原文转载自「刘悦的技术博客」https://v3u.cn/a_id_212
有人说,如果一个人相信运气,那么他一定参透了人生。想象一下,如果你在某款moba游戏中,在装备平平,队友天坑的情况下,却刀刀暴击,在一小波gank中轻松拿下五杀,也许你会感叹自己的神操作和好运气,但其实,还有另外一种神秘的力量在支配着这一切,那就是:随机算法。
伪随机(Pseudo-Randomization)
其实,竞技游戏通常是拒绝随机性干预的,因为它干扰了玩家实际操作水平的考量。但是,应对突发情况也应该是玩家应变能力的一种表现。因此,在moba游戏中,有很多随机事件,这些随机事件降低了游戏的可预测性,增加了变数。为了限制这种随机性的影响,伪随机算法应运而生。
伪随机分布(pseudo-random distribution,简称PRD)在游戏中用来表示关于一些有一定几率的装备和技能的统计机制。在这种实现中,事件的几率会在每一次没有发生时增加,但作为补偿,第一次的几率较低。这使得效果的触发结果更加一致。
以Dota2为例,在大量的英雄技能中,比如说斯拉达的重击、酒仙的醉拳、主宰的剑舞之类的技能,都利用了伪随机机制:
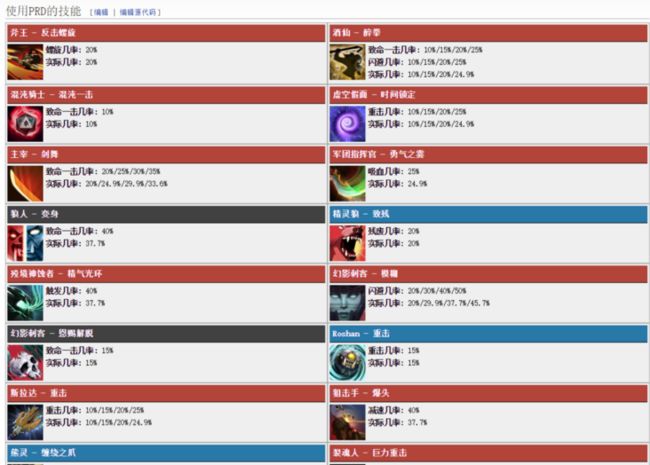
具体的实现逻辑是这样的,每次释放技能,都使用一个不断增加的概率来进行计算,如果这个事件一直触发不成功,那么概率就不断上升,直到事件发生为止。
要完成这个伪随机算法,要解决的问题就是,对于一个发生概率为p的事件,在我们第n次释放技能的时候,发生的几率在第N次成功触发的几率为P(N) = C × N,对于每一个没有成功触发的实例来说,伪随机分布PRD会通过一个常数C来增加下一次效果触发的几率。这个常数会作为初始几率,比效果说明中的几率要低,一旦效果触发,计数器会重置,几率重新恢复到初始几率。
举个例子,斯拉达的重击有25%几率对目标造成眩晕,那么第一次攻击,他实际上只有大约8.5%几率触发重击,随后每一次没有成功的触发实例都会增加大约8.5%触发几率,于是到了第二次攻击,几率就变成大约17%,第三次大约25.5%……以此类推,直到重击的概率达到100%。在一次重击触发后,下一次攻击的触发几率又会重置到大约8.5%,那么经过一段时间之后,这些重击几率的平均值就会接近25%。
基于伪随机的效果使得多次触发或多次不触发的极端情况都变得罕见,这使得游戏的运气成分相对降低了一些。然而虽然理论上可行,但是在游戏中玩家很难运用这个机制来“刻意”增加下一次触发的几率。值得一提的是,Dota2对伪随机技能算法也有限制,如果被释放技能的对象根本就不可能触发效果,那么触发几率不会增加,也就是说,一个英雄反补或攻击建筑不会增加他下一次攻击触发的致命一击几率,因为致命一击对反补和建筑无效。
马尔可夫链(Markov chain)
那么,Dota2底层到底怎么实现的呢?这涉及到一个算法公式:马尔可夫链(Markov chain)
马尔可夫链因俄国数学家Andrey Andreyevich Markov得名,为状态空间中经过从一个状态到另一个状态的转换的随机过程。该过程要求具备“无记忆”的性质:下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。
说白了就是,如果对于一个触发概率为5%暴击的技能,那么我砍第一刀出现暴击的概率是c,第二刀是2c,如果一直没有暴击,直到第N刀,出现了(c*N)大于1了,那么这次暴击就必然发生了,而在中间的每一次,如果暴击发生了,那么我们就把随机概率重置为c。
P = 1*c + 2*c(1-c) + 3*c(1-c)(1-2c)+4*c(1-c)(1-2c)(1-3c)其中 P = 1/p,N=1/c(第N刀,即累加概率的最后一刀必然暴击)
那么我们就可以用折半查找在(0,1)之间不断估算c,直到这个公式成立就行了。
首先,模拟N次触发,计算是否会在N次触发之后必然发生:
import math
def p_from_c(c):
po, pb = 0, 0
sumN = 0
maxTries = math.ceil(1/c)
for n in range(maxTries):
po = min(1, c*n) * (1-pb)
pb = pb + po
sumN = sumN + n * po
return (1 / sumN) 随后,在遍历中,不断地取中值判断,如果触发的概率足够小,那么认为已经找到了对应的c系数:
def c_from_p(p):
cu = p
cl = 0.0
p1, p2 = 0, 1
while True:
cm = (cu + cl) / 2
p1 = p_from_c(cm)
if abs(p1 - p2) <= 0.000000001:
break
if p1>p:
cu = cm
else:
cl = cm
p2 = p1
return cm具体使用上,我们需要单独存储一个阈值变量,那就是释放次数 fail,如果 fail 一直处于未暴击的状态,那就累加对应的释放概率:
fail = 1
print(c_from_p(0.20)*100*fail)
fail = 2
print(c_from_p(0.20)*100*fail)
fail = 3
print(c_from_p(0.20)*100*fail)输出返回值:
5.570398829877376
11.140797659754751
16.711196489632126对于一个20%暴击的技能,第一刀实际上只有5%,第二刀11%,等到砍到第三刀就有16%。
那么知道了底层算法和实现,有什么用呢?我们就可以在游戏中超神了吗?事实上,底层算法对玩家在游戏实际操作技巧是有一定指导意义的,比如,如果玩家能够记住释放技能以后的攻击次数,对应的,玩家脑子里就会有一个概率,事实上,第一刀5%触发的概率还是非常低的,而反补和打建筑物又不能增加fail阈值的次数,所以如果是在团战中,面对半血或者残血英雄,第一刀完全可以不砍他,因为概率太小,完全可以前两刀砍对方别的英雄,留出后面几刀再砍,这样就会在无形中增加暴击或者眩晕技能,是的,如果半血被晕,基本上人头就交出去了,电光石火之间,算法可以帮我们增大超神的概率,要知道,职业玩家的反应能力不是业余玩家可以想象的。

这就好比,在牌局中,真正的高手会靠记忆力将手牌中间段的数量记住,如9/10/J,来保证自己的顺子能够在最后时刻打通或者逼出对手炸弹。
真随机(True-Randomization)
什么叫真随机?有人会说,抛硬币、掷骰子,这些都是真随机事件。
是的,一枚銀色的硬币在半空中快速地翻转着,一闪一闪地泛着光辉,你看不清楚哪面向上、哪面向下,甚至连硬币的主人自己也不清楚。
但其实,抛硬币的角度、力量、周围风速等等因素都会影响最终结果,所以,严格意义上来说,拋硬币当然不是真随机事件,因为这个宏观运动过程和结果严格遵守物理定律,而每次的输入变量也是有限且确定的。
所以,我们所定义的真随机是有条件的,即如果伪随机是靠次数做关联系递增,那么真随机就跟它相反,多次实施过程中没有关联的事件,我们称之为真随机。
那么,在Python中,能否用逻辑实现这种“真随机”?
假设我从1-100个数里,“真随机”挑数字,计数器进行随机挑选后的记录,挑一万次,理论上,它会存在正态分布吗:
import random
from collections import Counter
c = Counter()
for _ in range(10000):
c[random.randint(1, 100)] += 1
print(c)
print(c.values())
print(max(c.values()))返回输出:
Counter({90: 123, 51: 122, 84: 121, 77: 119, 74: 118, 2: 117, 86: 116, 33: 116, 72: 113, 81: 112, 56: 112, 42: 112, 9: 111, 11: 110, 97: 110, 16: 109, 27: 109, 8: 109, 6: 109, 62: 109, 15: 108, 29: 108, 12: 107, 22: 106, 28: 106, 82: 106, 7: 105, 94: 105, 89: 105, 71: 105, 5: 105, 24: 105, 80: 105, 65: 104, 20: 104, 48: 104, 93: 104, 1: 104, 79: 103, 57: 103, 40: 103, 26: 103, 63: 103, 30: 102, 68: 102, 75: 101, 18: 101, 23: 101, 39: 100, 44: 100, 54: 99, 85: 99, 91: 99, 59: 99, 76: 99, 43: 98, 31: 98, 66: 98, 25: 98, 60: 97, 58: 97, 35: 97, 64: 97, 70: 97, 19: 97, 34: 97, 96: 96, 13: 96, 52: 96, 61: 95, 100: 95, 21: 95, 98: 95, 49: 94, 69: 94, 99: 93, 87: 93, 88: 93, 78: 92, 73: 91, 17: 91, 67: 91, 4: 91, 46: 90, 92: 90, 36: 90, 3: 89, 14: 89, 41: 89, 55: 87, 53: 85, 32: 85, 38: 84, 37: 84, 50: 83, 83: 83, 10: 83, 45: 82, 47: 80, 95: 75})
dict_values([121, 99, 112, 99, 94, 110, 89, 93, 93, 98, 95, 91, 109, 100, 109, 116, 104, 105, 91, 84, 106, 104, 105, 92, 106, 83, 104, 105, 110, 103, 82, 102, 112, 85, 105, 103, 85, 89, 103, 99, 117, 83, 87, 96, 100, 96, 90, 105, 123, 99, 91, 104, 101, 118, 99, 103, 91, 83, 98, 95, 98, 107, 111, 97, 104, 101, 113, 116, 97, 98, 97, 122, 90, 101, 108, 94, 96, 106, 112, 97, 102, 103, 108, 75, 97, 109, 80, 93, 109, 109, 95, 95, 90, 97, 89, 84, 105, 119, 97, 105])
123最高的一次出现了123次,接着我们来换个方式,不用random:
import random
from collections import Counter
c = Counter()
for _ in range(10000):
c[100] += 1
print(c)
print(c.values())
print(max(c.values()))返回输出:
Counter({100: 10000})
dict_values([10000])
10000对比之下,我们可以这么理解,出现次数的最大值约大,我们的随机性就越小。
所以,虽然每一次获取没有表面上关联性,但这并不是“真随机”,所以说,计算机到底能不能实现“真随机”?并不能,因为Python的random模块本身就是基于PRD伪随机算法,可以理解为Python中的随机是“使用随机算法”计算出的随机,而使用恰当的随机算法可以让这个随机很逼近“真正”的随机。
结语:
伪随机指的是“从逻辑层面对随机算法的结果进行干扰”,真随机指的是“现有技术或可支出成本无法修正的系统误差”,两套逻辑均被大量应用在游戏领域,但不能否认的是,运气这东西也确实存在,所以古代玩家难免也会发出“时来天地皆同力,运去英雄不自由。”的感慨。
原文转载自「刘悦的技术博客」 https://v3u.cn/a_id_212