Java—并发编程指南
并发编程是提高程序运行效率与响应速度的重要手段,在多CPU条件下,并发编程可以使硬件得到更大程度的运用。由于在并发环境下CPU随时会对多线程的运行进行调度,因此线程中各指令执行的顺序是不确定的,出现问题时也难以复现和定位。如果开发人员了解并发的原理,就能在有并发问题隐患的地方妥善处理来规避风险。
并发的知识体系很庞大,涉及到内存模型、并发容器、线程池等一系列知识点,优秀并发程序对性能与活跃性也有较高的要求,因此想要吃透并发并不是一件容易的事。想要写好并发程序,不仅需要对并发的原理有所了解,更需要工程上的实践,万丈高楼平地起,下面让我们来一起探索并发编程。
一、原子性、可见性、顺序性问题
1.1 原子性
提到并发,有一个很经典的例子就是同时启动2个线程对一个数循环+1,程序如下所示。线程t1和t2都会循环1万次a++,理想状态下a最终的值应该是20000,但是运行之后a的值总是小于20000,并且每次的结果都不尽相同,这是为什么呢?
public class Test {
public static int a = 0;
public static void main(String[] args) {
Runnable r = () -> {
for (int i = 0; i < 10000; i++) {
a++;
}
};
Thread t1 = new Thread(r);
Thread t2 = new Thread(r);
t1.start();
t2.start();
try {
// 程序本身运行在主线程, 这里需要让主线程等待t1和t2运行完再获取a的值
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("a: " + a);
}
}
这里涉及到2个问题:
- 一是原子性问题。先明确原子操作的定义:如果某个操作要么不执行,要么完全执行且不会被打断,则将其称为原子操作。上述程序中我们将
a++当成了原子操作,而它实际由多个原子操作组成,本身并不是原子操作。 - 二是可见性问题。线程t1修改了a的值后,t2可能感知不到。
可见性问题1.2中会讲,这里我们先讨论原子性问题。a++看起来是一个原子操作,而实际上a++需要3条CPU指令完成,这里的CPU指令才具备原子性。
指令1: 将变量a从内存加载到CPU寄存器
指令2: 寄存器修改a的值为a+1
指令3: 将结果写入内存
并发情况下,线程切换可能发生在任一CPU指令执行完的时候。例如当t1和t2一起运行时,可能出现下面的情况。
t1线程读到a的值为0
t1线程对寄存器中的值+1得到1
----------线程切换----------
t2线程从内存中读到a的值为0
t2线程对寄存器的值+1得到1
t2线程将1写入内存
----------线程切换----------
t1线程将1写入内存
可以发现在并发环境下,某个线程从内存中读取到的值可能不是最新数据,这也解释了为什么程序的结果总是小于20000。要解决这个问题,只需要将a++变为原子操作即可,通过synchronized关键字即可使某块代码具备原子性,该代码块也被称为同步代码块,如下所示。
synchronized (Test.class) {
a++;
}
该同步代码块以Test.class作为互斥锁,任何线程在进入该代码块之前需要先获取该锁,如果获取不到则需等待当前持有该锁的线程释放锁。可以理解为,锁是用来保护共享变量的,这里的Test.class就是用来保护共享变量a同一时刻只能被一个线程访问的锁。
那么如果新增一个与a无关的共享变量b,是否也可以使用Test.class来保护呢?
答案是否定的,如果用同一个锁来保护它们,那么不管修改a或b之前都要得到Test.class这个锁,导致访问a的同时不能访问b,但这两个变量并无关联,反而降低了运行效率。
不过可以通过另一个锁来保护b,由于Java中的任何对象都可以作为锁来使用,所以可以直接新建一个final对象来保护b,如下所示。
public class Test {
public static int b = 0;
public static final Object lock = new Object();
public static void main(String[] args) {
Runnable r = () -> {
for (int i = 0; i < 10000; i++) {
synchronized (lock) {
b++;
}
}
};
......
}
}
1.2 可见性与CPU缓存
可见性问题是指在并发条件下,一个线程修改共享变量后,另一个线程无法感知到共享变量的变化。该问题是由CPU缓存引起的,由于CPU与内存的运行速度相差太多,为了平衡这个差距,CPU引入了高速缓存cache作为中间层,当CPU从内存中读取数据时会将其读入cache中,之后CPU不用每次读取内存,而是直接操作cache中的数据,最后在合适的时机际将cache中的数据写入内存,当然这个时机对开发人员来说是不可控的。
在单核CPU条件下,CPU整体只有一个cache,因此多线程操作的也是同一个cache,不会出现可见性问题。而在多核CPU条件下,每核CPU都对应一个cache,很有可能两个线程读写的是各自的cache,由此产生了可见性问题。
下面用一个例子说明可见性问题,子线程t1在flag为true时会一直运行,但是主线程会在500ms后将flag改为false,看起来子线程只会运行500ms,但事实是子线程会一直运行下去。换句话说,主线程修改flag的行为对子线程来说不可见。
public class Test {
private static boolean flag = true;
private static int i = 0;
public static void main(String[] args) throws InterruptedException {
Runnable r1 = () -> {
while (flag) {
i++;
}
System.out.println("子线程结束");
};
Thread t1 = new Thread(r1);
t1.start();
Thread.sleep(500);
flag = false;
System.out.println("Main Thread结束");
}
}
要解决这个问题,使用volatile关键字修饰flag变量即可。
volatile关键字表示一个变量是易变的,从抽象的角度明确了该变量的可见性。作为高级语言关键字,volatile屏蔽了底层硬件的不一致性,在不同的环境下,volatile关键字在底层可能具有不同的实现,但是作为高级语言的开发者,我们只需要理解volatile在抽象层面的定义即可。
之前提到,CPU高速缓存中的数据会在合适的时机被写入内存,那么上面程序中的flag变量即使不加volatile,主线程对flag变量的修改也会在一段时间后写入内存。那为什么子线程一直感知不到flag的变化呢?
我们有理由猜测,子线程在while(flag)循环中读取的一直是CPU缓存中的flag变量,而没有从内存中重新获取。为了验证这个猜测,尝试在while(flag)循环中加上一些代码,如下所示。
public class Test {
private static boolean flag = true;
private static int i = 0;
public static void main(String[] args) throws InterruptedException {
Runnable r1 = () -> {
while (flag) {
i++;
try {
Thread.sleep(50);
System.out.println("......");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("子线程结束");
};
Thread t1 = new Thread(r1);
t1.start();
Thread.sleep(500);
flag = false;
System.out.println("Main Thread结束");
}
}
运行后发现子线程运行约500ms后停止,表示子线程在某个时机获取到了内存中flag的值,印证了我们的猜测。这表明如果不加volatile关键字,虽然cache的值与内存的值也会同步,但同步的时机是不确定的,这也是很多并发bug难以溯源的原因。
这时候你可能会对1.1的例子产生疑惑,虽然1.1中使用synchronized关键字使a++具备了原子性,不过并没有使用volatile修饰变量a,如果a不具备可见性的话,最终的结果也应该小于预期值才对。
但实际情况是,该程序最终的结果都是正确的,这与Java内存模型(JMM)有关,内存模型保证原子操作中的变量具备可见性,第2节会阐述JMM相关内容。
1.3 顺序性与指令重排
指令重排是指编译器为了提高程序的运行效率,在不影响运行结果的前提下对CPU的指令重新排序。即使指令之间存在依赖关系,编译器也会保证运行结果不受影响。
在单线程运行环境下,指令重排确实不会影响运行结果,但在多线程环境下它是存在一定隐患的。拿双重判空的单例模式来举例,其代码如下。假设A线程和B线程同时运行到同步代码块,A线程成功获取到锁并新建Singleton,A线程释放锁后B线程抢占到锁进入同步代码块,随后B线程发现单例已经初始化就退出。如果没有指令重排,这一段代码确实没有任何问题。
public class Singleton {
private static Singleton sInstance;
public static Singleton getInstance() {
if (sInstance == null) {
synchronized(Singleton.class) {
if (sInstance == null)
sInstance = new Singleton();
}
}
return instance;
}
}
但是sInstance= new Singleton()是可能会被指令重排的,正常来说这句代码的指令的执行顺序是这样的。
指令1: 分配一块内存
指令2: 在内存上初始化Singleton对象
指令3: 将内存地址赋值给sInstance变量
指令重排后的执行顺序可能是这样的。
指令1: 分配一块内存
指令2: 将内存的地址赋值给sInstance变量
指令3: 在内存上初始化Singleton对象
假设A线程执行到指令2处时被挂起,而B线程进入getInstance()方法,在第一个判空处发现sInstance不为空就会直接返回,但此时sInstance指向的内存并没有初始化,访问sInstance时很可能出现问题。因此需要使用volatile修饰sInstance来禁止相关的指令重排。
那么有没有一种更简单的实现单例的方法呢?自然是有的,如果一个单例对象在系统运行中肯定会被使用,在类初始化的时候直接新建单例的实例对象即可,不用考虑并发情况,其实现如下。
public class Singleton {
private static class Holder {
private static Singleton INSTANCE = new Singleton();
}
private Singleton() {
}
public static Singleton getInstance() {
return Holder.INSTANCE;
}
二、Java内存模型
并发场景下的原子性、可见性和顺序性问题会导致程序的运行结果不可预测,为了解决这些问题,Java内存模型(JMM)提供了volatile和synchronized关键字,其中volatile关键字用于实现共享变量的可见性与限制重排序,synchronized关键字用于实现代码块的原子性。JMM提供了6条Happens-Before规则来描述这两个关键字的作用,以便给开发人员提供指导。
Happens-Before是指,如果操作A Happens-Before 操作B,则表示在内存顺序上,A的结果对B是可见的。Happens-Before的具体规则如下。
① 对synchronized互斥锁的解锁Happens-Before对该互斥锁的后续加锁
② 对volatile变量的写操作Happens-Before对该变量的后续读操作
③ 主线程调用子线程start()方法前的操作Happens-Before该子线程的start()方法
④ 一个线程内的所有操作Happens-Before其他线程成功join()该线程
⑤ 任意对象的默认初始化Happens-Before程序的其他操作
⑥ Happens-Before具有可传递性,如果A Happens-Before B,B Happens-Before C,则A Happens-Before C
回头看1.1,代码中使用synchronized关键字使a++具备了原子性,同时a变量也具备了可见性。这是因为互斥锁的解锁Happens-Before后续加锁,因此之后拿到互斥锁的线程都知道上个线程对a的操作结果。
三、互斥锁
互斥锁用于保证代码块的原子性,实际是用于保护一个或一系列共享变量同一时刻只能被一个线程访问。当某个线程进入同步代码块时,该线程需要先获取同步代码块的锁,退出同步代码块时则释放锁。如果线程尝试获取锁时发现锁已被占用,则该线程被挂起,直到获取锁之后再进入运行态。
Java提供了synchronized和Lock两种互斥锁的实现。synchronized是Java关键字,属于语言特性,但是在Java6之前它的效率并不高。Lock系列由并发大师Doug Lea编写,在Java5时加入Java并发包。
3.1 synchronized
3.1.1 基本使用
synchronized用于修饰方法或代码块,它隐式地实现了加锁/解锁操作,线程进入方法或代码块时会自动加锁,退出时会自动解锁。其使用示例如下。
public class Sample {
private static final Object lock = new Object();
// 1. 修饰代码块
public void fun1() {
synchronized(lock) {
// ......
}
}
// 2. 修饰非静态方法
public synchronized void fun2() {
// ......
}
// 3. 修饰静态方法
public synchronized static void fun3() {
// ......
}
}
可以发现synchronized只有在修饰代码块时才需要指定互斥锁,而修饰方法时的互斥锁是Java隐性添加的。其规则为:修饰static方法时,互斥锁为当前类的class对象,也就是例子中的Sample.class;而修饰非static方法时,互斥锁为当前的对象实例。
3.1.2 锁的选择
首先需要明确什么样的对象适合作为互斥锁,由于互斥锁是用于保护共享变量的,那么互斥锁的生命周期应该与它保护的共享变量一致,且在运行过程中不可再被赋值。
synchronized修饰方法时隐式添加的锁就遵循了这样的规则,当synchronized修饰静态方法时,它的锁为当前类的class对象,该对象在程序开始运行时就被创建,且不可更改。
以下面的程序为例,staticList作为静态变量,它的生命周期是整个程序,与互斥锁Sample.class的生命周期相同。
public class Sample {
private static List<String> staticList = new ArrayList<>();
public synchronized static void addString(String s) {
staticList.add(s);
}
}
当synchronized修饰非静态方法时,它的锁为当前对象this。因为非静态方法用于操作非静态成员,例如下面示例中的mList,而非静态成员的生命周期就是当前对象this的生命周期。
public class Sample {
private List<String> mList;
public Sample() {
mList = new ArrayList<>();
}
public synchronized void addString(String s) {
mList.add(s);
}
}
需要注意的是,使用synchronized修饰static方法时,该类所有static方法的互斥锁都是同一个对象,所以该类所有static方法都是互斥的。如果各个static方法中需要保护的资源不一样,这样只会影响运行效率,使用synchronized修饰非静态方法时同理。
下方程序就使用了Sample.class这把锁保护了两个不同的资源,那么该如何修改呢?
public class Sample {
private static List<String> staticList1 = new ArrayList<>();
private static List<String> staticList2 = new ArrayList<>();
public synchronized static void addString1(String s) {
staticList1.add(s);
}
public synchronized static void addString2(String s) {
staticList2.add(s);
}
}
一般来说,互斥锁应与被保护的资源一一对应,最简单的方法就是将被保护的对象本身作为互斥锁,如下所示。
public class Sample {
private static final List<String> staticList1 = new ArrayList<>();
private static final List<String> staticList2 = new ArrayList<>();
public static void addString1(String s) {
synchronized (staticList1) {
staticList1.add(s);
}
}
public static void addString2(String s) {
synchronized (staticList2) {
staticList2.add(s);
}
}
}
可以发现新的示例中,我们使用final修饰了staticList1和staticList2,这是为什么呢?
这涉及到对线程加锁的原理,当程序对线程加锁时,实际是在锁对象中写入了该线程的id,因此锁对象在运行期间不该被重新赋值。如果在运行期间锁被重新赋值(例如上方的staticList1指向了一个新的对象),就相当于使用多个锁保护一个资源,无法达到互斥的目的。而被final修饰的对象是必须被初始化的,且无法被重新赋值,满足作为锁的条件。
3.1.3 线程"等待-通知"机制
考虑如下程序,当fun()方法中canExecute()这个运行条件不满足时,我们可能会通过循环等待的方式,直到canExecute()方法返回true后再运行接下来的逻辑。
public class Sample {
private boolean execute = false;
public void fun() throws InterruptedException {
while (!canExecute()) {
Thread.sleep(10);
}
// ......
}
private synchronized boolean canExecute() {
return execute;
}
public synchronized void setExecute() {
execute = true;
}
}
问题在于,线程睡眠的时间是一个固定的值。如果该值太大,线程无法在运行条件满足后的第一时间开始运行;如果该值太小,线程会不断地调用同步方法canExecute()判断当前的状态,浪费了运行资源。那么有没有一种方法,能够使不满足运行条件的线程进入休眠状态(该状态下线程不消耗运行资源),而在满足条件后的第一时间开始运行呢?这就是线程的"等待-通知"机制。
Java所有的对象都有wait()、notify()和notifyAll()这3个方法,这是对象作为互斥锁时所使用的方法,它们与synchronized共同实现了线程的"等待-通知"机制,需要注意的是,这3个方法必须在synchronized代码块中执行。下面介绍这3个方法的作用。
- **wait(): 用于使当前线程进入休眠状态。**如果当前的运行条件未满足,可以调用互斥锁的
wait()方法主动放弃互斥锁并进入休眠态,随后该线程会进入互斥锁的等待队列中,直到被其他线程唤醒。 - **notify(): 用于唤醒互斥锁等待队列中的一个线程。**当等待队列中的线程的运行条件被满足时,可以调用
notify()方法随机唤醒等待队列中的一个线程,随后被唤醒的线程去争夺互斥锁。 - **notifyAll(): 唤醒互斥锁等待队列中的所有线程。**由于
notify()方法唤醒线程时是随机的,可能唤醒的并不是真正满足运行条件的线程,因此实际开发中基本只用notifyAll(),让等待队列中的所有线程去争夺互斥锁。
举个简单的例子,代码如下所示。
线程t1运行tryExecute()方法,发现mShouldExecute为false,调用wait()主动进入休眠态。线程t2睡眠3秒后将mShouldExecute设置为true并调用notifyAll()通知等待队列中的线程,t1被唤醒后发现运行条件满足,继续执行。
public class Sample {
private boolean mShouldExecute = false;
public void tryExecute() throws InterruptedException {
synchronized (this) {
while (!mShouldExecute) {
System.out.println("tryExecute wait...");
wait();
}
realExecute();
}
}
private void realExecute() {
System.out.println("realExecute");
}
public void setExecute() {
synchronized (this) {
mShouldExecute = true;
notifyAll();
}
}
public static void main(String[] args) {
Sample sample = new Sample();
Thread t1 = new Thread(() -> {
try {
sample.tryExecute();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
Thread t2 = new Thread(() -> {
try {
Thread.sleep(3000);
sample.setExecute();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t1.start();
t2.start();
}
}
上述程序中的互斥锁是当前对象this,因此在调用wait()和notifyAll()方法时省略了this,写完整应该是this.wait()和this.notifyAll()。
在判断程序是否满足运行条件时,tryExecute()方法中使用了循环while (!mShouldExecute),这是因为线程t2调用notifyAll()后,线程t1并不会马上执行,而是要去争夺互斥锁。有可能争夺到互斥锁时,运行条件又不满足了,因此需要重新判断。
线程"等待-通知"机制可以用来实现阻塞队列(BlockingQueue)。阻塞队列是一种"生产者-消费者"模型的数据结构,当队列为空时,所有尝试获取数据的线程都会休眠,直到别的线程成功添加数据后唤醒它们;当队列已满时,所有尝试添加数据的线程都会休眠,直到获取数据成功的线程唤醒它们。
public class BlockingQueue<T> {
private Queue<T> mQueue;
private int mCapacity;
public BlockingQueue(int capacity) {
mQueue = new ArrayDeque<>(capacity);
mCapacity = capacity;
}
/**
* 尝试向队列添加数据, 如果队列已满则休眠当前线程
*/
public void offer(T t) throws InterruptedException {
synchronized (this) {
while (isQueueFull()) {
wait();
}
mQueue.offer(t);
notifyAll();
}
}
/**
* 尝试获取队头数据, 如果队列为空则休眠当前线程
*/
public T take() throws InterruptedException {
synchronized (this) {
while (isQueueEmpty()) {
wait();
}
T result = mQueue.poll();
notifyAll();
return result;
}
}
/**
* 判断队列是否为空
*/
private boolean isQueueEmpty() {
return mQueue.isEmpty();
}
/**
* 判断队列是否已满
*/
private boolean isQueueFull() {
return mQueue.size() == mCapacity;
}
}
3.2 Lock
Lock用于解决synchronized在某些场景下的缺陷,在以下场景中synchronized无法实现最佳效果,但是Lock可以轻松解决。
- 当线程进入synchronized修饰的方法或代码块中,只有等线程执行完或者调用
wait()方法才会释放锁。如果一个线程在进行耗时任务,那么其他线程都必须等待它运行完毕,无法中断。 - 使用synchronized保护共享变量时,在同一时刻最多只有一个线程进行读写。但是多个读线程并不冲突,如果读线程也互斥的话会影响程序效率。针对这种情况,Lock提供了读写锁ReadWriteLock。
- 使用synchronized实现"等待-通知"机制时,调用
notifyAll()会唤醒所有阻塞的线程,无法唤醒特定的线程。例如在3.1.3的阻塞队列中,如果某个线程执行poll()方法取出了队列中的最后一个数据,随后只需要唤醒那些调用offer(T t)的线程即可,而notifyAll()会唤醒所有线程,如果调用poll()方法的线程抢占到互斥锁,也会马上发现条件不满足,然后继续休眠。
Lock本身是一个接口,针对不同的场景Lock提供了不同的实现类,接口如下所示。
/**
* 获取锁
*
* Lock的实现应该能够监测到锁的错误使用, 例如可能产生死锁或抛出异常
* Lock的实现必须记录锁的情况和异常类型
*/
void lock();
/**
* 获取锁, 除非线程被中断
*
* 如果当前线程在进入方法前或者在获取锁的过程中被设置为interrupted
* 那么会抛出InterruptedException并且当前线程的中断状态会被清除
*/
void lockInterruptibly() throws InterruptedException;
/**
* 如果当前锁可用, 则获取锁, 否则直接返回false
*
* 一个典型的用法如下所示:
* Lock lock = ...;
* if (lock.tryLock()) {
* try {
* // manipulate protected state
* } finally {
* lock.unlock();
* }
* } else {
* // 备用逻辑
* }}
*/
boolean tryLock();
/**
* 如果在给定时间内线程没有被中断且获取到锁则返回true
* 如果在给定时间之后线程还未获取到锁, 则返回false
*/
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
/**
* 释放锁
*/
void unlock();
/**
* 返回一个绑定了当前Lock的条件变量Condition, 用于实现线程的"等待-通知"机制
* 在某个Condition上被阻塞的线程可以被单独唤醒
*/
Condition newCondition();
Lock作为并发包的实现,在使用上与synchronized关键字有所不同。synchronized是自动加锁/解锁的,即使在同步代码块中出现异常,JVM也能保证锁正常释放。但是Lock无法做到,在使用Lock时,需要遵守以下的范式来保证遇到异常时也能正常释放锁,否则其他线程永远得不到运行的机会。
public void fun() {
lock.lock();
try {
// ......
} finally {
rtl.unlock();
}
}
3.2.1 可重入锁ReentrantLock
可重入锁指的是线程可以重复获取同一把锁,示例如下所示,一个线程运行到fun1()时获取到了锁,在未释放锁的情况下调用fun2()是可以正常运行的。
synchronized关键字也是可重入锁,因为它的加锁操作本质上就是在锁这个Java对象的对象头写入当前线程的id,表示锁被当前线程占有了,自然是可重入的。
public class Sample {
private Lock lock = new ReentrantLock();
public void fun1() {
lock.lock();
try {
fun2(); // fun2()也需要获取锁
} finally {
lock.unlock();
}
}
public void fun2() {
lock.lock();
try {
// ......
} finally {
lock.unlock();
}
}
使用synchronized关键字时,可以通过wait()和notifyAll()实现线程的"等待-通知"机制,在3.1.3中通过它们实现了一个阻塞队列。但是使用wait()和notifyAll()存在的问题是,只能唤醒所有休眠的线程,而无法根据当前的条件唤醒特定的线程去执行。
但是Lock解决了这个问题,Lock接口有个方法Condition newCondition()可以新建一个与当前Lock绑定的条件变量。可以通过Condition.await()方法使某个线程休眠,当该条件变量满足后,可以通过Condition.signalAll()唤醒该条件变量下休眠的线程。
下面用ReentrantLock和Condition实现阻塞队列如下,此时可以创建两个Condition,一个Condition表示队列不满,如果线程添加数据时发现队列已满,那么阻塞在该Condition上,直到有数据出队时唤醒阻塞在该条件上的线程;另一个Condition表示队列不空,如果线程获取数据时发现队列为空,则阻塞在该Condition上,直到有数据入队时唤醒阻塞在该条件上的线程。
public class BlockingQueue<T> {
final Lock lock = new ReentrantLock();
final Condition notFull = lock.newCondition(); // 条件: 队列不满
final Condition notEmpty = lock.newCondition(); // 条件: 队列不空
private Queue<T> mQueue;
private int mCapacity;
public BlockingQueue(int capacity) {
mQueue = new ArrayDeque<>(capacity);
mCapacity = capacity;
}
public void offer(T t) {
lock.lock();
try {
while (isQueueFull()) {
notFull.await();
}
mQueue.offer(t);
// 入队后, 通知可以出队了
notEmpty.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
private boolean isQueueFull() {
return mQueue.size() == mCapacity;
}
public T take() {
T result = null;
lock.lock();
try {
while (isQueueEmpty()) {
notEmpty.await();
}
result = mQueue.poll();
// 出队后, 通知可以入队了
notFull.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
return result;
}
private boolean isQueueEmpty() {
return mQueue.size() == 0;
}
}
3.2.2 读写锁ReadWriteLock
使用synchronized关键字保护共享变量时,线程的读操作也会互斥,但是多个线程的读操作并不会产生并发问题。针对读写场景,Java并发包提供了读写锁ReadWriteLock,它是一个接口,如下所示。
public interface ReadWriteLock {
Lock readLock(); // 返回读锁
Lock writeLock(); // 返回写锁
}
ReadWriteLock的实现为ReentrantReadWriteLock,从命名可以看出,这是一个可重入锁。当调用readLock()或writeLock()获取读锁或写锁时,返回的是ReentrantReadWriteLock中的内部变量readerLock和writerLock,它们都是Lock接口的实现类。
public class ReentrantReadWriteLock
implements ReadWriteLock, java.io.Serializable {
/** Inner class providing readlock */
private final ReentrantReadWriteLock.ReadLock readerLock;
/** Inner class providing writelock */
private final ReentrantReadWriteLock.WriteLock writerLock;
/** Performs all synchronization mechanics */
final Sync sync;
// 默认新建非公平锁
public ReentrantReadWriteLock() {
this(false);
}
public ReentrantReadWriteLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
readerLock = new ReadLock(this);
writerLock = new WriteLock(this);
}
public ReentrantReadWriteLock.WriteLock writeLock() { return writerLock; }
public ReentrantReadWriteLock.ReadLock readLock() { return readerLock; }
......
}
在使用之前先来看一下ReadWriteLock的特性:
- 读和读之间不互斥,读和写之间互斥,写和写之间互斥。这意味着没有写锁时,读锁可以被多个线程持有。
- 读写锁只适用于读多写少的场景,例如某个很少被修改但是经常被搜索的数据(如条目)就适合使用读写锁。如果写操作较为频繁,那么数据大部分时间都被独占锁占据,并不会提升并发性能。
- 持有读锁的线程无法直接获取写锁,但是持有写锁的线程可以获取读锁,其他线程无法获取读锁。换句话说,读锁无法升级为写锁,写锁可以降级为读锁。
- 读锁和写锁都实现了Lock接口,因此它们都支持
tryLock()和lockInterruptibly()等方法。但是只有写锁支持Condition,读锁不支持使用条件变量。
使用ReadWriteLock的一个简单示例如下。
public class Sample<T> {
private ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private T mData;
public T read() {
readWriteLock.readLock().lock();
try {
return mData;
} finally {
readWriteLock.readLock().unlock();
}
}
public void write(T t) {
readWriteLock.writeLock().lock();
try {
mData = t;
} finally {
readWriteLock.writeLock().unlock();
}
}
}
3.2.3 支持乐观读的StampedLock
StampedLock具有三种支持读/写功能的模式,它的状态由版本(stamp)和当前的模式组成。StampedLock获取锁的方法会返回一个stamp,该值用于表示当前锁的状态,在释放锁和转换锁时需要stamp作为参数,如果它与锁的状态不匹配就会失败。StampedLock支持的三种模式为写、读和乐观读。
- 写模式,类似读写锁的写锁。线程调用
StampedLock.writeLock()后独占访问数据,该方法返回一个stamp表示锁的状态,调用StampedLock.unlockWrite(stamp)解锁时需要该stamp。
tryWriteLock()和tryWriteLock()方法也会返回stamp,这2个方法获取锁失败时会返回0。当锁处于写模式时无法获得读锁,所有乐观读的验证都将失败。 - 读模式,类似读写锁的读锁。线程调用
StampedLock.readLock()后进行读操作,多个线程的读操作可同时进行。读锁加锁时也会返回stamp,用于解锁时调用StampedLock.unlockRead(stamp)使用。 - 乐观读模式,该模式是读锁的弱化版本,使用时不需要获取锁。乐观读的思想是,假设读的过程中数据并未被修改。乐观读避免了锁的争用并提高了吞吐量,但是它的正确性无法保证,因此读到结果后需要验证在乐观读时是否有线程获取了写锁。
调用StampedLock.tryooptimisticread()后可进行乐观读,如果当前不处于写入模式则返回非零stamp,乐观读结束后调用validate(stamp)判断结果是否有效。
StampedLock的使用依赖于对所保护的数据、对象和方法的了解,如果乐观读的结果未经验证,不应该用于无法忍受潜在不一致的方法。StampedLock是不可重入的,因此获取了锁的线程不应该调用其他尝试获取锁的方法。
来看官方提供的例子,Point类有3个方法,move(...)方法描述了写模式的一般流程;distanceFromOrigin()描述了乐观读模式的流程,如果乐观读的数据失效,则获取读锁进行读操作;moveIfAtOrigin(...)描述了StampedLock的锁升级,在平时开发中,锁的升级要慎重使用。
public class Point {
private double x, y;
private final StampedLock sl = new StampedLock();
// 写锁
void move(double deltaX, double deltaY) {
long stamp = sl.writeLock();
try {
x += deltaX;
y += deltaY;
} finally {
sl.unlockWrite(stamp);
}
}
// 乐观读
double distanceFromOrigin() {
long stamp = sl.tryOptimisticRead();
double currentX = x, currentY = y;
if (!sl.validate(stamp)) {
// 如果数据已过时, 则获取读锁进行读操作
stamp = sl.readLock();
try {
currentX = x;
currentY = y;
} finally {
sl.unlockRead(stamp);
}
}
return Math.sqrt(currentX * currentX + currentY * currentY);
}
// 锁的升级
void moveIfAtOrigin(double newX, double newY) {
long stamp = sl.readLock();
try {
while (x == 0.0 && y == 0.0) {
long ws = sl.tryConvertToWriteLock(stamp);
if (ws != 0L) {
// 需要将升级后的stamp值更新
stamp = ws;
x = newX;
y = newY;
break;
} else {
sl.unlockRead(stamp);
stamp = sl.writeLock();
}
}
} finally {
sl.unlock(stamp);
}
}
}
四、线程安全的变量
互斥锁是用于保护共享变量的,但如果一个变量不会被多个线程同时访问也就没有保护的必要了,例如方法内的局部变量。根据Java虚拟机规范,每个线程的内存中都包含程序计数器、虚拟机栈以及本地方法区这3块内存,其中虚拟机栈用于存储线程的方法调用,当调用某个方法时,线程会在虚拟机栈中压入一个栈帧;等该方法调用完毕时,对应的栈帧就会从虚拟机栈中弹出,而局部变量表就保存在栈帧中。

在大部分Java虚拟机的实现中,虚拟机栈的大小是固定的,只有少数JVM的虚拟机栈是可以扩展的。虚拟机栈大小固定的情况下,如果进行一个深度过大的递归调用时,就可能产生StackOverflow异常,就是因为虚拟机栈没有足够的空间去存储一个栈帧了。
当然共享变量也不一定是线程不安全的,下面介绍3种线程安全的变量,它们实现线程安全的方式各不相同。
4.1 不可变变量
并发环境下对共享变量的读写会出现问题,但是只读不写就没有并发问题。如果一个共享变量在初始化后不会再改变,它就是线程安全变量。我们知道被final关键字修饰的变量是必须被初始化且初始化后不再改变的,那么被final修饰的共享变量是否就是线程安全的呢?我们以两个例子来说明。
先来看这个例子,类中有2个共享变量分别是String和int类型的,它们在构造方法中会被初始化,并且不可更改,因此是线程安全的。
public class Sample {
private final String mString;
private final int mInt;
public Sample(String s, int i) {
mString = s;
mInt = i;
}
public String getString() {
return mString;
}
public int getInt() {
return mInt;
}
}
来看第二个例子,虽然Sample中将mTest修饰为final变量,但是这里的final只是表示mTest对象的内存地址不可变,对象中的值是可变的,所以通过getTest()获取到mTest变量后,是可以对mTest中的String和int重新赋值的。而Test类中的String和int变量不是final变量,所以Sample不是线程安全的。
public class Sample {
private final Test mTest;
public Sample(Test test) {
this.mTest = test;
}
public Test getTest() {
return mTest;
}
static class Test {
public String s;
public int i;
}
}
如果想要让类的对象是不可变的,那么类的属性应该全部修饰为final,如果某个属性不是基本类型,那么该类也应将所有属性修饰为final。
需要注意的是,String类型是不可变的,当调用String的subString()或replace()方法时不是修改原来的String,而是生成一个新的String对象。但是StringBuilder和StringBuffer是可变的,调用append()方法时是在原对象上操作的。
4.2 原子类变量
在1.1中我们解决a++原子性问题的方法是使用synchronized,但是加锁/解锁操作以及线程切换都是比较消耗性能的。但是有一种变量叫原子类变量,它的方法本身就是原子操作,这是通过CPU指令支持的,因此具有很好的效率。
4.2.1 基本变量原子类
原子类中的AtomicBoolean, AtomicInteger, AtomicLong对应基本类型的Boolean, Integer, Long,这3个原子类共有的方法如下。
// 只有当前原子变量的值是expect才更新为update, 成功返回true, 失败返回false
boolean compareAndSet(expect, update);
// 将原子变量的值更新为newValue并返回更新前的值
boolean/int/long getAndSet(newValue);
// 将原子变量的值更新为newValue, 但是对其他线程并不一定立即可见
void lazySet(newValue);
当然AtomicInteger和AtomicLong还有另外的方法,这些方法通常成对出现,例如getAndIncrement()和incrementAndGet(),它们的功能都是自增,唯一的不同就在于返回的是更新前的值还是更新后的值。如果1.1的例子使用原子类来实现,只需要将a改为原子变量a = new new AtomicInteger(0)并将a++改为a.getAndIncrement()就能得到正确的结果。
// 增加delta, 返回更新后的值, getAndAdd()与其作用相同但是返回更新前的值
int/long addAndGet(int delta);
// 通过IntBinaryOperator对prev和x计算得到新的值, IntBinaryOperator的方法必须无副作用
int/long accumulateAndGet(x, IntBinaryOperator);
// 通过IntUnaryOperator对prev计算得到新的值, IntUnaryOperator的方法必须无副作用
int/long updateAndGet(IntUnaryOperator updateFunction);
原子类通过CPU提供的CAS指令实现了原子性,该指令本身具有原子性。CAS指Compare And Swap,即比较并交换,该指令先比较共享变量的值与期望值,只有这两个值相等才将共享变量的值更新。原子类的compareAndSet(expect, update)方法就是通过native的compareAndSwapXXX(...)方法实现的。
CAS+自旋是并发编程的一大利器,在Java并发包中得到了广泛的应用,"自旋"实际上就是通过循环不断尝试CAS操作直到成功。例如AtomicInteger的getAndAdd(delta)方法,它实际调用Unsafe中的getAndAddInt(Object var1, long var2, int var4)方法,如下所示。由于在进行CAS指令之前,原子类的值可能被其他线程修改,因此需要循环获取原子变量当前的值并调用compareAndSwapInt(...)直到成功。
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
4.2.2 原子数组类
数组原子类包括AtomicIntegerArray, AtomicLongArray和AtomicReferenceArray,它们的方法都大同小异。以AtomicIntegerArray为例,它有2个构造方法,一个传入数组长度,数组中所有的值被初始化为0,另一个构造方法直接传入一个int数组。
public AtomicIntegerArray(int length) {
array = new int[length];
}
public AtomicIntegerArray(int[] array) {
// Visibility guaranteed by final field guarantees
this.array = array.clone();
}
相比于AtomicInteger,AtomicIntegerArray的方法在使用时只是多传入了数组下标参数i,看看下面的方法,是不是似曾相识?AtomicLongArray同理。
AtomicReferenceArray是原子引用的数组,接下来的4.2.3会讲解原子引用AtomicReference,使用原子数组类时只需加上下标即可。
boolean compareAndSet(int i, int expect, int update);
int getAndAdd(int i, int delta);
int getAndIncrement(int i);
......
4.2.3 原子引用类
引用原子类为AtomicReference,那么它是将改变引用这个操作封装成了原子操作吗?当然不是!因为改变引用这个操作本身就是原子的,对引用赋值只需要一条指令,它不会被CPU打断。
这点也可以从AtomicReference的set(V newValue)方法看出来,该方法只是对引用赋值。
public final void set(V newValue) {
value = newValue;
}
因此AtomicReference的价值就在于它的CAS指令,用于防止其他线程随意篡改引用的值。
boolean compareAndSet(V expect, V update);
使用AtomicReference要注意是否存在ABA问题,先来解释一下什么是ABA问题。
之前使用AtomicInteger时,我们将原子类的值当成了它的状态,在调用compareAndSet(A, update)时只要原子类的值与A相等就认为它没有被修改过,但这样的判断是存在隐患的。如果T1线程在调用compareAndSet(A, update)之前,T2线程将值从A改为B,再从B改为A,虽然原子类的值没变,但是它的状态已经发生了变化。随后T1线程执行CAS时发现值未变就会继续执行,但是原子类状态上的变化会引起一些意想不到的错误。
维基百科的CAS词条[参考2]描述了一个无锁栈可能出现的ABA问题。先解释一下无锁栈,如果需要实现一个支持并发的栈,有哪些方式可以实现呢?
显而易见的实现方式是在pop()和push()方法上加锁,这种实现简单粗暴,不会出错,但是效率较低。更好的方式是使用CAS+自旋,该实现不需要加锁,通过CAS+自旋实现的数据结构也被称为无锁结构。
以无锁栈为例,其数据结构为链表,通过一个指针head指向栈顶,栈的push和pop操作都依赖head完成,当head指向null时栈为空。
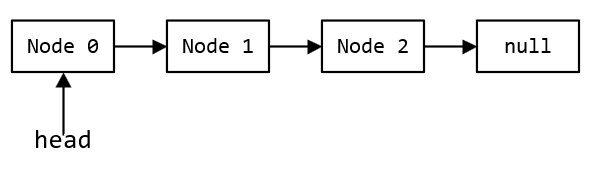
为了保证线程对head操作时的原子性,需要将head定义为原子引用AtomicReference,无锁栈代码如下所示。
下面以push操作为例,介绍CAS+自旋是如何工作的。如下方代码的push()方法所示,新建pushNode后,将pushNode.next指向head,并通过CAS将head指向pushNode。但是执行CAS之前head可能会被修改,因此如果CAS执行失败,就需要重新为pushNode赋值并再次尝试CAS直到成功。
public class ConcurrentStack {
private AtomicReference<StackNode> headReference;
public ConcurrentStack() {
headReference = new AtomicReference<>(null);
}
public void push(Integer i) {
StackNode pushNode = new StackNode(i);
while (true) {
StackNode head = headReference.get();
pushNode.next = head;
// 其他线程可能在此处修改了head的值
if (headReference.compareAndSet(head, pushNode)) {
break;
}
}
}
public StackNode pop() {
while (true) {
StackNode head = headReference.get();
if (head == null) {
return null;
}
StackNode newHead = head.next;
// 其他线程可能在此处修改了head的值
if (headReference.compareAndSet(head, newHead)) {
return head;
}
}
}
private static class StackNode {
public int value;
public StackNode next;
public StackNode(Integer i) {
value = i;
}
}
}
那么在什么情况下,无锁栈会发生ABA问题呢?假设当前栈如下所示。

此时T1线程调用pop(),但是在执行CAS之前该线程被挂起,也就是停在了上述pop()方法的注释处。此时head指向StackNode4,newHead指向StackNode3。
但是这时T2线程调用了2次pop()使得StackNode4和StackNode3出栈,随后新建另一个值为4的节点StackNode4*并push入栈。可以看到此时StackNode4和StackNode3是游离在栈外的,但是StackNode3.next还是指向StackNode2的。T1线程中的临时变量head指向StackNode4,临时变量newHead指向StackNode3。
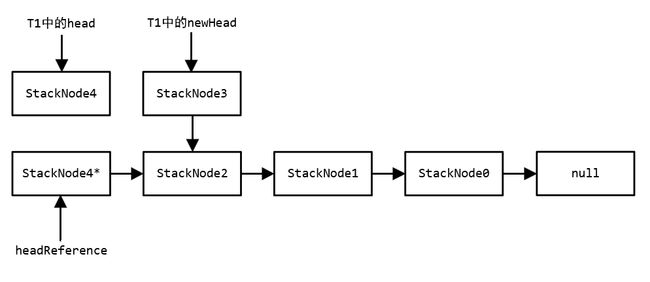
如果由于某种原因,StackNode4*的地址与T1线程中的head(也就是StackNode4)相等,那么T1线程获得时间片后会认为head并未发生变化并执行CAS,即使此时栈的结构和T1挂起前已经不一样了。T1执行完之后栈如下所示,该结果与预期的并不一致。
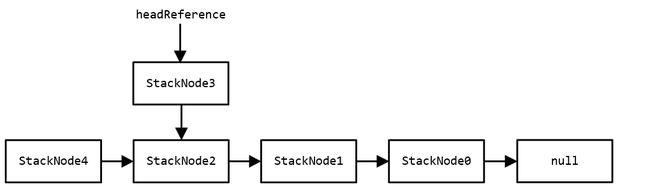
问题在于,StackNode4*的地址可能与StackNode4一样吗?换个问法,新的对象可能与之前的对象地址相同吗?当然有可能!主要是以下2种情况:
① 该类使用享元模式,所有值一样的对象实际都是一个。但是StackNode不可能使用享元模式,因为节点的next值都是不同的。
② 类使用了对象缓存池,以StackNode为例,被pop的节点会被缓存,需要新节点时先从缓存池中获取。
了解了ABA问题产生的原因后,我们通过代码来模拟。由于该场景难以模拟,因此选择在栈的pop()方法中进行延时,保证其他线程在CAS之前能够修改head,修改后的ConcurrentStack如下。
public class ConcurrentStack {
省略其他代码......
public StackNode pop(long t) {
while (true) {
StackNode head = headReference.get();
if (head == null) {
return null;
}
StackNode newHead = head.next;
try {
Thread.sleep(t);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (headReference.compareAndSet(head, newHead)) {
return head;
}
}
}
}
然后修改StackNode类,通过ConcurrentHashMap缓存被回收的StackNode对象,获取StackNode对象统一通过obtain(Integer i)方法。
public class StackNode {
public int value;
public StackNode next;
private static ConcurrentHashMap<Integer, StackNode> mCache = new ConcurrentHashMap<>();
public static StackNode obtain(Integer i) {
StackNode stackNode = mCache.remove(i);
if (stackNode == null) {
stackNode = new StackNode(i);
}
return stackNode;
}
public static void recycle(StackNode stackNode) {
mCache.putIfAbsent(stackNode.value, stackNode);
}
private StackNode(Integer i) {
value = i;
}
}
随后运行以下代码测试,就会发现无锁栈最后的结果与预期不符。代码中的注释详细描述了每一步的运行流程,不再赘述。
public class Main {
public static void main(String[] args) throws InterruptedException {
ConcurrentStack concurrentStack = new ConcurrentStack();
// 初始化栈为 StackNode4->StackNode3->StackNode2->StackNode1->StackNode0
for (int i = 0; i < 5; i++) {
concurrentStack.push(i);
}
// 开启 popThread, 在 CAS 前 sleep 一段时间, 让另一个线程去修改栈
Thread popThread = new Thread(() -> {
concurrentStack.pop(1000);
});
// 开启 abaThread 先 pop StackNode4 和 StackNode3, 并回收 StackNode4
// 再 push StackNode4, 正常情况下栈应为 4->2->1->0
// 但是 popThread 在休眠后继续执行 CAS 时发现栈头还是 StackNode4, 误以为栈未发生变化
// 因此 popThread 将 headReference 赋值给已经被 pop 的 StackNode3
// 而 StackNode3.next 指向 StackNode2, 最后栈为 3->2->1->0
Thread abaThread = new Thread(() -> {
StackNode.recycle(concurrentStack.pop(0));
concurrentStack.pop(0);
concurrentStack.push(4);
});
popThread.start();
Thread.sleep(500);
abaThread.start();
popThread.join();
// 运行完, 查看栈的结果
StackNode s;
System.out.print("当前栈为: ");
while ((s = concurrentStack.pop(0)) != null) {
System.out.print(s.value + " -> ");
}
}
}
针对这个问题,并发包中自然也提供了解决方案,那就是AtomicStampedReference,该类通过stamp记录原子类当前的版本,每次修改都会更新版本。
4.3 ThreadLocal
ThreadLocal也被称为线程本地变量,它为各个线程都存储了一个变量。每个线程调用ThreadLocal.set(value)或ThreadLocal.get()时操作的都是当前线程对应的变量,因此ThreadLocal是线程安全的。
4.3.1 基本使用
Java提供了一个例子,通过ThreadLocal为每个线程设置一个ID,代码如下所示。
public class ThreadId {
// 通过原子变量为线程设置ID
private static final AtomicInteger nextId = new AtomicInteger(0);
// 重写ThreadLocal的initialValue()方法, 用于初始化各线程对应的变量
private static final ThreadLocal<Integer> threadId = new ThreadLocal<Integer>() {
@Override
protected Integer initialValue() {
return nextId.getAndIncrement();
}
};
// Returns the current thread's unique ID, assigning it if necessary
public static int get() {
return threadId.get();
}
}
在新建ThreadLocal时重写了它的initialValue()方法,该方法的作用是,如果某个线程调用ThreadLocal.get()时发现值为null,就会调用initialValue()初始化该线程对应的变量。
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
ThreadLocal还提供了一个静态的构造方法withInitial(Supplier supplier),也用于为ThreadLocal的每个线程设置初始值。
ThreadLocal<Integer> threadId = ThreadLocal.withInitial(new Supplier<Integer>() {
@Override
public Integer get() {
return nextId.getAndIncrement();
}
});
ThreadLocal.withInitial(...)返回的是SuppliedThreadLocal对象,它继承了ThreadLocal并重写了initialValue()方法,其实与第一种初始化方法没什么区别。
static final class SuppliedThreadLocal<T> extends ThreadLocal<T> {
private final Supplier<? extends T> supplier;
SuppliedThreadLocal(Supplier<? extends T> supplier) {
this.supplier = Objects.requireNonNull(supplier);
}
@Override
protected T initialValue() {
return supplier.get();
}
}
4.3.2 ThreadLocal实现原理
在ThreadLocal中,线程和数据是一对一的关系,这种对应关系很容易让我们联想到Map。直观上来看,似乎是ThreadLocal中维护了一个Key为线程,Value为数据的Map。这样当然也能实现ThreadLocal,不过在这种实现下,ThreadLocal成为了线程数据的持有者,并且持有Thread的引用,这种实现很容易造成内存泄漏。
而在Java的实现中,Thread才是数据的持有者,ThreadLocal是线程本地变量的管理者。Thread中持有一个ThreadLocalMap类型的Map用于保存该线程的本地变量。
public class Thread {
......
ThreadLocal.ThreadLocalMap threadLocals = null;
......
}
ThreadLocalMap是ThreadLocal的内部类,它是一个专门设计出来,用于维护线程本地变量的Map,它的Key为ThreadLocal的弱引用,Value则是数据。问题在于,为什么要专门实现一个Map来维护线程本地变量,难道原生的HashMap不满足需求吗?下面让我们带着问题去分析ThreadLocalMap的源码。
①. 成员变量和构造方法
ThreadLocalMap通过Entry[] table保存所有的实体。实体Entry继承自ThreadLocal的弱引用,Entry中的value保存当前线程与ThreadLocal关联的变量。我们知道,当一个对象只有弱引用指向它时,它就会被GC回收。因此ThreadLocal本身不会内存泄漏。
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
private static final int INITIAL_CAPACITY = 16; // 初始容量, 容量必须是2的倍数
private Entry[] table; // Hash表
private int size = 0; // Hash表当前Entry的数量
private int threshold; // size达到这个数量时扩容
// 根据容量计算下一个索引
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
// 根据容量计算上一个索引
private static int prevIndex(int i, int len) {
return ((i - 1 >= 0) ? i - 1 : len - 1);
}
// ThreadLocalMap是懒加载的,只有当线程需要保存本地变量时
// 才会新建ThreadLocalMap并在构造方法传入第一个变量的key和value。
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
......
}
②. 保存数据
ThreadLocl.set(value)方法如下,首先获取当前线程的ThreadLocalMap,如果存在直接调用ThreadLocalMap的set(key, value)方法,如果不存在就新建。
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
下面来看ThreadLocalMap是如何保存数据的,它使用线性探测法解决Hash冲突。保存Entry时先计算key的hash值,再通过index = hash & (len - 1)得到Entry应保存的位置。如果table[index]为空则在该位置保存Entry,如果不为空说明出现hash冲突,对index向后顺移直到table[index+n] (n=1,2,3...)为空。使用线性探测法时,如果Hash冲突较多,它的效率会大幅下降。

ThreadLocalMap的set(ThreadLocal key, Object value)方法如下,该方法描述了使用线性探测法时添加数据的整体逻辑。
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
// 从位置i开始向后遍历, 直到table[i]为空
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
// 当前key已经存在, 则保存新的value即可
if (k == key) {
e.value = value;
return;
}
// key为null说明ThreadLocal已经被GC回收了
// 需要用新的数据替代之前已经过期的
if (k == null) {
// replaceStaleEntry()方法做了大量的工作, 下面会详细分析
replaceStaleEntry(key, value, i);
return;
}
}
// 遍历到table[i]为空也没有发现相同的key或过期的key
// 因此需要新建一个Entry放置在当前位置
tab[i] = new Entry(key, value);
int sz = ++size;
// 如果数量达到了threshold则进行扩容并重新hash
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
接着来看replaceStaleEntry(key, value, staleSlot)方法,该方法用于将要插入的数据放到合适的位置,并清除Hash表中过期的key和value。
private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
// 向前遍历, 找到最前面的Entry不为空但是key被回收的位置
int slotToExpunge = staleSlot;
for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len))
if (e.get() == null)
slotToExpunge = i;
// 从staleSlot下一个位置开始向后遍历
for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// 如果找到了与当前key相同的Entry
// 需要将其与staleSlot位置上的Entry对换, 这样能保证Hash表的顺序
if (k == key) {
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
// slotToExpunge == staleSlot表示向前遍历时没有找到过期的key
if (slotToExpunge == staleSlot)
slotToExpunge = i;
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
// slotToExpunge == staleSlot表示向前遍历时没有找到过期的key
// 这里找到的是staleSlot后的第1个过期的位置, 将其赋值给slotToExpunge
// staleSlot位置本身不用清除, 因为要在该位置上放置新插入的数据
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
// 如果当前要插入的key不存在, 那么新建一个Entry放到staleSlot位置上
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
// slotToExpunge != staleSlot表示有过期的key, 需要将它们清除
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
这里通过一个例子来分析replaceStaleEntry(key, value, staleSlot)方法的运行过程,为了便于分析,假设使用index = key % 10来计算数据存放的位置。初始时情况如下图,假设当前调用ThreadLocalMap.set(key, value)方法插入一个key为13的数据,该数据的index应为3,发现该位置上的key已经过时,则调用replaceStaleEntry(key, value, staleSlot)方法。
首先向前遍历,找到最前面的Entry不为空但是key已经过时的位置,示例中就是index为1的位置,因此slotToExpunge为1。
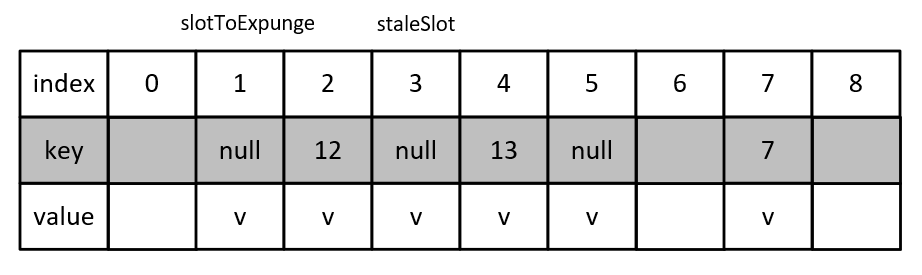
随后向后遍历,尝试寻找key与13相等的位置,发现table[4]符合条件,随后将table[4]与staleSlot位置的数据table[3]交换,得到结果如下。
这里交换的意义在于维持线性探测法的特性,如果不交换的话,table[3]上的数据之后会被清除,就不满足线性探测法的规律了。因为之后查找key为13的数据的话,定位到table[3]会发现为空,而实际上key为13的数据在table[4]上。

如果在replaceStaleEntry(key, value, staleSlot)方法中找不到key与要插入数据相等的位置,就在staleSlot位置存放要插入的数据。将数据存放到合适的位置后,最后调用expungeStaleEntry(slotToExpunge)将Hash表中过期的数据清除。
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// 清除staleSlot位置上的数据
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
// 向后遍历, 对各个位置上的数据重新hash, 直到Entry为null
Entry e;
int i;
for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
③. 获取数据
ThreadLocal获取数据的逻辑比较简单,直接调用了ThreadLocalMap的getEntry(key)方法。
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
如果直接key直接命中第一个数据,那么直接返回,否则调用getEntryAfterMiss()方法。方法内遵循线性探测法去寻找对应的Entry,在发现过时的数据时调用expungeStaleEntry()方法进行清理,直到找到对应key的Entry或遍历到空数据。
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
ThreadLocal<?> k = e.get();
if (k == key)
return e;
if (k == null)
expungeStaleEntry(i);
else
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
4.3.3 预防ThreadLocal内存泄漏
ThreadLocalMap内部使用弱引用指向ThreadLocal,当ThreadLocal被回收时,map中对应的数据过时,Entry和value会残留在map中造成内存泄露。虽然在ThreadLocalMap下一次添加或删除数据时就可能被清理,但也可能一直留在map中。
因此当线程不需要某个ThreadLocal时需要手动调用一下ThreadLocal.remove()方法,该方法最终会调用ThreadLocalMap的remove(ThreadLocal key)方法去清理对应的Entry。
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
expungeStaleEntry(i);
return;
}
}
}
五、并发容器
由于ArrayList、HashMap等容器不支持并发,早期JDK提供了Vector、Hashtable等一系列同步容器,它们实现的方法是对所有公有方法进行同步,使得同一时刻只有一个线程能访问容器的状态。通过Collections.synchronizedXxx()方法,可以创建各个基础容器的同步容器。
即使Vector这样的容器对所有方法都进行了同步,但它还是不安全的,这种情况出现在对容器进行复合操作时。以下面的程序为例,假设A线程执行getLast()方法,在step1处挂起,随后B线程执行完了整个deleteLast()方法,A线程继续执行时size的值已经过时了,再执行vector.get(size - 1)就会出错。
public Object getLast(Vector vector) {
int size = vector.size();
// step1
return vector.get(size - 1);
}
public void deleteLast(Vector vector) {
int size = vector.size();
vector.remove(size - 1);
}
这种“先判断后执行”的操作称为竞态条件,再以Hashtable为例,如果有2个线程执行如下putIfNotExist(Object key, Object value)方法,可能会导致覆盖插入。要想解决这个问题,需要将整个复合操作进行同步。
public void putIfNotExist(Object key, Object value) {
if (!hashtable.contains(key)) {
hashtable.put(key, value);
}
}
由于同步容器的效率不高且具备竞态条件这样的隐患,Java推出了并发容器来改进同步容器的性能,不同的并发容器对应不同的场景,并且ConcurrentHashMap这样的并发容器还封装了常见的复合操作。
5.1 CopyOnWriteArrayList
当通过Iterator对容器进行迭代时,如果有别的线程修改了容器,那么正在迭代的线程会抛出ConcurrentModificationException,这是一种“及时失败”的机制,用于通知用户该处代码存在隐患,想要避免该异常,需要在迭代过程中加锁。但是如果容器数量很大或者每个元素的操作时间很长,那么其余线程就会等待很久。一种解决方案是在容器发生修改时克隆该容器,并在副本上进行写操作,期间的迭代操作都在原容器上进行。
上述方法被称为写时拷贝CopyOnWrite(COW),CopyOnWriteArrayList中通过变量array保存实际的数组,当容器即将发生变化(add, remove…)时克隆当前容器,并在副本上进行增删操作,操作之后再将结果赋值给array,以add(E e)方法为例,相关代码如下所示。
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
private transient volatile Object[] array;
final void setArray(Object[] a) {
array = a;
}
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
......
}
当对CopyOnWriteArrayList迭代时,通过iterator()方法新建迭代器,该迭代器遍历的是当前array的快照。迭代器中已经保存了引用,即使别的线程通过setArray(newElements)方法修改了array的引用也不会出现异常。
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
public Iterator<E> iterator() {
return new COWIterator<E>(getArray(), 0);
}
static final class COWIterator<E> implements ListIterator<E> {
/** Snapshot of the array */
private final Object[] snapshot;
/** Index of element to be returned by subsequent call to next. */
private int cursor;
private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
snapshot = elements;
}
......
}
......
}
根据CopyOnWriteArrayList的实现,可以发现该容器具有“弱一致性”,因为迭代时容器的内容可能会发生变化,如果一个场景能容忍短暂的数据不一致性,才适合使用该容器。例如通过CopyOnWriteArrayList保存监听器,该场景对时效性的要求不高,而且遍历监听器并执行是一个非常耗时的操作。
5.2 ConcurrentHashMap
ConcurrentHashMap与HashMap一样是一个基于散列的Map,JDK1.8中它采用CAS+Node锁的同步方式来提供更高的并发性与伸缩性。ConcurrentHashMap的使用方法与HashMap相同,并且封装了一些常见的复合操作,如下所示。
// 当前key没有对应值时插入
public V putIfAbsent(K key, V value)
// 仅当key对应的值为value时才移除
public boolean remove(Object key, Object value)
// 仅当key对应的值为oldValue时才替换为newValue
public boolean replace(K key, V oldValue, V newValue)
// 仅当key对应到某个值时才替换为value
public V replace(K key, V value)
ConcurrentHashMap中的检索操作一般不阻塞,因此可能与更新操作重叠,检索操作反映的是最近的更新操作完成的结果,换句话说,更新操作对检索操作来说是可见的(happen-before)。以get()方法为例,代码中并没有进行同步的地方,这是因为Node节点中的val和next字段都是volatile修饰的,因此一个线程的更新操作是对其他线程可见的。
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
......
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode()); // 得到hash值
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
// 槽中的首节点就是要寻找的节点
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// hash < 0表示正在扩容
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
......
}
}
ConcurrentHashMap中的更新操作是通过CAS+Node锁的方式进行同步的,以putVal(K key, V value, boolean onlyIfAbsent)方法为例,其主体逻辑如下。
① 判断table是否已经初始化,如果没有则调用initTable()方法
② 如果当前槽为空,则调用casTabAt(...)插入数据
③ 如果当前正在扩容,当前线程也去参与扩容(ConcurrentHashMap支持并发扩容)
④ 根据当前是链表还是树插入对应节点
可以发现putVal(...)方法的主体逻辑是位于一个循环中的,这是一种CAS+自旋的思路。假设2个线程同时执行到第②步,成功的线程会退出循环,失败的线程会开始自旋直到插入成功或失败。
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0) // 如果table为空则进行初始化
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 当前槽为空,通过cas插入节点,成功则退出循环
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 有hash值为MOVED的节点表示正在扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) { // 当前槽上是链表
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value, null);
break;
}
}
}
else if (f instanceof TreeBin) { // 当前槽上是树节点
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
扩容Hash表是一个相对缓慢的操作,最好在新建时提供一个预估的大小initialCapacity来构造。
六、线程生命周期
Java中线程的生命周期与操作系统的有所不同,在操作系统中,线程只有在真正获取到CPU使用权时才属于运行状态,如果一个线程可以执行但是没获取到CPU,它则属于就绪状态。而在Java中,如果一个线程在广义上能够运行,它就是运行状态。
Java将线程分为以下6种状态:
-
NEW(初始化状态):新建了一个线程对象,但是还没有调用线程的
start()方法,此时线程只存在于JVM,在操作系统中它还没有被创建。 -
RUNNABLE(运行状态):Java线程的RUNNABLE状态表达的含义比较宽泛,它对应操作系统中线程的就绪状态、运行状态以及部分休眠状态。
当线程在抢占CPU的使用权时,其对应操作系统中的就绪状态;当线程调用操作系统层面的阻塞式API时(例如I/O),其对应操作系统中的休眠状态。在Java中,这些状态统称为RUNNABLE,JVM并不关心线程是否真的在运行,只要当前线程不在等待锁,也没有被其他线程阻塞,那么它就是运行状态。 -
BLOCKED(阻塞状态):当线程正在等待进入synchronized代码块时,该线程会从RUNNABLE状态变为BLOCKED状态;当抢占到锁时,再从BLOCKED状态转换到RUNNABLE状态。
-
WAITING(无时限等待):当获得锁的线程主动调用
Object.wait()时,线程会从RUNNABLE状态进入WAITING状态直到被唤醒。还有一种情况是线程调用LockSupport.park()从RUNNABLE状态进入WAITING状态,并发包中的Lock就是依赖LockSupport实现的,如果要将线程恢复到RUNNABLE状态,则需调用LockSupport.unpark(Thread thread)方法。 -
TIMED_WAITING(有时限等待):TIMED_WAITING状态与WAITING状态唯一的区别是,线程调用方法进入该状态时多了时间参数。例如
Thread.sleep(long millis),Object.wait(long timeout),LockSupport.parkNanos(Object blocker, long deadline)等方法。 -
TERMINATED(终止状态):线程的
run()方法执行完后,或者出现未捕获的异常就会进入TERMINATED状态。如果想要主动终止一个线程,可以调用Thread.interrupt()方法通知线程停止,其他类似Thread.stop()这样的方法因为安全性问题已经被弃用了。
如何正确地停止线程?
上面提到通过Thread.interrupt()方法通知线程结束运行,该方法并不会强行停止线程,它只是为线程添加了一个标志位表示该线程应该结束了。为什么这么做呢?因为我们更希望线程收到通知后进行收尾工作再停止(例如释放Lock),这样可以保证共享资源状态的一致性,更加安全,而不是像已被弃用的Thread.stop()方法那样强制停止线程。
下面来看如何处理中断异常(InterruptedException)和停止线程,当对线程调用Thread.interrupt()方法后,RUNNABLE状态下的线程可以通过Thread.currentThread().isInterrupted()检查自己的中断标志位,如果发现自己被中断,则进行退出工作。但是如果线程处于WAITING状态,那么当前线程会抛出异常并清除中断标志位,以下方法可以响应中断并抛出中断异常。
Object.wait() / Object.wait(long) / Object.wait(long,int)
Thread.sleep(long) / Thread.sleep(long,int)
Thread.join() / Thread.join(long) / Thread.join(long,int)
java.util.concurrent.BlockingQueue.take() / put(E)
java.util.concurrent.locks.Lock.lockInterruptibly()
java.util.concurrent.CountDownLatch.await()
java.util.concurrent.CyclicBarrier.await()
java.util.concurrent.Rxchanger.exchange(V)
java.nio.channels.InterruptibleChannel相关方法
java.nio.channels.Selector的相关方法
对于RUNNABLE状态下的线程,可以在循环中检查自己的状态,发现被中断后进行收尾工作。
Thread thread = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {
// 业务逻辑
}
// 收尾工作
});
如果线程处于WAITING状态并响应了中断异常,在方法内的话一般选择抛出,让上层处理;如果必须处理的话,则需要重置线程的中断标志,以便让线程正常退出,如下所示。
Thread thread = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {
// 业务逻辑
try {
Thread.sleep(500);
} catch (InterruptedException e) {
// 捕获中断异常会清除中断标志, 需要重新设置
Thread.currentThread().interrupt();
// 收尾工作...
}
}
});
七、死锁
7.1 死锁的产生条件
死锁是指两个线程都需要多个资源,但是每个线程只占有了其中一部分并请求另外的资源,此时就会产生循环等待,导致两个线程都无法运行。在《操作系统》这门课中,归纳了4个产生死锁的必要条件:
① 资源互斥:共享资源在同一时刻只能被一个线程占有。
② 占有资源并等待:占有资源的线程不会释放,并请求其余资源。
③ 不可抢占:线程无法抢夺其余线程占有的资源。
④ 循环等待:每个线程都在等待其余线程占有的资源。
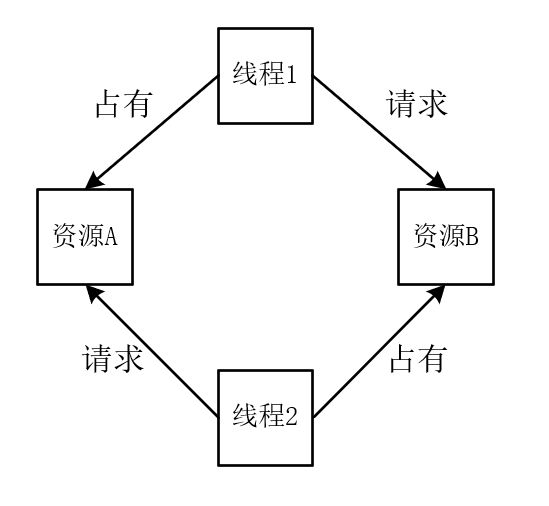
7.2 死锁的解决方式
7.2.1 使用Lock
使用synchronized关键字进行同步时,线程占有资源后不会释放,如果在申请其他资源时阻塞,就有出现死锁的风险。而使用Lock.tryLock()方法,线程尝试获取资源失败时会直接返回false,开发人员可以使线程释放之前占有的资源。也可以使用Lock.tryLock(long time, TimeUnit unit)方法,让线程尝试在指定时间内获取某个资源,如果失败则返回false,开发人员可以根据返回值进一步处理。
7.2.2 统一资源获取顺序
出现死锁的代码,一定是两个线程循环等待,这是因为两个线程获取资源的顺序不一样,如下所示。线程t1先尝试获取a资源,再尝试获取b资源;而线程t2先尝试获取b资源,再尝试获取a资源,这就有死锁的风险。如果这两个线程获取资源的顺序相等,就不可能发生死锁了。
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
synchronized (a) {
......
synchronized (b) {
......
}
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
synchronized (b) {
......
synchronized (a) {
......
}
}
}
});
八、线程池
线程池遵循典型的"生产者-消费者"模型,生产者是线程池的使用者,消费者是线程池本身。提到"生产者-消费者"模型,我们很容易联想到阻塞队列,实际上线程池就是依赖阻塞队列实现的。在线程池中,生产者提交的任务会被添加到阻塞队列中,如果阻塞队列已满,则生产者阻塞;消费者会不断从阻塞队列中取出任务执行,如果阻塞队列为空,则消费者阻塞。
利用3.2.1中实现的BlockQueue可以实现一个简单的线程池,代码如下所示。在测试时,新建了一个具有5个工作线程的线程池,运行后发现各任务执行的顺序是不确定的,因此线程池一般不用于执行一系列耦合的任务。不过如果将工作线程数量设为1个的话,任务的执行顺序就是确定的,当需要执行一连串耦合的任务时,可以新建只有1个工作线程的线程池进行处理。
public class SampleTreadPool {
private BlockingQueue<Runnable> mRunnableQueue;
private List<Worker> mWorkers = new ArrayList<>();
public SampleTreadPool(int threadSize, BlockingQueue<Runnable> queue) {
mRunnableQueue = queue;
for (int i = 0; i < threadSize; i++) {
Worker worker = new Worker();
worker.start();
mWorkers.add(worker);
}
}
public void execute(Runnable r) {
mRunnableQueue.offer(r);
}
private class Worker extends Thread {
@Override
public void run() {
while (true) {
Runnable r = mRunnableQueue.take();
r.run();
}
}
}
// 测试
public static void main(String[] args) {
BlockingQueue<Runnable> blockingQueue = new BlockingQueue<>(20);
SampleTreadPool treadPool = new SampleTreadPool(5, blockingQueue);
for (int i = 0; i < 50; i++) {
int t = i;
treadPool.execute(() -> {
System.out.println("execute: " + t);
});
}
}
}
上述线程池显然无法投入实际使用,因为它存在很多问题:
① 在阻塞队列已满的情况下提交任务,该线程池会阻塞主线程。虽然可以使用无界的阻塞队列,但是当任务数量过多时,可能会造成OOM。
② 该线程池中工作线程的数量是固定的,我们希望能设置工作线程数量的最大值和最小值,让它能够随系统的运行情况灵活地增加或减少。
③ 当线程运行出现异常时,线程池没有容错机制。
④ 该线程池只能提交Runnable这种无返回值的任务,无法处理Future这类有返回值的任务。
8.1 Java线程池的使用
Java线程池中最核心的实现是ThreadPoolExecutor,它定义了线程池的5种状态如下。
- RUNNING: 线程池正在运行,接受新任务并处理已经提交的任务。
- SHUTDOWN: 线程池即将停止,此时不接受新任务,但是会处理已经提交的任务。调用线程池的
shutdown()方法会使其状态从RUNNING变为SHUTDOWN。 - STOP: 线程池即将停止,此时不接受新任务,也不处理已经提交的任务,并会中断正在处理的任务。调用线程池的
shutdownNow()方法会使其状态从(RUNNING/SHUTDOWN)变为STOP。 - TIDYING: 线程池已经停止运行,工作线程为0,此时会执行用户重载的
terminated()函数。 - TERMINATED:
terminated()函数运行完毕,线程池彻底停止。
8.1.1 新建线程池
下面来看如何新建一个线程池,ThreadPoolExecutor中重载了4个构造函数,最完整的构造函数有7个参数,如下所示。
/**
* @param corePoolSize: 核心线程数量,指线程池中最少的线程数量,即使这些线程空闲
* 但如果设置了 allowCoreThreadTimeOut, 核心线程也可以回收
* @param maximumPoolSize: 线程池中允许存在的最大线程数
* @param keepAliveTime: 当前线程数量大于核心线程数量时
* 如果等待该时间后仍然没有新任务, 则回收空闲线程
* @param unit: keepAliveTime参数的单位
* @param workQueue: 任务队列, 这是一个阻塞队列
* 用于保存用户提交但尚未执行的 Runnable
* @param threadFactory: 线程池新建线程时使用的 ThreadFactory
* @param handler: 任务拒绝策略, 用于在线程数量和任务队列都已满时拒绝新任务
* 线程池提供了以下四种策略:
* CallerRunsPolicy: 提交任务的线程自己执行
* AbortPolicy: 默认策略, 抛出RejectedExecutionException
* DiscardPolicy: 静默丢弃任务
* DiscardOldestPolicy: 丢弃任务队列中最老的任务并添加新任务
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
......
}
为了避免OOM,在新建线程池时,强烈建议指定线程池的maximumPoolSize,否则在任务繁忙时会出现线程数暴增的情况;同时也建议使用有界的阻塞队列,不然阻塞队列的无限制增长也会增加OOM的风险。
8.1.2 提交任务
ExecutorService接口中定义了线程池提交任务的方法,如下所示。
// 提交一个Runnable, 该任务无返回值, 也无法查询它的运行情况
void execute(Runnable command);
// 提交一个Callable, 该任务有返回值, 并且可以查询它的运行情况
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
// 提交一个Runnable任务,可以通过返回的Future查询其运行情况,返回null时表示运行完毕
Future<?> submit(Runnable task);
// 执行给定的任务, 当所有任务完成(或超时), 返回一个保存其状态和结果的Future列表
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks);
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit);
// 执行给定的任务,当任一任务完成(或超时), 返回对应结果, 其余任务会被取消
<T> T invokeAny(Collection<? extends Callable<T>> tasks);
<T> T invokeAny(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit);
需要注意的是,如果调用Future.get()方法,调用线程会被阻塞,直到Future任务返回结果,因此可以选择Future.get(long timeout, TimeUnit unit)设置最大等待时间,也可以在获取结果前先调用Future.isDone()查询其运行情况。
8.1.3 关闭线程池
在介绍线程池的状态时我们提到了shutdown()和shutdownNow()这两个方法,这两个方法都用于关闭线程池,不过处理上有所不同:shutdown()方法会让线程池不再接受新的任务,但是会继续处理已经开始运行的任务;而shutdownNow()方法不仅会让线程池不再接受新的任务,也会去中断当前正在执行任务的线程。
关闭线程池可以使用如下的两段式关闭法,调用shutdown()后等待尚未完成的任务继续运行一段时间,如果等待后还没运行完,则调用shutdownNow()中断这些线程。
这里用到了awaitTermination()方法,它会阻塞一段时间,直到线程池中的任务全部运行完或者等待超时,如果线程池的所有任务运行完则返回true,否则返回false。需要注意的是,该方法会阻塞调用线程。
void shutdownAndAwaitTermination(ExecutorService pool) {
// 拒绝新任务的提交
pool.shutdown();
try {
// 等待一段时间, 让当前任务继续执行
if (!pool.awaitTermination(60, TimeUnit.SECONDS)) {
// 尝试中断正在运行的线程
pool.shutdownNow();
// 等待一段时间, 让尚未结束任务的线程响应中断
if (!pool.awaitTermination(60, TimeUnit.SECONDS))
System.err.println("Pool did not terminate");
}
} catch (InterruptedException ie) {
// 如果当前线程被中断了, 再次尝试关闭线程池
pool.shutdownNow();
// 重新设置中断标志位
Thread.currentThread().interrupt();
}
}
8.2 如何确定线程池的参数
新建ThreadPoolExecutor时需要传入多个参数,包括核心线程数、最大线程数、空闲线程保留时间以及阻塞队列等,实际开发中应该根据具体的业务类型来确定这一系列的参数。
在项目中并不建议将所有的任务都放到一个线程池中去执行,可以根据任务场景新建CPU线程池、IO线程池等,CPU线程池的大小可以固定为(CPU核心数+1),而IO线程池的大小可以预设为(2 * CPU核心数+1),之后再根据IO的吞吐量进行调整。美团的技术博客Java线程池实现原理及其在美团业务中的实践介绍了动态修改线程池参数的实现,可以根据线程池的运行情况不断调整参数,保证系统的吞吐量。
参考
- 并发编程实战
- 维基百科-CAS