Spark:离线综合案例
分布式计算平台Spark:离线综合案例
一、课程回顾
-
SparkSQL使用
-
开发接口
- DSL:使用函数来对表进行处理,类似于RDD的编程,表的体现:DF、DS
- SQL语法函数:select、where、groupBy、orderBy、limit、agg
- RDD的函数:map/filter/flatMap
- SQL:使用SQL语句来实现对表的处理,类似于Hive的编程,表的体现:DF/DS注册成视图、Hive表
- step1:将数据集注册为视图
- step2:通过SQL语句进行处理
- DSL:使用函数来对表进行处理,类似于RDD的编程,表的体现:DF、DS
-
UDF函数
-
DSL
val funName = udf(函数体) -
SQL
spark.udf.register(函数名,函数体)
-
-
SparkSQL中数据源
-
read
spark.read.format("类型").load =》 DataFrameReader- parquet
- json
- textfile
- csv
- jdbc
-
write
ds/df.write.mode(SaveMode).format("类型").option.save- csv
- jdbc
-
SaveMode:保存模式

- ErrorIfExists:如果存在就抛出异常,默认的模式
- Append:追加模式
- Overwrite:覆盖模式
- Ignore:忽略本次请求
-
-
SparkSQL使用方式
- 在IDEA中开发,打成jar包运行:类似于SparkCore开发
- 工作中比较常用的方式
- 通过spark-sql来运行SQL文件
- 一般用于调度系统,常用的方式
- 使用Spark-SQL的命令行来测试SQL语句的运行
- 一般用于测试开发阶段,用的比较少
- 使用SparkSQL的服务端ThriftServer,通过beeline连接
- 一般用于测试开发
- 使用JDBC连接ThriftServer
- 封装计算接口
- 在IDEA中开发,打成jar包运行:类似于SparkCore开发
-
-
问题
-
rdd的血脉信息保存在哪里
-
RDD分区源码有点看不懂,课堂如果时间充裕的话,老师可以再带我们看看源码吗
-
今天将的hiveserver2与ThriftServer端口都是10000,是否会有冲突问题,使用时将服务端分开在两台设备避免端口冲突问题
-
- HiveServer2:启动在第三台:10000 、 10001
- 创建或者修改元数据的操作:create、drop、alter
- ThriftServer:启动在第一台:10000
- 查询统计类的操作:select
- 补充一点:SparkSQL 与 Hive on Spark的区别
- SparkSQL =》 解析SQL =》 SparkCore
- SparkSQL负责解析
- SparkSQL =》 解析SQL =》 SparkCore
- HiveServer2:启动在第三台:10000 、 10001
-
HiveSQL =》 解析SQL =》 MapReduce/Tez/Spark
- Hive负责解析
-
val Array(userId,itemId,rating,timestamp) = line.trim.split("\s+")这句代码有些不太明白 是定义了一个匿名常量,类型为Array,对Array内的数据赋值操作吗?
val Array(userId,itemId,rating,timestamp) = line.trim.split("\\s+") val Array(userId,itemId,_,_) = line.trim.split("\\s+")
-
二、课程目标
-
离线综合练习
- 熟悉SparkCore和SparkSQL的代码开发
- 熟悉实际业务需求中一些规范和细节
-
Streaming流式计算方式
-
实时数据流采集:Flume
-
实时数据存储:Kafka
-
实时数据计算:Streaming
-
实时结果保存:Redis
-
三、离线综合练习需求
1、广告业务需求
- 目标:基于广告的投放效果做分析
- 分析1:统计每个地区用户浏览广告的次数
- 分析2:统计广告投放效果的各个指标和转换率
2、数据内容
-
数据来源:来自于广告投放信息数据和用户访问数据
-
数据内容:整合为一个json数据
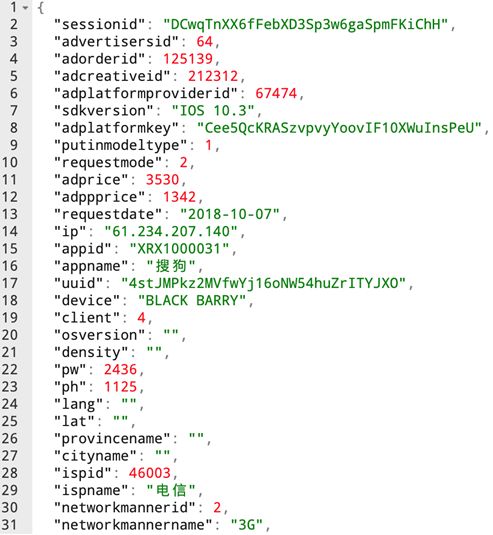
- ip:通过ip来解析得到用户所在的省份和城市
-
实现的设计
-
step1:ETL
- 补全地域字段:省份、城市
- 通过IP解析得到
- 将ETL的结果写入Hive表
- 分区表:写入对应的分区,基于T+1做数据的处理和分析
- 补全地域字段:省份、城市
-
step2:基于ETL的结果来实现分析:SQL、DSL
-
读Hive分区表的数据:昨天的数据
-
分析1:统计每个地区用户浏览广告的次数
-
分析2:统计广告投放效果的各个指标和转换率
-
-
四、环境准备
1、应用服务
-
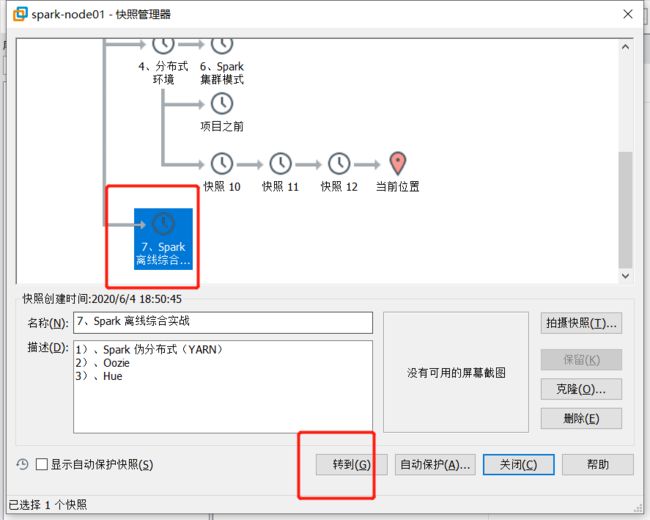
先将三台机器拍个快照
-
将第一台机器恢复快照至:《7、Spark 离线综合实战》
-
启动所有相关服务
# Start HDFS hadoop-daemon.sh start namenode hadoop-daemon.sh start datanode # Start YARN yarn-daemon.sh start resourcemanager yarn-daemon.sh start nodemanager # Start MRHistoryServer mr-jobhistory-daemon.sh start historyserver # Start Spark HistoryServer /export/server/spark/sbin/start-history-server.sh # Start Hue hue-daemon.sh start # Start HiveMetaStore 和 HiveServer2 hive-daemon.sh metastore # Start Spark JDBC/ODBC ThriftServer /export/server/spark/sbin/start-thriftserver.sh \ --hiveconf hive.server2.thrift.port=10000 \ --hiveconf hive.server2.thrift.bind.host=node1.itcast.cn \ --master local[2] # Start Beeline /export/server/spark/bin/beeline -u jdbc:hive2://node1.itcast.cn:10000 -n root -p 123456
2、开发环境
-
新建一个模块,引入Maven依赖《参考附录一》

-
创建包结构
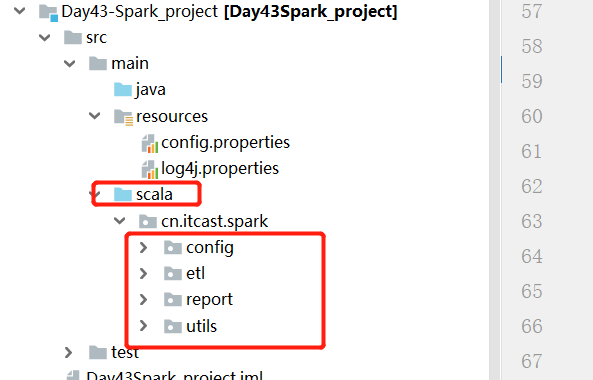
- config:放配置文件的解析工具类
- etl:放ETL的代码
- report:放数据分析的代码
- utils:工具类
- 日期工具类
- IP解析工具类
- ……
3、配置管理工具类
-
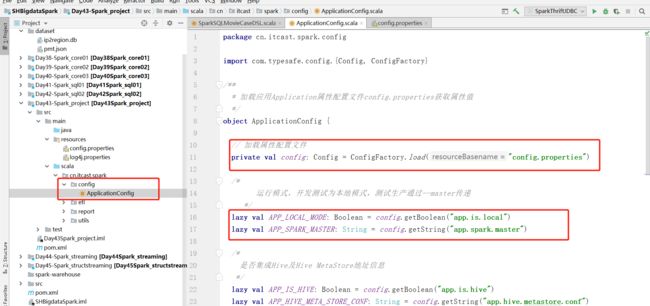
需求:将所有属性的配置放入配置文件
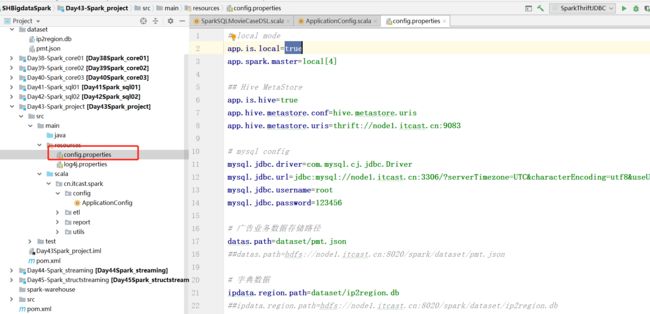
-
解析工具类:解析配置文件获取属性的值
4、SparkSession工具类
-
需求:针对于本地模式和集群模式、是否集成Hive,不同的情况,来创建SparkSession
package cn.itcast.spark.utils import cn.itcast.spark.config.ApplicationConfig import org.apache.spark.internal.Logging import org.apache.spark.sql.SparkSession /** * @ClassName SparkUtils * @Description TODO 提供创建SparkSession的方法 * @Date 2020/12/23 10:55 * @Create By Frank */ object SparkUtils extends Logging{ /** * 用于构建SparkSession对象返回 * @return */ def createSparkSession(clazz:Class[_]):SparkSession = { /** * val spark = SparkSession.builder() * .appName(this.getClass.getSimpleName.stripSuffix("$")) * .master("local[2]") * .getOrCreate() * * 问题1:以后这个代码可能放到Linux集群运行,所以不一定是本地模式 * 问题2:有时候需要集成Hive */ //step1:先构建一个建造者 val builder = SparkSession.builder() //设置程序的名称为调用的类的类名 .appName(clazz.getSimpleName.stripSuffix("$")) //step2:先判断是否是本地模式 if(ApplicationConfig.APP_LOCAL_MODE){ //设置本地master builder.master(ApplicationConfig.APP_SPARK_MASTER)、 //打印INfo级别的日志 logInfo("已开启本地模式") } //step3:判断是否需要集成Hive if(ApplicationConfig.APP_IS_HIVE){ //配置Hive的属性 builder //Metastore服务的地址 .config(ApplicationConfig.APP_HIVE_META_STORE_CONF,ApplicationConfig.APP_HIVE_META_STORE_URLS) //启用Hive的支持 .enableHiveSupport() //打印WARN级别的日志 logWarning("已集成Hive") } //step:返回 builder.getOrCreate() } def main(args: Array[String]): Unit = { val session = createSparkSession(this.getClass) print(session) } } -
Logging:Spark中使用的日志记录的工具类,我们可以自己继承这个类来实现日志的记录
- 常用方法
- logInfo(日志内容)
- logWarning(日志内容)
- ……
- 常用方法
五、ETL解析实现
1、需求
- 补全地域字段:省份、城市
- 通过IP解析得到
- 将ETL的结果写入Hive表
- 分区表:写入对应的分区,基于T+1做数据的处理和分析
2、解析IP构建地域
-
测试
package bigdata.itcast.cn.spark.test.ip import cn.itcast.spark.config.ApplicationConfig import org.lionsoul.ip2region.{DataBlock, DbConfig, DbSearcher} /** * @ClassName IpAnalaysisTest * @Description TODO 解析IP测试 * @Date 2020/12/23 11:36 * @Create By Frank */ object IpAnalaysisTest { def main(args: Array[String]): Unit = { //step1:先构建解析类的对象:第一个参数是一个配置对象,第二个参数是解析库文件的位置 val dbSearcher = new DbSearcher(new DbConfig(),ApplicationConfig.IPS_DATA_REGION_PATH) //step2:解析IP val dataBlock: DataBlock = dbSearcher.btreeSearch("223.167.137.230") //step3:输出结果 val Array(_,_,province,city,_) = dataBlock.getRegion.split("\\|") println(province+"\t"+city) } } -
封装工具类
package cn.itcast.spark.utils import cn.itcast.spark.config.ApplicationConfig import cn.itcast.spark.etl.Region import org.lionsoul.ip2region.{DataBlock, DbConfig, DbSearcher} /** * @ClassName IpUtils * @Description TODO 解析IP的工具类 * @Date 2020/12/23 11:48 * @Create By Frank */ object IpUtils { /** * 用于解析IP,返回Region(ip,省份,城市) * @param ip * @return */ def convertIpToRegion(ip:String,dbSearcher: DbSearcher):Region = { //step1:先构建解析类的对象:第一个参数是一个配置对象,第二个参数是解析库文件的位置 // val dbSearcher = new DbSearcher(new DbConfig(),ApplicationConfig.IPS_DATA_REGION_PATH) //step2:解析IP val dataBlock: DataBlock = dbSearcher.btreeSearch(ip) //step3:输出结果 val Array(_,_,province,city,_) = dataBlock.getRegion.split("\\|") //封装region对象 Region(ip,province,city) } }
3、存储Hive分区表
-
设计表
cd /export/server/hive bin/hive
- 创建表
```sql
-- 创建数据库,不存在时创建
DROP DATABASE IF EXISTS itcast_ads;
CREATE DATABASE IF NOT EXISTS itcast_ads;
USE itcast_ads;
-- 设置表的数据snappy压缩
set parquet.compression=snappy ;
-- 创建表,不存在时创建
DROP TABLE IF EXISTS itcast_ads.pmt_ads_info;
CREATE TABLE IF NOT EXISTS itcast_ads.pmt_ads_info(
adcreativeid BIGINT,
adorderid BIGINT,
adpayment DOUBLE,
adplatformkey STRING,
adplatformproviderid BIGINT,
adppprice DOUBLE,
adprice DOUBLE,
adspacetype BIGINT,
adspacetypename STRING,
advertisersid BIGINT,
adxrate DOUBLE,
age STRING,
agentrate DOUBLE,
ah BIGINT,
androidid STRING,
androididmd5 STRING,
androididsha1 STRING,
appid STRING,
appname STRING,
apptype BIGINT,
aw BIGINT,
bidfloor DOUBLE,
bidprice DOUBLE,
callbackdate STRING,
channelid STRING,
cityname STRING,
client BIGINT,
cnywinprice DOUBLE,
cur STRING,
density STRING,
device STRING,
devicetype BIGINT,
district STRING,
email STRING,
idfa STRING,
idfamd5 STRING,
idfasha1 STRING,
imei STRING,
imeimd5 STRING,
imeisha1 STRING,
initbidprice DOUBLE,
ip STRING,
iptype BIGINT,
isbid BIGINT,
isbilling BIGINT,
iseffective BIGINT,
ispid BIGINT,
ispname STRING,
isqualityapp BIGINT,
iswin BIGINT,
keywords STRING,
lang STRING,
lat STRING,
lomarkrate DOUBLE,
mac STRING,
macmd5 STRING,
macsha1 STRING,
mediatype BIGINT,
networkmannerid BIGINT,
networkmannername STRING,
openudid STRING,
openudidmd5 STRING,
openudidsha1 STRING,
osversion STRING,
paymode BIGINT,
ph BIGINT,
processnode BIGINT,
provincename STRING,
putinmodeltype BIGINT,
pw BIGINT,
rate DOUBLE,
realip STRING,
reqdate STRING,
reqhour STRING,
requestdate STRING,
requestmode BIGINT,
rtbcity STRING,
rtbdistrict STRING,
rtbprovince STRING,
rtbstreet STRING,
sdkversion STRING,
sessionid STRING,
sex STRING,
storeurl STRING,
tagid STRING,
tel STRING,
title STRING,
userid STRING,
uuid STRING,
uuidunknow STRING,
winprice DOUBLE,
province STRING,
city STRING
)
PARTITIONED BY (date_str string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat';
-- STORED AS PARQUET ;
4、整体实现
-
解析IP,添加日期字段
/** * 实现ETL,添加省份,城市,日期返回 * @param inputData * @return */ def processData(inputData: DataFrame) = { //从DF中获取SparkSession val session = inputData.sparkSession //step1:解析IP得到,添加省份城市 //先获取数据RDD val dataRdd: RDD[Row] = inputData.rdd val etlRdd: RDD[Row] = dataRdd .mapPartitions(part => { //构建解析IP的对象 val dbSearcher: DbSearcher = new DbSearcher(new DbConfig(),ApplicationConfig.IPS_DATA_REGION_PATH) //对每个分区进行操作 part.map(row => { //对每条数据进行处理,先获取ip val ip: String = row.getAs[String]("ip") //解析IP val region = IpUtils.convertIpToRegion(ip,dbSearcher) //合并:当前的数据row,新增的列:region val newSeq: Seq[Any] = row.toSeq :+ region.province :+ region.city //将集合转换为Row,返回 Row.fromSeq(newSeq) }) }) //得到一个增加了两列的schema val newSchema = inputData.schema .add("province",StringType,true) .add("city",StringType,true) //将新的RDD和新的Schema合并为DataFrame val newDf = session.createDataFrame(etlRdd,newSchema) //给DF添加一个字段:昨天的日期 val etlData = newDf.withColumn("date_str",date_sub(current_date(),1).cast(StringType)) //最后返回一个新的DF[原来的数据+省份+城市+日期] etlData } -
保存为parquet测试
//将数据保存到parquet文件中 def saveToParquetFile(etlData: DataFrame) = { etlData .write .mode(SaveMode.Overwrite) //指定分区字段 .partitionBy("date_str") //指定生成结果的位置 .parquet("datas/output/case") } -
保存到Hive分区表中
//写入Hive表:df.write.partitionBy("key").format("hive").saveAsTable("hive_part_tbl") def saveToHiveTable(etlData: DataFrame) = { etlData .write .mode(SaveMode.Overwrite) .format("hive") .partitionBy("date_str") .saveAsTable("itcast_ads.pmt_ads_info") } -
申明用户
// 设置Spark应用程序运行的用户:root, 默认情况下为当前系统用户 System.setProperty("user.name", "root") System.setProperty("HADOOP_USER_NAME", "root")
5、Spark分布式缓存
-
功能与应用
- 用于将一个小文件存储到每台Worker节点的磁盘中,方便每台Worker中的Task直接使用读取
-
如果遇到以下报错:不用关心
六、需求分析实现
1、业务需求
- 读Hive分区表的数据:昨天的数据
- 分析1:统计每个地区用户浏览广告的次数
- 分析2:统计广告投放效果的各个指标和转换率
2、加载数据
//todo:1-读取
val etlData: DataFrame = spark.read.table("itcast_ads.pmt_ads_info")
//只读取昨天的数据
// .where($"date_str" === date_sub(current_date(),1))
.where($"date_str".equalTo(date_sub(current_date(),1)))
etlData.show()
3、每天各地区的广告访问统计
-
分析
-
结果
日期 省份 城市 次数 2020-12-22 上海 上海 1000 -
SQL
etlData.createOrReplaceTmpView("tmp_view_ads") spark.sql( select date_str, province, city, count(1) as numb from tmp_view_ads group by date_str,province,city order by numb desc limit 10 ) -
DSL
etlData .select(province,city) .groupBy(province,city) .count .withColumn("date_str",昨天的日期)
-
-
MySQL中建表
-- 创建数据库,不存在时创建 -- DROP DATABASE IF EXISTS itcast_ads_report; CREATE DATABASE IF NOT EXISTS itcast_ads_report; USE itcast_ads_report; -- 创建表 DROP TABLE IF EXISTS itcast_ads_report.region_stat_analysis ; CREATE TABLE `itcast_ads_report`.`region_stat_analysis` ( `report_date` varchar(255) NOT NULL, `province` varchar(255) NOT NULL, `city` varchar(255) NOT NULL, `count` bigint DEFAULT NULL, PRIMARY KEY (`report_date`,`province`,`city`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci; -
SQL代码实现
/** * 第一种SQL方式 */ //将数据注册为视图 etlData.createOrReplaceTempView("tmp_view_ads") //运行SQL进行处理 // val rsData = session.sql( // """ // |select // | date_str, // | province, // | city, // | count(1) as numb // |from tmp_view_ads // |group by date_str,province,city // |order by numb desc // |limit 10 // """.stripMargin) -
DSL代码实现
/** * 第二种DSL方式 */ val rsData = etlData //将需要用到的数据先过滤出来 .select($"province",$"city") //对数据进行分组 .groupBy($"province",$"city") //聚合 .count() //添加日期字段 .withColumn("report_date",date_sub(current_date(),1).cast(StringType)) -
保存到MySQL
-
SparkSQL中自带的方式
/** * 结果的保存输出 */ // rsData.printSchema() // rsData.show() // rsData // //降低分区个数 // .coalesce(1) // .write // //问题:如果用Append会导致主键重复,如果用Overwrite,会导致之前的数据被清空 // .mode(SaveMode.Append) // .format("jdbc") // // 设置MySQL数据库相关属性 // .option("driver", ApplicationConfig.MYSQL_JDBC_DRIVER) // .option("url", ApplicationConfig.MYSQL_JDBC_URL) // .option("user", ApplicationConfig.MYSQL_JDBC_USERNAME) // .option("password", ApplicationConfig.MYSQL_JDBC_PASSWORD) // .option("dbtable", "itcast_ads_report.region_stat_analysis") // .save() -
问题:如果用Append会导致主键重复,如果用Overwrite,会导致之前的数据被清空
-
思路:MySQL中提供了两种方式可以实现,如果主键存在就更新,如果不存在就插入
-
方式一:replace
replace into region_stat_analysis values('2020-12-14','上海','上海市',999); -
方式二:DUPLICATE KEY UPDATE
insert into region_stat_analysis values('2020-12-14','上海','上海市',888) ON DUPLICATE KEY UPDATE count=VALUES (count);
-
-
解决:自己开发JDBC写入MySQL
/** * 将每个分区的数据写入MySQL * @param part */ def saveToMySQL(part: Iterator[Row]): Unit = { //申明驱动 Class.forName(ApplicationConfig.MYSQL_JDBC_DRIVER) //构建连接对象 var conn:Connection = null var pstm:PreparedStatement = null //构建实例 try{ conn = DriverManager.getConnection( ApplicationConfig.MYSQL_JDBC_URL, ApplicationConfig.MYSQL_JDBC_USERNAME, config.ApplicationConfig.MYSQL_JDBC_PASSWORD ) //需求:如果主键不存在,就插入,如果主键存在,就更新 val sql = "insert into itcast_ads_report.region_stat_analysis values(?,?,?,?) ON DUPLICATE KEY UPDATE count=VALUES (count);" pstm = conn.prepareStatement(sql) //取出分区的每条数据 part.foreach(row =>{ pstm.setString(1,row.getAs[String]("report_date")) pstm.setString(2,row.getAs[String]("province")) pstm.setString(3,row.getAs[String]("city")) pstm.setLong(4,row.getAs[Long]("count")) //放入batch中 pstm.addBatch() }) //对整个批量操作 pstm.executeBatch() }catch { case e:Exception => e.printStackTrace() }finally { if(pstm != null) pstm.close if(conn != null) conn.close } }
-
4、每天各地区的广告指标
-
分析
-
需求:统计基于不同维度下的广告指标
-
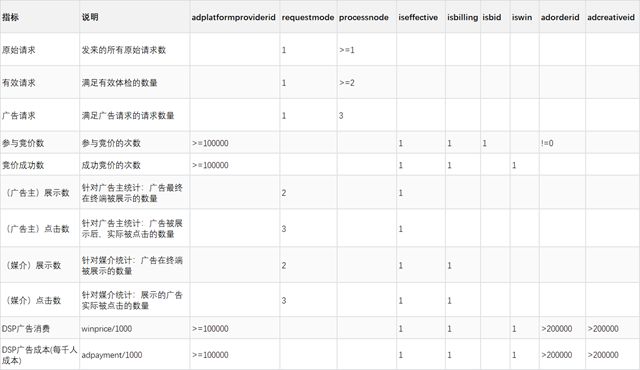
广告指标

-
问题1:要想得到比例,先统计得到对应分子和分母对应的指标
- 分母不能为0
-
问题2:怎么得到其他的基本指标
-
怎么计算原始请求数
- step1:先判断当前这条数据的请求是否是一个原始请求
- ·条件:requestmode = 1 and processnode >= 1
- step2:总的原始请求数
- 外层做聚合
- step1:先判断当前这条数据的请求是否是一个原始请求
-
如果用SQL语句应该怎么写?
select province, city, sum(case when requestmode = 1 and processnode >= 1 then 1 else 0 end) as 原始请求数, sum(case when requestmode = 1 and processnode >= 2 then 1 else 0 end) as 有效请求数, …… from table group by province,city -
统计比例
select *, 竞价成功个数 / 参与竞价个数 as 竞价成功率, …… from tmp1 where 竞价成功数 != 0 and 参与竞价个数 != 0
-
-
MySQL中建表
-- 创建表 DROP TABLE IF EXISTS itcast_ads_report.ads_region_analysis ; CREATE TABLE `itcast_ads_report`.`ads_region_analysis` ( `report_date` varchar(255) NOT NULL, `province` varchar(255) NOT NULL, `city` varchar(255) NOT NULL, `orginal_req_cnt` bigint DEFAULT NULL, `valid_req_cnt` bigint DEFAULT NULL, `ad_req_cnt` bigint DEFAULT NULL, `join_rtx_cnt` bigint DEFAULT NULL, `success_rtx_cnt` bigint DEFAULT NULL, `ad_show_cnt` bigint DEFAULT NULL, `ad_click_cnt` bigint DEFAULT NULL, `media_show_cnt` bigint DEFAULT NULL, `media_click_cnt` bigint DEFAULT NULL, `dsp_pay_money` bigint DEFAULT NULL, `dsp_cost_money` bigint DEFAULT NULL, `success_rtx_rate` double DEFAULT NULL, `ad_click_rate` double DEFAULT NULL, `media_click_rate` double DEFAULT NULL, PRIMARY KEY (`report_date`,`province`,`city`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ; -
SQL代码实现
-
方式一:通过两步来实现
- 先统计基本指标
- 再基于基本指标的DF统计比例
-
方式二:通过一步来做,构建子查询
-
需求:统计每个部门薪资最高的前两名
-
传统子查询
select * from ( select empno, ename, sal, deptno, row_number() over (partition by deptno order by sal desc) as rn from emp ) tmp where tmp.rn < 3; -
另外一种方式
-
语法
with 别名 as ( sql ) select * from 别名 -
实现
with t1 as ( select empno, ename, sal, deptno, row_number() over (partition by deptno order by sal desc) as rn from emp ) select * from t1 where t1.rn<3;
-
-
-
-
DSL代码实现
-
问题:怎么做判断然后聚合的问题?:sum(case when requestmode = 1 and processnode >= 1 then 1 else 0 end) as 原始请求数
etlData .groupBy(province,ciry) .agg( sum(when函数).as("原始请求数") ) -
when函数的语法:类似于case when
when(条件1.and(条件2).and……,符合条件的返回值).otherwise(不符合条件的返回值)
-
5、其他维度的广告指标
- 更换分组的条件即可
七、提交应用测试
1、打包准备
-
打包
-
修改集群配置
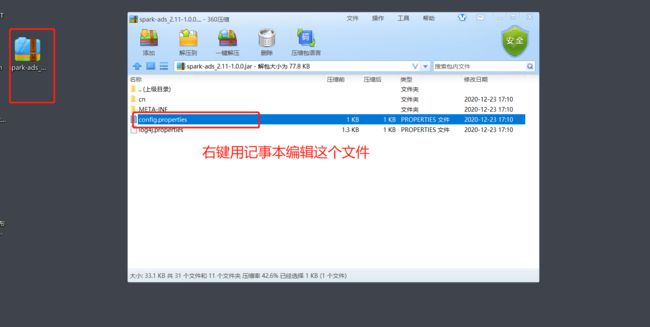
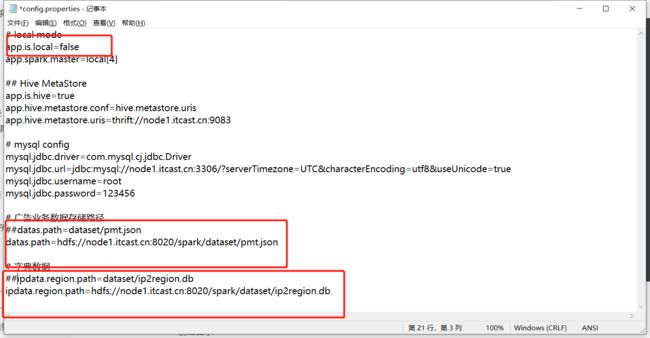
-
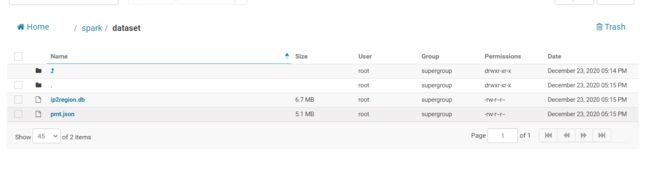
准备集群数据
-
创建目录
hdfs dfs -mkdir /spark/dataset -
上传数据和解析库
-
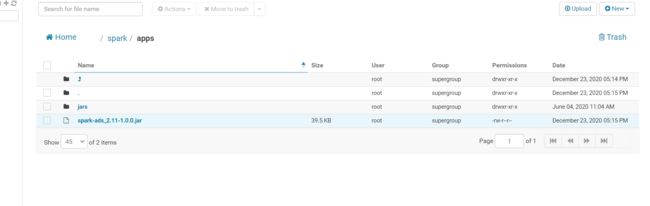
上传jar包到/spark/apps目录下
-
上传依赖jar包
mkdir -p /root/submit-ads-app/jars cd /root/submit-ads-app/jars rz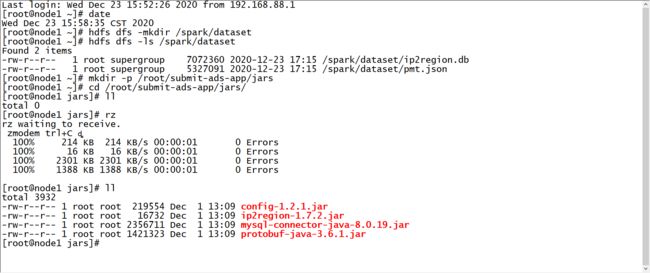
-
删除hive表和MySQL表的数据
-
2、本地测试
SPARK_HOME=/export/server/spark
EXTERNAL_JARS=/root/submit-ads-app/jars
${SPARK_HOME}/bin/spark-submit \
--master local[2] \
--conf "spark.sql.shuffle.partitions=2" \
--class cn.itcast.spark.etl.PmtEtlRunner \
--jars ${EXTERNAL_JARS}/ip2region-1.7.2.jar,${EXTERNAL_JARS}/config-1.2.1.jar \
hdfs://node1.itcast.cn:8020/spark/apps/spark-ads_2.11-1.0.0.jar
SPARK_HOME=/export/server/spark
EXTERNAL_JARS=/root/submit-ads-app/jars
${SPARK_HOME}/bin/spark-submit \
--master local[2] \
--conf spark.sql.shuffle.partitions=2 \
--class cn.itcast.spark.report.PmtReportRunner \
--jars ${EXTERNAL_JARS}/mysql-connector-java-8.0.19.jar,${EXTERNAL_JARS}/protobuf-java-3.6.1.jar,${EXTERNAL_JARS}/config-1.2.1.jar \
hdfs://node1.itcast.cn:8020/spark/apps/spark-ads_2.11-1.0.0.jar
3、集群测试
-
ETL:client
SPARK_HOME=/export/server/spark EXTERNAL_JARS=/root/submit-ads-app/jars ${SPARK_HOME}/bin/spark-submit \ --master yarn \ --deploy-mode client \ --driver-memory 512m \ --executor-memory 512m \ --executor-cores 1 \ --num-executors 2 \ --queue default \ --conf spark.sql.shuffle.partitions=2 \ --class cn.itcast.spark.etl.PmtETLRunner \ --jars ${EXTERNAL_JARS}/ip2region-1.7.2.jar,${EXTERNAL_JARS}/config-1.2.1.jar \ hdfs://node1.itcast.cn:8020/spark/apps/spark-ads_2.11-1.0.0.jar- –conf:临时的指定一些属性
- –jars:添加需要用到的一些额外jar包
-
分析:cluster
SPARK_HOME=/export/server/spark EXTERNAL_JARS=/root/submit-ads-app/jars ${SPARK_HOME}/bin/spark-submit \ --master yarn \ --deploy-mode cluster \ --driver-memory 512m \ --executor-memory 512m \ --executor-cores 1 \ --num-executors 2 \ --queue default \ --conf spark.sql.shuffle.partitions=2 \ --class cn.itcast.spark.report.PmtReportRunner \ --jars ${EXTERNAL_JARS}/mysql-connector-java-8.0.19.jar,${EXTERNAL_JARS}/protobuf-java-3.6.1.jar,${EXTERNAL_JARS}/config-1.2.1.jar \ hdfs://node1.itcast.cn:8020/spark/apps/spark-ads_2.11-1.0.0.jar
八、Streaming流式计算介绍
1、实时数据计算场景及架构
-
分布式计算的需求和场景
- 离线批处理:每天分析处理昨天的数据
- 实时数据流处理:处理实时数据,数据只要一产生,就立即处理
-
应用场景
- 双十一:实时交易分析,实时推荐
- 风控:淘宝刷单、恶意访问、实时征信信息统计
- 离线的技术来实现,上面的场景就没有意义了
- 适合于对于数据的时效性非常高的场景下
-
架构:lambda架构
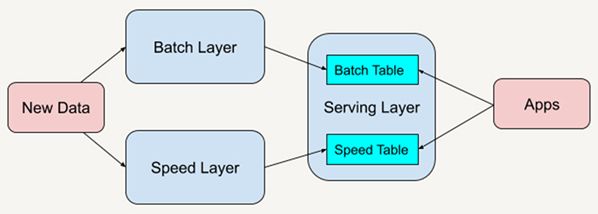
- 离线数据层:所有业务都是离线业务
- 文件:Flume => HDFS => SparkCore/SparkSQL:ETL => Hive => SparkSQL/Impala/Presto
- 数据库:Canal => HDFS => SparkCore/SparkSQL:ETL => Hive => SparkSQL/Impala/Presto
- 实时数据层:所有业务都是实时业务
- 文件Flume/数据库Canal => Kafka => SparkStreaming / Flink => Redis/MySQL/Hbase
- 离线数据层:所有业务都是离线业务
-
实时计算的分类
- 实时计算:对实时数据流【时间】进行处理,数据一产生,立即就被处理了
- 要求
- 数据生成:实时的
- 数据采集:Flume、Canal、Logstash
- 数据存储:Kafka
- 保证数据的一次性语义
- 数据计算:SparkStreaming/Flink
- 数据应用:Redis
- 真实时计算:Flink、Storm
- 以数据为单位,数据产生一条,处理一条
- 准实时计算:SparkStreaming
- 本质:还是批处理
- 以微小时间为单位的批处理,来模拟实时计算
- 每500ms计算一次
2、Streaming的定义及特点

Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams.
- SparkStreaming是基于SparkCore的,代码的调用基本一致
- scalable:可扩展,分布式的
- high-throughput:高吞吐量的
- fault-tolerant:优秀的容错能力,RDD的特性
3、官方介绍及案例
-
官方案例测试
-
先在Linux中启动HDFS
start-dfs.sh -
在第一台机器上启动nc
nc -lk 9999- 往第一台机器的9999端口发送数据
-
在第一台机器上运行示例程序,流式计算wordcount
-
先调整下日志级别
cd /export/servers/spark mv conf/log4j.properties.template conf/log4j.properties vim conf/log4j.properties log4j.rootCategory=WARN, console -
运行官方的示例程序
cd /export/server/spark bin/run-example --master local[3] streaming.NetworkWordCount node1 9999- 从第一台机器的9999端口读取数据,并实现Wordcount
- 默认每1s处理一次
-
-

附录一:Spark离线案例Maven依赖
<repositories>
<repository>
<id>aliyunid>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
repository>
<repository>
<id>clouderaid>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/url>
repository>
<repository>
<id>jbossid>
<url>http://repository.jboss.com/nexus/content/groups/publicurl>
repository>
repositories>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<scala.version>2.11.12scala.version>
<scala.binary.version>2.11scala.binary.version>
<spark.version>2.4.5spark.version>
<hadoop.version>2.6.0-cdh5.16.2hadoop.version>
<mysql.version>8.0.19mysql.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>${mysql.version}version>
dependency>
<dependency>
<groupId>org.lionsoulgroupId>
<artifactId>ip2regionartifactId>
<version>1.7.2version>
dependency>
<dependency>
<groupId>com.typesafegroupId>
<artifactId>configartifactId>
<version>1.2.1version>
dependency>
<dependency>
<groupId>com.squareup.okhttp3groupId>
<artifactId>okhttpartifactId>
<version>3.14.2version>
dependency>
dependencies>
<build>
<outputDirectory>target/classesoutputDirectory>
<testOutputDirectory>target/test-classestestOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resourcesdirectory>
resource>
resources>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.0version>
<configuration>
<source>1.8source>
<target>1.8target>
<encoding>UTF-8encoding>
configuration>
plugin>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.0version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
plugins>
build>