云智慧 AIOps 社区是由云智慧发起,针对运维业务场景,提供算法、算力、数据集整体的服务体系及智能运维业务场景的解决方案交流社区。该社区致力于传播 AIOps 技术,旨在与各行业客户、用户、研究者和开发者们共同解决智能运维行业技术难题,推动 AIOps 技术在企业中落地,建设健康共赢的AIOps 开发者生态。
日志模式解析是将日志从半结构化数据解析为结构化数据的一种算法,可以帮助我们快速了解大量日志的概貌,在日志的自动化分析过程中,常作为中间步骤,服务于日志后续的异常检测等任务。本技术黑板报中,我们将围绕三个问题来详细讲解日志模式解析:日志模式解析是什么,为什么要做日志模式解析,如何实现日志模式解析。
一、日志模式解析是什么:
我们可以用下面这张图来理解日志模式解析所做的工作:

首先需要明确的是,日志是一种半结构化数据,他是由特定的代码生成的。如上图中,日志消息:2015-10-18 18:05:29,570 INFO dfs.DataNode$PacketResponder: Received block blk_-562725280853087685 of size 67108864 from /10.251.91.84。就是由代码LOG.info("Received block " + block + " of size " + block.getNumBytes() + " from " + inAddr);生成。日志模式解析的目的就是将日志解析成如上图所示的结构化数据的形式,即从日志中提取出时间戳、等级、组件、日志模板和参数信息。日志的时间戳、等级、组件这三个信息通过简单的正则就可以非常容易获得,所以日志模式解析算法真正关注的是日志模板及参数的提取。
什么是日志模板和参数呢?稍微有一点代码知识,我们都能知道代码LOG.info("Received block " + block + " of size " + block.getNumBytes() + " from " + inAddr)打印出的日志中,都会出现文本:Received block 、of size 、from,这些文本我们称为常量,而由于每次打印日志时系统状态的不同,每条日志打印出的block、block.getNumBytes()、inAddr可能不同,这些文本我们称为参数。我们将日志中的常量保留,参数用特定符号<*>代替,这样所生成的文本就是日志的模板。
日志模式解析过程可以理解为是一个倒推日志打印代码的过程,也是一个对日志聚类的过程(相同模板的日志认为是同一类日志)。不同文章对日志模式解析有不同的称呼,日志模板挖掘、日志模式发现、日志模式识别、日志聚类等,其实指的都是日志模式解析。
二、为什么要做日志模式解析:
日志模式解析是现在很多日志产品中都有的一个功能,为什么大家都要做日志模式解析这件事呢?首先,日志模式解析可以帮助我们快速了解日志概貌,在如今的计算机系统中,日志数量往往非常庞大,一个系统一天内可能就会产生上百万条日志,人眼直接观测显然不现实,但通过日志模式解析,我们可以将上百万条日志压缩成几百个模板,这样就可以达到人眼可看的目的(如下图)。

其次,模式解析常常是自动化分析过程的中间步骤,服务与后续异常检测等任务,因为模式解析后的结果是更易于分析的。比如,我们可以通过对某种模式的日志的打印时间进行分析,获得模式的周期性,将不符合周期的点认为是异常;又比如,我们可以通过分析得到模式之间的出现顺序关系,如若当我们发现模式2总是会跟在模式1后面出现,如果突然发现在某个时间,模式2单独出现了,这大概率也是一个异常;此外,对某种模式参数的占比进行分析,也能判断异常。

三、如何实现日志模式解析:
本技术黑板报一共调研了13种经典日志解析算法,其中大部分出自于综述《Tools and Benchmarks for Automated Log Parsing》中。本技术黑板报中,根据算法的原理,将这些算法分为三类:基于聚类的日志模式解析算法、基于频繁项挖掘的日志模式解析算法、基于启发的日志模式解析算法。下图为本技术黑板报中设计到的算法及其分类:

被同一条代码打印出来的日志肯定是相似的,所以我们可以得到第一种模式解析的思路,给出文本相似度公式或距离公式,通过聚类算法,将相同模式的日志聚到一起,然后再获取日志模板,即基于聚类的日志模式解析算法,如Drain、Spell(LCS也可以认为是一种文本相似度)、Lenma、Logmine、SHISO等。
而因为代码在打印日志的时候,常量在所有打印出来的日志中都会出现,参数则在日志中可能大不相同,所以我们认为,常量在日志中出现的频率较高,参数在日志中出现的频率较低,换言之,出现频率较高的为常量,出现频率较低的为参数,通过这个性质,我们可以得到第二种模式解析的思路,即基于频繁项挖掘的日志模式解析算法,如SLCT、Logram、FT-Tree。
此外,某些算法中包含对日志的一些启发性假设,比如相同长度的日志才有可能是同一类日志、前几个单词相同的日志才有可能是同一类日志,这些假设也能用于模式解析中。某些聚类算法也有可能含有一些启发性假设,但可以通过算法是否使用了相似度来分辨基于聚类的日志模式解析算法与基于启发的日志模式解析算法。
整体来说,这三类方法,都可以抽象为以下流程,其中,少部分方法中会涉及到模式融合流程,大部分方法只有预处理、聚类、模板获得过程,而模板获得常常与聚类过程融合,部分算法甚至先获得模板,然后将相同模板的日志聚在一起,所以本技术黑板报将这两个流程合在聚类流程中介绍。

1、预处理:
不管是基于聚类的日志模式解析算法、基于频繁项挖掘的日志模式解析算法还是基于启发的日志模式解析算法,在对日志进行解析前,都会先进行分词,因为词是表达完整含义的最小单位。除了分词之外,Drain、DAGDrain、POP、LogMine、LkE均提到要进行类型识别,即通过正则匹配,将一些特殊词,如IP地址、时间等给识别出来,然后替换为特殊字符或去掉,这是由于这些特殊词明显是参数,如此处理可以有效提高相同模式日志的相似度。AEL则提出要识别key-value对,并将value替换成特殊字段,也是类似的考量。此外,Logram提出,在进行解析之前,需要将日志的header给去除(即日志的时间戳、等级、组件信息)。而Lenma、SHISO算法,是基于日志提取的特征向量计算相似度的,而不是基于分词后的日志单词列表,所以这俩算法预处理时会多特征提取这一步骤。
2、聚类:
本节将根据解析算法的类别来对聚类方法进行说明。
(1). 基于聚类的日志模式解析:
a. 相似度
基于聚类的日志模式解析,都会通过文本相似度或距离公式,判断日志是否属于某一模式。有些算法在计算文本相似度时,直接通过单词列表计算相似度,如Drain、DAGDrain等;而有些算法,则是先通过单词列表提取特征,然后计算特征的相似度,如Lenma、SHISO。有些算法使用的文本相似度公式要求输入等长,而有些算法则不需要。

从上表中可以看到,大部分算法使用的文本相似度公式中,都是要求输入要等长的,这是由于这些算法都有假定,同一模式的日志长度相同,这一假定可以有效减少相似度计算的次数,降低相似度计算的难度,但也存在一定的局限性。
Drain和DAGDrain使用的相似度公式相同,都为:

公式翻译下来,就是两条日志从左往右,一个一个单词看,相不相同,统计相同单词的数量,除以日志长度就得到相似度了,如日志[Node,001,is,unconnected]与日志[Node,002,is,unconnected],Node、is、unconneted三个单词相同,且位置一致,所以两条日志的相似度为3/4。
LogMine使用的距离公式为:

这个距离公式与Drain使用的相似度公式非常相似,不过他允许两条日志不等长,也允许手动设置单词相同时的分数。公式翻译下来,也是两条日志从左往右,一个一个单词看相不相同,直到更短的日志看到了结尾就不看了,统计相同单词的数量,除以更大的日志长度得到相似度。如,若k1=1,日志[Node,001,is,unconnected]与日志[Node,002,is, unconnected,too],Node、is、unconneted三个单词相同,且位置一致,所以两条日志的相似度为3/5。但是这个距离公式同样有局限性,若日志位置出现了一点偏移,那么相同模式的日志计算出的相似度也会非常低,如日志[Node,001,is,unconnected]与日志[Node,002,003,is,unconnected]。虽然日志都包含单词Node、is、unconneted,属于同一模式,但is、unconneted在两条日志中的位置不同,所以两条日志的相似度算下来只有1/5。
Spell中,则通过LCS(最大公共子序列)来判断相似度:

LCS是计算机科学中的一个经典问题,不了解的同学可以自行百度一下,Spell通过LCS判断相似度的方式突破了长度的局限性,但是也带来了效率的问题,因为精确解决LCS问题的算法需要O(mn) (m,n为seq1、seq2长度) 的时间复杂度。
LKE使用的距离为文本的编辑距离,及计算将seq1转化为seq2,所需要操作(增、删、改)的最小单词数量。此外,LKE提出,在计算距离时,要考虑到操作的单词的位置,操作的单词越靠前,两条文本的距离越大。因此,文章提出了加权的编辑距离:
![]()
编辑距离同样突破了长度的局限性,但时间复杂度仍然是一个痛点。
Lenma计算相似度时,需要先根据日志消息,提取特征向量。Lenma使用的特征向量叫做词长度向量,提取的方式很简单,即记下日志每个单词的长度,然后将长度拼接在一块就可以了。如日志[Node,001,is,unconneted],其词长度向量为[4,3,2,10]。其相似度计算公式为词长度向量的余弦相似度:

先提取特征向量再计算相似度的优点在于,向量可以并行进行矩阵计算,在相似度计算这一模块计算效率会更高,但是提取特征,也意味着丢失信息。
SHISO的所使用的相似度公式为:

其中,C(W1[i])、C(W2[i])为根据单词W1[i]、W2[i]生成的特征向量。SHISO中考虑的特征向量有大写字母、小写字母、数字、及其他,则生成的向量为4维,每一维度分别是大写字母、小写字母、数字、及其他的个数。如单词Node,生成的特征向量为[1,3,0,0]。
b. 聚类逻辑:
有了相似度计算公式之后,就可以进行聚类了。一种最简单的聚类逻辑就是,将所有聚类簇存储下来,当有一条日志需要解析时,将该日志与所有聚类簇的聚类中心(聚类中心可能是单词列表,也可能是特征向量,由第一个进入该聚类簇的日志决定,并随着进入的日志而更新)一一计算相似度,找到相似度最大的聚类簇。若相似度满足阈值要求,则将待解析日志并入该聚类簇中,并更新聚类中心,若没有满足阈值要求的聚类簇,则将待解析日志作为聚类中心,创建新的聚类簇。Spell和Lenma用的都是这样的聚类逻辑。
这种聚类逻辑非常简单,但有一个问题,就是计算相似度的次数太多,有多少个聚类簇就要计算多少次相似度,计算效率低下。所以,更多的算法,在计算相似度之前,会先给日志进行分组,然后每个组内采用这样的聚类逻辑进行聚类。
如Drain算法,就采用了树结构的方式对日志进行分组。Drain的分组策略有两块:根据日志的长度分组以及根据日志的前几个单词分组。Drain的树深度可设,树深度决定了用前多少个单词进行分组。其分组策略如图所示,当有一条日志需要解析时,会根据该日志的长度及前几个单词依次向下搜索,直到叶子节点。叶子节点下存储着该组别中的聚类簇,搜索到叶子节点后再计算相似度,根据相似度计算结果更新聚类中心或者创建新的聚类簇。

DAGDrain算法与Drain算法类似,也采用了树结构进行分组,分组策略有两块:根据日志的长度分组及根据日志的首单词或尾单词分组。日志的长度容易理解,根据日志的首单词或尾单词分组的方式是:根据日志的首单词或者尾单词是否含有数字及特殊字符,提取出日志的首单词或者尾单词,并给其加上首单词或者尾单词的标志作为split_token,split_token一致的日志才会被分到同一组别当中。
AEL算法则会根据日志长度及key-value对的对数给日志进行分组,然后在组别下计算相似度进行聚类。
总结下来,提前分组的方式一共有四种:根据日志长度分组,根据日志前几个单词分组,根据日志的首单词或者尾单词分组,根据key-value对的对数分组,这四种方式其实都有其不足之处。根据日志长度分组受分词影响太大,不当的分词可能会使相同模式的日志有不同的长度,而且,对于某些参数占多个位置的日志,长度也会将其错误的分到不同组别中。如日志[Node,000,is,unconnected]与日志[Node,001,002,is,unconnected]。根据日志前几个单词分组在大部分时候是有用的,但有时参数也有可能在日志前列。根据日志的首单词或者尾单词分组的策略,若日志的header未去除,则大概率无法发挥其效果。根据key-value对的对数分组,则有可能受到正则匹配不当的影响。
除了提前分组之外,层次聚类也是提高解析效率的一个方法,如SHISO,SHISO也是一个树结构的解析算法,树的每个节点都对应一个聚类簇,算法要求每个节点的子节点个数都要小于阈值t。其算法流程为:遍历子节点,看是否存在相似度满足要求的聚类簇。若存在,则更新聚类中心;若不存在,且子节点个数小于阈值,则在该节点下插入新聚类簇;若不存在,且子节点个数等于阈值,则找到相似度最大的节点,在该节点下继续遍历子节点,一直迭代直到找到相似度满足要求的聚类簇。
Logmine中也提到可以用层次聚类算法,不过他的层次聚类目的却并不是提高效率,相反,可能还会降低一定的解析效率,但却给人工灵活处理解析等级提供了可能。Logmine也是采用的树结构进行聚类,其提出,在树的第一层,用非常小的距离阈值对日志进行聚类,形成聚类簇,这样,可以将日志分的足够细,避免不同模式的日志聚在一起,聚类簇的聚类中心为第一个进入该聚类簇的日志,且不更新。第二层开始,用更大的距离阈值,对上一层的聚类中心进行聚类,形成聚类中心的聚类簇,聚类中心为第一个进入聚类簇的数据,且随着新的数据进入而更新。
c. 自动阈值:
大部分基于聚类的解析算法,相似度阈值都是需要人工设置的,LKE和DAGDrain给出了两种自动阈值的思路。LKE提出可以通过k-means聚类获得相似度阈值,而DAGDrain则提出如下的自动阈值公式:
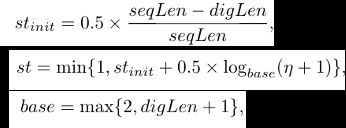
然而自动阈值的有效性还有待验证,在此就不再展开说明。
(2). 基于频繁项挖掘的日志模式解析:
基于频繁项挖掘的日志模式解析算法,在聚类前,要对频率进行统计(大部分是单词频率,Logram统计的是n-gram频率)。
SLCT是最早的日志模式解析算法,其原理较为简单,算法流程如下:如果某条日志中日志单词W(i)的出现频率大于阈值s,那么认为W(i)是一个频繁词,将该条日志的所有频繁词及其位置提取出来,作为聚类候选。如日志[Interface,eth0,down]中,若Interface,down的出现频率大于阈值,则该日志生成的聚类候选为{(Interface, 1) (down, 3)},聚类簇候选出现次数大于阈值则正式称为聚类簇。
Logram创新性的将n-gram引入到频繁项挖掘算法中。其在解析前,需要统计日志中所有的n-gram频率(n=1,2,……k, k为设置参数)。解析时,先获得日志的k-gram频率,将频率小于k-gram阈值的k-gram挑出来作为参数候选,然后,将挑选出来的k-gram分解为k-1-gram,再从其跳出k-1-gram的参数候选,直到2-gram。对于日志的任一单词,若其所有2-gram都在2-gram参数候选中,则该单词为参数,反之为常量。如日志[Node,000,is,unconnected]中,000的2-gram有Node->000,000->is,若Node->000,000->is都在2-gram参数候选中,则000为参数。将常量固定,参数转化为特殊符号<*>即可获得日志模式。
SLCT与Logram都是效率非常快的算法,但是他们均有一个问题:判断频繁词(或频繁n-gram)的阈值不好确定。而且,在现实中,存在这样一种情况:某些代码打印的次数非常少,但有些代码打印的次数非常多,这就意味着,那些打印次数少的代码生成的日志中,常量的频率也会很低,非常容易被认为是参数。所以,这两种算法不太推荐使用。
FT-tree也是一种基于频繁项挖掘的日志模式解析算法,采用了独创的FT-tree的数据结构进行解析。在解析前,该算法会遍历所有日志,然后获得日志中单词的出现频率,将单词根据其出现频率从大到小排序,形成列表L。解析日志时,对于待解析日志,会根据列表L对日志的单词进行排序,然后插入到FT-tree中(这样可以让频率高的单词更靠近根节点,频率低的单词更远离根节点),如图所示,直到所有日志都插入完成。那接下来FT-tree又是如何判断常量与参数的呢?
我们考虑对于同一代码打印出来的日志,如[Node,000,is,unconnected],[Node,001,is,unconnected],[Node,002,is,unconnected],将这些日志插入到FT-tree中后,越靠近根节点的单词肯定越有可能是常量,因为出现频率越高。而且,我们会发现,在靠近根节点时,树几乎没有分岔,但到某个节点后,子节点的个数将指数型上升,该节点正是常量与参数的分界线。通过这个思想实验,我们可以很自然的得到FT-tree接下来的操作——剪枝。这样一来,留在FT-tree中的节点代表的就都是常量了。含有相同常量的日志,FT-tree认为属于同一模式。
FT-tree结构巧妙,但也有可能存在一些问题,如有些参数可能是有限的,在FT-tree上不会造成那么大的分岔,可能也会留在FT-tree上,此外,不同模式之间,若含有共同的常量,在该常量下也有可能会造成分岔而导致子节点被剪枝,将多种模式分到一起。

(3). 基于启发的日志模式解析
本文调研的基于启发的日志模式解析算法只有两种,POP和IPLOM,但是其实,在基于聚类的日志模式解析算法中,也用到了很多启发式规则,如Drain、DAGDrain的分组策略。
POP中所用的启发式策略有两个:1、根据日志长度分组。2、根据单词位置分组。根据单词位置分组的思路与FT-tree的思路有些类似,都是基于认为参数会导致分岔过多而设计的。其步骤是:在组别内,统计每个位置上,该组别中一共有几种单词,找到单词种类最少但不为1的位置进行分组。如下图四条日志中,就可以选择位置1或位置2进行分组,因为位置1和位置2都只有2种单词,而位置3有4种。一直如此分,直到非1的最小单词种类数及单词种类数除以组内日志数的值都大于阈值。

IPLOM中用的启发式策略有三个:1、根据日志长度分组。2、根据单词位置分组。3、根据双射关系分组。其中,启发式策略3的原理同样是认为参数会导致分岔过多,在此不继续介绍。
3、模式融合:
DAGDrain算法及POP算法中,都提到在得到日志模式之后,可以将通过计算日志模式之间的相似度,将日志模式再次聚类进行融合。日志模式融合是一个高杠杆的操作,因为模式的融合需要聚类的数据量为模式数量,远小于日志数量,所以相对于日志聚类,模式融合花费的时间非常少,而其又可以起到改善聚类结果的作用。
DAGDrain中,采用的模式融合相似度为:
![]()
其中,lenNew为融合后的新模式的长度,lenExist为原有模式的长度,lenLCS为新模式与原有模式的最大公共子序列长度。
POP中,采用的模式融合距离公式为曼哈顿距离:

其中,N为两个文本所含有的公共单词,ai、bi分别值文本a、b中,第i个单词的数量。
四、小tip:
日志解析算法很多,而且通过刚才的介绍我们可以发现,上述算法中,很多步骤,都可以理解为是一个分组的过程,分组是互相不影响的过程,我们根据这个策略分组之后,在分完的组内,继续通过其他策略分组也是可以的。所以我们不妨大胆一些,有很多算法中的方法都是可以相互融合组成新算法的。比如说,在Drain算法的树结构中,是否可以加入按照key-value对个数分组的层呢?又比如说,是否可以将FT-tree的树结构,看做是一个分组的过程,分组之后,再根据相似度计算进行聚类呢?又比如说,Drain算法分完组后,是否可以再使用SHISO的层次聚类策略,避免Drain算法某个叶子节点下的模式过多影响效率呢?但是,在融合的过程,永远要注意效果,与效率。
写在最后
近年来,在AIOps领域快速发展的背景下,IT工具、平台能力、解决方案、AI场景及可用数据集的迫切需求在各行业迸发。基于此,云智慧在2021年8月发布了AIOps社区, 旨在树起一面开源旗帜,为各行业客户、用户、研究者和开发者们构建活跃的用户及开发者社区,共同贡献及解决行业难题、促进该领域技术发展。
社区先后 开源 了数据可视化编排平台-FlyFish、运维管理平台 OMP 、云服务管理平台-摩尔平台、 Hours 算法等产品。
可视化编排平台-FlyFish:
项目介绍:https://www.cloudwise.ai/flyF...
Github地址: https://github.com/CloudWise-...
Gitee地址: https://gitee.com/CloudWise/f...
行业案例:https://www.bilibili.com/vide...
部分大屏案例:

请您通过上方链接了解我们,添加小助手(xiaoyuerwie)备注:飞鱼。加入开发者交流群,可与业内大咖进行1V1交流!
也可通过小助手获取云智慧AIOps资讯,了解云智慧FlyFish最新进展!
