Python可视化库Matplotlib的使用(折线图、柱状图、散点图)
声明:代码是根据课件整理的,初学python,只是当做自己记个笔记。
一、导入数据
首先要导入数据,使用pandas库里的read_csv方法,将 .csv后缀的文件中的数据进行导入,导入后的数据结构是DataFrame。(DataFrame是pandas库中的一种数据结构,它类似excel,是一种二维表)
import pandas as pd
unrate = pd.read_csv("unrate.csv")
# 如果导入的.csv文件不在当前代码所在的文件下,则需要编辑路径。注意:路径内不能有中文
#导入的格式如:
# unrate = pd.read_csv(r"E:\Python\data\UNRATE.csv")
unrate['DATE'] = pd.to_datetime(unrate['DATE'])
# 把unrate.csv的日期格式为1948/1/1,改为1948-01-01
print(unrate.head(12))
# DateFrame中的方法head:只看前12行
输出的结果如下:
DATE VALUE
0 1948-01-01 3.4
1 1948-02-01 3.8
2 1948-03-01 4.0
3 1948-04-01 3.9
4 1948-05-01 3.5
5 1948-06-01 3.6
6 1948-07-01 3.6
7 1948-08-01 3.9
8 1948-09-01 3.8
9 1948-10-01 3.7
10 1948-11-01 3.8
11 1948-12-01 4.0
关于日期相关的转换,即to_datetime方法的详细编写查看这里,大标题3
二、子图
其实就是先划定一个区域
fig = plt.figure(figsize=(3,3))
#采用figure方法来划区域
#figsize(3,3)指,每行3个图,一共3行
然后分别定义每个图在哪个位置
ax1 = fig.add_subplot(3,3,1)
ax2 = fig.add_subplot(3,3,4)
# 1和4代表图所在的位置,按Z字型的顺序数就可以了

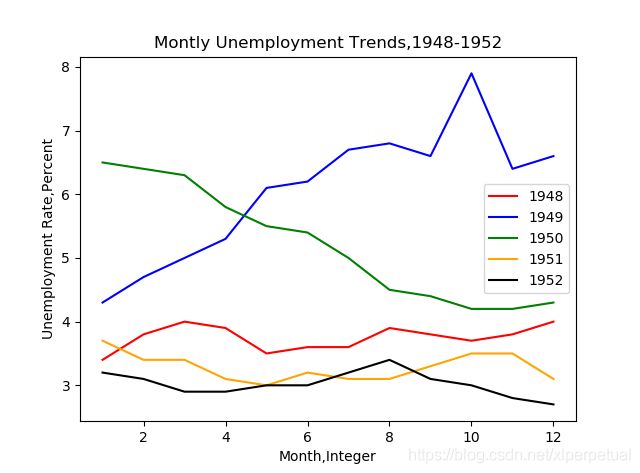
三、折线图
直接上多折线的图,单线图也就呼之欲出了
我想分别对1948-1952年间的1~12个月的失业率绘制曲线。
import pandas as pd
import matplotlib.pyplot as plt
unrate = pd.read_csv('unrate.csv')
unrate['DATE'] = pd.to_datetime(unrate['DATE'])
unrate['MONTH'] = unrate['DATE'].dt.month
#这一步要重点说明
#将之前DATA里的MONTH作为x轴,从而比较不同年份在这12个月之间的折线图
colors = ['red','green','blue','orange','black']
for i in range(5)
start_index = i*12
end_index = (i+1)*12
subset = unrate[start_index,end_index]
label = str(1948 + i)
# label是图示中,各个颜色线代表哪一年份的标注
plt.plot(subset['MONTH'],subset['VALUE'],c = colors[i],label = lable)
#第一个subset指横坐标,第二个代表纵坐标
plt.legend(loc='best')
#图示的位置,best指系统自动找一个好位置
#也有upper right(放在右上角)等方法
plt.xlabel('MONTH,Integer')
plt.ylabel('Unemployment Rate,Percent')
# 横纵坐标分别代表什么
plt.title('Montly Unemployment Trends,1948-1952')
plt.show()
结果如下
四、柱形图
比如对于某电影评分的汇总
查看各个不同的公司对一部电影的打分情况
import pandas as pd
import matplotlib.pyplot as plt
from numpy import arange
reviews = pd.read_csv('fandango_scores.csv')
num_cols = ['RT_user_norm','Metacritic_user_nom','IMDB_norm','Fandango_Ratingvalue','Fandango_Stars']
# 打分的公司的名称组成的数组
norms_reviews = reviews[num_cols]
#提取每个公司对于电影的分数
bar_heights = norm.reviews.ix[0,num_cols].values
#柱形的高度与他的values直接相关,用这个函数来写
bar_position = arange(5) + 1
# 1是第一个柱形的位置,5是x轴分配给柱形的总长度,间距是平分的
tick_position = range(1,6)
fig,ax = plt.subplots()
ax.bar(bar_position,bar_heights,0.3)
#这里要放入的是一个数
#这里的0.3是柱形的宽度
ax.set_xticks(tick_position)
# 这里,要放入的是一个list
ax.set_xticklabels(num_cols,rotation=45)
# 旋转45°方便观看
ax.set_xlabel('Rating Source')
ax.set_ylabel('Average Rating')
ax.set_title('Average User Rating for Avengers:Age of Ultron 2015')
ax.show()
arange和range的唯一区别:
arange返回的是一个数据,而range返回的是list
具体介绍,点击这里
代码运行结果如下

五、散点图
在编辑散点图的时候,我们把前面的子图复习一下
还是上面电影评分的例子
import pandas as pd
import matplotlib.pyplot as plt
reviews = pd.read_csv("fandango_scores.csv")
num_cols = ['RT_user_norm','Metacritic_user_nom','IMDB_norm','Fandango_Ratingvalue','Fandango_Stars']
norm_reviews = reviews[num_cols]
# 两个list 一个是打分平台的名字,一个是分别对应的打分
fig = plt.figure(figsize=(2,1))
ax1 = fig.add_subplot(2,1,1)
ax2 = fig.add_subplot(2,1,2)
ax1.scatter(norm_reviews['Fandango_Ratingvalue'], norm_reviews['RT_user_norm'])
ax1.set_xlabel('Fandango')
ax1.set_ylabel('Rotten Tomatoes')
ax2.scatter(norm_reviews['RT_user_norm'], norm_reviews['Fandango_Ratingvalue'])
ax2.set_xlabel('Rotten Tomatoes')
ax2.set_ylabel('Fandango')
plt.show()
#两个图的x和y进行了交换,可以看出来他正好是关于x=y对称的
代码结果如下

以上是我自己对照课件总结的,但是还是不够完整,我只提取了我觉得有用的地方整理,其实还有直方图、四分图等,如果用到了,可以参考其他人整理的,更加丰富一点。
点击这里