一文搞懂 Prometheus 多集群监控神器 Thanos
公众号关注 「奇妙的 Linux 世界」
设为「星标」,每天带你玩转 Linux !
1介绍
在本文中,我们将看到Prometheus监控技术栈的局限性,以及为什么移动到基于Thanos的技术栈可以提高指标留存率并降低总体基础设施成本。
用于此演示的内容可以在下面链接中获取,并提交到他们各自的许可证。
https://github.com/particuleio/teks/tree/main/terragrunt/live/thanos
https://github.com/particuleio/terraform-kubernetes-addons/tree/main/modules/aws
2Kubernetes普罗米修斯技术栈
在为我们的客户部署Kubernetes基础设施时,在每个集群上部署监控技术栈是标准做法。这个堆栈通常由几个组件组成:
Prometheus:收集度量标准
告警管理器:根据指标查询向各种提供者发送警报
Grafana:可视化豪华仪表板
简化架构如下:

注意事项
这种架构有一些注意事项,当你想从其中获取指标的集群数量增加时,它的伸缩性以及可扩展性不太好。
多个Grafana
在这种设置中,每个集群都有自己的Grafana和自己的一组仪表板,维护起来很麻烦。
存储指标数据是昂贵的
Prometheus将指标数据存储在磁盘上,你必须在存储空间和指标保留时间之间做出选择。如果你想长时间存储数据并在云提供商上运行,那么如果存储TB的数据,块存储的成本可能会很高。同样,在生产环境中,Prometheus经常使用复制或分片或两者同时运行,这可能会使存储需求增加两倍甚至四倍。
解决方案
多个Grafana数据源
可以在外部网络上公开Prometheus的端点,并将它们作为数据源添加到单个Grafana中。你只需要在Prometheus外部端点上使用TLS或TLS和基本认证来实现安全性。此解决方案的缺点是不能基于不同的数据源进行计算。
Prometheus联邦
Prometheus联邦允许从Prometheus中抓取Prometheus,当你不抓取很多指标数据时,这个解决方案可以很好地工作。在规模上,如果你所有的Prometheus目标的抓取持续时间都比抓取间隔长,可能会遇到一些严重的问题。
Prometheus远程写
虽然远程写入是一种解决方案(也由Thanos receiver实现),但我们将不在本文中讨论“推送指标”部分。你可以在这里[1]阅读关于推送指标的利弊。建议在不信任多个集群或租户的情况下(例如在将Prometheus构建为服务提供时),将指标作为最后的手段。无论如何,这可能是以后文章的主题,但我们将在这里集中讨论抓取。
3Thanos,它来了
Thanos是一个“开源的,高可用的Prometheus系统,具有长期存储能力”。很多知名公司都在使用Thanos,也是CNCF孵化项目的一部分。
Thanos的一个主要特点就是允许“无限”存储空间。通过使用对象存储(比如S3),几乎每个云提供商都提供对象存储。如果在前提环境下运行,对象存储可以通过rook或minio这样的解决方案提供。
它是如何工作的?
Thanos和Prometheus并肩作战,从Prometheus开始升级到Thanos是很常见的。
Thanos被分成几个组件,每个组件都有一个目标(每个服务都应该这样:)),组件之间通过gRPC进行通信。
Thanos Sidecar

Thanos和Prometheus一起运行(有一个边车),每2小时向一个对象存储库输出Prometheus指标。这使得Prometheus几乎是无状态的。Prometheus仍然在内存中保存着2个小时的度量值,所以在发生宕机的情况下,你可能仍然会丢失2个小时的度量值(这个问题应该由你的Prometheus设置来处理,使用HA/分片,而不是Thanos)。
Thanos sidecar与Prometheus运营者和Kube Prometheus栈一起,可以轻松部署。这个组件充当Thanos查询的存储。
Thanos存储
Thanos存储充当一个网关,将查询转换为远程对象存储。它还可以在本地存储上缓存一些信息。基本上,这个组件允许你查询对象存储以获取指标。这个组件充当Thanos查询的存储。
Thanos Compactor
Thanos Compactor是一个单例(它是不可扩展的),它负责压缩和降低存储在对象存储中的指标。下采样是随着时间的推移对指标粒度的宽松。例如,你可能想将你的指标保持2年或3年,但你不需要像昨天的指标那么多数据点。这就是压缩器的作用,它可以在对象存储上节省字节,从而节省成本。
Thanos Query
Thanos查询是Thanos的主要组件,它是向其发送PromQL查询的中心点。Thanos查询暴露了一个与Prometheus兼容的端点。然后它将查询分派给所有的“stores”。记住,Store可能是任何其他提供指标的Thanos组件。Thanos查询可以发送查询到另一个Thanos查询(他们可以堆叠)。
Thanos Store
Thanos Sidecar
Thanos Query
还负责对来自不同Store或Prometheus的相同指标进行重复数据删除。例如,如果你有一个度量值在Prometheus中,同时也在对象存储中,Thanos Query可以对该指标值进行重复数据删除。在Prometheus HA设置的情况下,重复数据删除也基于Prometheus副本和分片。

点击上方图片,打开小程序,『饿了么外卖』红包天天免费领!
Thanos Query Frontend
正如它的名字所暗示的,Thanos查询前端是Thanos查询的前端,它的目标是将大型查询拆分为多个较小的查询,并缓存查询结果(在内存或memcached中)。
还有其他组件,比如在远程写的情况下接收Thanos,但这仍然不是本文的主题。
4多集群架构
有多种方法可以将这些组件部署到多个Kubernetes集群中,根据用例的不同,有些方法比其他方法更好,在这里我们不能给出详细的介绍。
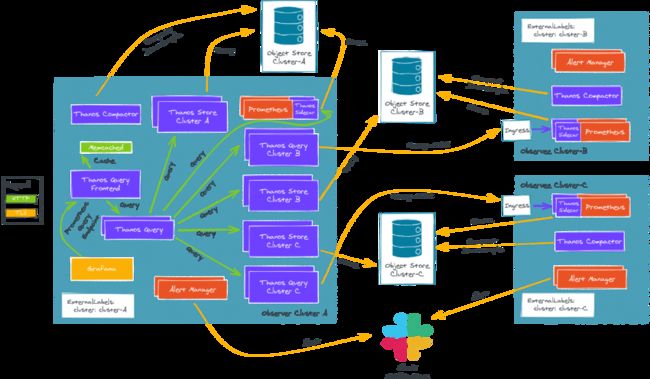
我们的例子是在AWS上运行,使用tEKS[2]部署了2个集群,我们的all in one解决方案将生产就绪的EKS集群部署在AWS上:
一个观察者集群[3]
一个被观察集群[4]
我们的部署使用了官方的kube-prometheus-stack和bitnami thanos图表。
一切都是在我们的terraform-kubernetes-addons存储库中策划的。
Thanos demo文件夹中的目录结构如下:
.
├── env\_tags.yaml
├── eu-west-1
│ ├── clusters
│ │ └── observer
│ │ ├── eks
│ │ │ ├── kubeconfig
│ │ │ └── terragrunt.hcl
│ │ ├── eks-addons
│ │ │ └── terragrunt.hcl
│ │ └── vpc
│ │ └── terragrunt.hcl
│ └── region\_values.yaml
└── eu-west-3
├── clusters
│ └── observee
│ ├── cluster\_values.yaml
│ ├── eks
│ │ ├── kubeconfig
│ │ └── terragrunt.hcl
│ ├── eks-addons
│ │ └── terragrunt.hcl
│ └── vpc
│ └── terragrunt.hcl
└── region\_values.yaml这允许DRY(Don 't Repeat Yourself)基础设施,并可以轻松地扩展AWS帐户、区域和集群的数量。
观察者集群
观察者集群是我们的主集群,我们将从它查询其他集群:
Prometheus正在运行:
Grafana启用
Thanos边车上传到特定的桶
kube-prometheus-stack = \{
enabled = true
allowed\_cidrs = dependency.vpc.outputs.private\_subnets\_cidr\_blocks
thanos\_sidecar\_enabled = true
thanos\_bucket\_force\_destroy = true
extra\_values = \<\<-EXTRA\_VALUES
grafana:
deploymentStrategy:
type: Recreate
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: nginx
cert-manager.io/cluster-issuer: "letsencrypt"
hosts:
- grafana.\$\{local.default\_domain\_suffix\}
tls:
- secretName: grafana.\$\{local.default\_domain\_suffix\}
hosts:
- grafana.\$\{local.default\_domain\_suffix\}
persistence:
enabled: true
storageClassName: ebs-sc
accessModes:
- ReadWriteOnce
size: 1Gi
prometheus:
prometheusSpec:
replicas: 1
retention: 2d
retentionSize: "10GB"
ruleSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
podMonitorSelectorNilUsesHelmValues: false
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: ebs-sc
accessModes: \["ReadWriteOnce"\]
resources:
requests:
storage: 10Gi
EXTRA\_VALUES为观察者集群生成一个CA证书:
这个CA将被进入sidecar的被观察集群所信任
为Thanos querier组件生成TLS证书,这些组件将查询被观察集群
Thanos组件部署:
Thanos组件全部部署完成
查询前端,作为Grafana的数据源端点
存储网关用于查询观察者桶
Query将对存储网关和其他查询器执行查询
部署的额外Thanos组件:
配置了TLS的Thanos查询器对每个被观察集群进行查询
thanos-tls-querier = \{
"observee" = \{
enabled = true
default\_global\_requests = true
default\_global\_limits = false
stores = \[
"thanos-sidecar.\$\{local.default\_domain\_suffix\}:443"
\]
\}
\}
thanos-storegateway = \{
"observee" = \{
enabled = true
default\_global\_requests = true
default\_global\_limits = false
bucket = "thanos-store-pio-thanos-observee"
region = "eu-west-3"
\}被观测集群
被观测集群是Kubernetes集群,具有最小的Prometheus/Thanos安装,将被观测集群查询。
Prometheus operator正在运行:
Thanos这边就是上传给观察者特定的桶
Thanos边车与TLS客户端认证的入口对象一起发布,并信任观察者集群CA
kube-prometheus-stack = \{
enabled = true
allowed\_cidrs = dependency.vpc.outputs.private\_subnets\_cidr\_blocks
thanos\_sidecar\_enabled = true
thanos\_bucket\_force\_destroy = true
extra\_values = \<\<-EXTRA\_VALUES
grafana:
enabled: false
prometheus:
thanosIngress:
enabled: true
ingressClassName: nginx
annotations:
cert-manager.io/cluster-issuer: "letsencrypt"
nginx.ingress.kubernetes.io/ssl-redirect: "true"
nginx.ingress.kubernetes.io/backend-protocol: "GRPC"
nginx.ingress.kubernetes.io/auth-tls-verify-client: "on"
nginx.ingress.kubernetes.io/auth-tls-secret: "monitoring/thanos-ca"
hosts:
- thanos-sidecar.\$\{local.default\_domain\_suffix\}
paths:
- /
tls:
- secretName: thanos-sidecar.\$\{local.default\_domain\_suffix\}
hosts:
- thanos-sidecar.\$\{local.default\_domain\_suffix\}
prometheusSpec:
replicas: 1
retention: 2d
retentionSize: "6GB"
ruleSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
podMonitorSelectorNilUsesHelmValues: false
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: ebs-sc
accessModes: \["ReadWriteOnce"\]
resources:
requests:
storage: 10Gi
EXTRA\_VALUESThanos组件部署:
Thanos压缩器来管理这个特定集群的下采样
thanos = \{
enabled = true
bucket\_force\_destroy = true
trusted\_ca\_content = dependency.thanos-ca.outputs.thanos\_ca
extra\_values = \<\<-EXTRA\_VALUES
compactor:
retentionResolution5m: 90d
query:
enabled: false
queryFrontend:
enabled: false
storegateway:
enabled: false
EXTRA\_VALUES
\}5再深入一点
让我们检查一下集群上正在运行什么。关于观察员,我们有:
$ kubectl -n monitoring get pods
NAME READY STATUS RESTARTS AGE
alertmanager-kube-prometheus-stack-alertmanager-0 2/2 Running 0 120m
kube-prometheus-stack-grafana-c8768466b-rd8wm 2/2 Running 0 120m
kube-prometheus-stack-kube-state-metrics-5cf575d8f8-x59rd 1/1 Running 0 120m
kube-prometheus-stack-operator-6856b9bb58-hdrb2 1/1 Running 0 119m
kube-prometheus-stack-prometheus-node-exporter-8hvmv 1/1 Running 0 117m
kube-prometheus-stack-prometheus-node-exporter-cwlfd 1/1 Running 0 120m
kube-prometheus-stack-prometheus-node-exporter-rsss5 1/1 Running 0 120m
kube-prometheus-stack-prometheus-node-exporter-rzgr9 1/1 Running 0 120m
prometheus-kube-prometheus-stack-prometheus-0 3/3 Running 1 120m
thanos-compactor-74784bd59d-vmvps 1/1 Running 0 119m
thanos-query-7c74db546c-d7bp8 1/1 Running 0 12m
thanos-query-7c74db546c-ndnx2 1/1 Running 0 12m
thanos-query-frontend-5cbcb65b57-5sx8z 1/1 Running 0 119m
thanos-query-frontend-5cbcb65b57-qjhxg 1/1 Running 0 119m
thanos-storegateway-0 1/1 Running 0 119m
thanos-storegateway-1 1/1 Running 0 118m
thanos-storegateway-observee-storegateway-0 1/1 Running 0 12m
thanos-storegateway-observee-storegateway-1 1/1 Running 0 11m
thanos-tls-querier-observee-query-dfb9f79f9-4str8 1/1 Running 0 29m
thanos-tls-querier-observee-query-dfb9f79f9-xsq24 1/1 Running 0 29m
$ kubectl -n monitoring get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
kube-prometheus-stack-grafana \ grafana.thanos.teks-tg.clusterfrak-dynamics.io k8s-ingressn-ingressn-afa0a48374-f507283b6cd101c5.elb.eu-west-1.amazonaws.com 80, 443 123m 被观察者:
$ kubectl -n monitoring get pods
NAME READY STATUS RESTARTS AGE
alertmanager-kube-prometheus-stack-alertmanager-0 2/2 Running 0 39m
kube-prometheus-stack-kube-state-metrics-5cf575d8f8-ct292 1/1 Running 0 39m
kube-prometheus-stack-operator-6856b9bb58-4cngc 1/1 Running 0 39m
kube-prometheus-stack-prometheus-node-exporter-bs4wp 1/1 Running 0 39m
kube-prometheus-stack-prometheus-node-exporter-c57ss 1/1 Running 0 39m
kube-prometheus-stack-prometheus-node-exporter-cp5ch 1/1 Running 0 39m
kube-prometheus-stack-prometheus-node-exporter-tnqvq 1/1 Running 0 39m
kube-prometheus-stack-prometheus-node-exporter-z2p49 1/1 Running 0 39m
kube-prometheus-stack-prometheus-node-exporter-zzqp7 1/1 Running 0 39m
prometheus-kube-prometheus-stack-prometheus-0 3/3 Running 1 39m
thanos-compactor-7576dcbcfc-6pd4v 1/1 Running 0 38m
$ kubectl -n monitoring get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
kube-prometheus-stack-thanos-gateway nginx thanos-sidecar.thanos.teks-tg.clusterfrak-dynamics.io k8s-ingressn-ingressn-95903f6102-d2ce9013ac068b9e.elb.eu-west-3.amazonaws.com 80, 443 40m我们的TLS查询器应该能够查询被观测集群的度量标准。让我们来看看它们的行为:
$ k -n monitoring logs -f thanos-tls-querier-observee-query-687dd88ff5-nzpdh
level=info ts=2021-02-23T15:37:35.692346206Z caller\=storeset.go:387 component=storeset msg="adding new storeAPI to query storeset" address=thanos-sidecar.thanos.teks-tg.clusterfrak-dynamics.io:443 extLset="\{cluster=\\"pio-thanos-observee\\", prometheus=\\"monitoring/kube-prometheus-stack-prometheus\\", prometheus\_replica=\\"prometheus-kube-prometheus-stack-prometheus-0\\"\}"所以这个查询器pods可以查询我的其他集群,如果我们检查Web,我们可以看到存储:
$ kubectl -n monitoring port-forward thanos-tls-querier-observee-query-687dd88ff5-nzpdh 10902
太棒了,但是我只有一个存储,还记得我们说过查询器可以堆叠在一起吗?在我们的观察者集群中,我们有标准的http查询器,它可以查询架构图中的其他组件。
$ kubectl -n monitoring port-forward thanos-query-7c74db546c-d7bp8 10902这里我们可以看到所有的存储已经被添加到我们的中心查询器:
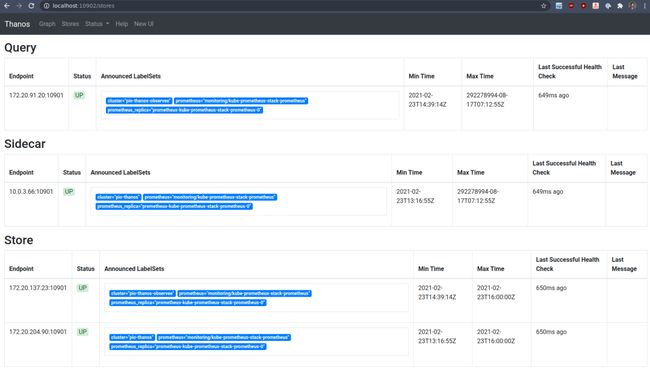
观察者把本地Thanos聚集
我们的存储网关(一个用于远程观测者集群,一个用于本地观测者集群)
本地TLS查询器,它可以查询被观察的sidecar
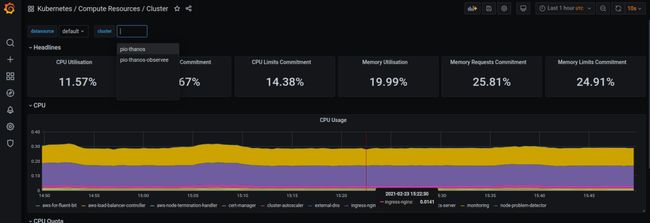
6在Grafana可视化
最后,我们可以前往Grafana,看看默认的Kubernetes仪表板是如何与多集群兼容的。
7总结
Thanos是一个非常复杂的系统,有很多移动部件,我们没有深入研究具体的自定义配置,因为它会花费太多的时间。
我们在tEKS存储库中提供了一个相当完整的AWS实现,它抽象了很多复杂性(主要是mTLS部分),并允许进行很多定制。你也可以使用terraform-kubernetes-addons模块作为独立的组件。我们计划在未来支持其他云提供商。不要犹豫,通过Github上的任何一个项目的问题联系我们。
根据你的基础设施和需求,有许多可能适合你的Thanos实现。
如果你想深入研究Thanos,可以查看他们的官方kube-thanos存储库,以及他们关于跨集群通信的建议[5]。
当然,我们很乐意帮助你设置你的云原生监控堆栈,欢迎联系我们 [email protected]:)
你也可以每天通过CNCF/Kubernetes Slack频道联系我们。
相关链接:
https://docs.google.com/document/d/1H47v7WfyKkSLMrR8_iku6u9VB73WrVzBHb2SB6dL9_g/edit#heading=h.2v27snv0lsur
https://github.com/particuleio/teks
https://github.com/particuleio/teks/tree/main/terragrunt/live/thanos/eu-west-1/clusters/observer
https://github.com/particuleio/teks/tree/main/terragrunt/live/thanos/eu-west-3/clusters/observee
https://thanos.io/tip/operating/cross-cluster-tls-communication.md/
原文链接:https://particule.io/en/blog/thanos-monitoring/
本文转载自:「分布式实验室」,原文:https://tinyurl.com/525bbzvc,版权归原作者所有。欢迎投稿,投稿邮箱: [email protected]。

![]()
你可能还喜欢
点击下方图片即可阅读

5 分钟搞懂高性能分布式消息系统 Kafka
『美团|饿了么』外卖红包天天免费领,吃饭省钱杠杠滴!

更多有趣的互联网新鲜事,关注「奇妙的互联网」视频号全了解!