《论文阅读笔记》——Deep Reinforcement Learning for Intelligent Transportation Systems: A Survey
来源:arXiv:2005.00935v1 [cs.LG] 2 May 2020
作者:Ammar Haydari, Student Member, IEEE, Yasin Yilmaz, Member, IEEE
单位:the University of South Florida
年份:2020
链接:论文下载链接
关键词
deep reinforcement learning (RL)
traffic signal control (TSC)
intelligent transportation systems(ITS)
RL + 深度学习 = (deep RL)
Markov Decision Process(MDP)
摘要
本文详细讨论了基于深度强化学习(RL)的交通控制的最新应用,本文讨论了交通信号控制系统(TSC)的不同问题公式、RL参数和仿真环境,在文献中,也讨论了几个基于深度强化模型的自动驾驶汽车的研究案例。本文将现有的工作按照应用类型、控制模型和学习算法进行分类。最后,我们讨论了基于深度RL的交通应用所面临的挑战和有待解决的问题。
Index Terms—Deep reinforcement learning, Intelligent transportation systems, Traffic signal control, Autonomous driving,Multi-agent systems.
介绍
智能交通系统(ITS)的主要目标是提供安全、有效、可靠的运输系统。为此,交通信号优化控制(TSC)、自动车辆控制、交通流控制是研究的重点。
采用自适应模块控制交通灯是近年来ITS领域的一个研究热点。通过交通信号设计自适应交通管理系统是缓解交通拥堵的有效方法。对于研究人员来说,优化交通灯的最佳方法仍是一个悬而未决的问题,但优化TSC的一个有希望的方法是使用基于学习的人工智能技术。
有三种主要的机器学习方法。监督学习根据训练中提供的输出标签进行决策。无监督学习是基于模式发现而进行的,不需要预先知道输出标签。第三种机器学习方法是强化学习(RL),它采用基于Markov Decision Process(MDP)的顺序行为,并带有奖励或惩罚标准。RL与深度学习(deep RL)相结合,被称为deep RL,是目前控制系统中最先进的学习框架。RL可以解决复杂的控制问题,而深度学习有助于从复杂的数据集得到高度逼近的非线性函数。
在这篇文章中,我们回顾了针对TSC问题提出的deep RL应用。该文献讨论了不同的RL方法。由于交叉口模型主要是连通的、分布式的,因此本研究涉及的multi-agent dynamic control techniques在基于RL的ITS应用中发挥着关键作用。
贡献
- 第一次全面地调查了RL和基于deep RL的ITS应用。
- 从广义的概念出发,阐述了RL和deep RL模型的理论背景,特别是在ITS文献中使用的模型。
- 对TSC中使用RL和deep RL的现有工作进行了讨论,并在表中进行了明确的总结,以便进行适当的比较。
- 同样,deep RL在其他ITS领域(如自动驾驶)的不同应用也被总结为表格以供比较。
论文结构

相关工作
最早总结涉及到RL及其他方法的TSC AI模型可追溯到2007年,当时,模糊逻辑、人工神经网络和RL是研究人员应用于TSC的三种流行的人工智能方法。由于ITS的连通性,multi-agent模型与single-agent模型相比,提供了更完整、更可行的解决方案。因此,将TSC问题构建为multi-agentxitong具有很大的研究潜力。
基于multi-agent RL的TSC的机遇和研究方向在文献[1]中有所描述。文献[2]从实验的角度讨论了文献中常用的RL方法。[3]比较全面地介绍了基于强化学习(RL)的交通信号控制(TSC)算法。[4]从更广阔的视角研究ITS中的AI方法。
Abduljabbar等人总结了[5]中基于人工智能的交通应用的文献,主要有三个主题:交通管理应用、公共交通和自动驾驶车辆。在[6]中,作者讨论了一般的TSC方法,包括经典的控制方法,驱动控制,绿波,最大频带(max-band)系统,和基于RL的控制方法。Veres等人在[7]中强调了深度学习应用的趋势和挑战。深度学习模型在深度RL中起着重要的作用。非线性神经网络在数据驱动的应用中克服了传统的挑战,如可扩展性。最近,在[8]中提出了一项关于自动驾驶车辆的深层RL应用的调查,其中作者讨论了在现实世界中部署这种基于RL的自动驾驶方法所面临的挑战。除了自动驾驶,在这个调查中,我们讨论了它的一个广泛的应用领域,其中深倒车越来越受欢迎,并对深倒车概念进行了全面的概述。
深度 RL
Deep RL是最成功的人工智能模型之一,也是最接近人类学习的机器学习。它结合了深度神经网络和RL,用于更有效和稳定的函数逼近,特别是高维和无限状态问题。本节介绍了传统RL的理论背景和主要的深度RL算法在其应用中的实现。
Reinforcement Learning
RL常用于agent与环境相互作用时,agent在没有任何先验知识的情况下学习如何在环境中做出行动。在采取行动后,RL agent根据其行为得到一个反馈,通过这种反馈机制,agent不断更新自己的行动策略,直到得到最优控制策略。RL从环境中学习经验,呈现了一种尝试与试错式的学习,类似于人类。
RL过程原理图如下所示
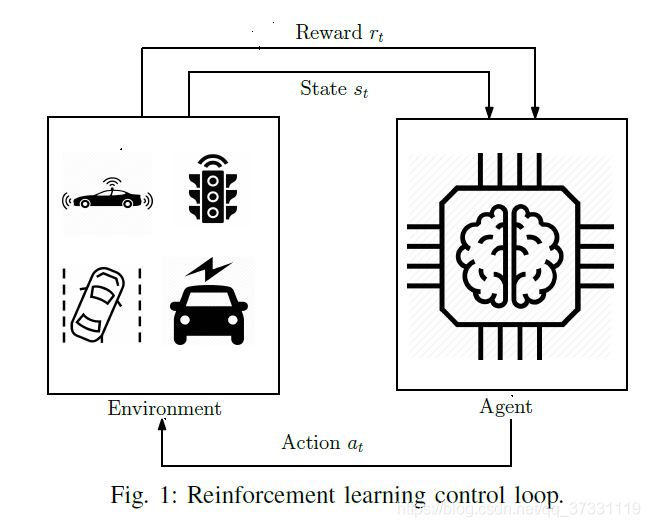
在大多数的RL模型中,agent由算法控制,当agent在状态 s t s_t st采取行动 a t a_t at后,从环境中获得奖励 r t r_t rt,在基于当前的策略 π \pi π采取行动后,系统的状态转移到 s t + 1 s_{t+1} st+1。每次交互之后,RL代理都会更新环境知识。
马可夫决策过程(Markov Decision Process,MDP)
强化学习的任务通常用MDP来描述。MDP对应了五元组:
- 状态空间 S \mathcal{S} S
- 动作空间 A \mathcal{A} A
- 转移函数 T ( s t + 1 ∣ s t , a t ) \mathcal{T}(s_{t+1}|s_t,a_t) T(st+1∣st,at)
- 奖励函数 R ( s t , a t , s t + 1 ) \mathcal{R}(s_t,a_t,s_{t+1}) R(st,at,st+1)
- 折扣因子 γ \gamma γ,值在0到1之间
MDP的目标是找到最好的策略 π ∗ \pi^* π∗,使得在每个状态 s s s的预期累计奖赏和 γ \gamma γ折扣累积奖赏最大。
- 预期累积奖赏
E [ R t ∣ s , π ] \mathbb{E}[\mathcal{R}_t|s,\pi] E[Rt∣s,π] - γ \gamma γ折扣累积奖赏
R t = ∑ i = 0 T − 1 γ i r t + 1 \mathcal{R}_t=\sum^{T-1}_{i=0}\gamma^ir_{t+1} Rt=i=0∑T−1γirt+1
折扣参数 γ \gamma γ反映了未来奖励重要性。在0和1之间选择较大的值,表示agent的行为对未来奖赏的依赖程度较高。然而,取较小的值表示更多的关注即时奖赏。
RL agent可以按照两种方式采取行动(i)model-based RL (ii)model-free L.model-free RL 又可以被分为value-based和policy-based两种。
有模型学习(Value-based RL)
E = < S , A , T , R > E=<\mathcal{S},\mathcal{A},\mathcal{T},\mathcal{R}> E=<S,A,T,R>均为已知,即机器已经对环境进行了建模,能在机器内部模拟出与环境相似或相同的状况。在已知环境的模型中学习叫“有模型学习”(model-based learning).
函数 V π ( s ) V^{\pi}(s) Vπ(s)表示从状态 s s s出发,使用策略 π \pi π所带来的累积奖赏。
函数 Q π ( s , a ) Q^{\pi}(s,a) Qπ(s,a)表示从状态 s s s出发,执行动作 a a a后再使用策略 π \pi π所带来的累积奖赏。
V ( ⋅ ) V(\cdot) V(⋅)称为“状态值函数”(state value function), Q ( ⋅ ) Q(\cdot) Q(⋅)称为“状态-动作值函数”(state value function),分别表示指定“状态”上以及指定“状态-动作”上的累积奖励。
V π ( s ) = E [ R t ∣ s , π ] V ^{\pi}(s) = \mathbb{E}[R_t|s,\pi ] Vπ(s)=E[Rt∣s,π]
Q π ( s , a ) = E [ R t ∣ s , a , π ] Q^{\pi}(s,a) = \mathbb{E}[R_t|s,a,\pi ] Qπ(s,a)=E[Rt∣s,a,π]
最优价值函数最优状态值函数
V ∗ ( s ) = max π V π ( s ) , ∀ s ∈ S V ^*(s) = \max_{\pi}V ^{\pi}(s),\forall s \in \mathcal{S} V∗(s)=πmaxVπ(s),∀s∈S
看不动了,这部分内容再更
基于以上,主要有两种有模型学习:
- Q-learning
- SARSA
Policy-based RL
Multi-Agent RL
在两种算法中,将状态-动作对保存在 Q Q Q-table
Deep Reinforcement Learning
在高维和复杂系统中,标准的RL方法无法学习环境的信息特征,以实现有效的函数逼近。然而,这个问题基于深度学习可以处理这个问题,其中的深度神经网络被训练学习最优策略或值函数。,深度学习在很多领域都有应用,包括计算机视觉、语音识别、自然语言处理和深度RL应用.
在本节中,我们讨论了深度RL的背景,包括基于策略和基于价值的RL模型。在讨论ITS中deep RL应用的细节之前,值得一提的是,根据应用领域的规范,在不同的应用中,某些deep RL算法是首选的。开发新的深度RL技术是一个活跃的研究领域,基于Q-learning的DQN和基于actor-批评家的DDPG算法继续主导基于RL的控制器。对于高维状态空间,deep RL方法优于标准RL方法。在动作空间方面,基于策略的deep RL方法比基于价值的deep RL方法更适合连续动作空间。对于离散的动作空间,它的控制器通常使用DQN及其变体,因为它们的结构比基于策略的方法更简单。一般来说,我们可以说基于Q-learning的DQN模型通常用于具有有限状态和动作空间的不太复杂的系统,而基于策略或行为评论家算法主要用于大型复杂系统,包括多智能体控制系统。在这里我们还应该注意到,在许多情况下,设计师在设置问题时可以在离散和连续状态和动作空间之间进行选择。例如,在下一节中讨论的TSC中,一些作者将连续动作定义为绿灯延长的时间,而另一些作者将离散动作空间定义为选择绿灯方向。
TSC问题中的deep RL配置
Deep DL 在智能交通系统中的一个主要应用领域之一为交叉口信号控制。首先,控制单元收集状态信息,可以是不同格式的状态信息,如队列长度、车辆位置、车辆速度等,然后控制单元根据所提出的deep RL策略采取行动。最后,agent(控制单元)根据所采取的行动获得奖励。通过遵循这些步骤,agent试图找到一个最优策略,以使交叉路口的拥塞最小化。
使用RL算法处理模拟器上的TSC问题,需要在状态、动作、奖励定义和神经网络结构等几个方面有良好的问题规划。在本节中,我们将讨论这些主要的deep RL配置以及文献中使用的交通模拟器。
S t a t e State State
学习表现高度依赖于状态定义的精准度,因此有许多不同的状态表示用于交通信号灯的RL应用.可分为以下几类:
- 类图像表示格式,称为离散交通状态编码(discrete traffic state encoding,DTSE),是目前最流行的状态定义方法.车辆的速度、位置、信号相位和加速度在 DTSE 中以单独的阵列显示。
- 另一个常用的方法是构建基于特征的值向量(feature-based value vector),在值向量状态表示与基于车的状态表示不同的是,每个车道特定信息的平均值和总和表示在一个向量中。队列长度、相位周期中的累积等待时间、车道上的平均速度、相位持续时间(绿色、红色、黄色)和每条车道上的车辆数是用于状态表示的一些常见特征。
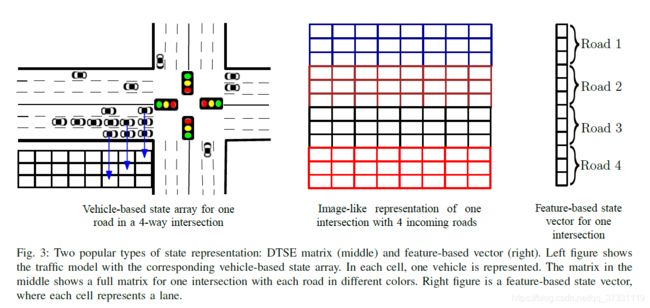
如图所示,两种主要的状态表示:DTSE 矩阵(中)和基于特征的向量(右)。左图显示的用对应的基于汽车的状态数组的交通模型。每一个格子表示一辆车。中图中的矩阵显示的是一个交叉口的完整矩阵,每条路用不同颜色表示。右图表示基于特征的状态向量,每一个格子表示一个车道。
对于多交叉口的TSC模型,状态定义也应该包含相邻交通灯的信息,比如信号相位,交通车数量和平均速度.
A c t i o n Action Action
RL 算法在接收到状态后从一组可能的行动中采取某个行动对学习有着至关重要的影响。在单个四路交叉口,每一个方向都由红灯、绿灯和黄灯控制。有很多单交叉口的行动选择,最常用的选择其中一个可能的绿灯相位。另一个二元行动可以设置为保持当前相位还是改变其方向。第三个不太常用的行动模型是根据预先定义的长度来更新相位时长。
对于单交叉口,主要有四种可能的绿灯相位:North-South Green (NSG),East-West Green (EWG),North-South Advance Left Green (NSLG) 和 East-West Advance Left Green (EWLG)。在某个相位的绿灯相位期间,汽车向交叉口允许的方向前进。如果行动设置为选择其中一个可能会的绿灯相位, deep RL 智能体在每个时间 t 选择四个绿灯相位中的一个。在黄灯和红灯转移后,选择的行动在交通灯上执行。
早期的应用将相位定义简化为 NSG 和 EWG 两种,而不考虑左转[32,40]。在另一种二元行动模型中,绿灯相位时长是预先定义的,例如NSG→EWG→NSLG→EWLG,智能体决定是保持在当前相位还是转移到下一相位。如果智能体决定改变相位,则黄灯和红灯转换需要先执行完,以确保交通流的安全[33,37,38,42,47]。
大部分应用考虑的是离散的行动,即从一组行动集合中选择某个行动。当然,也有少量工作考虑连续的输出,仅仅控制下一个相位的时长[20]。这种类型的行动定义适合多交叉口的情形。基于预先定义的最小和最大相位时长,算法为当前的相位预测一个合适的时间长度[41,48]。
原创地址
R e w a r d Reward Reward
在强化学习中,状态可以是一个特征向量或高维矩阵,行动可以是连续值或者离散选择的向量。然而,奖励总是标量值,且为交通数据的函数。在强化学习中奖励的作用是分析某个状态下采取某个行动的质量,也即对智能体采取特定行动的惩罚或奖赏。
等待时间、累积延迟和队列长度是 TSC 中最常见的奖励定义。等待时间可以所有汽车停留时间的总和来表示。延迟是指连续绿灯相位中等待时间的差。队列长度针对交叉口中每个车道进行计算。
美国公共道路局(BPR)在交通规划中定义的一个特殊拥堵函数也被一些工作用来作为奖励的定义[34,47]。在另一些工作中,交通数据的绝对值被用来定义奖励,其他工作也使用交通数据的负值和平均值来定义奖励。
原创地址
N e u r a l N e t w o r k S t r u c t u r e Neural Network Structure NeuralNetworkStructure
在 deep RL 中,深层神经网络的结构也对学习有着重要的影响。在 TSC 领域,研究者提出了很多不同的网络结构。多层感知机(MDP),即标准的全连接前馈神经网络模型,在传统数据分类中是一个有用的工具。卷积神经网络(CNN)是 MDP 使用核滤波器的一个扩展,在将图像映射为输出方面取得了很好的效果。
标准的 DQN 使用 CNN 网络结构,将连续的原始像素帧作为状态定义。有很多 TSC 领域的论文在 DTSE 状态定义下使用 CNN 作为网络结构(见图3,[31,33,49])。
残差网络(ResNet)通常用来解决基于 CNN 的深层网络结构的过度拟合问题[34]。另外一种在图中进行操作的基于卷积的网络结构是图卷积网络(GCN)。
循环神经网络(RNN),例如长短期记忆(LSTM)常常用户时间序列数据。由于 TSC 控制通常是时序进行,RNN 也被用于深度强化学习场景中[35,37]。另外一种神经网络模型是自编码器,可以为高维数据数据学习低维子空间表示,通常被用于清洗输入数据中的噪音[40]。
原创地址
模拟环境
早期:Green Light District (GLD) 模拟器,基于Java
最流行:SUMO,支持python
最成熟:VISSIM,与AIMSUN 类似,与 MATLAB 的交互更好
Deep RL在交通信号灯控制中的应用
根据agent的数量,我们可以将基于学习的模型分为两类:single agent RL和multi-agent RL,前者使用一个agent获得整个TSC网络的最优策略,后者使用网络中的多个agent获取最优策略。
标准RL应用
Single agent RL
Multi-agent RL
Deep RL应用
Single agent deep RL
三种不同的状态定义:
- 每条车道的占用率和平均速度
- 每条车道的排队长度和车辆密度
- 第三种状态形式是具有布尔位置信息的类像表示,DTSE,其中车辆的存在以1表示。
Multi-agent deep RL
参考文献
[1] A. L. Bazzan, “Opportunities for multiagent systems and multiagent reinforcement learning in traffic control,” Autonomous Agents and Multi-Agent Systems, vol. 18, no. 3, p. 342, 2009.
[2] P. Mannion, J. Duggan, and E. Howley, “An experimental review of reinforcement learning algorithms for adaptive traffic signal control,” in Autonomic Road Transport Support Systems. Springer, 2016, pp. 47–66.
[3] K.-L. A. Yau, J. Qadir, H. L. Khoo, M. H. Ling, and P. Komisarczuk, “A survey on reinforcement learning models and algorithms for traffic signal control,” ACM Computing Surveys (CSUR), vol. 50, no. 3, p. 34, 2017.
[4] W. Tong, A. Hussain, W. X. Bo, and S. Maharjan, “Artificial intelligence for vehicle-to-everything: A survey,” IEEE Access, vol. 7, pp. 10 823–10 843, 2019.
[5] R. Abduljabbar, H. Dia, S. Liyanage, and S. Bagloee, “Applications of artificial intelligence in transport: An overview,” Sustainability, vol. 11, no. 1, p. 189, 2019.
[6] H. Wei, G. Zheng, V. Gayah, and Z. Li, “A survey on traffic signal control methods,” arXiv preprint arXiv:1904.08117, 2019.
[7] M. Veres and M. Moussa, “Deep learning for intelligent transportation systems: A survey of emerging trends,” IEEE Transactions on Intelligent Transportation Systems, 2019.
[8] B. R. Kiran, I. Sobh, V. Talpaert, P. Mannion, A. A. A. Sallab, S. Yogamani, and P. P´erez, “Deep reinforcement learning for autonomous driving: A survey,” arXiv preprint arXiv:2002.00444, 2020.