【第十届“泰迪杯”数据挖掘挑战赛】C题:疫情背景下的周边游需求图谱分析 问题一方案及Python实现

相关链接
(1)问题一方案及实现
(2)问题二方案及实现,待上传
(3)问题三方案及实现,待上传
代码下载
(1)问题一代码下载
1 题目
1.1 问题背景
随着互联网和自媒体的繁荣,文本形式的在线旅游(Online Travel Agency,OTA)和游客的用户生成内容(User Generated Content,UGC)数据成为了解旅游市场现状的重要信息来源。OTA 和UGC 数据的内容较为分散和碎片化,要使用它们对某一特定旅游目的地进行研究时,迫切需要一种能够从文本中抽取相关的旅游要素,并挖掘要素之间的相关性和隐含的高层概念的可视化分析工具。
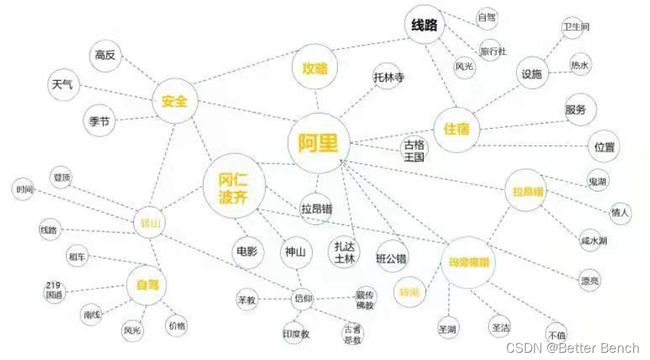
为此本赛题提出本地旅游图谱这一概念,它在通用知识图谱的基础上加入了更多针对 旅游行业的需求。本地旅游图谱采用图的形式直观全面地展示特定旅游目的地“吃住行娱 购游”等旅游要素,以及它们之间的关联。图 1 所示为我国西藏阿里地区的本地旅游图谱, 中心位置节点为旅游目的地“阿里”,它的下层要素包括该地区的重要景点如“冈仁波齐” 和“玛旁雍错”,以及“安全”、“住宿”等旅游要素。旅游要素分为多个等级,需要从 文本中挖掘出面对不同要素游客所关注的下一级要素。如阿里地区的“安全”要素下包括 “高反”、“天气”和“季节”等下一级要素,这个组合是西藏旅游所特有的。旅游要素 之间会存在关联关系,如“冈仁波齐”和“玛旁雍错”这两个景点通过“神山圣湖”这一 高层概念产生联系,在本地旅游图谱中使用连接两个节点的一条边来表示。
在近年来新冠疫情常态化防控的背景下,我国游客的旅游消费方式已经发生明显的转变。在出境游停滞,跨省游时常因为零散疫情的影响被叫停的情况下,中长程旅游受到非常大的冲击,游客更多选择短程旅游,本地周边游规模暴涨迎来了风口。疫情防控常态化背景下研究分析游客消费需求行为的变化,对于旅游企业产品供给、资源优化配置以及市场持续开拓具有长远而积极的作用。本赛题提供收集自互联网公开渠道的 2018 年至 2021年广东省茂名市的 OTA 和 UGC 数据,期待参赛者采用自然语言处理等数据挖掘方法通过建立本地旅游图谱的方式来分析新冠疫情时期该市周边游的发展。
1.2 解决问题
1、微信公众号文章分类
构建文本分类模型,对附件 1 提供的微信公众号的推送文章根据其内容与文旅的相关性分为“ 相关” 和“ 不相关” 两类, 并将分类结果以表 1 的形式保存为文件“result1.csv”。与文旅相关性较强的主题有旅游、活动、节庆、特产、交通、酒店、景 区、景点、文创、文化、乡村旅游、民宿、假日、假期、游客、采摘、赏花、春游、踏青、康养、公园、滨海游、度假、农家乐、剧本杀、旅行、徒步、工业旅游、线路、自驾游、 团队游、攻略、游记、包车、玻璃栈道、游艇、高尔夫、温泉等等。

2、周边游产品热度分析
从附件提供的 OTA、UGC 数据中提取包括景区、酒店、网红景点、民宿、特色餐饮、乡村旅游、文创等旅游产品的实例和其他有用信息,将提取出的旅游产品和所依托的语料以的形式保存为文件“result2-1.csv”。建立旅游产品的多维度热度评价模型,对提取出的旅游产品按年度进行热度分析,并排名。将结果以表 3 的形式保存为文件“result2- 2.csv”。


3、本地旅游图谱构建与分析
依据提供的 OTA、UGC 数据,对问题 2 中提取出的旅游产品进行关联分析,找出以景区、酒店、餐饮等为核心的强关联模式,结果以表 的形式保存为文件“result3.csv”。在此基础上构建本地旅游图谱并选择合适方法进行可视化分析。鼓励参赛队挖掘旅游产品间隐含的关联模式并进行解释。

4、疫情前后旅游产品需求的变化分析
基于历史数据,使用本地旅游图谱作为分析工具,分析新冠疫情前后茂名市旅游产品的变化,并撰写一封不超过 2 页的信件向该地区旅游主管部门提出旅游行业发展的政策建议。
1.3 附件说明
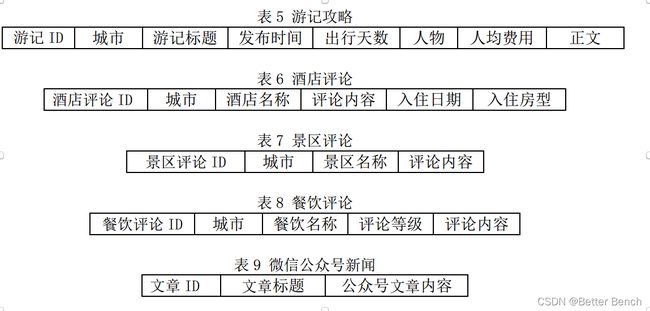
附件 1 数据来源于互联网公开渠道,具体表结构字段如下:
2 问题一思路
数据预处理包括:读取微信公众号文章,将标题和文本合并后,先用正则表达式删除中文中的特殊符号,再jieba分词、再去掉停用词,停用词有很多类型的,有哈工大、百度、川大的,下载地址https://github.com/goto456/stopwords。以下实现用哈工大的。
判断主题类型:方法一,计算文本相似度,对每个样本计算与旅游、活动等等这些关键词的TFIDF相似度。大于0的,即为相关。方法二,用LDA提取文档主题,计算样本与以上的关键词文档的相似度,大于0的,即为相关。
3 Python实现
import warnings
from gensim import corpora, models, similarities
from gensim.corpora import Dictionary
from gensim import corpora, models
import numpy as np
import pandas as pd
import re
from tqdm import tqdm
import jieba
tqdm.pandas()
warnings.filterwarnings('ignore')
3.1 读取文件
# 读取微信公众号文章
train_data = pd.read_excel('./data/data.xlsx',sheet_name=4)
train_data

# 合并标题和正文
train_data['text'] = train_data['文章标题']+'\n'+train_data['公众号文章内容']
train_data['text']

3.2 删除特殊字符和文本分词
def clearTxt(line):
if line != '':
line = line.strip()
#去除文本中的英文和数字
line = re.sub("[a-zA-Z0-9]", "", line)
#去除文本中的中文符号和英文符号
。。。略
#分词
segList = jieba.cut(line, cut_all=False)
segSentence = ''
for word in segList:
if word != '\t':
segSentence += word + " "
return segSentence.strip()
text = train_data['text'].progress_apply(clearTxt)
text

3.3 去停用词
import codecs
#读取停顿词列表
stopword_list = [k.strip() for k in open(
'stop/cn_stopwords.txt', encoding='utf8').readlines() if k.strip() != '']
def stopWord(line):
sentence = delstopword(line, stopword_list)
return sentence
#删除停用词
def delstopword(line, stopkey):
wordList = line.split(' ')
sentence = ''
for word in wordList:
word = word.strip()
if word not in stopkey:
if word != '\t':
sentence += word + " "
return sentence.strip()
train_data['分词后文本'] = text
text2 = train_data['分词后文本'].progress_apply(stopWord)
text2

3.4 计算文本相似度
方法一:TF—IDF相似度
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
from scipy.linalg import norm
# def tf_similarity(s1, s2):
s1 = 略
tf_sim_num = []
for i in range(len(text2)):
s2 = text2[i]
cv = CountVectorizer(tokenizer=lambda s: s.split()) # 转化为TF矩阵
corpus = [s1, s2]
vectors = cv.fit_transform(corpus).toarray() # 计算TF系数
sim = np.dot(vectors[0], vectors[1]) / (norm(vectors[0]) * norm(vectors[1]))
print(sim)
tf_sim_num.append(sim)
方法二:LDA主题模型相似度
s1 = 略
def get_dict():
train = []
for i in enumerate(text2):
line = i[1].split()
train.append(line)
train.append(s1.split())
dictionary = Dictionary(train)
return dictionary, train
#计算两个文档的相似度
dictionary = get_dict()[0]
train = get_dict()[1]
corpus = [dictionary.doc2bow(text) for text in train] # 每个text对应的稀疏向量
tfidf = models.TfidfModel(corpus) # 统计tfidf
corpus_tfidf = tfidf[corpus]
。。。略
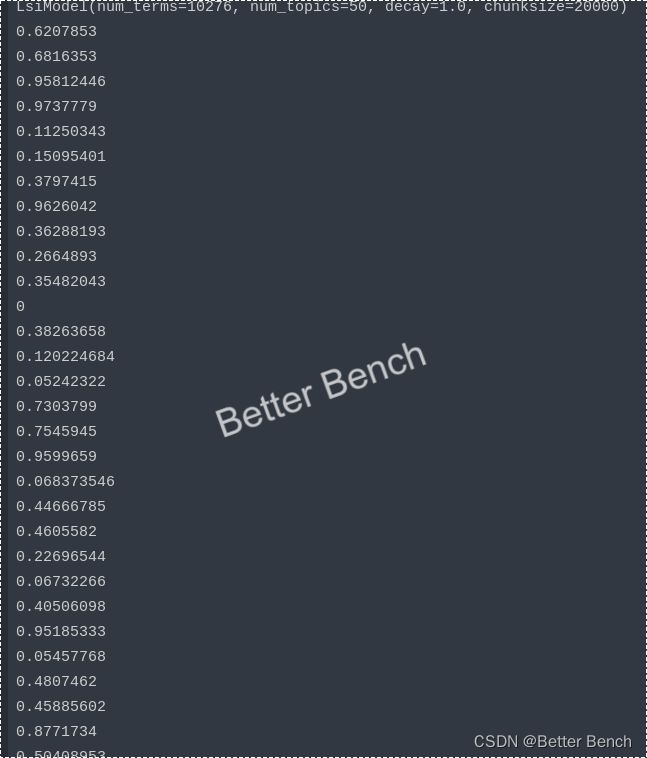
lda_sim_num = []
for txt in enumerate(text2):
s2 = txt[1]
test_doc = s1.split() # 新文档进行分词
dictionary = get_dict()[0]
doc_bow = dictionary.doc2bow(test_doc) # 文档转换成bow
doc_lda = lda[doc_bow] # 得到新文档的主题分布
# # 输出新文档的主题分布
list_doc1 = [i[1] for i in doc_lda]
test_doc2 = s2.split() # 新文档进行分词
doc_bow2 = dictionary.doc2bow(test_doc2) # 文档转换成bow
doc_lda2 = lda[doc_bow2] # 得到新文档的主题分布
# 输出新文档的主题分布
list_doc2 = [i[1] for i in doc_lda2][:len(list_doc1)]
try:
sim = np.dot(list_doc1, list_doc2) / \
(np.linalg.norm(list_doc1) * np.linalg.norm(list_doc2))
print(sim)
except ValueError:
sim = 0
print(sim)
lda_sim_num.append(sim)
3.5 根据相似度分类文本
# 根据tfidf相似度分类文本
# sim_num = tf_sim_num
# 根据lda相似度分类文本
sim_num = lda_sim_num
label = []
for i in enumerate(sim_num):
if i[1]>0:
label.append('相关')
else:
label.append('不相关')
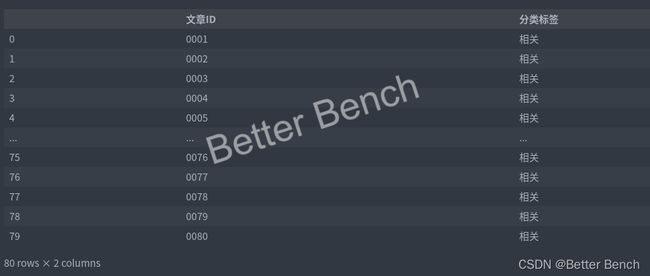
result = pd.DataFrame(columns=['文章ID','分类标签'])
result['文章ID'] = [str(i+1).zfill(4) for i in range(len(train_data))]
result['分类标签'] =label
result.to_csv('./data/result1.csv',index=False)
result
4 代码下载
https://mianbaoduo.com/o/bread/YpmXlp5x