LSM-Tree - LevelDb了解和实现
引言
自从[[《数据密集型型系统设计》LSM-Tree VS BTree]]这篇文章完成之后,对于LSM-Tree这种结构非常感兴趣,于是趁热打铁在之后的几天静下心来研究了一下LevelDB的具体实现,最终阅读了一下源代码。
本文涉及了LevelDB的基础功能和相关数据结构的介绍,最后讲述LevelDB中至关重要的读写操作,通过设计数据结构和读写操作的讲解,相信读者可以自行解答为什么LevelDB可以做到极为高效的读写操作,并且比查询操作要远远优秀。
简介
Levledb是Google的两位Fellow (Jeaf Dean和Sanjay Ghemawat)设计和开发的嵌入式K-V系统,读写性能非常彪悍,官方网站报道其写性能40万/s,读性能达到6万/s,写操作要远快于读操作。
如果对于这个数据结构感兴趣,可以访问下面的github:
https://github.com/google/lev...
意义
需要注意的是Level-DB不仅是LSM-Tree日志存储结构的代表作品,同时也是对于Bigtable中SSTable的实践和扩展。
数据结构
首先底层的基础数据结构是LSM-Tree,同时存储结构为Key-Value形式,但是在此基础上进行了一些调整,比如让数据存储在磁盘并且保证数据的顺序读写,为了高效读取设计了大小树结构,也就是将LSM- Tree一分为二,大的存磁盘,小的常驻内存,两者共同维护同一个。
当数据不断写入导致树不断的膨胀,此时为了频繁的磁盘写入对于数据肯定会有很大的影响,索引LevelDb将树在此基础上又拆分了多层,当一层的数据到达一定量的时候就往下一层归并,最终形成一颗自上而下的增长树。LevelDb的Level就是这么来的。
下面是这种特殊结构的设计图:

基本特征
- 键和值是任意字节数组。
- 数据按key排序存储。
- 调用者可以提供自定义比较函数来覆盖排序顺序。
- 基本运算是
Put(key,value),Get(key),Delete(key). - 可以在一个原子批处理中进行多项更改。
- 用户可以创建临时快照以获得一致的数据视图。
- 支持对数据进行前向和后向迭代。
- 使用Snappy 压缩库自动压缩数据。
- 外部活动(文件系统操作等)通过虚拟接口中继,因此用户可以自定义操作系统交互。
- 系统可移植性很强,因为底层使用了C++编写。
数据结构
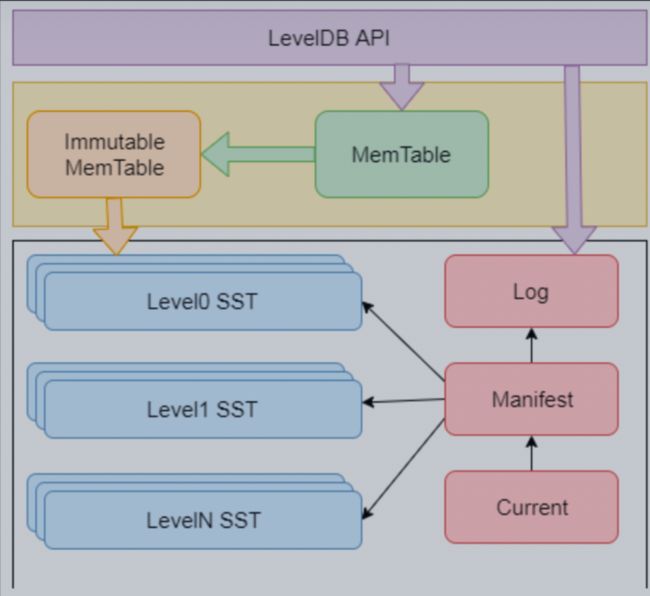
下面是各个组件介绍:
- Memtable:LevelDB在写入数据的时候并不会直接写入磁盘,而是和多数的数据库工具一样先写入到内存的数据结构,内存数据结构通过跳表实现,新的数据会首先写入这里,Memtable负责管理所有的Key数据,这种数据结构效率可以比拟二叉查找树,绝大多数操作的时间复杂度为O(log n)。
- Log:Level-DB是典型的日志存储结构形式,在写入Memtable之前首先写入日志文件,对于写入日志以单纯的追加形式进行写入,这一点相比Btree相关的注重事务的复杂日志维护要简单不少,Level-DB和多数的LSM-Tree没有太大区别,日志的主要作用是数据库崩溃之后进行数据恢复,比如当程序出现下面的问题之后可以通过Log进行数据恢复:
- 写log期间进程异常。
- 写log完成,写内存未完成。
- write动作完成(即log、内存写入都完成)后,进程异常。
- Immutable memtable持久化过程中进程异常。
- 其他压缩异常(较为复杂,首先不在这里介绍)。
- Immutable Memtable:顾名思义不可变的内存数据结构,当内存数据结构数据满了之后就需要触发数据合并的操作,此时需要停掉数据读写并且对数据进行压缩。
不可变的数据结构其实是通过简单的C++ 锁机制实现的,不需要额外的维护锁对象控制。
- SST文件::磁盘数据存储文件,分为Level 0到Level N多层,每一层包含多个SST文件;单层SST文件总量随层次增加成倍增长。SST文件本身是不可被修改的,这是Level-DB 设计哲学的一环,通过追加的和定期合并文件的方式实现了“删除”的操作,同时在读取的时候通过特殊的标记来判断更新还是删除操作,借此保证获取到最新的数据,这些内容在源代码中都能很好的发现,在后续的文章中会详细的解释,这里只需要有个大概的概念即可。
- Manifest文件: Level-Db存在版本控制的概念,版本信息的差别主要来自于每一层维护的元信息的差别。Manifest文件在整个系统中十分关键,不仅维护了最大key和最小key,Manifest文件中还记录SST文件在不同Level的分布,同时MainFest主要管理SST文件的层级,在进行合并操作的时候需要依赖Mainfest文件中的元信息完成合并的关键步骤。
元信息包括:(1)最大Key值,(2)最小Key值,(3)文件大小。
- Current文件:LevelDB启动时的首要任务就是找到当前的Manifest,而Manifest可能有多个,Current文件记录了Manifest文件相关的文件名。
读写操作
在了解源代码之前我们从数据库的读写操作进行分析。如果了解Btree和事务型数据库的生态就会发现两者的差别是非常大的,Level-DB 的最大优点是读写速度要优秀于查询动作,由于不需要事务所以他的性能要比Btree的搞非常多。

可以看到整个Level-DB分为两次写操作,头一次是写入log,接着才是写入记录数据,但是写入记录的数据并不会立刻写到磁盘,而是通过一些触发机制完成。
由于记录日志的方式够简单直接,所以Level-DB可以拥有很好的写入性能,如果在用户写入完成但是数据没入盘的时候突然发生系统宕机没有影响,因为数据压根没有写入硬盘,只要再次读日志还原相关操作即可。
写操作实现
LevelDb对外提供了1)Put2)Delete两种接口,但是更新的操作和删除的操作可以看作是同一个操作,一个Delete操作会被转换成一个value为空的Put操作。
另外LevelDB 专门提供了批量操作的工具Batch完成批量操作的动作,为了保证数据的完整性,内部会通过加锁的方式实现原子操作。
Batch的整体结构大致如下:

注意:这个结构图并不完整,在源代码里面还有其他的信息,这里简化了部分数据
批量操作的每一个操作项都是通过类似上面的结构组成,通过type来标记整个记录的数据项类型,在记录key的内容之前,会记录key的长度,同样记录value的值之前会记录整个value的长度。
另外batch中还会维护一个size值表示key+value长度的总和,以及每条数据项额外的8个字节表示,这8个字节标识用于存储一条数据项额外的一些信息。
原子性操作:
写操作的原子性体现日志记录操作上,一条日志记录的所有内容代表了一次写操作,这也是日志的写入最小单位。
既然是日志写入就会出现下面两种情况:
- 未开始写入或者日志写一半断电。
- 日志写入完成真实数据没有变动。
合并写入操作:
LevelDb合并写入操作
合并写入是对于日志问题的最大挑战, 为了保证操作原子性,并发写入的时候只有一个线程允许操作日志和追加数据,但是这样显然会影响写入的性能并且导致多线程阻塞等待,为了提高写入的性能,对于多线程频繁的写入的操作进行“合并”,将单一线程对于同一个日志的多次操作进行合并。
整个合并写入的流程如下: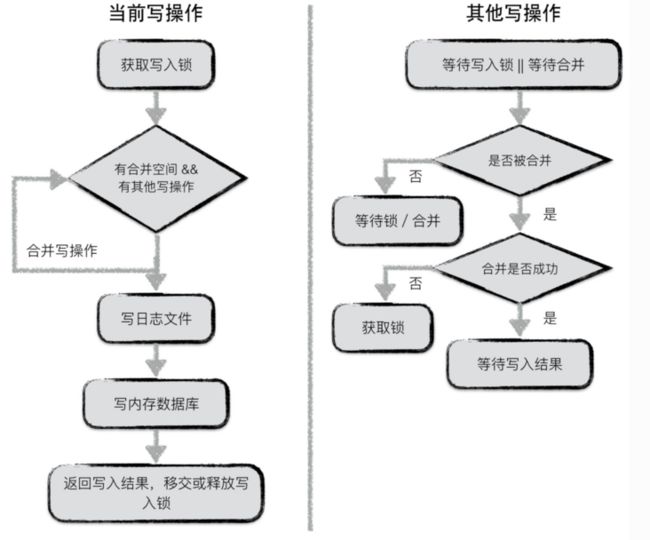
- 第一次写入获取写入锁。
- 写操作没有达到出发合并写入的阈值,并且存在其他写入线程等待的情况下,将会“帮忙”把其他线程的写操作和自己进行合并。
- 如果到达了合并写入的阈值,并且没有其他线程等待的时候,把所有的内容合并写入到日志文件,然后再存储到数据库当中。
- 通知其他“被帮忙”的线程我已经帮你们把活干完了并且把操作结果告诉你们,同时释放写锁给下一个访问线程。
对于其他的线程来说合并写入的操作类似下面的情况:
- 等待上一个锁的持有者完成合并写入操作,如果操作成功接受结果并且返回。
- 如果上一个线程操作失败或者没有进行表明当前的锁可以进行合并写入了,则自动结果任务继续尝试合并写入的操作。
- 如果还是没有合并完成继续等待锁和合并结果。
通过这样的处理可以发现无论那个线程进来都可以尝试帮其他线程工作,但是仅限于和自己的操作相关的内容可以尝试合并。
读操作实现
读操作的实现通过下面两种方式完成:
- 通过
get接口完成数据的获取。 - 为了提高读取的效率,会通过快照对于当前读到的数据进行缓存,最终通过快照的
get接口完成数据获取。
从这里来看,快照即是缓存也是代理。
其实两个操作类似,只不过一次读操作之前加入了快照,但是快照读到的数据不会因为后续的记录操作出现改动。
快照类似数据库某一个时刻状态的一个拷贝,对于大量的读操作来说可以减轻数据查找的压力。
这里可能会存在疑问,读取的快照出现更新的时候会出现什么情况?
这里就必须要简单描述一下快照的实现了,快照的实现是通过 乐观锁 的方式实现的,内部通过维护一个 版本号的方式记录同一个Key的操作结果,同时一条记录有唯一的序列号,序列号在每次记录变动的时候不断+1,意味着序列号越大记录的值越新。
也就是说通过序列号和版本号这两个值可以模拟整个数据项的变更状态,同时为了保证快照的有效性,可以通过版本号和序列号检查是否对应,反过来说,如果当前序列号超过快照的序列号,则直接“掩盖”保证快照不会读到最新的数据。
如果你了解Mysql的InnoDB中的MVCC机制,那么相信更好理解。
读取的步骤:
- 在memtable中获取指定Key,如果数据符合条件则结束查找。
- 在Imumemtable中查找指定Key,如果数据符合条件则结束查找。
- 按低层至高层的顺序在level i层的sstable文件中查找指定的key,若搜索到符合条件的数据项就会结束查找,否则返回Not Found错误,表示数据库中不存在指定的数据。
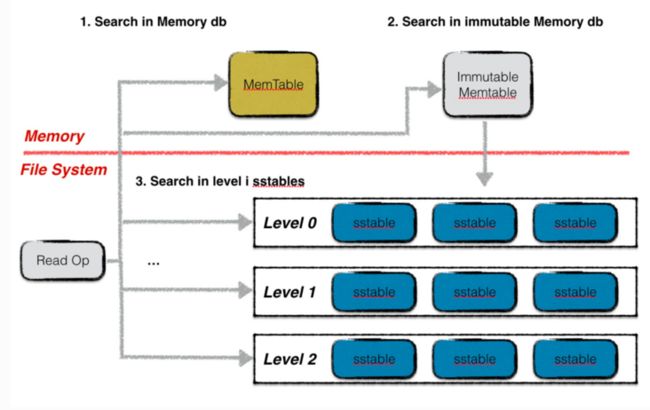
在LevelDB的每一层扫描SSTable 是按照顺序扫描的方式进行查找的(中间不会跳过)。
Level0层最为特殊,因为SSTable之间的Key会出现重合的情况,所以这时候会根据文件编号更大的作为查找参考
PS:为什么要文件编号更大的数据作为参考,因为序列号是递增的,所以更大的文件编号会存在更新的数据。
Level N层的数据,Key之间不会存在重合,并且由于每一层通过Mainfest的元数据找到最大key和最小key进行快速的定位操作,最终每一层只需要扫描一个SSTable就可以往下查找。
在memory db或者sstable的查找过程中,需要根据指定的序列号拼接一个internalKey,如果查找用户key一致且seq号不大于指定seq的数据。
小结
本节内容简单介绍了LevelDB,并且介绍了内部几个重要的数据结构内容,之后介绍了有关Level读写操作的细节,这些内容的理解对于后续介绍源代码是一个前提和铺垫。
在介绍完数据结构和读写操作的大致流程之后,下一节将会深入具体的源代码进行拓展介绍。