Ubuntu20.04安装k8s环境一些可能存在的bug
主要是总结一下我在安装时候踩的那些坑……
安装步骤
准备
1. 禁止swap分区
主要有两种方式:暂时禁止和永久禁止
暂时禁止:
sudo swapoff -a
永久禁止:
sudo vi /etc/fstab
# /etc/fstab: static file system information.
#
# Use 'blkid' to print the universally unique identifier for a
# device; this may be used with UUID= as a more robust way to name devices
# that works even if disks are added and removed. See fstab(5).
#
#
# / was on /dev/sda5 during installation
UUID=651efbee-6215-4ad3-b95f-587ec547ae2b / ext4 errors=remount-ro 0 1
# /boot/efi was on /dev/sda1 during installation
UUID=5204-33C6 /boot/efi vfat umask=0077 0 1
# /swapfile none swap sw 0 0
/dev/fd0 /media/floppy0 auto rw,user,noauto,exec,utf8 0 0
- 更改net.bridge.bridge-nf-call-iptables的值为1.(Ubuntu 20.04默认为1)
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sudo sysctl --system
- 安装Docker
sudo apt update
sudo apt install docker.io
sudo systemctl start docker
sudo systemctl enable docker
- 采用阿里云镜像加速
参考阿里云镜像加速配置
开始安装k8s
- 安装kubeadm kubeadm kubectl
sudo apt-get update && sudo apt-get install -y ca-certificates curl software-properties-common apt-transport-https curl
curl -s https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
sudo tee /etc/apt/sources.list.d/kubernetes.list <<EOF
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
- 初始化
sudo kubeadm init
如果在这里出现了如下错误
[init] Using Kubernetes version: v1.23.1
[preflight] Running pre-flight checks
[WARNING Swap]: swap is enabled; production deployments should disable swap unless testing the NodeSwap feature gate of the kubelet
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR ImagePull]: failed to pull image k8s.gcr.io/kube-apiserver:v1.23.1: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
, error: exit status 1
[ERROR ImagePull]: failed to pull image k8s.gcr.io/pause:3.6: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
, error: exit status 1
[ERROR ImagePull]: failed to pull image k8s.gcr.io/etcd:3.5.1-0: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
, error: exit status 1
[ERROR ImagePull]: failed to pull image k8s.gcr.io/coredns/coredns:v1.8.6: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
首先使用下面的命令获取需要的docker镜像名称:
sudo kubeadm config images list
结果如下:
ubuntu@ubuntu:~$ sudo kubeadm config images list
k8s.gcr.io/kube-apiserver:v1.23.1
k8s.gcr.io/kube-controller-manager:v1.23.1
k8s.gcr.io/kube-scheduler:v1.23.1
k8s.gcr.io/kube-proxy:v1.23.1
k8s.gcr.io/pause:3.6
k8s.gcr.io/etcd:3.5.1-0
k8s.gcr.io/coredns/coredns:v1.8.6
注意:新版本的coredns改名了,变成了coredns/coredns,记得在images里面改一下!!!
首先要看看该在哪个地方拉取,可以去docker hub搜一搜哪里有kube-proxy之类的组件
进入dockerhub搜索:
https://hub.docker.com/search?q=kube-proxy&type=image
我自己的版本对应的找到一个,然后开始编写脚本:
sudo vi pull_k8s_images.sh
set -o errexit
set -o nounset
set -o pipefail
##这里定义版本,按照上面得到的列表自己改一下版本号
KUBE_VERSION=v1.23.1
KUBE_PAUSE_VERSION=3.6
ETCD_VERSION=3.5.1-0
DNS_VERSION=v1.8.6
##这是原始仓库名,最后需要改名成这个
GCR_URL=k8s.gcr.io
##这里就是写你要使用的仓库
DOCKERHUB_URL=v5cn
##这里是镜像列表,新版本要把coredns改成coredns/coredns
images=(
kube-proxy:${KUBE_VERSION}
kube-scheduler:${KUBE_VERSION}
kube-controller-manager:${KUBE_VERSION}
kube-apiserver:${KUBE_VERSION}
pause:${KUBE_PAUSE_VERSION}
etcd:${ETCD_VERSION}
coredns:${DNS_VERSION}
)
##这里是拉取和改名的循环语句
for imageName in ${images[@]} ; do
docker pull $DOCKERHUB_URL/$imageName
docker tag $DOCKERHUB_URL/$imageName $GCR_URL/$imageName
docker rmi $DOCKERHUB_URL/$imageName
done
授予执行权限
chmod +x ./pull_k8s_images.sh
执行:
./pull_k8s_images.sh
执行过程中就会拉取镜像,完成后,使用sudo docker images命令查看所有镜像,如下:
ubuntu@ubuntu:~$ sudo docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
k8s.gcr.io/kube-apiserver v1.23.1 b6d7abedde39 11 days ago 135MB
k8s.gcr.io/kube-proxy v1.23.1 b46c42588d51 11 days ago 112MB
k8s.gcr.io/kube-scheduler v1.23.1 71d575efe628 11 days ago 53.5MB
k8s.gcr.io/kube-controller-manager v1.23.1 f51846a4fd28 11 days ago 125MB
k8s.gcr.io/etcd 3.5.1-0 25f8c7f3da61 7 weeks ago 293MB
k8s.gcr.io/coredns v1.8.6 a4ca41631cc7 2 months ago 46.8MB
k8s.gcr.io/pause 3.6 6270bb605e12 4 months ago 683kB
现在执行sudo kubeadm init集群开始初始化还是会出问题,先来看看报错信息
[init] Using Kubernetes version: v1.23.1
[preflight] Running pre-flight checks
[WARNING Swap]: swap is enabled; production deployments should disable swap unless testing the NodeSwap feature gate of the kubelet
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR ImagePull]: failed to pull image k8s.gcr.io/coredns/coredns:v1.8.6: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
这个地方就是上面提到的注意部分,即需要更改一下coredns,我采用的是打标签的方式:
sudo docker tag k8s.gcr.io/coredns:v1.8.6 k8s.gcr.io/coredns/coredns:v1.8.6
打完标签以后使用sudo docker images就可以看到两个coredns
REPOSITORY TAG IMAGE ID CREATED SIZE
k8s.gcr.io/kube-apiserver v1.23.1 b6d7abedde39 11 days ago 135MB
k8s.gcr.io/kube-proxy v1.23.1 b46c42588d51 11 days ago 112MB
k8s.gcr.io/kube-controller-manager v1.23.1 f51846a4fd28 11 days ago 125MB
k8s.gcr.io/kube-scheduler v1.23.1 71d575efe628 11 days ago 53.5MB
k8s.gcr.io/etcd 3.5.1-0 25f8c7f3da61 7 weeks ago 293MB
k8s.gcr.io/coredns/coredns v1.8.6 a4ca41631cc7 2 months ago 46.8MB
k8s.gcr.io/coredns v1.8.6 a4ca41631cc7 2 months ago 46.8MB
k8s.gcr.io/pause 3.6 6270bb605e12 4 months ago 683kB
接下来需要删除老版本的coredns,由于这两个的IMAGE ID是相同的,因此不能通过ID的形式删除,只能以名字+版本号的方式删除
sudo docker rmi k8s.gcr.io/coredns:v1.8.6
删除后使用sudo docker images查看镜像就是这样就是这样:
REPOSITORY TAG IMAGE ID CREATED SIZE
k8s.gcr.io/kube-apiserver v1.23.1 b6d7abedde39 11 days ago 135MB
k8s.gcr.io/kube-proxy v1.23.1 b46c42588d51 11 days ago 112MB
k8s.gcr.io/kube-controller-manager v1.23.1 f51846a4fd28 11 days ago 125MB
k8s.gcr.io/kube-scheduler v1.23.1 71d575efe628 11 days ago 53.5MB
k8s.gcr.io/etcd 3.5.1-0 25f8c7f3da61 7 weeks ago 293MB
k8s.gcr.io/coredns/coredns v1.8.6 a4ca41631cc7 2 months ago 46.8MB
k8s.gcr.io/pause 3.6 6270bb605e12 4 months ago 683kB
接下来执行sudo kubeadm init再初始化,还是会出现问题:
[init] Using Kubernetes version: v1.23.1
[preflight] Running pre-flight checks
[WARNING Swap]: swap is enabled; production deployments should disable swap unless testing the NodeSwap feature gate of the kubelet
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local ubuntu] and IPs [10.96.0.1 192.168.35.131]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost ubuntu] and IPs [192.168.35.131 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost ubuntu] and IPs [192.168.35.131 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused.
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- 'systemctl status kubelet'
- 'journalctl -xeu kubelet'
Additionally, a control plane component may have crashed or exited when started by the container runtime.
To troubleshoot, list all containers using your preferred container runtimes CLI.
Here is one example how you may list all Kubernetes containers running in docker:
- 'docker ps -a | grep kube | grep -v pause'
Once you have found the failing container, you can inspect its logs with:
- 'docker logs CONTAINERID'
error execution phase wait-control-plane: couldn't initialize a Kubernetes cluster
To see the stack trace of this error execute with --v=5 or higher
解决方案:
在/etc/docker/daemon.json文件中加入"exec-opts": ["native.cgroupdriver=systemd"]一行配置,重启docker,清除一下kubeadm信息即可重新初始化,这个地方记得要加一个逗号哦!
sudo vi /etc/docker/daemon.json
sudo systemctl restart docker

此时执行sudo kubeadm init如果出现如下错误,那么sudo kubeadm reset一下再执行就可以了
[init] Using Kubernetes version: v1.23.1
[preflight] Running pre-flight checks
[WARNING Swap]: swap is enabled; production deployments should disable swap unless testing the NodeSwap feature gate of the kubelet
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
只要看到这个界面就说明集群初始化成功了!
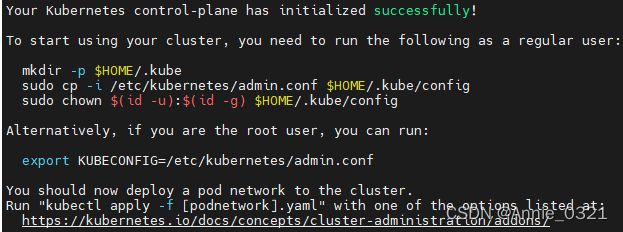
接着,就是按提示创建文件夹等,以及将node节点加入集群
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
节点加入集群需要node节点执行红色箭头所指的这段代码,为了避免大家抄错了我就直接放图了,记得复制自己的!!!
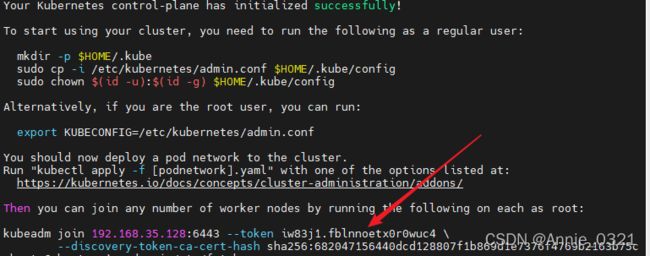
休息一下,还没写完,明天再更……
主要参考:
- Kubernetes官方文档
- 在Ubuntu 20.04上安装K8S环境
- Kubernetes v1.22.1部署报错2:error: Get “http://localhost:10248/healthz“: dial t…
- Kubernetes k8s拉取镜像失败最简单最快最完美解决方法 [ERROR ImagePull]: failed to pull image k8s.gcr.io/kube-apiserver