爬虫爬取知乎评论并利用flask框架做简单的可视化
学完一点简单的爬虫技术后,直接开始实践…
将知乎的某个评论内容爬取下来,取出里面的关键字,并按照点赞数排序,形成一个表单,点击查看,可以看到原来的内容,比如下面这个网页:
python能做那些有趣还很酷的事
我们发现右边的下拉条是拉不到底的,而且打开开发者模式,发现拉一点,他就加载一点,我们需要循环拉到底
,然后获取整个网页的HTML内容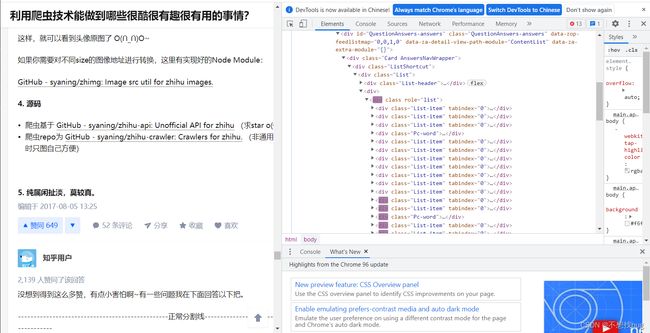
在进行代码编译前需要根据自己浏览器的版本,比如我的谷歌在搜索框输入:chrome://version/
出现:
Google Chrome 96.0.4664.93 (正式版本) (64 位) (cohort: Stable)
我的就是96的
下载地址:http://chromedriver.storage.googleapis.com/index.html
选择符合自己的版本和系统的压缩包,解压后放到项目文件目录下

第一步:获取网页HTML内容
需要导入的库:
from selenium import webdriver # 控制滚动条
from time import sleep # 时间控制
from bs4 import BeautifulSoup # 网页解析 获取数据
代码
# 获取网页HTML内容
def gethtml(url):
driver = webdriver.Chrome() # 初始化一个浏览器
driver.maximize_window() # 设置窗口最大化
driver.get(url) # 打开网页
driver.refresh() # 刷新一下(如果不刷新,在下面循环的时候到最底下就会直接跳出)
temp_h = 0 # 设置一个高度为 0
js = "var q=document.documentElement.scrollTop=100000"
driver.execute_script(js) # 执行上一行的js语句,直接将滚动条下拉到最底下
sleep(3) # 等待三秒,向远程
count = 100
while count > 0: # 这里设置的循环一百次,想爬取完全可以改为True
count -= 1
driver.execute_script("window.scrollBy(0,4000)") # 循环向下拉去4000个单位,可以按照自己的速度设置快慢
sleep(3)
check_h = driver.execute_script("return document.documentElement.scrollTop;") # 获取当前滑动条的位置
if check_h == temp_h:
sleep(3) # 如果相等,等待3秒网速加载
check_h = driver.execute_script("return document.documentElement.scrollTop;")
if check_h == temp_h:
break # 如果还相等,说明滑动条已经跳到下,评论全部加载完成,跳出循环
temp_h = check_h # 将获取的高度设置为初始高度
html = BeautifulSoup(driver.page_source, features="html.parser") # 使用解析器,解析获取的HTML内容
driver.close() # 关闭浏览器
return html
第二步:解析内容
需要导入的库:
import jieba # 分解词汇
import re # 正则表达式 进行文件匹配
import os # 创建目录
import requests # 下载图片
代码:
# 解析网页数据
def getData(baseurl, headers):
findAgree = re.compile(r'') # 查找点赞人数的正则表达式
findContent = re.compile(r'(.*?)
|![]() , re.S)
# 查找item文本内容和图片,里面的超链接,代码,和列表等内容也可以创建正则表达式筛选出来,我就没写了
data = [] # 用来存所有解析好的数据
html = gethtml(baseurl) # 调用获取上一步获取html代码的函数
if os.path.exists("image"):
shutil.rmtree("image")
os.mkdir("image") # 创建一个image文件夹,存爬取的图片,如果已经存在,就删除
for item in html.find_all('div', class_="List-item"): # 解析每一条,div里面class="List-item"的数据
datalist = [] # 用来存每一条解析完的数据
item = str(item) # 将item改为字符串格式
agree = re.findall(findAgree, item) # 点赞人数更改格式
if not agree: # 如果点赞人数列表为空就跳出(那是因为我爬取了几次发现最后一次的点赞人数都为空,会报错)
break
temp = agree[0].replace(",", "") # 去掉数字里面的","
if int(temp) < 5:
continue # 点赞数小于5 表示不是我们感兴趣的数据
content = re.findall(findContent, item) # 用正则表达式查找所有内容
stxt = "" # 用来存查找关键字的文本
image = [] # 用来存需要爬取的图片的url
newcontent = "" # 用来存添加了HTML标签、最后可以直接展示出来的内容
for i, j in content:
if i == '':
if j == "": # 有可能图片也会存在为空的情况,要排除
continue
image.append(j) # 如果content里面的第一项为空,那就说明这次是取到的图片url,具体content的样式自己可以输出来看一看,就明白了
newcontent += '
, re.S)
# 查找item文本内容和图片,里面的超链接,代码,和列表等内容也可以创建正则表达式筛选出来,我就没写了
data = [] # 用来存所有解析好的数据
html = gethtml(baseurl) # 调用获取上一步获取html代码的函数
if os.path.exists("image"):
shutil.rmtree("image")
os.mkdir("image") # 创建一个image文件夹,存爬取的图片,如果已经存在,就删除
for item in html.find_all('div', class_="List-item"): # 解析每一条,div里面class="List-item"的数据
datalist = [] # 用来存每一条解析完的数据
item = str(item) # 将item改为字符串格式
agree = re.findall(findAgree, item) # 点赞人数更改格式
if not agree: # 如果点赞人数列表为空就跳出(那是因为我爬取了几次发现最后一次的点赞人数都为空,会报错)
break
temp = agree[0].replace(",", "") # 去掉数字里面的","
if int(temp) < 5:
continue # 点赞数小于5 表示不是我们感兴趣的数据
content = re.findall(findContent, item) # 用正则表达式查找所有内容
stxt = "" # 用来存查找关键字的文本
image = [] # 用来存需要爬取的图片的url
newcontent = "" # 用来存添加了HTML标签、最后可以直接展示出来的内容
for i, j in content:
if i == '':
if j == "": # 有可能图片也会存在为空的情况,要排除
continue
image.append(j) # 如果content里面的第一项为空,那就说明这次是取到的图片url,具体content的样式自己可以输出来看一看,就明白了
newcontent += ' + j[26:57] + '.jpg"/>
+ j[26:57] + '.jpg"/>
' # 给本地的图片 添加HTML标签:src路径 + 在本地保存的图片名
else: # 下面就是content里面取到的文本内容
if i.find(") == -1: # 查找超链接标签,没找到
i = re.sub(r'![.*?/]() ', '', i) # 去掉知乎的样式图片
stxt += i # 将取出来的文本加入stxt中,用来取出关键字
i = i + '
', '', i) # 去掉知乎的样式图片
stxt += i # 将取出来的文本加入stxt中,用来取出关键字
i = i + '
' # 加上换行标签
else: # 找到了超链接标签
i = re.sub(r'', '', i)
i = re.sub(r'', '', i)
i = re.sub(r'', '', i) # 去掉所有超链接内容
i = re.sub(r'![.*?/]() ', '', i)
stxt += i
i = i + '
', '', i)
stxt += i
i = i + '
'
newcontent += i # 将取到的内容放到新的内容中
kword = findkword(stxt) # 查找关键字
if kword == 0: # 返回0 不存储
continue
datalist.append(temp) # 1、存点赞数
datalist.append(kword) # 2、存关键字
datalist.append(newcontent) # 3、存总文本
print("爬取图片中...") # 下载图片
for i in image:
path = "image/" + i[26:57] + ".jpg" # 下载到本地的路径
while True:
try:
req = requests.get(i, headers=headers, stream=True, timeout=3) # 向图片的url请求
break # 一直死循环爬取,爬取不到不出循环,并不是每次都能爬取成功
except requests.exceptions.RequestException as e:
continue
with open(path, "wb") as f: # 打开文件,保存图片到本地
f.write(req.content)
print("爬取图片完毕")
data.append(datalist) # 添加到需要返回的列表中
return data
查找关键字的函数:
# 查找关键字
def findkword(stxt):
excludes = ["用户", "可以", "我们", "这个", "一个", "于是", "大家", "这些", "--------", "-------------------", "---------", "span", "div", "class", "id"]
# 一些不属于我们需要的内容的词
kw = jieba.cut(stxt) # jieba拆分字符串
d = {} # 空字典,用来存关键字和关键字出现的次数
for i in kw:
if len(i) == 1 or i in excludes: # 去掉我们不需要的词
continue
d[i] = d.get(i, 0) + 1 # 关键字次数加一
newd = sorted(d.items(), key=lambda x: x[1], reverse=True) # 按出现的次数排序
count = 10 # 这里我们取出现次数最多的前十个
temp = ""
if len(newd) < count: # 如果关键字小于我们需要的关键字个数,说明就不是我们想要的数据,就结束,放弃储存
return 0
for i in newd:
temp += i[0] # 将关键字加到我们返回的temp中
if count == 0:
break
temp += "、" # 关键字之间用"、"分割
count -= 1
return temp
第三步:将得到的数据保存在excel中
导入库:
import xlwt # 进行excel操作
代码:
def saveData(data, savepath):
if os.path.exists(savepath):
os.remove(savepath) # 判断excel的路径是否存在,存在就删除
print("保存数据到excel")
book = xlwt.Workbook(encoding="utf-8") # 初始化一个excel对象,编码格式为utf-8
sheet = book.add_sheet("知乎评论内容", cell_overwrite_ok=True) # 向对象中添加一张sheet,更新是覆盖以前单元的数据
col = ("点赞数", "关键字", "内容")
for i in range(0, 3):
sheet.write(0, i, col[i]) # 先写入一行 标题
for i in range(len(data)):
for j in range(len(data[i])):
sheet.write(i+1, j, data[i][j]) # 依次每个位置写入数据
book.save(savepath) # 保存excel
第四步:保存在数据库中
导入库:
import sqlite3 # 进行SQLITE数据库操作
代码:
#保存数据到数据库
def saveDataDB(data, savepathdb):
if os.path.exists(savepathdb):
os.remove(savepathdb) # 判断数据库是否存在,存在就删除
init_db(savepathdb) # 创建数据库和数据表
print("保存数据到数据库")
conn = sqlite3.connect(savepathdb) # 连接到数据库
cur = conn.cursor() # 获取数据库游标
for d in data:
d[2] = d[2].replace("'", "''") # 将数据中的一个单引号变为两个单引号,SQLITE数据库的单引号转义方式
for i in range(len(d)):
d[i] = "'"+d[i]+"'" # 给每个数据两边加上单引号,方便执行sql语句插入
sql = '''
insert into python(
agree,keyword,content)
values(%s)'''%",".join(d) # 插入数据,使用","将d链表里面的数据链接起来
cur.execute(sql)
conn.commit() # 如果不执行这个语句,数据的增加修改不会真的提交到数据库
cur.close() # 关闭游标
conn.close() # 关闭连接
创建数据库:
#创建数据库
def init_db(savepathdb):
sql = '''
create table python
(
id integer primary key autoincrement,
agree numeric ,
keyword text,
content text
);
''' # 创建表的sql语句
conn = sqlite3.connect(savepathdb) # 连接数据库,如果数据库不存在则创建一个数据库
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
第五步:主函数调用
def main():
baseurl = "https://www.zhihu.com/question/27621722" # 网页url
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
} # 添加headers头,爬取图片的时候使用
data = getData(baseurl, headers) # 得到数据
savepath = "有趣的python.xls" # excel路径
savepathdb = "python.db" # 数据库路径
saveData(data, savepath) # 保存数据到excel表
saveDataDB(data, savepathdb) # 保存数据到数据库
print("爬取成功")
数据的爬取与存储就搞定了

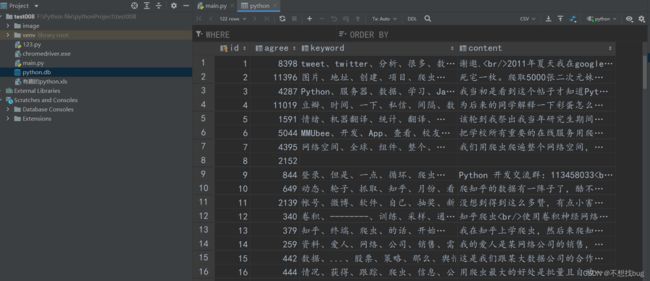
excel:

数据库:
接下来我们做了一点数据的可视化:使用flask框架
第一步:创建主页
导入库
from flask import Flask, render_template, request
import sqlite3
主要代码:
@app.route('/')
def index():
conn = sqlite3.connect("python.db") # 连接数据库
cur = conn.cursor()
sql = "select id,agree,keyword from python order by agree desc"
data = cur.execute(sql) # 查找数据并点赞数排序
newdate = []
count = 0
for i in data:
count += 1
newdate.append(i+(count,)) # 添加一个名次
return render_template("index.html", datalist=newdate) # 跳转到index.html界面,传递一个datalist参数
index.html代码:
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>有趣的pythontitle>
head>
<body>
<table border="1">
<tr>
<td>排名td>
<td>关键字td>
<td>点赞数td>
<td>操作td>
tr>
{% for data in datalist %}
<tr>
<td>{{ data[3] }}td>
<td>{{ data[2] }}td>
<td>{{ data[1] }}td>
<td><a href="/look?id={{ data[0] }}">查看a>td>
tr>
{% endfor %}
table>
body>
html>
运行完效果:
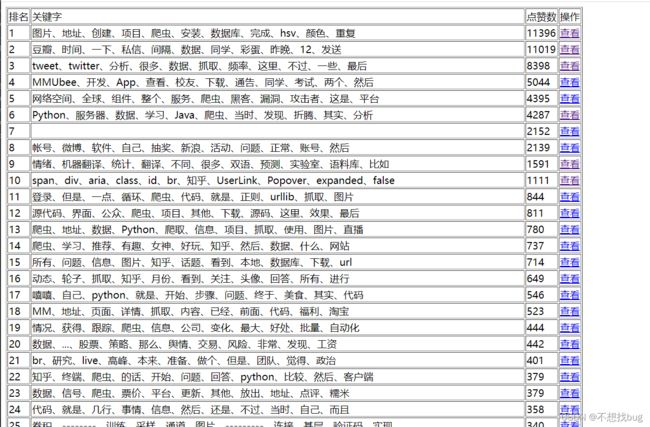
接着查看页面:
@app.route('/look',methods = ['POST', 'GET']) # 添加post、get方法
def look():
id = request.args.get('id') # 获取index.html页面传过来的id
conn = sqlite3.connect("python.db")
cur = conn.cursor()
sql = "select content from python where id = {}".format(id)
content = cur.execute(sql) # 查找文本
for i in content:
newcontent = i
return render_template("look.html", content=newcontent[0]) # 将文本传到look.html页面
look.html:
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>查看title>
head>
<body>
<p>{{ content | safe }}p> # 将传过来的文本转义后输出
body>
html>
效果:
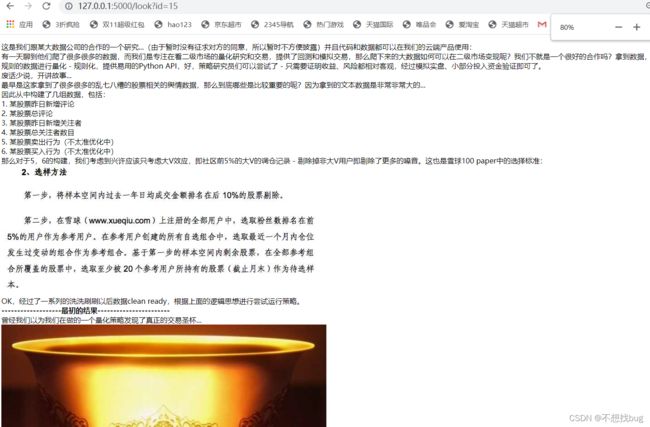
项目到此还没结束
我们在index界面添加一个url的输入框

index.html添加以下代码:
<form action = "" method="post" >
<p>请输入一个知乎网址p>
<input type="text" name="url">
<input type="submit" name="submit" value="开始爬取">
form>
再将爬取数据的代码放入flask框架中,用main函数调用一下

将图片保存的路径修改一下


这样我们的项目就已经完成了,可以实现爬取任何知乎网页数据,只需要你提交一个知乎url
总结:
不会的要学会查阅资料,总有解决办法。我只爬取了文本和图片,超链接和代码也可以根据HTML进行正则表达式摘取,还可以判断是否是知乎网址,还有数据分析,可以制作词云等比较直观的方式,页面也可以美化,但没必要。虽然代码短,但是花费的时间一点都不短。才学疏浅,有什么问题或者能改的可以求大佬给点建议。