BM25算法介绍
BM25算法介绍
BM25(BM=best matching)是TDIDF的优化版本,首先我们来看看TFIDF是怎么计算的
TFIDF
T F − I D F = T F ∗ I D F = 某 单 词 数 量 单 词 总 数 ∗ l o g ( 总 文 档 包 含 某 单 词 的 文 档 数 + 1 ) TF-IDF=TF*IDF=\frac{某单词数量}{单词总数}*log(\frac{总文档}{包含某单词的文档数+1}) TF−IDF=TF∗IDF=单词总数某单词数量∗log(包含某单词的文档数+1总文档)
其中tf称为词频,idf为逆文档频率。
BM25
B M 25 ( i ) = 词 i 的 数 量 总 词 数 ∗ ( k + 1 ) C C + k ( 1 − b + b ∣ d ∣ ∣ a v d l ∣ ) ∗ l o g ( 总 文 档 数 包 含 i 的 文 档 数 ) BM25(i)=\frac{词i的数量}{总词数}*\frac{(k+1)C}{C+k(1-b+b\frac{|d|}{|avdl|})}*log(\frac{总文档数}{包含i的文档数}) BM25(i)=总词数词i的数量∗C+k(1−b+b∣avdl∣∣d∣)(k+1)C∗log(包含i的文档数总文档数)
C = t f = 词 i 的 数 量 总 词 数 , k > 0 , b ∈ [ 0 , 1 ] C=tf=\frac{词i的数量}{总词数},k>0, b \in [0,1] C=tf=总词数词i的数量,k>0,b∈[0,1], d d d为文档 i i i的长度, a v d l avdl avdl是文档的平均长度
BM25和tfidf的计算结果很相似,唯一的区别在于中多了一项,这一项是用来对tf的结果进行的一种变换。
把 1 − b + b d a v d l 1-b+b\frac{d}{avdl} 1−b+bavdld中的 b b b看成0,那么此时项的结果为 ( k + 1 ) t f k + t f \frac{(k+1)tf}{k+tf} k+tf(k+1)tf,通过设置一个 k k k,就能够保证其最大值为1,达到限制 t f tf tf过大的目的。
即:
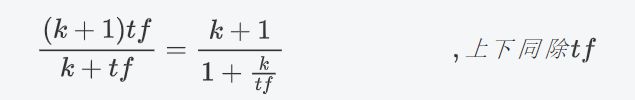
k k k不变的情况下,上式随着tf的增大而增大,上限为 k + 1 k+1 k+1,但是增加的程度会变小,如下图所示。
在一个句子中,某个词重要程度应该是随着词语的数量逐渐衰减的,所以中间项对词频进行了惩罚,随着次数的增加,影响程度的增加会越来越小。通过设置 k k k值,能够保证其最大值为 k + 1 k+1 k+1, k k k往往取值1.2。
其变化如下图(无论k为多少,中间项的变化程度会随着次数的增加,越来越小):

1 − b + b d a v d l 1-b+b\frac{d}{avdl} 1−b+bavdld的作用是用来对文本的长度进行归一化。
例如在考虑整个句子的tdidf的时候,如果句子的长度太短,那么计算的总的tdidf的值是要比长句子的tdidf的值要低的。所以可以考虑对句子的长度进行归一化处理。
可以看到,当句子的长度越短, 1 − b + b d a v d l 1-b+b\frac{d}{avdl} 1−b+bavdld的值是越小,作为分母的位置,会让整个第二项越大,从而达到提高短文本句子的BM25的值的效果。当b的值为0,可以禁用归一化, b b b往往取值0.75

BM25算法实现
from sklearn.feature_extraction.text import TfidfVectorizer,TfidfTransformer,_document_frequency
from sklearn.base import BaseEstimator,TransformerMixin
from sklearn.preprocessing import normalize
from sklearn.utils.validation import check_is_fitted
import numpy as np
import scipy.sparse as sp
class Bm25Vectorizer(CountVectorizer):
def __init__(self,k=1.2,b=0.75, norm="l2", use_idf=True, smooth_idf=True,sublinear_tf=False,*args,**kwargs):
super(Bm25Vectorizer,self).__init__(*args,**kwargs)
self._tfidf = Bm25Transformer(k=k,b=b,norm=norm, use_idf=use_idf,
smooth_idf=smooth_idf,
sublinear_tf=sublinear_tf)
@property
def k(self):
return self._tfidf.k
@k.setter
def k(self, value):
self._tfidf.k = value
@property
def b(self):
return self._tfidf.b
@b.setter
def b(self, value):
self._tfidf.b = value
def fit(self, raw_documents, y=None):
"""Learn vocabulary and idf from training set.
"""
X = super(Bm25Vectorizer, self).fit_transform(raw_documents)
self._tfidf.fit(X)
return self
def fit_transform(self, raw_documents, y=None):
"""Learn vocabulary and idf, return term-document matrix.
"""
X = super(Bm25Vectorizer, self).fit_transform(raw_documents)
self._tfidf.fit(X)
return self._tfidf.transform(X, copy=False)
def transform(self, raw_documents, copy=True):
"""Transform documents to document-term matrix.
"""
check_is_fitted(self, '_tfidf', 'The tfidf vector is not fitted')
X = super(Bm25Vectorizer, self).transform(raw_documents)
return self._tfidf.transform(X, copy=False)
class Bm25Transformer(BaseEstimator, TransformerMixin):
def __init__(self,k=1.2,b=0.75, norm='l2', use_idf=True, smooth_idf=True,
sublinear_tf=False):
self.k = k
self.b = b
##################以下是TFIDFtransform代码##########################
self.norm = norm
self.use_idf = use_idf
self.smooth_idf = smooth_idf
self.sublinear_tf = sublinear_tf
def fit(self, X, y=None):
"""Learn the idf vector (global term weights)
Parameters
----------
X : sparse matrix, [n_samples, n_features]
a matrix of term/token counts
"""
_X = X.toarray()
self.avdl = _X.sum()/_X.shape[0] #句子的平均长度
# print("原来的fit的数据:\n",X)
#计算每个词语的tf的值
self.tf = _X.sum(0)/_X.sum() #[M] #M表示总词语的数量
self.tf = self.tf.reshape([1,self.tf.shape[0]]) #[1,M]
# print("tf\n",self.tf)
##################以下是TFIDFtransform代码##########################
if not sp.issparse(X):
X = sp.csc_matrix(X)
if self.use_idf:
n_samples, n_features = X.shape
df = _document_frequency(X)
# perform idf smoothing if required
df += int(self.smooth_idf)
n_samples += int(self.smooth_idf)
# log+1 instead of log makes sure terms with zero idf don't get
# suppressed entirely.
idf = np.log(float(n_samples) / df) + 1.0
self._idf_diag = sp.spdiags(idf, diags=0, m=n_features,
n=n_features, format='csr')
return self
def transform(self, X, copy=True):
"""Transform a count matrix to a tf or tf-idf representation
Parameters
----------
X : sparse matrix, [n_samples, n_features]
a matrix of term/token counts
copy : boolean, default True
Whether to copy X and operate on the copy or perform in-place
operations.
Returns
-------
vectors : sparse matrix, [n_samples, n_features]
"""
########### 计算中间项 ###############
cur_tf = np.multiply(self.tf, X.toarray()) #[N,M] #N表示数据的条数,M表示总词语的数量
norm_lenght = 1 - self.b + self.b*(X.toarray().sum(-1)/self.avdl) #[N] #N表示数据的条数
norm_lenght = norm_lenght.reshape([norm_lenght.shape[0],1]) #[N,1]
middle_part = (self.k+1)*cur_tf /(cur_tf +self.k*norm_lenght)
############# 结算结束 ################
if hasattr(X, 'dtype') and np.issubdtype(X.dtype, np.floating):
# preserve float family dtype
X = sp.csr_matrix(X, copy=copy)
else:
# convert counts or binary occurrences to floats
X = sp.csr_matrix(X, dtype=np.float64, copy=copy)
n_samples, n_features = X.shape
if self.sublinear_tf:
np.log(X.data, X.data)
X.data += 1
if self.use_idf:
check_is_fitted(self, '_idf_diag', 'idf vector is not fitted')
expected_n_features = self._idf_diag.shape[0]
if n_features != expected_n_features:
raise ValueError("Input has n_features=%d while the model"
" has been trained with n_features=%d" % (
n_features, expected_n_features))
# *= doesn't work
X = X * self._idf_diag
############# 中间项和结果相乘 ############
X = X.toarray()*middle_part
if not sp.issparse(X):
X = sp.csr_matrix(X, dtype=np.float64)
############# #########
if self.norm:
X = normalize(X, norm=self.norm, copy=False)
return X
@property
def idf_(self):
##################以下是TFIDFtransform代码##########################
# if _idf_diag is not set, this will raise an attribute error,
# which means hasattr(self, "idf_") is False
return np.ravel(self._idf_diag.sum(axis=0))
测试
from BM25Vectorizer import Bm25Vectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
if __name__ == '__main__':
# format_weibo(word=False)
# format_xiaohuangji_corpus(word=True)
bm_vec = Bm25Vectorizer()
tf_vec = TfidfVectorizer()
# 1. 原始数据
data = [
'hello world',
'oh hello there',
'Play it',
'Play it again Sam,24343,123',
]
# 2. 原始数据向量化
bm_vec.fit(data)
tf_vec.fit(data)
features_vec_bm = bm_vec.transform(data)
features_vec_tf = tf_vec.transform(data)
print("Bm25 result:",features_vec_bm.toarray())
print("*"*100)
print("Tfidf result:",features_vec_tf.toarray())