(大数据方向)分布式实验三:高可用搭建
注:本例中20192697-2~20192697-5为hadoop集群
这篇博客实在上一篇完全分布式的基础上进行的搭建,免除了克隆虚拟机等一些步骤详情请见
完全分布式
目录
一.免密钥
二. 配置文件
(1)core-site.xml
(2)hdfs-site.xml
(3)分发配置文件
三.安装zookeeper
(1)解压zookeeper
(2)配置zookeeper
(3)修改zoo.cfg文件
(4)分发节点
(5)Myid
(6)设置环境变量
(7)启动zookeeper
(8)启动journalnode(3个节点)
(9)格式化node02 (或 node03)
(10)注册两个namenode
(11)在20192697-2上启动
四.浏览器查看
一.免密钥
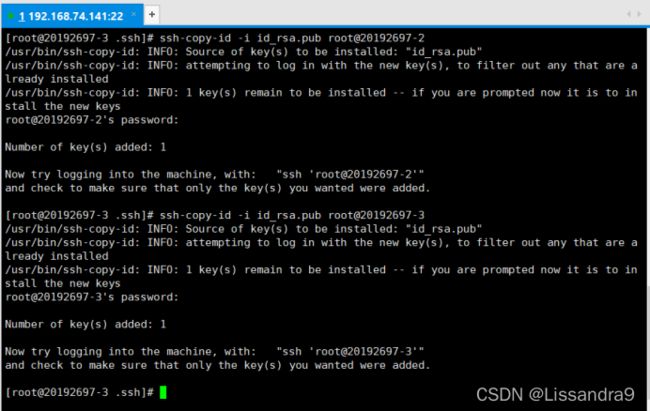
两个namenode节点互相免密钥(本例中20192697-2,和-3互相免密钥)
ssh-keygen -t rsa
//分别在20192697-2与-3中生成密钥
ssh localhost
//登陆localhost
cd /root/.ssh
//进入.ssh文件夹
ssh-copy-id -i id_rsa.pub root@20192697-3
//在-2中向-3传递密钥
ssh-copy-id -i id_rsa.pub root@20192697-2
//在-2中向-2自身传递密钥
二. 配置文件
(1)core-site.xml
fs.defaultFS
hdfs://20192697-2:9000
hadoop.tmp.dir
/etc/hadoop2/tmp
fs.defaultFS
hdfs://mycluster
hadoop.tmp.dir
/etc/hadoop2/ha
dfs.journalnode.edits.dir
/etc/hadoop2/ha/journalnode
ha.zookeeper.quorum
20192697-3:2181,20192697-4:2181,20192697-5:2181
(2)hdfs-site.xml
dfs.replication
2
dfs.namenode.secondary.http-address
20192697-2:50090
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
20192697-2:8020
dfs.namenode.rpc-address.mycluster.nn2
20192697-3:8020
dfs.namenode.http-address.mycluster.nn1
20192697-2:50070
dfs.namenode.http-address.mycluster.nn2
20192697-3:50070
dfs.namenode.shared.edits.dir
qjournal://20192697-2:8485;20192697-3:8485;20192697-4:8485/mycluster
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_dsa
dfs.ha.automatic-failover.enabled
true
(3)分发配置文件
scp -r hdfs-site.xml 20192697-3:/etc/hadoop2/hadoop/etc/hadoop
scp -r hdfs-site.xml 20192697-4:/etc/hadoop2/hadoop/etc/hadoop
scp -r hdfs-site.xml 20192697-5:/etc/hadoop2/hadoop/etc/hadoop
#跟自己的主机名,以及路径
#根据上面的方式同样传输core-site.xml文件
三.安装zookeeper
zookeeper-3.4.6.tar.gz
提取码:SY99
https://pan.baidu.com/s/1Uo2egxhGTl8wx2ZQF13_Sw
(1)解压zookeeper
#用xftp进行传输,解压之前先进入该文件传进linux后的位置
tar -zxvf zookeeper-3.4.6.tar.gz -C /etc/zook(2)配置zookeeper
#进入conf目录
cd /etc/zook/zookeeper-3.4.6/conf
#修改zoo.cfg文件
mv zoo_sample.cfg zoo.cfg
(3)修改zoo.cfg文件
dataDir=/etc/zook/data1
server.1=20192697-3:2888:3888
server.2=20192697-4:2888:3888
server.3=20192697-5:2888:3888
#1是ID,2888是主从节点通信端口,3888是选举机制端口,zookeeper也是主从架构,也有选举机制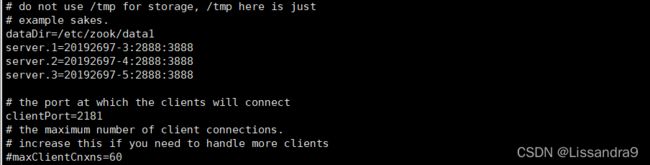
(4)分发节点
scp -r /etc/zook/ 20192697-3:/etc/
#分发给其余三个节点(5)Myid
mkdir -p /etc/zook/data1/
#这里创建的是在zoo.cfg里面修改的DATA路径
echo 1 > /etc/zook/data1/myid //node03
echo 2 > /etc/zook/data1/myid //node04
echo 3 > /etc/zook/data1/myid //node05(6)设置环境变量
vim /etc/profile
export ZOOKEEPER_HOME=/etc/zook/zookeeper-3.4.6/bin
export PATH=$PATH:$ZOOKEEPER_HOME
source /etc/profile
#重新加载
scp -r /etc/profile 20192697-3:/etc/
scp -r /etc/profile 20192697-4:/etc/
scp -r /etc/profile 20192697-5:/etc/
#将此文件传到各节点后,再各节点分别再次进行重新加载(7)启动zookeeper
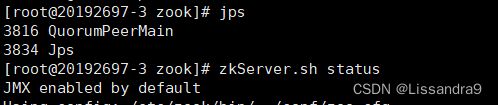
zkServer.sh start
jps //查看进程:
# QuorumPeerMain或者:
zkServer.sh status // Mode:leader or Mode:foolwer
zkServer.sh stop //关闭zookeeper
#注意:至少启动两台服务器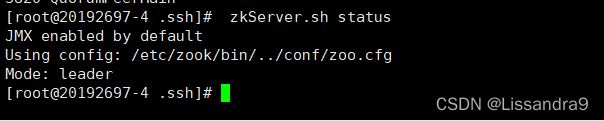
(8)启动journalnode(3个节点)
hadoop-daemon.sh start journalnode
#再-2 -3 -4上进行启动,-5不用启动(9)格式化node02 (或 node03)
hdfs namenode -format //格式化
#再-2或者-3节点上进行格式化
#status 0 则格式化成功
hadoop-daemon.sh start namenode
#在-2上启动节点
hdfs namenode -bootstrapStandby
#复制节点信息给-3,在-3上使用此命令 
(10)注册两个namenode
zkCli.sh //客户端查看
#在-3上使用
ls / //再查看: [hadoop-ha,zookeeper]
#在-3上使用
hdfs zkfc -formatZK //initializing HA state in zookeeper
#在-2上使用 
(11)在20192697-2上启动
start-dfs.sh四.浏览器查看
20192697-2:50070
20192697-3:50070
#此处的-2 -3用自己的IP地址
#最后进入浏览器后会发现一个是active,另一个是standby即搭建成功如果有疑问,或者错误欢迎评论去留言讨论,共同学习