C++常见崩溃问题分析
一、前言
从事自动化测试平台开发的编程实践中,遭遇了几个程序崩溃问题,解决它们颇费了不少心思,解决过程中的曲折和彻夜的辗转反侧却历历在目,一直寻思写点东西,为这段难忘的经历留点纪念,总结惨痛的教训带来的经验,以期通过自己的经历为他人和自己带来福祉:写出更高质量的程序;
由于 C 和 C++ 这两种语言血缘非常近,文本亦对 C 编程语言有借鉴作用;
二、C++ 崩溃分类
在编程实践中,遭遇到了诸如内存无效访问、无效对象、内存泄漏、堆栈溢出等很多C / C++ 程序员常见的问题,最后都是同一个结果:程序崩溃,为解决崩溃问题,过程都是非常让人难以忘怀的;
可谓吃一堑长一智,出现过几次这样的折腾后就寻思找出它们的原理和规律,把这些典型的编程错误一网打尽,经过系统性的分析和梳理,发现其内在机理大同小异,通过对错误表现和原理进行分类分析,把各种导致崩溃的错误进行归类,详细分类如下:
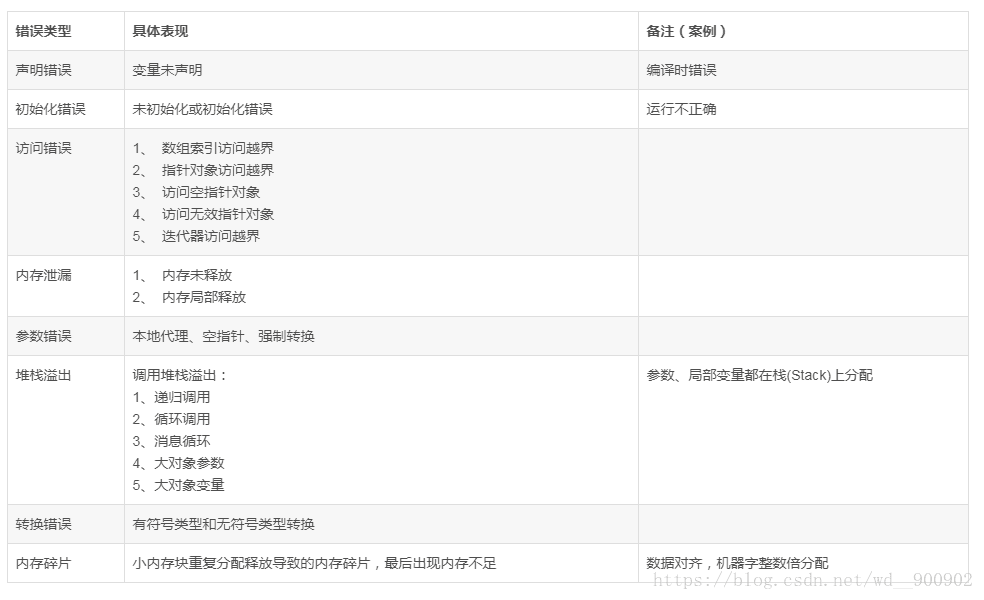
其它如内存分配失败、创建对象失败等都是容易理解和相对少见的错误,因为目前的系统大部分情况下内存够用;此外除0错误也是容易理解和防范;
三、C++ 编程回顾
为了更好的理解崩溃错误产生的根源,我们一起回顾一下几个概念和知识点,为后面的讨论打下基础;
由于本篇只谈程序设计,不谈软件设计,故忽略了文档开发、过程管理、软件测试、配置管理等内容,各位看官在审阅文档中的著述时若有分歧请勿忽略这个隐喻;
3.1、程序构造视图
Pascal 之父、结构化程序设计的先驱 Niklaus Wirth提出了著名的公式:算法 + 数据结构 = 程序,以简单直接的方式道出了他对软件开发的理解,简明扼要的说明了程序设计的本质;为了更加全面的暴露程序设计的本源,我们把这个公式稍加扩展:算法 + 数据结构 + 内存管理 = 程序设计,它进一步揭开了程序设计的老底:程序设计需要关注内存空间管理;
从计算机科学的发展趋势来看,Niklaus Wirth 极具远见卓识,因为现代程序设计越来越不需要关注内存空间的使用了,首先是由于科技的发展,存储器件成本越来越低,物理内存容量越来越大;其次是动态语言和以JAVA为代表的托管语言都具有自动内存分配和垃圾内存回收功能,用户只需要专注于人机交互、数据结构设计和业务逻辑的梳理了;
C / C++ 这类传统的静态语言也追随着这股潮流,在内存空间管理方面添加了越来越多的自动化支持,简化了内存管理,然而简单并不意味着内存管理的复杂性消失,出现崩溃问题时我们一筹莫展正是因为简单性蒙蔽了我们的思维,而崩溃的根源就是内存空间的使用不当造成的,因此对操作系统原理、内存管理、语言语义的透彻理解是我们解决崩溃问题的关键所在;
3.2、进程内存布局
在介绍详细介绍进程空间内存布局之前,我们首先看一下 Windows 的资源管理器进程的内存布局视图,如下所示:
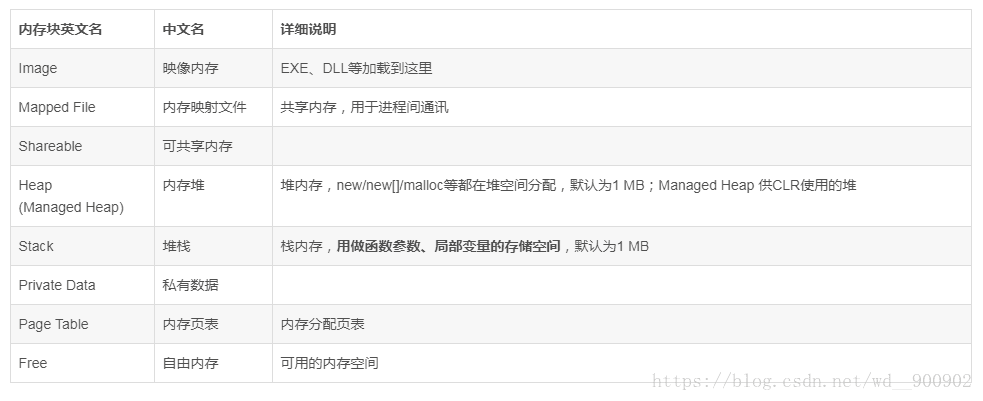
由于编译器在后台做了大量的内存管理自动化工作,因此程序设计过程中主要关注的内存区域类型有:Stack、Heap、Free(Free Virtual Address Space),下面我们对这几种做一个简要介绍:
Stack 是一块固定大小的连续内存,受运行时管理,无需用户自行分配和回收;当函数调用嵌套层次非常深时会产生 Stack overflow(堆栈溢出)错误,如递归调用、循环调用、消息循环、大对象参数、大对象局部变量等都容易触发堆栈溢出;
Heap 主要用于管理小内存块,是一个内存管理单元,默认为1MB,可动态增长;每一个应用程序默认有一个 Heap,用户也可以创建自己的 Heap,new/delete, malloc/free 都是从堆中直接分配内存块;
Free(Free Virtual Address Space)即进程空间中的整个可用地址空间,它会以两种方式被使用,一种是Heap 自动分配和回收,一种是直接使用VirtualAlloc*/VirtualFree* 分配和回收;用户对它的直接使用是用于分配连续大块内存,分配和释放的速度比使用 Heap 更快;
3.3、数据结构视图
内存始终都还是内存,所不同的是我们解读内存的方式不同;从代码视野来看内存中的数据结构,它就是对一块连续内存的专有解读;对任何一个内存地址,我们可以用数据结构A视图来解读,亦可以用数据结构B视图来解读,使用正确的数据结构视图读到正确的数据,使用错误的数据结构视图我们读到错误的数据;为了简明扼要的说明这个问题,我们来个案例:
char szSentence[] = “this is a example”;
int * nValue = (int *)szSentence; ----> *nValue = 1310540
记住这一点非常重要,C / C++ 程序设计中的很多技术法门都出自这;例如基本类型转换、指针对象转换、面向对象的多态、改写只读对象等都体现为连续内存块的解读视图变化;
由于操作系统已经接管了物理内存的使用,并且提供了透明的访问机制,对内存的使用更直接体现为对操作系统提供的进程地址空间的分配和回收;
在实际的编程实践中,程序员需要把整块空间再细分为8位、16位、32位、64位、8位连续块等数据空间,这里还涉及到两个概念:字节对齐和字节序列(又名端序,有大端小端之说),透彻理解编译器的对齐规则和处理所支持的字节序列,对于正确理解内存中的数据很关键。
3.3.1、字节序列
字节序列对于网络编程的同学尤其熟悉,因为需要把数据包在本机字节序列和网络字节序列(大端序列)来回转换,部分经常使用printf和基于偏移量访问内存的同学也会遇到字节序列带来的烦恼;
字节序列简单的讲是对大于一个字节的数据在内存中如何存放的问题,比如32位整数需要使用4个字节,这个四个字节该如何放置?按照二进制位切割为四个字节吗?下面我们详细介绍一下字节序列的两种定义:

端序的内存案例:

下面我们来看一个实践中产生的和端序想关联的问题,案例来自 Vimer的程序世界
int64_t a = 1;
int b = 2;
printf("%d, %d\n", a, b); ====> 1, 0
为什么会这样?有同事对该问题做了精辟的注解,为了尊重作者版权,故截图分享,请看下图:
【注】这个Bug依赖于编译器实现,可能在某些编译器上不会重现。
3.3.2、字节对齐
字节对齐涉及内存分配的问题,具体涉及到结构、联合类型、类成员数据的对齐分配,编译器根据不同的对齐规则分配不同的内存空间。
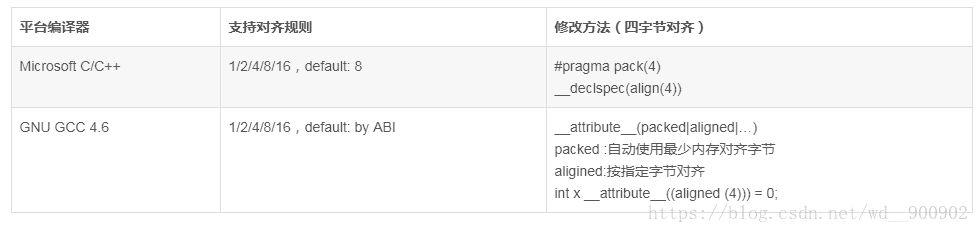
掌握对齐规则后,我们就可以在使用标量类型时、设计结构、联合、类类型时合理选择类型,既可以合理使用内存空间,又可以提高程序性能;下面我们看一个来自实践中的案例:


从上面我们可以看出,在默认对齐规则下,单个实例会浪费5个字节的内存,如果1万实例则会浪费 48 K内存,如果再加上不合理的长度定义,可能浪费更多的内存空间,在小内存空间限制的系统中,这显然是巨大的优化空间。
3.4、函数参数传递
C/C++ 的入口程序就是函数,函数需要传入参数,详细了解参数分类、传递规则、传递过程对写出正确且高效的程序起着至关重要的作用。笔者就曾因为传错了一个参数而导致程序崩溃,最后费了非常多的时间来查找原因,最后找出的原因是取址符(&)用错了,这让我下定决心彻底搞明白参数是怎么回事。
3.4.1、函数参数详解
参数分为输入参数、输入输出参数、输出参数、返回参数四种,分别适用于用于不同的场景,其作用和值得关注的细节如下:
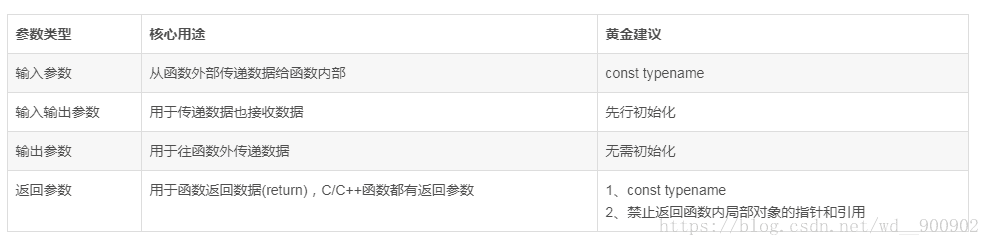
在输入参数和返回参数添加常量修饰符const 是一个非常好的编程习惯,能显著的预防很多错误,因为我们不知道编译器自动生成的参数入栈代码和参数出栈代码的具体模样,亦不知它何时何地执行,只能最大化的防范它的风险。
参数传递顺序有从左到右传递、从右到左传递两种,由于参数也是一个表达式,关注参数的求值顺序对写出正确的程序非常关键,例如:calc (origin++, origin+inc),如果不清楚参数表达式求值顺序就无法正确理解程序;

参数传递方式有值传递、引用传递、指针传递三种,三种参数本质上都是【值传递】,基本类型由于地址所指即为真实数据,传递时会生成真实数据的拷贝,将会消耗更多的堆栈内存,而引用传递和指针传递乃间接指向对象,传递时只是生成地址的拷贝,堆栈内存消耗比较少;我们首先对各个概念做一个简要回顾:

3.4.2、函数参数约定
参数传递顺序和传递形式组合形成了几种不同的函数调用约定,下面我们一起回顾一下编程实践中常见的几种约定:function resize(void ** p)

【注】VC++对函数的省缺声明是"__cedcl",将只能被C/C++调用,C++调用约定中的符号(*)需要根据参数填充;
由于函数调用清理代码由编译器自动生成,例如C/C++ 函数调用由调用函数清理堆栈,编译器会把清理代码生成在紧挨着被调用函数位置还是在函数退出前位置?对于我们来说是未知的,这里产生了潜在的未知风险;
3.4.2、函数参数能效
参数如何传递才最安全、最有效率?
Windows平台的调用栈空间是在链接时固定分配并写入二进制文件,UNIX类平台则可以通过环境变量设置,他们的默认栈初始空间情况如下:
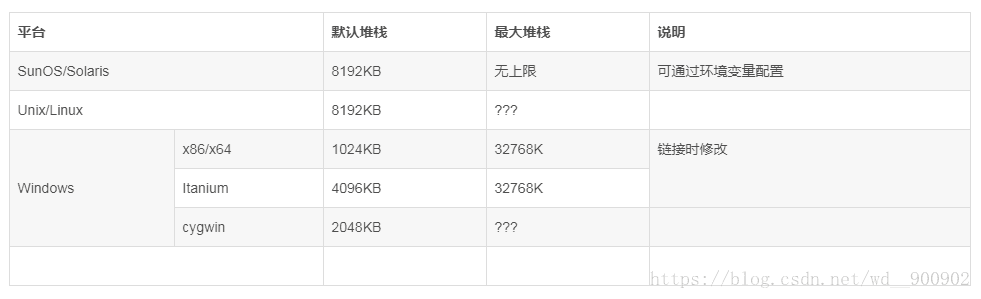
指针传递、引用传递都是传递对象的地址,传给函数时都是把这个地址压入栈,32位平台为四个字节,64位平台为八个字节,除结构实例、类实例外的标量类型,其数据长度均固定,可以精确的计算参数所需空间;我们做个简单的计算:取平台位宽为参数空间平均长度,以平均每个函数三个参数、1000级函数调用来计算,他们的占用空间如下:

由此可以看出,标量类型、指针、引用等数据类型长度都小于等于机器字长,占用的空间小,入栈、出栈速度都是非常块的,一般情况下默认栈空间足够使用,不会出现堆栈溢出的问题;
哪些数据类型会潜在的降低程序效率呢?答案是结构类型、类类型,他们是程序低效率的潜在幕后黑手;由于标量类型、指针、引用占用的空间等都是机器字长,标量类型无论使用哪种方式传递,和指针、引用都是同样的速度;结构类型、类类型的值传递方式呢?
咱们需要了解一下结构类型、类类型的值传递过程:调用参数类的复制构造函数生成新的类型实例并入栈,复制构造函数编译器自动生成,用户亦可以自己编写一个;我们可先看一个案例:

这段代码在 Visual C++ 编译器下运行的结果如上所示,其中多次执行最后三行代码,第三个窗口表现一致,由此我们可以判断出结构、类的复制构造函数不会深度复制对象,用值传递时会丢失数据。结构、类由于包含多个成员,逐个复制会倍数于标量和指针操作,带来了速度的降低;
前面的试验探讨了值传递、指针传递、引用传递,标量类型、指针、引用传递参数长度固定,安全高效,但结构、类的值传递方式带来诸多问题,例如堆栈溢出、数据丢失、效率低下等,建议结构、类完全使用指针或者引用传递;

3.5、变量生命周期
变量声明了,是不是直接使用就万事大吉了呢?我们当然希望就是这么简单,动态语言和托管类型语言确实实施了严格初始化机制:变量只要声明就初始化为用户设置的初始值或者零值;然而 C/C++ 不是这种实施了保姆级初始化机制的语言,透彻了解 C/C++ 的初始化规则对帮助我们写出健壮的程序大有裨益;
3.5.1、变量内存分配
C / C++ 支持声明静态变量(对象)、全局变量(对象)、局部变量(对象)、静态常量等,这些变量在分配时机、内存分配位置、初始化等方面上有些细微上的差别,熟悉并掌握他们对于写出正确的程序非常有帮助,请看下表:

对象创建后的成员数据取决于构造函数及其参数,系统自动生成的构造函数是不会初始化成员变量的;
对于函数、结构实例、类实例中的变量,编译器不会自动初始化,其值是不确定的,故直接使用会导致不确定的行为,这就是实践中经常碰到的程序行为表现莫名其妙的根源所在;
对于动态分配的内存(new/delete、new[]/delete[]、malloc/free),默认是不会置初值的,需要显式的初始化;对于结构和类型实例,new/new[]操作会自动调用构造函数初始化内存,详情请参见【对象初始化】;
【注】使用 VirtualAlloc/VirtualAllocEx 分配的虚拟内存会自动化初始化为零值;
【注】使用 HeapAlloc 分配的堆内存可以通过参数设置初始化为零值
3.5.2、变量初始化
从前面的变量初始化中得知结构实例、类实例、函数中声明的变量是不会自动初始化的,需要用户显式的初始化;值类型相对比较安全,可以声明时即初始化,这是最安全的作法;
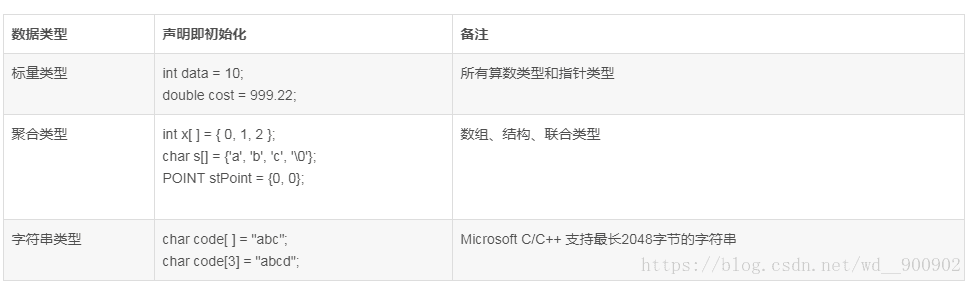
C/C++ 提供了两种初始化的机制可以完成结构实例和类实例的初始化,他们是:
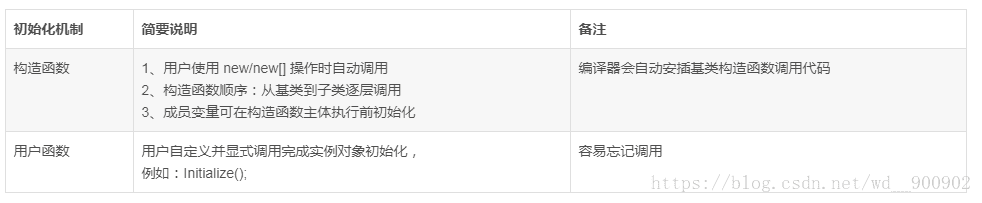
子类的构造函数被 new/new[] 操作时自动触发,它首先调用最底层基类的构造函数对其成员进行初始化,以此类推直到子类构造函数完成整个初始化过程;编译器会自动在子类构造函数的最前面中插装基类的默认构造函数以完成基类数据的初始化,如需要传递特别参数,则需要显示的调用基类构造函数。
由于类存在继承关系,基类和子类的构造函数调用存在着先后顺序关系,这意味着新对象的内存空间初始化会因为构造函数的调用顺序而呈现不同的状态:即这个对象内存块是一部分一部分的初始化; 由于这个特点,缺陷的幽灵就有了可乘之机,我们先看一个案例:

上述代码由于继承关系和内存初始化的特点而产生了两处缺陷:

【经验总结】
构造函数中要避免调用虚函数;
析构函数中要避免抛出异常;
3.5.3、变量多态与切片
在我们深入探讨这个问题前我们先看一个代码案例,然后我们基于这个案例讲解本节:

类继承关系带来了两个全新的概念:多态(类透视)和对象切片;这两类应用在面向对象编程(OOP)语言中都很常见两个技术;
多态常见的应用情况是对象泛化,即已基类视图操作对象。它的典型构成是基类数据结构视图 + 基类成员方法视图,从字面意思我们可以解读透视图只是视野范围的改变,即用户只能看到并调用基类定义视图中的数据和方法,而非数据和方法的改变,所以函数调用的依然是当前对象的方法。如图(四)所示展示的Shape透视图所示;
下面我们来举例为您演示一下多态类透视效果,通过基类指针指向同一个对象实例,只是透过基类的结构视图来调用相关方法,由于虚拟方法表指针指向同一个虚拟方法表,所以调用的还是同一个类的函数。

对象切片很好理解,相当于32位整数转换为16位整数时会根据目标类型裁减丢弃一部分数据,对象切片亦会裁减对象数据,它的变换过程是:分配目标类对象空间 è 复制源对象等长内存 è 设置虚拟方法表指针【如果有】,类对象切片与普通数据类型唯一的不同是它会切换对应的函数视图,如果有虚方法则还会切换虚拟方法表指针以确保调用正确的虚函数;
3.5.4、变量对象释放
自动分配的对象在离开其生命周期时会自动释放,这是由编译器自动保证的,一般情况下无需我们担忧;
我们需要关注的是对象指针所指的对象释放情况,尤其是跨越函数的对象值得关注,由于它的 new/delete、new[]/delete[]、malloc/free 等匹配性不明确,很容易被遗落而导致内存泄漏;比如模块A创建一个结构对象通过消息传递给模块B,模块B需要复制对象后即刻释放或者使用完毕后释放;
多态类型是我们需要着重关注的设计案例,它的析构函数在没有标记为虚函数和标记为虚函数的表现截然不同:
未标记为虚函数时它只会析构当前类实例,从对象指针类型开始向基类逐层析构,子类析构函数不会调用,会导致子类分配并持有的资源未释放,造成内存泄漏;
标记为虚函数时会按照对象指针所指对象类型往基类逐层调用其析构函数;
在图(三)所示案例中,如果基类 Shape 的析构函数未标记为虚函数,下面的代码会导致啥结果:

是的,会发生内存泄漏!!!
释放对象导致内存泄漏的另一个典型案例是对象数组释放不匹配导致的,为了解释清楚这个问题,我们先看一看 delete 操作是如何实现的:

编译器释放对象的过程分两步:调用其析构函数释放持有的资源,然后释放对象占用的内存;由于对象数组用普通对象释放操作来释放,其结果是只有第一个对象的析构函数被调用,其它对象都未调用析构函数,导致其它对象持有的内存资源未释放;我们先看一个具体的案例:

您或许会问:字符串对象数组本身是否完全释放?根据技术分析来看,Visual C++ 编译器会完全释放,其它编译器不确定。由于它使用普通对象释放操作,第二个、第三个字符串对象未调用其析构函数,字符串对象持有的资源未释放,导致内存泄漏。
四、C++ 错误根源分析
前面我们回顾了各个方面的技术点,分析和解决实践中遇到的案例就比较容易了,下面请跟我一起来看看一些常见案例;
4.1、变量未声明
由于 C/C++ 是静态类型编译语言,这类型错误一般都在编译阶段就会发现,不会带入到运行时阶段,但是这种类型的错误客观存在,并且会增大我们的排错时间;
出现这种类型的错误一般源自两种情况,一种是从动态语言转为使用 C/C++ ,由于习惯问题而直接使用未定义的对象;另一种是由于粗心而写错了变量名字,导致编译器理解为一个新的未声明的变量。
4.2、变量初始化
变量初始化看似平淡无奇,但它却是我们程序运行过程中不确定行为的幕后推手,并且常常在我们意料之外;重视变量的初始化对于我们写出正确的程序非常重要;为了帮助各位认识到其重要性,我们先看几个案例:

上面的代码会导致程序运行崩溃:访问无效的指针;

上面的代码运行会导致不可预知的行为,实践中表现为字体异常粗大,界面错乱;

上面的代码在不同的编译版本下表现出不同的行为,具体请看下面的输出:
在 Debug 状态下输出为:-858993460, -858993460,
在 Release 状态下输出为:4381392, 4381392
前面我们回顾知识点时介绍了只有全局变量(全局名字空间变量和子名字空间内变量)、静态变量会在首次执行时初始化,其它例如函数内局部变量、类成员变量、结构成员变量都不会自动初始化,每次执行时会为每一个变量分配内存,局部变量、成员变量指向未初始化的内存,于是就出现了上述案例所出现的情况;
局部变量、成员变量不会自动初始化,所以我们要养成声明即初始化的良好习惯;
4.3、内存访问
内存访问错误是所有C/C++开发人员都曾亲密接触的一类错误,这类错误最常见,它常常在我们无意识状态下蹦出来了,下面我们分析一下这类错误的根源;

内存访问触发的错误时常发生,但总结起来可以归纳为几类,他们分别是:数组访问越界、指针访问越界、字符串访问越界、迭代器访问越界、访问游移指针对象、访问空指针,他们有共同特征,也存在着一些细微的差别,让我们一起来看看:

为节省篇幅,这里不准备一一列举案例,有兴趣的同学可收集和罗列一下案例。
对指针加强检测自始至终都是一个良好的习惯,这是防御性编程的核心;
4.4、分配和释放
内存分配和释放在我们的程序中分分秒秒的进行着,它分为隐式分配回收和显式分配回收两种,我们详细说明一下这两种情况:
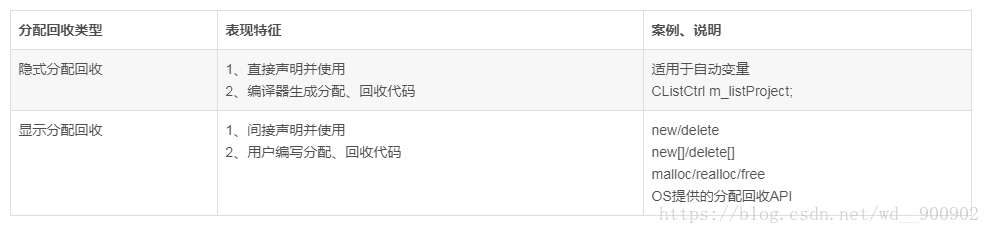
按照摩尔定律,内存器件的成本迅速下降,但内存紧缺的问题却没有随之解决,内存分配失败的问题依然存在,保持检测内存指针或捕获内存异常的习惯依然有必要;由于内存分配失败的原因是内存不足,故我们把探讨的重点放到内存不足的原因上来。
内存分配释放语义简单、明确,只需要配对使用正确即可,如果不配对使用则会导致内存泄漏,进而导致内存分配失败。我们着重讨论内存泄漏的正常和不正的原因,详细如下:
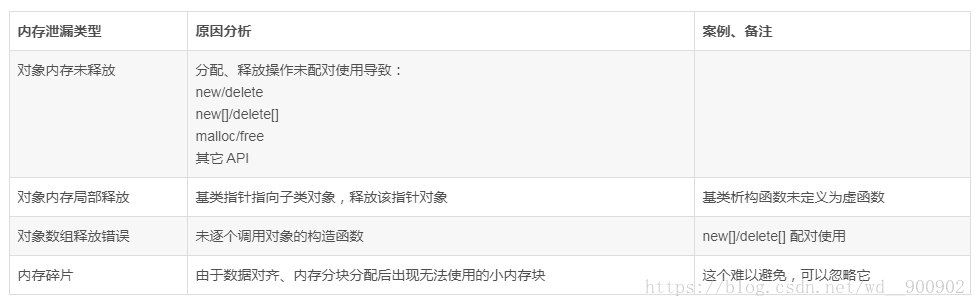
4.5、参数传递
函数参数传递的不像内存分配、释放那么自由,受到诸多的限制,例如类型限制、常量修饰符限制、传递类型限制等,并且编译器能检测出大部分参数传递方面的错误,然而仍然无法阻止我们犯错误,到底是由于疏忽还是认识不足导致这样的情况呢?
在详细阐述前我们一起来看一个实践中碰到的因为参数传递错误引发的崩溃案例,请看代码:

代码的真实意图是要扩充缓冲区(m_LexerState.buff),但由于通过中间变量的方式传递,并未真正的把扩充后的缓冲区地址传给&m_LexerState.buff,所以对象缓冲区实际没有变化,当访问扩充后的地址空间时,访问越界,程序崩溃;
在堆栈溢出章节我们还将看到类、结构类型的参数以值传递方式带来的危害:堆栈溢出、无法深度复制导致数据丢失,因此这两类参数应该尽量以指针、引用方式传递,对于不需要修改的参数尽量使用常量修饰符修饰(const)。
4.6、堆栈溢出
实践中碰到的另一类典型的崩溃是堆栈溢出,代码能编译通过,运行过程中会出现堆栈溢出而崩溃,为了加深对堆栈溢出的印象我们先看一个案例:[直接摘取自项目代码]
void CPerfJobRunResultModel::Load(LPCTSTR a_pszJobRunResultFilePath)
{
int iRet = 0;
// 获取头结构元数据
LPTDRMETA pstDrMetaData = tdr_get_meta_by_name(m_pstDrMetaLibrary, "PERF_JOBRUN_RESULT");
// 读取结构头获取整个结构空间大小
TDRDATA tdrHost;
PERF_JOBRUN_RESULT stJobRunResult;
memset(&stJobRunResult, 0, sizeof(PERF_JOBRUN_RESULT));
tdrHost.iBuff = sizeof(PERF_JOBRUN_RESULT);
tdrHost.pszBuff = (char *)&stJobRunResult;
iRet = tdr_input_file(pstDrMetaData, &tdrHost, a_pszJobRunResultFilePath, tdr_get_meta_current_version(pstDrMetaData), TDR_IO_NEW_XML_VERSION);
if (TDR_ERR_IS_ERROR(iRet))
{
// 错误处理代码,省略之
}
// 重新分配内存并加载文件
UINT memSize = sizeof(PERF_JOBRUN_RESULT) + (stJobRunResult.dwSuiteNum - 1) * sizeof(PERF_JOBRUN_SUITE_RESULT);
m_pstJobRunResultModel = (LPPERF_JOBRUN_RESULT)malloc(memSize);
if (NULL == m_pstJobRunResultModel)
{
UserThrowATPException(01005, "分配内存失败!");
}
memset(m_pstJobRunResultModel, 0, memSize);
tdrHost.iBuff = memSize;
tdrHost.pszBuff = (char *)m_pstJobRunResultModel;
iRet = tdr_input_file(pstDrMetaData, &tdrHost, a_pszJobRunResultFilePath, tdr_get_meta_current_version(pstDrMetaData), TDR_IO_NEW_XML_VERSION);
if (TDR_ERR_IS_ERROR(iRet))
{
UserThrowATPException(01005, "加载 TDR 实例文件失败: %s\n%s", a_pszJobRunResultFilePath, tdr_error_string(iRet));
}
m_HasUpdated = FALSE;
}
这个函数初期运行平稳,没出现啥问题;后来为了支持扩容,修改了性能测试相关数据结构,随后被发现出现了堆栈溢出崩溃;扩大程序栈空间(4M è 8M è 16M),仍然出现堆栈溢出;反复调试验证,堆栈溢出都集中出现在同一个函数:即进入函数的瞬间
void CPerfJobRunResultModel::Load(LPCTSTR a_pszJobRunResultFilePath)
随着一个个疑点的排除,问题集中在函数代码内;进一步测试发现性能测试数据结构占用16M空间:【PERF_JOBRUN_RESULT stJobRunResult;】,但还是没办法证实问题根源,于是在网络上搜寻触发函数(_chkstk)原因,终于找到一个说法是:函数内局部变量是在堆栈分配空间,当局部变量空间大于4K时(x86为4K, x64为8K,Itanium为16K)会触发函数(_chkstk)检查;结构变量属于值变量,在栈(Stack)空间分配,结构变量占用16M空间远远大于默认的1M空间,所以引发了堆栈溢出;
堆栈溢出并不可怕,只要我们认识它、掌握它的规律就知道如何防范;这里把常见的堆栈溢出类型一一列举,工作中稍加注意就可以预防;
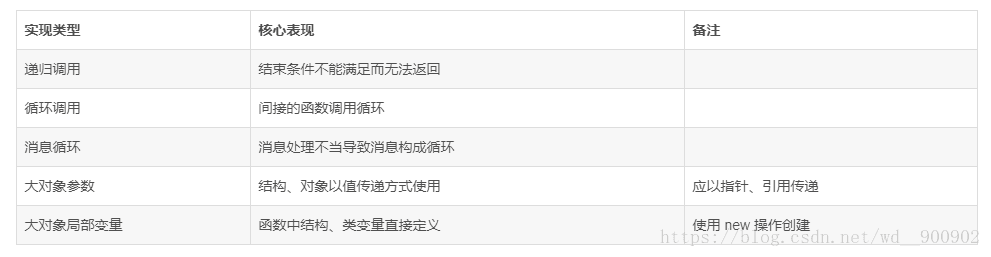
4.7、转换错误
标量类型强制转换出错是比较隐秘,因为 C/C++ 中本身就隐藏着大量的类型转换,不易为人察觉;但它经常来得莫名欺骗,排查起来亦痛苦万分。
我们看一个实践中发生的案例:http://km.oa.com/group/728/articles/show/14051
该段取时间的代码一直运行正常,突然有一天出现了错误,此前运行非常完好的代码怎么会突然出错呢?你百思不得其解。从代码本身来看,主要涉及从 uint64_t 到 int 类型的转换,即从无符号类型向有符号类型转换;据当事人事后分析得出的结论是由于转换操作是直接截断,而有符号类型的正负是根据最高位来解读的,0 表示该数据为正数,1 表示该数据为负数;基于此,转换的正确与否基于此那只能求菩萨保佑了。
我们再来看一个类型宽度一样的数据类型转换的案例,由于类型宽度相同,无需做截断处理,有符号类型同样基于最高位来确定数据的数值,于是就看到如下的结果。
int main()
{
// 有符号到无符号
short i = -3;
unsigned short u = 0;
cout << (u = i) << “\n”; // 输出: 65533
// 无符号到有符号
i = 0;
u = 65533;
cout << (i = u) << "\n"; // 输出: -3
}
我们再看一个实践中的案例:http://km.oa.com/group/533/topics/show/14900
//导航提示逻辑,提示显示3秒
if (oper->typeNavigate >=0)
{
oper->typeNavigateCount++;
if (oper->typeNavigateCount > 2)
{
oper->typeNavigate = -1;
oper->typeNavigateCount = 0;
TCtrlBase_Invalidate((TCtrlBase*)object, NULL);
}
}
现象:这段代码在模拟器运行正常,在MTK真机有问题;
原因:typeNavigate是个char型变量,受ARM编译器编译参数影响,这里的char等同于unsigned char,导致 if 语句永远为真,引起逻辑错误;
【问题】如果要逐字节操作大块内存时应该使用什么类型?char or signed char or unsigned char ?
五、C++ 编程最佳实践
1、遵循编程规范,例如公司的编程规范、Google C++ 编程规范等;
2、小就是美、简单就是美;
3、尽可能多的使用 const 修饰符;
4、声明即初始化:变量、对象声明时就初始化;
5、结构、类等实例变量都以指针变量的方式使用;
6、始终在使用前检测指针变量的有效性;
7、指针和标量类型使用值传递,其它都使用指针和引用传递;
8、多用智能指针: auto_ptr, shared_ptr,少用原始指针;
9、多用 new/delete/new[]/delete[],少用malloc/free/realloc;
10、多用只读常量、局部变量,少用全局变量、静态变量;
11、识别无符号数和有符号数的应用场景并正确选择数据类型;
12、重试编译器警告:重视并修复编译器警告;