kaggle——信用卡欺诈检测项目实战
笔记
- 第一步:了解题目,确定任务
- 第二步:场景分析
- 第三步:数据预处理
-
- 看是否有缺失值
- 查看样本类别分布
- 数据不均衡解决办法
- 数据值标准化/归一化
- 第四步:特征工程
-
- 1)查看特征分布情况,把不同类别下特征分布相差不大的特征删除掉
- 2)特征缩放
- 3)特征重要性分析
- 第五步:模型训练
-
- 处理不平衡样本
- k折交叉验证或者网格搜索调优参数(grid search)求取最好的模型参数
- 第六步:模型评估
-
- 使用下采样数据训练与测试
- 使用下采样数据训练与测试(不同的阈值对结果的影响)
- 使用下采样数据训练,原始数据进行测试
- 原始数据进行K折交叉验证
- 使用原始数据进行训练和测试
- 查看ROC曲线
- 逻辑回归阈值选择
- 过采样
- 总结
第一步:了解题目,确定任务
信用卡欺诈是指故意使用伪造、作废的信用卡,冒用他人的信用卡骗取财物,或用本人信用卡进行恶意透支的行为。
常见信用卡欺诈使用的情况有:
1.失卡冒用:失卡一般有三种情况,一是发卡银行在向持卡人寄卡时丢失,即未达卡;二是持卡人自己保管不善丢失;三是被不法分子窃取。
2.假冒申请:利用他人资料申请信用卡,或是故意填写虚假资料申请,伪造身份证,填报虚假单位或家庭住址等
3.伪造信用卡:据统计,国际上信用卡诈骗案件中,有60%以上是伪造卡的诈骗,其特点是团伙性质,从盗取卡资料、制造假卡、贩卖假卡,到用假卡作案。伪造者经常利用一些最新的科技手段盗取真实的信用卡资料,有些是用微型测录机窃取信用卡资料,有些是伺机偷改授权机终端功能窃取信用卡资料,当窃取真实的信用卡资料后,便进行批量性的制造假卡,然后通过贩卖假卡大肆作案,牟取暴利。
本项目通过利用信用卡的历史交易数据,通过数据预处理,变量选择,建模分析预测等方法,构建简单的信用卡反欺诈预测模型,提前发现客户信用卡被盗刷的事件。
本项目通过利用信用卡的历史交易数据——进行机器学习,构建信用卡反欺诈预测模型——提前发现客户信用卡被盗刷的事件。
确定任务:即通过用户的历史信息,建立一个反欺诈预测模型,当有新的用户刷卡信息来的时候,模型能准确的预测出这是正常的刷卡行为还是盗刷行为即预测持卡人的信用卡是否被盗刷。
第二步:场景分析

**分析场景:**判断是否监督,二分类还是多分类。——场景不同,应用的算法也不同。
首先,我们拿到的数据是是有标签的,每个样本中表明了是不是盗刷行为的。无盗刷行为是0,有盗刷行为是1——所以确定了是一个监督学习的场景。
其次,持卡人是否发送盗刷是一个二分类问题——意味着可以通过二分类相关的算法来找到具体的解决办法。(比如用逻辑回归,逻辑回归就是一个二分类问题)
分析数据: 给我们的数据一共是31列。其中特征v1到v28是经过PCA处理的,我们不需要动。然后特征时间和消费金额,两个数据的值和其他特征数据值相差很大,所以我们需要做特征缩放,将特征缩放到同一规格。 在数据质量方面,没有出现乱码或空字符的数据,最后一列特征class为我们的目标列,前30列为我们的特征列。
如何处理这份数据进行我们最后的验证:数据是全部打标好的数据,可以通过交叉验证的方法对训练集生成的模型进行评估。70%的数据进行训练,30%的数据进行预测和评估。
现对该业务场景进行总结如下:
1.根据历史记录数据学习并对信用卡持卡人是否会发生被盗刷进行预测,二分类监督学习场景,选择逻辑斯蒂回归(Logistic Regression)算法。
2.数据为结构化数据,不需要做特征抽象,是否需要做特征缩放有待后续观察
第三步:数据预处理
原始数据为个人交易记录,但是考虑数据本身的隐私性,已经对原始数据进行了类似PCA的处理,现在已经把特征数据提取好了,接下来的目的就是如何建立模型使得检测的效果达到最好,这里我们虽然不需要对数据做特征提取的操作,但是面对的挑战还是蛮大的。

它只包含作为PCA转换结果的数字输入变量。不幸的是,由于保密问题,我们无法提供有关数据的原始功能和更多背景信息。特征V1,V2,… V28是使用PCA获得的主要组件,没有用PCA转换的唯一特征是“时间”和“量”。特征’时间’包含数据集中每个事务和第一个事务之间经过的秒数。特征“金额”是交易金额,此特征可用于实例依赖的成本认知学习。特征’Class’是响应变量,如果发生被盗刷,则取值1,否则为0。 一共为31列。共31个特征。
看是否有缺失值


无缺失值。如果有缺失值,可以用中位数或者平均数代替。
查看样本类别分布
看看样本的分布是如何的,是不是不平衡样本,也就是不同的类对应的数量相差极大。
正负样本数相差极大。
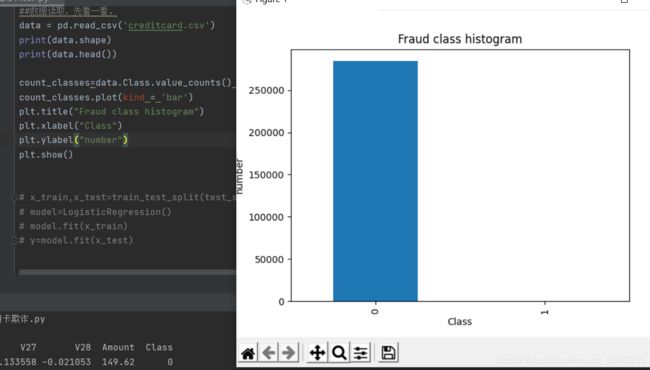
数据很不均衡:数据不均衡很可能导致我们模型预测结果‘0’时很准确,而预测‘1’时并不准确。
注意,在数据分析阶段,先不对数据样本数量进行调整,否则会干扰后续的特征工程。在模型训练阶段,用训练样本训练模型的时候,再进行样本不均衡调整。
数据不均衡解决办法
处理这个不平衡问题,可以从数据和算法两个层面入手。
1.数据
下采样(比较简单实现):下采样——给我下去。不是两类数据不均衡吗,那我让你们同样少(也就是1有多少个 0就消减成多少个),这样不就均衡了吗。即把多的样本下去删除掉。
很简单的实现方法,在属于0的数据中,进行随机的选择,就选跟class为1的那类样本一样多就好了。让多的跟少的一样
过采样:让少的跟多的一样

1、数据层面:欠采样、过采样、欠采样和过采样结合
2、算法层面:集成学习、代价敏感、特征选择
改变评价标准,以下标准可以更加深入地洞察模型的准确率
混淆矩阵:将要预测的数据分到表里来显示正确的预测(对角线),并了解其不正确的预测的类型(哪些类被分配了不正确的预测);
精度:一种分类准确性的处理方法;
召回率:一种分类完整性的处理方法;
F1分数(或F-分):精度和召回率的加权平均。
使用不同的算法


数据值标准化/归一化
amount序列数值浮动比较大待会要做标准化或归一化,因为计算机对于数值较大的值会误认为该特征的权重大,要把数据的大小尽量均衡

第四步:特征工程
1)查看特征分布情况,把不同类别下特征分布相差不大的特征删除掉
1)先查看盗刷与正常刷卡的刷卡金额分布图
即查看不同类别的特征数值分布图
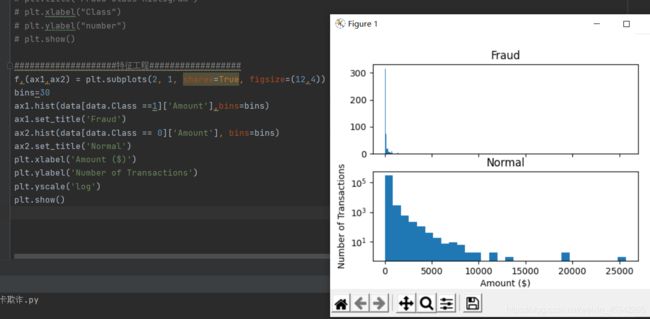 横轴是金额,纵轴是交易数量。
横轴是金额,纵轴是交易数量。
两者数据分布相差较大。不能删掉该特征。信用卡被盗刷发生的金额与信用卡正常用户发生的金额相比,比较小。这说明信用卡盗刷者为了不引起信用卡卡主的注意,更偏向选择小金额消费。
2)正常刷卡与盗刷时间分布

信用正常刷卡与盗刷时间分布从大体上看并没有太大差别,由此推测盗刷者为了减小被识别的风险,将盗刷时间放在正常刷卡时间集中区域。因此建立模型预测时,可以将该特征过滤。
3)查看其它特征分布

我们将选择在不同信用卡状态下的分布有明显区别的特征变量。因此剔除变量V8、V13 、V15 、V20 、V21 、V22、 V23 、V24 、V25 、V26 、V27 和V28变量这也与我们开始用相关性图谱观察得出结论一致,同时剔除变量Time。

2)特征缩放
可以明显看到金额特征的值和其他特征的值相差加大,所以进行特征缩放
为了消除不同量纲之间的影响,将‘Amount’特征标准化形成新的特征‘normAmount’,
3)特征重要性分析
利用随机森林的feature importance对特征的重要性进行排序
链接


用随机森林进行特征重要性排序时,会加大连续特征的重要性,比如索引号是连续值从0–100000,会加大它的重要性,但其实它和我们最终的目标没有任何关系。所以要具体分析。
第五步:模型训练
第一种:先划分训练集测试机,然后对训练集进行下采样/过采样,测试集是正常的样本。
第二种:先下采样,然后再进行训练集测试机划分,这样的测试集是采样后的,不能准确代表模型的能力
处理不平衡样本
1)简单的方法——下采样
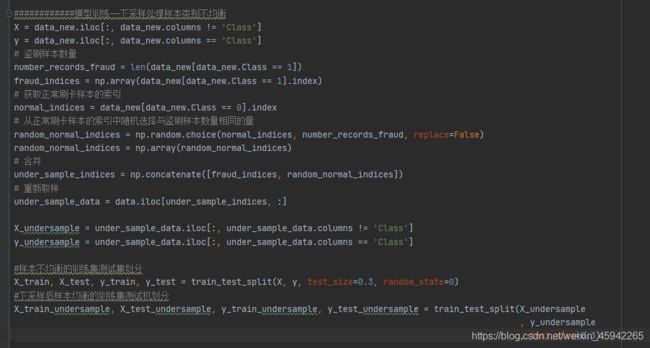
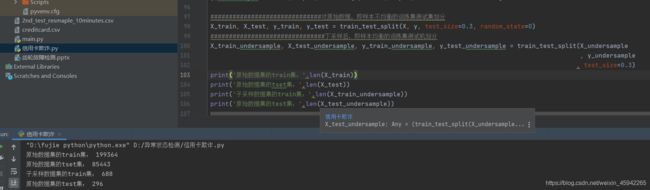
上面我们可以看到我们制造的样本均衡的数据比较小,在做测试是测试集不足以代表样本的整体性,所以真正测试时还是用原来数据集的测试集比较符合原始数据的分布
2)使用SMOTE算法做数据过采样
SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中
只对训练集进行过采样。
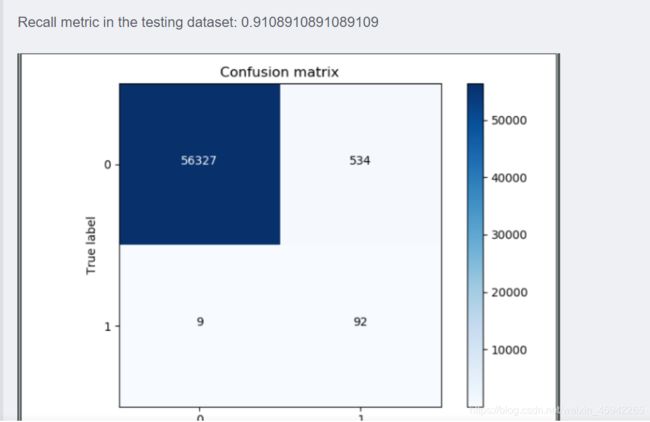
说明:过采样明显减少了误杀的数量,所以在出现数据不均衡的情况下,较经常使用的是生成数据而不是减少数据,但是数据一旦多起来,运行时间也变长了。
k折交叉验证或者网格搜索调优参数(grid search)求取最好的模型参数
最好的取值为c=10

第六步:模型评估
不同的目标任务,对应着不同的模型指标。
在这里我们是要尽可能的把那些有欺诈行为的用户全都检测出来,所以使用召回率。
我们的目的是什么呢?是不是要检测出来那些异常的样本呀!
换个例子来说,假如现在医院给了我们一个任务要检测出来1000个病人中,有癌症的那些人。那么假设数据集中1000个人中有990个无癌症,只有10个有癌症,我们需要把这10个人检测出来。
假设我们用精度来衡量,那么即便这10个人没检测出来,也是有 990/1000 也就是99%的精度,但是这个模型却没任何价值!这点是非常重要的,
因为不同的评估方法会得出不同的答案,一定要根据问题的本质,去选择最合适的评估方法。
使用下采样数据训练与测试


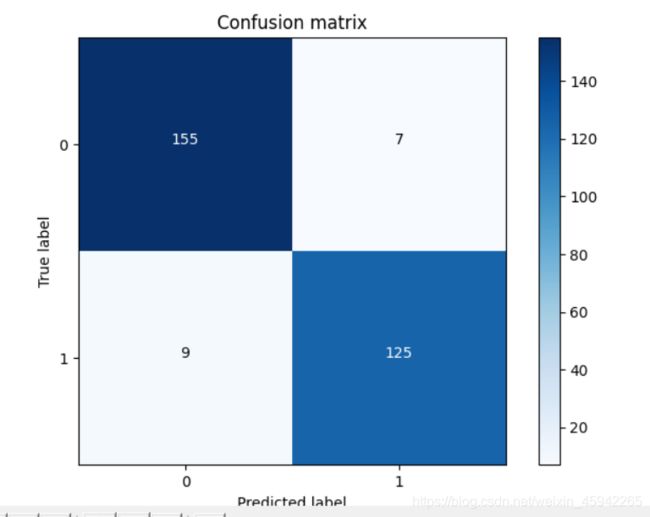
使用下采样数据训练与测试(不同的阈值对结果的影响)
对于阈值,设置的太大不好,设置的太小也不好,所以阈值设定地越适当,才能使得模型拟合效果越好。
Recall metric in the testing dataset: 0.9727891156462585
Recall metric in the testing dataset: 0.9523809523809523
Recall metric in the testing dataset: 0.9319727891156463
Recall metric in the testing dataset: 0.9319727891156463
Recall metric in the testing dataset: 0.9319727891156463
Recall metric in the testing dataset: 0.9251700680272109
Recall metric in the testing dataset: 0.8979591836734694
Recall metric in the testing dataset: 0.8775510204081632
Recall metric in the testing dataset: 0.8639455782312925

使用下采样数据训练,原始数据进行测试
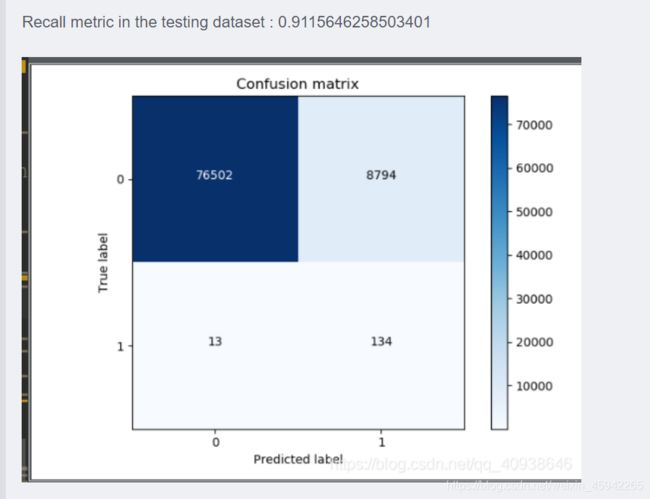
可以看到虽然召回率比较高,但是正确样本有8794个被分类错误。这也是下采样的缺点。把很多正确的分成了错误的。
说明:对于下采样得到的数据集,虽然召回率比较高,但是误杀还是比较多的。这个现象其实就是下采样策略本身的一个缺陷。
原始数据进行K折交叉验证


使用原始数据进行训练和测试

查看ROC曲线
Roc曲线:即接收者操作特征曲线(receiver operating characteristic curve),反映了真阳性率(灵敏度)和假阳性率(1-特异度)之间的变化关系。Roc曲线越趋近于左上角,预测结果越准确。
逻辑回归阈值选择
对于逻辑回归算法来说,我们还可以指定这样一个阈值,也就是说最终结果的概率是大于多少我们把它当成是正或者负样本。不用的阈值会对结果产生很大的影响。

阈值较小,意味着我们的模型非常严格宁肯错杀也不肯放过,这样会使得绝大多数样本都被当成了异常的样本,recall很高,精度稍低
当阈值较大的时候我们的模型就稍微宽松些啦,这个时候会导致recall很低,精度稍高,
综上当我们使用逻辑回归算法的时候,还需要根据实际的应用场景来选择一个最恰当的阈值!
如何设置阈值没有固定的标准,更多的结合业务来判断(因为不同的阈值,对召回率和精确率是有影响的),就看我们的业务到底希望提升那个指标为参考。例如:信用卡欺诈这种业务,更希望召回率高些(意思就是把可能欺诈交易全部拦截)
如果是想要召回率高,就把阈值设置的低点,宁可错杀100,也不能放过1个。
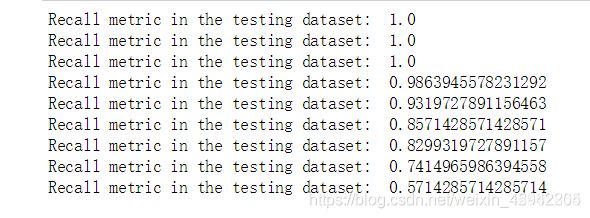
过采样
总结
确定任务——分析场景(监督/无监督、二分类/多分类,采用什么算法)——数据预处理(看有没有缺失值,不同类别的数据量相差大不大,归一化标准化)——特征工程(删除不同类的特征数据分布相差不大的,构造新的特征类)——训练模型(先划分训练集测试集,在这里处理一下数据分布,如果遇到数据不均衡则考虑把训练集下采用,下采样会把很多正确的分成错误的。或过采样,然后训练集进行训练,利用k折交叉验证找到模型的最优参数)——评估模型(不同任务对应不同的评估指标,如该项目就是考虑召回率,有多少盗用信用卡的用户被我们检测到了)——评判结果(评估指标好,就说明可以了,模型可以用了。如果评估指标不好,想着其他解决办法,对于逻辑回归算法来说,取值不同的阈值对我们最终的结果也是有影响的。找到最佳阈值。如果找最佳阈值评估指标也不是很高,那么就尝试其他算法,改其他方法)

该项目也可以看作异常检测,用autoencoder来进行异常检测。