初识爬虫——爬虫与HTML介绍
目录
一. 爬虫是什么?
二. Python爬虫的优势
三. 体验爬虫
四. 爬虫伦理
五. Python爬虫需要掌握什么
六. HTML基础
七. HTTP协议之请求
总结
爬虫系列文章目录
一. 爬虫是什么?
爬虫,从本质上来说,就是利用程序在网上拿到对我们有价值的数据。
1.1 浏览器工作原理
浏览器工作原理总的来说,可以用下面这张图来表示给大家看:

- 解析数据:当服务器把数据响应给浏览器之后,浏览器并不会直接把数据丢给我们。因 为这些数据是用计算机的语言写的,浏览器还要把这些数据翻译成我们能看得懂的内容;
- 提取数据:我们就可以在拿到的数据中,挑选出对我们有用的数据;
- 存储数据:将挑选出来的有⽤数据保存在某一文件/数据库中。
1.2 爬虫工作原理
爬虫工作原理也可如下图所示给大家表现出来:

- 获取数据:爬⾍程序会根据我们提供的⽹址,向服务器发起请求,然后返回数据;
- 解析数据:爬⾍程序会把服务器返回的数据解析成我们能读懂的格式;
- 提取数据:爬⾍程序再从中提取出我们需要的数据;
- 储存数据:爬⾍程序把这些有用的数据保存起来,便于你日后的使用和分析。
二. Python爬虫的优势
- PHP: 虽然是世界上最好的语言,但是天生不是干爬虫的命,php对多线程,异步支持不足,并 发不足,爬虫是工具性程序,对速度和效率要求较高;
- Java: 生态圈完善,是PYthon最大的对手,但是java本身很笨重,代码量大,重构成本比较 高,任何修改都会导致大量的代码的变动.最要命的是爬虫需要经常修改部分代码;
- C/C++: 运行效率和性能几乎最强,但是学习成本非常高,代码成型较慢,能用C/C++写爬虫, 说明能力很强,但不是最正确的选择;
- Python: 语法优美,代码简洁,开发效率高,三方模块多,调用其他接口也方便, 有强大的爬 虫Scrapy,以及成熟高效的scrapy‐redis分布策略
三. 体验爬虫
3.1 requests.get()
1)安装requests 库:
Mac电脑⾥打开终端软件(terminal),输⼊ pip3 install requests ,然后点击 enter; Windows电脑⾥叫命令提示符(cmd),输⼊ pip install requests 。
2)requests 库作用:
requests 库可以帮我们下载网页源代码、⽂本、图⽚,甚⾄是⾳频。其实,“下载”本质上是向服务器发送请求并得到响应。
3)requests 库使用:
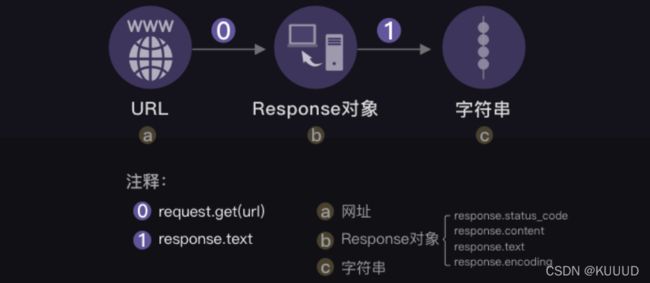
res = requests.get('URL')requests.get 是在调用requests库中的get()方法,它向服务器发送了⼀个请求,括号里的参数是你需要的数据所在的⽹址,然后服务器对请求作出了响应。我们把这个响应返回的结果赋值在变量res上,如下图所示:

3.2 Response对象的常用属性
Response对象的常用属性有以下几种:

1)response.status_code :
作用:打印 response 的响应状态码,以检查请求是否成功。
常见的响应状态码如下:

2)response.content:
作用:把 Response 对象的内容以⼆进制数据的形式返回,适⽤于图片、音频、视频的下载。
3)response.text :
作用:把 Response 对象的内容以字符串的形式返回,适⽤于⽂字、网页源代码的下载。
4)response.encoding:
能帮我们定义 Response 对象的编码。(附:只有遇上文本的乱码问题,才考虑用res.encoding)
3.3 汇总图解
四. 爬虫伦理
4.1 Robots 协议
Robots 协议是互联网爬⾍的⼀项公认的道德规范,它的全称是“网络爬⾍排除标准”(Robots exclusion protocol),这个协议用来告诉爬⾍,哪些页面是可以抓取的,哪些不可以。
4.2 协议查看
- 在网站的域名后加上/robots.txt就可以了。如淘宝的robots协议( http://www.taobao.com/robots.txt);
- 协议里最常出现的英文是Allow和Disallow,Allow代表可以被访问,Disallow代表禁止被访问。
五. Python爬虫需要掌握什么
- Python基础语法
- HTML基础
- 如何抓取页面: HTTP请求处理,urllib处理后的请求可以模拟浏览器发送请求,获取服务器响应文件 解析服务器响应的内容;
- 各种库:re,xpath,BeautifulSoup4,jsonpath,pyquery :目的是使用某种描述性语法来提取匹配规则的数据;
- 如何采取动态html,验证码处理:通用的动态页面采集, Selenium+PhantomJs(无界面浏览器),模拟真实浏览器加载js,ajax等非静态页面数据;
- Scrapy框架 :国内常见的框架Scrapy,Pyspider ,高定制性高性能(异步网络框架twisted),所以数据下载速度非常快,提供了数据存储,数据下载,提取规则等组件(异步网络框架twisted类似tornado)和Django,Flask相比的优势是高并发,性能较强 的服务器框架;
六. HTML基础
HTML(Hyper Text Markup Language)是用来描述网页的⼀种语言,也叫超文本标记语言。
6.1 查看网页的 HTML 代码
- 显示网页源代码
在网页任意地⽅点击⿏标右键,然后点击“显示网页源代码”。(Windows系统的电脑还可以使⽤快捷键ctrl+u来查看网页源代码)
- 检查
windows:在网页的空白处点击右键,然后选择“检查”(快捷方式是ctrl+shift+i); mac: 在网页的空白处点击右键,然后选择“检查”(快捷键 command + option + I(大写 I ))
6.2 HTML 的组成
1)标签和元素:
- 标签:夹在尖括号<>中间的字母,标签通常是成对出现的:前⾯的是【开始标签】,比如;后⾯的是【结束标签】,如;
- 元素:开始标签+结束标签+中间的所有内容组成。
以下是常见的HTML元素:

注意:HTML标签是可以嵌套标签的,而且可以多层嵌套;这就像是在电脑中,⼀个硬盘可以包含数个文件夹,文件夹中还可以嵌套文件夹。
6.3 网页头和网页体
HTML文档的最外层标签⼀定是,里面嵌套着元素与元素。
元素代表了【网页头】,元素代表了【网页体】,这是最基本的网页结构。
- 【网页头】的内容不会被直接呈现在浏览器里的网页正文中;
- 【网页体】的内容是会直接显示在网页正文中的。
HTML的基本结构如下所示:

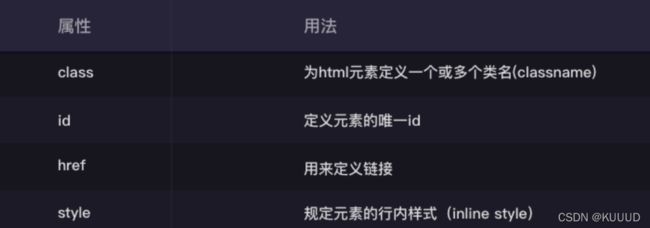
6.4 属性
注意:HTML的属性和Python中的属性不是⼀个东西
常见HTML的属性及用法:
七. HTTP协议之请求
我们向一个网址(也就是URL,之后采取的都会是URL的称呼)发起请求,这个URL所在的服务器会相应地返回我们一个结果,这个结果就是响应。看起来似乎是一个很简单的流程,其实不然。无论是请求还是响应,都会隐形地携带很多和请求、响应有关的内容,接下来,我们就来看看都会携带哪些参数(参数有很多,我们挑下重要的讲讲)
7.1 请求报文重要片段信息:
我们来看看请求报文中我们需要了解哪些与爬虫有关的信息:

1)method:
这个字段是用来指明请求的方法是哪一种的,常用的请求方法有GET、POST,这两种请求有什么区别、以及分别适用什么场景,后面我们会详细讲解。如果method是GET的时候,在使用requests的时候,就只能用requests.get(),比如这样:
import requests
response = requests.get('https://www.zhihu.com')如果method是POST的时候,在使用requests的时候,就只能用requests.post(),而post是请求是需要传递数据的,这个之后会详细介绍。比如这样:
import requests
data = {
'username': 'kuuud',
'password': 'kuuud'
}
response = requests.post('https://www.wzhihu.com', data=data)2)Accept:
这个字段是用来通知服务器,用户代理(浏览器等客户端)能够处理的媒体类型及媒体类型的相对优先级。可以使用type/subtype这种形式,一次可指定多种媒体类型。常用的媒体类型有以下几类:
文本文件:text/html,text/plain,text/css,application/xhtml+xml, application/xml...
图片文件:image/jpeg,image/gif,image/png...
视频文件:video/mpeg,vedio/quicktime...
应用程序使用的二进制文件:application/octer-stream,application/zip...附:比如说浏览器不支持图片PNG的显示,那么accept就不指定image/png,因为浏览器处理不了。(这个字段需要了解,尤其是如果后期想从事网站开发的童鞋)
- 客户端发起请求时,服务器会返回一个键值对形式的数据给浏览器,下一次浏览器再访问这个域名下的网页时,就需要携带这些键值对 数据在 Cookie中,用来记录用户在当前域名下的历史行为的。
- 提到Cookie就不得不提,HTTP本身是一种无状态的协议,它是不会保存每次请求和响应的
- 相关信息的,就比如我们登录淘宝,如果没有Cookie技术,那么我们每进入一个淘宝的页面都需要重新登录一次,这样是不是会特别麻烦?
- 就是因为这个原因,才引入了Cookie技术,使得用户在一个域名下的历史行为能够得以保 存,只要登录一次淘宝就可以了,不需要频繁地登录,而且能够看到历史记录。
- 这个字段很重要,在爬虫中经常会用到,因为有的数据只有携带了Cookie才能够爬取到,所以经常会根据前次访问得到 cookie数据,然后添加到下一次的访问请求头中。
import requests
url = 'https://www.baidu.com'
headers = {
'cookie': 'PSTM=1496322685; BIDUPSID=BC36002F7DA142E6674AE290CD5A38DB; _ _cfduid=ddf4836dd1f1ac99eeea8ef0f140493301522406372; BAIDUID=5FA7A2B4FDDA3C ECC6BE9B74FDCD00B8:FG=1; sugstore=1; BDUSS=1hvT3VoQmc5TDl5bFE1c2NjcGpOenByc nJTOEstZ0ZKcGs5UnB1dzVyU1hpYXRiQVFBQUFBJCQAAAAAAAAAAAEAAABCcYSYAAAAAAAAAAAA AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAJf 8g1uX~INbR; BD_UPN=12314753; MCITY=‐340%3A; delPer=0; BD_CK_SAM=1; PSINO=7; BDRCVFR[Dq4jqEr7erC]=mk3SLVN4HKm; H_PS_PSSID=; BDORZ=FFFB88E999055A3F8A630C 64834BD6D0; H_PS_645EC=216feJgh%2BnAm%2BJD6G3sw10RBbYN1O%2FeCJqUhgtRyZ3OuJO 0EOqbXUwL8Kgf8zhqXH7RWxBnn; BDSVRTM=0; ispeed_lsm=6'
}
response = requests.get(url, headers=headers)4)Refer:
这个字段用来记录浏览器上次访问的URL,有的网站会通过请求中有没有携带这个参数来判断是不是爬虫,从而确定是否限制访问。所以有时候也需要在headers中添加上这个参数。
5)User-Agent:
是用来标识请求的浏览器身份的,大部分网站都会通过请求中有没有携带这个参数来判断是不是爬虫,从而确定是否限制访问。所以有时候也需要在headers中添加上这个参数;
代码如下:
import requests
url = 'https://www.baidu.com'
headers = {
'user‐agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'
}
response = requests.get(url, headers=headers)但当我们要爬取的数据量比较大的时候,仅仅用一个user-agent是不够的,因为服务器又不傻,你一个浏览器不停地在访问我的URL,而且频率那么快,肯定不是人在后面操作,然后就会限制你的访问了,所以我们经常会用一个user-agent列表,来回地切换。这样服务器就会以为是多个浏览器(也就是多个用户)在访问URL,会判断这是正常的;
代码如下:
import requests,random
url = 'https://www.baidu.com'
agent_list = [
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (K HTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en‐us) AppleWebKit/53 4.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)'
]
# 这是一个User‐Agent列表,在使用的时候随机从中选取一个作为请求头的参数传递进去
headers = {
'user‐agent': random.choice(agent_list)
}
response = requests.get(url, headers=headers)7.2 HTTP请求报文
组成:请求行 + 请求头 + 请求体请求行:请求方法,请求地址(URL),HTTp版本请求头(报文头):以key-value方式存储,存储是客户端信息请求体(报文体):需要传递的一些参数信息
组成:响应行 + 响应头 + 响应体响应行:HTTp版本,状态码响应头(报文头):服务端信息响应体(报文体):需要传递的数据
2开头2xx:成功类3xx:重定向4xx:客户端错误5xx:服务端错误
总结
程序员写代码并不是从0开始的,我们也是需要借助多个模板拼接,使得代码能够实现我们的想法,而且也并非默写出来,毕竟学习编程是开卷学习,开卷使用,加油,希望你我一同走进爬虫的世界~~
欢迎大家留言一起讨论问题~~~
爬虫系列文章目录
一:初识爬虫——爬虫与HTML介绍
二:初始爬虫——BeautifulSoup分析及实践
扩展知识一:爬虫scrapy框架不理解?通俗⼀点告诉你
扩展知识二:爬虫多协程该咋说呢?其实不难