java面试常见知识点整理
本人现在计算机专业硕士一年级,菜鸡一枚,结合前段时间面试经历,整理一下java后端面试常见知识点。本文会持续更新
java面试常见问题
-
- 一、java基础部分
-
- 1.迭代器
- 2.String
- 3. StringBuilder、StringBuffer
- 4.反射
- 6 Java 8 新特性
- 二、MySql数据库
-
- 1. mysql索引类型
- 2. 索引创建原则
- 3. mysql的char和varchar的区别
- 4. explain关键字
- 5.数据库四大特性与隔离级别
- 6.MyIsam引擎与InnoDB引擎的区别(正在施工)
- 7.mysql日志
- 8. mvcc
- 三、Redis
-
- 1.redis分布式锁
- 2 redis数据结构(正在施工)
- 3. reids的过期键删除策略
- 4. redis文件处理器
- 5 redis集群
- 6. 主从复制
- 7. redis淘汰策略
- 四、设计模式
-
- 4.1 单例模式
- 4.2 代理模式
- 五、JAVA并发编程
-
- 5.1 进程与线程的区别
- 5.2 进程之间是如何通信的?
- 5.3 线程池(施工中)
- 5.4 HashMap&ConcurrentHashMap
- 5.5 AQS
- 5.6 HashMap为什么线程不安全
- 5.7 JUC
- 六、JVM
-
- 6.1 java内存划分
- 6.2 jvm垃圾回收
- 6.3 JVM垃圾回收器
- 6.4 JVM类结构
- 6.5 java类加载机制
- 6.6 OOM排查
- 七、Linux
-
- 7.1 Linux常见命令
- 八、开放题目
-
- 8.1 大文件url判断重复问题(待补充)
- 九、计算机网络
-
- 9.1 访问一次百度的过程(待补充)
- 9.2 DNS(待补充)
- 9.3 tcp三次握手
- 9.4 http四次挥手
- 9.5 https
- 9.7 https建立连接的过程
- 9.8 防止SYN攻击
- 十、分布式
-
- 10.1 reactor模式
- 10.2 IO
- 10.3 epoll与select
- 10.4 CAP与BASE
- 十一、Spring
-
- 11.1 IOC与AOP
- 11.2 Spring Cloud负载均衡(正在施工中。。)
- 11.3 bean的生命周期
- 十二、计算机组成原理
-
- 12.1 虚地址
一、java基础部分
1.迭代器
java容器中,最定级的两个接口之一的Collection包含有两个基本方法。其中一个方法用来添加元素,另外一个用来获取迭代器,可见迭代器有多重要了。

Iterator接口包含4个方法:

java迭代器可以被认为是在两个元素之间。初始时在第一个元素前面,每调用一次就会越过下一个元素,并返回刚刚越过的那个元素的引用。
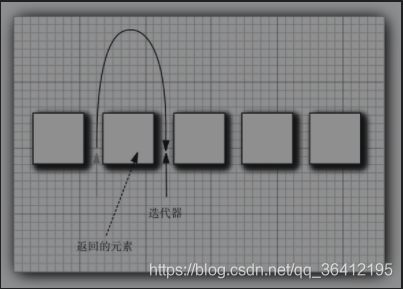
Iterator接口的remove方法会删除上次调用next方法返回时的元素。所以使用的时候先要用一次next()方法。
如ArrayList等Collection接口的实现类内部都会有一个私有内部类,这个类会implements Iterator接口。实现其中的方法。
迭代器ListIterator
ListIterator有两个Iterator接口中没有的方法。previous(),和hasPrevious(),这样就可以实现向前遍历。
2.String
String的底层原理是什么这是一个比较常见的问题,看一下String的源码
@Stable
private final byte[] value;
private final byte coder;
private int hash; // Default to 0
这里的三个属性中,value和hash是最重要的,可以看到java底层其实是使用byte数组来存储的。
hash存储的是String的哈希码,其中哈希玛的计算过程如下所示:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
hash = h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
}
return h;
}
这里就用到了coder这个字段,coder这个字段代表了编码方式
private boolean isLatin1() {
return COMPACT_STRINGS && coder == LATIN1;
}
@Native static final byte LATIN1 = 0;
@Native static final byte UTF16 = 1;
如果这个字段的值为0的话代表编码方式为LATIN,为1的话编码方式为UTF16。这里我们看一下编码方式为LATN1的情况下hashcode()方法的具体情况。
public static int hashCode(byte[] value) {
int h = 0;
for (byte v : value) {
h = 31 * h + (v & 0xff);
}
return h;
}
可以看到,就是s[0]*31^(n-1) + s[1]*31^(n-2) + … + s[n-1],就是第一个值乘31的(n-1)次方,然后第二个乘31的(n-1)次方。。。
2.字符串相加是否会产生新对象
public class StringTest {
public class StringTest {
public static void main(String[] args) {
String a="1";
String b="";
String c = "1"; //a == c为true,此时常量字符串"1"已经被a使用过
String a1 = a+"1"; // a == a1为false,会创建新对象,原因是有变量参与计算。
String str1=a+b; //a == a+b为false,b == a+b为false,产生新对象
String str2=a+b; //产生新对象
String str3="1"+b; //有变量参与计算,产生新对象
String str4="1"+""; //a == str4 为true,编译器自动优化 <==> String str4="1"; "1"常量字符串已被a引用过
String str5="1"+""; //同上
}
}
3. StringBuilder、StringBuffer
- StringBuilfer:原有String类型虽然可以直接通过加号直接拼接字符串,但是,在循环中,每次拼接会创建新的字符串对象,然后扔掉旧的字符串。这样,绝大部分字符串都是临时对象,不但浪费内存,还会影响GC效率。为了能高效拼接字符串,Java标准库提供了StringBuilder,它是一个可变对象,可以预分配缓冲区,这样,往StringBuilder中新增字符时,不会创建新的临时对象:
public class Main {
public static void main(String[] args) {
var sb = new StringBuilder(1024);
sb.append("Mr ")
.append("Bob")
.append("!")
.insert(0, "Hello, ");
System.out.println(sb.toString());
}
}
其实String类型的拼接操作也是通过将String转化为StringBuiler然后调用append()方法来实现的。
- StringBuffer:api和StringBuilder完全一样,只不过线程安全。
4.反射
Class类
除了int等基本类型外,Java的其他类型全部都是class(包括interface)。例如:
- String
- Object
- Runable
- Exception
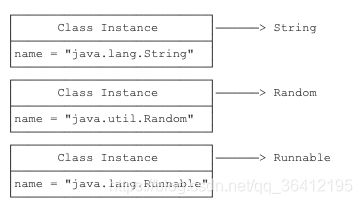
class(包括interface)的本质是数据类型(Type),而class是由JVM在执行过程中动态加载的。JVM在第一次读取到一种class类型时,将其加载进内存。
每加载一种class,JVM就为其创建一个Class类型的实例,并关联起来。注意:这里的Class类型是一个名叫Class的class。它长这样:
public final class Class {
private Class() {}
}
以String类为例,当JVM加载String类时,它首先读取String.class文件到内存,然后,为String类创建一个Class实例并关联起来:
Class cls = new Class(String);
这个Class实例是JVM内部创建的,如果我们查看JDK源码,可以发现Class类的构造方法是private,只有JVM能创建Class实例,我们自己的Java程序是无法创建Class实例的。
所以,JVM持有的每个Class实例都指向一个数据类型(class或interface):
一个Class实例包含了该class的所有完整信息:
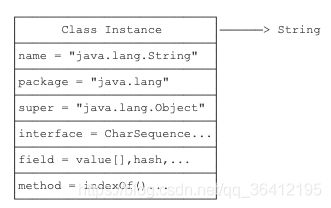
由于JVM为每个加载的class创建了对应的Class实例,并在实例中保存了该class的所有信息,包括类名、包名、父类、实现的接口、所有方法、字段等,因此,如果获取了某个Class实例,我们就可以通过这个Class实例获取到该实例对应的class的所有信息。
这种通过Class实例获取class信息的方法称为反射(Reflection)
获取一个class的class实例的方式有三种
- 直接通过一个class的静态变量class获取:
Class cls = String.class;
- 如果我们有一个实例变量,可以通过该实例变量提供的getClass()方法获取:
String s = "Hello";
Class cls = s.getClass();
- 如果知道一个class的完整类名,可以通过静态方法Class.forName()获取:
Class cls = Class.forName("java.lang.String");
因为反射的目的是为了获得某个实例的信息。因此,当我们拿到某个Object实例时,我们可以通过反射获取该Object的class信息:
public class Main {
public static void main(String[] args) {
printClassInfo("".getClass());
printClassInfo(Runnable.class);
printClassInfo(java.time.Month.class);
printClassInfo(String[].class);
printClassInfo(int.class);
}
static void printClassInfo(Class cls) {
System.out.println("Class name: " + cls.getName());
System.out.println("Simple name: " + cls.getSimpleName());
if (cls.getPackage() != null) {
System.out.println("Package name: " + cls.getPackage().getName());
}
System.out.println("is interface: " + cls.isInterface());
System.out.println("is enum: " + cls.isEnum());
System.out.println("is array: " + cls.isArray());
System.out.println("is primitive: " + cls.isPrimitive());
}
}
数组(例如String[])也是一种Class,而且不同于String.class,它的类名是[Ljava.lang.String。此外,JVM为每一种基本类型如int也创建了Class,通过int.class访问。
如果获取到了一个Class实例,我们就可以通过该Class实例来创建对应类型的实例:
// 获取String的Class实例:
Class cls = String.class;
// 创建一个String实例:
String s = (String) cls.newInstance();
上述代码相当于new String()。通过Class.newInstance()可以创建类实例,它的局限是:只能调用public的无参数构造方法。带参数的构造方法,或者非public的构造方法都无法通过Class.newInstance()被调用。
访问字段
对任意的一个Object实例,只要我们获取了它的Class,就可以获取它的一切信息。
我们先看看如何通过Class实例获取字段信息。Class类提供了以下几个方法来获取字段:
- Field getField(name):根据字段名获取某个public的field(包括父类)
- Field getDeclaredField(name):根据字段名获取当前类的某个field(不包括父类)
- Field[] getFields():获取所有public的field(包括父类)
- Field[] getDeclaredFields():获取当前类的所有field(不包括父类)
public class Main {
public static void main(String[] args) throws Exception {
Class stdClass = Student.class;
// 获取public字段"score":
System.out.println(stdClass.getField("score"));
// 获取继承的public字段"name":
System.out.println(stdClass.getField("name"));
// 获取private字段"grade":
System.out.println(stdClass.getDeclaredField("grade"));
}
}
class Student extends Person {
public int score;
private int grade;
}
class Person {
public String name;
}
上述代码首先获取Student的Class实例,然后,分别获取public字段、继承的public字段以及private字段,打印出的Field类似:
public int Student.score
public java.lang.String Person.name
private int Student.grade
一个Field对象包含了一个字段的所有信息:
- getName():返回字段名称,例如,“name”
- getType():返回字段类型,也是一个Class实例
- getModifiers():返回字段的修饰符,它是一个int,不同的bit表示不同的含义
以String类的value字段为例,它的定义是:
public final class String {
private final byte[] value;
}
我们用反射获取该字段的信息,代码如下:
Field f = String.class.getDeclaredField("value");
f.getName(); // "value"
f.getType(); // class [B 表示byte[]类型
int m = f.getModifiers();
Modifier.isFinal(m); // true
Modifier.isPublic(m); // false
Modifier.isProtected(m); // false
Modifier.isPrivate(m); // true
Modifier.isStatic(m); // false
利用反射拿到字段的一个Field实例只是第一步,我们还可以拿到一个实例对应的该字段的值。
例如,对于一个Person实例,我们可以先拿到name字段对应的Field,再获取这个实例的name字段的值:
public class Main {
public static void main(String[] args) throws Exception {
Object p = new Person("Xiao Ming");
Class c = p.getClass();
Field f = c.getDeclaredField("name");
Object value = f.get(p);
System.out.println(value); // "Xiao Ming"
}
}
class Person {
private String name;
public Person(String name) {
this.name = name;
}
}
上述代码先获取Class实例,再获取Field实例,然后,用Field.get(Object)获取指定实例的指定字段的值。
运行代码,如果不出意外,会得到一个IllegalAccessException,这是因为name被定义为一个private字段,正常情况下,Main类无法访问Person类的private字段。要修复错误,可以将private改为public,或者,在调用Object value = f.get§;前,先写一句:
f.setAccessible(true);
调用Field.setAccessible(true)的意思是,别管这个字段是不是public,一律允许访问。
通过Field实例既然可以获取到指定实例的字段值,自然也可以设置字段的值。
设置字段值是通过Field.set(Object, Object)实现的,其中第一个Object参数是指定的实例,第二个Object参数是待修改的值。示例代码如下:
public class Main {
public static void main(String[] args) throws Exception {
Person p = new Person("Xiao Ming");
System.out.println(p.getName()); // "Xiao Ming"
Class c = p.getClass();
Field f = c.getDeclaredField("name");
f.setAccessible(true);
f.set(p, "Xiao Hong");
System.out.println(p.getName()); // "Xiao Hong"
}
}
class Person {
private String name;
public Person(String name) {
this.name = name;
}
public String getName() {
return this.name;
}
}
获取方法
我们已经能通过Class实例获取所有Field对象,同样的,可以通过Class实例获取所有Method信息。Class类提供了以下几个方法来获取Method:
- Method getMethod(name, Class…):获取某个public的Method(包括父类)
- Method getDeclaredMethod(name, Class…):获取当前类的某个Method(不包括父类)
- Method[] getMethods():获取所有public的Method(包括父类)
- Method[] getDeclaredMethods():获取当前类的所有Method(不包括父类)
public class Main {
public static void main(String[] args) throws Exception {
Class stdClass = Student.class;
// 获取public方法getScore,参数为String:
System.out.println(stdClass.getMethod("getScore", String.class));
// 获取继承的public方法getName,无参数:
System.out.println(stdClass.getMethod("getName"));
// 获取private方法getGrade,参数为int:
System.out.println(stdClass.getDeclaredMethod("getGrade", int.class));
}
}
class Student extends Person {
public int getScore(String type) {
return 99;
}
private int getGrade(int year) {
return 1;
}
}
class Person {
public String getName() {
return "Person";
}
}
上述代码首先获取Student的Class实例,然后,分别获取public方法、继承的public方法以及private方法,打印出的Method类似:
public int Student.getScore(java.lang.String)
public java.lang.String Person.getName()
private int Student.getGrade(int)
一个Method对象包含一个方法的所有信息:
- getName():返回方法名称,例如:“getScore”;
- getReturnType():返回方法返回值类型,也是一个Class实例,例如:String.class;
- getParameterTypes():返回方法的参数类型,是一个Class数组,例如:{String.class, int.class};
- getModifiers():返回方法的修饰符,它是一个int,不同的bit表示不同的含义。
当我们获取到一个Method对象时,就可以对它进行调用。我们以下面的代码为例:
String s = "Hello world";
String r = s.substring(6); // "world"
如果用反射来调用substring方法,需要以下代码:
public class Main {
public static void main(String[] args) throws Exception {
// String对象:
String s = "Hello world";
// 获取String substring(int)方法,参数为int:
Method m = String.class.getMethod("substring", int.class);
// 在s对象上调用该方法并获取结果:
String r = (String) m.invoke(s, 6);
// 打印调用结果:
System.out.println(r);
}
}
对Method实例调用invoke就相当于调用该方法,invoke的第一个参数是对象实例,即在哪个实例上调用该方法,后面的可变参数要与方法参数一致,否则将报错。
如果获取到的Method表示一个静态方法,调用静态方法时,由于无需指定实例对象,所以invoke方法传入的第一个参数永远为null。我们以Integer.parseInt(String)为例:
public class Main {
public static void main(String[] args) throws Exception {
// 获取Integer.parseInt(String)方法,参数为String:
Method m = Integer.class.getMethod("parseInt", String.class);
// 调用该静态方法并获取结果:
Integer n = (Integer) m.invoke(null, "12345");
// 打印调用结果:
System.out.println(n);
}
}
和Field类似,对于非public方法,我们虽然可以通过Class.getDeclaredMethod()获取该方法实例,但直接对其调用将得到一个IllegalAccessException。为了调用非public方法,我们通过Method.setAccessible(true)允许其调用:
public class Main {
public static void main(String[] args) throws Exception {
Person p = new Person();
Method m = p.getClass().getDeclaredMethod("setName", String.class);
m.setAccessible(true);
m.invoke(p, "Bob");
System.out.println(p.name);
}
}
class Person {
String name;
private void setName(String name) {
this.name = name;
}
}
调用构造方法
如果通过反射来创建新的实例,可以调用Class提供的newInstance()方法:
Person p = Person.class.newInstance();
调用Class.newInstance()的局限是,它只能调用该类的public无参数构造方法。如果构造方法带有参数,或者不是public,就无法直接通过Class.newInstance()来调用。
为了调用任意的构造方法,Java的反射API提供了Constructor对象,它包含一个构造方法的所有信息,可以创建一个实例。Constructor对象和Method非常类似,不同之处仅在于它是一个构造方法,并且,调用结果总是返回实例
public class Main {
public static void main(String[] args) throws Exception {
// 获取构造方法Integer(int):
Constructor cons1 = Integer.class.getConstructor(int.class);
// 调用构造方法:
Integer n1 = (Integer) cons1.newInstance(123);
System.out.println(n1);
// 获取构造方法Integer(String)
Constructor cons2 = Integer.class.getConstructor(String.class);
Integer n2 = (Integer) cons2.newInstance("456");
System.out.println(n2);
}
}
动态代理
有没有可能不编写实现类,直接在运行期创建某个interface的实例呢?
这是可能的,因为Java标准库提供了一种动态代理(Dynamic Proxy)的机制:可以在运行期动态创建某个interface的实例
什么叫运行期动态创建?听起来好像很复杂。所谓动态代理,是和静态相对应的。我们来看静态代码怎么写:
定义接口:
public interface Hello {
void morning(String name);
}
编写实现类:
public class HelloWorld implements Hello {
public void morning(String name) {
System.out.println("Good morning, " + name);
}
}
创建实例,转型为接口并调用:
Hello hello = new HelloWorld();
hello.morning("Bob");
还有一种方式是动态代码,我们仍然先定义了接口Hello,但是我们并不去编写实现类,而是直接通过JDK提供的一个Proxy.newProxyInstance()创建了一个Hello接口对象。这种没有实现类但是在运行期动态创建了一个接口对象的方式,我们称为动态代码。JDK提供的动态创建接口对象的方式,就叫动态代理。
public class Main {
public static void main(String[] args) {
InvocationHandler handler = new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println(method);
if (method.getName().equals("morning")) {
System.out.println("Good morning, " + args[0]);
}
return null;
}
};
Hello hello = (Hello) Proxy.newProxyInstance(
Hello.class.getClassLoader(), // 传入ClassLoader
new Class[] { Hello.class }, // 传入要实现的接口
handler); // 传入处理调用方法的InvocationHandler
hello.morning("Bob");
}
}
interface Hello {
void morning(String name);
}
在运行期动态创建一个interface实例的方法如下:
- 定义一个InvocationHandler实例,它负责实现接口的方法调用;
- 通过Proxy.newProxyInstance()创建interface实例,它需要3个参数:
1. 使用的ClassLoader,通常就是接口类的ClassLoader;
2. 需要实现的接口数组,至少需要传入一个接口进去;
3. 用来处理接口方法调用的InvocationHandler实例。 - 将返回的Object强制转型为接口。
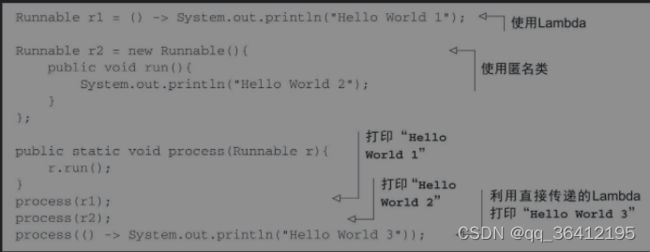
6 Java 8 新特性
Lambda表达式
可以把Lambda表达式理解为简洁地表示可传递的匿名函数的一种方式:它没有名称,但它有参数列表、函数主体、返回类型,可能还有一个可以抛出的异常列表。。
例如我们可以用Lambda表达式更简单的定义Comparator对象。
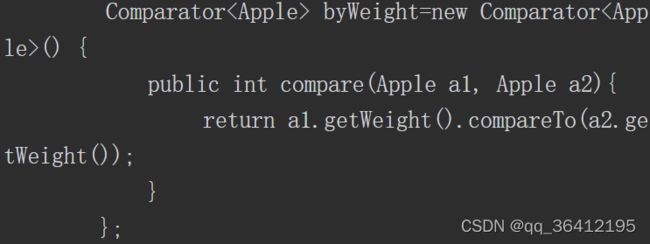
使用Lambda表达式后就可以变成:

Lambda表达式有三个部分,如下图所示:

- 参数列表——这里它采用了Comparator中compare方法的参数,两个Apple。
- 箭头——箭头->把参数列表与Lambda主体分隔开。
- Lambda主体——比较两个Apple的重量。表达式就是Lambda的返回值了。
那么究竟在何处以及如何使用Lambda呢?
答案就是函数式接口,任何函数式接口都可以使用Lambda来代替。一言以蔽之,函数式接口就是只定义一个抽象方法的接口。如我们熟悉的Comparator和Runnable接口,他们均只有一个方法。

有了Lambda后我们可以像下面那种方式使用Runnable接口了:
二、MySql数据库
1. mysql索引类型
- Primary Key(聚集索引):InnoDB存储引擎的表会存在主键(唯一非null),如果建表的时候没有指定主键,则会使用第一非空的唯一索引作为聚集索引,否则InnoDB会自动帮你创建一个不可见的、长度为6字节的row_id用来作为聚集索引。
- 单列索引:单列索引即一个索引只包含单个列
- 组合索引:组合索引指在表的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用。使用组合索引时遵循最左前缀集合
- Unique(唯一索引):索引列的值必须唯一,但允许有空值。若是组合索引,则列值的组合必须唯一。主键索引是一种特殊的唯一索引,不允许有空值
- Key(普通索引):是MySQL中的基本索引类型,允许在定义索引的列中插入重复值和空值
- FULLTEXT(全文索引):全文索引类型为FULLTEXT,在定义索引的列上支持值的全文查找,允许在这些索引列中插入重复值和空值。全文索引可以在CHAR、VARCHAR或者TEXT类型的列上创建
- SPATIAL(空间索引):空间索引是对空间数据类型的字段建立的索引,MySQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING和POLYGON。MySQL使用SPATIAL关键字进行扩展,使得能够用于创建正规索引类似的语法创建空间索引。创建空间索引的列必须声明为NOT NULL
2. 索引创建原则
- 索引并非越多越好,一个表中如果有大量的索引,不仅占用磁盘空间,而且会影响INSERT、DELETE、UPDATE等语句的性能,因为在表中的数据更改的同时,索引也会进行调整和更新
- 避免对经常更新的表进行过多的索引,并且索引中的列尽可能少。而对经常用于查询的字段应该创建索引,但要避免添加不必要的字段。
- 数据量小的表最好不要使用索引,由于数据较少,查询花费的时间可能比遍历索引的时间还要短,索引可能不会产生优化效果。
- 在条件表达式中经常用到的不同值较多的列上建立索引,在不同值很少的列上不要建立索引。比如在学生表的“性别”字段上只有“男”与“女”两个不同值,因此就无须建立索引。如果建立索引,不但不会提高查询效率,反而会严重降低数据更新速度。
- 当唯一性是某种数据本身的特征时,指定唯一索引。使用唯一索引需能确保定义的列的数据完整性,以提高查询速度。
- 在频繁进行排序或分组(即进行group by或order by操作)的列上建立索引,如果待排序的列有多个,可以在这些列上建立组合索引。
- 搜索的索引列,不一定是所要选择的列。换句话说,最适合索引的列是出现在WHERE子句中的列,或连接子句中指定的列,而不是出现在SELECT关键字后的选择列表中的列。
- 使用短索引。如果对字符串列进行索引,应该指定一个前缀长度,只要有可能就应该这样做。例如,有一个CHAR(200)列,如果在前10个或20个字符内,多数值是唯一的,那么就不要对整个列进行索引。对前10个或20个字符进行索引能够节省大量索引空间,也可能会使查询更快。较小的索引涉及的磁盘 IO 较少,较短的值比较起来更快。更为重要的是,对于较短的键值,索引高速缓存中的块能容纳更多的键值,因此,MySQL 也可以在内存中容纳更多的值。这样就增加了找到行而不用读取索引中较多块的可能性。
- 利用最左前缀。在创建一个n列的索引时,实际是创建了MySQL可利用的n个索引。多列索引可起几个索引的作用,因为可利用索引中最左边的列集来匹配行。这样的列集称为最左前缀。
- 对于InnoDB存储引擎的表,记录默认会按照一定的顺序保存,如果有明确定义的主键,则按照主键顺序保存。如果没有主键,但是有唯一索引,那么就是按照唯一索引的顺序保存。如果既没有主键又没有唯一索引,那么表中会自动生成一个内部列,按照这个列的顺序保存。按照主键或者内部列进行的访问是最快的,所以InnoDB表尽量自己指定主键,当表中同时有几个列都是唯一的,都可以作为主键的时候,要选择最常作为访问条件的列作为主键,提高查询的效率。另外,还需要注意,InnoDB 表的普通索引都会保存主键的键值,所以主键要尽可能选择较短的数据类型,可以有效地减少索引的磁盘占用,提高索引的缓存效果
3. mysql的char和varchar的区别
CHAR和VARCHAR很类似,都用来保存MySQL中较短的字符串。二者的主要区别在于存储方式的不同:
- CHAR列的长度固定,为创建表时声明的长度,长度可以为从0~255的任何值;在检索的时候,CHAR列删除尾部的空格
- VARCHAR列中的值为可变长字符串,长度可以指定为0~255(MySQL 5.0.3版本以前)或者 65535(MySQL 5.0.3版本以后)之间的值。而检索的时候VARCHAR则保留尾部空格。
4. explain关键字
MySQL 提供了一个 EXPLAIN 命令, 它可以对 SELECT 语句进行分析, 并输出 SELECT 执行的详细信息, 以供开发人员针对性优化.
EXPLAIN 命令用法十分简单, 在 SELECT 语句前加上 Explain 就可以了, 例如:
EXPLAIN SELECT * from user_info WHERE id < 300;
为了接下来方便演示 EXPLAIN 的使用, 首先我们需要建立两个测试用的表, 并添加相应的数据:
CREATE TABLE `user_info` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(50) NOT NULL DEFAULT '',
`age` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_index` (`name`)
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8
INSERT INTO user_info (name, age) VALUES ('xys', 20);
INSERT INTO user_info (name, age) VALUES ('a', 21);
INSERT INTO user_info (name, age) VALUES ('b', 23);
INSERT INTO user_info (name, age) VALUES ('c', 50);
INSERT INTO user_info (name, age) VALUES ('d', 15);
INSERT INTO user_info (name, age) VALUES ('e', 20);
INSERT INTO user_info (name, age) VALUES ('f', 21);
INSERT INTO user_info (name, age) VALUES ('g', 23);
INSERT INTO user_info (name, age) VALUES ('h', 50);
INSERT INTO user_info (name, age) VALUES ('i', 15);
CREATE TABLE `order_info` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`user_id` BIGINT(20) DEFAULT NULL,
`product_name` VARCHAR(50) NOT NULL DEFAULT '',
`productor` VARCHAR(30) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `user_product_detail_index` (`user_id`, `product_name`, `productor`)
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8
INSERT INTO order_info (user_id, product_name, productor) VALUES (1, 'p1', 'WHH');
INSERT INTO order_info (user_id, product_name, productor) VALUES (1, 'p2', 'WL');
INSERT INTO order_info (user_id, product_name, productor) VALUES (1, 'p1', 'DX');
INSERT INTO order_info (user_id, product_name, productor) VALUES (2, 'p1', 'WHH');
INSERT INTO order_info (user_id, product_name, productor) VALUES (2, 'p5', 'WL');
INSERT INTO order_info (user_id, product_name, productor) VALUES (3, 'p3', 'MA');
INSERT INTO order_info (user_id, product_name, productor) VALUES (4, 'p1', 'WHH');
INSERT INTO order_info (user_id, product_name, productor) VALUES (6, 'p1', 'WHH');
INSERT INTO order_info (user_id, product_name, productor) VALUES (9, 'p8', 'TE');
explain的输出格式
mysql> explain select * from user_info where id = 2\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user_info
partitions: NULL
type: const
possible_keys: PRIMARY
key: PRIMARY
key_len: 8
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
各列的含义如下:
- id: select查询的标识符,每个select都会分配一个唯一的标识符
- select_type: select查询的类型
- table:查询的哪张表
- partitions:匹配的分区
- type:join类型
- possible_keys:此次查询中可能用到的索引
- key: 此次查询中确切用到的索引
- ref:那个字段或常数与key一起被使用
- rows:显示此查询一共扫描了多少行,这是一个估计值
- filltered:表示此查询条件所过滤的数据的百分比
- extra:额外信息
接下来我们来重点看一下比较重要的几个字段.
1. select_type
select_type 表示了查询的类型, 它的常用取值有:
-
SIMPLE, 表示此查询不包含 UNION 查询或子查询
-
PRIMARY, 表示此查询是最外层的查询
-
UNION, 表示此查询是 UNION 的第二或随后的查询
-
DEPENDENT UNION, UNION 中的第二个或后面的查询语句, 取决于外面的查询
-
UNION RESULT, UNION 的结果
-
SUBQUERY, 子查询中的第一个 SELECT
-
DEPENDENT SUBQUERY: 子查询中的第一个 SELECT, 取决于外面的查询. 即子查询依赖于外层查询的结果.
最常见的查询类别应该是 SIMPLE 了, 比如当我们的查询没有子查询, 也没有 UNION 查询时, 那么通常就是 SIMPLE 类型, 例如:
mysql> explain select * from user_info where id = 2\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user_info
partitions: NULL
type: const
possible_keys: PRIMARY
key: PRIMARY
key_len: 8
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
如果我们使用了 UNION 查询, 那么 EXPLAIN 输出 的结果类似如下:
mysql> EXPLAIN (SELECT * FROM user_info WHERE id IN (1, 2, 3))
-> UNION
-> (SELECT * FROM user_info WHERE id IN (3, 4, 5));
+----+--------------+------------+------------+-------+---------------+---------+---------+------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------+------------+------------+-------+---------------+---------+---------+------+------+----------+-----------------+
| 1 | PRIMARY | user_info | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 3 | 100.00 | Using where |
| 2 | UNION | user_info | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 3 | 100.00 | Using where |
| NULL | UNION RESULT | <union1,2> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------+------------+------------+-------+---------------+---------+---------+------+------+----------+-----------------+
3 rows in set, 1 warning (0.00 sec)
2.table
表示查询涉及的表或衍生表
3 type
type 字段比较重要, 它提供了判断查询是否高效的重要依据依据. 通过 type 字段, 我们判断此次查询是 全表扫描 还是 索引扫描 等.type 常用类型有:
- system:表中只有一条数据。这个类型是特殊的const型
- const:针对主键或唯一索引的等值查询扫描,最多只返回一条数据。const查询特别快,因为它仅仅读取一次即可。例如下面的这个查询, 它使用了主键索引, 因此 type 就是 const 类型的
mysql> explain select * from user_info where id = 2\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user_info
partitions: NULL
type: const
possible_keys: PRIMARY
key: PRIMARY
key_len: 8
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
- eq_ref:此类型通常出现在多表的 join 查询, 表示对于前表的每一个结果, 都只能匹配到后表的一行结果. 并且查询的比较操作通常是 =, 查询效率较高. 例如:
mysql> EXPLAIN SELECT * FROM user_info, order_info WHERE user_info.id = order_info.user_id\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: order_info
partitions: NULL
type: index
possible_keys: user_product_detail_index
key: user_product_detail_index
key_len: 314
ref: NULL
rows: 9
filtered: 100.00
Extra: Using where; Using index
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: user_info
partitions: NULL
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 8
ref: test.order_info.user_id
rows: 1
filtered: 100.00
Extra: NULL
2 rows in set, 1 warning (0.00 sec)
- ref:此类型通常出现在多表的 join 查询, 针对于非唯一或非主键索引, 或者是使用了 最左前缀 规则索引的查询.例如下面这个例子中, 就使用到了 ref 类型的查询:
mysql> EXPLAIN SELECT * FROM user_info, order_info WHERE user_info.id = order_info.user_id AND order_info.user_id = 5\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user_info
partitions: NULL
type: const
possible_keys: PRIMARY
key: PRIMARY
key_len: 8
ref: const
rows: 1
filtered: 100.00
Extra: NULL
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: order_info
partitions: NULL
type: ref
possible_keys: user_product_detail_index
key: user_product_detail_index
key_len: 9
ref: const
rows: 1
filtered: 100.00
Extra: Using index
2 rows in set, 1 warning (0.01 sec)
- range: 表示使用索引范围查询, 通过索引字段范围获取表中部分数据记录. 这个类型通常出现在 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN() 操作中.
当 type 是 range 时, 那么 EXPLAIN 输出的 ref 字段为 NULL, 并且 key_len 字段是此次查询中使用到的索引的最长的那个.
mysql> EXPLAIN SELECT *
-> FROM user_info
-> WHERE id BETWEEN 2 AND 8 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user_info
partitions: NULL
type: range
possible_keys: PRIMARY
key: PRIMARY
key_len: 8
ref: NULL
rows: 7
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
- index: 表示全索引扫描(full index scan), 和 ALL 类型类似, 只不过 ALL 类型是全表扫描, 而 index 类型则仅仅扫描所有的索引, 而不扫描数据。index 类型通常出现在: 所要查询的数据直接在索引树中就可以获取到, 而不需要扫描数据. 当是这种情况时, Extra 字段 会显示 Using index.
mysql> EXPLAIN SELECT name FROM user_info \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user_info
partitions: NULL
type: index
possible_keys: NULL
key: name_index
key_len: 152
ref: NULL
rows: 10
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
上面的例子中, 我们查询的 name 字段恰好是一个索引, 因此我们直接从索引中获取数据就可以满足查询的需求了, 而不需要查询表中的数据. 因此这样的情况下, type 的值是 index, 并且 Extra 的值是 Using index.
- ALL: 表示全表扫描, 这个类型的查询是性能最差的查询之一. 通常来说, 我们的查询不应该出现 ALL 类型的查询, 因为这样的查询在数据量大的情况下, 对数据库的性能是巨大的灾难. 如一个查询是 ALL 类型查询, 那么一般来说可以对相应的字段添加索引来避免.
下面是一个全表扫描的例子, 可以看到, 在全表扫描时, possible_keys 和 key 字段都是 NULL, 表示没有使用到索引, 并且 rows 十分巨大, 因此整个查询效率是十分低下的.
mysql> EXPLAIN SELECT age FROM user_info WHERE age = 20 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user_info
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 10
filtered: 10.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
通常来说, 不同的 type 类型的性能关系如下:
ALL < index < range ~ index_merge < ref < eq_ref < const < system
ALL 类型因为是全表扫描, 因此在相同的查询条件下, 它是速度最慢的.
而 index 类型的查询虽然不是全表扫描, 但是它扫描了所有的索引, 因此比 ALL 类型的稍快.
后面的几种类型都是利用了索引来查询数据, 因此可以过滤部分或大部分数据, 因此查询效率就比较高了.
4 possible_keys
possible_keys 表示 MySQL 在查询时, 能够使用到的索引. 注意, 即使有些索引在 possible_keys 中出现, 但是并不表示此索引会真正地被 MySQL 使用到. MySQL 在查询时具体使用了哪些索引, 由 key 字段决定.
5 key
此字段是 MySQL 在当前查询时所真正使用到的索引.
6 key_len
表示查询优化器使用了索引的字节数. 这个字段可以评估组合索引是否完全被使用, 或只有最左部分字段被使用到.
-
字符串
char(n): n 字节长度
varchar(n): 如果是 utf8 编码, 则是 3 n + 2字节; 如果是 utf8mb4 编码, 则是 4 n + 2 字节. -
数值类型:
TINYINT: 1字节
SMALLINT: 2字节
MEDIUMINT: 3字节
INT: 4字节
BIGINT: 8字节 -
时间类型
DATE: 3字节
TIMESTAMP: 4字节
DATETIME: 8字节 -
字段属性: NULL 属性 占用一个字节. 如果一个字段是 NOT NULL 的, 则没有此属性.
mysql> EXPLAIN SELECT * FROM order_info WHERE user_id < 3 AND product_name = 'p1' AND productor = 'WHH' \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: order_info
partitions: NULL
type: range
possible_keys: user_product_detail_index
key: user_product_detail_index
key_len: 9
ref: NULL
rows: 5
filtered: 11.11
Extra: Using where; Using index
1 row in set, 1 warning (0.00 sec)
上面的例子是从表 order_info 中查询指定的内容, 而我们从此表的建表语句中可以知道, 表 order_info 有一个联合索引:
KEY `user_product_detail_index` (`user_id`, `product_name`, `productor`)
不过此查询语句 WHERE user_id < 3 AND product_name = ‘p1’ AND productor = ‘WHH’ 中, 因为先进行 user_id 的范围查询, 而根据 最左前缀匹配 原则, 当遇到范围查询时, 就停止索引的匹配, 因此实际上我们使用到的索引的字段只有 user_id, 因此在 EXPLAIN 中, 显示的 key_len 为 9. 因为 user_id 字段是 BIGINT, 占用 8 字节, 而 NULL 属性占用一个字节, 因此总共是 9 个字节. 若我们将user_id 字段改为 BIGINT(20) NOT NULL DEFAULT ‘0’, 则 key_length 应该是8.
上面因为 最左前缀匹配 原则, 我们的查询仅仅使用到了联合索引的 user_id 字段, 因此效率不算高.
mysql> EXPLAIN SELECT * FROM order_info WHERE user_id = 1 AND product_name = 'p1' \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: order_info
partitions: NULL
type: ref
possible_keys: user_product_detail_index
key: user_product_detail_index
key_len: 161
ref: const,const
rows: 2
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
这次的查询中, 我们没有使用到范围查询, key_len 的值为 161. 为什么呢? 因为我们的查询条件 WHERE user_id = 1 AND product_name = ‘p1’ 中, 仅仅使用到了联合索引中的前两个字段, 因此 keyLen(user_id) + keyLen(product_name) = 9 + 50 * 3 + 2 = 161
7 rows
rows 也是一个重要的字段. MySQL 查询优化器根据统计信息, 估算 SQL 要查找到结果集需要扫描读取的数据行数.
这个值非常直观显示 SQL 的效率好坏, 原则上 rows 越少越好.
8 extra
EXplain 中的很多额外的信息会在 Extra 字段显示, 常见的有以下几种内容:
- Using filesort
当 Extra 中有 Using filesort 时, 表示 MySQL 需额外的排序操作, 不能通过索引顺序达到排序效果. 一般有 Using filesort, 都建议优化去掉, 因为这样的查询 CPU 资源消耗大
mysql> EXPLAIN SELECT * FROM order_info ORDER BY product_name \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: order_info
partitions: NULL
type: index
possible_keys: NULL
key: user_product_detail_index
key_len: 253
ref: NULL
rows: 9
filtered: 100.00
Extra: Using index; Using filesort
1 row in set, 1 warning (0.00 sec)
我们的索引是
KEY `user_product_detail_index` (`user_id`, `product_name`, `productor`)
但是上面的查询中根据 product_name 来排序, 因此不能使用索引进行优化, 进而会产生 Using filesort.
如果我们将排序依据改为 ORDER BY user_id, product_name, 那么就不会出现 Using filesort 了. 例如:
mysql> EXPLAIN SELECT * FROM order_info ORDER BY user_id, product_name \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: order_info
partitions: NULL
type: index
possible_keys: NULL
key: user_product_detail_index
key_len: 253
ref: NULL
rows: 9
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
- Using index
“覆盖索引扫描”, 表示查询在索引树中就可查找所需数据, 不用扫描表数据文件, 往往说明性能不错 - Using temporary
查询有使用临时表, 一般出现于排序, 分组和多表 join 的情况, 查询效率不高, 建议优化.
5.数据库四大特性与隔离级别
事务的四大特性
数据库如果支持事务的操作,那么就具备以下四个特性:
- 原子性:事务是数据库的逻辑工作单位,事务中包括的诸操作要么全做,要么全不做。
- 一致性:事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
- 隔离性:一个事务不能被其他事务干扰
- 永久性:一个事务一旦提交,它对数据库的修改应该是永久性的
事务的隔离级别
(1)读未提交(可能出现脏读):
公司发工资了,把50000元打到我的账号上,但是该事务并未提交,而我正好去查看账户,发现工资已经到账,是50000元整,非常高兴。可是不幸的是,领导发现发给的工资金额不对,是2000元,于是迅速回滚了事务,修改金额后,将事务提交,最后我实际的工资只有2000元,空欢喜一场。
脏读是两个并发的事务,“事务A:领导发工资”、“事务B:我查询工资账户”,事务B读取了事务A尚未提交的数据。
当隔离级别设置为Read uncommitted时,就可能出现脏读,如何避免脏读,请看下一个隔离级别。
(2)读已提交(可能出现不可重复读)
我拿着工资卡去消费,系统读取到卡里确实有2000元,而此时老婆也正好在网上转账,把工资卡的2000元转到她账户,并在我之前提交了事务,当我扣款时,系统检查到工资卡已经没有钱,扣款失败,十分纳闷,明明卡里有钱,为何…
不可重复读是两个并发的事务,“事务A:消费”、“事务B:老婆网上转账”,事务A事先读取了数据,事务B紧接了更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变。
当隔离级别设置为Read committed时,避免了脏读,但是可能会造成不可重复读。
(3)可重复读(可能出现幻读)
当隔离级别设置为Repeatable read时,可以避免不可重复读。当我拿着工资卡去消费时,一旦系统开始读取工资卡信息(即事务开始),我老婆就不可能对该记录进行修改,也就是不能在此时转账。
虽然Repeatable read避免了不可重复读,但还有可能出现幻读。例如:老婆工作在银行部门,她时常通过银行内部系统查看我的信用卡消费记录。有一天,她正查询到我当月信用卡的总消费金额(select sum(amount) from transaction where month = 本月)为80元,而我此时正好在外面吃完大餐后在收银台买单,消费1000元,即新增了一条1000元的消费记录(insert transaction … ),并提交了事务,随后老婆将我的当月信用卡消费的明细打印到A4纸上,却发现消费总额为1080元,老婆很诧异,以为出现了幻觉,幻读就这样产生了。
(4)串行化:可避免脏读、不可重复读、幻读的发生。
6.MyIsam引擎与InnoDB引擎的区别(正在施工)
7.mysql日志
(1)错误日志
错误日志是MySQL中最重要的日志之一,它记录了当mysqld启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关信息。当数据库出现任何故障导致无法正常使用时,可以首先查看此日志。
可以用–log-error[=file_name]选项来指定mysqld(MySQL服务器)保存错误日志文件的位置。如果没有给定file_name值,mysqld使用错误日志名host_name.err(host_name为主机名)并默认在参数DATADIR(数据目录)指定的目录中写入日志文件。
(2)二进制日志(binlog)
二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但是不包括数据查询语句。语句以“事件”的形式保存,它描述了数据的更改过程。此日志对于灾难时的数据恢复起着极其重要的作用。
MySQL 5.5中,二进制日志的格式分为 3种:STATEMENT、ROW、MIXED,可以在启动时通过参数-- binlog_format进行设置,这 3种格式的区别如下。
- STATEMENT:,日志中记录的都是语句(statement),每一条对数据造成修改的SQL语句都会记录在日志中。主从复制的时候,从库(slave)会将日志解析为原文本,并在从库重新执行一次。这种格式的优点是日志记录清晰易读、日志量少,对I/O影响较小。缺点是在某些情况下slave的日志复制会出错。
- ROW:MySQL 5.1.11之后,出现了这种新的日志格式。它将每一行的变更记录到日志中,而不是记录SQL语句。比如一个简单的更新SQL:update emp set name=‘abc’,如果是STATEMENT格式,日志中会记录一行SQL文本;如果是ROW,由于是对全表进行更新,也就是每一行记录都会发生变更,如果是一个100万行的大表,则日志中会记录100万条记录的变化情况。日志量大大增加。这种格式的优点是会记录每一行数据的变化细节,不会出现某些情况下无法复制的情况。缺点是日志量大,对I/O影响较大
- MIXED:这是目前MySQL默认的日志格式,即混合了STATEMENT和ROW两种日志。默认情况下采用STATEMENT,但在一些特殊情况下采用ROW来进行记录,比如采用NDB存储引擎,此时对表的DML语句全部采用ROW;客户端使用了临时表;客户端采用了不确定函数,比如current_user()等,因为这种不确定函数在主从中得到的值可能不同,导致主从数据产生不一致。MIXED格式能尽量利用两种模式的优点,而避开它们的缺点。
(3)查询日志
查询日志记录了客户端的所有语句,而二进制日志不包含只查询数据的语句
(4)慢查询日志
慢查询日志记录了所有执行时间超过参数long_query_time(单位:秒)设置值并且扫描记录数不小于min_examined_row_limit的所有SQL语句的日志(注意,获得表锁定的时间不算作执行时间)。long_query_time默认为10秒,最小为0,精度可以到微秒。
在默认情况下,有两类常见语句不会记录到慢查询日志:管理语句和不使用索引进行查询的语句。这里的管理语句包括 ALTER TABLE、ANALYZE TABLE、CHECK TABLE、CREATE INDEX、 DROP INDEX、OPTIMIZE TABLE和REPAIR TABLE。如果要监控这两类SQL语句,可以分别通过参数–log-slow-admin-statements和log_queries_not_using_indexes进行控制。
8. mvcc
三、Redis
1.redis分布式锁
如果涉及到分布式系统中的并发安全问题就要用到分布式锁,分布式锁要保证以下几个特性。
-
互斥性。互斥是锁的基本特征,同一时刻锁只能被一个线程持有,执行临界区操作。
-
超时释放。通过超时释放,可以避免死锁,防止不必要的线程等待和资源浪费,类似于 MySQL 的 InnoDB 引擎中的 innodblockwait_timeout 参数配置。
-
可重入性。一个线程在持有锁的情况可以对其再次请求加锁,防止锁在线程执行完临界区操作之前释放。
-
高性能和高可用。加锁和释放锁的过程性能开销要尽可能的低,同时也要保证高可用,防止分布式锁意外失效。
使用 Redis 作为分布式锁,本质上要实现的目标就是一个进程在 Redis 里面占据了仅有的一个“茅坑”,当别的进程也想来占坑时,发现已经有人蹲在那里了,就只好放弃或者等待稍后再试。
最简单的加锁方式就是直接使用 Redis 的 SETNX 指令,该指令只在 key 不存在的情况下,将 key 的值设置为 value,若 key 已经存在,则 SETNX 命令不做任何动作。key 是锁的唯一标识,可以按照业务需要锁定的资源来命名。
比如在某商城的秒杀活动中对某一商品加锁,那么 key 可以设置为 lock_resource_id ,value 可以设置为任意值,在资源使用完成后,使用 DEL 删除该 key 对锁进行释放,整个过程如下:

很显然,这种获取锁的方式很简单,但也存在一个问题,就是我们上面提到的分布式锁三个核心要素之一的锁超时问题,即如果获得锁的进程在业务逻辑处理过程中出现了异常,可能会导致 DEL 指令一直无法执行,导致锁无法释放,该资源将会永远被锁住。
所以,在使用 SETNX 拿到锁以后,必须给 key 设置一个过期时间,以保证即使没有被显式释放,在获取锁达到一定时间后也要自动释放,防止资源被长时间独占。由于 SETNX 不支持设置过期时间,所以需要额外的 EXPIRE 指令,整个过程如下:

这样实现的分布式锁仍然存在一个严重的问题,由于 SETNX 和 EXPIRE 这两个操作是非原子性的, 如果进程在执行 SETNX 和 EXPIRE 之间发生异常,SETNX 执行成功,但 EXPIRE 没有执行,导致这把锁变得“长生不老”,这种情况就可能出现前文提到的锁超时问题,其他进程无法正常获取锁。
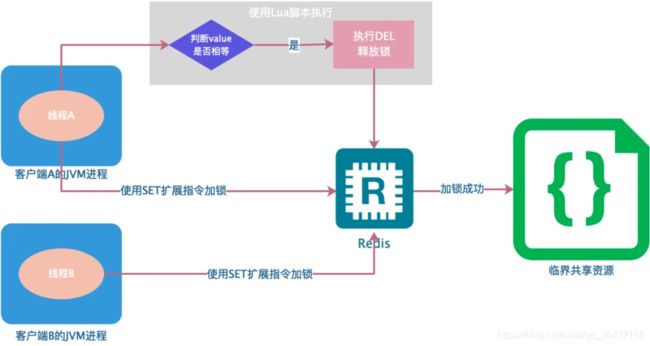
为了解决 SETNX 和 EXPIRE 两个操作非原子性的问题,可以使用 Redis 的 SET 指令的扩展参数,使得 SETNX 和 EXPIRE 这两个操作可以原子执行,整个过程如下

在这个 SET 指令中:
- NX 表示只有当 lock_resource_id 对应的 key 值不存在的时候才能 SET 成功。保证了只有第一个请求的客户端才能获得锁,而其它客户端在锁被释放之前都无法获得锁。
- EX 10 表示这个锁 10 秒钟后会自动过期,业务可以根据实际情况设置这个时间的大小。
但是这种方式仍然不能彻底解决分布式锁超时问题:
-
锁被提前释放。假如线程 A 在加锁和释放锁之间的逻辑执行的时间过长(或者线程 A 执行过程中被堵塞),以至于超出了锁的过期时间后进行了释放,但线程 A 在临界区的逻辑还没有执行完,那么这时候线程 B 就可以提前重新获取这把锁,导致临界区代码不能严格的串行执行。
-
锁被误删。假如以上情形中的线程 A 执行完后,它并不知道此时的锁持有者是线程 B,线程 A 会继续执行 DEL 指令来释放锁,如果线程 B 在临界区的逻辑还没有执行完,线程 A 实际上释放了线程 B 的锁。
为了避免以上情况,建议不要在执行时间过长的场景中使用 Redis 分布式锁,同时一个比较安全的做法是在执行 DEL 释放锁之前对锁进行判断,验证当前锁的持有者是否是自己。
具体实现就是在加锁时将 value 设置为一个唯一的随机数(或者线程 ID ),释放锁时先判断随机数是否一致,然后再执行释放操作,确保不会错误地释放其它线程持有的锁,除非是锁过期了被服务器自动释放,整个过程如下:

但判断 value 和删除 key 是两个独立的操作,并不是原子性的,所以这个地方需要使用 Lua 脚本进行处理,因为 Lua 脚本可以保证连续多个指令的原子性执行。

- 程序计数器(Program Counter Register)是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。在虚拟机的概念模型里,字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。线程私有。
- Java虚拟机栈(Java Virtual Machine Stacks)也是线程私有的,它的生命周期与线程相同。虚拟机栈描述的是Java方法执行的内存模型:每个方法在执行的同时都会创建一个栈帧用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。局部变量表存放了编译期可知的各种基本数据类型、对象引用和returnAddress类型(指向了一条字节码指令的地址)。如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常;如果虚拟机栈可以动态扩展,并且扩展时无法申请到足够的内存,就会抛出OutOfMemoryError异常。
- 本地方法栈(Native Method Stack)与虚拟机栈所发挥的作用是非常相似的,它们之间的区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的Native方法服务。与虚拟机栈一样,本地方法栈区域也会抛出StackOverflowError和OutOfMemoryError异常。
- Java堆(Java Heap)是Java虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。
- 方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
2 redis数据结构(正在施工)
redis中的数据结构有字符串、链表、字典、有序集合、整数集合、压缩列表。
有序集合的底层
有序集合的底层是跳表,在大部分情况下,跳跃表的效率可以和平衡树相媲美,并且因为跳跃表的实现比平衡树要来得更为简单。
下图是一个简单的有序单链表,单链表的特性就是每个元素存放下一个元素的引用。即:通过第一个元素可以找到第二个元素,通过第二个元素可以找到第三个元素,依次类推,直到找到最后一个元素。
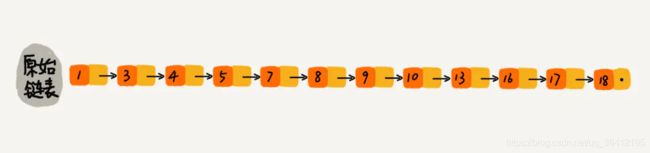
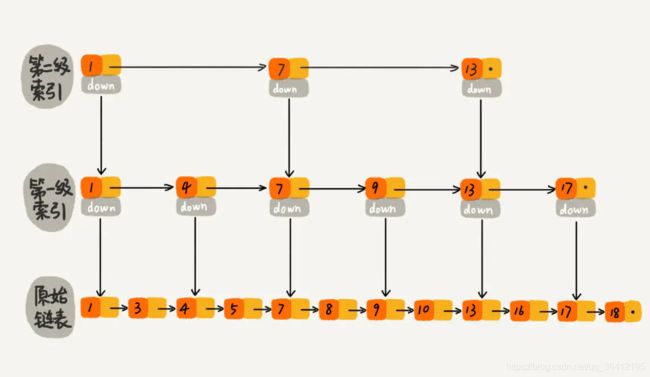
现在我们有个场景,想快速找到上图链表中的 10 这个元素,只能从头开始遍历链表,直到找到我们需要找的元素。查找路径:1、3、4、5、7、8、9、10。这样的查找效率很低,平均时间复杂度很高O(n)。那有没有办法提高链表的查找速度呢?如下图所示,我们从链表中每两个元素抽出来,加一级索引,一级索引指向了原始链表,即:通过一级索引 7 的down指针可以找到原始链表的 7 。那现在怎么查找 10 这个元素呢?
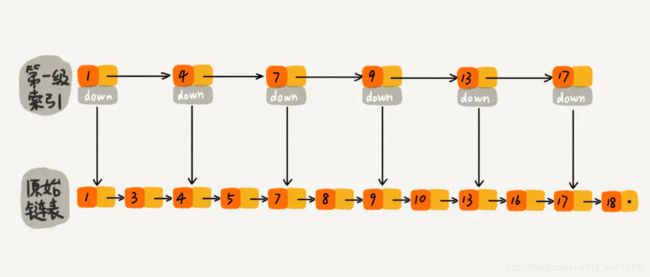
跳表-一级索引.jpeg
先在索引找 1、4、7、9,遍历到一级索引的 9 时,发现 9 的后继节点是 13,比 10 大,于是不往后找了,而是通过 9 找到原始链表的 9,然后再往后遍历找到了我们要找的 10,遍历结束。有没有发现,加了一级索引后,查找路径:1、4、7、9、10,查找节点需要遍历的元素相对少了,我们不需要对 10 之前的所有数据都遍历,查找的效率提升了。
那如果加二级索引呢?如下图所示,查找路径:1、7、9、10。是不是找 10 的效率更高了?这就是跳表的思想,用“空间换时间”,通过给链表建立索引,提高了查找的效率。
可能同学们会想,从上面案例来看,提升的效率并不明显,本来需要遍历8个元素,优化了半天,还需要遍历 4 个元素,其实是因为我们的数据量太少了,当数据量足够大时,效率提升会很大。如下图所示,假如有序单链表现在有1万个元素,分别是 0~9999。现在我们建了很多级索引,最高级的索引,就两个元素 0、5000,次高级索引四个元素 0、2500、5000、7500,依次类推,当我们查找 7890 这个元素时,查找路径为 0、5000、7500 … 7890,通过最高级索引直接跳过了5000个元素,次高层索引直接跳过了2500个元素,从而使得链表能够实现二分查找。由此可以看出,当元素数量较多时,索引提高的效率比较大,近似于二分查找。

到这里大家应该已经明白了什么是跳表。跳表是可以实现二分查找的有序链表。
既然跳表可以提升链表查找元素的效率,那查找一个元素的时间复杂度到底是多少呢?查找元素的过程是从最高级索引开始,一层一层遍历最后下沉到原始链表。所以,时间复杂度 = 索引的高度 * 每层索引遍历元素的个数。
先来求跳表的索引高度。如下图所示,假设每两个结点会抽出一个结点作为上一级索引的结点,原始的链表有n个元素,则一级索引有n/2 个元素、二级索引有 n/4 个元素、k级索引就有 n/2k个元素。最高级索引一般有2个元素,即:最高级索引 h 满足 2 = n/2h,即 h = log2n - 1,最高级索引 h 为索引层的高度加上原始数据一层,跳表的总高度 h = log2n。
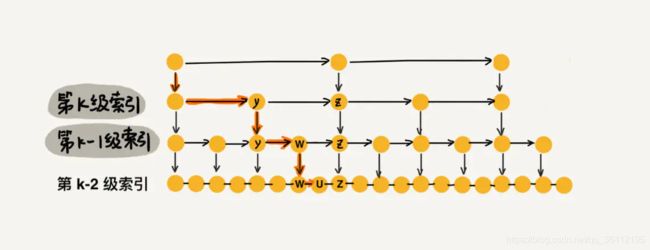
我们看上图中加粗的箭头,表示查找元素 x 的路径,那查找过程中每一层索引最多遍历几个元素呢?
图中所示,现在到达第 k 级索引,我们发现要查找的元素 x 比 y 大比 z 小,所以,我们需要从 y 处下降到 k-1 级索引继续查找,k-1级索引中比 y 大比 z 小的只有一个 w,所以在 k-1 级索引中,我们遍历的元素最多就是 y、w、z,发现 x 比 w大比 z 小之后,再下降到 k-2 级索引。所以,k-2 级索引最多遍历的元素为 w、u、z。其实每级索引都是类似的道理,每级索引中都是两个结点抽出一个结点作为上一级索引的结点。 现在我们得出结论:当每级索引都是两个结点抽出一个结点作为上一级索引的结点时,每一层最多遍历3个结点.
跳表的索引高度 h = log2n,且每层索引最多遍历 3 个元素。所以跳表中查找一个元素的时间复杂度为 O(3*logn),省略常数即:O(logn)。
跳表通过建立索引,来提高查找元素的效率,就是典型的“空间换时间”的思想,所以在空间上做了一些牺牲,那空间复杂度到底是多少呢?
假如原始链表包含 n 个元素,则一级索引元素个数为 n/2、二级索引元素个数为 n/4、三级索引元素个数为 n/8 以此类推。所以,索引节点的总和是:n/2 + n/4 + n/8 + … + 8 + 4 + 2 = n-2,空间复杂度是 O(n)
往跳表中插入数据可能会导致两个索引结点数据非常多的情况,从而导致跳表退化成单表。比较容易理解的做法就是完全重建索引,我们每次插入数据后,都把这个跳表的索引删掉全部重建,重建索引的时间复杂度是多少呢?因为索引的空间复杂度是 O(n),即:索引节点的个数是 O(n) 级别,每次完全重新建一个 O(n) 级别的索引,时间复杂度也是 O(n) 。造成的后果是:为了维护索引,导致每次插入数据的时间复杂度变成了 O(n)。
那有没有其他效率比较高的方式来维护索引呢?假如跳表每一层的晋升概率是 1/2,最理想的索引就是在原始链表中每隔一个元素抽取一个元素做为一级索引。换种说法,我们在原始链表中随机的选 n/2 个元素做为一级索引是不是也能通过索引提高查找的效率呢? 当然可以了,因为一般随机选的元素相对来说都是比较均匀的。如下图所示,随机选择了n/2 个元素做为一级索引,虽然不是每隔一个元素抽取一个,但是对于查找效率来讲,影响不大,比如我们想找元素 16,仍然可以通过一级索引,使得遍历路径较少了将近一半。如果抽取的一级索引的元素恰好是前一半的元素 1、3、4、5、7、8,那么查找效率确实没有提升,但是这样的概率太小了。我们可以认为:当原始链表中元素数量足够大,且抽取足够随机的话,我们得到的索引是均匀的。我们要清楚设计良好的数据结构都是为了应对大数据量的场景,如果原始链表只有 5 个元素,那么依次遍历 5 个元素也没有关系,因为数据量太少了。所以,我们可以维护一个这样的索引:随机选 n/2 个元素做为一级索引、随机选 n/4 个元素做为二级索引、随机选 n/8 个元素做为三级索引,依次类推,一直到最顶层索引。这里每层索引的元素个数已经确定,且每层索引元素选取的足够随机,所以可以通过索引来提升跳表的查找效率。
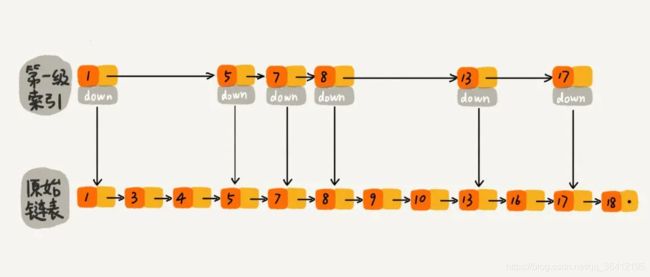
那代码该如何实现,才能使跳表满足上述这个样子呢?可以在每次新插入元素的时候,尽量让该元素有 1/2 的几率建立一级索引、1/4 的几率建立二级索引、1/8 的几率建立三级索引,以此类推,就能满足我们上面的条件。现在我们就需要一个概率算法帮我们把控这个 1/2、1/4、1/8 … ,当每次有数据要插入时,先通过概率算法告诉我们这个元素需要插入到几级索引中,然后开始维护索引并把数据插入到原始链表中。
我们可以实现一个 randomLevel() 方法,该方法会随机生成 1~MAX_LEVEL 之间的数(MAX_LEVEL表示索引的最高层数),且该方法有 1/2 的概率返回 1、1/4 的概率返回 2、1/8的概率返回 3,以此类推。
- randomLevel() 方法返回 1 表示当前插入的该元素不需要建索引,只需要存储数据到原始链表即可(概率 1/2)
- randomLevel() 方法返回 2 表示当前插入的该元素需要建一级索引(概率 1/4)
- randomLevel() 方法返回 3 表示当前插入的该元素需要建二级索引(概率 1/8)
- randomLevel() 方法返回 4 表示当前插入的该元素需要建三级索引(概率 1/16)
- 。。。以此类推
所以,通过 randomLevel() 方法,我们可以控制整个跳表各级索引中元素的个数。重点来了:randomLevel() 方法返回 2 的时候会建立一级索引,我们想要一级索引中元素个数占原始数据的 1/2,但是 randomLevel() 方法返回 2 的概率为 1/4,那是不是有矛盾呢?明明说好的 1/2,结果一级索引元素个数怎么变成了原始链表的 1/4?我们先看下图,应该就明白了。
假设我们在插入元素 6 的时候,randomLevel() 方法返回 1,则我们不会为 6 建立索引。插入 7 的时候,randomLevel() 方法返回3 ,所以我们需要为元素 7 建立二级索引。这里我们发现了一个特点:当建立二级索引的时候,同时也会建立一级索引;当建立三级索引时,同时也会建立一级、二级索引。所以,一级索引中元素的个数等于 [ 原始链表元素个数 ] * [ randomLevel() 方法返回值 > 1 的概率 ]。因为 randomLevel() 方法返回值 > 1就会建索引,凡是建索引,无论几级索引必然有一级索引,所以一级索引中元素个数占原始数据个数的比率为 randomLevel() 方法返回值 > 1 的概率。那 randomLevel() 方法返回值 > 1 的概率是多少呢?因为 randomLevel() 方法随机生成 1~MAX_LEVEL 的数字,且 randomLevel() 方法返回值 1 的概率为 1/2,则 randomLevel() 方法返回值 > 1 的概率为 1 - 1/2 = 1/2。即通过上述流程实现了一级索引中元素个数占原始数据个数的 1/2。
同理,当 randomLevel() 方法返回值 > 2 时,会建立二级或二级以上索引,都会在二级索引中增加元素,因此二级索引中元素个数占原始数据的比率为 randomLevel() 方法返回值 > 2 的概率。 randomLevel() 方法返回值 > 2 的概率为 1 减去 randomLevel() = 1 或 =2 的概率,即 1 - 1/2 - 1/4 = 1/4。OK,达到了我们设计的目标:二级索引中元素个数占原始数据的 1/4。
以此类推,可以得出,遵守以下两个条件:
- randomLevel() 方法,随机生成 1~MAX_LEVEL 之间的数(MAX_LEVEL表示索引的最高层数),且有 1/2的概率返回 1、1/4的概率返回 2、1/8的概率返回 3 …
- randomLevel() 方法返回 1 不建索引、返回2建一级索引、返回 3 建二级索引、返回 4 建三级索引 …
就可以满足我们想要的结果,即:一级索引中元素个数应该占原始数据的 1/2,二级索引中元素个数占原始数据的 1/4,三级索引中元素个数占原始数据的 1/8 ,依次类推,一直到最顶层索引。
但是问题又来了,怎么设计这么一个 randomLevel() 方法呢?直接撸代码:
// 该 randomLevel 方法会随机生成 1~MAX_LEVEL 之间的数,且 :
// 1/2 的概率返回 1
// 1/4 的概率返回 2
// 1/8 的概率返回 3 以此类推
private int randomLevel() {
int level = 1;
// 当 level < MAX_LEVEL,且随机数小于设定的晋升概率时,level + 1
while (Math.random() < SKIPLIST_P && level < MAX_LEVEL)
level += 1;
return level;
}
整体思路大家应该明白了,那插入数据时维护索引的时间复杂度是多少呢?元素插入到单链表的时间复杂度为 O(1),我们索引的高度最多为 logn,当插入一个元素 x 时,最坏的情况就是元素 x 需要插入到每层索引中,所以插入数据到各层索引中,最坏时间复杂度是 O(logn)。
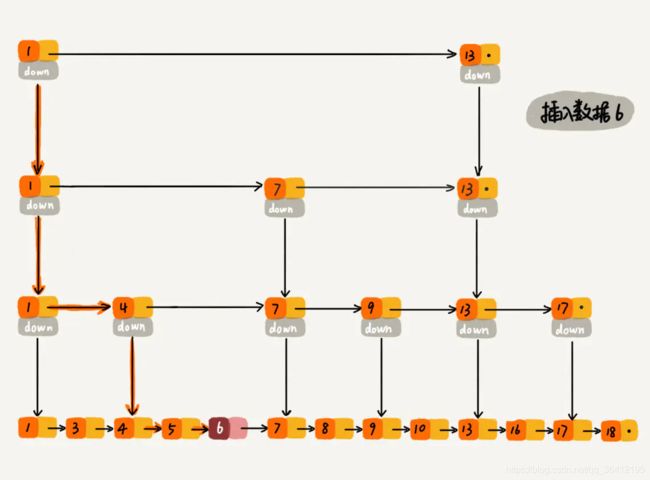
过程大概理解了,再通过一个例子描述一下跳表插入数据的全流程。现在我们要插入数据 6 到跳表中,首先 randomLevel() 返回 3,表示需要建二级索引,即:一级索引和二级索引需要增加元素 6。该跳表目前最高三级索引,首先找到三级索引的 1,发现 6 比 1大比 13小,所以,从 1 下沉到二级索引。
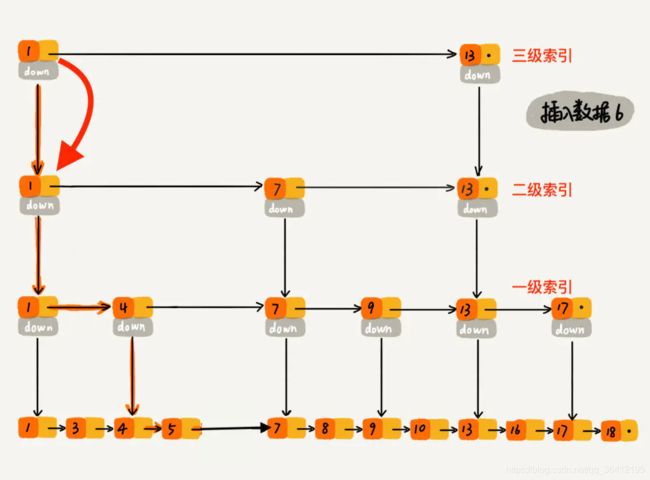
下沉到二级索引后,发现 6 比 1 大比 7 小,此时需要在二级索引中 1 和 7 之间加一个元素6 ,并从元素 1 继续下沉到一级索引。
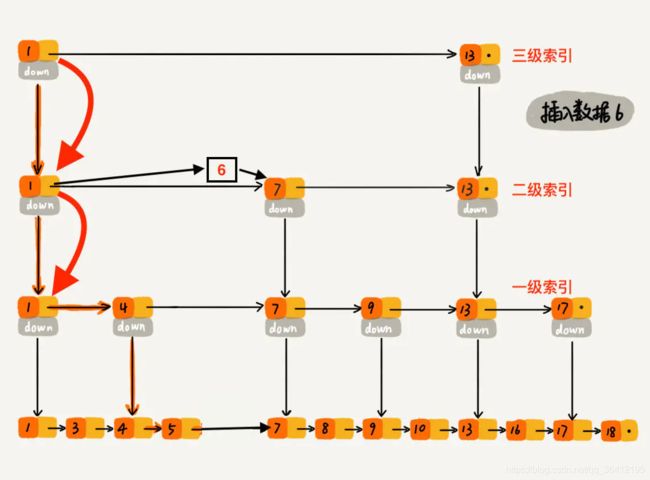
下沉到一级索引后,发现 6 比 1 大比 4 大,所以往后查找,发现 6 比 4 大比 7 小,此时需要在一级索引中 4 和 7 之间加一个元素 6 ,并把二级索引的 6 指向 一级索引的 6,最后,从元素 4 继续下沉到原始链表。
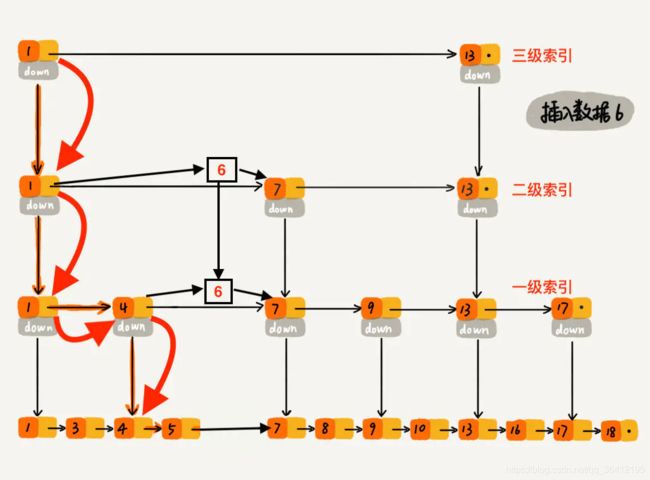
下沉到原始链表后,就比较简单了,发现 4、5 比 6小,7比6大,所以将6插入到 5 和 7 之间即可,整个插入过程结束。
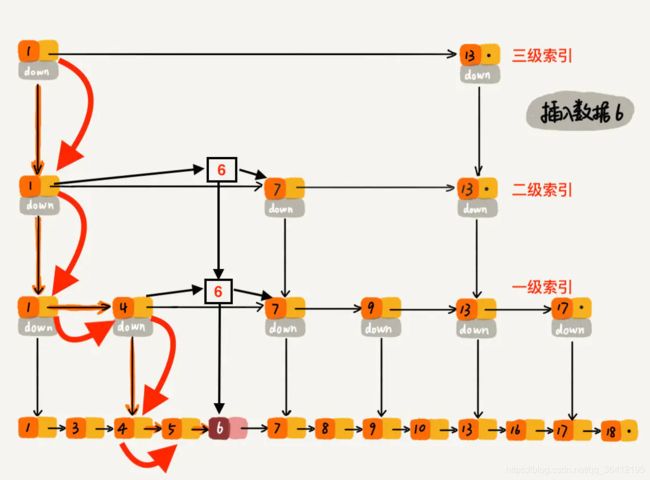
跳表删除数据时,要把索引中对应节点也要删掉。如下图所示,如果要删除元素 9,需要把原始链表中的 9 和第一级索引的 9 都删除掉。
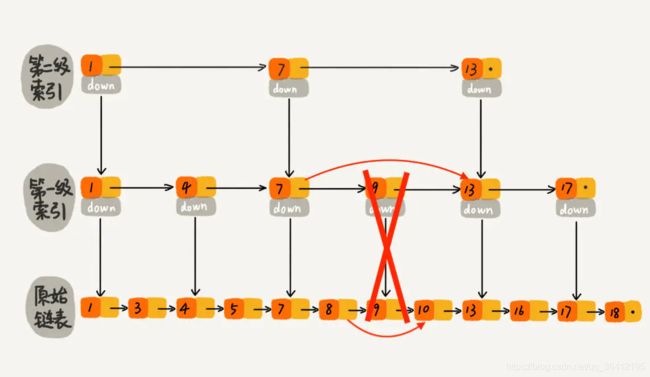
删除元素的过程跟查找元素的过程类似,只不过在查找的路径上如果发现了要删除的元素 x,则执行删除操作。跳表中,每一层索引其实都是一个有序的单链表,单链表删除元素的时间复杂度为 O(1),索引层数为 logn 表示最多需要删除 logn 个元素,所以删除元素的总时间包含 查找元素的时间 加 删除 logn个元素的时间 为 O(logn) + O(logn) = 2 O(logn),忽略常数部分,删除元素的时间复杂度为 O(logn)。
3. reids的过期键删除策略
Redis服务器实际使用的是惰性删除和定期删除两种策略:通过配合使用这两种删除策略,服务器可以很好地在合理使用CPU时间和避免浪费内存空间之间取得平衡。
惰性删除策略的实现
过期键的惰性删除策略由db.c/expireIfNeeded函数实现,所有读写数据库的Redis命令在执行之前都会调用expireIfNeeded函数对输入键进行检查:
- 如果输入键已经过期,那么expireIfNeeded函数将输入键从数据库中删除。
- 如果输入键未过期,那么expireIfNeeded函数不做动作。
expireIfNeeded函数就像一个过滤器,它可以在命令真正执行之前,过滤掉过期的输入键,从而避免命令接触到过期键。
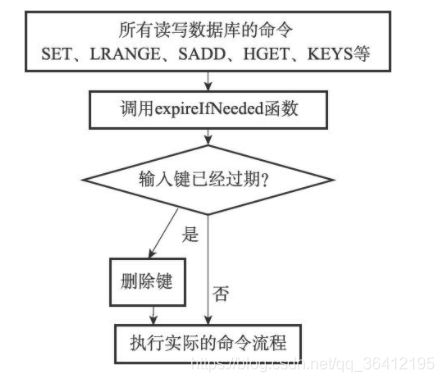
所以每个命令的实现函数都必须能同时处理键存在以及键不存在这两种情况:
- 当键存在时,命令按照键存在的情况执行。
- 当键不存在或者键因为过期而被expireIfNeeded函数删除时,命令按照键不存在的情况执行。
定期删除策略的实现
过期键的定期删除策略由redis.c/activeExpireCycle函数实现,每当Redis的服务器周期性操作redis.c/serverCron函数执行时,activeExpireCycle函数就会被调用,它在规定的时间内,分多次遍历服务器中的各个数据库,从数据库的expires字典中随机检查一部分键的过期时间,并删除其中的过期键。
整个过程可以用伪代码描述如下:

activeExpireCycle函数的工作模式可以总结如下:
- 函数每次运行时,都从一定数量的数据库中取出一定数量的随机键进行检查,并删除其中的过期键。
- 全局变量current_db会记录当前activeExpireCycle函数检查的进度,并在下一次activeExpireCycle函数调用时,接着上一次的进度进行处理。比如说,如果当前activeExpireCycle函数在遍历10号数据库时返回了,那么下次activeExpireCycle函数执行时,将从11号数据库开始查找并删除过期键。
- 随着activeExpireCycle函数的不断执行,服务器中的所有数据库都会被检查一遍,这时函数将current_db变量重置为0,然后再次开始新一轮的检查工作
4. redis文件处理器
Redis基于Reactor模式开发了自己的网络事件处理器:这个处理器被称为文件事件处理器(file event handler)
- 文件事件处理器使用I/O多路复用(multiplexing)程序来同时监听多个套接字,并根据套接字目前执行的任务来为套接字关联不同的事件处理器
- 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时,与操作相对应的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
下图展示了文件事件处理器的四个组成部分,它们分别是套接字、I/O多路复用程序、文件事件分派器(dispatcher),以及事件处理器。
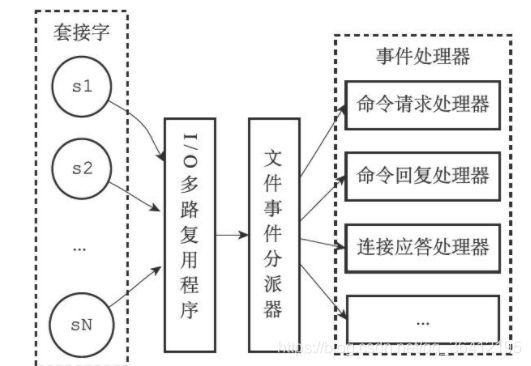
文件事件是对套接字操作的抽象,每当一个套接字准备好执行连接应答(accept)、写入、读取、关闭等操作时,就会产生一个文件事件。因为一个服务器通常会连接多个套接字,所以多个文件事件有可能会并发地出现。
I/O多路复用程序负责监听多个套接字,并向文件事件分派器传送那些产生了事件的套接字。尽管多个文件事件可能会并发地出现,但I/O多路复用程序总是会将所有产生事件的套接字都放到一个队列里面,然后通过这个队列,以有序(sequentially)、同步(synchronously)、每次一个套接字的方式向文件事件分派器传送套接字。

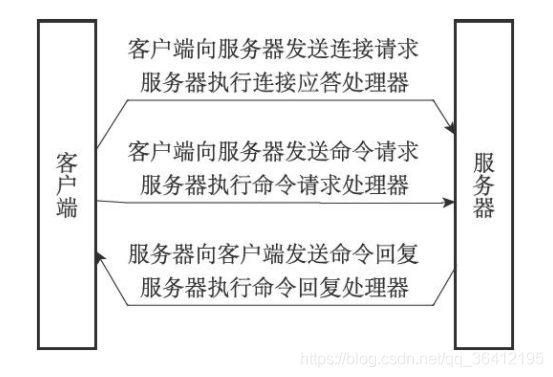
一次完整的客户端与服务端事件示例
假设一个Redis服务器正在运作,那么这个服务器的监听套接字的AE_READABLE事件应该正处于监听状态之下,而该事件所对应的处理器为连接应答处理器。
如果这时有一个Redis客户端向服务器发起连接,那么监听套接字将产生AE_READABLE事件,触发连接应答处理器执行。处理器会对客户端的连接请求进行应答,然后创建客户端套接字,以及客户端状态,并将客户端套接字的AE_READABLE事件与命令请求处理器进行关联,使得客户端可以向主服务器发送命令请求。
之后,假设客户端向主服务器发送一个命令请求,那么客户端套接字将产生AE_READABLE事件,引发命令请求处理器执行,处理器读取客户端的命令内容,然后传给相关程序去执行。
执行命令将产生相应的命令回复,为了将这些命令回复传送回客户端,服务器会将客户端套接字的AE_WRITABLE事件与命令回复处理器进行关联。当客户端尝试读取命令回复的时候,客户端套接字将产生AE_WRITABLE事件,触发命令回复处理器执行,当命令回复处理器将命令回复全部写入到套接字之后,服务器就会解除客户端套接字的AE_WRITABLE事件与命令回复处理器之间的关联。
5 redis集群
节点
一个Redis集群通常由多个节点(node)组成,在刚开始的时候,每个节点都是相互独立的,它们都处于一个只包含自己的集群当中,要组建一个真正可工作的集群,我们必须将各个独立的节点连接起来,构成一个包含多个节点的集群。
连接各个节点的工作可以使用CLUSTER MEET命令来完成,向一个节点node发送CLUSTER MEET命令,可以让node节点与ip和port所指定的节点进行握手(handshake),当握手成功时,node节点就会将ip和port所指定的节点添加到node节点当前所在的集群中。
每个节点都会使用一个clusterNode结构来记录自己的状态,并为集群中的所有其他节点(包括主节点和从节点)都创建一个相应的clusterNode结构,以此来记录其他节点的状态:

clusterNode结构的link属性是一个clusterLink结构,该结构保存了连接节点所需的有关信息,比如套接字描述符,输入缓冲区和输出缓冲区:
角下,集群目前所处的状态,例如集群是在线还是下线,集群包含多少个节点,集群当前的配置纪元,诸如此类:

槽指派
Redis集群通过分片的方式来保存数据库中的键值对:集群的整个数据库被分为16384个槽(slot),数据库中的每个键都属于这16384个槽的其中一个,集群中的每个节点可以处理0个或最多16384个槽。
当数据库中的16384个槽都有节点在处理时,集群处于上线状态(ok);相反地,如果数据库中有任何一个槽没有得到处理,那么集群处于下线状态(fail)。
通过向节点发送CLUSTER ADDSLOTS命令,我们可以将一个或多个槽指派(assign)给节点负责:
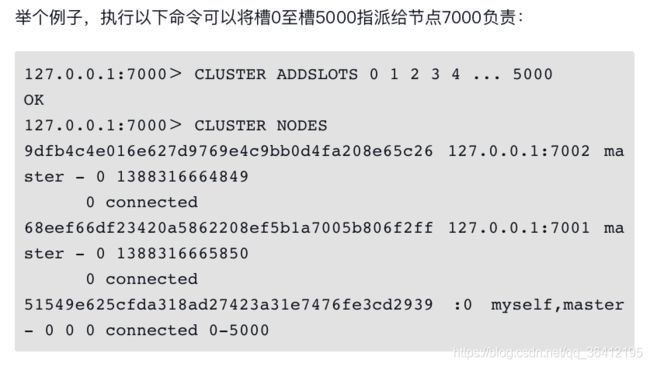
一个节点除了会将自己负责处理的槽记录在clusterNode结构的slots属性和numslots属性之外,它还会将自己的slots数组通过消息发送给集群中的其他节点,以此来告知其他节点自己目前负责处理哪些槽
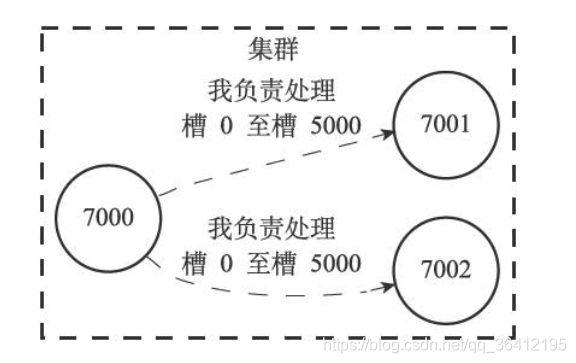
clusterState结构中的slots数组记录了集群中所有16384个槽的指派信息:
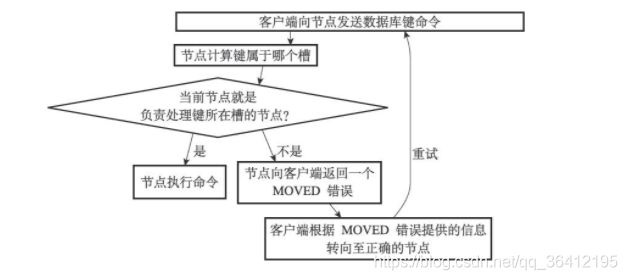
在集群中执行命令
在对数据库中的16384个槽都进行了指派之后,集群就会进入上线状态,这时客户端就可以向集群中的节点发送数据命令了,当客户端向节点发送与数据库键有关的命令时,接收命令的节点会计算出命令要处理的数据库键属于哪个槽,并检查这个槽是否指派给了自己
- 如果键所在的槽正好就指派给了当前节点,那么节点直接执行这个命令。
- 如果键所在的槽并没有指派给当前节点,那么节点会向客户端返回一个MOVED错误,指引客户端转向(redirect)至正确的节点,并再次发送之前想要执行的命令。
复制与故障转移
Redis集群中的节点分为主节点(master)和从节点(slave),其中主节点用于处理槽,而从节点则用于复制某个主节点,并在被复制的主节点下线时,代替下线主节点继续处理命令请求。
举个例子,对于包含7000、7001、7002、7003四个主节点的集群来说,我们可以将7004、7005两个节点添加到集群里面,并将这两个节点设定为节点7000的从节点,如图17-32所示(图中以双圆形表示主节点,单圆形表示从节点)。
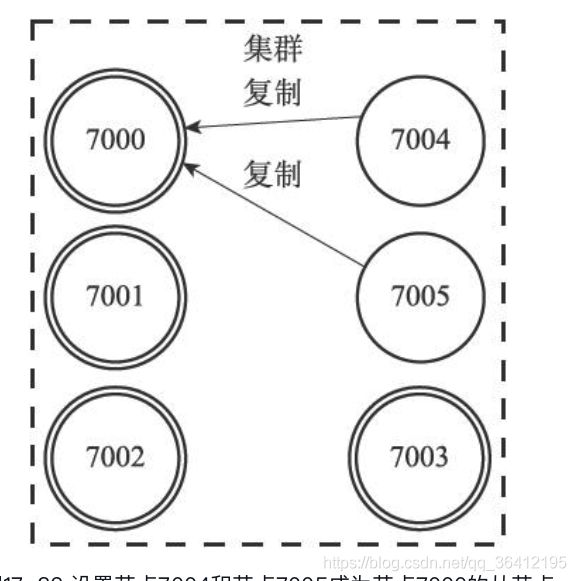
如果这时,节点7000进入下线状态,那么集群中仍在正常运作的几个主节点将在节点7000的两个从节点——节点7004和节点7005中选出一个节点作为新的主节点,这个新的主节点将接管原来节点7000负责处理的槽,并继续处理客户端发送的命令请求。
例如,如果节点7004被选中为新的主节点,那么节点7004将接管原来由节点7000负责处理的槽0至槽5000,节点7005也会从原来的复制节点7000,改为复制节点7004,如图17-33所示(图中用虚线包围的节点为已下线节点)。
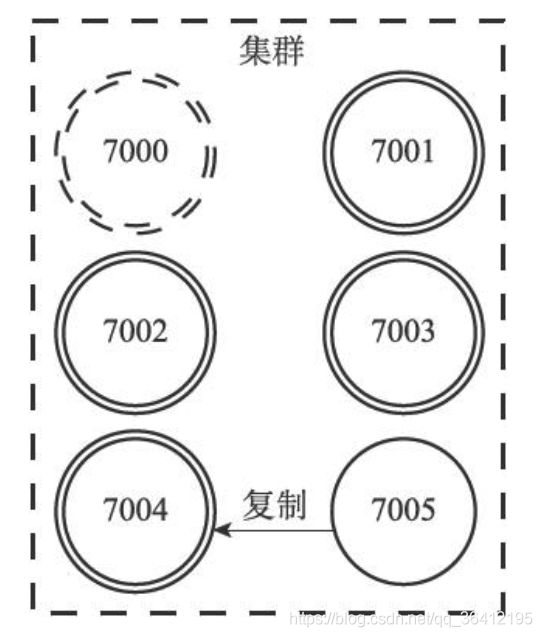
如果在故障转移完成之后,下线的节点7000重新上线,那么它将成为节点7004的从节点
6. 主从复制
Redis的复制功能分为**同步(sync)和命令传播(command propagate)**两个操作:
- 同步:同步操作用于将从服务器的数据库状态更新至主服务器当前所处的数据库状态。
- 命令传播:命令传播操作则用于在主服务器的数据库状态被修改,导致主从服务器的数据库状态出现不一致时,让主从服务器的数据库重新回到一致状态。
同步
当客户端向从服务器发送SLAVEOF命令,要求从服务器复制主服务器时,从服务器首先需要执行同步操作,也即是,将从服务器的数据库状态更新至主服务器当前所处的数据库状态。
(1)从服务器向主服务器发送SYNC命令。
(2)收到SYNC命令的主服务器执行BGSAVE命令,在后台生成一个RDB文件,并使用一个缓冲区记录从现在开始执行的所有写命令
(3)当主服务器的BGSAVE命令执行完毕时,主服务器会将BGSAVE命令生成的RDB文件发送给从服务器,从服务器接收并载入这个RDB文件,将自己的数据库状态更新至主服务器执行BGSAVE命令时的数据库状态。
(4)主服务器将记录在缓冲区里面的所有写命令发送给从服务器,从服务器执行这些写命令,将自己的数据库状态更新至主服务器数据库当前所处的状态。

命令传播
在同步操作执行完毕之后,主从服务器两者的数据库将达到一致状态,但这种一致并不是一成不变的,每当主服务器执行客户端发送的写命令时,主服务器的数据库就有可能会被修改,并导致主从服务器状态不再一致。
为了让主从服务器再次回到一致状态,主服务器需要对从服务器执行命令传播操作:主服务器会将自己执行的写命令,也即是造成主从服务器不一致的那条写命令,发送给从服务器执行,当从服务器执行了相同的写命令之后,主从服务器将再次回到一致状态。
从服务器对主服务器的复制可以分为以下两种情况
- 初次复制:从服务器以前没有复制过任何主服务器,或者从服务器当前要复制的主服务器和上一次复制的主服务器不同。
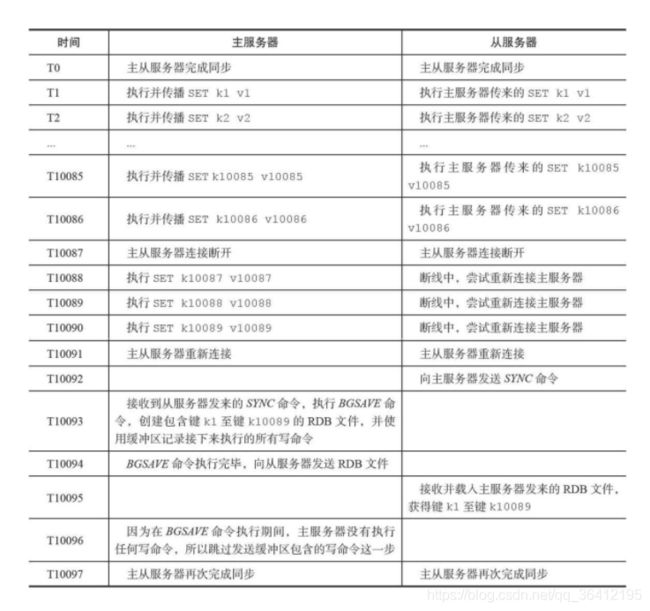
- 断线后重复制:处于命令传播阶段的主从服务器因为网络原因而中断了复制,但从服务器通过自动重连接重新连上了主服务器,并继续复制主服务器。
旧版的断线后重复制如下所示:
新版复制功能的实现
为了解决旧版复制功能在处理断线重复制情况时的低效问题,Redis从2.8版本开始,使用PSYNC命令代替SYNC命令来执行复制时的同步操作。
PSYNC命令具有完整重同步和部分重同步两种模式:
- 完整重同步:用于处理初次复制情况:完整重同步的执行步骤和SYNC命令的执行步骤基本一样,它们都是通过让主服务器创建并发送RDB文件,以及向从服务器发送保存在缓冲区里面的写命令来进行同步。
- 部分重同步:用于处理断线后重复制情况:当从服务器在断线后重新连接主服务器时,如果条件允许,主服务器可以将主从服务器连接断开期间执行的写命令发送给从服务器,从服务器只要接收并执行这些写命令,就可以将数据库更新至主服务器当前所处的状态。
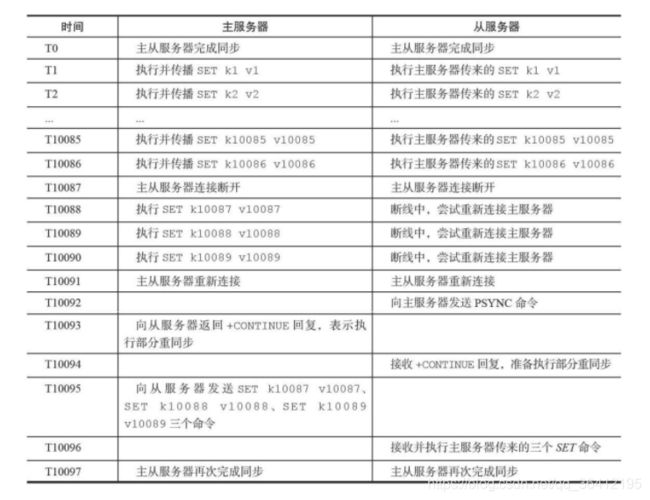
部分重同步实现细节
部分重同步功能由以下三个部分构;
- 主服务器的复制偏移量(replication offset)和从服务器的复制偏移量。
- 主服务器的复制积压缓冲区(replication backlog)。
- 服务器的运行ID(run ID)。
复制偏移量
- 主服务器每次向从服务器传播N个字节的数据时,就将自己的复制偏移量的值加上N。
- 从服务器每次收到主服务器传播来的N个字节的数据时,就将自己的复制偏移量的值加上N。
在图15-7所示的例子中,主从服务器的复制偏移量的值都为10086。

如果这时主服务器向三个从服务器传播长度为33字节的数据,那么主服务器的复制偏移量将更新为10086+33=10119,而三个从服务器在接收到主服务器传播的数据之后,也会将复制偏移量更新为10119
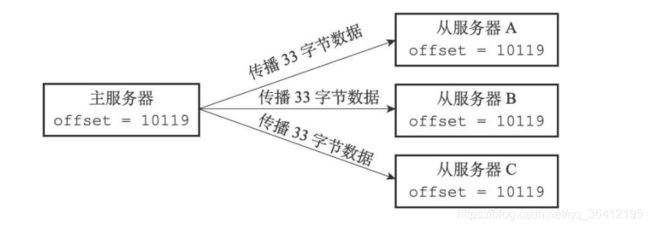
如果这时主服务器向三个从服务器传播长度为33字节的数据,那么主服务器的复制偏移量将更新为10086+33=10119,而三个从服务器在接收到主服务器传播的数据之后,也会将复制偏移量更新为10119
复制积压缓冲区
复制积压缓冲区是由主服务器维护的一个固定长度(fixed-size)先进先出(FIFO)队列,默认大小为1MB。当主服务器进行命令传播时,它不仅会将写命令发送给所有从服务器,还会将写命令入队到复制积压缓冲区里面,因此,主服务器的复制积压缓冲区里面会保存着一部分最近传播的写命令,并且复制积压缓冲区会为队列中的每个字节记录相应的复制偏移量,就像表15-4展示的那样。

当从服务器重新连上主服务器时,从服务器会通过PSYNC命令将自己的复制偏移量offset发送给主服务器,主服务器会根据这个复制偏移量来决定对从服务器执行何种同步操作
- 如果offset偏移量之后的数据(也即是偏移量offset+1开始的数据)仍然存在于复制积压缓冲区里面,那么主服务器将对从服务器执行部分重同步操作。
- 相反,如果offset偏移量之后的数据已经不存在于复制积压缓冲区,那么主服务器将对从服务器执行完整重同步操作。
服务器运行ID
除了复制偏移量和复制积压缓冲区之外,实现部分重同步还需要用到服务器运行ID(run ID):
- 每个Redis服务器,不论主服务器还是从服务,都会有自己的运行ID。
- 运行ID在服务器启动时自动生成,由40个随机的十六进制字符组成,例如53b9b28df8042fdc9ab5e3fcbbbabff1d5dce2b3。
当从服务器对主服务器进行初次复制时,主服务器会将自己的运行ID传送给从服务器,而从服务器则会将这个运行ID保存起来。
当从服务器断线并重新连上一个主服务器时,从服务器将向当前连接的主服务器发送之前保存的运行ID:
- 如果从服务器保存的运行ID和当前连接的主服务器的运行ID相同,那么说明从服务器断线之前复制的就是当前连接的这个主服务器,主服务器可以继续尝试执行部分重同步操作。
- 相反地,如果从服务器保存的运行ID和当前连接的主服务器的运行ID并不相同,那么说明从服务器断线之前复制的主服务器并不是当前连接的这个主服务器,主服务器将对从服务器执行完整重同步操作。
7. redis淘汰策略
长期将Redis作为缓存使用,难免会遇到内存空间存储瓶颈,当Redis内存超出物理内存限制时,内存数据就会与磁盘产生频繁交换,使Redis性能急剧下降。此时如何淘汰无用数据释放空间,存储新数据就变得尤为重要了。
当前Redis3.0版本支持的淘汰策略有6种:
- volatile-lru:从设置过期时间的数据集(server.db[i].expires)中挑选出最近最少使用的数据淘汰。没有设置过期时间的key不会被淘汰,这样就可以在增加内存空间的同时保证需要持久化的数据不会丢失。
- volatile-ttl:除了淘汰机制采用LRU,策略基本上与volatile-lru相似,从设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰,ttl值越大越优先被淘汰。
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰。当内存达到限制无法写入非过期时间的数据集时,可以通过该淘汰策略在主键空间中随机移除某个key。
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰,该策略要淘汰的key面向的是全体key集合,而非过期的key集合。
- allkeys-random:从数据集(server.db[i].dict)中选择任意数据淘汰。
- no-enviction:禁止驱逐数据,也就是当内存不足以容纳新入数据时,新写入操作就会报错,请求可以继续进行,线上任务也不能持续进行,采用no-enviction策略可以保证数据不被丢失,这也是系统默认的一种淘汰策略。
我们知道,LRU算法需要一个双向链表来记录数据的最近被访问顺序,但是出于节省内存的考虑,Redis的LRU算法并非完整的实现。Redis并不会选择最久未被访问的键进行回收,相反它会尝试运行一个近似LRU的算法,通过对少量键进行取样,然后回收其中的最久未被访问的键。通过调整每次回收时的采样数量maxmemory-samples,可以实现调整算法的精度。
四、设计模式
4.1 单例模式
1、懒汉式
public class Singleton {
// 静态字段引用唯一实例:
private static final volatile Singleton INSTANCE = new Singleton();
// 通过静态方法返回实例:
public static Singleton getInstance() {
if(INSTANCE == null){
syncronized(this.class){
if(INSTANCE==null){
INSTANCE = new Singleton();
}
}
}
return INSTANCE;
}
// private构造方法保证外部无法实例化:
private Singleton() {
}
}
2、饿汉式
public class Singleton {
public static final LazyHolder {
private static final Singleton INSTANCE = new Singleton();
}
// private构造方法保证外部无法实例化:
private Singleton() {
}
public static Singleton getInstance(){
return LazyHolder.INSTANCE;
}
}
4.2 代理模式
定义:为其他对象提供一种代理以控制对这个对象的访问
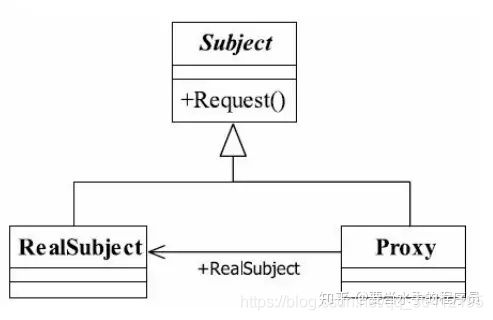
代理模式的通用类图
上图中,Subject是一个抽象类或者接口,RealSubject是实现方法类,具体的业务执行,Proxy则是RealSubject的代理,直接和client接触的。
代理模式可以在不修改被代理对象的基础上,通过扩展代理类,进行一些功能的附加与增强。值得注意的是,代理类和被代理类应该共同实现一个接口,或者是共同继承某个类。
代理模式优点
职责清晰
高扩展,只要实现了接口,都可以用代理。
智能化,动态代理。
静态代理
以租房为例,我们一般用租房软件、找中介或者找房东。这里的中介就是代理者。
首先定义一个提供了租房方法的接口
public interface IRentHouse {
void rentHouse();
}
定义租房的实现类:
public class RentHouse implements IRentHouse {
@Override
public void rentHouse() {
System.out.println("租了一间房子。。。");
}
}
我要租房,房源都在中介手中,所以找中介:
public class IntermediaryProxy implements IRentHouse {
private IRentHouse rentHouse;
public IntermediaryProxy(IRentHouse irentHouse){
rentHouse = irentHouse;
}
@Override
public void rentHouse() {
System.out.println("交中介费");
rentHouse.rentHouse();
System.out.println("中介负责维修管理");
}
}
这里中介也实现了租房的接口。
再main方法中测试:
public class Main {
public static void main(String[] args){
//定义租房
IRentHouse rentHouse = new RentHouse();
//定义中介
IRentHouse intermediary = new IntermediaryProxy(rentHouse);
//中介租房
intermediary.rentHouse();
}
}
这就是静态代理,因为中介这个代理类已经事先写好了,只负责代理租房业务
强制代理
如果我们直接找房东要租房,房东会说我把房子委托给中介了,你找中介去租吧。这样我们就又要交一部分中介费了,真坑。
来看代码如何实现,定义一个租房接口,增加一个方法。
public interface IRentHouse {
void rentHouse();
IRentHouse getProxy();
}
这时中介的方法也稍微做一下修改:
public class IntermediaryProxy implements IRentHouse {
private IRentHouse rentHouse;
public IntermediaryProxy(IRentHouse irentHouse){
rentHouse = irentHouse;
}
@Override
public void rentHouse() {
rentHouse.rentHouse();
}
@Override
public IRentHouse getProxy() {
return this;
}
}
其中的getProxy()方法返回中介的代理类对象
我们再来看房东是如何实现租房:
public class LandLord implements IRentHouse {
private IRentHouse iRentHouse = null;
@Override
public void rentHouse() {
if (isProxy()){
System.out.println("租了一间房子。。。");
}else {
System.out.println("请找中介");
}
}
@Override
public IRentHouse getProxy() {
iRentHouse = new IntermediaryProxy(this);
return iRentHouse;
}
/**
* 校验是否是代理访问
* @return
*/
private boolean isProxy(){
if(this.iRentHouse == null){
return false;
}else{
return true;
}
}
}
房东的getProxy方法返回的是代理类,然后判断租房方法的调用者是否是中介,不是中介就不租房。
动态代理
我们知道现在的中介不仅仅是有租房业务,同时还有卖房、家政、维修等得业务,只是我们就不能对每一个业务都增加一个代理,就要提供通用的代理方法,这就要通过动态代理来实现了。
中介的代理方法做了一下修改:
public class IntermediaryProxy implements InvocationHandler {
private Object obj;
public IntermediaryProxy(Object object){
obj = object;
}
/**
* 调用被代理的方法
* @param proxy
* @param method
* @param args
* @return
* @throws Throwable
*/
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Object result = method.invoke(this.obj, args);
return result;
}
}
在这里实现InvocationHandler接口,此接口是JDK提供的动态代理接口,对被代理的方法提供代理。其中invoke方法是接口InvocationHandler定义必须实现的, 它完成对真实方法的调用。动态代理是根据被代理的接口生成所有的方法,也就是说给定一个接口,动态代理就会实现接口下所有的方法。通过 InvocationHandler接口, 所有方法都由该Handler来进行处理, 即所有被代理的方法都由 InvocationHandler接管实际的处理任务。
public static void main(String[] args){
IRentHouse rentHouse = new RentHouse();
//定义一个handler
InvocationHandler handler = new IntermediaryProxy(rentHouse);
//获得类的class loader
ClassLoader cl = rentHouse.getClass().getClassLoader();
//动态产生一个代理者
IRentHouse proxy = (IRentHouse) Proxy.newProxyInstance(cl, new Class[]{IRentHouse.class}, handler);
proxy.rentHouse();
ISellHouse sellHouse = new SellHouse();
InvocationHandler handler1 = new IntermediaryProxy(sellHouse);
ClassLoader classLoader = sellHouse.getClass().getClassLoader();
ISellHouse proxy1 = (ISellHouse) Proxy.newProxyInstance(classLoader, new Class[]{ISellHouse.class}, handler1);
proxy1.sellHouse();
}
在main方法中我们用到了Proxy这个类的方法,
public static Object newProxyInstance(ClassLoader loader,
Class<?>[] interfaces,
InvocationHandler h)
- loder:类加载器,
- interfaces:代码要用来代理的接口,
- h:一个 InvocationHandler 对象 。
InvocationHandler 是一个接口,每个代理的实例都有一个与之关联的 InvocationHandler 实现类,如果代理的方法被调用,那么代理便会通知和转发给内部的 InvocationHandler 实现类,由它决定处理。
InvocationHandler 内部只是一个 invoke() 方法,正是这个方法决定了怎么样处理代理传递过来的方法调用。
因为,Proxy 动态产生的代理会调用 InvocationHandler 实现类,所以 InvocationHandler 是实际执行者
五、JAVA并发编程
5.1 进程与线程的区别
进程是资源分配的最小单位,线程是CPU调度的最小单位。
举个例子:进程=火车,
- 线程=车厢线程在进程下行进(单纯的车厢无法运行)
- 一个进程可以包含多个线程(一辆火车可以有多个车厢)
- 不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
- 同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)
- 进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
- 进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
- 进程可以拓展到多机,进程最多适合多核(不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)
- 进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)-“互斥锁”
- 进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-“信号量”
5.2 进程之间是如何通信的?
1、管道
我们来看一句linux代码。
netstat -tulnp | grep 8080
学过 Linux 命名的估计都懂这条语句的含义,其中”|“是管道的意思,它的作用就是把前一条命令的输出作为后一条命令的输入。在这里就是把 netstat -tulnp 的输出结果作为 grep 8080 这条命令的输入。如果两个进程要进行通信的话,就可以用这种管道来进行通信了,并且我们可以知道这条竖线是没有名字的,所以我们把这种通信方式称之为匿名管道。
并且这种通信方式是单向的,只能把第一个命令的输出作为第二个命令的输入,如果进程之间想要互相通信的话,那么需要创建两个管道。
居然有匿名管道,那也意味着有命名管道,下面我们来创建一个命名管道。
mkfifo test
这条命令创建了一个名字为 test 的命名管道。
接下来我们用一个进程向这个管道里面写数据,然后有另外一个进程把里面的数据读出来。
echo "this is a pipe" > test // 写数据
这个时候管道的内容没有被读出的话,那么这个命令就会一直停在这里,只有当另外一个进程把 test 里面的内容读出来的时候这条命令才会结束。
cat < test // 读数据
我们可以看到,test 里面的数据被读取出来了。上一条命令也执行结束了。从上面的例子可以看出,管道的通知机制类似于缓存,就像一个进程把数据放在某个缓存区域,然后等着另外一个进程去拿,并且是管道是单向传输的。
这种通信方式有什么缺点呢?显然,这种通信方式效率低下,你看,a 进程给 b 进程传输数据,只能等待 b 进程取了数据之后 a 进程才能返回。所以管道不适合频繁通信的进程。当然,他也有它的优点,例如比较简单,能够保证我们的数据已经真的被其他进程拿走了。我们平时用 Linux 的时候,也算是经常用。
2、消息队列
那我们能不能把进程的数据放在某个内存之后就马上让进程返回呢?无需等待其他进程来取就返回呢?
答是可以的,我们可以用消息队列的通信模式来解决这个问题,例如 a 进程要给 b 进程发送消息,只需要把消息放在对应的消息队列里就行了,b 进程需要的时候再去对应的消息队列里取出来。同理,b 进程要个 a 进程发送消息也是一样。这种通信方式也类似于缓存吧。这种通信方式有缺点吗?答是有的,如果 a 进程发送的数据占的内存比较大,并且两个进程之间的通信特别频繁的话,消息队列模型就不大适合了。因为 a 发送的数据很大的话,意味**发送消息(拷贝)**这个过程需要花很多时间来读内存。哪有没有什么解决方案呢?答是有的,请继续往下看。
3、共享内存
共享内存这个通信方式就可以很好着解决拷贝所消耗的时间了。
这个可能有人会问了,每个进程不是有自己的独立内存吗?两个进程怎么就可以共享一块内存了?
我们都知道,系统加载一个进程的时候,分配给进程的内存并不是实际物理内存,而是虚拟内存空间。那么我们可以让两个进程各自拿出一块虚拟地址空间来,然后映射到相同的物理内存中,这样,两个进程虽然有着独立的虚拟内存空间,但有一部分却是映射到相同的物理内存,这就完成了内存共享机制了。
4、信号量
共享内存最大的问题是什么?没错,就是多进程竞争内存的问题,就像类似于我们平时说的线程安全问题。如何解决这个问题?这个时候我们的信号量就上场了。信号量的本质就是一个计数器,用来实现进程之间的互斥与同步。例如信号量的初始值是 1,然后 a 进程来访问内存1的时候,我们就把信号量的值设为 0,然后进程b 也要来访问内存1的时候,看到信号量的值为 0 就知道已经有进程在访问内存1了,这个时候进程 b 就会访问不了内存1。所以说,信号量也是进程之间的一种通信方式。
5、Socket
上面我们说的共享内存、管道、信号量、消息队列,他们都是多个进程在一台主机之间的通信,那两个相隔几千里的进程能够进行通信吗?
5.3 线程池(施工中)
线程池的状态有:
- RUNNING:接受新任务并且处理阻塞队列里的任务。
- SHUTDOWN:拒绝新任务但是处理阻塞队列里的任务。
- STOP:拒绝新任务并且抛弃阻塞队列里的任务,同时会中断正在处理的任务。
- TIDYING:所有任务都执行完(包含阻塞队列里面的任务)后当前线程池活动线程数为0,将要调用terminated方法。
- TERMINATED:终止状态。terminated方法调用完成以后的状态。线程池状态转换列举如下。
线程池常用参数: - corePoolSize:线程池核心线程个数。
- workQueue:用于保存等待执行的任务的阻塞队列,比如基于数组的有界ArrayBlockingQueue、基于链表的无界LinkedBlockingQueue、最多只有一个元素的同步队列SynchronousQueue及优先级队列PriorityBlockingQueue等。
- maximunPoolSize:线程池最大线程数量。
- ThreadFactory:创建线程的工厂。
- RejectedExecutionHandler:饱和策略,当队列满并且线程个数达到maximunPoolSize后采取的策略,比如AbortPolicy(抛出异常)、CallerRunsPolicy(使用调用者所在线程来运行任务)、DiscardOldestPolicy(调用poll丢弃一个任务,执行当前任务)及DiscardPolicy(默默丢弃,不抛出异常)
- keeyAliveTime:存活时间。如果当前线程池中的线程数量比核心线程数量多,并且是闲置状态,则这些闲置的线程能存活的最大时间。
- imeUnit:存活时间的时间单位。
线程池类型:
- newFixedThreadPool :创建一个核心线程个数和最大线程个数都为nThreads的线程池,并且阻塞队列长度为Integer.MAX_VALUE。keeyAliveTime=0说明只要线程个数比核心线程个数多并且当前空闲则回收。构建一个具有固定大小的线程池。
即:如果提交的任务数多于空闲的线程数,那么把得不到服务的任务放置到队列中。当其他任务完成以后再运行它们。 - newSingleThreadExecutor:创建一个核心线程个数和最大线程个数都为1的线程池,并且阻塞队列长度为Integer.MAX_VALUE。keeyAliveTime=0说明只要线程个数比核心线程个数多并且当前空闲则回收。
即:是一个退化了的大小为1的线程池:由一个线程执行提交的任务,一个接着一个。 - newCachedThreadPool :创建一个按需创建线程的线程池,初始线程个数为0,最多线程个数为Integer.MAX_VALUE,并且阻塞队列为同步队列。keeyAliveTime=60说明只要当前线程在60s内空闲则回收。这个类型的特殊之处在于,加入同步队列的任务会被马上执行,同步队列里面最多只有一个任务。
即:对于每个任务,如果有空闲线程可用,立即让它执行任务,如果没有可用的空闲线程,则创建一个新线程。
常线程池类型

5.4 HashMap&ConcurrentHashMap
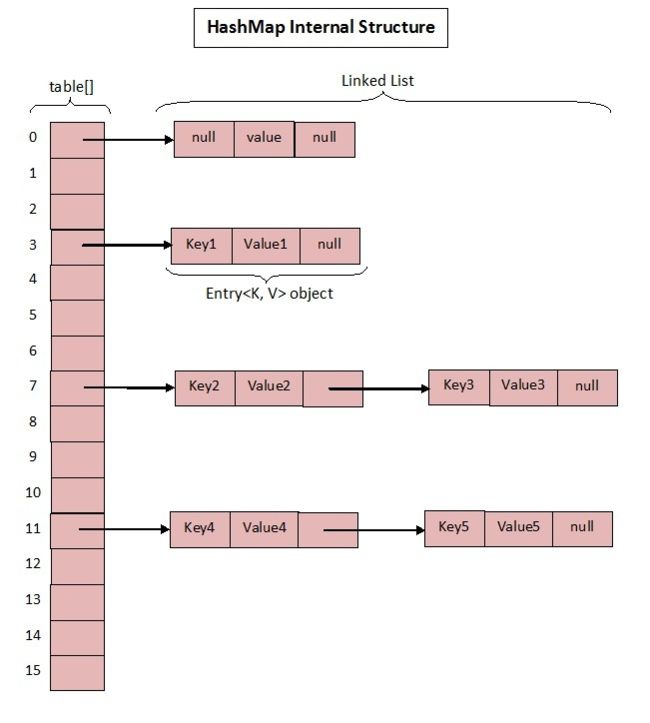
众所周知 HashMap 底层是基于 数组 + 链表 组成的,不过在 jdk1.7 和 1.8 中具体实现稍有不同。
1.7 中的数据结构图:
1 jdk1.7中的hashMap
这是 HashMap 中比较核心的几个成员变量;看看分别是什么意思?
- DEFAULT_INITIAL_CAPACITY: 初始化桶大小,因为底层是数组,所以这是数组默认的大小。
- MAXIMUM_CAPACITY: 桶最大值。
- DEFAULT_LOAD_FACTOR: 默认的负载因子(0.75)
- table 真正存放数据的数组。
- size Map 存放数量的大小。
- threshold 桶大小,可在初始化时显式指定。
- loadFactor负载因子,可在初始化时显式指定。
重点解释下负载因子,由于给定的 HashMap 的容量大小是固定的,比如默认初始化:
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。因此通常建议能提前预估 HashMap 的大小最好,尽量的减少扩容带来的性能损耗。
根据代码可以看到其实真正存放数据的是:
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
这个数组,那么它又是如何定义的呢?
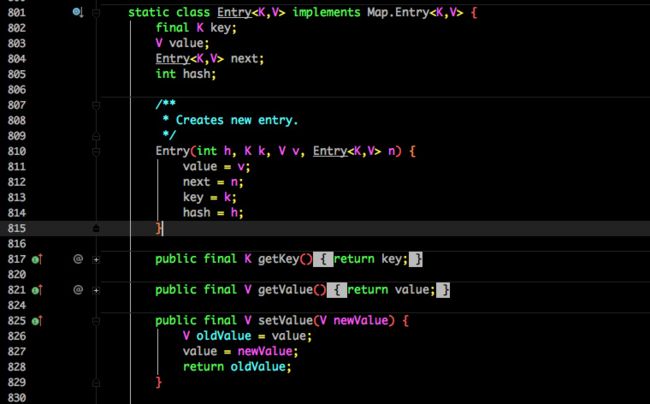
Entry 是 HashMap 中的一个内部类,从他的成员变量很容易看出:
- key 就是写入时的键。
- value 自然就是值。
- 开始的时候就提到 HashMap 是由数组和链表组成,所以这个 next 就是用于实现链表结构。
- hash 存放的是当前 key 的 hashcode。
知晓了基本结构,那来看看其中重要的写入、获取函数
put方法
public V put(K key, V value) {
//判断是否需要初始化
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//如果key为空,则调用putForNullKey将空值作为key
if (key == null)
return putForNullKey(value);
//根据key计算出hashcode
int hash = hash(key);
//根据hashcode定位出桶的位置
int i = indexFor(hash, table.length);
//如果桶是一个链表则需要遍历,判断里面Entry的key的hashcode、key是否和传入的key相等,如果相等则覆盖,并返回原来的值
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//如果桶是空的,说明当前位置没有数据存入;新增一个 Entry 对象写入当前位置。
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
get 方法
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
- 首先也是根据 key 计算出 hashcode,然后定位到具体的桶中。
- 判断该位置是否为链表。
- 不是链表就根据 key、key 的 hashcode 是否相等来返回值。
- 为链表则需要遍历直到 key 及 hashcode 相等时候就返回值。
- 啥都没取到就直接返回 null 。
2 jdk1.8中的HashMap
jdk1.8中对HashMap最重要的一个优化就是,如果桶上的链表过长会转化成红黑树。
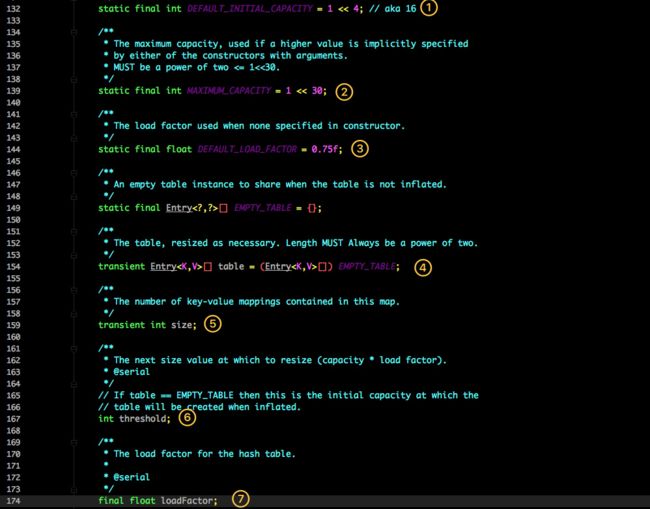
核心成员变量如下:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int TREEIFY_THRESHOLD = 8;
transient Node<K,V>[] table;
/**
* Holds cached entrySet(). Note that AbstractMap fields are used
* for keySet() and values().
*/
transient Set<Map.Entry<K,V>> entrySet;
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
和 1.7 大体上都差不多,还是有几个重要的区别:
- TREEIFY_THRESHOLD 用于判断是否需要将链表转换为红黑树的阈值。
- HashEntry 修改为 Node。
Node 的核心组成其实也是和 1.7 中的 HashEntry 一样,存放的都是 key value hashcode next 等数据。
put方法
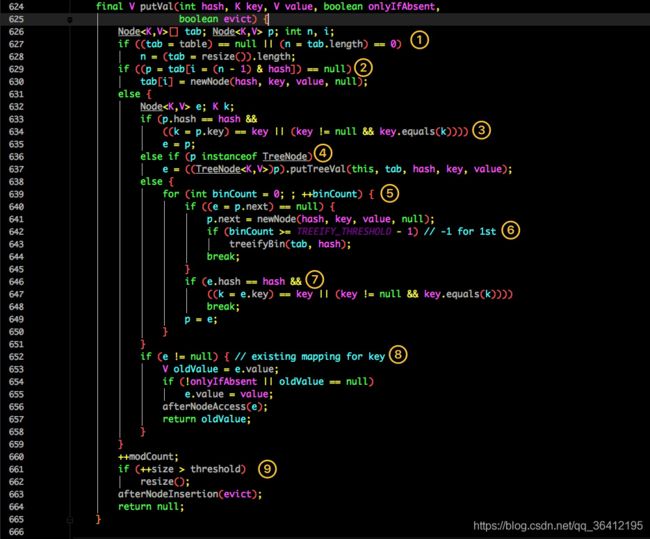
- 判断当前桶是否为空,空的就需要初始化(resize 中会判断是否进行初始化)。
- 根据当前 key 的 hashcode 定位到具体的桶中并判断是否为空,为空表明没有 Hash 冲突就直接在当前位置创建一个新桶即可。
- 如果当前桶有值( Hash 冲突),那么就要比较当前桶中的 key、key 的 hashcode 与写入的 key 是否相等,相等就赋值给 e,在第 8 步的时候会统一进行赋值及返回。
- 如果当前桶为红黑树,那就要按照红黑树的方式写入数据。
- 如果是个链表,就需要将当前的 key、value 封装成一个新节点写入到当前桶的后面(形成链表)。
- 接着判断当前链表的大小是否大于预设的阈值,大于时就要转换为红黑树。
- 如果在遍历过程中找到 key 相同时直接退出遍历。
- 如果 e != null 就相当于存在相同的 key,那就需要将值覆盖。
- 最后判断是否需要进行扩容。
get 方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
- 首先将 key hash 之后取得所定位的桶。
- 如果桶为空则直接返回 null 。
- 否则判断桶的第一个位置(有可能是链表、红黑树)的 key 是否为查询的 key,是就直接返回 value。
- 如果第一个不匹配,则判断它的下一个是红黑树还是链表。
- 红黑树就按照树的查找方式返回值。
- 不然就按照链表的方式遍历匹配返回值。
但是 HashMap 原有的问题也都存在,比如在并发场景下使用时容易出现死循环。HashMap 扩容的时候会调用 resize() 方法,就是这里的并发操作容易在一个桶上形成环形链表;这样当获取一个不存在的 key 时,计算出的 index 正好是环形链表的下标就会出现死循环。
3 jdk1.7 ConcurrentHashMap

如图所示,是由 Segment 数组、HashEntry 组成,和 HashMap 一样,仍然是数组加链表。它的核心成员变量:
/**
* Segment 数组,存放数据时首先需要定位到具体的 Segment 中。
*/
final Segment<K,V>[] segments;
transient Set<K> keySet;
transient Set<Map.Entry<K,V>> entrySet;
Segment 是 ConcurrentHashMap 的一个内部类,主要的组成如下:
static final class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
// 和 HashMap 中的 HashEntry 作用一样,真正存放数据的桶
transient volatile HashEntry<K,V>[] table;
transient int count;
transient int modCount;
transient int threshold;
final float loadFactor;
}
看看其中 HashEntry 的组成:
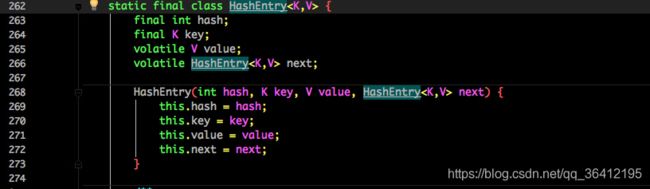
和 HashMap 非常类似,唯一的区别就是其中的核心数据如 value ,以及链表都是 volatile 修饰的,保证了获取时的可见性。
原理上来说:ConcurrentHashMap 采用了分段锁技术,其中 Segment 继承于 ReentrantLock。不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
put 方法
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
首先是通过 key 定位到 Segment,之后在对应的 Segment 中进行具体的 put。
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
虽然 HashEntry 中的 value 是用 volatile 关键词修饰的,但是并不能保证并发的原子性,所以 put 操作时仍然需要加锁处理。首先第一步的时候会尝试获取锁,如果获取失败肯定就有其他线程存在竞争,则利用 scanAndLockForPut() 自旋获取锁。
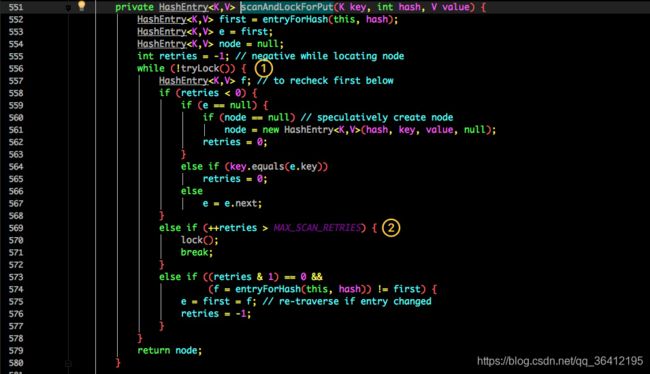
- 尝试自旋获取锁。
- 如果重试的次数达到了 MAX_SCAN_RETRIES 则改为阻塞锁获取,保证能获取成功。
再结合图看看 put 的流程。
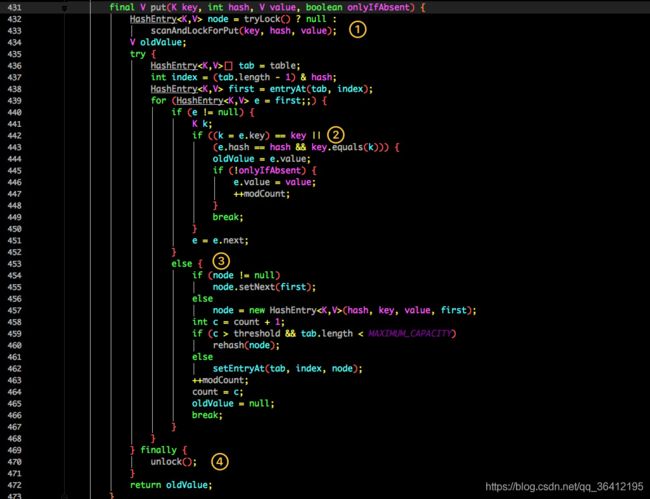
- 将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry。
- 遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value。
- 不为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容。
最后会解除在 1 中所获取当前 Segment 的锁
get 方法
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
get 逻辑比较简单:
只需要将 Key 通过 Hash 之后定位到具体的 Segment ,再通过一次 Hash 定位到具体的元素上。
由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值。
ConcurrentHashMap 的 get 方法是非常高效的,因为整个过程都不需要加锁。
jdk 1.8中的ConcurentHashMap
1.7 已经解决了并发问题,并且能支持 N 个 Segment 这么多次数的并发,但依然存在 HashMap 在 1.7 版本中的问题,那就是查询遍历链表效率太低。因此 1.8 做了一些数据结构上的调整。
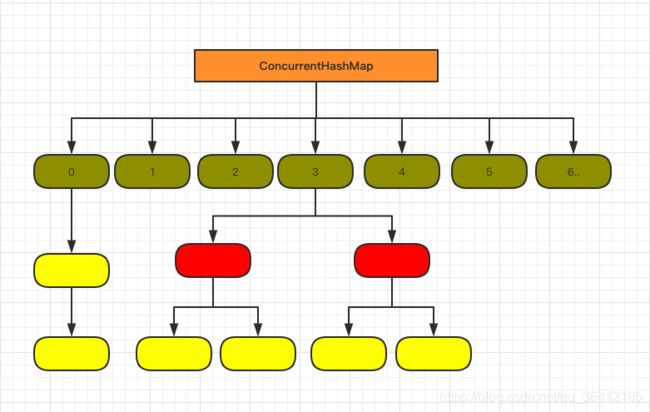
抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。
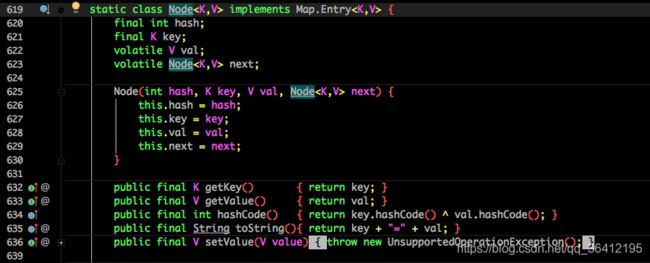
也将 1.7 中存放数据的 HashEntry 改为 Node,但作用都是相同的。
put 方法

- 根据 key 计算出 hashcode 。
- 判断是否需要进行初始化。
- f 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
- 如果当前位置的 hashcode == MOVED == -1,则需要进行扩容。
- 如果都不满足,则利用 synchronized 锁写入数据。
- 如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树
get 方法
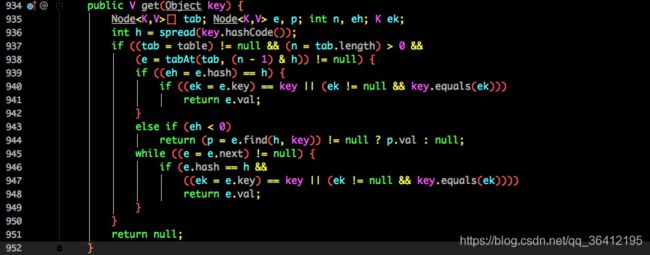
- 根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
- 如果是红黑树那就按照树的方式获取值。
- 都不满足那就按照链表的方式遍历获取值。
hashMap扩容
jdk1.7中的resize()
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//判断是否有超出扩容的最大值,如果达到最大值则不进行扩容操作
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
// transfer()方法把原数组中的值放到新数组中
transfer(newTable, initHashSeedAsNeeded(newCapacity));
//设置hashmap扩容后为新的数组引用
table = newTable;
//设置hashmap扩容新的阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
transfer()在实际扩容时候把原来数组中的元素放入新的数组中:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//通过key值的hash值和新数组的大小算出在当前数组中的存放位置
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
jdk8中的扩容机制
Java8不再像Java7中那样需要满足两个条件,Java8中扩容只需要满足一个条件:
- 当前存放新值(注意不是替换已有元素位置时)的时候已有元素的个数大于等于阈值(已有元素等于阈值,下一个存放后必然触发扩容机制)
(1)扩容一定是放入新值的时候,该新值不是替换以前位置的情况下(说明:put(“name”,“zhangsan”),而map里面原有数据<“name”,“lisi”>,则该存放过程就是替换一个原有值,而不是新增值,则不会扩容)
(2)扩容发生在存放后,即是数据存放后(先存放后扩容),判断当前存入对象的个数,如果大于阈值则进行扩容。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length; //未扩容时数组的容量
int oldThr = threshold;
int newCap, newThr = 0;//定义新的容量和临界值
//当前Map容量大于零,非第一次put值
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) { //超过最大容量:2^30
//临界值等于Integer类型的最大值 0x7fffffff=2^31-1
threshold = Integer.MAX_VALUE;
return oldTab;
}
//当前容量在默认值和最大值的一半之间
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; //新临界值为当前临界值的两倍
}
//当前容量为0,但是当前临界值不为0,让新的容量等于当前临界值
else if (oldThr > 0)
newCap = oldThr;
//当前容量和临界值都为0,让新的容量为默认值,临界值=初始容量*默认加载因子
else {
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//如果新的临界值为0
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);
}
//临界值赋值
threshold = newThr;
//扩容table
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;//此时newCap = oldCap*2
else if (e instanceof TreeNode) //节点为红黑树,进行切割操作
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { //链表的下一个节点还有值,但节点位置又没有超过8
//lo就是扩容后仍然在原地的元素链表
//hi就是扩容后下标为 原位置+原容量 的元素链表,从而不需要重新计算hash。
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
//循环链表直到链表末再无节点
do {
next = e.next;
//e.hash&oldCap == 0 判断元素位置是否还在原位置
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//循环链表结束,通过判断loTail是否为空来拷贝整个链表到扩容后table
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
5.5 AQS
AQS的结构如下所示,由该图可以看到,AQS是一个FIFO的双向队列,其内部通过节点head和tail记录队首和队尾元素。
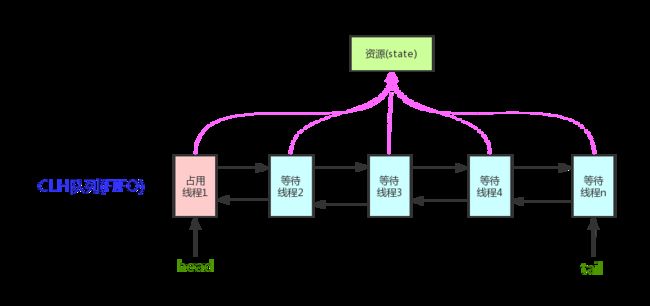
队列元素的类型为Node。Node节点内部的SHARED用来标记该线程是获取共享资源时被阻塞挂起后放入AQS队列的,EXCLUSIVE用来标记线程是获取独占资源时被挂起后放入AQS队列的;waitStatus记录当前线程等待状态:
-
CANCELLED(1):表示当前结点已取消调度。当timeout或被中断(响应中断的情况下),会触发变更为此状态,进入该状态后的结点将不会再变化。
-
SIGNAL(-1):表示后继结点在等待当前结点唤醒。后继结点入队时,会将前继结点的状态更新为SIGNAL。
-
CONDITION(-2):表示结点等待在Condition上,当其他线程调用了Condition的signal()方法后,CONDITION状态的结点将从等待队列转移到同步队列中,等待获取同步锁。
-
PROPAGATE(-3):共享模式下,前继结点不仅会唤醒其后继结点,同时也可能会唤醒后继的后继结点。

AQS方法详解:
1、acquire(int)
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
函数流程如下:
- tryAcquire()尝试直接去获取资源,如果成功则直接返回(这里体现了非公平锁,每个线程获取锁时会尝试直接抢占加塞一次,而CLH队列中可能还有别的线程在等待);
- addWaiter()将该线程加入等待队列的尾部,并标记为独占模式;
- acquireQueued()使线程阻塞在等待队列中获取资源,一直获取到资源后才返回。如果在整个等待过程中被中断过,则返回true,否则返回false。
- 如果线程在等待过程中被中断过,它是不响应的。只是获取资源后才再进行自我中断selfInterrupt(),将中断补上。
2、tryAcquire(int)
此方法尝试去获取独占资源。如果获取成功,则直接返回true,否则直接返回false。此方法需要子类自己去实现其定义。
3、addWaiter(Node)
private Node addWaiter(Node mode) {
//以给定模式构造结点。mode有两种:EXCLUSIVE(独占)和SHARED(共享)
Node node = new Node(Thread.currentThread(), mode);
//尝试快速方式直接放到队尾。
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
//上一步失败则通过enq入队。
enq(node);
return node;
}
4、enq(Node)
private Node addWaiter(Node mode) {
//以给定模式构造结点。mode有两种:EXCLUSIVE(独占)和SHARED(共享)
Node node = new Node(Thread.currentThread(), mode);
//尝试快速方式直接放到队尾。
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
//上一步失败则通过enq入队。
enq(node);
return node;
}
5、acquireQueued(Node, int)
OK,通过tryAcquire()和addWaiter(),该线程获取资源失败,已经被放入等待队列尾部了。聪明的你立刻应该能想到该线程下一部该干什么了吧:进入等待状态休息,直到其他线程彻底释放资源后唤醒自己,自己再拿到资源,然后就可以去干自己想干的事了。没错,就是这样!是不是跟医院排队拿号有点相似~~acquireQueued()就是干这件事:在等待队列中排队拿号(中间没其它事干可以休息),直到拿到号后再返回。这个函数非常关键,还是上源码吧:
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;//标记是否成功拿到资源
try {
boolean interrupted = false;//标记等待过程中是否被中断过
//又是一个“自旋”!
for (;;) {
final Node p = node.predecessor();//拿到前驱
//如果前驱是head,即该结点已成老二,那么便有资格去尝试获取资源(可能是老大释放完资源唤醒自己的,当然也可能被interrupt了)。
if (p == head && tryAcquire(arg)) {
setHead(node);//拿到资源后,将head指向该结点。所以head所指的标杆结点,就是当前获取到资源的那个结点或null。
p.next = null; // setHead中node.prev已置为null,此处再将head.next置为null,就是为了方便GC回收以前的head结点。也就意味着之前拿完资源的结点出队了!
failed = false; // 成功获取资源
return interrupted;//返回等待过程中是否被中断过
}
//如果自己可以休息了,就通过park()进入waiting状态,直到被unpark()。如果不可中断的情况下被中断了,那么会从park()中醒过来,发现拿不到资源,从而继续进入park()等待。
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;//如果等待过程中被中断过,哪怕只有那么一次,就将interrupted标记为true
}
} finally {
if (failed) // 如果等待过程中没有成功获取资源(如timeout,或者可中断的情况下被中断了),那么取消结点在队列中的等待。
cancelAcquire(node);
}
}
6、shouldParkAfterFailedAcquire(Node, Node)
此方法主要用于检查状态,看看自己是否真的可以去休息了
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;//拿到前驱的状态
if (ws == Node.SIGNAL)
//如果已经告诉前驱拿完号后通知自己一下,那就可以安心休息了
return true;
if (ws > 0) {
/*
* 如果前驱放弃了,那就一直往前找,直到找到最近一个正常等待的状态,并排在它的后边。
* 注意:那些放弃的结点,由于被自己“加塞”到它们前边,它们相当于形成一个无引用链,稍后就会被保安大叔赶走了(GC回收)!
*/
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
//如果前驱正常,那就把前驱的状态设置成SIGNAL,告诉它拿完号后通知自己一下。有可能失败,人家说不定刚刚释放完呢!
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
整个流程中,如果前驱结点的状态不是SIGNAL,那么自己就不能安心去休息,需要去找个安心的休息点,同时可以再尝试下看有没有机会轮到自己拿号。
7、parkAndCheckInterrupt()
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);//调用park()使线程进入waiting状态
return Thread.interrupted();//如果被唤醒,查看自己是不是被中断的。
}
8、release(int)
acquire()的反操作release()。此方法是独占模式下线程释放共享资源的顶层入口。它会释放指定量的资源,如果彻底释放了(即state=0),它会唤醒等待队列里的其他线程来获取资源。这也正是unlock()的语义,当然不仅仅只限于unlock()。下面是release()的源码:
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;//找到头结点
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);//唤醒等待队列里的下一个线程
return true;
}
return false;
}
9、unparkSuccessor(Node)
private void unparkSuccessor(Node node) {
//这里,node一般为当前线程所在的结点。
int ws = node.waitStatus;
if (ws < 0)//置零当前线程所在的结点状态,允许失败。
compareAndSetWaitStatus(node, ws, 0);
Node s = node.next;//找到下一个需要唤醒的结点s
if (s == null || s.waitStatus > 0) {//如果为空或已取消
s = null;
for (Node t = tail; t != null && t != node; t = t.prev) // 从后向前找。
if (t.waitStatus <= 0)//从这里可以看出,<=0的结点,都是还有效的结点。
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);//唤醒
}
5.6 HashMap为什么线程不安全
jdk 1.7中线程不安全
HashMap的线程不安全主要是发生在扩容函数中,其中调用了JDK1.7 HshMap#transfer(),而这段代码采用的是头插法将元素迁移到新的数组中。
假设现在有两个线程A、B同时对下面这个HashMap进行扩容操作:
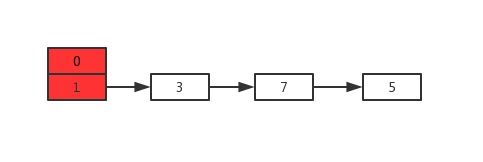
正常扩容后的结果是下面这样的:
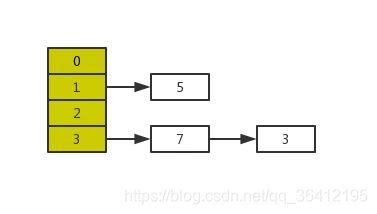
但是当线程A执行到上面transfer函数的第11行代码时,CPU时间片耗尽,线程A被挂起。即如下图中位置所示:
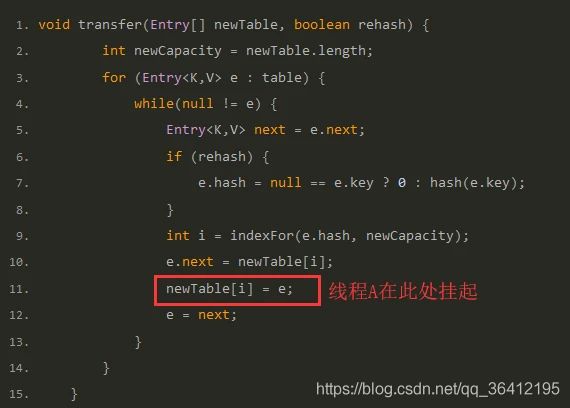
此时线程A中:e=3、next=7、e.next=null:
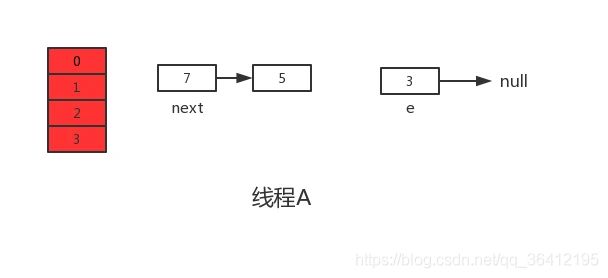
当线程A的时间片耗尽后,CPU开始执行线程B,并在线程B中成功的完成了数据迁移:
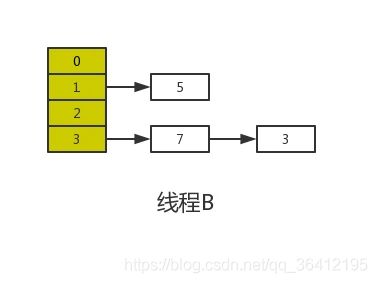
重点来了,根据Java内存模式可知,线程B执行完数据迁移后,此时主内存中newTable和table都是最新的,也就是说:7.next=3、3.next=null。
随后线程A获得CPU时间片继续执行newTable[i] = e,将3放入新数组对应的位置,执行完此轮循环后线程A的情况如下:
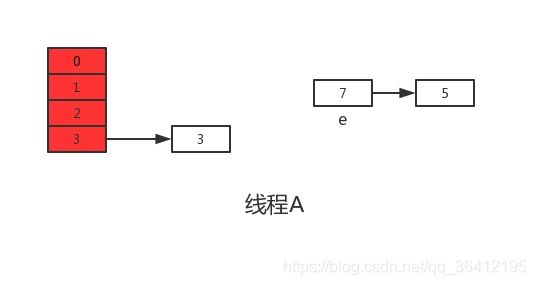
接着继续执行下一轮循环,此时e=7,从主内存中读取e.next时发现主内存中7.next=3,此时next=3,并将7采用头插法的方式放入新数组中,并继续执行完此轮循环,结果如下:

此时没任何问题。
上轮next=3,e=3,执行下一次循环可以发现,3.next=null,所以此轮循环将会是最后一轮循环。
接下来当执行完e.next=newTable[i]即3.next=7后,3和7之间就相互连接了,当执行完newTable[i]=e后,3被头插法重新插入到链表中,执行结果如下图所示:
读写锁的使用并不复杂,可以参考以下使用示例:
class RWDictionary {
private final Map<String, Data> m = new TreeMap<String, Data>();
private final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
private final Lock r = rwl.readLock();
private final Lock w = rwl.writeLock();
public Data get(String key) {
r.lock();
try { return m.get(key); }
finally { r.unlock(); }
}
public String[] allKeys() {
r.lock();
try { return m.keySet().toArray(); }
finally { r.unlock(); }
}
public Data put(String key, Data value) {
w.lock();
try { return m.put(key, value); }
finally { w.unlock(); }
}
public void clear() {
w.lock();
try { m.clear(); }
finally { w.unlock(); }
}
}
5.7 JUC
1.ReadWriteLock:
ReentrantReadWriteLock底层是基于ReentrantLock和AbstractQueuedSynchronizer来实现的,所以,ReentrantReadWriteLock的数据结构也依托于AQS的数据结构。
public interface ReadWriteLock {
/**
* Returns the lock used for reading.
*
* @return the lock used for reading
*/
Lock readLock();
/**
* Returns the lock used for writing.
*
* @return the lock used for writing
*/
Lock writeLock();
}
根据示例代码可以发现,读写锁需要关注的重点函数为获取读锁及写锁的函数,对于读锁及写锁对象则主要关注加锁和解锁函数,这几个函数及对象关系如下图:
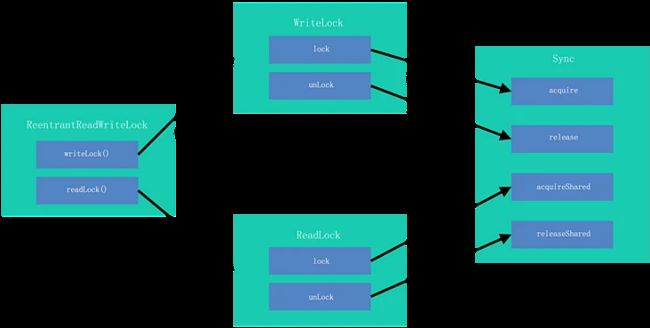
从图中可见读写锁的加锁解锁操作最终都是调用ReentrantReadWriteLock类的内部类Sync提供的方法。与{% post_link 细谈重入锁ReentrantLock %}一文中描述相似,Sync对象通过继承AbstractQueuedSynchronizer进行实现,故后续分析主要基于Sync类进行。
Sync继承于AbstractQueuedSynchronizer,其中主要功能均在AbstractQueuedSynchronizer中完成,其中最重要功能为控制线程获取锁失败后转换为等待状态及在满足一定条件后唤醒等待状态的线程。先对AbstractQueuedSynchronizer进行观察。
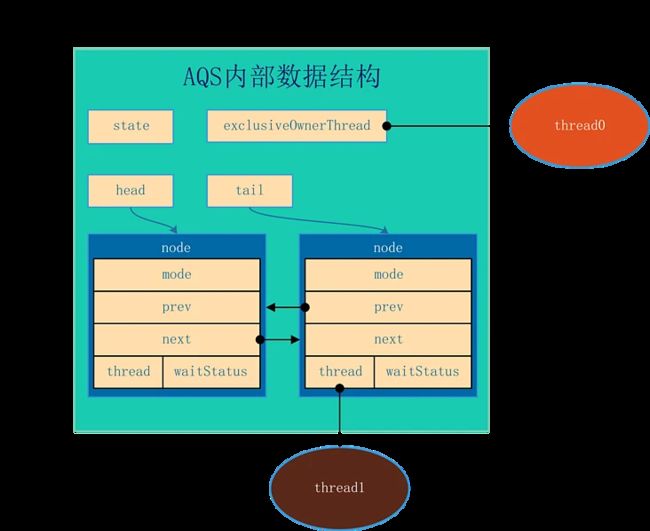
读写锁中Sync类是继承于AQS,并且主要使用上文介绍的数据结构中的state及waitStatus变量进行实现。
实现读写锁与实现普通互斥锁的主要区别在于需要分别记录读锁状态及写锁状态,并且等待队列中需要区别处理两种加锁操作。
Sync使用state变量同时记录读锁与写锁状态,将int类型的state变量分为高16位与低16位,高16位记录读锁状态,低16位记录写锁状态,如下图所示:

Sync使用不同的mode描述等待队列中的节点以区分读锁等待节点和写锁等待节点。mode取值包括SHARED及EXCLUSIVE两种,分别代表当前等待节点为读锁和写锁。
写锁加锁
通过对于重要函数关系的分析,写锁加锁最终调用Sync类的acquire函数(继承自AQS)
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
现在分情况图解分析
无锁状态AQS内部数据结构如下图所示:
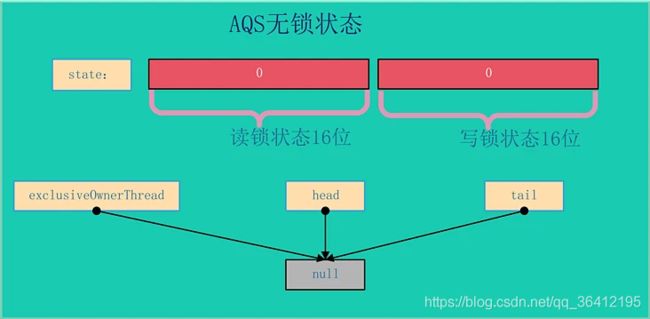
其中state变量为0,表示高位地位地位均为0,没有任何锁,且等待节点的首尾均指向空(此处特指head节点没有初始化时),锁的所有者线程也为空。
在无锁状态进行加锁操作,线程调用acquire 函数,首先使用tryAcquire函数判断锁是否可获取成功,由于当前是无锁状态必然成功获取锁(如果多个线程同时进入此函数,则有且只有一个线程可调用compareAndSetState成功,其他线程转入获取锁失败的流程)。获取锁成功后AQS状态为
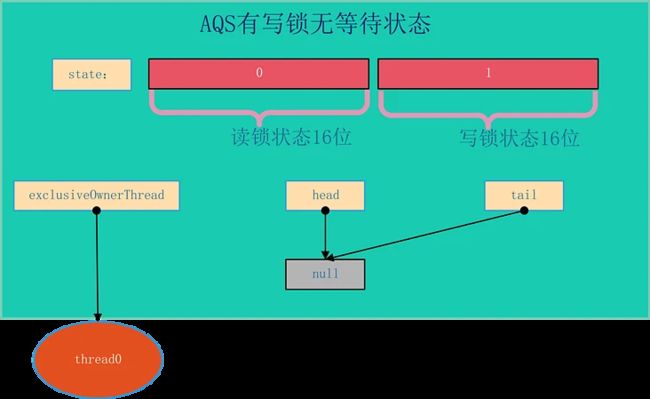
在加写锁时如果当前AQS已经是有锁状态,则需要进一步处理。有锁状态主要分为已有写锁和已有读锁状态,并且根据最终当前线程是否可直接获取锁分为两种情况:
-
非重入:如果满足一下两个条件之一,当前线程必须加入等待队列(暂不考虑非公平锁抢占情况)
a. 已有读锁;
b. 有写锁且获取写锁的线程不为当前请求锁的线程。 -
重入:有写锁且当前获取写锁的线程与当前请求锁的线程为同一线程,则直接获取锁并将写锁状态值加1。
写锁重入状态如图:

写锁非重入等待状态如图:
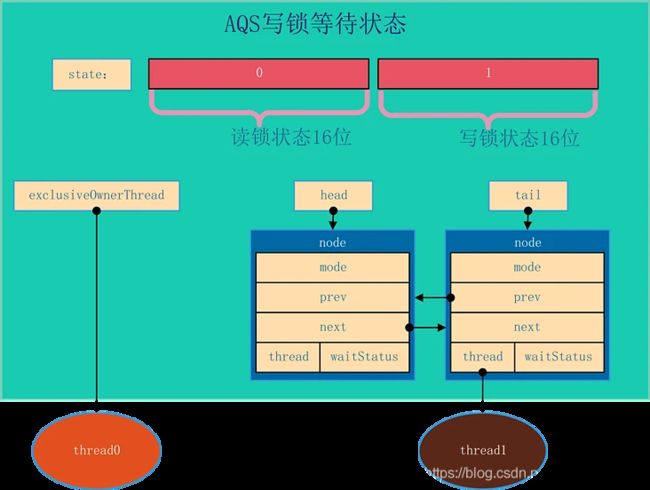
在非重入状态,当前线程创建等待节点追加到等待队列队尾,如果当前头结点为空,则需要创建一个默认的头结点。
之后再当前获取锁的线程释放锁后,会唤醒等待中的节点,即为thread1。如果当前等待队列存在多个等待节点,由于thread1等待节点为EXCLUSIVE模式,则只会唤醒当前一个节点,不会传播唤醒信号
写锁加锁
通过对于重要函数关系的分析,写锁加锁最终调用Sync类的acquireShared函数(继承自AQS)
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
无所状态AQS内部数据状态图与写加锁是无锁状态一致:

在无锁状态进行加锁操作,线程调用acquireShared 函数,首先使用tryAcquireShared函数判断共享锁是否可获取成功,由于当前为无锁状态则获取锁一定成功(如果同时多个线程在读锁进行竞争,则只有一个线程能够直接获取读锁,其他线程需要进入fullTryAcquireShared函数继续进行锁的获取,该函数在后文说明)。当前线程获取读锁成功后,AQS内部结构如图所示:
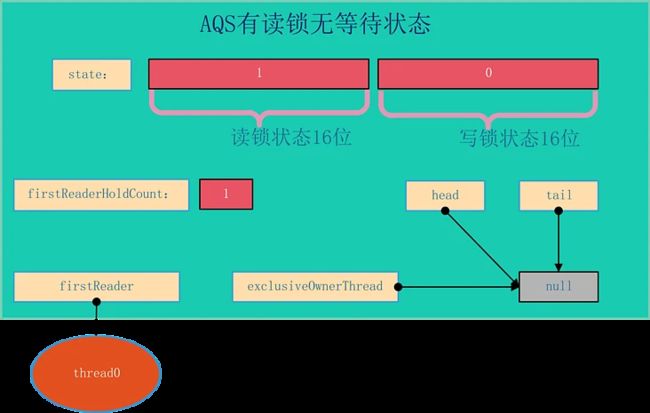
其中有两个新的变量:firstReader及firstReaderHoldCount。firstReader指向在无锁状态下第一个获取读锁的线程,firstReaderHoldCount记录第一个获取读锁的线程持有当前锁的计数(主要用于重入)。
无锁状态获取读锁比较简单,在有锁状态则需要分情况讨论。其中需要分当前被持有的锁是读锁还是写锁,并且每种情况需要区分等待队列中是否有等待节点。
已有读锁且等待队列为空
此状态比较简单,图示如:
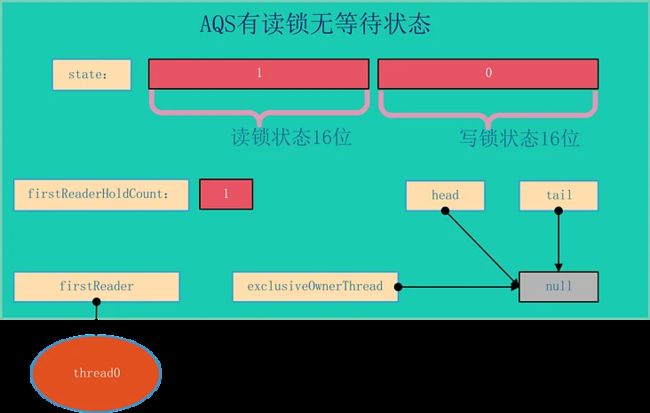
此时线程申请读锁,首先调用readerShouldBlock函数进行判断,该函数根据当前锁是否为公平锁判断规则稍有不同。
- 如果为非公平锁,则只需要当前第一个等待节点不是写锁就可以尝试获取锁(考虑第一个结点为写锁主要为了防止写锁“饿死”);
- 如果是公平锁则只要有等待节点且当前锁不为重入就需要等待。
由于本节的前提是等待队列为空的情况,故readerShouldBlock函数一定返回false,则当前线程使用CAS对读锁计数进行增加(同上文,如果同时多个线程在读锁进行竞争,则只有一个线程能够直接获取读锁,其他线程需要进入fullTryAcquireShared函数继续进行锁的获取)。
在成功对读锁计数器进行增加后,当前线程需要继续对当前线程持有读锁的计数进行增加。此时分为两种情况:
- 当前线程是第一个获取读锁的线程,此时由于第一个获取读锁的线程已经通过firstReader及firstReaderHoldCount两个变量进行存储,则仅仅需要将firstReaderHoldCount加1即可;
- 当前线程不是第一个获取读锁的线程,则需要使用readHolds进行存储,readHolds是ThreadLocal的子类,通过readHolds可获取当前线程对应的HoldCounter类的对象,该对象保存了当前线程获取读锁的计数。考虑程序的局部性原理,又使用cachedHoldCounter缓存最近使用的HoldCounter类的对象,如在一段时间内只有一个线程请求读锁则可加速对读锁获取的计数。
第一个读锁线程重入如图:
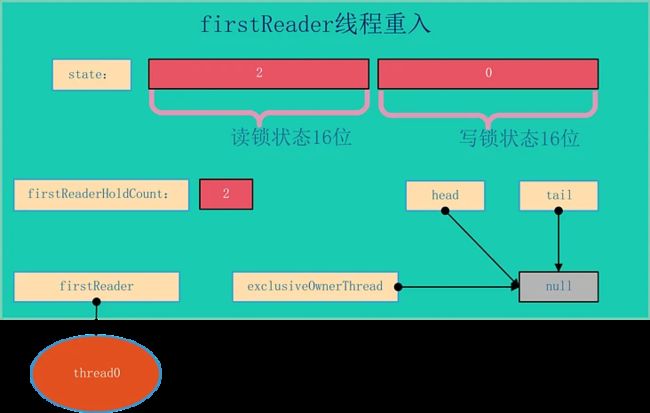
非首节点获取读锁

在当前锁已经被读锁获取,且等待队列不为空的情况下 ,可知等待队列的头结点一定为写锁获取等待,这是由于在读写锁实现过程中,如果某线程获取了读锁,则会唤醒当前等到节点之后的所有等待模式为SHARED的节点,直到队尾或遇到EXCLUSIVE模式的等待节点(具体实现函数为setHeadAndPropagate后续还会遇到)。所以可以确定当前为读锁状态其有等待节点情况下,首节点一定是写锁等待。如图所示:
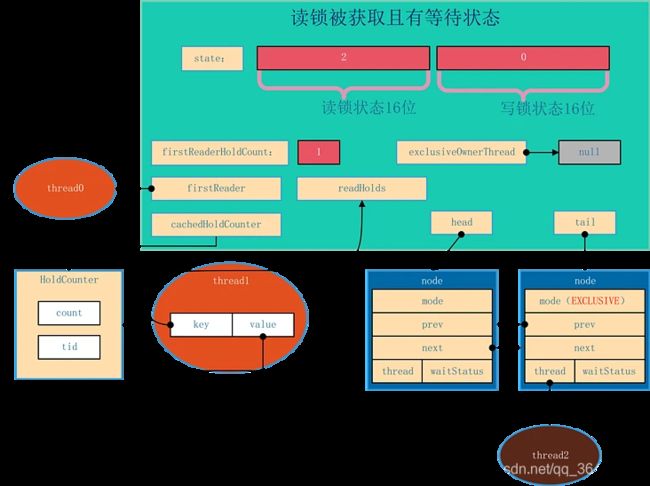
上图展示当前thread0与thread1线程获取读锁,thread0为首个获取读锁的节点,并且thread2线程在等待获取写锁。
在上图显示的状态下,无论公平锁还是非公平锁的实现,新的读锁加锁一定会进行排队,添加等待节点在写锁等待节点之后,这样可以防止写操作的饿死。申请读锁后的状态如图所示:
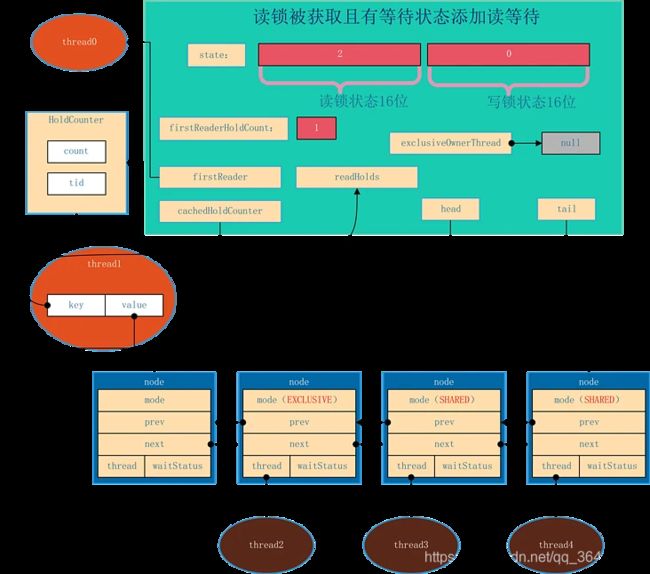
六、JVM
6.1 java内存划分
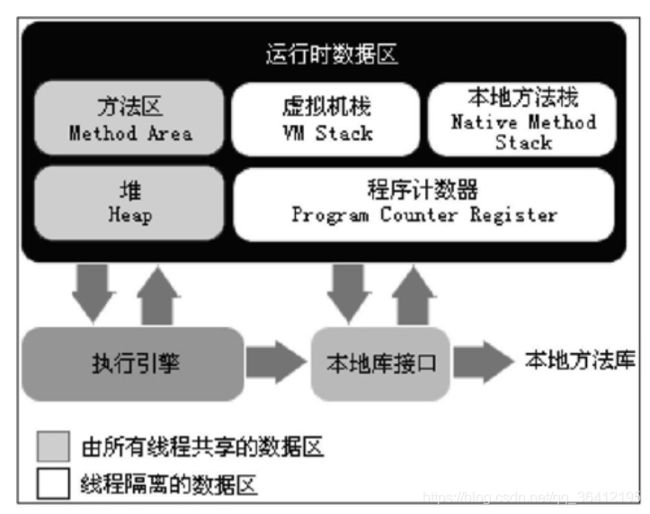
1、程序计数器
线程私有,程序计数器(Program Counter Register)是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。在虚拟机的概念模型里(仅是概念模型,各种虚拟机可能会通过一些更高效的方式去实现),字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
2、 java虚拟机栈
与程序计数器一样,Java虚拟机栈(Java Virtual Machine Stacks)也是线程私有的,它的生命周期与线程相同。虚拟机栈描述的是Java方法执行的内存模型:每个方法在执行的同时都会创建一个栈帧(Stack Frame)[插图]用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
3、本地方法栈
本地方法栈(Native Method Stack)与虚拟机栈所发挥的作用是非常相似的,它们之间的区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的Native方法服务。
4、java堆
Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。Java堆是垃圾收集器管理的主要区域,因此很多时候也被称做“GC堆”。由于现在收集器基本都采用分代收集算法,所以Java堆中还可以细分为:新生代和老年代;再细致一点的有Eden空间、From Survivor空间、To Survivor空间等
5、方法区
方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的应该是与Java堆区分开来。
6.2 jvm垃圾回收
1、判断对象已经死亡
- 引用计数法:对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加1;当引用失效时,计数器值就减1;任何时刻计数器为0的对象就是不可能再被使用的。
- 可达性分析算法:通过一系列的称为“GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链相连(用图论的话来说,就是从GC Roots到这个对象不可达)时,则证明此对象是不可用的。在Java语言中,可作为GC Roots的对象包括下面几种:(1)虚拟机栈(栈帧中的本地变量表)中引用的对象。(2)方法区中类静态属性引用的对象。(3)方法区中常量引用的对象。(4)本地方法栈中JNI(即一般说的Native方法)引用的对象。
2、垃圾回收算法
- 标记清除算法:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。它的主要不足有两个:一个是效率问题,标记和清除两个过程的效率都不高;另一个是空间问题,标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行过程中需要分配较大对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
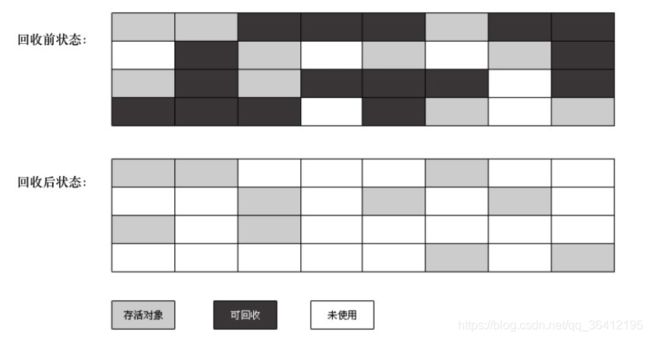
- 复制算法:将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。这样使得每次都是对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将内存缩小为了原来的一半,未免太高了一点。
现在的商业虚拟机都采用复制算法来回收新生代,IBM公司的专门研究表明,新生代中的对象98%是“朝生夕死”的,所以并不需要按照1∶1的比例来划分内存空间,而是将内存分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden和其中一块Survivor。当回收时,将Eden和Survivor中还存活着的对象一次性地复制到另外一块Survivor空间上,最后清理掉Eden和刚才用过的Survivor空间。
- 标记整理算法:针对老年代的特点,有人提出了另外一种“标记-整理”(Mark-Compact)算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存,“标记-整理”算法的示意图如图3-4所示。
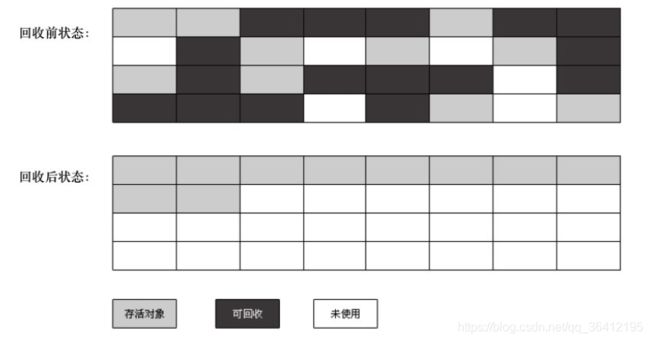
- 分代收集算法:根据对象存活周期的不同将内存划分为几块。一般是把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记—清理”或者“标记—整理”算法来进行回收。
6.3 JVM垃圾回收器
JVM垃圾回收器可以分为新生代垃圾回收器和老年代垃圾回收器,如下图所示,两者之间有连线的表示可以搭配使用。
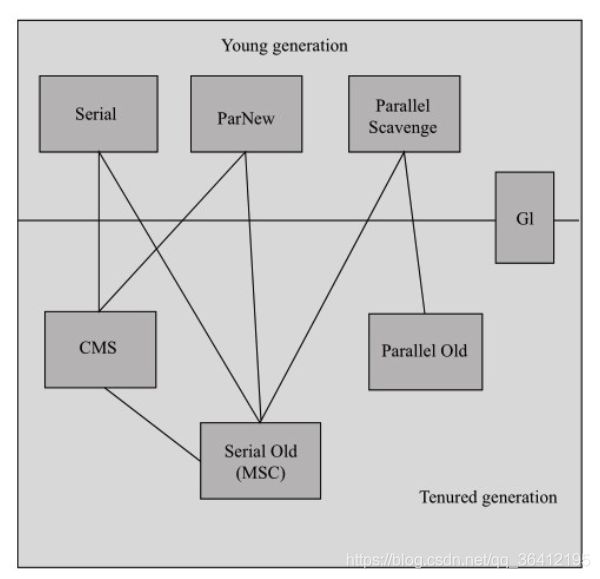
1、Serial新生代收集器
Serial收集器是一个单线程的收集器,但它的“单线程”的意义并不仅仅说明它只会使用一个CPU或一条收集线程去完成垃圾收集工作,更重要的是在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束。

到现在为止,它依然是虚拟机运行在Client模式下的默认新生代收集器。它也有着优于其他收集器的地方:简单而高效(与其他收集器的单线程比),对于限定单个CPU的环境来说,Serial收集器由于没有线程交互的开销,专心做垃圾收集自然可以获得最高的单线程收集效率。
2、ParNew新生代收集器
ParNew收集器其实就是Serial收集器的多线程版本,其工作方式如下图所示:

ParNew收集器除了多线程收集之外,其他与Serial收集器相比并没有太多创新之处,但它却是许多运行在Server模式下的虚拟机中首选的新生代收集器,其中有一个与性能无关但很重要的原因是,除了Serial收集器外,目前只有它能与CMS收集器配合工作。
3、Parallel Scavenge新生代收集器
Parallel Scavenge收集器是一个新生代收集器,它也是使用复制算法的收集器。Parallel Scavenge收集器的特点是它的关注点与其他收集器不同,CMS等收集器的关注点是尽可能地缩短垃圾收集时用户线程的停顿时间,而Parallel Scavenge收集器的目标则是达到一个可控制的吞吐量(Throughput)。所谓吞吐量就是CPU用于运行用户代码的时间与CPU总消耗时间的比值,即吞吐量 = 运行用户代码时间 /(运行用户代码时间 +垃圾收集时间),虚拟机总共运行了100分钟,其中垃圾收集花掉1分钟,那吞吐量就是99%。
4、Serial Old老年代收集器
Serial Old是Serial收集器的老年代版本,它同样是一个单线程收集器,使用“标记-整理”算法。这个收集器的主要意义也是在于给Client模式下的虚拟机使用。如果在Server模式下,那么它主要还有两大用途:一种用途是在JDK 1.5以及之前的版本中与Parallel Scavenge收集器搭配使,另一种用途就是作为CMS收集器的后备预案,在并发收集发生Concurrent Mode Failure时使用。

5、Parallel Old老年代收集器
Parallel Old是Parallel Scavenge收集器的老年代版本,使用多线程和“标记-整理”算法。这个收集器是在JDK 1.6中才开始提供的,在此之前,新生代的ParallelScavenge收集器一直处于比较尴尬的状态。原因是,如果新生代选择了ParallelScavenge收集器,老年代除了Serial Old(PS MarkSweep)收集器外别无选择。

6、CMS老年代收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。CMS收集器是基于“标记—清除”算法实现的,它的运作过程相对于前面几种收集器来说更复杂一些,整个过程分为4个步骤:
- 初始标记:初始标记仅仅只是标记一下GC Roots能直接关联到的对象。需要stop the world
- 并发标记:并发标记阶段就是进行GC Roots Tracing的过程
- 重新标记:修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短。需要stop the world
- 并发清除:清除被标记的对象
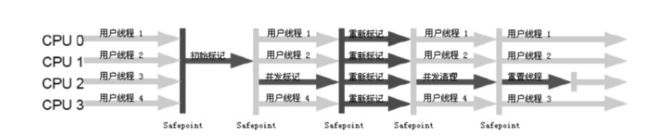
7、G1收集器
G1(Garbage-First)收集器是当今收集器技术发展的最前沿成果之一,G1是一款面向服务端应用的垃圾收集器。HotSpot开发团队赋予它的使命是(在比较长期的)未来可以替换掉JDK 1.5中发布的CMS收集器。
6.4 JVM类结构
根据Java虚拟机规范的规定,Class文件格式采用一种类似于C语言结构体的伪结构来存储数据,这种伪结构中只有两种数据类型:无符号数和表,后面的解析都要以这两种数据类型为基础,所以这里要先介绍这两个概念。
无符号数属于基本的数据类型,以u1、u2、u4、u8来分别代表1个字节、2个字节、4个字节和8个字节的无符号数,无符号数可以用来描述数字、索引引用、数量值或者按照UTF-8编码构成字符串值。
无符号数属于基本的数据类型,以u1、u2、u4、u8来分别代表1个字节、2个字节、4个字节和8个字节的无符号数,无符号数可以用来描述数字、索引引用、数量值或者按照UTF-8编码构成字符串值。
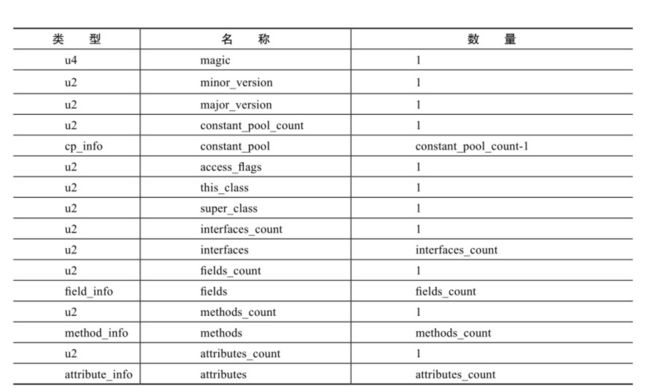
Class的结构不像XML等描述语言,由于它没有任何分隔符号,所以在上表中的数据项,无论是顺序还是数量,甚至于数据存储的字节序(Byte Ordering,Class文件中字节序为Big-Endian)这样的细节,都是被严格限定的,哪个字节代表什么含义,长度是多少,先后顺序如何,都不允许改变。接下来我们将一起看看这个表中各个数据项的具体含义。
1、魔数与Class文件的版本
每个Class文件的头4个字节称为魔数(Magic Number),它的唯一作用是确定这个文件是否为一个能被虚拟机接受的Class文件。Class文件的魔数的获得很有“浪漫气息”,值为:0xCAFEBABE(咖啡宝贝?)
紧接着魔数的4个字节存储的是Class文件的版本号:第5和第6个字节是次版本号(Minor Version),第7和第8个字节是主版本号(Major Version)。
2、常量池
紧接着主次版本号之后的是常量池入口,常量池可以理解为Class文件之中的资源仓库,它是Class文件结构中与其他项目关联最多的数据类型,也是占用Class文件空间最大的数据项目之一,同时它还是在Class文件中第一个出现的表类型数据项.
由于常量池中常量的数量是不固定的,所以在常量池的入口需要放置一项u2类型的数据,代表常量池容量计数值(constant_pool_count)
常量池中主要存放两大类常量:字面量(Literal)和符号引用(SymbolicReferences)。
字面量比较接近于Java语言层面的常量概念,如文本字符串、声明为final的常量值等。
而符号引用则属于编译原理方面的概念,包括了下面三类常量:
- 类和接口的全限定名
- 字段的名称和描述符
- 方法的名称和描述符
常量池中每一项常量都是一个表:
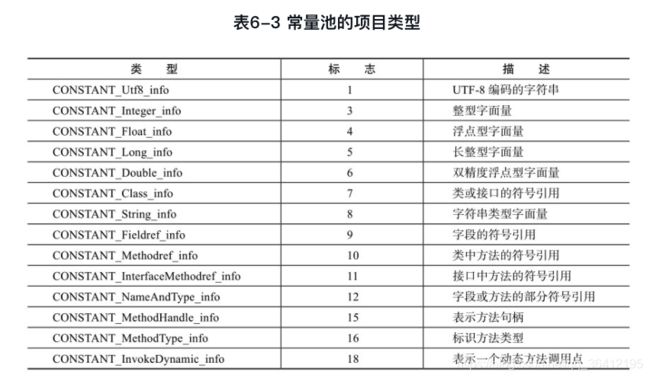
3、访问标志
在常量池结束之后,紧接着的两个字节代表访问标志(access_flags),这个标志用于识别一些类或者接口层次的访问信息,包括:这个Class是类还是接口;是否定义为public类型;是否定义为abstract类型;如果是类的话,是否被声明为final等

4、类索引、父类索引与接口索引集合
类索引(this_class)和父类索引(super_class)都是一个u2类型的数据,而接口索引集合(interfaces)是一组u2类型的数据的集合,Class文件中由这三项数据来确定这个类的继承关系。
- 类索引用于确定这个类的全限定名
- 父类索引用于确定这个类的父类的全限定名。由于Java语言不允许多重继承,所以父类索引只有一个,除了java.lang.Object之外,所有的Java类都有父类,因此除了java.lang.Object外,所有Java类的父类索引都不为0。
- 接口索引集合就用来描述这个类实现了哪些接口,这些被实现的接口将按implements语句(如果这个类本身是一个接口,则应当是extends语句)后的接口顺序从左到右排列在接口索引集合中。
5、字段表集合
字段表(field_info)用于描述接口或者类中声明的变量。字段(field)包括类级变量以及实例级变量。java描述一个字段可以包括的信息有:字段的作用域(public、private、protected修饰符)、是实例变量还是类变量(static修饰符)、可变性(final)、并发可见性(volatile修饰符,是否强制从主内存读写)、可否被序列化(transient修饰符)、字段数据类型(基本类型、对象、数组)、字段名称。上述这些信息中,各个修饰符都是布尔值,要么有某个修饰符,要么没有,很适合使用标志位来表示。而字段叫什么名字、字段被定义为什么数据类型,这些都是无法固定的,只能引用常量池中的常量来描述。
6、方法表集合
Class文件存储格式中对方法的描述与对字段的描述几乎采用了完全一致的方式,方法表的结构如同字段表一样,依次包括了访问标志(access_flags)、名称索引(name_index)、描述符索引(descriptor_index)、属性表集合(attributes)几项。
与那些在编译时需要进行连接工作的语言不同,在Java语言里面,类型的加载、连接和初始化过程都是在程序运行期间完成的。
6.5 java类加载机制
一个类从被加载到虚拟机内存中,到卸载出内存为止,它的整个生命周期包括:加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)7个阶段。其中验证、准备、解析3个部分统称为连接(Linking)。
加载、验证、准备、初始化和卸载这5个阶段的顺序是确定的,类的加载过程必须按照这种顺序按部就班地开始,而解析阶段则不一定:它在某些情况下可以在初始化阶段之后再开始,这是为了支持Java语言的运行时绑定(也称为动态绑定或晚期绑定)。
5种情况必须立即初始化:
- 遇到new、getstatic 、putstatic 、 invokestatic这四条字节码指令时,如果类未进行初始化必须初始化。生成这4条指令的最常见的Java代码场景是:使用new关键字实例化对象的时候、读取或设置一个类的静态字段(被final修饰、已在编译期把结果放入常量池的静态字段除外)的时候,以及调用一个类的静态方法的时候。
- 使用java.lang.reflect包的方法对类进行反射调用的时候,如果类没有进行过初始化,则需要先触发其初始化。
- 当初始化一个类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化。
- 当虚拟机启动时,用户需要指定一个要执行的主类(包含main()方法的那个类),虚拟机会先初始化这个主类。
- 当使用JDK 1.7的动态语言支持时,如果一个java.lang.invoke.MethodHandle实例最后的解析结果REF_getStatic、REF_putStatic、REF_invokeStatic的方法句柄,并且这个方法句柄所对应的类没有进行过初始化,则需要先触发其初始化。
只有这五种会触发初始化。
加载
在加载阶段,虚拟机需要完成以下3件事情:
- 通过一个类的全限定名来获取定义此类的二进制字节流。
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
- 在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
对非数组类来说,开发人员可以通过定义自己的类加载器去控制字节流的获取方式(即重写一个类加载器的loadClass()方法。加载阶段完成后,虚拟机外部的二进制字节流就按照虚拟机所需的格式存储在方法区之中。然后在内存中实例化一个java.lang.Class类的对象,这个对象将作为程序访问方法区中的这些类型数据的外部接口。
验证
验证是连接阶段的第一步,这一阶段的目的是为了确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。Class文件并不一定要求用Java源码编译而来,可以使用任何途径产生,甚至包括用十六进制编辑器直接编写来产生Class文件。虚拟机如果不检查输入的字节流,对其完全信任的话,很可能会因为载入了有害的字节流而导致系统崩溃,所以验证是虚拟机对自身保护的一项重要工作。
准备
准备阶段是正式为类变量分配内存并设置类变量初始值的阶段,这时候进行内存分配的仅包括类变量(被static修饰的变量),而不包括实例变量,实例变量将会在对象实例化时随着对象一起分配在Java堆中。这里所说的初始值“通常情况”下是数据类型的零值,
解析
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程,
- 符号引用(Symbolic References):符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可。符号引用与虚拟机实现的内存布局无关,引用的目标并不一定已经加载到内存中。各种虚拟机实现的内存布局可以各不相同,但是它们能接受的符号引用必须都是一致的,因为符号引用的字面量形式明确定义在Java虚拟机规范的Class文件格式中。
直接引用(Direct References):直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄。直接引用是和虚拟机实现的内存布局相关的,同一个符号引用在不同虚拟机实例上翻译出来的直接引用一般不会相同。如果有了直接引用,那引用的目标必定已经在内存中存在。
解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符7类符号引用进行,分别对应于常量池的CONSTANT_Class_info、CONSTANT_Fieldref_info、CONSTANT_Methodref_info、CONSTANT_InterfaceMethodref_info、CONSTANT_MethodType_info、CONSTANT_MethodHandle_info和CONSTANT_InvokeDynamic_info 7种常量类型。
初始化
类初始化阶段是类加载过程的最后一步,前面的类加载过程中,除了在加载阶段用户应用程序可以通过自定义类加载器参与之外,其余动作完全由虚拟机主导和控制。到了初始化阶段,才真正开始执行类中定义的Java程序代码(或者说是字节码)。
在准备阶段,变量已经赋过一次系统要求的初始值,而在初始化阶段,则根据程序员通过程序制定的主观计划去初始化类变量和其他资源,或者可以从另外一个角度来表达:初始化阶段是执行类构造器()方法的过程
()法是由编译器自动收集类中的所有类变量的赋值动作和静态语句块(static{}块)中的语句合并产生的,编译器收集的顺序是由语句在源文件中出现的顺序所决定的,静态语句块中只能访问到定义在静态语句块之前的变量,定义在它之后的变量,在前面的静态语句块可以赋值,但是不能访问。
()方法与类的构造函数(或者说实例构造器()方法)不同,它不需要显式地调用父类构造器,虚拟机会保证在子类的()方法执行之前,父类的()方法已经执行完毕。因此在虚拟机中第一个被执行的()方法的类肯定是java.lang.Object。
由于父类的()方法先执行,也就意味着父类中定义的静态语句块要优先于子类的变量赋值操作
类与类加载器
- 启动类加载器:这个类将器负责将存放在
\lib目录中的 ,或者被-Xbootclasspath参数所指定的路径中的,并且是虚拟机识别的(仅按照文件名识别,如rt.jar,名字不符合的类库即使放在lib目录中也不会被加载)类库加载到虚拟机内存中。 - 扩展类加载器:这个加载器由sun.misc.Launcher$ExtClassLoader实现,它负责加载
\lib\ext目录中的 ,或者被java.ext.dirs系统变量所指定的路径中的所有类库,开发者可以直接使用扩展类加载器。 - 应用程序类加载器(Application ClassLoader):这个类加载器由sun.misc.Launcher$App-ClassLoader实现。由于这个类加载器是ClassLoader中的getSystemClassLoader()方法的返回值,所以一般也称它为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库,开发者可以直接使用这个类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
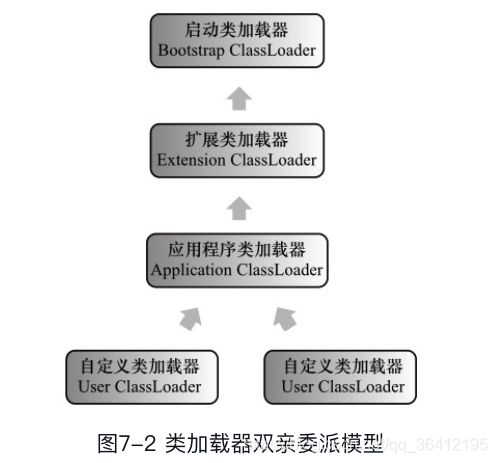
双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器。这里类加载器之间的父子关系一般不会以继承(Inheritance)的关系来实现,而是都使用组合(Composition)关系来复用父加载器的代码。
双亲委派模型的工作过程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载
6.6 OOM排查
一个OOM的例子,配置VM OPTION如下
代码如下:
public class HeapOOM {
static class OOMObject{
}
public static void main(String[] args) {
List<OOMObject> list = new ArrayList<>();
while (true){
list.add(new OOMObject());
}
}
}
最终结果如下:
java.lang.OutOfMemoryError: Java heap space
Dumping heap to java_pid50887.hprof ...
Heap dump file created [29196269 bytes in 0.102 secs]
Java堆内存的OOM异常是实际应用中常见的内存溢出异常情况。当出现Java堆内存溢出时,异常堆栈信息“java.lang.OutOfMemoryError”会跟着进一步提示“Javaheap space
dump文件分析
idea下需要安装插件JProfiler,这个插件启动需要一个文件,这个文件可以去https://www.ej-technologies.com/download/jprofiler/files下载。
七、Linux
7.1 Linux常见命令
(1)ps
Linux中的ps命令是Process Status的缩写。ps命令用来列出系统中当前运行的那些进程。ps命令列出的是当前那些进程的快照,就是执行ps命令的那个时刻的那些进程.
linux中进程有5种状态:
- 运行(正在运行或在运行队列中等待)
- 中断(休眠中,受阻,在等待某个条件形成或接受到信号)
- 不可中断(收到信号不唤醒和不可运行,进程必须等待直到有中断发送)
- 僵死(进程已终止,但进程描述符存在,直到父进程调用wait4()系统调用后释放)
- 停止
ps工具标识进程的5种状态码:
- D 不可中断
- R (runable)运行
- S(sleeping) 中断
- T (traced or stopeped)停止
- Z (zombie) 僵死
命令格式: ps[参数]
命令功能: 用来显示当前进程的状态
命令参数:
-
a 显示所有进程
-
-a 显示同一终端下的所有程序
-
-A 显示所有进程
-
c 显示进程的真实名称
-
-N 反向选择
-
-e 等于“-A”
-
e 显示环境变量
-
f 显示程序间的关系
-
-H 显示树状结构
-
r 显示当前终端的进程
-
T 显示当前终端的所有程序
-
u 指定用户的所有进程
-
-au 显示较详细的资讯
-
-aux 显示所有包含其他使用者的行程
-
-C<命令> 列出指定命令的状况
-
–lines<行数> 每页显示的行数
-
–width<字符数> 每页显示的字符数
-
–help 显示帮助信息
-
–version 显示版本显示
ps -l 各相关信息的意义:
-
F 代表这个程序的旗标 (flag), 4 代表使用者为 super user
-
S 代表这个程序的状态 (STAT),关于各 STAT 的意义将在内文介绍
-
UID 程序被该 UID 所拥有
-
PID 就是这个程序的 ID !
-
PPID 则是其上级父程序的ID
-
C CPU 使用的资源百分比
-
PRI 这个是 Priority (优先执行序) 的缩写,详细后面介绍
-
NI 这个是 Nice 值,在下一小节我们会持续介绍
-
ADDR 这个是 kernel function,指出该程序在内存的那个部分。如果是个 running的程序,一般就是 “-”
-
SZ 使用掉的内存大小
-
WCHAN 目前这个程序是否正在运作当中,若为 - 表示正在运作
-
TTY 登入者的终端机位置
-
TIME 使用掉的 CPU 时间。
-
CMD 所下达的指令为何
在预设的情况下, ps 仅会列出与目前所在的 bash shell 有关的 PID 而已,所以, 当我使用 ps -l 的时候,只有三个 PID。
ps aux说明:
-
USER:该 process 属于那个使用者账号的
-
PID :该 process 的号码
-
%CPU:该 process 使用掉的 CPU 资源百分比
-
%MEM:该 process 所占用的物理内存百分比
-
VSZ :该 process 使用掉的虚拟内存量 (Kbytes)
-
RSS :该 process 占用的固定的内存量 (Kbytes)
-
TTY :该 process 是在那个终端机上面运作,若与终端机无关,则显示 ?,另外, tty1-tty6 是本机上面的登入者程序,若为 pts/0 等等的,则表示为由网络连接进主机的程序。
-
STAT:该程序目前的状态,主要的状态有
R :该程序目前正在运作,或者是可被运作
S :该程序目前正在睡眠当中 (可说是 idle 状态),但可被某些讯号 (signal) 唤醒。
T :该程序目前正在侦测或者是停止了
Z :该程序应该已经终止,但是其父程序却无法正常的终止他,造成 zombie (疆尸) 程序的状态 -
START:该 process 被触发启动的时间
-
TIME :该 process 实际使用 CPU 运作的时间
-
COMMAND:该程序的实际指令
八、开放题目
8.1 大文件url判断重复问题(待补充)
九、计算机网络
9.1 访问一次百度的过程(待补充)
9.2 DNS(待补充)
9.3 tcp三次握手
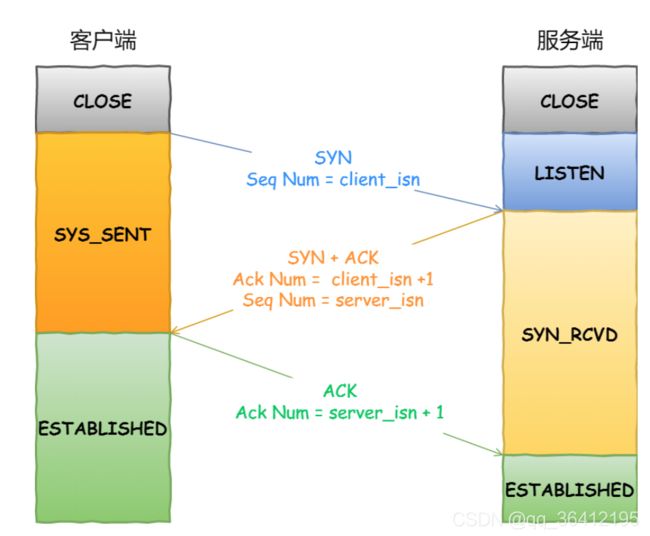
(1)一开始,客户端和服务端都处于CLOSED状态。先是服务端主动监听某个端口,处于LISTEN状态。
(2)客户端发送第一次握手信息,SYN=1,seq=x,不应该携带数据
(3)服务端收到SYN报文后,seq = y ,ack = x+1,ACK = 1,之后服务端处于SYN-RCVD状态
(4)客户端应该再想服务端回报一个报文。可以携带数据。
为什么采用三次链接?
-
主要是为了防止旧的重复连接初始化造成混乱,可能之前一个SYN报文靖哥网络堵塞很久才到服务端,这时候客户端与服务端都已经完事了,如果没有第三次握手就会造成这次链接成功初始化。
-
再就是三次握手可以同步序列号
9.4 http四次挥手
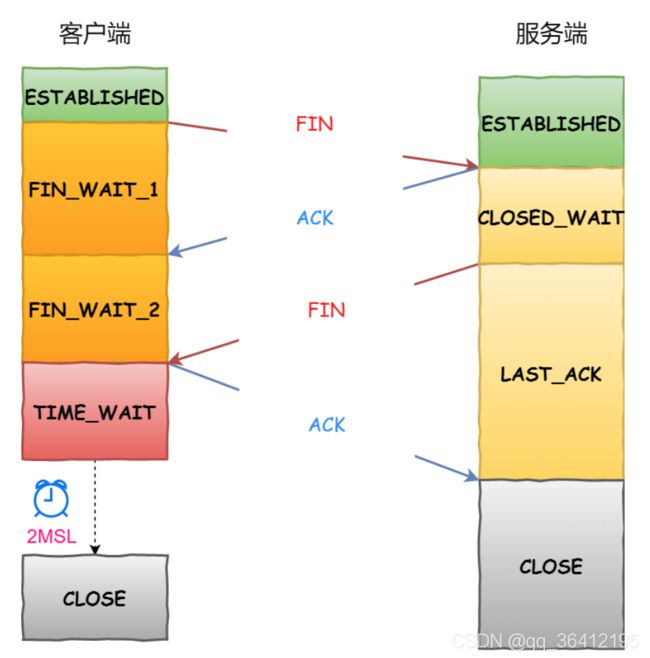

为什么挥手需要四次
- 关闭连接时,客户端向服务端发送FIN时仅仅表示客户端不再发送数据了但是还能接受数据。
- 服务端收到客户端的FIN报文时,先回一个ACK报文,而服务端可能还有数据需要处理和发送,等服务端不再发送数据时,才发送FIN报文给客户端来表示同意关闭现在的连接。
为什么TIME_WAIT的等待时间是2MSL?

如果被动关闭放没有收到主动关闭方的最后一个ACK,这时候被动关闭方会重传FIN,主动关闭方接收到这个FIn后就会再重传了,这里ACK到被动关闭方再到被动关闭方发送FIN的时间就是小于2MSL的。
而且2MSL后本次连接所有的数据报都会消失再网络中,不会对下一次连接造成影响。

9.5 https
1. 为什么https会出现?
一个简单的回答可能会是 HTTP 不安全。由于 HTTP 天生明文传输的特性,在 HTTP 的传输过程中,任何人都有可能从中截获、修改或者伪造请求发送,所以可以认为 HTTP 是不安全的;在 HTTP 的传输过程中不会验证通信方的身份,因此 HTTP 信息交换的双方可能会遭到伪装,也就是没有用户验证;在 HTTP 的传输过程中,接收方和发送方并不会验证报文的完整性,综上,为了结局上述问题,HTTPS 应用而生。
2. 什么是https
HTTPS 的全称是 Hypertext Transfer Protocol Secure,它用来在计算机网络上的两个端系统之间进行安全的交换信息(secure communication),它相当于在 HTTP 的基础上加了一个 Secure 安全的词眼,那么我们可以给出一个 HTTPS 的定义:HTTPS 是一个在计算机世界里专门在两点之间安全的传输文字、图片、音频、视频等超文本数据的约定和规范。 HTTPS 是 HTTP 协议的一种扩展,它本身并不保传输的证安全性,那么谁来保证安全性呢?在 HTTPS 中,使用传输层安全性(TLS)或安全套接字层(SSL)对通信协议进行加密。也就是
HTTP + SSL(TLS) = HTTPS。
3. https做了什么?
HTTPS 协议提供了三个关键的指标:
- 加密(Encryption), HTTPS 通过对数据加密来使其免受窃听者对数据的监听,这就意味着当用户在浏览网站时,没有人能够监听他和网站之间的信息交换,或者跟踪用户的活动,访问记录等,从而窃取用户信息。
- 数据一致性(Data integrity),数据在传输的过程中不会被窃听者所修改,用户发送的数据会完整的传输到服务端,保证用户发的是什么,服务器接收的就是什么。
- 身份认证(Authentication),是指确认对方的真实身份,也就是证明你是你(可以比作人脸识别),它可以防止中间人攻击并建立用户信任。
HTTPS 协议其实非常简单,RFC 文档很小,只有短短的 7 页,里面规定了新的协议名,默认端口号443,至于其他的应答模式、报文结构、请求方法、URI、头字段、连接管理等等都完全沿用 HTTP,没有任何新的东西。
也就是说,除了协议名称和默认端口号外(HTTP 默认端口 80),HTTPS 协议在语法、语义上和 HTTP 一样,HTTP 有的,HTTPS 也照单全收。那么,HTTPS 如何做到 HTTP 所不能做到的安全性呢?关键在于这个 S 也就是 SSL/TLS 。
4 什么是 SSL/TLS
TLS(Transport Layer Security) 是 SSL(Secure Socket Layer) 的后续版本,它们是用于在互联网两台计算机之间用于身份验证和加密的一种协议。
SSL/TLS 通过称为 X.509 证书的数字文档,将网站和公司的实体信息绑定到加密密钥来进行工作。每一个密钥对(key pairs) 都有一个 私有密钥(private key) 和 公有密钥(public key),私有密钥是独有的,一般位于服务器上,用于解密由公共密钥加密过的信息;公有密钥是公有的,与服务器进行交互的每个人都可以持有公有密钥,用公钥加密的信息只能由私有密钥来解密
什么是 X.509:X.509 是公开密钥证书的标准格式,这个文档将加密密钥与(个人或组织)进行安全的关联。
X.509 主要应用如下
SSL/TLS 和 HTTPS 用于经过身份验证和加密的 Web 浏览
通过 S/MIME 协议签名和加密的电子邮件
代码签名:它指的是使用数字证书对软件应用程序进行签名以安全分发和安装的过程。
通过使用由知名公共证书颁发机构(例如SSL.com)颁发的证书对软件进行数字签名,开发人员可以向最终用户保证他们希望安装的软件是由已知且受信任的开发人员发布;并且签名后未被篡改或损害。还可用于文档签名
还可用于客户端认证
政府签发的电子身份证
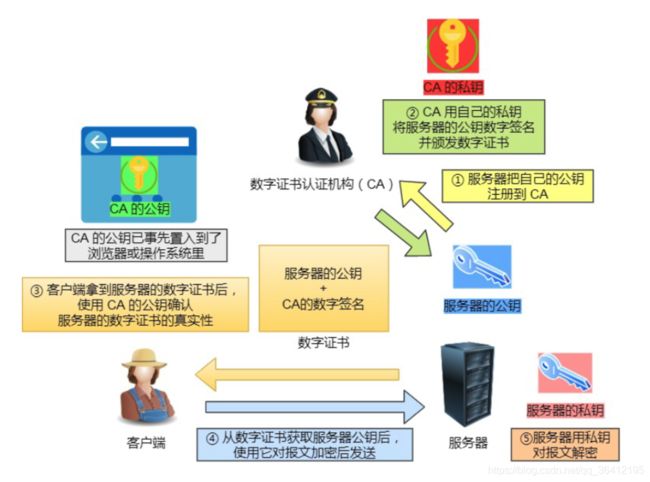
5 HTTPS 的内核是 HTTP
HTTPS 并不是一项新的应用层协议,只是 HTTP 通信接口部分由 SSL 和 TLS 替代而已。通常情况下,HTTP 会先直接和 TCP 进行通信。在使用 SSL 的 HTTPS 后,则会先演变为和 SSL 进行通信,然后再由 SSL 和 TCP 进行通信。也就是说,HTTPS 就是身披了一层 SSL 的 HTTP。(我都喜欢把骚粉留在最后。。。
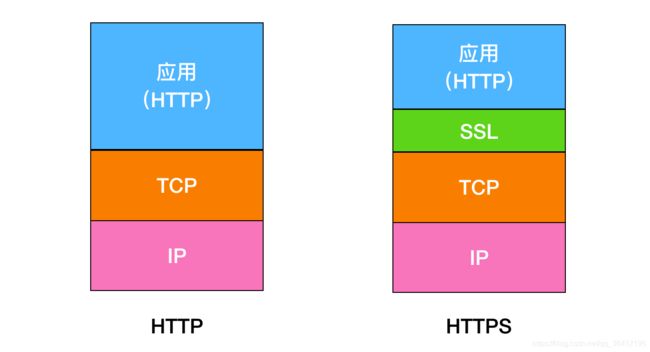
SSL 是一个独立的协议,不只有 HTTP 可以使用,其他应用层协议也可以使用,比如 SMTP(电子邮件协议)、Telnet(远程登录协议) 等都可以使用。
6 详解HTTPS
SSL 即安全套接字层,它在 OSI 七层网络模型中处于第五层,SSL 在 1999 年被 IETF(互联网工程组)更名为 TLS ,即传输安全层,直到现在,TLS 一共出现过三个版本,1.1、1.2 和 1.3 ,目前最广泛使用的是 1.2,所以接下来的探讨都是基于 TLS 1.2 的版本上的。
TLS 用于两个通信应用程序之间提供保密性和数据完整性。TLS 由记录协议、握手协议、警告协议、变更密码规范协议、扩展协议等几个子协议组成,综合使用了对称加密、非对称加密、身份认证等许多密码学前沿技术。
下面举一个 TLS 例子来看一下 TLS 的结构:
ECDHE-ECDSA-AES256-GCM-SHA384
TLS 的密码套件比较规范,基本格式就是 密钥交换算法 - 签名算法 - 对称加密算法 - 摘要算法 组成的一个密码串,有时候还有分组模式,我们先来看一下刚刚是什么意思。
使用 ECDHE 进行密钥交换,使用 ECDSA 进行签名和认证,然后使用 AES 作为对称加密算法,密钥的长度是 256 位,使用 GCM 作为分组模式,最后使用 SHA384 作为摘要算法。
TLS 在根本上使用对称加密和 非对称加密 两种形式。
对称加密(Symmetrical Encryption)顾名思义就是指加密和解密时使用的密钥都是同样的密钥。只要保证了密钥的安全性,那么整个通信过程也就是具有了机密性。
非对称加密:非对称加密(Asymmetrical Encryption) 也被称为公钥加密,相对于对称加密来说,非对称加密是一种新的改良加密方式。密钥通过网络传输交换,它能够确保及时密钥被拦截,也不会暴露数据信息。非对称加密中有两个密钥,一个是公钥,一个是私钥,公钥进行加密,私钥进行解密。公开密钥可供任何人使用,私钥只有你自己能够知道。
使用公钥加密的文本只能使用私钥解密,同时,使用私钥加密的文本也可以使用公钥解密。公钥不需要具有安全性,因为公钥需要在网络间进行传输,非对称加密可以解决密钥交换的问题。网站保管私钥,在网上任意分发公钥,你想要登录网站只要用公钥加密就行了,密文只能由私钥持有者才能解密。而黑客因为没有私钥,所以就无法破解密文。
摘要算法
如何实现完整性呢?在 TLS 中,实现完整性的手段主要是 摘要算法(Digest Algorithm)。摘要算法你不清楚的话,MD5 你应该清楚,MD5 的全称是 Message Digest Algorithm 5,它是属于密码哈希算法(cryptographic hash algorithm)的一种,MD5 可用于从任意长度的字符串创建 128 位字符串值。尽管 MD5 存在不安全因素,但是仍然沿用至今。MD5 最常用于验证文件的完整性。但是,它还用于其他安全协议和应用程序中,例如 SSH、SSL 和 IPSec。一些应用程序通过向明文加盐值或多次应用哈希函数来增强 MD5 算法。
我们再回到摘要算法的讨论上来,其实你可以把摘要算法理解成一种特殊的压缩算法,它能够把任意长度的数据压缩成一种固定长度的字符串,这就好像是给数据加了一把锁。
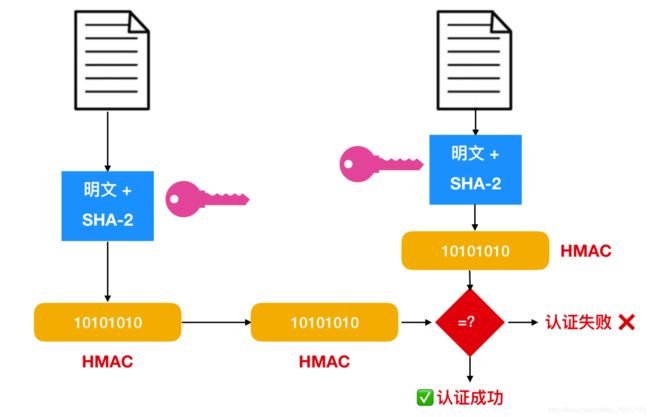
9.7 https建立连接的过程
(1)客户端发起http连接请求:
当用户在浏览器(后文称作客户端)地址栏敲击https://www.scwipe.com时,浏览器去到dns服务器获取此url对应的ip,然后客户端连接上服务端的443端口,将此请求发送给到服务端,此时客户端同时将自己支持的加密算法带给服务端;
(2)服务端发送证书
服务端收到这套加密算法的时候,和自己支持的加密算法进行对比(也就是和自己的私钥进行对比),如果不符合,就断开连接;如果符合,服务端就将CA证书发送给客户端,此证书中包括了数字证书包含的内容:1、证书颁发机构;2、使用机构;3、公钥;4、有效期;5、签名算法;6、签名hash算法;7、指纹算法;8、指纹。
这里服务端发送的东西是用私钥进行加密的,公钥都能解开,并不能保证发送的数据包不被别人看到,所以后面的过程会和客户端商量选择一个对称加密(只能用私钥解开,这里详情请移步非对称、对称加解密相关问题)来对传输的数据进行加密。
(3)客户端验证服务端发来的证书
- 验证证书:
客户端验证收到的证书,包括发布机构是否合法、过期,证书中包含的网址是否与当前访问网址一致等等。
- 生成随机数
客户端验证证书无误后(或者接受了不信任的证书),会生成一个随机数,用服务端发过来的公钥进行加密。如此一来,此随机数只有服务端的私钥能解开了。
- 生成握手信息
用证书中的签名hash算法取握手信息的hash值,然后用生成的随机数对[握手信息和握手信息的hash值]进行加密,然后用公钥将随机数进行加密后,一起发送给服务端。其中计算握手信息的hash值,目的是为了保证传回到服务端的握手信息没有被篡改。
(4)服务端接收随机数加密的信息,并解密得到随机数,验证握手信息是否被篡改。
服务端收到客户端传回来的用随机数加密的信息后,先用私钥解密随机数,然后用解密得到的随机数解密握手信息,获取握手信息和握手信息的hash值,计算自己发送的握手信息的hash值,与客户端传回来的进行对比验证。
如果验证无误,同样使用随机字符串加密握手信息和握手信息hash值发回给到客户端。
(5)客户端验证服务端发送回来的握手信息,完成握手
客户端收到服务端发送过来的握手信息后,用开始自己生成的随机数进行解密,验证被随机数加密的握手信息和握手信息hash值。
验证无误后,握手过程就完成了,从此服务端和客户端就开始用那串随机数进行对称加密通信了(常用的对称加密算法有AES)。


9.8 防止SYN攻击
(1)修改Linux内核参数
通过修改内核参数,控制队列大小和队满的时候应做什么处理。
- 当网卡接受数据包的速度大于内核处理速度时,会有一个队列保存这些数据包。控制该队列的最大值如下参数:
net.core.netdev_max_backlog
-
SYN_RCVD状态连接的最大个数:
net.ipv4.tcp_max_syn_backlog -
超出处理能力时,对新的SYN直接回报RST,丢弃连接:
(2)设置tcp_syncookies
先看一下syn队列与accept队列是如何工作的:
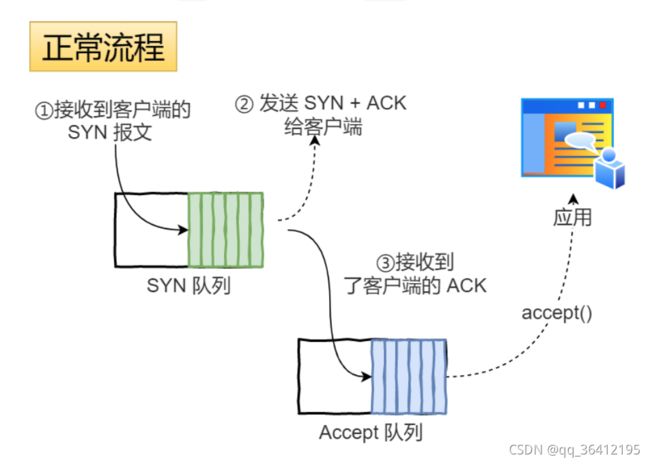
正常流程如下:
- 当服务端接受到客户端的SYN报文时,会将其加入到SYN队列
- 接着发送SYN+ACK给客户端,等待客户端回应ACK
- 服务端接受到ACK报文后,从SYN队列移除放入Acccept队列
- 应用通过调用accept()接口,从Accept队列中取出连接。
应用程序过慢时,会导致Accept队列被占满。
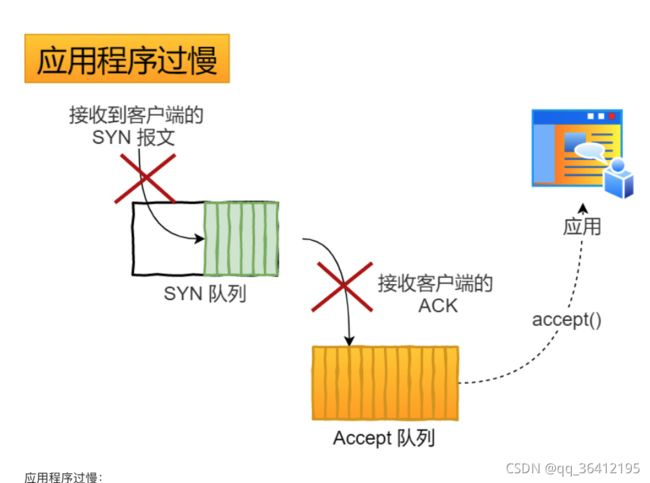
受到SYN攻击时,会导致SYN队列被占满
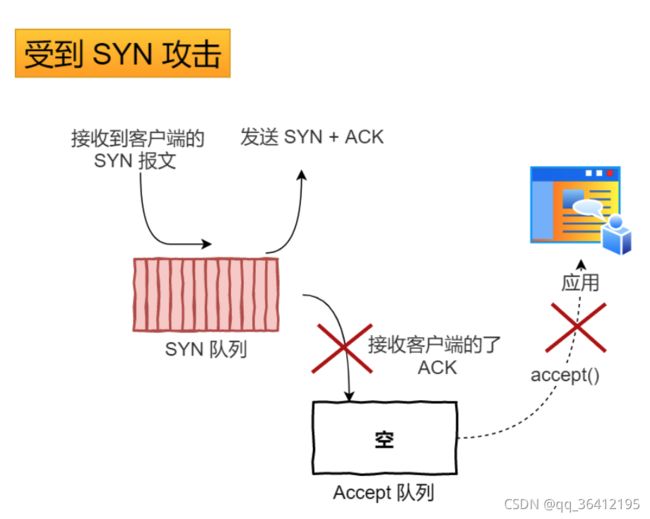
可以通过设置tcp_syncookies的方式来应对SYN攻击:
![]()
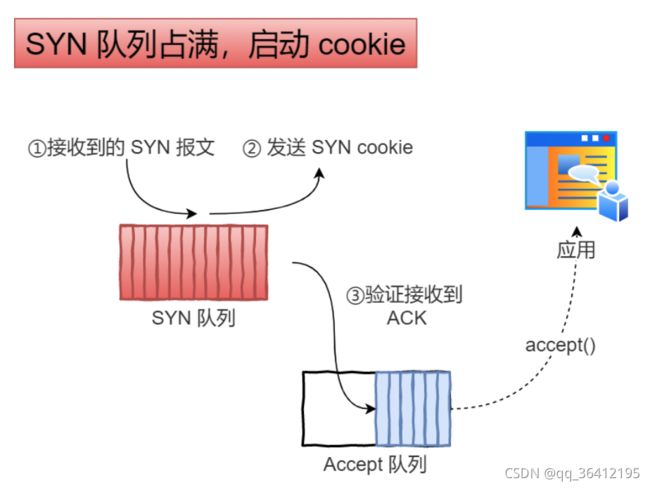
- 当SYN队列满了之后,后续服务收到SYN包,不进入SYN队列
- 计算出一个cookie值,再以SYN+ACK中的序列号返回客户端
- 服务端接收到客户端的应答报文时,服务器会检查这个ACK包的合法性。如果合法,直接放入Accept队列
- 最后应用调用accept()socket接口,从Accept队列取出连接。
十、分布式
10.1 reactor模式
Reactor模式,是基于Java NIO的,在他的基础上,抽象出来两个组件——Reactor和Handler两个组件:
(1)Reactor:负责响应IO事件,当检测到一个新的事件,将其发送给相应的Handler去处理;新的事件包含连接建立就绪、读就绪、写就绪等。
下图十最简单的单Reactor单线程模型,Reactor线程是个多面手,负责多路分离套接字,Accept新连接,并分派请求到Handler处理器中。
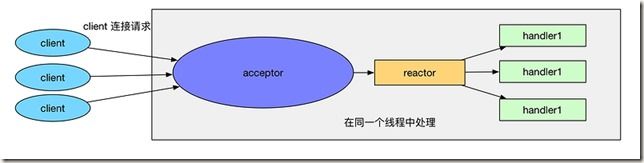
package com.crazymakercircle.ReactorModel;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
import java.util.Set;
class Reactor implements Runnable
{
final Selector selector;
final ServerSocketChannel serverSocket;
Reactor(int port) throws IOException
{ //Reactor初始化
selector = Selector.open();
serverSocket = ServerSocketChannel.open();
serverSocket.socket().bind(new InetSocketAddress(port));
//非阻塞
serverSocket.configureBlocking(false);
//分步处理,第一步,接收accept事件
SelectionKey sk =
serverSocket.register(selector, SelectionKey.OP_ACCEPT);
//attach callback object, Acceptor
sk.attach(new Acceptor());
}
public void run()
{
try
{
while (!Thread.interrupted())
{
selector.select();
Set selected = selector.selectedKeys();
Iterator it = selected.iterator();
while (it.hasNext())
{
//Reactor负责dispatch收到的事件
dispatch((SelectionKey) (it.next()));
}
selected.clear();
}
} catch (IOException ex)
{ /* ... */ }
}
void dispatch(SelectionKey k)
{
Runnable r = (Runnable) (k.attachment());
//调用之前注册的callback对象
if (r != null)
{
r.run();
}
}
// inner class
class Acceptor implements Runnable
{
public void run()
{
try
{
SocketChannel channel = serverSocket.accept();
if (channel != null)
new Handler(selector, channel);
} catch (IOException ex)
{ /* ... */ }
}
}
}
package com.crazymakercircle.ReactorModel;
import com.crazymakercircle.config.SystemConfig;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.SocketChannel;
class Handler implements Runnable
{
final SocketChannel channel;
final SelectionKey sk;
ByteBuffer input = ByteBuffer.allocate(SystemConfig.INPUT_SIZE);
ByteBuffer output = ByteBuffer.allocate(SystemConfig.SEND_SIZE);
static final int READING = 0, SENDING = 1;
int state = READING;
Handler(Selector selector, SocketChannel c) throws IOException
{
channel = c;
c.configureBlocking(false);
// Optionally try first read now
sk = channel.register(selector, 0);
//将Handler作为callback对象
sk.attach(this);
//第二步,注册Read就绪事件
sk.interestOps(SelectionKey.OP_READ);
selector.wakeup();
}
boolean inputIsComplete()
{
/* ... */
return false;
}
boolean outputIsComplete()
{
/* ... */
return false;
}
void process()
{
/* ... */
return;
}
public void run()
{
try
{
if (state == READING)
{
read();
}
else if (state == SENDING)
{
send();
}
} catch (IOException ex)
{ /* ... */ }
}
void read() throws IOException
{
channel.read(input);
if (inputIsComplete())
{
process();
state = SENDING;
// Normally also do first write now
//第三步,接收write就绪事件
sk.interestOps(SelectionKey.OP_WRITE);
}
}
void send() throws IOException
{
channel.write(output);
//write完就结束了, 关闭select key
if (outputIsComplete())
{
sk.cancel();
}
}
}
单线程模式的缺陷
当其中某个 handler 阻塞时, 会导致其他所有的 client 的 handler 都得不到执行, 并且更严重的是, handler 的阻塞也会导致整个服务不能接收新的 client 请求(因为 acceptor 也被阻塞了)。 因为有这么多的缺陷, 因此单线程Reactor 模型用的比较少。这种单线程模型不能充分利用多核资源,所以实际使用的不多。
多线程的Reactor
在单线程Reactor模式基础上,做如下改进:
- 将Handler处理器的执行放入线程池,多线程进行业务处理。
- 而对于Reactor而言,可以仍为单个线程。如果服务器为多核的CPU,为充分利用系统资源,可以将Reactor拆分为两个线程。
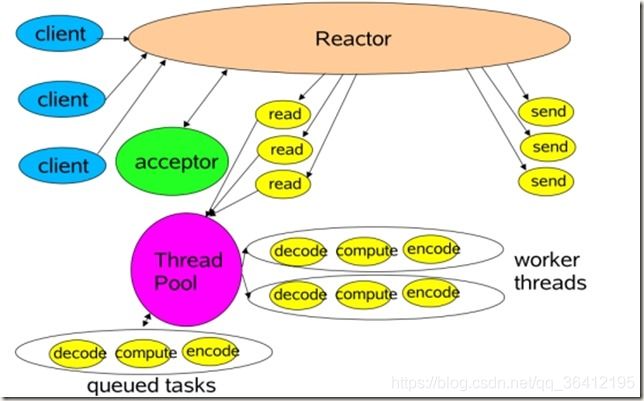
package com.crazymakercircle.ReactorModel;
import com.crazymakercircle.config.SystemConfig;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.SocketChannel;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
class MthreadHandler implements Runnable
{
final SocketChannel channel;
final SelectionKey selectionKey;
ByteBuffer input = ByteBuffer.allocate(SystemConfig.INPUT_SIZE);
ByteBuffer output = ByteBuffer.allocate(SystemConfig.SEND_SIZE);
static final int READING = 0, SENDING = 1;
int state = READING;
ExecutorService pool = Executors.newFixedThreadPool(2);
static final int PROCESSING = 3;
MthreadHandler(Selector selector, SocketChannel c) throws IOException
{
channel = c;
c.configureBlocking(false);
// Optionally try first read now
selectionKey = channel.register(selector, 0);
//将Handler作为callback对象
selectionKey.attach(this);
//第二步,注册Read就绪事件
selectionKey.interestOps(SelectionKey.OP_READ);
selector.wakeup();
}
boolean inputIsComplete()
{
/* ... */
return false;
}
boolean outputIsComplete()
{
/* ... */
return false;
}
void process()
{
/* ... */
return;
}
public void run()
{
try
{
if (state == READING)
{
read();
}
else if (state == SENDING)
{
send();
}
} catch (IOException ex)
{ /* ... */ }
}
synchronized void read() throws IOException
{
// ...
channel.read(input);
if (inputIsComplete())
{
state = PROCESSING;
//使用线程pool异步执行
pool.execute(new Processer());
}
}
void send() throws IOException
{
channel.write(output);
//write完就结束了, 关闭select key
if (outputIsComplete())
{
selectionKey.cancel();
}
}
synchronized void processAndHandOff()
{
process();
state = SENDING;
// or rebind attachment
//process完,开始等待write就绪
selectionKey.interestOps(SelectionKey.OP_WRITE);
}
class Processer implements Runnable
{
public void run()
{
processAndHandOff();
}
}
}
10.2 IO
BIO 同步阻塞IO
在linux中的Java进程中,默认情况下所有的socket都是blocking IO。在阻塞式 I/O 模型中,应用程序在从IO系统调用开始,一直到到系统调用返回,这段时间是阻塞的。返回成功后,应用进程开始处理用户空间的缓存数据

举个栗子,发起一个blocking socket的read读操作系统调用,流程大概是这样:
(1)当用户线程调用了read系统调用,内核(kernel)就开始了IO的第一个阶段:准备数据。很多时候,数据在一开始还没有到达(比如,还没有收到一个完整的Socket数据包),这个时候kernel就要等待足够的数据到来。
(2)当kernel一直等到数据准备好了,它就会将数据从kernel内核缓冲区,拷贝到用户缓冲区(用户内存),然后kernel返回结果。
(3)从开始IO读的read系统调用开始,用户线程就进入阻塞状态。一直到kernel返回结果后,用户线程才解除block的状态,重新运行起来
所以,blocking IO的特点就是在内核进行IO执行的两个阶段,用户线程都被block了。
同步非阻塞NIO(None Blocking IO)
在linux系统下,可以通过设置socket使其变为non-blocking。NIO 模型中应用程序在一旦开始IO系统调用,会出现以下两种情况:
(1)在内核缓冲区没有数据的情况下,系统调用会立即返回,返回一个调用失败的信息
(2)在内核缓冲区有数据的情况下,是阻塞的,直到数据从内核缓冲复制到用户进程缓冲。复制完成后,系统调用返回成功,应用进程开始处理用户空间的缓存数据。
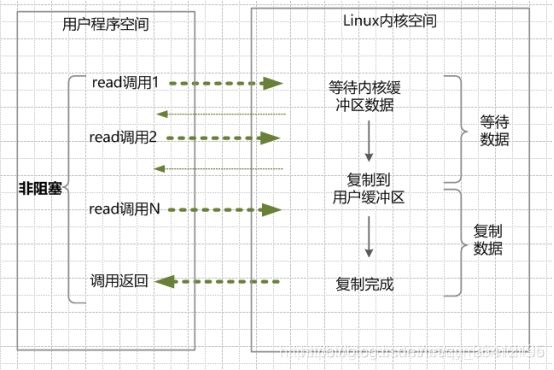
举个栗子。发起一个non-blocking socket的read读操作系统调用,流程是这个样子:
(1)在内核数据没有准备好的阶段,用户线程发起IO请求时,立即返回。用户线程需要不断地发起IO系统调用。
(2)内核数据到达后,用户线程发起系统调用,用户线程阻塞。内核开始复制数据。它就会将数据从kernel内核缓冲区,拷贝到用户缓冲区(用户内存),然后kernel返回结果。
(3)用户线程才解除block的状态,重新运行起来。经过多次的尝试,用户线程终于真正读取到数据,继续执行。
优点:每次发起的 IO 系统调用,在内核的等待数据过程中可以立即返回。用户线程不会阻塞,实时性较好。
缺点:需要不断的重复发起IO系统调用,这种不断的轮询,将会不断地询问内核,这将占用大量的 CPU 时间,系统资源利用率较低。
总之,NIO模型在高并发场景下,也是不可用的。一般 Web 服务器不使用这种 IO 模型。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。java的实际开发中,也不会涉及这种IO模型。
** IO多路复用模型(I/O multiplexing)**
Java NIO(New IO) 不是IO模型中的NIO模型,而是另外的一种模型,叫做IO多路复用模型( IO multiplexing
如何避免同步非阻塞NIO模型中轮询等待的问题呢?这就是IO多路复用模型。
IO多路复用模型,就是通过一种新的系统调用,一个进程可以监视多个文件描述符,一旦某个描述符就绪(一般是内核缓冲区可读/可写),内核kernel能够通知程序进行相应的IO系统调用。
目前支持IO多路复用的系统调用,有 select,epoll等等。select系统调用,是目前几乎在所有的操作系统上都有支持,具有良好跨平台特性。epoll是在linux 2.6内核中提出的,是select系统调用的linux增强版本。
IO多路复用模型的基本原理就是select/epoll系统调用,单个线程不断的轮询select/epoll系统调用所负责的成百上千的socket连接,当某个或者某些socket网络连接有数据到达了,就返回这些可以读写的连接。因此,好处也就显而易见了——通过一次select/epoll系统调用,就查询到到可以读写的一个甚至是成百上千的网络连接。
举个栗子。发起一个多路复用IO的的read读操作系统调用,流程是这个样子:
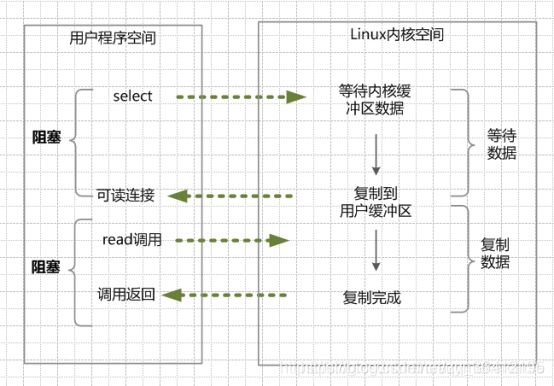
在这种模式中,首先不是进行read系统调动,而是进行select/epoll系统调用。当然,这里有一个前提,需要将目标网络连接,提前注册到select/epoll的可查询socket列表中。然后,才可以开启整个的IO多路复用模型的读流程。
(1)进行select/epoll系统调用,查询可以读的连接。kernel会查询所有select的可查询socket列表,当任何一个socket中的数据准备好了,select就会返回。
(2)用户线程获得了目标连接后,发起read系统调用,用户线程阻塞。内核开始复制数据。它就会将数据从kernel内核缓冲区,拷贝到用户缓冲区(用户内存),然后kernel返回结果.
(3)用户线程才解除block的状态,用户线程终于真正读取到数据,继续执行。
10.3 epoll与select
select的调用复杂度是线性的,即O(n)。举个例子,一个保姆照看一群孩子,如果把孩子是否需要尿尿比作网络IO事件,select的作用就好比这个保姆挨个询问每个孩子:你要尿尿吗?如果孩子回答是,保姆则把孩子拎出来放到另外一个地方。当所有孩子询问完之后,保姆领着这些要尿尿的孩子去上厕所(处理网络IO事件)。
还是以保姆照看一群孩子为例,在epoll机制下,保姆不再需要挨个的询问每个孩子是否需要尿尿。取而代之的是,每个孩子如果自己需要尿尿的时候,自己主动的站到事先约定好的地方,而保姆的职责就是查看事先约定好的地方是否有孩子。如果有小孩,则领着孩子去上厕所(网络事件处理)。因此,epoll的这种机制,能够高效的处理成千上万的并发连接,而且性能不会随着连接数增加而下降。

select
select本质上是通过设置或检查存放fd标志位的数据结构进行下一步处理。 这带来缺点: - 单个进程可监视的fd数量被限制,即能监听端口的数量有限 单个进程所能打开的最大连接数由FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是3232,同理64位机器上FD_SETSIZE为3264),当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响,这需要进一步的测试 一般该数和系统内存关系很大,具体数目可以cat /proc/sys/fs/file-max察看。32位机默认1024个,64位默认2048。
对socket是线性扫描,即轮询,效率较低: 仅知道有I/O事件发生,却不知是哪几个流,只会无差异轮询所有流,找出能读数据或写数据的流进行操作。同时处理的流越多,无差别轮询时间越长 - O(n)。
当socket较多时,每次select都要通过遍历FD_SETSIZE个socket,不管是否活跃,这会浪费很多CPU时间。如果能给 socket 注册某个回调函数,当他们活跃时,自动完成相关操作,即可避免轮询,这就是epoll与kqueue。
select方法本质其实就是维护了一个文件描述符(fd)数组,以此为基础,实现IO多路复用的功能。这个fd数组有长度限制,在32位系统中,最大值为1024个,而在64位系统中,最大值为2048个,这个配置可以调用
![]()
来查看
select方法被调用,首先需要将fd_set从用户空间拷贝到内核空间,然后内核用poll机制(此poll机制非IO多路复用的那个poll方法,可参加附录)直到有一个fd活跃,或者超时了,方法返回。
int select(int maxfdpl, fd_set readfds, fd_set writefds, fd_set exceptfds, struct timeval timeout);
- 如果返回值为-1,表明发生了错误
- 如果返回值为0,表明超时了
- 如果返回值为正数,表明有n个fd准备就绪了
select方法返回后,需要轮询fd_set,以检查出发生IO事件的fd。这样一套下来,select方法的缺点就很明显了:
- fd_set在用户空间和内核空间的频繁复制,效率低
- 单个进程可监控的fd数量有限制,无论是1024还是2048,对于很多情景来说都是不够用的。
- 基于轮询来实现,效率低
poll

poll本质上和select没有区别,依然需要进行数据结构的复制,依然是基于轮询来实现,但区别就是,select使用的是fd数组,而poll则是维护了一个链表,所以从理论上,poll方法中,单个进程能监听的fd不再有数量限制。但是轮询,复制等select存在的问题,poll依然存在
epoll
epoll就是对select和poll的改进了。它的核心思想是基于事件驱动来实现的,实现起来也并不难,就是给每个fd注册一个回调函数,当fd对应的设备发生IO事件时,就会调用这个回调函数,将该fd放到一个链表中,然后由客户端从该链表中取出一个个fd,以此达到O(1)的时间复杂度
epoll操作实际上对应着有三个函数:epoll_create,epoll_ctr,epoll_wait
- epoll_create:epoll_create相当于在内核中创建一个存放fd的数据结构。在select和poll方法中,内核都没有为fd准备存放其的数据结构,只是简单粗暴地把数组或者链表复制进来;而epoll则不一样,epoll_create会在内核建立一颗专门用来存放fd结点的红黑树,后续如果有新增的fd结点,都会注册到这个epoll红黑树上。
- epoll_ctr:另一点不一样的是,select和poll会一次性将监听的所有fd都复制到内核中,而epoll不一样,当需要添加一个新的fd时,会调用epoll_ctr,给这个fd注册一个回调函数,然后将该fd结点注册到内核中的红黑树中。当该fd对应的设备活跃时,会调用该fd上的回调函数,将该结点存放在一个就绪链表中。这也解决了在内核空间和用户空间之间进行来回复制的问题。
- epoll_wait:epoll_wait的做法也很简单,其实直接就是从就绪链表中取结点,这也解决了轮询的问题,时间复杂度变成O(1)
所以综合来说,epoll的优点有:
- 没有最大并发连接的限制,远远比1024或者2048要大。(江湖传言1G的内存上能监听10W个端口)
- 效率变高。epoll是基于事件驱动实现的,不会随着fd数量上升而效率下降
- 减少内存拷贝的次数
水平触发 :水平触发的意思就是说,只要条件满足,对应的事件就会一直被触发。所以如果条件满足了但未进行处理,那么就会一直被通知
边缘触发:边缘触发的意思就是说,条件满足后,对应的事件只会被触发一次,无论是否被处理,都只会触发一次。
而对于select和poll来说,其触发都是水平触发。而epoll则有两种模式:·EPOLLLT和EPOLLET
- EPOLLLT(默认状态):也就是水平触发。在该模式下,只要这个fd还有数据可读,那么epoll_wait函数就会返回该fd
- EPOLLET(高速模式):也就是边缘触发。在该模式下,当被监控的fd上有可读写事件发生时,epoll_wait会通知程序去读写,若本次读写没有读完所有数据,或者甚至没有进行处理,那么下一次调用epoll_wait时,也不会获取到该fd。这种效率比水平触发的要高,系统中不会充斥着大量程序不感兴趣的fd,不感兴趣直接忽视就行,下次不会再触发
总结
- select,poll是基于轮询实现的,将fd_set从用户空间复制到内核空间,然后让内核空间以poll机制来进行轮询,一旦有其中一个fd对应的设备活跃了,那么就把整个fd_set返回给客户端(复制到用户空间),再由客户端来轮询每个fd的,找出发生了IO事件的fd
- epoll是基于事件驱动实现的,加入一个新的fd,会调用epoll_ctr函数为该fd注册一个回调函数,然后将该fd结点注册到内核中的epoll红黑树中,当IO事件发生时,就会调用回调函数,将该fd结点放到就绪链表中,epoll_wait函数实际上就是从这个就绪链表中获取这些fd。
- epoll分为EPOLLLT(水平触发,默认状态)和EPOLLET(边缘触发,效率高)
- 并不是所有的情况中epoll都是最好的,比如当fd数量比较小的时候,epoll不见得就一定比select和poll好
10.4 CAP与BASE
CAP
- 一致性(consistency):保持所有节点在同一个时刻具有相同的、逻辑一致的数据。
- 可用性(availability):保证每个请求不管成功还是失败都有响应。
- 分区容忍性(partition tolerance):系统中任何的信息丢失或者失败都不会影响系统的继续运作
针对这3个特点,Eric Brewer教授在2000年提出了CAP原则,也称为CAP定理。该原则指出,任何分布式系统都不能同时满足3个特点,如图1-6所示。
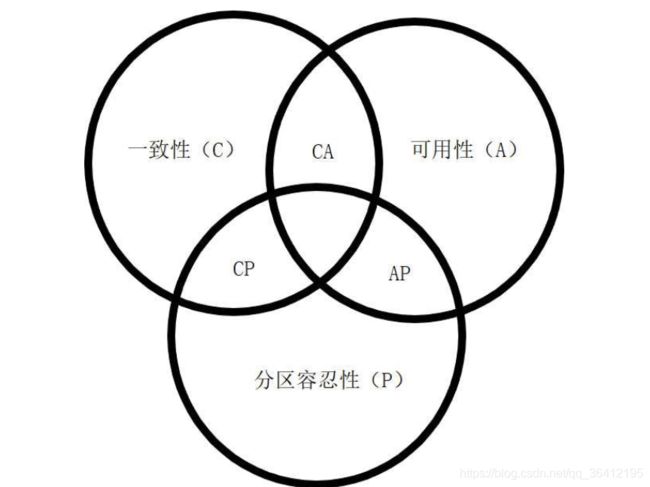
根据CAP原则,从图1-6中可以看出分布式系统只能满足3种情况。
- CA:满足一致性和可用性的系统。在可扩展性上难有建树。
- CP:满足一致性和分区容忍性的系统。通常性能不是特别高。
- AP:满足可用性和分区容忍性的系统。通常对一致性要求低一些,但性能会比较高。
BASE
- 强一致性:当用户完成数据更新操作之后,任何后续线程或者其他节点都能访问到最新值。这样的设计是最友好的,即用户上一次的操作,下一次都能读到。但根据CAP原则,这种实现需要对性能做出较大的牺牲。
- 弱一致性:当用户完成数据更新操作之后,并不能保证后续线程或者其他节点马上访问到最新值。它只能通过某种方法来保证最后的一致性。
BASE并非一个英文单词,而是几个英文单词的简写。
- BA(Basically Available,基本可用):在分布式系统中,最重要的需求是保证基本可用,有响应结果返回。例如,在“双十一抢购”的苛刻环境下,用户到电商处进行抢购。即使抢购失败,系统也会提示“系统繁忙,请过会儿再来”。我们分析一下这样的场景。用户是来购买商品的,而在抢购的环境下可能因为资源瓶颈,无法完成。为了避免用户长时间等待,系统会提示用户过会儿再来。这里的提示信息不需要消耗太多的系统资源,因而这样的场景就是典型的降级服务。虽然没有完成客户需要的抢购,但是却给了用户明确的信息,避免了用户长时间等待的情况,这样会给用户带来良好的体验
- S(Soft State,软状态):其意义在于允许系统存在中间状态。一般来说,系统之间的数据通信都会存有副本,而这些副本都会存在一定的延迟。这时推荐使用弱一致性代替强一致性。这样的好处在于,提高系统的可用和性能。在网站用户的体验中,快速显示结果往往比一致性更为重要,因为没人愿意使用一个几十秒都不能响应的网站。
- E(Eventual Consistency,最终一致性):是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态,以保证数据的正确性。
十一、Spring
11.1 IOC与AOP
IOC即控制反转, 是一种设计思想,而不是一个具体的技术实现。IoC 的思想就是将原本在程序中手动创建对象的控制权,交由 Spring 框架来管理。不过, IoC 并非 Spirng 特有,在其他语言中也有应用。是基于反射来实现的
AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。是基于代理来实现的。
AOP最为典型的应用实际就是数据库事务的管控。例如,当我们需要保存一个用户时,可能要连同它的角色信息一并保存到数据库中。于是,可以看到图4-4所示的一个流程图。
这里的用户信息和用户角色信息,我们都可以使用面向对象编程(OOP)进行设计,但是它们在数据库事务中的要求是,要么一起成功,要么一起失败,这样OOP就无能为力了。数据库事务毫无疑问是企业级应用关注的核心问题之一,而使用AOP可以解决这些问题。AOP还可以减少大量重复的工作。在Spring流行之前,我们可以使用JDBC代码实现很多的数据库操作,例如,插入一个用户的信息,我们可以用JDBC代码来实现。
- 打开数据库连接,然后对其属性进行设置;
- 执行SQL语句;
- 如果没有异常,则提交事务;
- 如果发生异常,则回滚事务;
- 关闭数据库事务连接。
我们如果使用AOP那整体流程就是下面这个样子的。
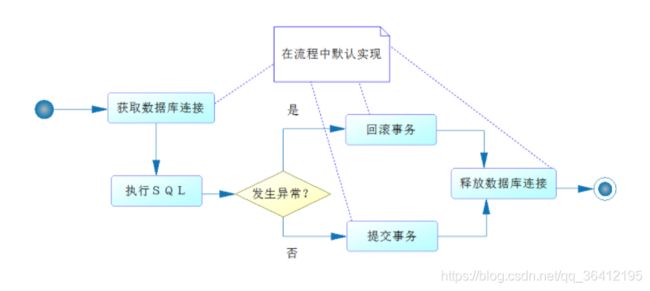
于是Spring就实现了用一个@Transactional就实现了这一套流程

11.2 Spring Cloud负载均衡(正在施工中。。)
BaseLoadBalancer
BaseLoadBalancer的chooseServer方法默认是采用轮询的方式来实现的,

ZoneAwareLoadBalancer
-
ZoneAwareLoadBalancer的chooseServer方法首先要判断是否存在Zone的概念并且判断一下Zone是否大于1,否则的话就会调用BaseLoadBalancer的chooseServer方法。
-
选取可用的Zone,并随机挑选一个Zone出来,然后根据此Zone的名称来获取负载均衡器。
具体流程如下所述:
- 判断是否启用了Zone的功能,如果没有Zone或者是Zone的数量只有1个,就采用BaseLoadBalancer的chooseServer方法来选择具体的服务,结束流程。
- 按照负载阈值来排除Zone,排除最高负载20%的Zone。
- 按照故障率阈值来排除Zone,排除故障率大于99.999%的Zone。
- 如果以上步骤都存在可用Zone,就采用随机算法获取Zone,选中Zone后,再通过负载均衡器(zoneLoadBalancer)的chooseServer方法选择服务。
- 如果Zone选择失败,就采用BaseLoadBalancer的chooseServer来选择服务实例。
负载均衡策略
11.3 bean的生命周期
下面展示了一个Bean的构造过程
如上图所示,Bean 的生命周期还是比较复杂的,下面来对上图每一个步骤做文字描述:
- Spring启动,查找并加载需要被Spring管理的bean,进行Bean的实例化
- Bean实例化后对将Bean的引入和值注入到Bean的属性中
- 如果Bean实现了BeanNameAware接口的话,Spring将Bean的Id传递给setBeanName()方法
- 如果Bean实现了BeanFactoryAware接口的话,Spring将调用setBeanFactory()方法,将BeanFactory容器实例传入
- 如果Bean实现了ApplicationContextAware接口的话,Spring将调用Bean的setApplicationContext()方法,将bean所在应用上下文引用传入进来。
- 如果Bean实现了BeanPostProcessor接口,Spring就将调用他们的postProcessBeforeInitialization()方法。
十二、计算机组成原理
12.1 虚地址
用户在编制程序时并不知道主存的使用状况,用户编程时使用的地址就是虚地址或逻辑地址,其对应的空间即徐空间或逻辑空间。而计算机物理内存的访问地址称为实地址或物理地址。程序将虚地址转换为实地址的过程称为程序的再定位。
以页为单位的虚拟存储器,称为页式虚拟存储器。它的虚拟空间跟主存空间都将被划分为相同大小的页。主存中的页,称为实页,虚存中的页,称为虚页。虚拟地址被分为两个字段,虚页号和页内偏移。为了对每个虚拟页的存放位置,存取位置,使用情况,修改情况等等进行等进行说明,操作系统在主存中给每个进程都生成一个页表。因此,每个虚拟页表都对应有一个页表项。页表是一张存放在主存中的,虚拟页与实页对照的映射表。其中存放位置字段用来建立虚拟页与实页之间的映射,进而进行地址转换。有效位用来表示对应页面是否存在。