语句
1. do while 基本用法
do 语句 和 while 语句其实本质上是相同的。只不过 do 语句至少会执行一次循环体。
基本形式:
do{
循环体
}while(控制表达式);
例2-1倒计数程序
int i = 10;
do{
printf("%d\n", i);
i--;
}while(i > 0);
顺便一提,do 语句最好都加上花括号。
虽然 do while 没有 while 语句使用的那么多,但是前者对于至少需要执行一次的循环来说是十分方便的。
三 for 循环
现在开始介绍 C 语言最后一种循环,也是功能最强大的一种循环:for 语句。它是我们用的最多的一种循环,一定要熟练掌握。
1. for 语句的基本用法
for(表达式1; 表达式2; 表达式3){
循环体
}
例3-1 倒计数程序
for(i = 10; i > 0; i--){
printf("%d\n", i);
}
在执行上面这个 for 语句时,i 先初始化为 10;然后判定 i 是否大于 0 ;因为结果为真,执行循环体;然后对变量 i 进行自减操作;然后再次判断 i 是否大于 0 … 直到最后一次 i 自减后,i > 0 不成立了,退出循环。
or 循环如果我们用 while 语句 也可以模拟:
i = 10;
while(i > 0){
printf("%d\n", i);
i--;
}
抽象一下即为:
表达式1;
while(表达式2){
循环体;
表达式3;
}
4. 逗号表达式
逗号表达式(comma expression)
基本用法
表达式1,表达式2,表达式3,...,表达式n;
- 逗号表达式的优先级低于所有其他运算符
- 从左向右依次执行:先计算表达式1,然后是表达式2 …
- 最终整个逗号表达式的值为最后一个表达式的值
例如:
i = 1, j = 2, k = i + j;
相当于是:
((i = 1), (j = 2), (k = i + j));
整个逗号表达式的值为 k = i + j 的值,也就是 3
08数组
一 一维数组
数组是含有多个数据值的数据结构,并且每个数据具有相同的数据类型。这些数据值称为元素(element)。
最简单的数组是一维数组。一维数组中的每个元素一个接一个的排列。
为了声明数组,需要指明数组元素的类型和数量。
int a[10];// 一个含有 10 个 int 类型变量的数组
数组的元素可以是任意类型,数组的长度可以是任何**(整数)常量表达式**指定。
#define N 10
int a[N];
但是不能使用变量(C89)
n = 10;
int a[n];
尽管 C99 已经允许这种做法,但是,很多编译器并不完全支持 C99 。
1. 数组下标
对数组取下标(subscripting)或进行索引(indexing):为了取特定的数组元素,可以在写数组名的同时在后面加上一个用方括号围绕的整数值。
数组元素始终从 0 开始,所以长度为 n 的数组元素的索引时 0 ~ n - 1
例如,a 是含有 10 个元素的数组:

a[i]是左值,所以数组元素可以像不同变量一样使用:
a[0] = 1;
printf("%d\n", a[5]);
++a[i];
2. 数组和 for 循环
许多程序包含的 for 循环都是为了对数组的每个元素执行一些操作。下面给出了长度为 N 的数组 a 的一些常见操作。
for(i = 0; i < N; i++){
a[i] = 0; // clears a
}
for(i = 0; i < N; i++){
scanf("%d", &a[i]); // reads data into a
}
for(i = 0; i < N; i++){
sum += a[i]; // sums the elements of a
}
程序:数列反向
要求录入一串数据,然后按反向顺序输出这些数:
Enter 10 numbers: 1 2 3 4 5
In reverse order: 5 4 3 2 1
参考程序:
#include这个程序使用宏的思想可以借鉴。
3. 数组初始化
数组初始化(array initializer)
一般的初始化方法:
int a[5] = {1, 2, 3, 4, 5};
如果初始化式子比数组短,那么剩余的元素被赋值为 0
int a[5] = {1, 2, 3};
// initial value of a is {1, 2, 3, 0, 0}
利用这一特性,可以很容易的将数组全部初始化为 0:
int a[5] = {0};
如果给定了数组的初始化式,可以省略数组长度:
int a[] = {1, 2, 3, 4, 5};
编译器利用初始化式的长度来确定数组大小。数组仍有固定数量的元素。
5. 对数组使用 sizeof 运算符
int a[10];
printf("%zu", sizeof(a));
数组的大小是数组每个元素大小的总和,也就是:数组元素个数 x 数组数据类型的大小
上例数组大小为 4 x 10 = 40 (int 大小为 4 的机器上)。
也可以用 sizeof 计算数组元素的大小:
int a[10];
printf("%zu", sizeof(a[0]));
// 4
此外还有我们经常使用的:**计算数组长度:**用数组的大小除以每个元素的大小
int a[] = {1, 2, 3};
printf("%zu", sizeof(a) / sizeof(a[0]));
细心的你可能已经发现,为什么我用的 printf 的转换说明都是 %zu 这是因为 sizeof 的返回值类型是 size_t 类型(unsigned int),%zu 是专门为这种类型设置的转换说明。
所以,有时候当你这样写程序时,可能会有报错:
for(int i = 0; i < sizeof(a) / sizeof(a[0]); i++){
...
}
这时因为 i 和 sizeof(a) / sizeof(a[0]) 类型不一样,可以强制类型转换一下:
for(int i = 0; i < (int)sizeof(a) / sizeof(a[0]); i++){
...
}
如果你嫌麻烦,可以使用宏定义数组长度,但是如果两个数组大小不一样,你就要定义两个宏。
这时候我们可以使用带参数的宏:
#define ARRAY_LENGTH(a) (int)sizeof(a) / sizeof(a[0])
int b[5];
printf("%d", ARRAY_LENGTH(b));
如果不懂,也没有关系,后面我们会详细讲解。
二 多维数组
数组可以有任意维数。不过多维数组我们一般只使用二维数组。
二维数组的声明:
int a[3][3];

a[i][j]访问的时 第 i 行 第 j 列的元素。
虽然我们以表格的形式显示二维数组,但是实际上它们在计算机的内存中是按照行主序线性存储的,也就是从第 0 行开始。
所以上面的数组实际是这样存储的:

基于这个特性,我们一般用嵌套的 for 循环遍历二维数组:
int a[3][3];
for(int row = 0; row < 3; row++){
for(int col = 0; col < 3; col++){
a[row][col] = 0;
}
}
1. 多维数组初始化
嵌套的一维数组初始化式:
int a[3][3] = {
{1, 2, 3},
{4, 5, 6},
{7, 8, 9}
};
缺省:
int a[3][3] = {
{1},
{2, 3}
}
我们只初始化了第 1 行第 1 个元素,第 2 行第 1,2 个元素,其余的元素初始化为 0
甚至可以不写内层的大括号:
int a[3][3] = {
1, 2, 3,
4, 5, 6,
7, 8, 9
};
一旦编译器填满一行,就开始填充下一行。
试思考,如果这样初始化二维数组,结果会是怎样:
int a[3][3] = {
1,
2, 3,
};
第一行被初始化为 1,2,3 其余都为 0
推荐阅读:
- 反思数组
09函数
一 函数的定义和调用
在介绍函数的定义之前,让我们先来看 3 个简单定义的函数。
这三个函数我就不详细分析了,你可以打开我之前讲 main 函数的构成那篇文章,和 main 函数对比着看。
1. 3 个 简单的函数
① 计算平均值
假设计算两个 double 类型的数值的平均值。
double average(double x, double y){
return (x + y) / 2;
}
int main(void){
double x = 1.0, y = 2.0;
printf("%f", average(x, y));
return 0;
}
② 显示倒计数
不是每一个函数都有返回值:
void print_count(int n){
printf("T minus %d and counting\n", n);
}
int main(void){
for(int i = 10; i > 0; i--){
print_count(i);
}
return 0;
}
③ 显示双关语
不是每个函数都有参数:
void print_pun(){
printf("To C or not to C: that is a question\n");
}
int main(void){
print_pun();
return 0;
}
2. 函数定义
返回类型 函数名(形式参数){
声明
语句
}
返回类型
函数的返回类型是函数返回值的类型。
- 函数不能返回数组
- 返回类型是void表示没有返回值
- 如果省略返回值,C89 会假设函数返回的是 int 类型;C99 中这是不合法的。
一些程序员喜欢将返回类型放在函数名的上边:
double
average(double x, double y){
return (x + y) / 2;
}
如果返回类型很长,比如 unsigned long int 类型,那么这样写是非常有用的。
形式参数
每个形式参数前需要写明其类型,形参之间用逗号隔开。
【C语言程序设计——现代方法】这本书中写到:“如果函数没有形式参数,那么圆括号内应该出现 void ”
注意:即使几个形参具有相同的数据类型,也必须对每个形参分别进行类型说明。
double average(double a, b){// error
}
函数体
C89 中,变量声明必须出现在语句之前。
C99 中,允许声明和语句混在一起,只要在第一次使用之前进行声明即可。
C89
// 声明
int a, b, c;
// 语句
printf("请输入两个数:");
scanf("%d %d", &a, &b);
c = a + b;
printf("%d\n", c);
C99
// 语句
printf("请输入两个数:");
// 声明
int a, b;
// 语句
scanf("%d %d", &a, &b);
// 声明
int c = a + b;
// 语句
printf("%d\n", c);
块
块(block):一对花括号内就是一个块
我们在讲循环时说过,如果你这样写 for 语句:
for(int i = 0; ; ){
}
在 for 语句内定义变量 i ,那么当 for 循环结束后,后面的程序没有办法再去使用 i 了,因为 i 已经不存在了。
for 语句的大括号其实就是一个块。
在块内定义的变量只属于这一个块,块外的程序是没有办法访问和修改块内定义的变量的。
如果你还是不理解,可以看看下一章内容中的作用域和生存期。
3. 函数调用
函数调用由函数名和实参列表组成,实参列表用圆括号括起来:
average(x, y);
print_count(i);
print_pun();
返回值非 void 的函数会产生一个值,该值可以存储在变量中,还可以进行测试,显示或者其他用途。
avg = average(x, y);
if(avg > 0){
printf("Average is positive\n");
}
如果不需要非 void 函数返回的值,总可以将其丢弃:
average(x, y); // discard return value
average 函数的这个调用就是一个表达式语句的例子:计算出结果,但是不保存它
有时候我们可以直接将函数调用产生的结果当做 printf 函数的参数:
printf("%f", average(x, y));
这种做法其实也是丢弃了 average 的返回值。
说到丢弃返回值,我们最常用的两个函数 printf 和 scanf也是有返回值的:
num_chars = printf("Hello World!\n"); // num_chars is now 13
程序:判断素数
编写程序提示用户录入数,然后给出一条信息说明此数是否为素数。
Enter a number: 24
Not prime
把判断素数的实现写到另外一个函数中,此函数返回值为 true 就表示是素数,返回 false 表示不是素数。
参考程序:
#include形式参数:(parameter) 出现再函数的定义中
实际参数:(argument)出现在函数调用中的表达式。
在 C语言中,实际参数是通过值传递的:调用函数时,计算出每个实际参数的值并将它赋值给相应的形式参数。在函数执行的过程中,形式参数的改变不会影响实参的值,这是因为形式参数是实参的副本。从效果上来讲,每个形式参数初始化为相应的实参的值。
实际参数按值传递有利有弊。
-
利:可以直接修改形参的值
比如:计算 x 的 n 次方
int power(int x, int n){ int i = n; int ret = 1; for(i = 1; i <= n; i++){ ret *= x; } return ret; }我们可以在函数内直接修改 n 来减少引入的变量:
int power(int x, int n){ int ret = 1; while(n--){ ret *= x; } return ret; } -
弊:如果我们需要函数返回一个以上的值,那么按值传递显然是无法直接做到的
例如:我们需要设计一个函数,将 double 类型的值分解成整数和小数部分。因为无法返回两个数,所以通过返回值返回我们计算出的整数部分和小数部分是不现实的。所以可以尝试传入两个变量给函数并修改它们:
void decompose(double x, long int_part, double frac_part){ int_part = (long)x; // drops the fractional part of x frac_part = x - int_part; }前面我们也说了,这显然也是不现实的。因为形参的改变无法修改实参。
如果你感到困惑,我们可以来测试一下:我们在 main 函数中调用这个函数:
int main(void){ double x = 3.1415926; int i; int d; decompose(x, i, d); printf("%d %f", i, d); // 编译应该会报错,提示 i,d 未初始化,总之,不是我们想要的结果 return 0; }2. 数组型实际参数
数组经常被当作实际参数。当形式参数为一维数组时,可以(而且是通常情况下)不说明数组长度:
int f(int a[]){ ...; }C 语言没有为函数提供任何简便的方法来确定传递给它的数组的长度,所以通常情况下,我们必须把数组长度作为额外的参数提供出来
示例:数组求和
int sum_array(int a[], int n); int main(void){ int a[] = {1, 2, 3, 4, 5}; int len = sizeof(a) / sizeof(a[0]); int sum; sum = sum_array(a, len); return 0; } int sum_array(int a[], int len){ int ret = 0; for(int i = 0; i < len; i++){ ret += a[i]; } return 0; }**注意:**虽然可以用运算符
sizeof计算出数组变量的长度,但是它无法给出数组类型的形式参数参数的正确答案:int f(int a[]){ int len = sizeof(a) / sizeof(a[0]); ...; }数组变量作为函数参数的特性
1)数组无法检测传入的数组长度是否正确,所以:
-
一个数组有 100 个元素,但是实际仅仅使用 50 个元素,实参可以只写 50:
sum_array(a, 50);函数甚至不会知道数组还有 50 个元素存在!
-
如果实际参数给的比数组还要大,会造成数组越界,从而导致未定义行为
sum_array(a, 150);// wrong
2)在函数中改变数组型形式参数的元素,同时会改变实际参数的数组元素。
#includevoid store_zero(int a[], int len){ for(int i = 0; i < len; i++){ a[i] = 0; } } int main(void){ int a[3] = {1, 2, 3}; store_zero(a, sizeof(a) / sizeof(a[0])); for(int i = 0; i < 3; i++){ printf("%d ", a[i]); } return 0; } //输出: 0 0 0 多维数组
多维数组的形式参数可以省略第一维的长度,比如
a[][3]但是,这样的方式不能传递具有任意列数的多维数组。幸运的是,我们通常可以通过使用指针数组的方式解决这一问题。
-
四 return 语句
非 void 类型的函数必须使用
return语句来指定将要返回的值。
return 表达式;
表达式可以是
- 常量:
return 0 - 变量:
return a - 复杂的表达式:
return n >= 0 ? n : 0
如果 return 语句表达式的值和返回类型不匹配,那么系统将把表达式的类型隐式转换为返回类型。
return 也可以出现在返回值类型为 void 的函数中:我们可以直接使用return;(没有表达式)来让函数结束。
下面的例子中,如果 i 是负数,return 语句会让函数立即返回
void print_int(int i){
if(i < 0)
return;
printf("%d", i);
}
return 语句可以出现在 void 函数的末尾:
void print_pun(){
printf("To C or not to C: that is a question\n");
return; // Ok,but not needed.
}
但是 return 语句不是必须的,因为在执行完最后一条语句后函数会自动返回。
六 递归
如果一个函数调用它本身,那么此函数就是递归的(recursive)。
有些编程语言极度依赖递归,而有些编程语言甚至不允许使用递归。C语言介于中间:它允许递归,但是大多数 C 程序员并不经常使用递归。
用递归计算 n! 的结果:
int fact(int n){
if(n <= 1){
return 1;
}
else{
return n * fact(n - 1);
}
}
为了了解递归的工作原理,一起来追踪下面这个语句的执行:
i = fact(3);
fact(3) 发现 3 不是小于等于 1 的,fact(3) 调用
fact(2),此函数发现 2 不是小于等于 1 的,fact(2) 调用
fact(1) ,此函数发现 1 是小于等于 1 的,所以 fact(1) 返回 1,从而导致
fact(2) 返回 2 * 1 = 2,从而导致
fact(3) 返回 3 * 2 = 6
注意: 要理解 fact 函数最终传递 1 之前,未完成的 fact 函数是如何“堆积”的。在最终传递 1 的那一点上,fact 函数逐个解开,直到 fact(3) 的原始调用返回 6 为止。
上面的程序也可以简化为:
int fact(int n){
return n <= 1 ? 1 : n * fact(n - 1);
}
注意: n <= 1 就是终止条件,为了放置无限递归,所有的递归都应该有终止条件。
推荐阅读:
- 反思函数
10程序结构
一 局部变量
函数体内声明的变量称为该函数的局部变量。
比如:
int main(void){
int i;
return 0;
}
变量 i 就是局部变量。
局部变量的性质:
- 自动存储期限。变量的存储期限(生存期)(storage duration)(或存储长度)。局部变量的存储单元在函数被调用时“自动”分配,函数返回时自动回收,所以称这种变量具有自动的存储期限。包含局部变量的函数返回时,局部变量的值无法保留。当再次调用该函数时,无法保证变量仍拥有原先的值。
- 块作用域。变量的作用域是可以引用该变量的程序文本部分。局部变量拥有块作用域:从变量声明的点开始一直到所在函数体的末尾。因为变量的作用域不能延伸到其所属的函数之外,所以其他函数可以把同名变量用于其他用途。
这一段介绍写的太书面化了。其实上面说的无非就是生存期和作用域问题。
关于生存期和作用域的程序演示
下面的程序计算数组元素的和:
#include我们将上面的程序改写为:
#include用简单的描述一下作用域和生存期:
作用域:限定某个名字的可用性的代码范围就是该名字的作用域
生存期:变量值存在的时间
块:一个花括号
{}就是一个块。通常来说,变量的作用域和生存期都是在一个块内。
上面第二个程序的执行结果和第一个完全一样,我们现在来一步一步分析一下:
// 新的块(函数)中,i 是一个新的变量,mian 函数中的 i 在这里不再生效(作用域和生存期失效)
// 这个 i 就是实参的值,也就是 5
void sum_array(int a[], int i) {
int len = i;
int sum = 0;
// for 语句内 i 的情况和 mian 函数中的一样
for (int i = 0; i < len; i++) {
sum += a[i];
// 为了证明 for 语句内的 i 和外面形参 i 完全不同,在即将退出循环时,我将 i 增加了 5,
// 所以退出循环时里面的 i 的值为 10
if (i == len - 1) {
i += 5;
}
}
// 最后输出的 i 依然是形参 5
printf("sum is %d, length of array is %d", sum, i);
}
int main(void) {
int i = 10;
int a[5];
//在 for 语句这个块内重新声明的 i ,这个 i 和上面的 i 是完全不同的变量。
// 修改 for 语句内的 i 不会影响外面的 i ,虽然外面的 i 在 for 语句内依然生效,但是可以理解为里面的 i 将其覆盖了
// 正所谓谁的地盘谁做主
for (int i = 0; i < 5; i++) {
scanf("%d", &a[i]);
}
// for 语句执行结束后,里面的 i 被自动回收了。i 不再生效。
// 所以下面的 i 就是外部的 i,也就是 10
sum_array(a, i / 2);
return 0;
}
1. 静态局部变量
在局部变量中放置单词 static 可以使变量具有静态存储期限而不再是自动存储期限。
因为具有静态存储期限的变量拥有永久的存储单元,所以在整个程序的执行期间都会保留变量的值。比如:
void func(){
int static n; // static locol variable
}
在函数 func 返回时,变量 n 的值不会丢失。
静态局部变量虽然生存期是整个程序,但是作用域尽在其所定义的块内。也就是说,上例中函数 func 返回后,func 内的 n 就不再可用。
#include二 全局变量
全局变量(外部变量 external variable)声明在所有函数体之外。
全局变量的性质
-
静态存储期限。
#includeint i = 0; void func() { printf("%d\n", ++i); } int main(void) { func(); func(); func(); return 0; } //输出: 1 2 3 -
文件作用域。全局变量的作用域:从变量被声明的点开始一直到所在文件的末尾。外部变量声明之后的函数都可以访问(并修改)它。
#includeint i = 0; void func() { printf("%d\n", ++i); } void func1() { printf("%d\n", ++i); } int main(void) { func(); func1(); func(); return 0; } //输出: 1 2 3
全局变量的利与弊
利: 多个函数共享一个变量时或者少数几个函数共享大量变量时,外部变量很有用。
然而在大多数情况下,对于函数而言,传参比共享变量更好。原因如下:
弊:
- 在程序维护期间,如果改变全局变量(比方说改变其类型),那么将需要检查同一文件中的每个函数,以确认该变化如何对函数产生影响。
- 如果全局变量被赋了错误的值,可能很难确定出错的函数。
- 很难在其他程序中复用依赖于全局变量的函数。依赖全局变量的函数不是“独立”的。为了在另一个程序中使用该函数,必须带上此函数需要的全局变量。
- 如果全局变量在多个函数中使用(比如 for 循环的控制变量 i),让人误认为变量的使用彼此关联,而实际可能并非如此。
注意: 使用全局变量时,要确保它们的名字都有意义。如果你发现全局变量的名字就像 i,temp一样,这可能意味着这些变量其实应该是局部变量。
将局部变量声明为全局变量可能会导致一些问题。思考下例:
int i;
void print_one_row(void){
for(i = 1; i <= 10; i++)
printf("*");
}
void print_all_row(void){
for(i = 1; i <= 10; i++){
print_one_row();
printf("\n");
}
}
此时,print_all_row 打印的不是 10 行,而是 1 行。第一次调用 print_one_row 函数返回时, i 的值将为 11 ,不满足 for 的控制表达式,循环退出。
所以,全局变量建议不要使用。
三 构建 C 程序
从 猜数 的程序中你应该大体可以感受到如何从头到尾去写一个 c 程序。我们这里给出比较好的编排顺序:
#include指令#define指令- 类型定义
- 全局变量声明
- 函数原型
- main 函数定义
- 其他函数定义
多写写程序自然会领略到其中的道理。
推荐阅读:
- 初探程序结构
11指针
一 指针变量
现代大多数计算机将内存分割为字节(byte),每个字节可以存储 8 位的信息:0000 0001。
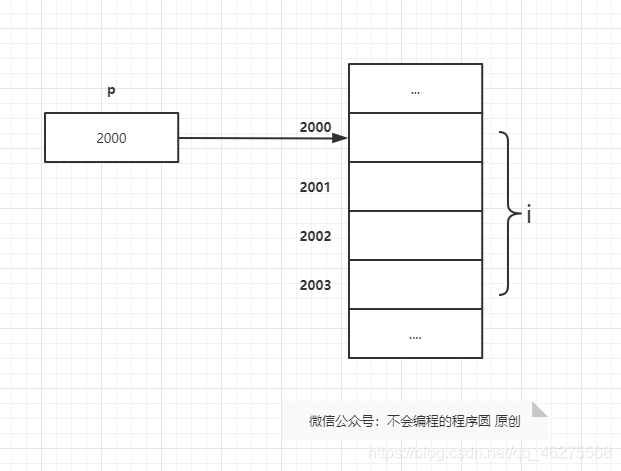
每个字节都有唯一的地址(address),用来和内存种的其他字节相区别。如果内存中有 n 个字节,那么可以把地址看作 0 ~ n - 1的数。

可执行程序由代码(原始 C 程序中于语句对应的机器指令)和 数据(原始程序中的变量)两部分构成。程序中的每个变量占有一个或多个字节,把第一个字节的地址称为是变量的地址。

上图中,i 占有的字节是 2000 ~ 2003 4 个字节,2000 就是 i 的地址。
虽然用数表示地址,但是地址的取值范围可能不同于整数的取值范围,所以一定不能用普通的整型变量存储地址。
但是,我们可以用特殊的指针变量(pointer variable)存储地址。在用指针变量存储 p 存储变量 i 的地址时,我们说 p “指向” i 。换句话说,指针就是地址,而指针变量就是存储地址的变量。
1. 指针变量的声明
int* p;
上述声明说明p 是指向 int 类型对象的指针变量。这里我们用术语对象代替变量,这是因为 p 可以指向不属于变量的内存区域。(后面会讲)
指针变量可以与其他变量一起出现在声明中:
int a, b[10], *p, *q;
C 语言要求每个指针变量只能指向一种特定类型(引用类型)的对象。
int* p;
double* q;
char* r;
关于指针变量声明中 * 与谁挨着的问题:
请看下面的声明:
int* p,q;
请问,上面的声明中 p 和 q 都是指针变量吗?
小黄:我觉得是,如果你写成这样:
int *p, q;
那就是只有 p 是指针变量了。
程序圆:你这样想就大错特错啦,上面这两种写法是等价的。都是声明 p 为指针变量而 q 是一个普通的 int 类型变量。
小黄:哦~那我们平时应该选择那种写法呢?
程序圆:通常情况下我们都是选择第一种写法,即:int* p。但是这样确实容易造成误解,所以我们通常一行只声明一个指针变量就可以了。
二 取地址运算符和间接寻址运算符
1. 取地址运算符
声明指针变量时我们没有将它指向任何对象:
int* p;
在使用之前初始化 p 是至关重要的。使用取地址运算符&把某个变量的地址赋值给它。
int i;
p = &i; //&i 就是 i 在内存中的地址
现在 p 就指向了整型变量 i
我们也可以声明的同时初始化:
int i;
int* p = &i;
甚至可以这样:
int i, *p = &i;
但是需要先声明 i
2. 间接寻址运算符
间接寻址运算符也叫解引用运算符,我个人还是喜欢叫它用解引用运算符。
int i;
int* p = &i;
指针变量 p 指向 i,使用*运算符可以访问存储在对对象中的内容(访问存储在指针变量指向的地址上的内容)。
printf("%d", *p); // (*p == i)
“*和&互为逆运算”:
j = *&i;// same as j = i;
只要 p 指向 i,*p 就是 i 的别名。**p 不仅拥有和 i 相同的值,而且 p 的改变也会改变 i 的值。
int i = 0;
int* p = &i;
printf("i = %d\n", i);
printf("p = %d\n", *p);
// 输出:0 0
*p = 1;
printf("now i = %d\n", i);
printf("now p = %d\n", *p);
//输出:1 1
注意:
解引用未初始化的指针变量会导致未定义行为:
int* p;
printf("%d", *p);
给 *p赋值尤为危险。如果 p 恰好具有有效的内存地址,程序会试图修改存储在该地址的数据:
int* p;
*p = 1; // wrong
这是极度不安全的行为。好在我们的编译器会给出警告。即使这样使用了,编译器不会真的让你去修改其他地方(比如操作系统等)的数据。
所以如果你定义的指针特别多,你也不知道那个会被用上,可以这样初始化指针变量:
int* p = NULL; // NULL 表示空指针,该处的内存无法修改
然后在需要对 p 解引用的地方添加一个判断:
if(p != NULL){
...;
}
三 指针赋值
C 语言允许相同类型的指针变量进行赋值。
int i;
int* p = &i;
int* q;
q = p;
或者直接初始化并赋值:
int* q = p;

现在可以通过改变 *p 的值来改变 i :
int i = 0;
int* p = &i;
int* q = p;
printf("now i = %d\n", i);
printf("now p = %d\n", *q);
// 输出:0 0
*q = 2;
printf("now i = %d\n", i);
printf("now p = %d\n", *q);
//输出:2 2
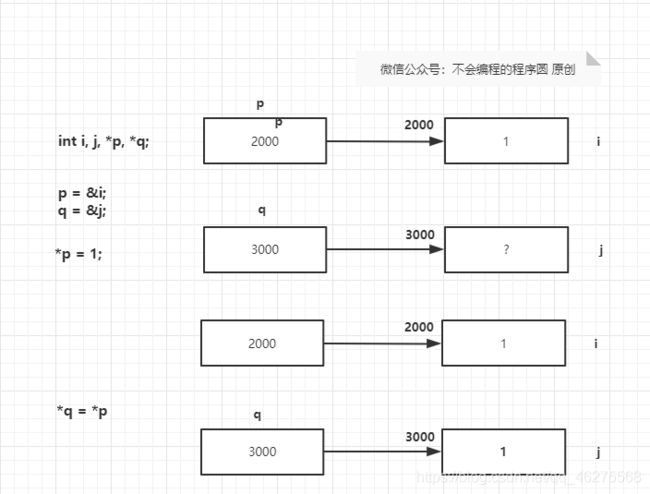
不要将 *q = *p 和 q = p 搞混,前者是将 p 指向的对象的值(变量 i 的值)赋值给 q 指向的对象(变量 j)中。
四 指针作为参数
还记得之前分解小数的函数 decompose 吗?我们曾将想在这个函数中通过改变形参来改变实参,但是我们失败了,今天我们再来重新看一下如何用指针作为参数完成这一任务:
将 decompose 函数定义中的形参 int_part 和 frac_part 声明成指针类型。
void decompose(double x, long* int_part; double* frac_part){
*int_part = (long)x;
*frac_part = x - *int_part;
}
调用该函数:
int i;
double x, d;
decompose(x, &i, &d);

当函数调用完成,实参 i 和 d 的值也修改了。你可以再 main 函数中输出一下 i 和 d 测试一下。
用指针作为参数其实并不新鲜:
int i;
scanf("%d", &i);
必须将 & 放在 i 前以便传给 scanf 函数指向 i 的指针,指针会告诉 scanf 函数将读取的值放在那里。如果没有 & 传递给 scanf 的将是 i 的值。
虽然 scanf 函数的实参必须是指针,但是并不是总需要 & 运算符:
int i;
int* p = &i;
scanf("%d", p);
p 已经包含了 i 的地址,所以不需要 &。使用 & 是错误的:
scanf("%d", &p);
scanf 函数将把读入的整数放在 p 中而不是 i 中。
五 指针作为返回值
请看返回值类型为 int*类型的函数 max:
int* max(int* a, int* b){
if(*a > *b)
return a;
else
return b;
}
max 返回较大数的指针。
调用:
int a,b;
int* p = max(&a, &b);
需要使用相同的指针类型接收返回值。
注意:
永远不要返回指向自动局部变量的指针:
int* f(){
int i;
...
return i;
}
一旦 f 返回,i 就不存在了,所以指向 i 的指针是无效的。有的编译器可能给出警告:“function returns address of local variable”
推荐阅读:
- 基础
- 运算
- const
- 指针进阶
12指针与数组
一 指针的算数运算
int a[10] = {0};
int* p = &a[0];

我们可以通过 p 访问 a[0]:
*p = 5;
printf("%d", a[0]); // 5
C 语言只支持 3 种格式的指针算数运算:
- 指针加上整数
- 指针减去整数
- 两个指针相减
1. 指针加整数
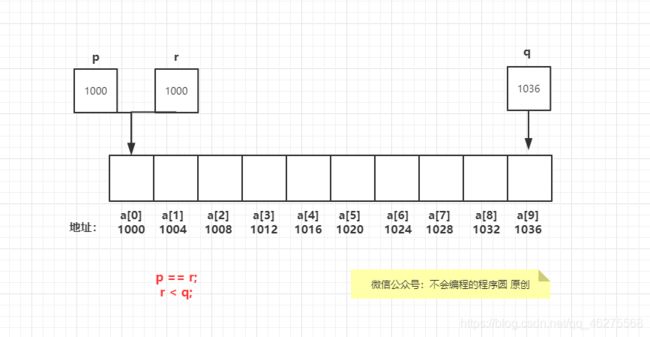
指针 p 加上整数 j 产生指向特定元素的指针,这个特定元素是 p 原先指向的元素的后的 j 个位置。也就是说如果 p 指向 a[i],那么 p + j 指向 a[i + j],前提是 a[i + j] 存在。如图:

2. 指针减整数
如果指针 p 指向数组元素 a[i],那么 p - j 指向 a[i - j] 。例如:

3. 两个指针相减
两个指针相减结果是指针之间的距离(用数组元素个数来度量)。
如果 p 指向 a[i],q 指向 a[j],q - p 等于 j - i 。例如:

注意:
在一个不指向任何数组元素的指针上执行算数运算会导致未定义行为。此外,只有在两个指针指向同一个数组时,把他们相减才有意义。
4. 指针比较
可以用关系运算符(<,>,<=,>=)和判等运算符(==和 !=)进行指针比较。只有在两个指针指向同一数组时,用关系运算符进行指针比较才有意义。比较的结果依赖于数组种两个元素的相对位置。如图:
二 指针用于数组处理
通过对指针变量进行重复自增来访问数组元素。
#define N 10
int a[N], sum, *p;
sum = 0;
for(p = &a[0]; p < &a[N]; p++)
sum += *p;
解引用 与 自增自减 的组合
对于语句:
a[i++] = j;
我们可以用指针改写为:
*p++ = j;
因为后缀 ++ 的优先级高于 * ,所以上面的语句等同于:
*(p++) = j;
先将 j 赋值给 p 指向的对象,然后 p 指向数组下一个元素。
| 表达式 | 含义 |
|---|---|
| (*p)++ | *p 自增(后置) |
| *++p 或 *(++p) | 先自增 p,然后解引用 |
| ++*p 或 ++(*p) | *p 自增 (前置) |
我们最常用到的就是 *p++ 。
对数组元素求和时,我们可以将前面写的 for 循环改写为:
p = &a[0];
sum = 0;
while(p < &a[N])
sum += *p++;
* 和 – 的组合和 ++ 类似。
三 数组名作为指针
可以用数组名作为指向数组第一个元素的指针
int a[5] = {1, 2, 3, 4, 5};
printf("%d\n", *a); // 1
printf("%d\n", *(a + 4)); // 5
*(a + 1) = 1; // a[1] is now 1
明白了这个原理,我们可以改写 for 语句求和数组元素的程序:
for(p = a; p < a + N; p++)
sum += *p;
**注意:**数组名是被 const 保护的指针:
int a[5];
// 类似于:
int* const a;
所以,数组名 a 的指向不能被改变。
int a[5], b[10];
a = b; // wrong
a++; // wrong
这一限制不会给我们造成什么损失:我们可以把 a 赋值给一个指针变量,然后改变该指针变量:
p = a;
p++;
程序:数列反向(改进版)
前面我们讲过一个逆序输出数列的程序。
原来的程序利用下标来访问数组中的元素。我们用指针的算数运算取代数组的取下标操作:
#include1. 处理多维数组的元素
如果把多维数组看作一维数组,可以这样遍历数组:
#includep 从数组的第一个元素地址开始遍历到数组的最后一个元素的地址。
虽然这种写法对大多数 C 的编译器都是合法的。但是明显破坏了程序的可读性,对一些老的编译器来说这种方法提高了效率。但是对许多现代编译器这样所获得的速度优势往往极少甚至没有。
13字符串
一 字符串字面量
字符串字面量(string literal)是一对用双引号括起来的字符序列。
C++ 中常称为字符串字面值,或称为常值,或称为字面量。有些 C 语言的书中称之为字串
1. 字符串字面量中的转义序列
字符串字面量可以包含转义序列。比如:
printf("Hello World\n");
虽然字符串字面量中的八进制数和十六进制数的转义序列也是合法的,但是字符转义序列更为常见。
3. 字符串字面量的存储
本质上而言,C 语言把字符串字面量作为字符数组来处理。当 C 语言编译器在程序中遇到了长度为 n 的字符串字面量时,它会为字符串字面量分配长度为 n + 1 的内存空间。额外的 1 个空间用来存放一个空字符来标识字符串末尾。空字符是所有位都为 0 的字节,因此用转义序列\0来表示。
注意:不要混淆空字符'\0'和零字符'0'。
'\0'的 ASCII 码值为 0;'0'的 ASCII 码值为 48
"abc"使用 4 个字符的数组来存储的:

字符串字面量可以为空:""表示单独存储一个空字符
既然字符串字面量是作为数组来存储的,那么编译器会把它看作是 char*类型的指针。
printf和scanf函数都接收 char*类型的值作为它们的第一个参数。思考下面的例子:
printf("abc");
当调用 printf 函数时,会传递 “abc” 的地址。(即指向存储字母 a 的内存单元的指针)
二 字符串变量
一些编程语言专门为声明字符串变量提供了专门的 string 类型。C 语言采用了不同的方式:只要保证字符串是以空字符结尾的,任何一维的字符数组都可以用来存储字符串。
假设需要用一个变量来存储最多有 80 个字符的字符串。由于字符串末尾有空字符,我们需要声明含有 81 个字符的数组:
#define STR_LEN 80
char str[STR_LEN + 1];
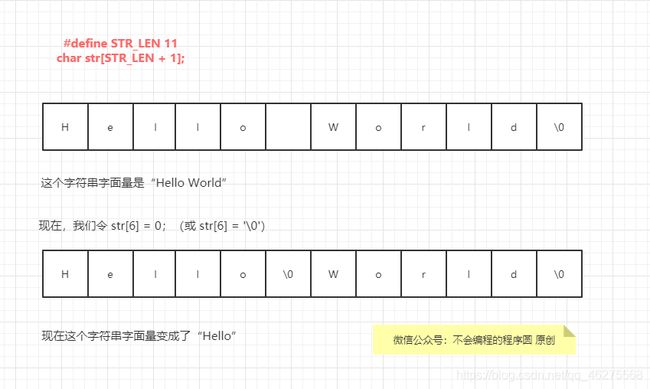
这里把 STR_LEN定义为 80 而不是 81,强调的是 str 最多可以存储 80 个字符;然后才在 str 的声明中对 STR_LEN 加 1 。这是 C 程序员常用的方式。
注意:声明用于存放字符串的数组时,要始终保证数组长度比字符串长度多一个字符
这是因为 C 语言规定每个字符串都已 \0 结尾。如果没有空字符预留位置,可能导致运行时出现未定义行为。因为C函数库中的函数假设字符串都以空字符结尾。

声明长度为 STR_LEN + 1的字符数组并不意味着总是存放长度为 STR_LEN 的字符串。字符串长度取决于 \0出现的位置。
1. 初始化字符串变量
字符串变量可以在声明时进行初始化:
char date1[8] = "June 14";
编辑器将把字符串 “June 14” 中的字符复制到数组 data1 中,然后追加一个空字符:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RvCbeCn1-1595685307533)(C:\Users\78172\Desktop\素材\C必知必会\24.png)]1
“June 14” 看起来像是字符串字面量,但其实不然。C 编译器会把它看成是数组初始化式的缩写形式。实际上我们可以写成:
char date1[8] = {'J', 'u', 'n', 'e', ' ', '1', '4', '\0'};
不管是编写还是阅读,后者都不是好的选择。使用数组的初始化式时,切记要手动加上 '\0’
如果初始化式太短以致于不能填满字符串变量将会如何呢?在这种情况下,编译器会添加空的字符。因此,在声明:
char date2[9] = "June 14";
之后,data2 将如下图所示:

如果初始化式比字符串变量长会怎样?这对字符串而言是非法的,就如同对数组而言是非法的一样。然而,C 语言允许初始化式(不包括空字符)与变量有完全相同的长度。
char data3[7] = "June 14";
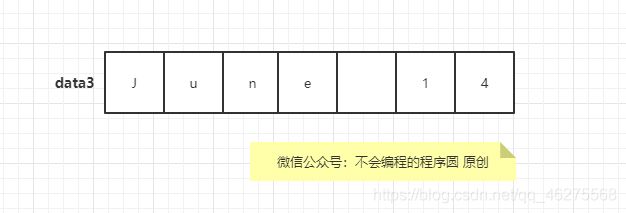
由于没有给空字符留出空间,所以编译器不会试图存储空字符。因此,data3 无法作为字符串使用。
字符串变量的声明中可以省略它的长度。这种情况下,编译器会自动计算长度:
char date4[] = "June 14";
编译器会为 date4 分配 8 个字符的空间。
如果初始化式很长,那么省略字符串变量的长度是特别有效的,因为手工计算长度很容易出错。
2. 字符数组与字符指针
char date[] = "June 14";
char* date = "June 14";
前者声明 date 是一个字符数组,或者声明 date 是一个指针。
它们的相同点类似数组和指针,现在我们看一下不同点:
- 声明为数组,可以修改存储在 date 中的元素;声明为指针,date 指向字符串字面量,前面我们已经讲过字符串字面量是不能被修改的。
- 声明为数组,date 是数组名。声明为指针,date 是变量,这个变量可以在程序执行期间指向其他字符串。
如果我们希望可以修改字符串,那么应该建立字符数组存储字符串。
如果我们声明了一个char*类型的指针,在使用它之前应让它指向字符串字面量或者字符串变量。
注意:使用未初始化的指针变量作为字符串是严重的错误
char *p;
p[0] = 'a'; // wrong
p[1] = 'b'; // wrong
p[2] = 'c'; // wrong
p[3] = '\0'; // wrong
这个程序试图创建一个字符串。因为 p 没有被初始化,所以我们不知道它指向哪里。直接解引用属于非法内存访问。
三 字符串的读和写
1. 用 printf 函数和 puts 函数写字符串
使用转换说明:%s
char str[] = "Are you happy?";
printf("%s\n", str);
输出会是:
Are you happy?
可以使用 puts函数输出字符串。
puts(str);
puts 函数只有一个参数,即需要显示的字符串。写完字符串后,puts 函数总会添加一个额外的换行符:
puts(str);
puts(str);
输出:
Are you happy?
Are you happy?
puts 函数
int puts( const char *str )头文件:
参数:
str- 要写入的参数返回值:
成功时返回非负值
失败时,返回 EOF 并设置 stdout 的错误指示器
定义:
写入每个来自空终止字符串
str的字符及附加换行符 ‘\n’ 到输出流stdout,如同以重复执行 putc 写入。不写入来自
str的空终止字符。
2. 用 scanf 函数和 gets 函数读字符串
转换说明 %s
scanf("%s", str);
在 scanf 函数调用中,不需要在 str 前加 & 运算符,因为 str 是数组名,编译器在把他传给函数时会把它当作指针来处理。
调用时,scanf 函数会跳过空白字符,然后读入字符并存储到 str 中,直到遇到空白字符为止。scanf 函数始终会在字符串末尾存储一个空字符。
用 scanf 函数读入字符串永远不会包括空白字符。因此,scanf 函数通常不会读入一整行输入。换行符,空格符和制表符都会使 scanf 函数停止读入。为了一次读入一整行输入,可使用 gets函数。
gets 函数
char * gets(char * str)head:
Parameters:
str- Pointer to a block of memory (array of char) where the string read is copied as a C string.Return Value: On success, the function returns str.
Description:
Reads characters from the standard input (stdin) and stores them as a C string into str until a newline character or the end-of-file is reached.
The newline character, if found, is not copied into str.
A terminating null character is automatically appended after the characters copied to str.
总结一下重点就是:
- gets 函数不会在开始读字符串之前跳过空白字符。
- gets 函数会持续读入直到找到换行符才停止。换行符会被忽略,不会存储到数组中,在字符串末尾追加空字符。
我们用程序来比较一下 scanf 和 gets :
先来测试 scanf:
char str[20];
scanf("%s", str);// 输入 Are you ok?
puts(str);
输出:
Are
只有 “Are” 被存储到了 str 中
测试 gets:
char str[20];
gets(str); // 输入 Are you ok?
puts(str);
输出:
Are you ok?
“Are you ok?” 一整行被存入 str 中
注意:
把字符读入数组时,scanf 函数和 gets 函数都无法检测数组何时被填满。因此,它们存储字符时可能会越过数组的边界,这会导致未定义行为。
通过转换说明 %ns代替%s可以使 scanf 更加安全。这里 n 指出可以存储的最多字符数。可惜的是,gets 天生就是不安全的,fgets函数则是好的多的选择(后面会讲)。
3. 逐个字符读取字符串
int read_line(char str[], int read_num) {
int ch, i = 0;
while ((ch = getchar()) != '\n') {
// i 大于 read_num 不执行操作,跳过后面的字符
if (i < read_num)
str[i++] = ch;
}
str[i] = '\0';
return i;
}
四 访问字符串中的字符
C 程序员更喜欢用指针来跟踪字符串当前的位置:
int count_spaces(const char* s){
int count = 0;
while(*s != '\0'){
if(*s == ' ')
count++;
s++;
}
return count;
}
五 C 语言字符串库
一些编程语言提供的运算符可以对字符串进行复制,比较,拼接,选择字串等操作,但 C 语言的运算符根本无法操作字符串。所以我们需要常用到一些
注意:
对于两个字符串数组:
char str1[] = "Hello";
char str2[] = "World";
如果你这样复制字符串:
str1 = str2;// wrong
str1 = "abc"; // wrong
如果想这样比较字符串的内容:
if(str1 == str2){ // wrong
...
}
上面这样的行为都是不能达到你的预期的。
如果你要使用 string.h 中的函数,需要包含它的头文件:
#include我们这里介绍几种最基本的函数。
strcpystrlenstrcatstrcmp
七 字符串数组
存储字符串数组的最佳方式是什么?最明显的解决方案是创建一个二维字符数组,然后按照每行一个字符串来存储。
char planets[][8] = {
"Mercury", "Venus", "Earth",
"Mars", "Jupiter", "Saturn",
"Uranus", "Neptune", "Pluto"
};

因为只有 3 个行星的名字填满了一行,所以这样的数组有一点浪费空间。remind.c 程序就是这种浪费的的代表。
我们需要的是参差不齐的数组(ragged array),即每一行有不同长度的二维数组。C 语言本身不提供这样的数组类型。但是我们可以创建一个指针数组,数组的每个元素都是一个指向字符串的指针。声明方式:
char* planets[] = {
"Mercury", "Venus", "Earth",
"Mars", "Jupiter", "Saturn",
"Uranus", "Neptune", "Pluto"
};
现在 planets 的存储方式变为:

planets 中的每个元素都是指向以空字符结尾的字符串的指针。虽然必须为 planets 数组中的指针分配空间,但是字符串中不再有任何浪费的字符。
获取字符串和普通数组访问一样。由于数组和指针的特殊关系,我们可以这样访问字符串中的字符:
for(i = 0; i < 9; i++)
if(planets[i][0] == 'M')
printf("%s begins with M\n", planets[i]);
推荐阅读:
- 基础
- 常用字符串函数详解
- 字符串函数与内存函数
14预处理器
一 预处理器的工作原理
预处理器的行为是由预处理指令(由 #字符开头的一些命令)控制的。
如图说明了预处理器在编译过程中的作用。

为了展示预处理器的作用,我们写一个 c 程序(.c 文件),我们来看一下预处理后的文件(. i 文件):
VS 查看预处理后的文件方法
链接:https://blog.csdn.net/weixin_33708432/article/details/85824803
我们写一个程序:
test.c
// Converts a Fahrenheit temperature to Celsius
#include打开生成的 .i 文件(我的在 Debug 目录中),拉到结尾,看到下面的代码:
test.i文件部分代码:
空行
空行
从 stdio 中引入的行
空行
空行
空行
空行
空行
int main(void) {
float fahrenheit, celsius;
printf("Enter Fahrenheit temperature: ");
scanf("%f", &fahrenheit);
celsius = (fahrenheit - 32.0f) * (5.0f / 9.0f); // 宏已经被替换
printf("Celsius equivalent is %.1f\n", celsius);
return 0;
}
我们可以发现,预处理器做了这些事情:
- 预处理器通过引入 stdio.h 的内容来响应 #define 指令,然后删除该指令
- 替换了该文件中稍后出现在任何位置上的 FREEZING_PT 和 SCALE_FACTOR
- 请注意预处理器并没有删除包含指令的行,而是简单地将它们替换为空
- 每一处注释都替换为一个空格字符
- 有一些预处理器还会删除不必要的空白字符,包括每一行开始用于缩进的空格符和制表符
在 C 语言较为早期的时期,预处理器是一个单独的程序,它的输出提供给编译器。如今,预处理器通常和编译器集成在一起。
二 预处理指令
- 宏定义:
#define指令为一个宏。#undef指令删除一个宏定义。 - 文件包含:
#include指令导致一个指定文件的内容被包含到程序中。 - 条件编译:
#if,#ifdef,#ifndef,#elif,#else和#endif指令可以根据预处理器可以测试的条件来确定是将一段文本块包含到程序中还是将其排除在程序之外。 - 剩下的:
#error,#line,#pragma指令是更特殊的指令,较少用到。
其中,文件包含指令会放到下一章节中介绍。
适用于所有指令的规则:
-
指令都以
#开始 -
在指令的各部分之间可以插入任意数量的空格或水平制表符
# define A 1 -
指令总在第一个换行符处结束,除非明确地指明要延续
#define ADD (A + \ B) -
指令可以出现在程序中的任何地方 但我们通常放在程序的开始
-
注释可以和指令放在同一行 事实上,这样做是个好习惯:
#define FREEZING_PT 32.0f // freezing point of water
三 宏定义
1. 简单的宏
简单的宏(C 标准中称为对象式宏)
#define 标识符 替换列表
替换列表可以包含标识符,关键字,数值常量,字符常量,字符串字面量,操作符和排列。
在宏后面的程序内容中,预处理器会用替换列表替换标识符
注意:
不要在宏定义中放置任何额外的符号,否则它们会被作为替换列表的一部分。
宏定义中使用 =
#define N = 100 // wrong
int a[N]; // becomes int a[= 100];
结尾使用分号;
#define N 100; // wrong
int a[N] // becomes 100;
编译器可以检测到宏定义中绝大多数由多余符号所导致的错误。但是,编译器只会讲每一个使用这个宏的地方标为错误,而不会直接找到错误的根源——宏定义本身,因为宏定义已经被预处理器删除了。
简单的宏主要用来定义那些被 K,R 称为“明示常量”(manifest constant)的东西。比如:
#define STR_LEN 80
#define TRUE 1
#define PI 3.14159
#define CR '\r'
#define EOS '\0'
#define MEM_ERR "Error: not enough money"
使用#define来为常量命名由许多显著的优点:
-
程序会更加易读 帮助读者理解常量的含义,减少“魔法数”。
-
程序会易于修改
-
可以避免前后不一致或键盘输入错误
-
对 C 语法做小的修改 比如:
#define BEGIN { #define END } #define LOOP for(;;)当然这样的做法可能会让别人难以阅读你的程序。
-
对类型重命名
#define BOOL int但是要知道,类型定义仍然是定义新类型的最佳方法。
-
控制条件编译
注意:
-
宏定义中的替换列表为空是合法的
#define DEBUG -
当宏作为常量使用时,C 程序员习惯在名字中只使用大写字母。
2. 带参数的宏
带参数的宏(也称为函数式宏)
#define 标识符(x1, x2,...,xn) 替换列表
比如:
#define MAX(x, y) ((x) > (y) ? (x) : (y))
#define IS_EVEN(n) ((n) % 2 == 0)
如果程序中有如下语句:
max = MAX(a, b);
if(IS_EVEN(i))
i++;
预处理器会将这些行替换为:
max = ((a) > (b) ? (a) : (b));
if(((i) % 2 == 0))
i++;
如这个例子所示,带参数的宏经常用来作为简单的函数使用。
ctype.h 头文件中的 toupper 的一种实现:
#define TOUPPER(c) ('a' <= (c) && (c) <= 'z' ? (c) - 'a' + 'A' : (c))
带参数的宏也可以包含空的参数列表:
#define getchar() getc(stdin)
使用带参数的宏替代函数有两个优点:
- 程序可能稍微快一些
- 宏更为通用 与函数不同,宏的参数没有类型。
但是带参的宏也有一些缺点:
-
编译后的代码通常会变大
比如用 MAX 宏来找出三个数中的最大值:
max = MAX(i, MAX(j, k));下面是预处理后的语句:
max = ((i) > (((j) > (k) ? (j) : (k))) ? (i) : (((j) > (k) ? (j) : (k)))) -
宏参数没有类型检查 预处理器不会检查参数类型,也不会进行类型转换。
-
无法用指针指向宏 C 语言允许指针指向函数。因为宏在预处理过程中被删除,所以不存在指向宏的指针。
-
宏可能不止一次地计算它的参数。 函数对它的参数只会计算一次,宏可能会计算多次。
max = MAX(i++, j);预处理后:
max = ((i++) > (j) ? (i++) : (j));如果 i 大于 j ,那么 i 可能会被(错误的)增加两次,同时 n 可能被赋予错误的值。
所以说,最好避免使用自增自减的参数
宏定义还可用于需要重复书写的代码段模式:
#define PRINT_INT(i) printf("%d\n", i)
PRINT_INT(i / j); // becomes printf("%d", i / j);
3. 宏的通用属性
-
宏的替换列表可以包含对其他宏的调用
#define PI 3.1415926 #define TWO_PI (2 * PI) -
预处理器只会替换完整的记号,而不会替换记号的片段
#define SIZE 256 int BUFFER_SIZE; if(BUFFER_SIZE > SIZE) puts("Error: SIZE exceeded");预处理后:
#define SIZE 256 int BUFFER_SIZE; if(BUFFER_SIZE > 256) puts("Error: SIZE exceeded");标识符
BUFFER_SIZE和字符串字面量中的 SIZE 不会被替换 -
宏定义的作用范围通常到出现这个宏的文件末尾 由于宏是预处理器处理的,他不遵从通常的作用域规则。
-
宏不可以被定义两遍,除非新的定义与旧的定义是一样的
-
宏可以使用
#undef指令“取消定义”#undef 标识符比如:
#undef N会删除宏 N 当前的定义。(如果 N 没有被定义成为一个宏,#undef 指令没有任何作用。)#undef 指令的一个用途是取消宏的现有定义,以便重新给出新的定义。
15编写大型程序
整理在思维导图中
16结构&联合&枚举
一 结构变量
前面我们说过数组有两个重要特性:
- 数组所有的元素具有相同的数据类型
- 选择数组元素需要指明元素的位置(下标)
结构和数组有很大不同。结构的元素(C 语言中的说法是成员)可以具有不同类型。而且每个结构成员都有名字,访问结构体成员需要指明结构成员的名字而不是位置。
在一些编程语言中,经常把结构体称为记录(record),把结构体的成员称为字段(field)。
0. 结构变量的声明
假如需要记录存储在仓库中的零件。我们可能需要记录零件的编号,名称和数量。我们可以使用结构体:
struct{
int number;
char name[NAME_LEN + 1];
int on_hand;
}part1, part2;
struct{...}指明类型,part1,part2是这种类型的变量。
结构体在内存中是按照声明顺序存储的。
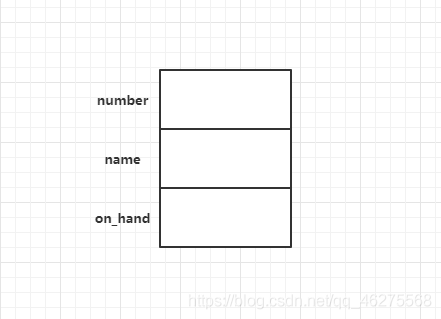
至于细化到字节,结构体是否也是紧挨着存储的,这里我们可以留个悬念,大家自行猜测一下。(如果你想了解,可以参考文章:https://mp.weixin.qq.com/s/uG1ZNWbmXAYPL4Rs4uqoKQ)
1. 结构变量的初始化
我们可以在定义结构体的同时初始化:
struct{
int number;
char name[NAME_LEN + 1];
int on_hand;
}part1 = {528, "Disk drive", 10}
part2 = {914, "Printer cable", 5};
初始化式中的值必须按照结构体成员的顺序进行显示。
结构初始化式遵循的原则类似于数组的。初始化式必须是常量(C99 中允许使用变量)。初始化式中的成员可以少于它所初始化的结构,“剩余的”成员用 0 作为初始值。特别的,剩余的字符串应为空字符串。
2. 指定初始化(C99)
特性和数组一样,比如:
struct {
int number;
char name[NAME_LEN + 1];
int on_hand;
}part1 = {.name = "Disk", 123};
number 被默认为 0,.name 直接跳过 number 初始化 name,123 初始化的成员为 .name 后一个成员。
3. 对结构的操作
访问成员方式如下:
printf("Part number: %d\n", part1.number);
printf("Part name: %s\n", part1.name);
printf("Quantity on hand: %d\n", part.on_hand);
结构的成员是左值,所以可以出现在赋值运算的左侧:
part1.number = 258;
part1.on_hand++;
.其实就是一个 C 语言的运算符。.运算符的优先级几乎高于所有其他运算符,所以思考:
scanf("%d", &part1.on_hand);
&计算的是 part1.on_hand的地址
赋值运算:
part1 = part2;
等价于:
part1.number = part2.number;
strcpy(part1.name, part2.name);
part1.on_hand = part2.on_hand;
如果这个结构内含有数组,数组也会被复制。
但是不能使用 == 和 != 运算符判定两个结构是否相等。
二 结构类型
如果我们要在程序的不同位置声明变量,我们就需要定义表示一种结构类型的名字。
试思考:
struct{
int number;
char name[NAME_LEN + 1];
int on_hand;
}part1;
在程序的某处,为了描述一个零件,我们写了上面的代码。但是,现在在程序的另一处有需要一个零件,直接增加一个变量:
struct{
int number;
char name[NAME_LEN + 1];
int on_hand;
}part1, part2;
这种方式固然可行,但是有些“呆”。
那么,如果我们再次定义一个相同的“零件类型”:
struct{
int number;
char name[NAME_LEN + 1];
int on_hand;
}part2;
请注意:part1 和 part2 具有不同的类型
0. 结构标记的声明
结构标记(struct tag)用来标识某一种特定的结构名称。下面的例子声明了名为 part 的结构类型:
struct part{
int number;
char name[NAME_LEN + 1];
int on_hand;
};
注意:花括号后的分号不可少
如果忽略了分号,可能回得到含义模糊的出错信息,比如:
struct part{
int number;
char name[NAME_LEN + 1];
int on_hand;
}
f(){
...
return 0;
}
由于前面的结构声明没有正常终止,所以编译器会假设函数 f 返回值是 struct part 类型的,所以直到 f 中的第一条 return 语句才会发现错误。
声明变量:
struct part part1, part2;
注意:不能省略 struct
也因为结构标记只有在 part 前放置 struct 才有意义,所以声明名为 part 的变量是完全合法的。(但是容易混淆)
声明结构标记和结构变量可以放在一起:
struct part{
int number;
char name[NAME_LEN + 1];
int on_hand;
}part1, part2;
所有声明为 struct part类型的结构彼此兼容。
1. 结构类型的定义
使用 typedef定义名为 part 的结构类型:
typedef struct {
int number;
char name[NAME_LEN + 1];
int on_hand;
}part;
如此,我们就可以像上面那样声明结构变量:
part part1, part2;
因为类型名为 part 所以书写 struct part 是不合法的。
如果你也想可以使用 struct part,那你可以这样声明:
typedef struct part{
int number;
char name[NAME_LEN + 1];
int on_hand;
}part;
2. 结构作为参数和返回值
结构作为参数
函数:
void print_part(struct part p){
printf("Part number: %d\n", p.number);
printf("Part name: %s\n", p.name);
printf("Quantity on hand: %d\n", p.on_hand);
}
调用方式:
print_part(part1);
结构作为返回值
函数:
struct part build_part(int number, const char* name, int on_hand){
struct part p;
p.number = number;
strcpy(p.name, name);
p.on_hand = on_hand;
return p;
}
调用方式:
part1 = build_part(527, "Disk", 10);
给函数传递结构和从函数返回结构都需要生成结构所有成员的副本,这回可能会产生一定数量的系统开销。为了避免这种开销,常传递或返回指向结构的指针来代替传递或返回结构本身。下一节中,我们将会看到这样的应用。
3. 复合字面量(C99)
略。
三 嵌套的结构和结构数组
0. 嵌套的结构
把一种结构嵌套在另一种结构中经常是非常有用的。比如:
定义一个结构存储一个人的姓名:
struct person_name{
char first[FRIST_NAME_LEN + 1];
char last[LAST_NAME_LEN + 1];
};
定义一个结构存储学生信息:
struct student{
struct person_name name;
int ID, age;
char gender;
}student1;
访问 student1 的名和姓需要应用两次.:
strcpy(student1.name.first, "Fred");
1. 结构数组
声明一个数组用来存储 100 个零件信息:
struct part Part[100];
访问零件数组中下标为 i 的元素的结构成员:
Part[i].number = 883;
使存储在零件数组中下标为 i 的元素的姓名变为空字符串,可以写成:
Part[i].name[0] = '\0';
2. 结构数组的初始化
初始化结构数组与初始化多维数组的方法非常相似。比如:
struct person_name{
char first[FRIST_NAME_LEN + 1];
char last[LAST_NAME_LEN + 1];
}name[] = { {"San", "Zhang"}, {"Si", "Li"} };
与数组一样,指定初始化(C99)也适用于这种情况。
四 联合
像结构一样,联合(union)也是由一个或多个成员构成,而且这些成员可以具有不同的类型。但是,编译器只为联合中最大的成员分配足够的空间。联合的成员在这个空间内彼此覆盖,给一个成员赋予新值也会改变其他成员的值。
union {
double d;
int i;
}u;
struct {
double d;
int i;
}s;
结构变量 s 和 联合变量 u 只有一处不同:s 的成员存储在不同的内存地址中;u 的成员存储在同一内存地址中。如图:

u.i = 3;
u.d = 1.0;
如果把一个值存储到u.d中,那么先前存储在 u.i中的值会丢失。类似的,改变 u.i也会影响u.d。
联合的性质几乎和结构一样。
联合的初始化方式和结构也很相似,但是,只有联合的第一个成员可以获得初始值。例如,如下初始化方式可以使得联合 u 的成员 i 的值为 0:
union {
double d;
int i;
}u = {0};
注意:花括号是必需的。
指定初始化(C99):
union {
double d;
int i;
}u = {.i = 3};
只能初始化一个成员,不一定是第一个。
五 枚举
C 语言为具有可能值较少的变量提供了一种专用类型 —— 枚举类型(enumeration type)
定义扑克花色:
enum{
CLUBS,
DIAMONDS,
HEARTS,
SPADES,
}s1;
CLUBS 的值为 0,DIAMAND 值为 1,后面的每个增加 1 ,以此类推。
如果没有枚举类型,我们需要一个个的来 #define
#define CLUBS 0
#define DIAMANDS 1
#define HEARTS 2
#define SPADES 3
这样无疑会增加程序的复杂度,也会降低同种情况的联系,让程序变得难以阅读。
0. 枚举类型声明
1)
enum suit{
CLUBS,
DIAMONDS,
HEARTS,
SPADES,
};
enum suit s1, s2;
2)
typedef enum{
CLUBS,
DIAMONDS,
HEARTS,
SPADES,
}Suit;
Suit s1, s2;
C89 中,使用枚举创建布尔类型:
typedef enum{TRUE, FALSE}Bool;
如果要使用枚举变量:
Suit suit = CLUBS;
Bool flag = TRUE;
枚举类型的变量可以赋值为任意枚举列出来的枚举常量。但是枚举常量可以赋值给普通整型变量,普通整型变量也可以赋值给枚举类型的变量。这是因为 C 语言对于枚举和整数的使用比较混乱,没有明确界限。
1. 枚举作为整数
在系统内部,C 语言会把枚举变量和常量作为整数来处理。默认情况下,编译器将 0,1,… 赋值给枚举常量。
我们可以为枚举常量自由选择不同的值。现在假设希望用 1 到 4 代表牌的花色,我们可以这样定义:
enum suit{
CLUBS = 1,
DIAMONDS = 2,
HEARTS = 3,
SPADES = 4,
};
我们知道后一个枚举常量比前一个大 1,所以,我们也可以简化为:
enum suit{
CLUBS = 1,
DIAMONDS,
HEARTS,
SPADES,
};
也可以换为任意整数:
enum suit{
CLUBS = 10,
DIAMONDS = 20,
HEARTS = 15,
SPADES = 40,
};
推荐阅读:
- 初探
- 内存对齐
17 指针的高级应用
一 动态存储分配
C 语言的数据结构通常是固定大小的。例如,一旦程序完成编译,数组元素的数组就固定了。(C99 中,变长数组的长度在运行时确定,但是数组的声明周期内仍然是固定长度的。)因为在编写程序时强制选择了大小,在不修改程序并且再次编译程序的情况下无法改变数据结构的大小。
为了扩大数据结构(前面我们通常用到的是数组)的大小,可以增加数组大小并重新编译程序。但是,无论如何增大数组,始终有可能填满数组。幸运的是,C 语言支持动态存储分配,即在程序执行期间分配内存单元的能力。利用动态存储分配,可以设计出根据需要扩大(和缩小)的数据结构。
0. 内存分配函数
为了动态地分配存储空间,需要调用三种内存分配函数的一种,这些函数都是声明在头
malloc函数 —— 分配内存块,但是不对内存块进行初始化calloc函数 —— 分配内存块,并对内存块进行清零realloc函数 —— 调整先前分配的内存块的大小
这三种函数中,malloc函数是最常用的。因为 malloc 不需要对分配的内存块进行清零,所以它比 calloc 函数效率更高。
当为申请内存块而调用内存分配函数时,由于函数无法知道计划存储在内存块中的数据是什么类型的,所以它不能返回 int 类型,char类型等普通类型的指针。取而代之的是,函数返回void*类型的值。void*类型的值是“通用”指针,本质上它只是内存地址。
1. 空指针
当调用内存分配函数中时,总存在这样的可能性:找不到满足我们需要的足够大的内存块。如果真的发生了这类问题,函数会返回空指针(null pointer)。空指针是“不指向任何地方的指针”,这是一个区别于所有有效指针的特殊值。
**注意:试图通过空指针访问内存的效果是未定义的,程序可能出现崩溃或者出现不可预测的行为。**因此,在把内存分配函数的返回值存储到指针变量中以后,需要判断该指针变量是否为空指针。
空指针用名为 NULL 的宏来表示,所以可以使用下列方式测试 malloc 函数的返回值:
p = malloc(10000);
if(p == NULL){
// allocation failed; take approriate action
}
一些程序员把 malloc 函数的调用和 NULL 的测试组合起来:
if((p == malloc(10000)) == NULL){
// allocation failed; take approriate action
}
名为 NULL的宏在 6 个头
语句:
if(p == NULL) ...
可以写成:
if(!p) ...
而语句:
if(p != NULL) ...
可以写成:
if(p) ...
二 动态分配字符串
0. 使用 malloc 函数为字符串分配内存
malloc函数具有如下原型:
void* malloc(size_t size);
size_t是 C 语言库定义的无符号整数类型,除非分配的空间巨大,否则可以用 int型。
为长度为 n 的字符串分配内存空间:
char* p = malloc(n + 1);
n + 1为空字符留出空间。执行赋值操作时会把 malloc 函数返回的通用指针转化为char*类型,而不需要强制类型转换。然后,一般我们都会进行强制类型转换:
p = (char*)malloc(n + 1);
注意:为字符串分配内存空间时,不要忘记包含空字符的空间

1. 在字符串函数中使用动态存储分配
我们自行编写一个函数将两个字符串连接起来而不改变其中任何一个字符串。先调用 malloc 分配适当大小的内存空间。接下来函数把第一个字符串复制到新的内存空间中,然后调用 strcat函数来拼接第二个字符串:
char* concat(const char* s1, const char* s2){
char* ret = (char*)malloc(strlen(s1) + strlen(s2) + 1);
if(ret == NULL){
printf("Error:malloc failed in concat.\n");
exit(EXIT_FAILURE);
}
strcpy(ret, s1);
strcat(ret, s2);
return ret;
}
如果 malloc 函数返回 NULL,函数显示出错信息并终止程序。这并不是正确的措施。
下面时可能的 concat 函数调用方式:
p = concat("abc", "def");
这个调用后,p 将指向字符串"abcdef",此字符串存储在动态内存分配的数组中。数组包含结尾的空字符一共 7 个字符长。
注意:注意最后调用 free 函数释放申请的空间
三 动态分配数组
当编写程序时,常常很难为数组估计合适的大小。前面我们是用宏来定义数组的大小;现在我们可以在程序执行期间为数组动态分配内存空间。
0. 使用 malloc 函数为数组分配存储空间
分配一个int[n]大小的数组:
int* a = (int*)malloc(sizeof(int) * n);
对 a 指向的数组进行初始化:
for(i = 0; i < n; i++)
a[i] = 0;
1. calloc 函数
函数原型:
void* calloc(size_t nmemb, size_t size);
下面 calloc 函数调用为 n 个整数的数组分配存储空间,并且初始化所有整数为 0:
a = calloc(n, sizeof(int));
调用以 1 作为第一个实参的 calloc 函数,可以为任何类型的数据分配空间:
struct point {int x, y}*p;
p = calloc(1, sizeof(struct point));
执行完此语句后,p 将指向一个结构,且此结构的成员 x 和 y 都会被设为 0 。
2. realloc 函数
一旦为数组分配完内存,稍后可能会发现数组过大或过小。realloc 函数可以调整数组的大小使它更适合需要。
函数原型
void* realloc(void* ptr, size_t size);
当调用realloc函数时,ptr 必须指向先前通过 malloc,calloc 或 realloc 的调用获得的内存块。size 表示内存块的新尺寸,新尺寸可能大于或小于原有尺寸。
注意:要确定传递给 realloc 函数的指针来自于先前 malloc,calloc 或 realloc 的调用。如果不是这样的指针,程序可能会行为异常
C 标准列出了几条关于 realloc 函数的规则:
- 当扩展内存块时,realloc 不会对添加进内存块的字节进行初始化
- 如果 realloc 函数不能按要求扩大内存块,那么它会返回空指针,并且原有的内存块中的数据不会发生改变
- 如果 realloc 函数调用时以空指针作为第一个参数,那么它的行为就像 malloc 函数一样
- 如果 realloc 函数被调用时以 0 作为第二个实参,那么它会释放掉内存块
如果无法扩大内存块(因为内存块后面的字节已经用于其他目的),realloc 函数会在别处分配新的内存块,然后把旧块中的内容复制到新块中。
注意:一旦 realloc 函数返回,请一定要对指向内存块的所有指针进行更新,因为 realloc 函数可能会使内存块移动到了其他地方。
四 释放存储空间
动态存储分配函数所获得的内存都来自一个称为堆(heap)的存储池。过于频繁地调用这些函数(或者让这些函数申请大内存块)可能会耗尽堆,这回导致函数返回空指针。
更糟的是,程序可能分配了内存块,然后又丢失了对这些块的记录,因而浪费了空间。请思考下例:
p = malloc(...);
q = malloc(...);
p = q;
如图:

因为没有指针指向第一个内存块,所以再也不能使用此块内存了。
对于程序而言,不可再访问到的内存称为垃圾(garbage)。留有垃圾的程序存在内存泄漏(memory leak)现象。一些语言提供垃圾收集器(garbage collector)用于垃圾的自动定位和回收,但是 C 语言不提供。所以我们使用 free函数来释放不需要的内存。
0. free函数
函数原型:
void* free(void* ptr);
使用 free 函数很简单,将指向不再需要的内存块的指针传递给 free 函数即可:
p = malloc(...);
q = malloc(...);
free(p);
p = q;
调用 free 函数会释放 p 指向的内存块。然后此内存块可以被后续的 malloc 函数或其他内存分配函数的调用重新使用。
注意:
- free 函数实参必须是先前由内存分配函数返回的指针,如果参数是指向其他对象的指针,可能会导致未定义行为。
- 实参可以空指针,此时 free 调用不起作用
1. “悬空指针”问题
虽然 free 函数允许收回不再需要的内存,但会导致一个新的问题:悬空指针(dangling pointer)。调用 free(p)函数会释放 p 指向的内存块,但是不会改变 p 本身。如果忘记了 p 不再指向有效内存块:
char* p = malloc(4);
...
free(p);
...
strcpy(p, "abc"); // wrong
修改 p 指向的内存是严重的错误,因为程序不再对此内存由任何控制权了。
注意:试图访问或修改释放掉的内存块会导致未定义行为。
五 链表
链表这部分请参考【数据结构轻松学】部分。
数据结构代码练习开源项目:https://github.com/hairrrrr/Data-Structure
不要忘记 star ~
推荐阅读:
- 初识 malloc
- 动态内存管理
18声明
整理在思维导图中
19程序设计
整理在思维导图中
20底层程序设计
整理在思维导图中
21 输入&输出
整理在思维导图中
推荐阅读:
- 初识文件
补充:
24运算符
推荐阅读:
- 运算符
C 语言所有知识点总结思维导图下载链接:
链接:https://pan.baidu.com/s/1DnPq5-4oTg7EfhL7LeFDaA
提取码:emei
C 语言每个知识点的所有代码练习在 github 开源项目上,地址:
https://github.com/hairrrrr/C-CrashCourse
推荐阅读:
- C 语言就这?整理学好 C 语言必看的网站书籍和视频
- 写博客原来对程序员这么有用!手把手教你应该如何写博客
3 万 5000 字长文肝了很久,如果对你有帮助给我 点个赞 吧~
上面的内容还会更新,有什么问题欢迎在评论区和我交流。