Python基础学习笔记
Python基础学习笔记
- 计算机组成和Python基础知识
-
- 计算机组成
- 计算机如何处理程序
- 编程语言
- 认识Python
- 第一个Python程序
- 注释
- 变量以及类型
- 标识符和关键字
- 输出
- 输入
- 类型转换
- 运算符
- 判断语句和循环语句
-
- if判断语句基本格式
- if else 结构
- if elif 结构
- if嵌套
- 三目运算符
- while循环
- while循环嵌套
- for循环
- for循环嵌套
- break 和continue
- 循环else结构
- 容器
-
- 字符串
- 列表
- 元组
- 字典
- 函数
-
- 定义和调用
- 函数的文档说明
- 函数的参数
- 局部变量
- 全局变量
- 函数的返回值
- 函数的嵌套调用
- 函数传参的两种方式
- 函数形参
- 函数形参的完整格式
- 拆包
- 引用
- 递归函数
- 匿名函数
- 列表推导式
- 文件
-
- 读文件
- 写文件
- 文件打开模式
- 文件备份
- 文件和目录操作
- 面向对象基础
-
- 介绍
- 类和对象
- 类的定义
- 创建对象
- 类外部添加和获取对象属性
- 类内部的操作
- 魔法方法
- 烤地瓜案例
- 继承
- 多态
- 异常
-
- 概念
- 捕获单个异常
- 捕获多个异常
- 打印异常信息
- 捕获所有异常
- 异常的完整结构
- 异常的传递
- 抛出自定义异常
- 模块
- 包
计算机组成和Python基础知识
计算机组成
由硬件系统和软件系统组成
- 硬件系统:
主机部分:CPU、内存
外设部分:输入设备、输出设备、外存储器 - 软件系统:
系统软件:操作系统、驱动程序、语言处理程序、数据库管理系统等
应用软件:浏览器、文本编译器等 - 冯诺依曼体系结构:
运算器、控制器、存储器、输入设备、输出设备
计算机如何处理程序
- 用户打开程序,程序开始执行
- 操作系统将程序内容和相关数据送入计算机的内存
- CPU根据程序内容从内存中读取指令
- CPU分析、处理指令,并为取下一次指令做准备
- 取下一条指令并分析、处理,如此重复操作,直到执行完陈旭中全部指令,最后将计算的结果放入指令指定的存储器地址中
编程语言
计算机只认识0和1
人类和计算机交流的语言
常见的编程语言:python, C ,C++ ,java
认识Python
作者:Guido van Rossum(龟叔) 1991年
Python 解释器:将Python代码,翻译成计算机认识的二进制代码
解释型语言:代码的执行,从上到下,依次解释执行(边解释边执行)
编译型语言:将源代码编译成一个可执行程序(二进制代码程序)[更快]
优点:简单、易学、免费、开源、高层语言、可移植性、解释型语言、面向对象、可扩展性、丰富的库、规范的代码
缺点:执行效率慢
应用:web开发、运维、网络爬虫、科学计算、桌面软件、服务器软件、游戏
第一个Python程序
python:Python解释器
pycharm:IDE(集成开发环境),集成写代码,运行代码、代码调试等功能
print(‘hello world!’)

注释
对程序代码进行解释说明,注释不会执行
单行注释: #
多行注释:三个单引号或双引号’’’ … ‘’’ , “”" … “”"
变量以及类型
- 变量的定义和使用
# 变量:内存地址的别名 作用,用来存储数据
# 在程序中想要存储数据,就想要使用变量
# 变量的定义:变量名 = 数据值 变量名需要遵循标识符定义规则
# 定义一个变量name ,变量name 中存储的数据是 'isaac'
name = 'isaac'
# 定义一个变量age,变量age中存储的数据值是 18
age = 18
# 使用变量中的值,直接使用变量即可
# 使用print函数打印输出name变量中存储的数据值
print(name)
print(age)
# 修改变量中的数据值 变量名 = 新的数据值
# 将19这个数据存储到变量age中
age = 19
print(age)
- 变量的类型

# 变量的数据类型,由变量中存储的数据决定的
# 可以使用type()函数得到变量的数据类型,想要进行输出,需要使用print函数
# int
result = 10
# 1. 先使用type()函数获得变量result的数据类型
# 2.使用print()打印
print(type(result)) # 标识符和关键字
规则:
由字母、下划线和数字组成,不能由数字开头
标识符区分大小写
关键字:
系统定义好的,具有特殊功能的标识符
输出
格式化输出
占位符:

# 在Python中输出使用print函数
# 基本输出
print('hello')
print(123)
# 一次输出多个内容
print('isaac',18) # 会输出isaac和18,两者之间使用空格隔开
# 可以书写表达式
print(1 + 2) # 会输出 1 + 2 的结果3
# 格式化输出,格式化占位符,%s 字符串 ,%d int 整数 %f 小数浮点数float
name = 'isaac'
# 需求:输出 我的名字是XXX,我很开心
print('我的名字是%s,我很开心。' % name)
age = 18
# 需求:输出 我的年龄是18岁
print('我的年龄是%d' % age)
height = 170.5
# %f 输出小数,默认保留6位小数
print('我的身高是%f' % height) # CtrL d 快速复制一行代码 ,shift+enter 下方新建一行代码
# %.nf 保留n位小数
print('我的身高是%.2f' % height)
# 输出50% 使用格式化输出时候,想要输出一个%,需要使用两个%
print('及格人数占比为%d%%' % 50)
# Python3.6版本开始支持 f-string,占位统一使用{}占位,填充直接写在{}里
print(f"我的名字是{name},我很开心。")

输入
input()
# 输入:从键盘获取输入内容,存入计算机程序中
# 在Python中使用的是input()函数
# input('给用户的提示信息'),得到用户输入的内容,回车结束,得到的数据都是字符串类型
# password = input() # input()不写内容,语法不会出错,但是非常不友好
password = input('请输入密码:')
print('你输入的密码是%s' % password)
类型转换
# 类型转换,将原始数据转换为我们需要的数据类型,在这个过程中,不会改变原始的数据,会
# 生成一个新的数据
# 1. 转换为int类型 int(原始数据)
# 1.1 float类型的数据 转换为int
pi = 3.14
num = int(3.14)
print(type(pi)) # float
print(type(num)) # int
# 1.2 整数类型的字符串,"10"
my_str = '10'
num1 = int(my_str)
print(type(my_str)) # str
print(type(num1)) # int
# 2. 转换为float类型
# 2.1 int---->float
num2 = 10
num3 = float(num2)
print(type(num2)) # int
print(type(num3)) # float
# 2.2 将数字类型字符串转换为 float "10" "3.14"
num4 = float("3.14")
num5 = float("10")
print(type(num4)) # float
print(type(num5)) # float
# eval() 还原原来的数据类型 去掉字符串的引号
num6 = eval('100') # 100 int
num7 = eval('3.14') # 3.14 float
运算符
- 算术运算符

- 复合赋值运算符
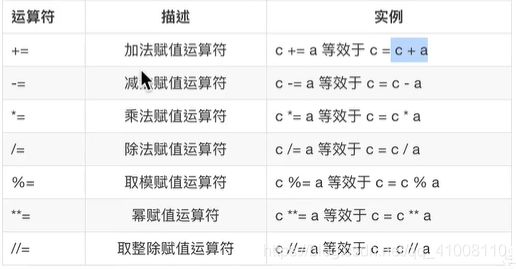
- 比较运算符

- 逻辑运算符

判断语句和循环语句
if判断语句基本格式

使用缩进,代替代码的层级关系,在if语句的缩进内,属于if语句的代码块
# 判断是否成年
age = input('请输入你的年龄:')
age = int(age)
if age >= 18:
print('成年了')
if else 结构

age = input('请输入你的年龄')
age = int(age)
if age >= 18:
print('成年了!')
else:
print('未成年!')
Debug调试
步骤:
- 打断点
- debug运行代码
- 点击 下一步 查看代码执行过程
if elif 结构

score = eval(input('请输入你的成绩:'))
# 简单成绩判断
if score >= 90:
print('优秀')
elif (score >= 80) and (score < 90):
print('良好')
elif score >= 60:
print('及格')
else:
print('不及格')
if嵌套


# 假设money >=2 可以上车
money = int(input('请输入你拥有的零钱:'))
# 1.有钱可以上车
if money >= 2:
print('我上车了')
seat = int(input('车上的空座位数'))
# 3.有空座位,可以做
if seat >= 1:
print('有座位坐')
else:
# 4.没有空座位,就站着
print('没有座位,只能站着')
else:
# 2.没有钱不能上车,走路
print('没钱,我只能走路')

三目运算符

a = int(input('请输入一个数字:'))
b = int(input('请输入一个数字:'))
result = a - b if a >= b else b - a
print(result)

while循环

# 使用print输出模拟跑一圈
i = 0
while i < 5:
print('操场跑圈中')
i += 1
print('跑圈完毕!')
![]()
while循环嵌套

# 操场跑圈,一共跑5圈
# 每跑一圈,需要做3个俯卧撑
i = 0
while i < 5:
j = 0
print('操场跑圈中')
while j < 3:
print('做了一个俯卧撑')
j += 1
i += 1
for循环

for i in 'hello':
# i 一次循环是字符串中的一个字符
print(i)
# range(n) 会生成[0,n)的整数序列,不包含 n
for i in range(5): # 0 1 2 3 4
print(i)
# range(a,b) 会生成[a,b)的整数序列,不包含 b
for i in range(3,7): # 3 4 5 6
print(i)
# range(a,b,step) 会生成[a,b)的整数序列,每个数字之间的间隔是step
for i in range(1,10,3): # 1 4 7
print(i)
for循环嵌套
# 操场跑圈,一共跑5圈
for i in range(5):
print('操场跑圈中')
# 每跑一圈,需要做3个俯卧撑
for j in range(3):
print('做俯卧撑')
break 和continue

# 5个苹果
# 1.吃了三个苹果,吃饱了,后续的苹果不吃了
# 2.吃了三个苹果之后,在吃第四个苹果的时候发现了虫子,这个苹果不吃了,吃下一个苹果
#break
for i in range(1,6):
if i == 4:
print('吃饱了,不吃了')
break # 终止循环的执行
print(f'正在吃标号为{i}的苹果')
# continue
for i in range(1,6):
if i == 4:
print('发现虫子,这个苹果不吃了,继续吃剩余的')
continue
print(f'吃了编号为{i}的苹果')
循环else结构

my_str = 'hello python!'
for i in my_str:
if i == 'p':
print('包含P这个字符')
break
else:
print('不包含p这个字符')
容器
字符串
- 定义:


- 输入和输出

- 下标和切片
# 下标是一个整型数字,可以是整数也可是是负数
# 正数下标从0开始,表示第一个字符 -1,表示最后一个字符
my_str = 'hello'
# 下标使用的语法 变量[下标]
print(my_str[0])
print(my_str[1])
print(my_str[-1])
print(my_str[-3])
# len()函数可以获得字符串的长度
print(len(my_str))
# 使用正数下标书写字符串最后一个元素
结果
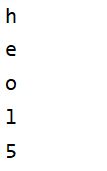
切片
# 切片可以获得一段数据
# 切片语法: 变量[start:end:step]
# start 开始位置的下标
# end 结束位置的下标,不包含end 对应的下标
# step 步长 下标之间的间隔位置,默认是1
my_str = 'hello'
my_str1 = my_str[2:4:1] # ll
print(my_str1)
# step 如果是1,即默认值,可以不写
my_str2 = my_str[2:4] # ll
print(my_str2)
# end 位置不写,表示len(),即可以收到最后一个元素
my_str3 = my_str[2:] # llo
print(my_str3)
# start 位置也可以省略 ,表示是0
my_str4 = my_str[:3] # hel
print(my_str4)
# start 和 end 都不写,但是冒号需要写
my_str5 = my_str[:] # hello
print(my_str5)
print(my_str[-4:-1]) # ell
print(my_str[3:1]) # 没有数据,
# 步长可以是负数
print(my_str[3:1:-1],'2') # ll
print(my_str[::-1]) # 字符串的逆置,olleh
print(my_str[::2]) # 0 2 hlo
- 操作
find&rfind 字符串的查找
my_str = 'hello world itcast and itcastcpp'
# find() 在字符串中查找是否存在某个字符串
# my_str.find(sub_str,start,end)
# sub_str 要在字符串中查找的字符 类型是str
# start 开始位置,默认为0
# end 结束的位置 默认是len()
# 返回值:找到返回sub_str在my_str中的正数下标
# 没有找到,返回-1
index = my_str.find('hello') # 0
print(index)
# 从下标位置3开始查找字符串hello
print(my_str.find('hello',3)) # -1
print(my_str.find('itcast')) # 12
print(my_str.find('itcast',15)) # 23
# rfind() right find() 从后边开始查找
print(my_str.rfind('itcast')) # 23
index&rindex 字符串的查找
# index() 在字符串中查找是否存在某个字符串
# my_str.index(sub_str,start,end)
# sub_str 要在字符串中查找的字符 类型是str
# start 开始位置,默认为0
# end 结束的位置 默认是len()
# 返回值:找到返回sub_str在my_str中的正数下标
# 没有找到,会报错
print(my_str.index('hello')) # 0
# print(my_str.index('hello', 5)) # 代码报错
# rindex() 从后边开始查找
print(my_str.index('itcast')) # 12
print(my_str.rindex('itcast')) # 23
count 字符串的统计
# count() 统计出现的次数
print(my_str.count('aaaa')) # 0
print(my_str.count('hello')) # 1
print(my_str.count('itcast')) # 2
print(my_str.count('itcast',15)) # 1
replace字符串的代替
# my_str.replace()(old_str,new_str,count) 字符串的替换
# old_str:将要被替换的字符
# new_str:新的字符串,替换成的字符串
# count:替换的次数,默认是全部替换
# 返回值:得到一个新的字符串,不会改变原来的字符串
my_str1 = my_str.replace('itcast','itheima')
print('my_str:',my_str)
print('my_str1:',my_str1)
my_str2 = my_str.replace('itcast','itheima',1) # 替换一次
print('my_str2',my_str2)
split字符串切割
my_str = 'hello world itcast and itcastcpp'
# my_str.split(sub_str,count) 将my_str字符串按照sub_str进行切割
# sub_str:按照什么内容切割字符串,默认是空白字符 空格和tab键
# count:切割几次,默认是全部切割
# 返回值:列表[]
result = my_str.split() # 按照空白字符全部切割
print(result)
print(my_str.split('itcast'))
print(my_str.split('itcast',1))
my_str.rsplit('itcast',1)
join字符串连接
# my_str.join(可迭代对象)
# 可迭代对象,str ,列表(需要列表中的每一个数据都是字符串类型)
# 将my_str 这个字符串添加到可迭对象的两个元素之间
# 返回值:一个新的字符串
my_str = '_'.join('hello')
print(my_str) # h_e_l_l_o
print('_*_'.join('hello')) # h_*_e_*_l_*_l_*_o
# 定义列表
my_list = ['hello','cpp','python']
print('_'.join(my_list)) # hello_cpp_python
print('_*_'.join(my_list)) # hello_*_cpp_*_python
print(' '.join(my_list)) # hello cpp python
- 其他操作
capitalize
把字符串的第一个字符大写
title
把字符串的每个单词首字母大写
startswith
检查字符串是否是以 固定字符 开头, 是则返回 True,否则返回 False
endswith
检查字符串是否以规定字符结束,如果是返回True,否则返回 False.
lower
转换 mystr 中所有大写字符为小写
upper
转换 mystr 中的小写字母为大写
ljust
返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串
rjust
返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串
center
返回一个原字符串居中,并使用空格填充至长度 width 的新字符串
lstrip
删除 mystr 左边的空白字符
rstrip
删除 mystr 字符串末尾的空白字符
strip
删除mystr字符串两端的空白字符
partition
把mystr以str分割成三部分,str前,str和str后
splitlines
按照行分隔,返回一个包含各行作为元素的列表
isalpha
如果 mystr 所有字符都是字母 则返回 True,否则返回 False
isdigit
如果 mystr 只包含数字则返回 True 否则返回 False.
isalnum
如果 mystr 所有字符都是字母或数字则返回 True,否则返回 False
isspace
如果 mystr 中只包含空格,则返回 True,否则返回 False.
列表
- 定义和基本使用
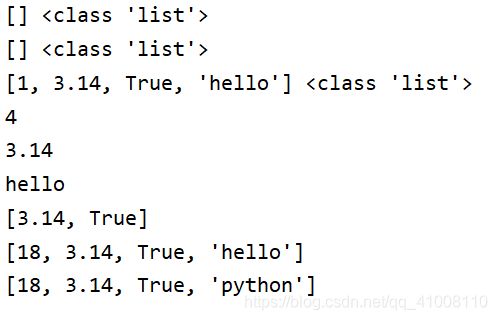
# 列表 是Python中的一种数据类型,可以存放多个数据,列表中得数据可以是任意类型的
# 列表 list ,定义使用[]
# 定义空列表
my_list = []
print(my_list,type(my_list))
my_list1 = list()
print(my_list1,type(my_list1))
# 定义带数据的列表
my_list2 = [1,3.14,True,'hello']
print(my_list2,type(my_list2))
# 求列表中数据元素的个数
num = len(my_list2)
print(num)
# 列表支持下标和切片操作
print(my_list2[1])
print(my_list2[-1])
print(my_list2[1:3])
# 下标操作和字符串不同的是:字符串不能使用下标修改其中数据,列表可以
my_list2[0] = 18
print(my_list2)
my_list2[-1] = 'python'
print(my_list2)
my_list2[0] = 'C++'
print(my_list2)
结果:
2.列表的遍历循环
my_list = ['郭德纲','李白','杜甫']
for i in my_list:
print(i)
print('*' * 30)
j = 0
while j < len(my_list):
print(my_list[j])
j += 1
- 列表的相关操作
添加:
# 列表添加数据,直接在原来列表中进行添加,不会返回新的列表
my_list = ['郭德纲','李白','杜甫']
print(my_list)
# 列表.append(数据) 向列表的尾部追加数据
my_list.append('aa')
print(my_list)
# 列表.insert(下标,数据) 在指定的位置添加数据
my_list.insert(0,'python')
print(my_list)
my_list.insert(5,3.14)
print(my_list)
# 列表.extend(可迭代对象) 会将可迭代对象中的数据逐个添加到愿列表的末尾
my_list.extend('hel')
print(my_list)
my_list.extend([1,'python'])
print(my_list)
结果:

数据查询
my_list = [1,3.14,'isaa']
# index() 根据数据值,查找元素所在的下标,找到返回元素的下标,没有找到,程序报错
# 列表中没有find方法,
num = my_list.index(3.14)
print(num)
# count() 统计出现的次数
num2 = my_list.count(1)
print(num2)
# in / not in 判断是否存在 存在是True,不存在是False
num4 = 3.14 in my_list
print(num4)
num4 = 3.14 not in my_list
print(num4)
结果

删除
my_list = [1,2,3,4,5]
# 1. 根据元素的数据值删除 remove(数据值)
my_list.remove(4)
print(my_list)
# my_list.remove(4) # 报错,要删除的数据不存在
# 2. 根据下标删除
# 2.1 pop(下标) 默认删除最后一个数据,返回删除的内容,不存在报错
num = my_list.pop()
print(num)
print(my_list)
num = my_list.pop(2)
print(num)
print(my_list)
# 2.2 del 列表[下标] 不存在下标会报错
del my_list[1]
print(my_list)
结果

排序
# 排序前提:列表中的数据类型一致
my_list = [1,5,3,7,9,6]
# sort() 直接在愿列表中进行排序,默认是升序,通过reverse=True,降序
my_list.sort()
print(my_list)
my_list.sort(reverse=True)
print(my_list)
# sorted(列表)排序会产生一个新的列表
my_list1 = sorted(my_list)
my_list2 = sorted(my_list,reverse=True)
print(my_list)
print(my_list1)
print(my_list2)
print('=' * 30)
my_list3 = ['a','b','c','d','e']
# 逆置
my_list4 = my_list3[::-1] # 得到一个新的列表
print(my_list3)
print(my_list4)
# 在原来列表中直接逆置
my_list3.reverse()
print(my_list3)
结果
 4. 列表的嵌套
4. 列表的嵌套
school_nams = [['清华大学','北京大学'],
['南开大学','天津大学','天津师范大学'],
['山东大学','中国海洋大学']]
print(school_nams[1])
print(school_nams[1][1])
print(school_nams[1][1][1])
# 山东大学
print(school_nams[2][0])
for schools in school_nams:
for name in schools:
print(name)
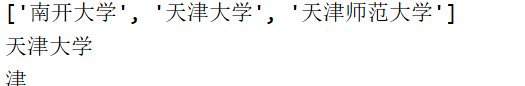
元组
元组与列表类似,元组的元素不能修改
# 元组和列表的区别
# 列表使用[]定义,元组使用()定义
# 列表的数据可以修改,元组不行
my_tuple = (18,3.14,True,'python')
# 元组支持下标和切片操作
print(my_tuple[1])
# 定义一个数据元素
my_tuple3 = (3,) # 没有逗号是整型
print(my_tuple3,tuple(my_tuple))
字典
- 定义和访问
# 字典 dict 定义使用{} 定义,是由键值对组成(key-value)
# 变量 = {key1:value1,key2:value2,...}一个key:value键值对是一个元素
# 字典的key 可以是 字符串类型和数字类型(int ,float),不能是列表
# value可以是任何类型
# 1. 定义空字典
my_dict = {}
my_dict1 = dict()
print(my_dict,type(my_dict))
print(my_dict1,type(my_dict1))
# 2. 定义带数据的字典
my_dict2 = {'name':'isaac','age':'18','like':['学习','购物','游戏'],1:[2,5,8]}
print(my_dict2)
# 3. 访问value值,在字典中没有下标的概念 ,使用key值访问对应的value值
# 18
print(my_dict2['age'])
# 购物
print(my_dict2['like'][1])
# 如果key值不存在
# print(my_dict2['gender']) # 代码报错
# 字典.get(key) 如果key值不存在,不会报错,返回None
print(my_dict2.get('gender')
# my_dict2.get(key,数据值) 如果key不存在,返回书写的数据值
print(my_dict2.get('gender', 'man'))
print(len(my_dict2)) # 4
- 添加和修改
my_dict = {'name':'isaac'}
print(my_dict)
# 字典中添加和修改数据,使用key值进行添加和修改
# 字典[key] = 数据值; 如果key值存在就是修改,如果key值不存在就是添加
my_dict['age'] = 18
print(my_dict)
my_dict['age'] = 19
print(my_dict)
# 注意点 key值 int 的1和float的1.0代表一个key值
my_dict[1] = 'int'
print(my_dict)
my_dict[1.0] = 'float'
print(my_dict)
结果

3. 删除数据
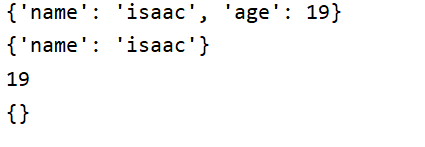
my_dict = {'name': 'isaac', 'age': 19, 1: 'float'}
# 根据key值删除 del 字典名[key]
del my_dict[1]
print(my_dict)
# 字典.pop(key) 根据key值删除,返回值是value值
result = my_dict.pop('age')
print(my_dict)
print(result)
# 字典.clear() 清空字典,删除所有的键值对
my_dict.clear()
print(my_dict)
# del 字典名 直接删除字典,不能使用,要是用需要再次定义
del my_dict
4. 遍历
my_dict = {'name': 'isaac', 'age': 19, 1: 'float'}
# 1.for循环直接遍历字典,遍历的字典的key值
for key in my_dict:
print(key,my_dict[key])
# 2 字典.keys() 获取字典中所有的key值,得到的类型是 dict_keys 该类型
# 2.1可以使用list()进行类型转换,将其转换为列表类型
# 2.2 可以使用for循环遍历
result = my_dict.keys()
print(result,type(result))
for key in result:
print(key)
# 3.字典.values()获取所有的value值,类型是dict_values
# 3.1 可以使用list()进行类型转换,将其转换为列表类型
# 3.2 可以使用for循环遍历
for value in my_dict.values():
print(value)
# 4.字典.items() 获取所有的键值对 类型是 dict_items ,key,value组成元组类型
# 4.1 可以使用list()进行类型转换,将其转换为列表类型
# 4.2 可以使用for循环遍历
for item in my_dict.items():
print(item[0],item[1])
for k,v in my_dict.items(): # k是元组中的一个数据 v是另一个数据
print(k,v)
- enumerate()函数
my_list = ['a','b','c','d','e']
for i in my_list:
print(my_list.index(i),i) # 下标,数据值
# enumerate 将迭代带序列中元素所在的下标和具体的数据组合在一快,变成元组
for j in enumerate(my_list):
print(j)
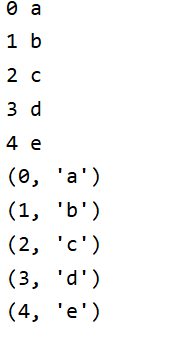
6. 公共方法

in和not in判断的是key值是否存在
max 和 min 字典比较的是key值
函数
定义和调用
# 函数,能够实现一个具体的功能,是多行代码的整合
# 定义:关键字 def,
# def 函数名():
# 函数代码(函数体)
# 函数调用时,才会执行函数中的代码
# 好处:重复的代码可以重复使用,减少代码冗余
# 函数的定义,函数的定义不会执行函数的代码
def func():
print('python')
print('hello world')
# 函数调用时才会执行函数的代码 函数名()
func() # 代码会跳转到函数定义的地方执行
函数的文档说明
# 函数文档说明本质是注释,解释函数是干啥的
# 特定的位置书写要求,写在函数名字的下方
def func():
"""
打印输出一个hello python
"""
print('hello python')
func()
# 查看函数的文档注释,使用help(函数名)
help(func)
函数的参数
# 定义一个函数,实现两个数的和
def add(a, b): # a和b成为形式参数
# a = 10
# b = 20
c = a + b
print(f"求和的结果为:{c}")
# 函数调用
# 实际参数
# 函数调用时,会将实参传给形参
add(1, 2)
add(100, 200)
# 好处:函数更加通用
局部变量
# 局部变量 函数内部定义的变量
# 只能在函数内部使用,不能在函数外部和其它函数中使用
def func():
# 定义局部变量num
num = 100
print(num)
def func1():
num = 200 # 这个num和func中的num没有关系
print(num)
# 函数调用
func()
全局变量
# 全局变量:函数外部定义的变量
# 函数内部可以访问全局变量
# 不能在函数内部修改全局变量
# 函数内部修改全局变量,需要使用global关键字声明这个变量为全局变量,放在函数的开始
# 定义全局变量
g_num = 100
def func1():
print(g_num)
func1()
函数的返回值
![]()
# 函数想要返回一个数据值,给调用的地方,需要使用关键字 return
# return 关键字作用:将return 后边的数据值进行返回,程序终止执行
# 注意:return关键字只能写在函数中
def add(a,b):
c = a + b
return c
result = add(100,200)
print(result)
return 返回多个数据值
def func(a,b):
c = a + b
d = a - b
# 将c 和 d放到容器中进行返回
# return [c,d]
# return (c,d)
return c,d # 默认组成元组进行返回
result = func(10,20)
print(f"a+b的结果{result[0]},a-b的结果{result[1]}")

函数的嵌套调用
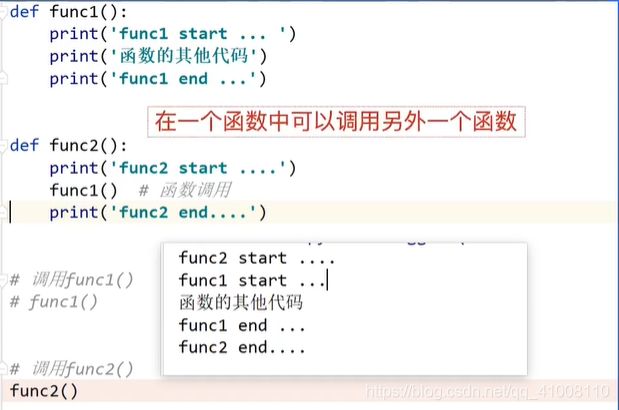
函数传参的两种方式
def func(a, b, c):
print(f"a:{a}")
print(f"b:{b}")
print(f"c:{c}")
# 位置传参,按照形参的位置顺序将实参的值传递给形参
func(1, 2, 3)
# 关键字传参,指定实参给到那个形参,注意:关键字必须是函数的形参名
func(a=10, b=20, c=30)
# 混合使用,先写位置传参,再写关键字传参
func(10, b=20, c=30) # 关键字实参要写到位置实参后边
函数形参
- 缺省参数
# 缺省参数,形参,在函数定义的时候,给形参一个默认值,这个形参就是缺省参数
# 注意点:缺省参数要写到普通参数的后边
# 特点:在函数调用时候,如果给缺省参数传递实参值,使用的是传递的参数值,如果没有传递,使用默认值
def func(a,b,c=10): # 形参c 成为缺省形参
print(f"a:{a}")
print(f"b:{b}")
print(f"c:{c}")
func(1,2) # 没有给c 实参,使用默认值10
func(1,2,3) # 给c传递实参值,使用传递的数据3
- 不定长参数
# 在形参前边加上一个*,该形参变为不定长元组形参,可以接受所有的位置实参,类型是元组
# 在形参前边加上两个**,该形参变为不定长字典形参,可以接收所有的关键字实参,类型是字典
def func(*args, **kwargs):
print(args)
print(kwargs)
func(1, 2, 3, 3, 4, 5)
func(a=1, b=2, c=3, d=4)
func(1, 2, 3, a=4, b=5, c=6)
结果

![]()
函数形参的完整格式
# 普通参数 缺省参数 不定长元组形参 不定长字典形参
def func(a, b=1): # 先普通再缺省
pass
def func1(a, *args, b=1): # 先普通形参 不定长元组形参 缺省形参
pass
def func2(a, *args, b=1, **kwargs): # 先普通形参 不定长元组形参 缺省形参 不定长字典形参
pass
func(1,2)
func1(1,2,3,4)
func2(1,2,3,4,b=10)
拆包
# 组包,将多个数据值,组成一个元组,给到一个变量
a = 1, 2, 3
print(a) # (1, 2, 3)
def func():
return 1, 2 # 组包
# 拆包:将容器的数据分别给到多个变量,需要注意:数据的个数和变量的个数要保持一致
b, c, d = a # 拆包
print(b, c, d)
e, f = func()
print(e, f)
my_list = [10, 20]
a, b = my_list
print(a, b)
my_dict = {'name':'isaac','age':18}
a, b = my_list
print(a, b)

# 交换a,b的值 组包和拆包
a, b = b, a
引用
- 定义
# 可以使用id() 查看变量的引用,可以将id 值认为是内存地址的别名
# Python中数据值的传递传的是引用
# 赋值运算符可以改变变量的引用
# 将数据10 存储到变量a 中,本质是将数据10 所在内存的引用地址保存到变量a中
a = 10
# 将变量a中保存的引用地址给到b
b = a
print(a,b) # 使用print函数打印变量a和b引用中存储的值

2. 可变与不可变类型
# 类型的可变与不可变:在不改变变量引用的前提下,能否改变变量中引用中的数据
# 如果能改变是可变类型,否则是不可变类型
# int float bool str list tuple dict
# 不可变类型:int float bool str tuple
# 可变类型:list dict
a = 10
b = 10
print(id(a), id(b)) # Python中的内存优化,对于不可变类型进行的


3. 引用作为函数参数
# 函数传参传递的也是引用
my_list = [1, 2, 3] # 全局变量
def func1(a):
a.append(4)
def func2():
# 为啥不加global,因为没有修改my_list中存的引用值
my_list.append(5)
def func3():
global my_list # 修改全局变量的值
my_list = [1, 2, 3]
def func4(a):
# += 对于列表来说,类似列表的extend方法,不会改变变量的引用地址
a += a # 修改了a变量的引用
func1(my_list) # [1, 2, 3, 4]
func2() # [1, 2, 3, 4, 5]
func3() # [1, 2, 3]
print(my_list)
b = 10 # 不可变类型
func4(b) # 10
func4(my_list)
print(my_list) # [1, 2, 3, 1, 2, 3]
- 拆包

递归函数
函数自己嵌套调用自己
形成条件:
1.自己调用自己
2.函数必须有一个终止条件
def get_age(num):
"""
求第num个人的年龄,每相邻的两个人的年龄差两岁,已知第一个人的年龄是18岁
:param num:
:return:
"""
if num == 1:
return 18
# 求第num个人的年龄,只需要num-1 这个人的年龄+2
age = get_age(num-1) + 2
return age
print(get_age(2))
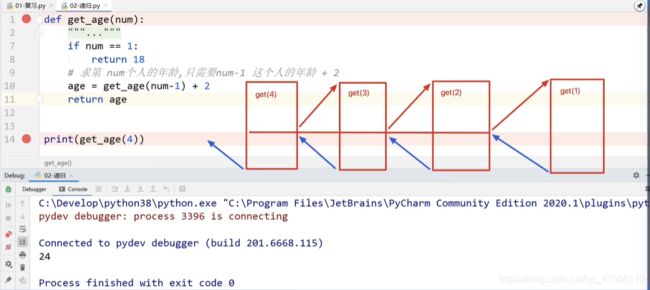
匿名函数
lambda 参数列表:表达式
# 1. 无参无返回值
def func1():
print('python')
(lambda : print('hello python'))()
func1()
f1 = lambda : print('hello python')
f1()
# 2. 无参有返回值
def func2():
return 1 + 2
f2 = lambda : 1 + 2
print(f2())
# 3. 有参无返回值
def func3(name):
print(name)
f3 = lambda name: print(name)
f3('hello')
# 4. 有参有返回值
def func4(*args):
return args
f4 = lambda *args :args
print(f4(1, 2, 3, 4, 5))

作为函数参数传递
def my_calc(a, b, func):
"""
进行四则运算
:param a: 第一个数据
:param b: 第二个数据
:param func: 函数,要进行的运算
:return: 运算的结果
"""
print('其他的函数代码...')
num = func(a, b)
print(num)
def add(a, b):
return a + b
# 调用
my_calc(10, 20, add)
my_calc(10, 20, lambda a, b: a - b)
my_calc(10, 20, lambda a, b: a * b)

列表排序

# 列表排序,列表中的数据的类型要保持一致
my_list = [1, 3, 4, 5]
my_list.sort()
print(my_list)
list1 = [{'name': 'd', 'age': 19},
{'name': 'a', 'age': 17},
{'name': 'c', 'age': 20},
{'name': 'b', 'age': 18}]
# list1.sort() # 程序报错
# 匿名函数的形参是列表中每一个数据
list1.sort(key=lambda x: x['name'])
print(list1)
list1.sort(key=lambda x: x['age'])
print(list1)
list2 = ['abcdef', 'bc', 'def', 'ghli']
print(list2)
# 需求:根据列表中字符串的长度,列表进行排序
list2.sort(key=lambda x: len(x))
print(list2)
# sort(key = lambda 形参 (排序规则1, 排序规则2,...)
# 当第一个规则相同时,会按照第二个规则进行排序
list1.sort(key=lambda x: (x['age'],x['name']))
print(list1)

列表推导式
# 列表推导式 为了快速的生成一个列表
# 1. 变量 = [生成数据的规则 for 临时变量 in xxx]
# 每循环一次,就会创建一个数据
my_list = [i for i in range(5)]
print(my_list)
my_list1 = ['hello' for i in range(5)]
print(my_list1)
my_list2 = [f'num:{i}' for i in my_list]
print(my_list2)
my_list3 = [i+i for i in range(5)]
print(my_list3)
# 2. 变量 = [生成数据的规则 for 临时变量 in xxx if xxx]
# 每循环一次,并且if条件为True,生成一个数据
my_list = [i for i in range(5) if i % 2 == 0]
print(my_list)
# 3. 变量 = [生成数据的规则 for 临时变量 in xxx for j in xxx]
# 第二个for 循环,循环一次生成一个数据
my_list4 = [(i, j) for i in range(3) for j in range(3)]
print(my_list4)
# 字典推导式
# 变量 = {生成字典的规则 for 临时变量 in xxx}
# my_dict = {key: value for i in range(3)}
my_dict = {f'name{i}': i for i in range(3)}
print(my_dict)
my_dict = {f'name{i}': j for i in range(3) for j in range(3)} # key相同修改数据
print(my_dict)

文件
作用:可以永久的保存数据
文件在硬盘中存储格式是二进制
- 打开文件
- 读写文件
- 关闭文件
读文件
# 打开文件
# open(file,mode='r' enconding=None)
# file 文件名,类型是str
# mode,文件打开方式,r(read)只读,r只写打开,a(append) 追加打开
# enconding 文件的编码方式 常见的gbk,utf-8
# 返回值,文件对象,回叙所有的文件操作,都要通过这个对象进行
# 以只读的方式打开当前目录,1.txt 文件,文件不存在会报错
f = open('1.txt','r')
# 读文件 文件对象.read()
buf = f.read()
print(buf)
# 关闭文件
f.close()
read()按字节读取
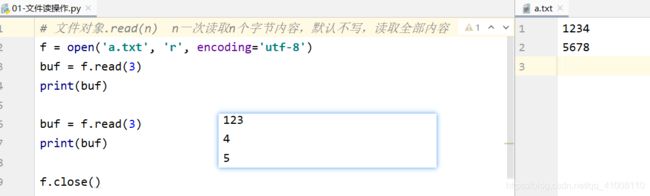
4 \n 5
readline()按行读取

读取大文件



写文件
# 1.打开文件 w方式打开文件,文件不存在,会创建文件,文件存在会覆盖清空原文件
f = open('1.txt','w',encoding='utf-8')
# 2.写文件 文件对象.write(写入文件的内容)
f.write('hello world')
f.write('你好,中国!')
# 3.关闭文件
f.close()
乱码问题

追加文件
# coding=gbk
# a 方式打开文件,追加内容,在文件的末尾写入内容
# 注意,写入内容都是write函数
f = open('b.txt', 'a', encoding='utf-8')
f.write('hello world!\n')
f.close()
文件打开模式



f = open('c.txt', 'wb')
f.write('你好'.encode()) # encode() 将str转换为二进制的字符串
f.close()
f1 = open('c.txt', 'rb')
buf = f1.read()
print(buf.decode())
f1.close()
文件备份
- 用只读方式打开文件
- 读取文件内容
- 关闭文件
- 只写的方式打开新文件
- 将 第二步读取的内容写入新文件
- 关闭文件
file_name = input('请输入要备份的文件名')
# 1. 用只读方式打开文件
f = open(file_name, 'rb')
# 2. 读取文件内容
buf = f.read()
# 3. 关闭文件
f.close()
# 根据原文件名,找到文件后缀和文件名
index = file_name.rfind('.')
# 后缀 file_name[index:]
# 新文件名
new_file_name = file_name[:index] + '[备份]' + file_name[index:]
# 4. 只写的方式打开新文件
f_w = open(new_file_name, 'wb')
# 5. 将 第二步读取的内容写入新文件
f_w.write(buf)
# 6. 关闭文件
f_w.close()
文件和目录操作
# 对文件和目录的操作,引入os模块
import os
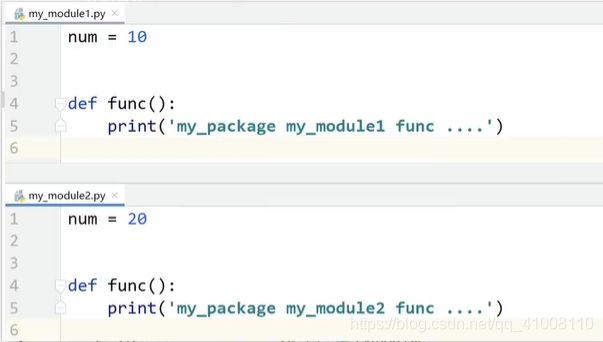
# 1. 文件重命名 os.rename(原文件路径名,新文件路径名)
os.rename('a.txt', 'aa.txt')
# 2. 删除文件 os.remove(文件的路径名)
os.remove('aa.txt')
# 3.创建目录 os.mkdir(目录路径名) make directory
os.mkdir('test')
os.mkdir('test/aa')
# 4. 删除空目录 os.rmdir(目录名) remove directory
os.rmdir('test/aa')
# 5. 获取当前目录 os.getcwd()
buf = os.getcwd()
# 6. 修改当前的目录 os.chdir(目录名)
os.chdir('test')
buf = os.getcwd()
print(buf)
# 7. 获取指定目录中的内容 os.listdir(目录),默认不写参数,是获取当前目录中的内容
# 返回值是列表,列表中的每一项是文件名
buf = os.listdir() # test
print(buf)
批量创建和修改文件名
import os
def create_files():
os.chdir('test')
for i in range(10):
file_name = 'file_' + str(i) + '.txt'
print(file_name)
f = open(file_name, 'w')
f.close()
os.chdir('../')
create_files()
def modify_filename():
os.chdir('test')
buf_list = os.listdir()
for file in buf_list:
new_file = 'py43_' + file
os.rename(file, new_file)
os.chdir('../')
modify_filename()
面向对象基础
介绍

类和对象
- 概念

- 类的组成

类的定义
# 在python中,定义类使用关键字class ,语法:
"""
# object 是所有类中最初始的类
# 类名:遵循大驼峰的命名规范
class 类名(object):
类中的代码
"""
# 定义方式一
class Dog(object):
pass
# 方式二
class Dog1():
pass
# 方式三
class Dog2:
pass
"""
新式类:直接或者间接继承object的类,在python3中,所有的类默认继承object类
创建对象
# 定义类
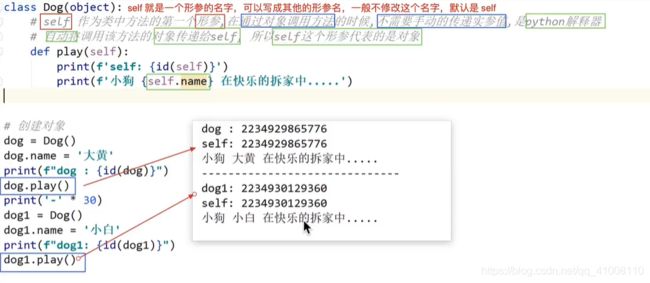
class Dog(object):
# 在类中定义的函数,称为方法,函数的所有知识都可以使用
def play(self):
print('小狗快乐拆家中----')
pass
# 创建对象 变量 = 类名()
dog = Dog() # 创建一个对象dog
print(id(dog))
dog1 = Dog() # 创建一个对象dog1
print(id(dog1))
# 可以使用对象调用类中的方法,使用 对象.方法名()
dog.play()
dog1.play()
类外部添加和获取对象属性
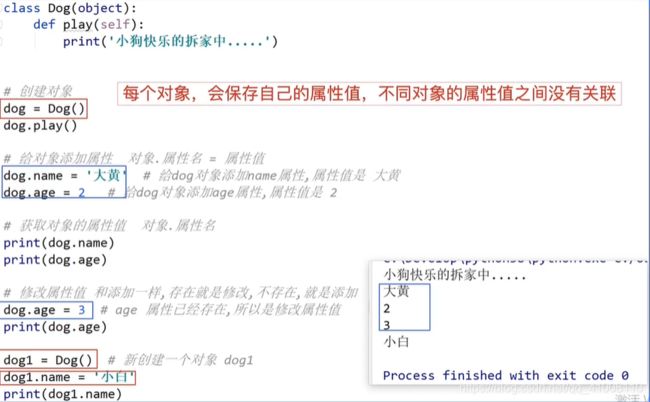
类内部的操作
魔法方法


1.init

带参数

2. str


3. del



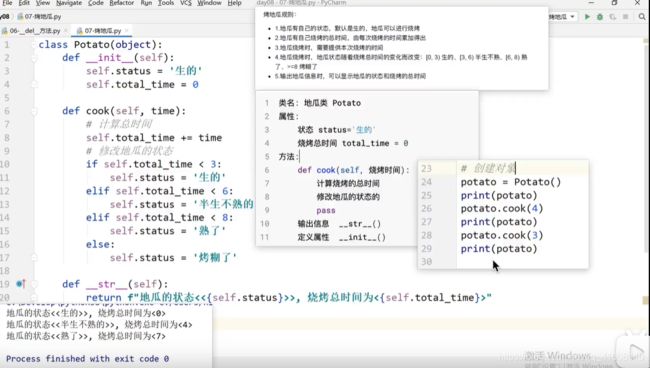
烤地瓜案例
封装

继承
- 基本语法

# 1. 定义一个动物类
class Animal(object):
# 2. 在animal类书写play方法,输出
def paly(self):
print('快乐的玩耍')
# 3. 定义Dog类继承animal方法
class Dog(Animal):
pass
# 4. 创建dog对象调用父类的方法
dog = Dog()
dog.paly()、
- 单继承和多继承
"""
单继承:如果一个类只有一个父类,
多继承:如果一个类有多个父类
多层继承;C-->B-->A
"""
# 1. 定义一个动物类
class Animal(object): # 对于Animal和object来说,单继承
# 2. 在animal类书写play方法,输出
def paly(self):
print('快乐的玩耍')
# 3. 定义Dog类继承animal方法
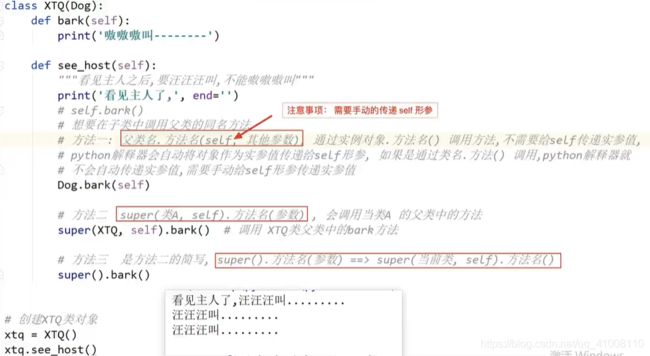
class Dog(Animal): # 也是单继承,Dog-->Animal-->Object 多层继承
def bark(self):
print('汪汪汪。。。。')
# 定义XTQ类,继承Dog类
# 多层继承,子类可以使用所有继承链中的类中的方法和属性
class XTQ(Dog):
pass
# 4. 创建dog对象调用父类的方法
dog = Dog()
dog.paly()
- 子类重写父类的同名方法


- 子类调用父类的同名方法
- 继承中的init

- 多继承
# 1. 定义Dog类,定义bark方法和eat方法
class Dog(object):
def bark(self):
print('汪汪汪叫')
def eat(self):
print('啃骨头')
# 2. 定义God类,定义play方法和eat方法
class God(object):
def play(self):
print('在云中飘一会把')
def eat(self):
print('吃仙丹')
# 3. 定义XTQ类,继承Dog类和God类
class XTQ(Dog, God): # XTQ类中有两个父类,这个继承成为多继承
pass
# 4. 创建XTQ类对象
xtq = XTQ()
xtq.bark()
xtq.play()
xtq.eat() # 两个父类都存在eat方法,子类会调用第一个父类的方法
- 多继承指定父类方法
# 1. 定义Dog类,定义bark方法和eat方法
class Dog(object):
def bark(self):
print('汪汪汪叫')
def eat(self):
print('啃骨头')
# 2. 定义God类,定义play方法和eat方法
class God(object):
def play(self):
print('在云中飘一会把')
def eat(self):
print('吃仙丹')
# 3. 定义XTQ类,继承Dog类和God类
class XTQ(Dog, God): # XTQ类中有两个父类,这个继承成为多继承
def eat(self):
print('子类重写')
# 方法一 类名.方法名(self, 参数)
# Dog.eat(self)
# 方法二 super(类A, self).方法名(参数) 类A的父类中的方法
# super(XTQ, self).eat() # God类中的方法
# 4. 创建XTQ类对象
xtq = XTQ()
xtq.bark()
xtq.play()
xtq.eat() # 两个父类都存在eat方法,子类会调用第一个父类的方法
# 类名.__mro__可以查看当前类的继承链
print(XTQ.__mro__)
-
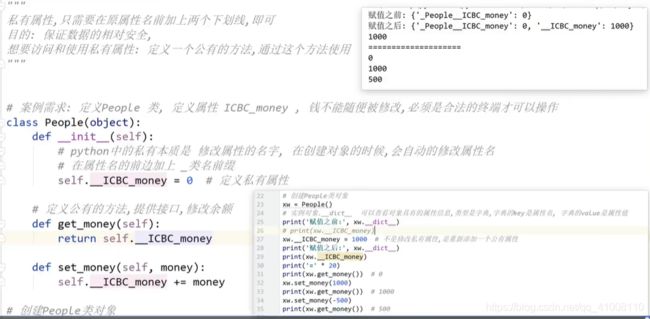
私有权限


私有方法

-
类属性
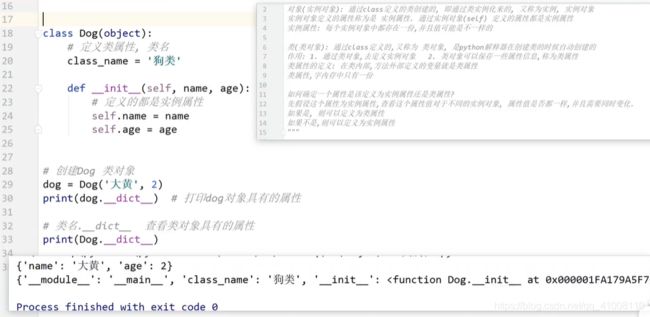
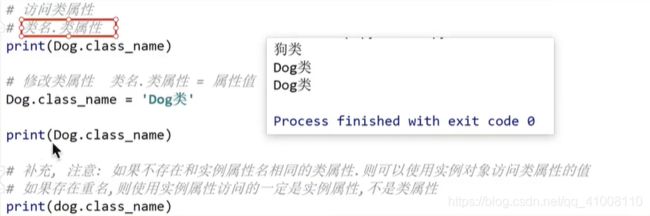
-
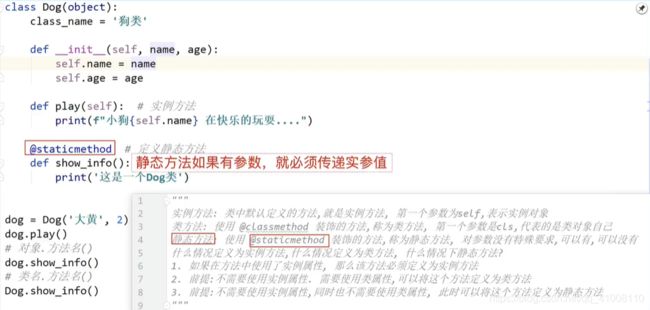
静态方法
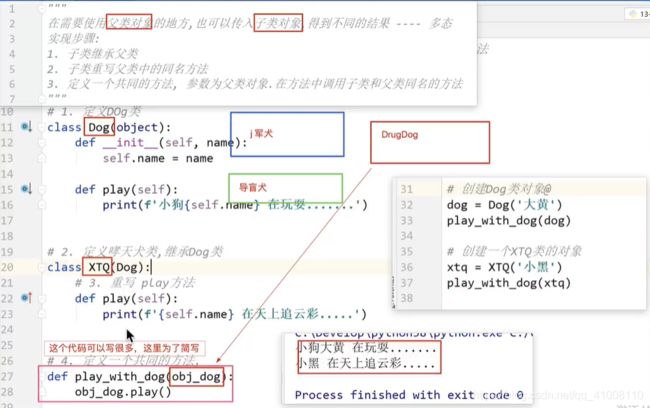
多态
异常
概念

![]()
捕获单个异常

捕获多个异常

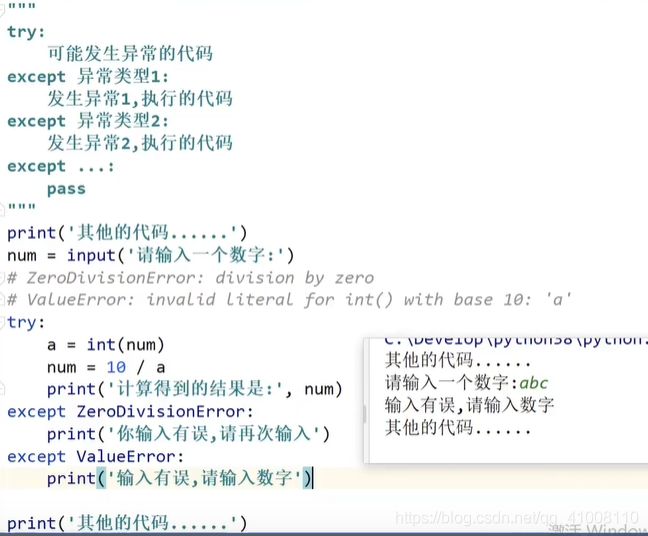
打印异常信息

捕获所有异常

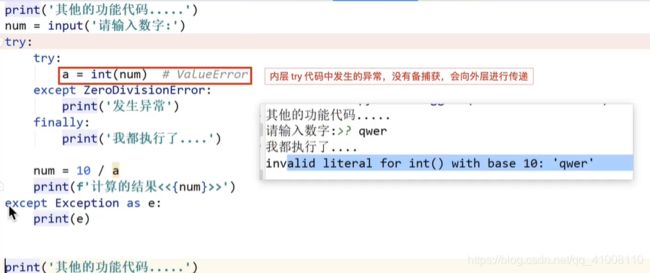
异常的完整结构

异常的传递


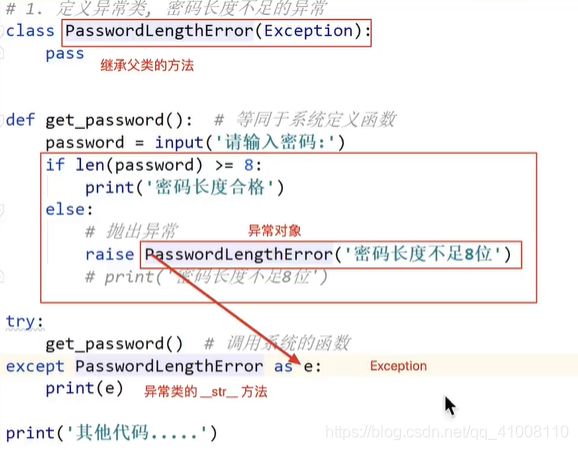
抛出自定义异常

模块






__all__变量
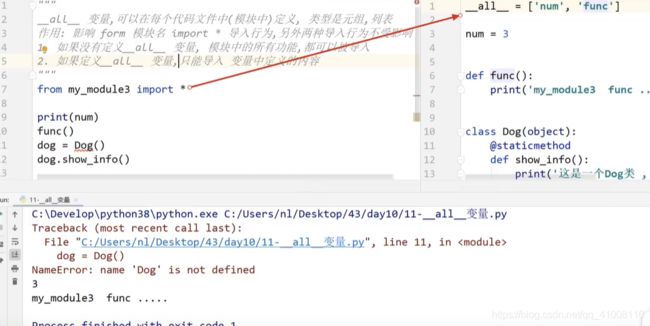
__name__变量
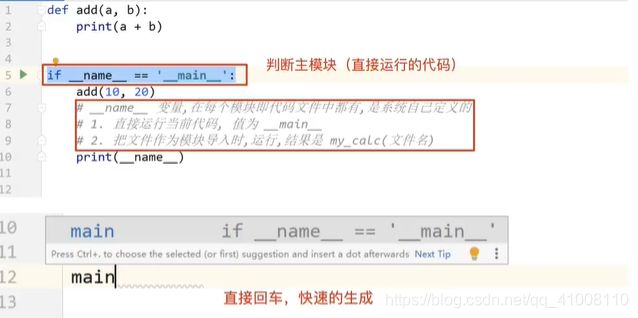
注意点:
自己定义的模块名不要和系统中要使用的模块名字相同

包