python爬取知乎回答并进行舆情分析:爬取数据部分
python爬取知乎回答并进行舆情分析:爬取数据部分
- 背景
- Ajax原理介绍
- Request URL分析
- json报文结构分析
- 代码
- 参考链接
背景
近期导师让我从社交媒体平台(包括微博、知乎、贴吧等)爬取用户评论数据,并进行相应的舆情分析。之前爬取过贴吧和微博的数据,这次第一回接触知乎的爬虫,发现还是有区别的。写篇博客记录一下~
Ajax原理介绍
利用google浏览器打开知乎中任意问题(本文中示例问题为 如何看待天府少年团改名熊猫少儿艺术团,公司称「不做饭圈文化,没有资本运作,爱舞台的孩子做有意义的事」?),发现知乎采取动态加载技术,内容块只有在浏览器下滚时才会刷新。与微博和贴吧不同,知乎的html文件中没有“下一页”的相关节点,无法直接解析。因此需要从原始的Request报文着手,获取文本数据。
Ajax(Asynchronous Java and XML的缩写)是一种异步请求数据的web开发技术,能够改善用户的体验,提高页面性能。
Ajax的工作原理相当于在用户和服务器之间加了—个中间层(XHR),使用户操作与服务器响应异步化。并不是所有的用户请求都提交给服务器,像—些数据验证和数据处理等都交给XHR自己来做, 只有确定需要从服务器读取新数据时再由XHR代为向服务器提交请求,示意图如下:
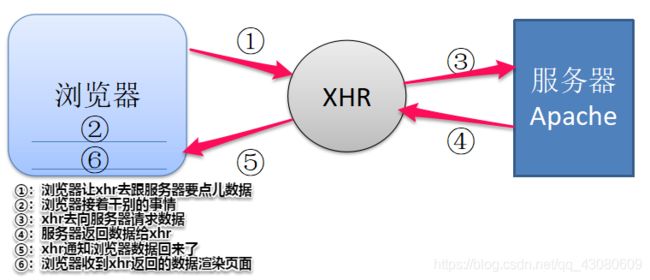 在本次爬虫中,利用Ajax技术获取服务器发往浏览器的原始报文。
在本次爬虫中,利用Ajax技术获取服务器发往浏览器的原始报文。
Request URL分析
F12进入开发者模式,进入Network界面,选择Fetch/XML,可以看到各个请求的相关信息。
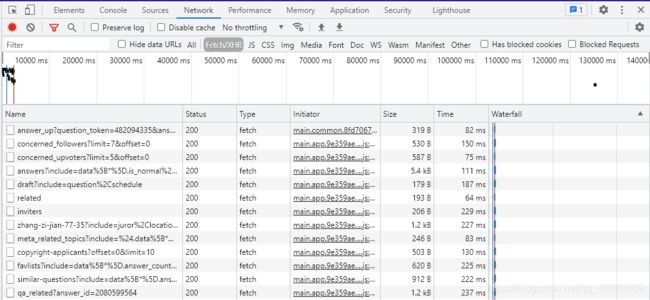 选择其中answers?开头的请求,观察Request URL。注意到有两个字段,offset 和 limit,其中 offset 指的是报文中第一个回答对应的索引号(从0开始),limit 指的是一条报文中能够包含的最多的回答数。用户可以在URL定义这两个值。
选择其中answers?开头的请求,观察Request URL。注意到有两个字段,offset 和 limit,其中 offset 指的是报文中第一个回答对应的索引号(从0开始),limit 指的是一条报文中能够包含的最多的回答数。用户可以在URL定义这两个值。
在设定时应当注意:
offset 不能超过回答总数 - 1;
limit 不能超过上限。
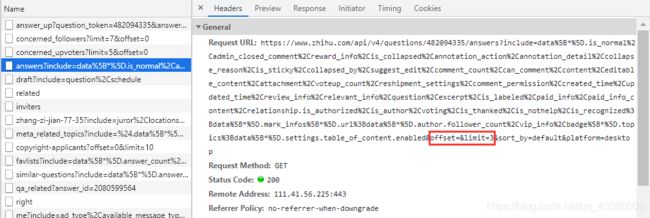 为了便于观察json数据报格式,将 limit 设定为1,复制以下URL即可查看json报文信息。
为了便于观察json数据报格式,将 limit 设定为1,复制以下URL即可查看json报文信息。
https://www.zhihu.com/api/v4/questions/482094335/answers?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cvip_info%2Cbadge%5B*%5D.topics%3Bdata%5B*%5D.settings.table_of_content.enabled&offset=0&limit=1&sort_by=default&platform=desktop
json报文结构分析
下面对json报文进行结构分析,报文主要分为两部分:“data” 和 “page”。
data:包含 html 文本数据,本次爬虫重点关注以下字段:
| 字段 | 含义 |
|---|---|
| author -> name | 用户名 |
| author -> url_token | 用户token |
| content | 回答 |
| updated_time | 回答时间 |
| voteup_count | 赞同数量 |
| comment_count | 评论数量 |
说明:
用户token是用户的唯一识别标志,“https://www.zhihu.com/people/” + url_token 为该用户知乎主页;
报文中的时间都是时间戳,需要转化为 “年-月-日 时-分-秒” 的形式。
page:记录是否已经是该问题下的最后一个回答。如果字段 is_end = true,则可以结束请求。
代码
引包:
import time
import csv
import codecs #解决乱码
import requests
from pyquery import PyQuery as pq
请求头和URL:
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
# Request URL
base_url = "https://www.zhihu.com/api/v4/questions/482094335/answers?"
include = "data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled"
获得页面:
# 获得页面
def get_page(offset):
page_url = 'include=' + include + '&limit=5&' + 'offset=' + str(offset) + '&platform=desktop&sort_by=default'
url = base_url + page_url
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)
时间转换:
# 时间戳转化为年-月-日 时-分-秒
def TimeStampToTime(timestamp):
timeStruct = time.localtime(timestamp)
return time.strftime('%Y-%m-%d %H:%M:%S', timeStruct)
解析页面:
# 解析网页
def parse_page(json):
if json:
items = json.get('data')
for item in items: # items: 一条报文中的所有回答
zhihu = {}
zhihu['作者'] = item.get('author').get('name')
zhihu['user_token'] = item.get('author').get('url_token')
zhihu['回答'] = pq(item.get('content')).text()
zhihu['创建时间'] = TimeStampToTime(item.get('updated_time'))
zhihu['赞同数'] = item.get('voteup_count')
zhihu['评论数'] = item.get('comment_count')
yield zhihu
主函数执行:
if __name__ == '__main__':
i = 0
f = codecs.open('test.csv', 'w+', 'utf_8_sig')
f_txt = open('test.txt', 'w+', encoding='utf_8')
fieldnames = ['作者', 'user_token', '回答', '创建时间', '赞同数', '评论数']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
while True:
js = get_page(i*5) # 根据报文首个回答对应的索引值获取页面
results = parse_page(js)
for res in results:
writer.writerow(res)
for detail in res.values():
f_txt.write(str(detail) + '\n')
f_txt.write('\n' + '*' * 50 + '\n') # 分隔符
if js.get('paging').get('is_end'):
print('finish!')
break
i += 1
f.close()
f_txt.close()
参考链接
2021年知乎爬虫
python爬虫——关于ajax加载之爬取2019年知乎问题和描述
Ajax原理