导读:
近些年随着云计算和云原生应用的兴起,容器技术可以很好地解决许多问题,所以将大数据平台容器化是一种理想的方案。本文将结合袋鼠云数栈在Flink on Kubernetes的实践让您对大数据平台容器化的操作和价值有初步的了解。
你可以看到
▫ Kubernetes如何解决Hadoop痛点
▫ 数栈在Flink on K8S的实践
▫ 容器化之后的未来设想:资源池化
作者 / 雅泽、狗焕
编辑 / 向山
引言
在过去的很长一段时间,大数据领域中构建可扩展的分布式应用框架中,Apache Hadoop占据的是绝对的统治地位。
目前绝大多数大数据平台都是基于Hadoop生态构建,使用YARN作为核心组件进行资源管理与资源调度,但是这些大数据平台普遍都会存在资源隔离性差、资源利用率低等问题,与此同时近些年随着云计算和云原生应用的兴起,容器技术可以很好地解决这些问题。
所以将大数据平台容器化是一种理想的方案,本文将结合袋鼠云数栈在Flink on Kubernetes的实践让您对大数据平台容器化的操作和价值有初步的了解。
Hadoop痛点频现,亟待解决
大数据平台顾名思义就是处理急速增长的实时、离线数据的大规模应用程序,所以设计大数据平台的解决方案的需要考虑的首要问题就是如何确定生产环境中大数据平台的部署架构,使得平台具有紧密联系数据、应用程序与基础设施之间的能力。
Hadoop主要提供了三个关键功能:资源管理器(YARN)、数据存储层(HDFS)、计算范式(MapReduce),市面上大多数大数据平台都是基于Hadoop生态构建的,但是这类型的平台会存在下列问题:
资源弹性不足
大数据系统的资源使用高峰是具有周期性的,不同业务线在一天中的高峰期是不一样的,当业务压力增大时,当前的大数据系统普遍缺乏资源弹性伸缩的能力,无法按需进行快速扩容,为了应对业务高峰只能预留出足够的资源保证任务正常运行;
资源利用率低
存储密集型的业务存储资源使用较高而CPU使用率长期处于较低的水平,计算密集型的业务虽然CPU使用率相对较高但是存储的使用率非常低,大量资源闲置;
资源隔离性差
从Hadoop2.2.0开始,YARN开始使用cgroup实现了CPU资源隔离,通过JVM提供的内存隔离机制来实现内存资源隔离,整体上来看YARN的资源隔离做的并不完善,会造成多个任务运行到同一个工作节点上时,不同任务会出现资源抢占的情况。
Kubernetes风头正劲,完美解决Hadoop痛点
Kubernetes是谷歌开源的生产级的容器编排系统,是建立在谷歌大规模运行生产工作负载方面的十几年的经验基础上的,而且拥有一个庞大且快速增长的生态系统,伴随着微服务、DevOps、持续交付等概念的兴起和持续发酵,并依托与云原生计算基金会(CNCF),Kubernetes保持着高速发展。
如下图所示,Google过去五年对于Kubernetes和Apache Hadoop热度统计结果展示表明市面上对Kubernetes的热情逐渐高涨而对Hadoop热度逐渐减退。

那么,Kubernetes是如何解决Hadoop存在的痛点的呢,我们一一分析一下。
解决资源弹性不足
对于资源弹性不足的问题,Kubernetes本身就是设计为一个利用模块化架构来进行扩展的系统,对用户来说,服务进行扩容只需要修改配置文件中容器的副本数或者是使用Pod水平自动扩缩(HPA),将应用扩缩容的复杂度交给Kubernetes控制可以极大减少人为介入的成本。HPA是基于CPU使用率、内存使用率或其他实时采集的性能指标自动扩缩ReplicationController、Deployment和ReplicaSet中的Pod数量。
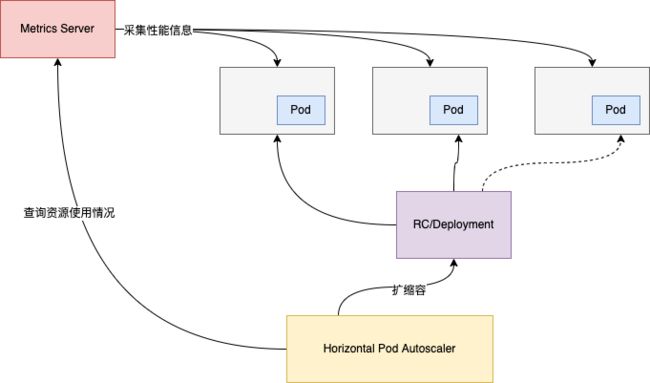
Kubernetes中的Metrics Server会持续采集所有Pod副本的性能指标信息,HPA控制器通过Metrics Server的API获取这些数据,并根据用户设置的自动扩缩容规则计算目标Pod副本数量,当目标Pod数量与当前Pod数量不一致时,HPA控制器就向Pod的副本控制器发起扩缩容操作,调整Pod数量,完成扩缩容操作。
解决资源使用率低
对于资源使用率低的问题,一方面Kubernetes支持更加细粒度的资源划分,这样可以尽量做到资源能用尽用,最大限度的按需使用。另外一方面支持更加灵活的调度,并根据业务SLA的不同,业务高峰的不同,通过资源的混合部署来进一步提升资源使用率。
解决资源隔离性差
对于资源隔离性差的问题,容器技术本身是具有资源隔离的能力的,底层使用Linux namespace进行资源隔离,它将全局系统的资源包裹在一个抽象层中,使得在每个 namespace 内部的进程看起来自己都拥有一个独立的全局资源。
同一个 namespace 下的资源变化对于同一 namespace 的进程是可见的,但是对于不同namespace下的进程是不可见的。为了能够让容器不占用其它容器的资源(或者说确定每个容器的“硬件”配置),采用cgroups来限制单个进程或者多个进程所使用资源的机制,可以对 cpu,内存等资源实现精细化的控制。

Flink on K8S实践,数栈研究小成
正因为大数据组件容器化优势明显,数栈使用的大数据计算和存储组件均预期往容器化方向排布。
在数栈目前使用的众多组件中,我们首先选择在k8s上尝试实践的是数栈流计算引擎——Flink 。经过研究布设,现在数栈的流计算容器化转换已经基本实现。接下来是一些Flink on K8S的经验分享:
Flink on K8S概述
目前在K8S中执行Flink任务的方式有两种,一种是Standalone,一种是原生模式:Flink native session 模式、Flink native per-job 模式,它们各自对应的优缺点如下:
Flink Standalone模式:
● 优点:优点是无需修改 Flink 源码,仅仅只需预先定义一些 yaml 文件,集群就可以启动,互相之间的通信完全不经过 K8s Master;
● 缺点:缺点是资源需要预先申请无法动态调整。
Flink native session 模式:
● 优点:taskManager 的资源是实时的、按需进行的创建,对资源的利用率更高,所需资源更精准。
● 缺点:taskManager 是实时创建的,用户的作业真正运行前, 与 Per Job集群一样, 仍需要先等待 taskManager 的创建, 因此对任务启动时间比较敏感的用户,需要进行一定的权衡。
Flink native per-job 模式:
● 优点:资源按需申请,适合一次性任务,任务执行后立即释放资源,保证了资源的利用率;
● 缺点:资源是在任务提交后开始创建,同样意味着对于提交任务后对延时比较敏感的场景,需要一定的权衡;
数栈Flink Standalone on K8S实践
接下来我们以standalone模式容器化为切入点介绍下我们的一些实践。
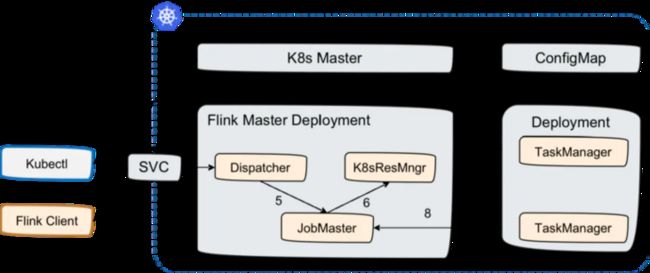
我们通过自定义的资源对象来定义我们应用的相关部署属性,然后将这个yaml文件和所需的配置文件以及镜像打包上传到easymanager平台(后续会将其开源)进行一键部署。这里对于应用整体状态的处理大致如下:
● 对于配置:这里我们把应用的涉及到的状态数据都提炼到应用的配置变成k8s中的configmap,通过该配置作为统一的修改入口。同时分离出jobmanager和taskmanager的配置使两者对各自状态进行维护互不干扰。
● 对于存储:分离存储状态,可采用pvc来声明我们所需要的存储类型(storageclass),或者我们可以在镜像中内置一个hdfs的client或者s3插件来直接对接客户现场的环境,这里我们是将hdfs client和s3的插件包封装到了flink的镜像中,然后通过上面提取出的配置来进行控制对应的存储对接。
● 对于集群状态信息:我们在部署flink的时候我们会部署好基础组件包,如zookeeper、redis、mysql等,同样也能通过上面提取的配置参数进行修改对接外部基础组件。
实践如下:
1) 定义我们自定义资源描述:
flink社区拥有大量的插件供我们使用,通过这些插件我们能扩展一些需要的能力,但是将这些插件都打包到镜像中,那么这个镜像体积势必会变得非常大,这里我们将这些插件单独抽离出来做成一个单独的基础服务组件,然后通过我们的业务镜像去引用这些基础组件,在引用这些基础组件后会以sidecar形式注入到我们的业务容器中完成目录绑定,从而实现按需索取也减小了镜像体积的大小。

上面对应资源描述了在k8s上应用最基本的部署能力,这里我们还需要将公共配置进行映射,然后将这些配置暴露到前端。通过这个统一的配置修改入口简化了交付人员对配置文件的筛查和修改。
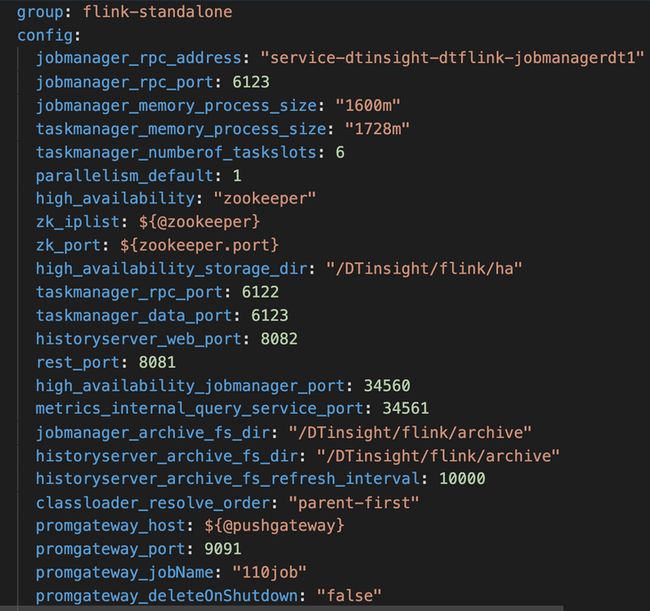
2) 自动化出包:
我们在定义好资源对象的描述后,根据定义的资源描述文件将需要的配置提取以及编写应用需要的相关属性,将这些内容放到一个yaml文件中,同时编写dockerfile、启动脚本、编写jenkinsfile接入自动化出包流程,最后出包验证。通过分工合作这样一来就能将内部原先大量人工的操作全部自动流程化,提高效率。
3) 部署:
完成部署后的结果如下:

通过点击“服务扩缩容”,我们可以一键扩缩taskmanager的计算资源:
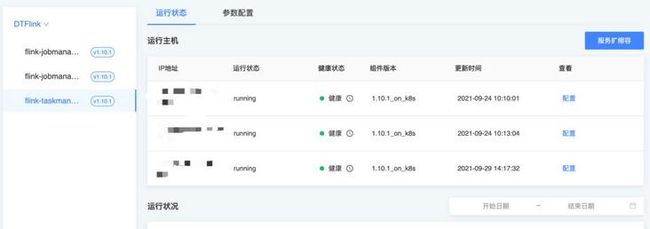
然后我们可以通过k8s的ingress资源对象暴露的地址来访问flink的ui进行后续flink集群的运维操作。

通过以上flink standalone容器化我们简化了主机模式下flink的部署、资源管理划分等问题。那么对于应用日志收集和监控,我们采用的是loki和prometheus的动态服务发现。
容器之后,数栈走向何方
尽管Kubernetes能够解决传统Hadoop生态存在的一些痛点问题,但是距离它能真正成为一个部署大数据应用切实可行的平台还是有很长的一段路要走的:比如为短生命周期与无状态应用设计的容器技术、不同job之间缺少共享的持久化存储以及大数据平台关心的调度、安全以及网络相关问题还需要更好的解决方案。现在,数栈正积极参与开源社区,帮助 Kubernetes 能成为部署大数据应用程序的实用选择。
对于数栈而言,基于存算分离的设计理念,使用Kubernetes解决了计算资源弹性扩展的问题后,由于计算资源与存储资源的分离,可能会出现计算性能降低、存储的弹性无法保证等问题。未来我们会考虑在存储层使用对象存储,整体架构在计算和底层存储之间加上一层缓存(比如JuiceFS和Alluxio),存储层选型在OpenStack Swift、Ceph、MinIO等成熟的开源方案中。
容器之后,我们并未停下脚步,关于未来我们有很多在考虑的设想,比如利用云化或者云原生技术统一管理资源池,实现大数系统产品、计算、存储资源池化,实现全局化、集约化的调度资源等等,技术在迭代,我们的自我革新也从未停止。
开源项目技术交流
ChunJun
https://github.com/DTStack/ch...
https://gitee.com/dtstack_dev...
Taier
https://github.com/DTStack/Taier
https://gitee.com/dtstack_dev...
MoleCule
https://github.com/DTStack/mo...
https://gitee.com/dtstack_dev...
欢迎加入开源框架技术交流群
(钉钉群:30537511)