从源码层面认识和理解@Autowired注解
@Autowired是什么
对于Java后端开发的读者在项目中肯定是大量使用@Autowired注解,在controller层使用@Autowired注入service层接口,在service层使用@Autowired注入dao层接口实现MVC的分层,相信这是大家在项目中项目分层使用到的一个注解。那么各种读者有没有从源码来理解@Autowired这个注解的呢?为了大家在项目中带有理解的使用@Autowired注解,所以此帖特意从源码角度来解析@Autowired注解。
@Autowired各种使用案例
在追源码之前,我希望用几个关于@Autowired注解的小案例带大家来见识一下各种@Autowired注解使用的场景和一些极端的情况,方便大家追源码之前有一个复习和推理的过程。
/**
* @Author liha
* @Date 2022-03-31 19:55
* 李哈YYDS
*/
@Component
public class AutowirteTest {
@Autowired
public Liha liha;
}
@Component
class Liha{
}
// 启动类
@SpringBootApplication
public class Application {
public static void main(String[] args) {
ConfigurableApplicationContext run = SpringApplication.run(Application.class, args);
AutowirteTest autowirteTest = (AutowirteTest) run.getBean("autowirteTest");
Object liha = run.getBean("liha");
System.out.println(autowirteTest.liha==liha);
}
}这是大家最常见的使用场景,就是把@Autowired注解标在类中的全局变量中,这里的返回值肯定是true。
那么下面来一个变形,可能很多读者没见过这种的写法。就是把@Autowired注解写在方法上
@Component
public class AutowirteTest {
public Liha liha;
@Autowired
public void setLiha(Liha liha){
this.liha = liha;
}
}
@Component
class Liha{
}启动类的代码不变,笔者把@Autowired注解从全局变量上面迁移到方法上面了,并且方法对全局变量做了一个赋值的操作。那么启动类的输出结果是什么呢?

可以看到是true,也就是标有@Autowired注解的方法,将方法的参数从容器中获取到,并且执行了当前方法。
那么我们下面继续追变形,我们创建一个一个接口,然后创建2个接口的实现类,然后再注入接口。
/**
* @Author liha
* @Date 2022-04-01 18:32
* 李哈YYDS
*/
public interface Liha {
}
// 记住这里新创建一个类
@Component
public class Liha1 implements Liha{
}
// 记住这里新创建一个类
@Component
public class Liha2 implements Liha{
}
// 记住这里新创建一个类
// 这个类注入Liha接口
@Component
public class AutowirteTest {
@Autowired
public Liha liha;
}
// 启动类
@SpringBootApplication
public class Application {
public static void main(String[] args) {
ConfigurableApplicationContext run = SpringApplication.run(Application.class, args);
AutowirteTest autowirteTest = (AutowirteTest) run.getBean("autowirteTest");
System.out.println(autowirteTest.liha);
}
}这里的运行结果肯定是报错,这不需要纠结,在Spring底层中,当注入Liha接口的实现类时候发现有两个,Spring鬼知道你要哪一个对吧。
那我们如何解决呢?
方案一

我们将全局变量名字改成liha1,也就是对应Liha1这个Liha的实现类。
因为Spring的容器在启动时,发现@Component、@Service等注解时会将当前类给注册到IoC容器中,他们的默认bean名称是类名首字母小写后面不变,当然也可以根据注解参数修改bean名称。
这样就成功注入了,所以我们目前得出一个结论,就是使用@Autowired注解会根据变量的名称来进行自动注入。
方案二
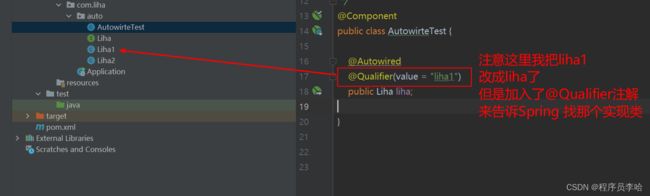
@Autowired注解和@Qualifier注解结合使用,把要注入的Liha实现类的bean名称告诉Spring,这样Spring就知道你要注入哪一个实现类了。
方案三
@Component
public class AutowirteTest {
@Autowired
public Liha liha;
}
// 注意这里我给起了一个别名
@Component(value = "liha")
public class Liha1 implements Liha{
}
这种就是给@Component等注解中的的value参数赋值,就是改变默认的bean名称。这样自动注入的全局实体类就会根据一个bean名称叫liha的去找。
方案四
@Component
public class AutowirteTest {
@Autowired
public Liha liha;
}
// 使用@Primary注解来解决
@Component
@Primary
public class Liha1 implements Liha{
}这里就是使用了@Primary注解来解决,这样Spring在自动注入一个接口有多个实现类的时候就会优先注入标有@Primary注解的实现类。
@Autowired源码追踪
源码之前的推理:
- 熟知Spring的IoC容器启动的同学可以知道(不知道也没关系),对于一个Bean的创建是大致分为:反射实例化bean->给bean中的属性赋值->一些接口的回调。所以我们就能推测标有@Autowired注解的属性或者方法肯定是在属性赋值的步骤中执行
- 熟悉Spring的同学,肯定现在可以推理出肯定是有一个类来解析处理@Autowired接口中一个自动注入,因为这是Spring的通常套路,就是定义一些接口,然后在IoC启动的时候回调这些接口来进行一些处理,这也是Spring的高扩展。
- 这里肯定是给属性赋值的时候发现标有@Autowired注解,然后对其进行getBean()方法递归来创建需要赋值的对象(循环依赖也是这样解决的),这是不用质疑的。
以上是笔者的推理,各位读者可以自行推理。个人觉得追之前一定要自己进行的一个推理,就算是错的也没关系。如果底子比较好的读者有Spring的启动过程的一个源码支持,我可以说基本所有关于Spring有关系的扩展点都能大概推理出来,然后自行Debug来证实自己的推理(个人觉得这样不管是培养一个推理的能力和兴趣还是对一个源码记忆都起了非常大的作用)
直接来到AbstractAutowireCapableBeanFactory类的createBean方法中的doCreateBean,这是创建和初始化bean的方法,下面是非常简洁的步骤讲解。
- createBeanInstance(beanName, mbd, args); // 反射实例化bean对象
- populateBean(beanName, mbd, instanceWrapper); // 对bean对象做内部的赋值操作
- initializeBean(beanName, exposedObject, mbd); // 一些接口回调操作(高扩展)
介绍完流程,我们是不是应该找到处理@Autowired注解的一个类呢?
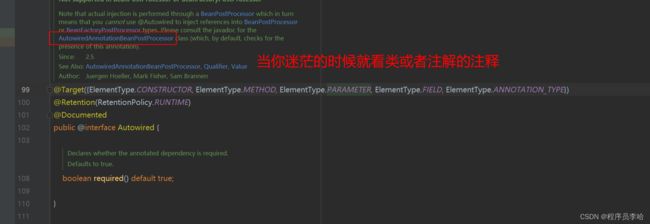
可以很清楚看到他要问我参考AutowiredAnnotationBeanPostProcessor类。
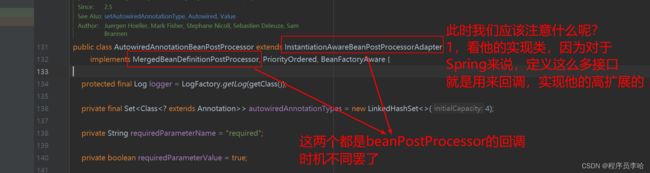
这两个接口也是我们追源码的核心了,所以追源码迷茫就从注释起手,然后看类的实现接口,再追寻到接口回调的地方,最后看接口的实现方法的逻辑。接口的实现方法及作用后面会介绍。
我们回到Spring中IoC容器中创建bean的过程中的doCreateBean方法,可以清楚的看到以下的一段代码。
// Allow post-processors to modify the merged bean definition.
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Post-processing of merged bean definition failed", ex);
}
mbd.postProcessed = true;
}
}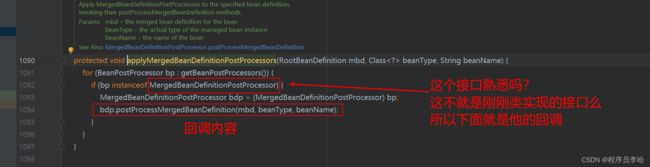
@Override
public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class beanType, String beanName) {
InjectionMetadata metadata = findAutowiringMetadata(beanName, beanType, null);
metadata.checkConfigMembers(beanDefinition);
}这里就是AutowiredAnnotationBeanPostProcessor类实现的接口的回调方法之一
这段代码的作用如下:
- 找到当前创建的bean中标有@Autowired注解和@Value的属性或者方法。
- 将属性或者方法封装成一个InjectedElement
- 放入缓存中,因为后面要使用
这里算是为了后面的操作做铺垫操作。
再继续看到前面介绍的populateBean()方法中,这个方法作用就是给属性赋值,是在上面的操作后面,因为先要判断获取到@Autowired或者@Value的属性内容,才能赋值呀!所以看到populateBean()方法中的一段逻辑
boolean hasInstAwareBpps = hasInstantiationAwareBeanPostProcessors();
boolean needsDepCheck = (mbd.getDependencyCheck() != AbstractBeanDefinition.DEPENDENCY_CHECK_NONE);
PropertyDescriptor[] filteredPds = null;
if (hasInstAwareBpps) {
if (pvs == null) {
pvs = mbd.getPropertyValues();
}
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
PropertyValues pvsToUse = ibp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
if (filteredPds == null) {
filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
}
pvsToUse = ibp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
return;
}
}
pvs = pvsToUse;
}
}
}看到InstantiationAwareBeanPostProcessor是不是又感觉很熟悉呀,没错,他就是AutowiredAnnotationBeanPostProcessor类实现的接口,所以这里又是一个接口回调操作。所以我们就可以看到postProcessProperties()方法在AutowiredAnnotationBeanPostProcessor类中的实现
@Override
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) {
InjectionMetadata metadata = findAutowiringMetadata(beanName, bean.getClass(), pvs);
try {
metadata.inject(bean, beanName, pvs);
}
catch (BeanCreationException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanCreationException(beanName, "Injection of autowired dependencies failed", ex);
}
return pvs;
}这个方法findAutowiringMetadata是不是又特别的熟悉呢?没错之前的一个接口回调中就使用到这个方法,这个方法也就是查询缓存,缓存中没有就创建然后放入到缓存中,因为之前的操作已经帮我们创建过了,并且放入到缓存中,所以我们这里直接从缓存中获取就行。

所以我们直接看到inject方法,inject英文翻译也是注入的意思,所以基本是可以推理出答案了。

可以看到这里实现有基于字段的基于方法,所以也就证明@Autowired可以写在属性上也可以写在方法上。
这里我们看到基于字段的实现把。
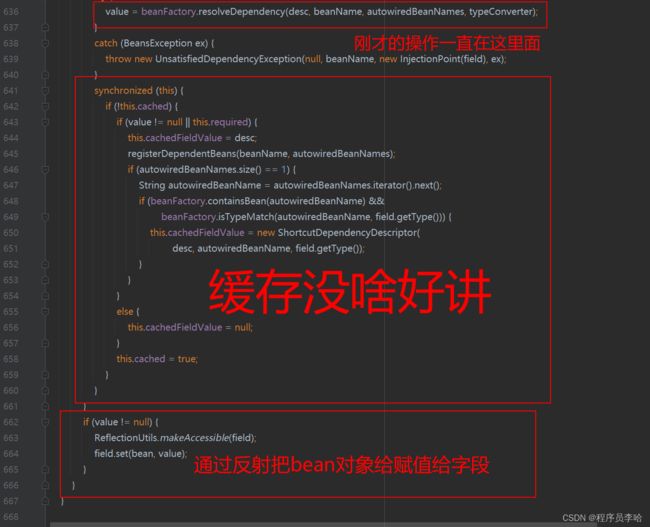
@Override
protected void inject(Object bean, @Nullable String beanName, @Nullable PropertyValues pvs) throws Throwable {
Field field = (Field) this.member;
Object value;
if (this.cached) {
value = resolvedCachedArgument(beanName, this.cachedFieldValue);
}
else {
DependencyDescriptor desc = new DependencyDescriptor(field, this.required);
desc.setContainingClass(bean.getClass());
Set autowiredBeanNames = new LinkedHashSet<>(1);
Assert.state(beanFactory != null, "No BeanFactory available");
TypeConverter typeConverter = beanFactory.getTypeConverter();
try {
value = beanFactory.resolveDependency(desc, beanName, autowiredBeanNames, typeConverter);
}
catch (BeansException ex) {
throw new UnsatisfiedDependencyException(null, beanName, new InjectionPoint(field), ex);
}
synchronized (this) {
if (!this.cached) {
if (value != null || this.required) {
this.cachedFieldValue = desc;
registerDependentBeans(beanName, autowiredBeanNames);
if (autowiredBeanNames.size() == 1) {
String autowiredBeanName = autowiredBeanNames.iterator().next();
if (beanFactory.containsBean(autowiredBeanName) &&
beanFactory.isTypeMatch(autowiredBeanName, field.getType())) {
this.cachedFieldValue = new ShortcutDependencyDescriptor(
desc, autowiredBeanName, field.getType());
}
}
}
else {
this.cachedFieldValue = null;
}
this.cached = true;
}
}
}
if (value != null) {
ReflectionUtils.makeAccessible(field);
field.set(bean, value);
}
}
} 核心就都在这里了,大概介绍一下吧:
- 将需要注入的属性转换成Filed,应为需要反射字段来赋值
- 查看是否开启缓存,没有开启就去解析这个字段(解析也就是看Spring中存在这个自动的类型有多少个,看看允不允许注入,允许就去getBean操作,不允许就抛出异常)
- 将getBean创建或者是IoC容器中获取到的bean对象做一个缓存
- 使用字段的反射进行赋值操作
所以我们就把所有的精力看到解析过程中。也就是resolveDependency()方法,然后再看到doResolveDependency()方法中。全部的核心就都在这里了。
大致介绍一下流程:
- 这里会去查找字段以属性(Type)在Spring中存在多少个实现
- 如果字段属性存在@Qualifier注解就会根据@Qualifier注解的值去查找有多少个实现
- 如果没有实现,切@Autowired的required值为true就会直接抛出异常,所以这里也说明了使用@Autowired注解如果没有实现只要required值为false也没事。
- 如果字段属性的实现类有多个就会根据字段名去找,如果没找到就会抛出异常
- 如果只有一个的情况就直接赋值,准备getBean去容器创建或者从缓存中获取
所以这里就是先根据Type找,但是@Qualifier可以控制直接从他的value找,就只返回一个,如果没有@Qualifier注解就根据Type找,此时可能是0个、1个、多个。0个的话如果@Autowired注解的required的值为true(默认为true)就直接抛出异常。如果是1个的话就直接赋值给变量,准备后面的getBean操作,从容器中创建或者从缓存中直接获取。如果是多个的话就根据Name来查找,就是跟字段名做映射,如果映射成功就赋值,准备后面的getBean操作,如果映射不成功就直接抛出异常。可以用下图来理解。

最后就会走到descriptor.resolveCandidate(autowiredBeanName, type, this);这个方法里面内容就是getBean()方法,熟悉Spring的读者就能知道这是创建bean实例或者是从容器的缓存中直接获取,要明白其实当前也是在getBean的方法中,所以这是一个递归的创建bean,对于Spring的循环依赖也差不多是这样。
后续也没啥讲的了,从IoC容器中创建或者是缓存中获取到属性对应的bean对象以后一路返回就回到了inject()方法,这里就会通过反射把bean对象复制给对应的字段。
总结
对于Spring源码基础比较薄弱的读者,我这里确实没怎么去体谅你们,因为要全部将清楚就会比较复杂,笔者认为讲一些核心的内容,关键还是靠自己去推理和证实,可能笔者的作用最多也就是帮助读者来解决一些没看懂的地方之类的。
并且笔者认为,一定要把Spring的启动流程给弄清楚,因为Spring全家桶系列的框架都离不开这里,懂启动流程以后,就能明白各种高扩展点了,并且其实Spring全家桶系统的框架也就是靠这些高扩展点来做的扩展。
最后,如果本帖对您有一定的帮助,希望能点赞+关注+收藏,您的支持是给我最大的动力,后续会一直更新各种框架的使用和框架的源码解读~!