K近邻算法以及python实现
K近邻算法以及python实现
- K K K 近邻 (K Nearest Neighbors)
-
- K近邻算法原理
- K近邻算法流程
- 距离度量
-
- 距离度量公式
- 距离度量例题
- K K K值的选择
-
- K K K值的影响
- K K K值选择实例
- k d kd kd树
-
- 二叉排序树
- k d kd kd 树原理
- k d kd kd 树构造算法
- k d kd kd 树构造例题
- k d kd kd 树构的搜索
- k d kd kd 树构的搜索原理
- k d kd kd 树构的搜索例题
- k k k 近邻的python实现
K K K 近邻 (K Nearest Neighbors)
K近邻算法利用数据在空间中的分布,将其划分为不同的类别,一个简单又不恰当的例子就是某个人在河南的某块区域,K近邻就会判断这个人是河南人,另一个人在北京的某块区域,K近邻就会判断这个人是北京人。K近邻算法是由Cover和Hart在1968年提出。K近邻输入的数据一般是二维以上的数据。因为不存在明显的学习过程,所以K近邻算法也是一种懒惰算法。关于K近邻算法的原理以及K值的构造和kd树的构造接下来将会进行分析。
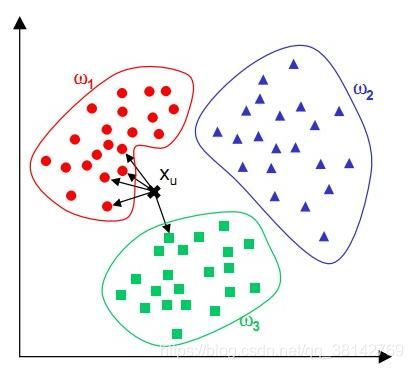
K近邻算法原理
K K K 近邻算法是一种简单直观的算法,根据英文名字我们就可以猜出来个大概。给定一个数据集,对于一个新的输入实例,在训练集当中寻找与该实例最为接近的 k k k 个实例,找出这 k k k 个实例当中类别最多的某一类,就将这个新实例分为这个类。
K近邻算法流程
数据集 T :
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . . , ( x n , y n ) } T = \lbrace(x_1,y_1),(x_2,y_2),....,(x_n,y_n)\rbrace T={(x1,y1),(x2,y2),....,(xn,yn)}
x i x_i xi为输入的特征向量, y i y_i yi为特征向量的类别。
输入: x , y x ,y x,y
- 根据给定的距离度量方式,在数据集 T T T 当中寻找与 x x x 最为接近的 k k k 个点,记录这些点的类别。
- 根据一定的规则,判断新输入的 x x x 的类别(通常为少数服从多数原则)
距离度量
上面k近邻算法流程当中我们提到了许多未确定的内容,比如算法流程当中的距离度量方式和k的取值,这一小节当中,我们会来讨论一下距离度量的方式。
距离度量公式
在初高中的时候应该接触过平面图形上两个点的距离公式
s = ( x 1 − x 2 ) 2 + ( y 1 − y 2 ) 2 s = \sqrt{(x_1-x_2)^2 + (y_1 - y_2)^2} s=(x1−x2)2+(y1−y2)2
在多维空间中,该距离公式可以表示为:
L p ( x i , y i ) = ( ∑ l = 1 n ∣ x i ( l ) − x j ( l ) ∣ p ) 1 / p L_p(x_i,y_i) = \bigg(\sum_{l=1}^n|x_i^{(l)} - x_j^{(l)}|^p\bigg)^{1/p} Lp(xi,yi)=(l=1∑n∣xi(l)−xj(l)∣p)1/p
l l l表示的就是n维输入向量 x i x_i xi和 x j x_j xj中每一个维度的取值。
如果 p = 2 , 那么就是我们接触到的距离公式(欧氏距离)。其中:
∣ x i ( l ) − x j ( l ) ∣ |x_i^{(l)} - x_j^{(l)}| ∣xi(l)−xj(l)∣
如果 p = 1,那么就成为曼哈顿距离,即:
L 1 ( x i , y i ) = ∑ l = 1 n ∣ x i ( l ) − x j ( l ) ∣ L_1(x_i,y_i) = \sum_{l=1}^n|x_i^{(l)} - x_j^{(l)}| L1(xi,yi)=l=1∑n∣xi(l)−xj(l)∣
如果 p = ∞ \infty ∞, 那么就成为了求各个坐标距离的最大值,即切比雪夫距离:
L ∞ ( x i , y i ) = m a x ∣ x i ( l ) − x j ( l ) ∣ L_\infty(x_i,y_i) = max|x_i^{(l)} - x_j^{(l)}| L∞(xi,yi)=max∣xi(l)−xj(l)∣
距离度量例题
已知二维空间有3个点, x 1 = ( 1 , 1 ) , x 2 = ( 5 , 1 ) , x 3 = ( 4 , 4 ) x_1 = (1,1),x_2 = (5,1),x_3 = (4,4) x1=(1,1),x2=(5,1),x3=(4,4), 试求在p取不同值时, L p L_p Lp 距离下 x 1 x_1 x1的最近邻点。
解:
先观察三个点,我们会发现 x 1 x_1 x1和 x 2 x_2 x2的y坐标都是1,所以两个向量是在一条线上,所以这两个的距离是一个定值。不受p的影响。即 x 1 x_1 x1和 x 2 x_2 x2的距离 L p ( x 1 , x 2 ) L_p(x_1,x_2) Lp(x1,x2) = 4。然后我们来计算其他的数值。
L 1 ( x 1 , x 3 ) = ∣ 1 − 4 ∣ + ∣ 1 − 4 ∣ = 6 L_1(x_1,x_3) = |1-4| + |1-4| = 6 L1(x1,x3)=∣1−4∣+∣1−4∣=6
L 2 ( x 1 , x 3 ) = ∣ 1 − 4 ∣ 2 + ∣ 1 − 4 ∣ 2 = 4.24 L_2(x_1,x_3) = \sqrt{|1-4|^2 +|1-4|^2} = 4.24 L2(x1,x3)=∣1−4∣2+∣1−4∣2=4.24
L 3 ( x 1 , x 3 ) = ∣ 1 − 4 ∣ 3 + ∣ 1 − 4 ∣ 3 3 = 3.78 L_3(x_1,x_3) = \sqrt[3]{|1-4|^3 +|1-4|^3} = 3.78 L3(x1,x3)=3∣1−4∣3+∣1−4∣3=3.78
L 4 ( x 1 , x 3 ) = ∣ 1 − 4 ∣ 4 + ∣ 1 − 4 ∣ 4 4 = 3.57 L_4(x_1,x_3) = \sqrt[4]{|1-4|^4 +|1-4|^4} = 3.57 L4(x1,x3)=4∣1−4∣4+∣1−4∣4=3.57
所以可以总结出,当 p = 1 或者 2的时候, x 2 x_2 x2是 x 1 x_1 x1的最邻近点,其余情况 x 3 x_3 x3是 x 1 x_1 x1的最邻近点.
K K K值的选择
在李航的《统计学习方法》一书中说到, k k k值的选择会对 k k k近邻算法的结果产生较大的影响。
K K K值的影响
如果选择较小的 k k k值,就相当于在较少的训练数据中进行选择,“学习”的近似误差会减小,因为只有与输入实例较为接近的训练数据才会起到作用,但是学习的估计误差会比较大,换句话说, k k k值的减小就意味着整体模型变得复杂,容易发生过拟合;
选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且 k k k值的增大就意味着整体的模型变得简单。
在实际应用中, k k k值一般取一个比较小的数值,例如采用交叉验证法(简单来说,就是把训练数据在分成两组:训练集和验证集)来选择最优的 k k k值。
K K K值选择实例
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = load_iris().data
y = load_iris().target
print(data.shape)
x_train,x_test,y_train,y_test = train_test_split(data,y,test_size=0.3)
for i in range(3,50):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(x_train,y_train)
pre = knn.predict(x_test)
print(i,':',accuracy_score(y_test,pre))
3 : 0.9555555555555556
4 : 0.9555555555555556
5 : 0.9777777777777777
6 : 0.9777777777777777
7 : 0.9777777777777777
8 : 0.9777777777777777
9 : 0.9777777777777777
10 : 0.9777777777777777
11 : 0.9777777777777777
12 : 1.0
13 : 1.0
14 : 1.0
15 : 0.9777777777777777
16 : 1.0
17 : 1.0
18 : 1.0
19 : 1.0
20 : 1.0
21 : 0.9777777777777777
22 : 1.0
23 : 0.9777777777777777
24 : 1.0
25 : 1.0
26 : 1.0
27 : 1.0
28 : 1.0
29 : 0.9777777777777777
30 : 0.9777777777777777
31 : 0.9777777777777777
32 : 0.9777777777777777
33 : 0.9777777777777777
34 : 0.9555555555555556
35 : 0.9777777777777777
36 : 0.9777777777777777
37 : 0.9777777777777777
38 : 0.9777777777777777
39 : 0.9777777777777777
40 : 0.9555555555555556
41 : 0.9555555555555556
42 : 0.9111111111111111
43 : 0.9333333333333333
44 : 0.9111111111111111
45 : 0.9333333333333333
46 : 0.9333333333333333
47 : 0.9333333333333333
48 : 0.9333333333333333
49 : 0.9333333333333333
从鸢尾花的数据集当中可以看出来,当k值从3变化到49的时候,准确率也是从0.95 - 1 - 0.93。k值的影响还是挺大的。所以我们在用knn算法的过程中,要根据数据量的大小来进行好k值的筛选。
k d kd kd树
现在提出一个问题,对于每一个需要进行类别判断的实例向量,我们要找出 k k k个与其相邻近的实例向量。那么要根据什么算法来求这 k k k个向量呢?需要将所有的数据向量来和输入向量进行计算求距离吗?这其实就是穷举法的思想。这种算法的时间复杂度是 O ( n ) O(n) O(n)。即将有n个实例向量的数据集遍历一遍。在少量的数据集当中我们可以采用这样的方法。但是如果数据集有几百万的实例呢?这将是十分大的计算量。为此,1975年,来自斯坦福大学的Jon Louis Bentley在ACM杂志上发表的一篇论文:Multidimensional Binary Search Trees Used for Associative Searching 中正式提出和阐述的了如下图形式的把空间划分为多个部分的k-d树。我们先从1维空间了解一下什么是二叉排序树。
二叉排序树
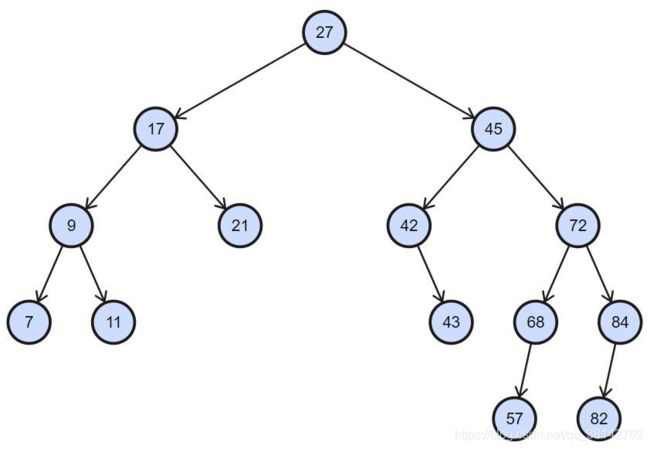
根节点的值大于其左子树中任意一个节点的值,小于其右节点中任意一节点的值,这一规则适用于二叉查找树中的每一个节点。学过数据结构的同学应该都懂得什么是二叉排序树。
二叉排序树有以下的特点:
(1)若左子树不空,则左子树上所有节点的值均小于它的根节点的值;
(2)若右子树不空,则右子树上所有节点的值均大于它的根节点的值;
(3)左、右子树也分别为二叉排序树;
(4)没有键值相等的节点。
根据二叉排序树,我们可以很方便的找到一个数值所在的位置。如果要插入一个数据,只需要跟着树的结点往下寻找数据附近的数值即可,大大的节省了时间。当然,二叉排序树是根据1维数据产生的。如果是多维度的数据,那么就需要我们的 k d kd kd树了。 k d kd kd树和排序二叉树采用了相同的原理。
k d kd kd 树原理
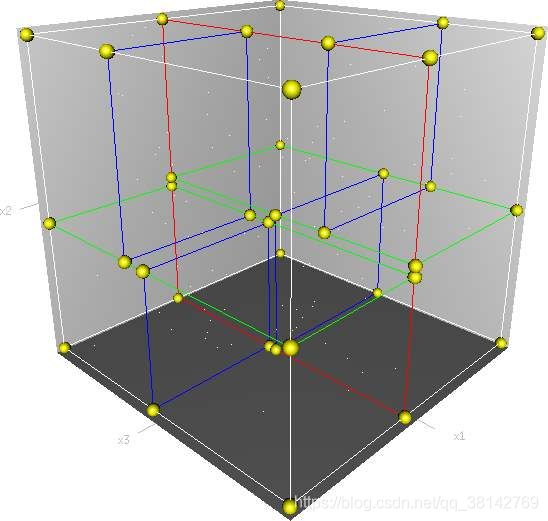
Kd树是K-dimension tree的缩写,是对数据点在k维空间(如二维(x,y),三维(x,y,z),k维(x1,y,z…))中划分的一种数据结构,主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索)。本质上说,Kd树就是一种平衡二叉树。首先必须搞清楚的是,kd树是一种空间划分树,说白了,就是把整个空间划分为特定的几个部分,然后在特定空间的部分内进行相关搜索操作。
k d kd kd 树构造算法
输入数据为:
T = { ( x 1 ( l ) , y 1 ) , ( x 2 ( l ) , y 2 ) , . . . . , ( x n ( l ) , y n ) } T = \lbrace(x_1^{(l)},y_1),(x_2^{(l)},y_2),....,(x_n^{(l)},y_n)\rbrace T={(x1(l),y1),(x2(l),y2),....,(xn(l),yn)}
其中 l 表示输入实例 x x x 的维度,例如 x 1 = ( 3 , 7 , 5 , 2 , 0 ) T x_1 = (3,7,5,2,0)^T x1=(3,7,5,2,0)T,这表明输入实例为5维实例。n 表示有 n 个多维数据实例。 y y y 则表示数据的分类情况。 x 1 ( 1 ) = 3 , x 1 ( 2 ) = 7 x_1^{(1)} = 3,x_1^{(2)} = 7 x1(1)=3,x1(2)=7,以此类推。
流程:
- 先以 x ( 1 ) x^{(1)} x(1)为坐标轴,将 T T T 中所有实例按照 x ( 1 ) x^{(1)} x(1)坐标的中位数进行切分。将一个多维空间切割为两个左右子域。在kd树上,我们构造出了树深度为1的左右、子节点。(第一次离数据),在左子节点中,所有数据的 x ( 1 ) x^{(1)} x(1)均小于中位数,在右子节点中,所有数据的 x ( 1 ) x^{(1)} x(1)均大于中位数。
- 对深度为m的左右子节点。我们选择 x ( s ) x^{(s)} x(s)为切分的坐标轴。其中s = m(mod l) + 1。以该节点所有区域的所有实例 x ( s ) x^{(s)} x(s)坐标的中位数进行切分。又将该区域划分为左右两个子区域。此时kd树生成了深度为m+1的左右子节点。
- 重复以上的过程。直到所有数据实例被存放在一个单独的子区域当中。
k d kd kd 树构造例题
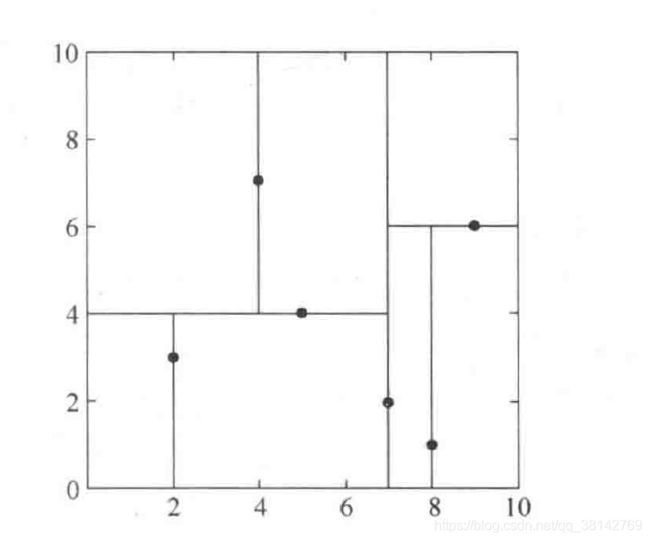
给定一个二维空间数据集:
T = { ( 2 , 3 ) , ( 5 , 4 ) , ( 9 , 6 ) , ( 4 , 7 ) , ( 8 , 1 ) , ( 7 , 2 ) } T = \lbrace (2,3),(5,4),(9,6),(4,7),(8,1),(7,2) \rbrace T={(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}
构造一个kd树
解:
- 选择 x ( 1 ) x^{(1)} x(1) 作为第一次划分维度,找到其维度的中位数是7,所以按照 x ( 1 ) = 7 x^{(1)} = 7 x(1)=7 将数据划分在两个平面上。左平面有(2,3),(5,4),(4,7)。右平面有(8,1),(9,6)。
- 在左平面上,选择 x ( 2 ) x^{(2)} x(2)作为第二次划分维度(2 = 1 mod 2 + 1)。找到其维度的中位数是4,所以按照 x ( 2 ) = 4 x^{(2)} = 4 x(2)=4 将数据划分在两个平面上。左上平面有数据点(4,7),左下平面有数据点(2,3)
- 在右平面上,选择 x ( 2 ) x^{(2)} x(2)作为第二次划分维度(2 = 1 mod 2 + 1)。找到其维度的中位数是6,所以按照 x ( 2 ) = 6 x^{(2)} = 6 x(2)=6 将数据划分在两个平面上。只有右下平面的(8,1) 。
- 每个平面只有一个数据点。构建完毕。
k d kd kd 树构的搜索
给定一个目标点,搜索其最近邻。首先我们根据目标点找到包含目标点的子区域。即kd树的树叶节点。然后从该叶节点出发,依次退回到父节点(根节点)。不断的查找与目标点想邻近的节点。当检查完所有经过路径上的节点时结束。
k d kd kd 树构的搜索原理
输入:已经够造好的kd树,目标点 x x x
- 在kd树中找出包含目标点的子区域:从根结点出发,按照构建kd树的顺序不断的递归向下,直到找到包含目标点的子区域。
- 把次节点所在的数据点作为最邻近点。
- 递归向上回退,在遇到的每个节点进行以下的操作。
(a)如果该节点保存的数据点比当前最邻近点距离还近,则把该数据点作为最邻近点。
(b)当前最近点一定存在于当前区域的子区域中,所以需要检查当前区域的兄弟区域。检查的方式为:检查兄弟区域是否与以目标点为圆心,最短距离为半径的圆形相交。如果没有相交,则不存在更加近的数据点。如果有相交,则需要在兄弟区域中寻找是否存在更近的数据点。
(c)不断的循环查找,直到走到根节点。此时的数据点就是最邻近点。
k d kd kd 树构的搜索例题
https://blog.csdn.net/Losteng/article/details/50893739
k k k 近邻的python实现
import numpy as np
class binaryTreeNode():
def __init__(self,data=None,left=None,right=None,split=None):
self.data = data
self.left = left
self.right = right
self.split = split
def getdata(self):
return self.data
def getleft(self):
return self.left
def getright(self):
return self.right
def getsplit(self):
return self.split
class KNNClassfier(object):
def __init__(self, k=1, distance='euc'):
self.k = k
self.distance = distance
self.root = None
def getroot(self):
return self.root
def kd_tree(self,train_X,train_Y):
'''构造kd树'''
if len(train_X)==0:
return None
if len(train_X)==1:
return binaryTreeNode((train_X[0],train_Y[0]))
index = np.argmax(np.var(train_X,axis=0))
argsort = np.argsort(train_X[:,index])
left = self.kd_tree(train_X[argsort[0:len(argsort)//2],:],train_Y[argsort[0:len(argsort)//2]])
right = self.kd_tree(train_X[argsort[len(argsort)//2+1: ],:],train_Y[argsort[len(argsort)//2+1: ]])
root = binaryTreeNode((train_X[argsort[len(argsort)//2],:],train_Y[argsort[len(argsort)//2]]),left,right,index)
return root
def inOrder(self,root):
'''中序遍历kd树'''
if root == None:
return None
self.inOrder(root.getleft())
print(root.getdata())
self.inOrder(root.getright())
def search_kd_tree(self,x,knn,root,nodelist):
while len(knn)==0:
if root.getleft() == None and root.getright() == None:
return knn.append(root.getdata())
if x[root.getsplit()]<root.getdata()[0][root.getsplit()]:
if root.getleft()!=None:
nodelist.append(root.getleft())
self.search_kd_tree(x,knn,root.getleft(),nodelist)
else:
nodelist.append(root.getright())
self.search_kd_tree(x,knn,root.getright(),nodelist)
else:
if root.getright()!=None:
nodelist.append(root.getright())
self.search_kd_tree(x,knn,root.getright(),nodelist)
else:
nodelist.append(root.getleft())
self.search_kd_tree(x,knn,root.getleft(),nodelist)
dis = np.linalg.norm(x-knn[0][0],ord=2)
while len(nodelist)!=0:
current = nodelist.pop()
# currentdis = np.linalg.norm(x-current.getdata()[0],ord=2)
if np.linalg.norm(x-current.getdata()[0],ord=2)<dis:
knn[0] = current.getdata()
if current.getleft()!=None and np.linalg.norm(x-current.getleft().getdata()[0],ord=2)<dis:
knn[0] = current.getleft().getdata()
if current.getright()!=None and np.linalg.norm(x-current.getright().getdata()[0],ord=2)<dis:
knn[0] = current.getright().getdata()
return knn
def fit(self,X,Y):
'''
X : array-like [n_samples,shape]
Y : array-like [n_samples,1]
'''
self.root = self.kd_tree(X,Y)
def predict(self,X):
output = np.zeros((X.shape[0],1))
for i in range(X.shape[0]):
knn = []
knn = self.search_kd_tree(X[i,:],knn,self.root,[self.root])
labels = []
for j in range(len(knn)):
labels.append(knn[j][1])
counts = []
# print('x:',X[i,:],'knn:',knn)
for label in labels:
counts.append(labels.count(label))
output[i] = labels[np.argmax(counts)]
return output
def score(self,X,Y):
pred = self.predict(X)
err = 0.0
for i in range(X.shape[0]):
if pred[i]!=Y[i]:
err = err+1
return 1-float(err/X.shape[0])
if __name__ == '__main__':
from sklearn import datasets
import time
digits = datasets.load_digits()
x = digits.data
y = digits.target
myknn_start_time = time.time()
clf = KNNClassfier(k=5)
clf.fit(x,y)
print('myknn score:',clf.score(x,y))
myknn_end_time = time.time()
from sklearn.neighbors import KNeighborsClassifier
sklearnknn_start_time = time.time()
clf_sklearn = KNeighborsClassifier(n_neighbors=5)
clf_sklearn.fit(x,y)
print('sklearn score:',clf_sklearn.score(x,y))
sklearnknn_end_time = time.time()
print('myknn uses time:',myknn_end_time-myknn_start_time)
print('sklearn uses time:',sklearnknn_end_time-sklearnknn_start_time)
myknn score: 0.9048414023372288
sklearn score: 0.9905397885364496
myknn uses time: 0.7600159645080566
sklearn uses time: 0.46475696563720703