HDFS基础-安装伪分布式Hadoop
使用工具
①centos6.5
②jdk1.8
③Hadoop2.7.1
【*】虚拟机使用Linux作为操作系统,这也是在生产情况下运行Hadoop的唯一指定操作系统。由于HDFS依赖于Hadoop,Hadoop依赖于Java。所以需要进行Hadoop的安装和jdk的安装。Hadoop的安装非常简单,大家可以去官网上下载到最新的几个版本。在安装Hadoop程序之前,需要安装两个程序,JDK和SSH(安全外壳协议)。对于伪分布式,Hadoop会采用与集群相同的处理方式,hadoop需要通过SSH来启动Slave列表中各台主机的守护进程,而在伪分布式中Slave为localhost,所以安装SSH也是必须的。
安装步骤
- 安装jdk
①在安装jdk之前,需要查看系统是否已经安装过了jdk。双击桌面的“终端”图标,在shell命令行中输入“java -version”命令,包含有OpenJDK,要先卸载掉OpenJDK,然后再安装sun公司的jdk。
接下来,我们在shell命令行输入“rpm -qa|grep java”命令查看具体的jdk信息。【没有openjdk可以忽略这一步】
rpm -qa|grep java删除openJDK,在shell命令行输入下列命令进行删除:
#rpm -e --nodeps tzdata-java-2013g-1.el6.noarch #rpm -e --nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64 #rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64删除完毕记得检查一下是否删除正确,可在shell命令行中再次输入“java –version”。
②开始安装jdk。在shell命令行输入下面的命令,在/usr目录下新建一个java文件夹
#mkdir /usr/java进入java文件下,下载jdk
#cd /usr/java #wget https://download.oracle.com/otn-pub/java/jdk/8u201-b09/42970487e3af4f5aa5bca3f542482c60/jdk-8u65-linux-x64.tar.gz解压jdk
#tar -zxvf jdk-8u65-linux-x64.tar.gz --解压操作 #mv jdk1.8.0_65 jdk --重命名仅仅是为了后面配置环境变量的时候方便操作③配置环境变量:在shell命令行中输入“vi ~/.bashrc”命令打开文件。这时,我们并不能对文件进行编辑,按下键盘上的“Esc”键后按“I”键进入插入模式,然后我们需要在该文件的末尾添加下列代码。编辑结束后,保存关闭文件,按“Esc”键和“:”键进入命令模式,在文件下方的冒号(:)后面输入“wq!”,回车保存关闭该文件。
JAVA_HOME=/usr/java/jdk export PATH=/usr/java/jdk/bin:$PATH退出到shell命令行下,我们要输入“source ~/.bashrc”命令编译该文件使其生效。
④验证jdk是否安装成功。在shell命令行中输入“java -version”,显示有java version“1.8.0_65“的字样,便安装成功了。
安装Hadoop
①为了操作方便,我们先来配置免密码登录服务SSH。在shell命令行下输入下列命令:
ssh localhost # ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa --此语句中‘’为两个单引号,在输入的时候要注意 # cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys操作过程中,需要我们手动输入密码和yes继续工作。
②开始安装hadoop:在shell命令行输入下列命令在/usr目录下新建一个hadoop的文件夹
#mkdir /usr/hadoop #cd /usr/hadoop下载hadoop2.7.1
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz完成解压后对其重命名。
#tar -zxvf hadoop-2.7.1.tar.gz #mv hadoop-2.7.1 hadoop③配置环境变量:在shell命令行中输入“vi ~/.bashrc”命令打开文件。这里配置环境变量同jdk的步骤相同。我们需要在文件末尾添加下列代码。然后,退出到shell命令行下,输入“source ~/.bashrc”命令编译该文件使其生效。这里需要注意的是,“export PATH=. . .“这行我们无需重写,只需将hadoop路径加到jdk路径后面即可。
JAVA_HOME=/usr/java/jdk HADOOP_HOME=/usr/hadoop/hadoop export PATH=/usr/java/jdk/bin:/usr/hadoop/hadoop/sbin:/usr/hadoop/hadoop/bin:$PATH --第二行不是重新写的,而是在jdk路径后面补充了hadoop的路径如图所示
④在shell命令行输入“cd /usr/hadoop/hadoop/etc/hadoop“命令,然后使用“ls”命令,可以看到该目录下的所有文件,在shell命令行下输入“vi hadoop-env.sh”命令打开hadoop-env.sh文件,并在该文件中添加JAVA_HOME。具体的做法是在该文件中找到“export JAVA_HOME=${JAVA_HOME}”这行代码,将其改成“export JAVA_HOME=/usr/java/jdk”,然后保存关闭该文件。
⑤在shell命令行输入“cd /usr/hadoop/hadoop/etc/hadoop“命令,在shell命令行下输入“vi core-site.xml”命令打开core-site.xml文件,修改该文件。具体的做法是在该文件末尾处的
中添加下列代码,完成后保存关闭该文件 hadoop.tmp.dir /usr/hadoop/hadoop/hadooptmp fs.defaultFS hdfs://localhost:9000 ⑥在shell命令行输入“cd /usr/hadoop/hadoop/etc/hadoop“命令,在shell命令行下输入“vi hdfs-site.xml”命令打开hdfs-site.xml文件,并修改文件。具体的做法是在该文件末尾处的
中添加下列代码,完成后保存关闭文件。 dfs.replication 1 dfs.data.dir /usr/hadoop/hadoop/data ⑦在shell命令行输入“cd /usr/hadoop/hadoop/etc/hadoop“命令,在shell命令行下输入“vi mapred-site.xml.template”命令打开mapred-site.xml.template文件,修改该文件。具体的做法是在该文件末尾处的
中添加下列代码,完成后保存关闭文件。 mapred.job.tracker localhost:9001 ⑧完成了上面的配置之后,在shell命令行输入下面的命令,进入到/usr/hadoop/hadoop/bin目录,执行格式化操作。操作执行后shell界面会显示大量的日志文件,不必理会。
#cd /usr/hadoop/hadoop/bin #./hadoop namenode -format⑨再进入/usr/hadoop/hadoop/sbin目录下,启动hadoop。
#cd /usr/hadoop/hadoop/sbin #./start-all.sh启动过程中,需要我们手动输入yes。
【可能出现的错误】解决办法
⑩验证是否安装完成:在shell命令行中“jps”,出现如下结果,则安装成功
打开火狐浏览器,我们通过页面验证hadoop是否安装成功。火狐浏览器地址栏中输入localhost:50070,观察界面是否如图所示
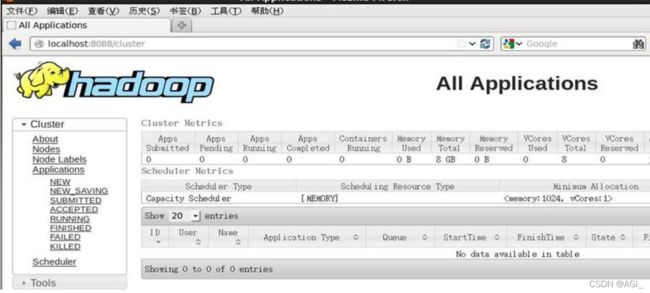
接着再在浏览器地址栏中输入localhost:8088,观察界面是否如图所示。