Python机器学习之决策树

决策树的枝叶:
以相亲为例:
- 女儿:多大年纪了?
- 母亲:26
- 女儿:长的帅不帅?
- 母亲:挺帅的
- 女儿:收入高不?
- 母亲:不算很高,中等情况。
- 女儿:是公务员不?
- 母亲:是,在税务局上班呢。
- 女儿:那好,我去见见。
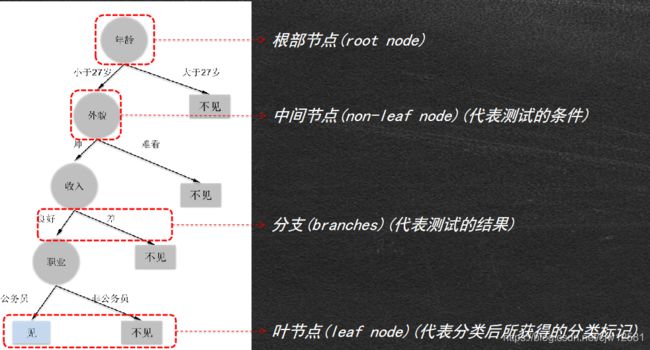
那么如何选择根部节点,中间节点呢?(属性选择的先后顺序)列名:属性
可以通过 熵值 信息增益 信息增益率
1.熵(entropy)
是信息的度量单位,是一种 对属性“不确定性的度量”。属性的不确定性越大,把它搞清楚所需要的信息量也就越大,熵也就越大。如果一个数据集D有N个类别,则该数据集的熵为:
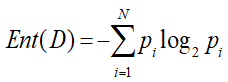
2.信息增益(gain):对纯度提升的程度
若离散属性a有V个取值(如约会还是不约会),则其信息增益为:
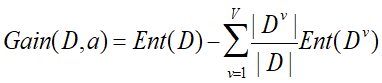 ,,
,,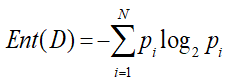
依据信息增益的大小可以确定属性选择的先后顺序,信息增益最大(谁的分支多选谁)的作为根节点,依次往下。
以打球为例:
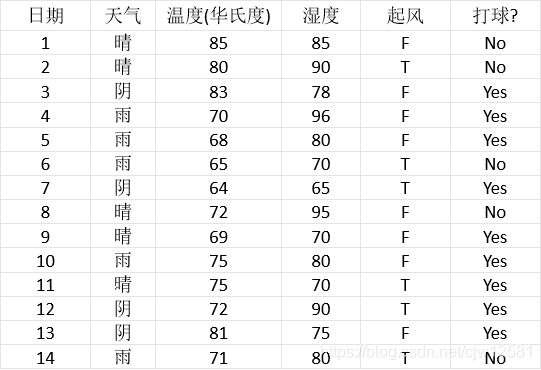
打球数据集(打球和不打球两类)的熵为:
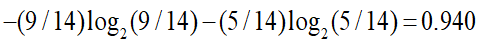
天气属性的信息增益:
晴:打球记录2条,不打球记录为3条
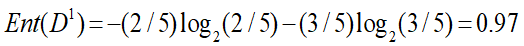
阴:打球记录4条,不打球记录0条
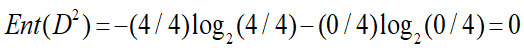
雨:打球记录3条,不打球记录2条
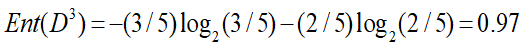
则其信息增益为:
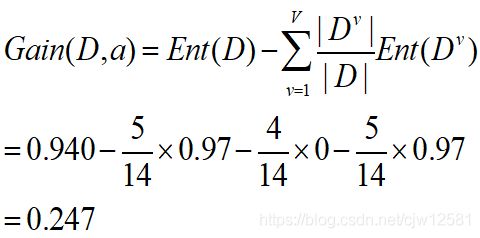
此外,就是对属性(根部节点,中间节点)的拆分(拆几个分支)
每次拆分都存在多种可能,哪个才是较好的选择呢?
理想情况:在拆分过程中,当叶节点只拥有单一类别时,将不必继续拆分,
目标是寻找较小的树,希望递归过程尽早停止
较小的树意味着什么?
当前最好的拆分属性产生的拆分中目标类的分布应该尽可能地单一(单纯),多数类占优。
如果能测量每一个节点的纯度,就可以选择能产生最纯子节点的那个属性进行拆分;
决策树算法通常按照纯度的增加来选择拆分属性。
纯度度量
当样本中没有两项属于同一类:0
当样本中所有项都属于同一类:1
最佳拆分可以转化为选择拆分属性使纯度度量最大化的优化问题。
拆分增加了纯度,但如何将这种增加量化呢,或者如何与其他拆分进行比较呢?
用于评价拆分分类目标变量的纯度度量包括:
基尼(Gini,总体发散性) CART
熵(entropy,信息量)
信息增益(Gain) ID3
信息增益率 C4.5,C5.0
改变拆分准则(splitting criteria)导致树的外观互不相同。
决策树系列中的经典算法——ID3算法
ID3算法是决策树系列中的经典算法之一,它包含了决策树作为机器学习算法的主要思想,缺点是:
由于ID3决策树算法采用信息增益作为选择拆分属性的标准,会偏向于选择取值较多的,即所谓高度分支属性,而这类属性并不一定是最优的属性。ID3算法只能处理离散属性,对于连续型的属性,在分类前需要对其进行离散化。
常用的决策树算法如下:

分类——实现类是DecisionTreeClassifier,能够执行数据集的多类分类
输入参数为两个数组X[n_samples,n_features]和 y[n_samples],X 为训练数据,y 为训练数据的标记数据
DecisionTreeClassifier 构造方法为:
sklearn.tree.DecisionTreeClassifier(criterion=‘gini’ , splitter=‘best’ , max_depth=None
, min_samples_split=2
, min_samples_leaf=1
, max_features=None
, random_state=None
, min_density=None
, compute_importances=None
, max_leaf_nodes=None)
回归——实现类是DecisionTreeRegressor,输入为X,y 同上,y 为浮点数
DecisionTreeRegressor 构造方法为:
sklearn.tree.DecisionTreeRegressor(criterion=‘mse’ , splitter=‘best’ , max_depth=None
, min_samples_split=2
, min_samples_leaf=1
, max_features=None
, random_state=None
, min_density=None
, compute_importances=None
, max_leaf_nodes=None)
决策树案例:泰坦尼克生还预测
是否死亡是预测的目标,且属于非数值型的也就是说是离散的(死亡:0,存活:1)
需要用到graphviz模块:
graphviz实际上是一个绘图工具,可以根据dot脚本画出树形图等,十分方便。我们利用它可以轻松完成树形图等图案的绘制工作。原理其实很简单,利用python代码生成dot脚本,然后调用graphviz软件解析,生成一张图片。
PassengerId列没用,可以删掉;对于性别来说:可以用0,1代替;对于年龄缺失值,可以用取平均值来补齐;
import pandas as pd
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.metrics import classification_report
import graphviz
data = pd.read_csv('titanic_data.csv') # 导入数据
data.drop('PassengerId', axis=1, inplace=True) # 删除PassengerId 列
data.loc[data['Sex'] == 'male', 'Sex'] = 1 # 用数值1来代替male,用0来代替female
data.loc[data['Sex'] == 'female', 'Sex'] = 0
data.fillna(data['Age'].mean(), inplace=True) # 用均值来填充缺失值,直接填充
Dtm = DecisionTreeClassifier(max_depth=5, random_state=8) # 构建决策树模型
Dtm.fit(data.iloc[:, 1:], data['Survived']) # 模型训练
pre = Dtm.predict(data.iloc[:, 1:]) # 模型预测
print(pre == data['Survived']) # 比较模型预测值与样本实际值是否一致
report = classification_report(data['Survived'], pre) # 分类报告
print('分类报告', '\n', report)
dot_data = export_graphviz(Dtm, feature_names=['Pclass', 'Sex', 'Age'], class_names='Survived')
graph = graphviz.Source(dot_data) # 决策树可视化
print(graph)
# 0 True
# 1 True
# 2 True
# 3 True
# 4 True
# 5 True
# 6 True
# 7 True
# 8 True
# 9 True
# ...
# 883 True
# 884 True
# 885 True
# 886 True
# 887 True
# 888 False
# 889 False
# 890 True
# Name: Survived, Length: 891, dtype: bool
# 分类报告
# precision recall f1-score support
#
# 0 0.84 0.88 0.86 549
# 1 0.79 0.73 0.76 342
#
# accuracy 0.82 891
# macro avg 0.82 0.81 0.81 891
# weighted avg 0.82 0.82 0.82 891