文章目录
-
-
- 1. 准备环境
- 2. 表设计
- 3. 注册表
- 4. 创建超级用户
- 5. 登入后台
- 6. 数据查询
- 7. 新增数据
- 8. 修改数据
- 9. 删除数据
- 10. 局部修改
- 11. 视图子类使用分页器
-
- 11.1 页码分页
-
- 1. 全局配置
- 2. 局部配置
- 3. 重新页码分页
- 11.2 偏移分页
- 11.3 光标分页
- 12. 视图基类使用分页器
1. 准备环境
* 1. 新建项目, 不勾选模块层.
* 2. 将rest_farmework添加到app应用列表中.
INSTALLED_APPS = [
...
'rest_framework',
]
* 3. 自定义响应模块
1. 正常响应
2. dispatch异常响应
from rest_framework.response import Response
from rest_framework import status
class CustomResponse(Response):
def __init__(self, code=200, msg='访问成功!', data=None, status=status.HTTP_200_OK, **kwargs):
back_info_dict = {'code': code, 'msg': msg}
if data:
back_info_dict.update(data=data)
back_info_dict.update(kwargs)
super().__init__(data=back_info_dict, status=status)
from rest_framework.views import exception_handler
def exception_response(exc, context):
response= exception_handler(exc, context)
if not response:
if isinstance(exc, Exception):
return CustomResponse(501, f'访问不成功! {exc}', status=status.HTTP_501_NOT_IMPLEMENTED)
return CustomResponse(501, f"访问不成功! {response.data}", status=status.HTTP_501_NOT_IMPLEMENTED)
* 4. 项目配置文件settings.py中, 全局配置dispatch异常响应.
只能全局配置, 自定义的异常响应, 值就是一个字符串, 不能是列表['自定义的异常响应']
REST_FRAMEWORK = {
'EXCEPTION_HANDLER': 'utils.response.exception_response',
}
* 5. 测试路由, 路由分发模式
from django.conf.urls import url, include
from django.contrib import admin
from app01 import urls
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^app01/api/', include(urls))
]
* 6. 子路由
from django.conf.urls import url, include
from django.contrib import admin
from app01 import views
urlpatterns = [
url('^books/(?P(\d+)?)', views.BookAPI.as_view()),
]
* 7. BooksAPI视图
class BookAPI(GenericAPIView):
...
2. 表设计
外键字段参数:
on_delete: 删除关联数据与之关联的信息的行为
当删除关联表中的数据数, 当前表与其关联表的行为.
models.CASCADE 删除关联数据, 与之关联的信息也删除, 慎重使用.
models.DOTHING 删除关联数据, 引发错误IntegerityError
models.PROTECT 删除关联数据, 引发错误ProtectedError
models.SET_NULL 删除关联数据, 与之关联的值设置为null, 前提条件: 该字段可为空.
models.SET_DEFAULT 删除关联数据, 与之关联的值设置为默认值, 前提条件: 该字段可设置默认值.
models.SET 删除关联数据,
1. 与之关联的值设置为指定值, 设置: models.SET(值)
2. 与之关联的值设置为可执行对象的放回值, 设置: models.SET(可执行对象)
db_constraint: 与外键建立的关系.
db_constraint=True 建立真正的关联, 增删的操作受外键影响.
db_constraint=False 建立逻辑关联, 增删的操作不受外键影响. ORM操作与之前一样.
增删的操作.
表断关联
1. 表之间没有外键关联, 但是有外键逻辑关联(有充当外键的字段)
2. 断关联后不会影响数据库查询效率, 但是会极大提高数据库的增删改效率(不影响增删改查操作)
3. 段关联一定要通过编写逻辑代码保证表之间数据安全, 不要出现脏数据.
4. 级联关系:
一对一, 作者没有, 作者详情页也跟随没有, on_delete=models.CASCADE
一对多, 出版社没有了, 书还是存在, 出版的的id还在, on_delete=models.DO_NOTHING
部门没了, 员工没有部分, on_delete=models.SET_NULLM, 该字段允许为空 null=true
部门没了, 员工进入默认部门, on_delete=models.SET_DEFAULT, 该字段设置了默认值, default='z部门'
* 1. 基础表
删除数据不是真正的删除, 设置一个字段, 值为False代表数据被删除
创建数据时, 自动添加创建时间
修改数据时, 自动更新修改文件时间
from django.db import models
class BaseModel(models.Model):
is_delete = models.BooleanField(default=False)
create_time = models.DateTimeField(auto_now_add=True)
last_update_time = models.DateTimeField(auto_now=True)
class Meta:
abstract = True
* 2. 书籍表
class Book(BaseModel):
book_id = models.AutoField(primary_key=True, verbose_name='书籍主键', help_text='书籍主键')
title = models.CharField(max_length=32, verbose_name='书名', help_text='书的名字')
price = models.CharField(max_length=32, verbose_name='价格', help_text='书的价格')
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE, db_constraint=False, verbose_name='外键,关联出版社')
author = models.ManyToManyField(to='Author', db_constraint=False, verbose_name='虚拟, 关联作者')
class Meta:
verbose_name_plural = '书籍表'
def __str__(self):
return f'{self.title}'
* 3. 出版社
class Publish(BaseModel):
publish_id = models.AutoField(primary_key=True, verbose_name='出版社主键')
name = models.CharField(max_length=32, verbose_name='出版社名字', help_text='出版社名字')
email = models.EmailField(verbose_name='出版社邮箱')
address = models.CharField(max_length=32, verbose_name='出版社地址')
class Meta:
verbose_name_plural = '出版社表'
def __str__(self):
return f'{self.name}'
* 4. 作者
class Author(BaseModel):
author_id = models.AutoField(primary_key=True, verbose_name='作者主键')
name = models.CharField(max_length=32, verbose_name='作者名字')
gender = models.IntegerField(choices=((1, '男'), (2, '女')), verbose_name='性别')
detail = models.OneToOneField(to='AuthorDetail', on_delete=models.CASCADE, db_constraint=False,
verbose_name='外键, 关联详情')
class Meta:
verbose_name_plural = '作者表'
def __str__(self):
return f'{self.name}'
* 5. 作者详情
class AuthorDetail(BaseModel):
email = models.EmailField(verbose_name='作者邮箱')
WeChat = models.CharField(max_length=32, verbose_name='微信')
class Meta:
verbose_name_plural = '作者详情表'
def __str__(self):
return f'邮箱: {self.email} - 微信: {self.WeChat}'
生成表记录, 数据库迁移
python3.6 manage.py makemigrations
python3.6 manage.py migrate
3. 注册表
使用admin的后台管理操作表, 在app应用的admin.py文件中注册表.
from django.contrib import admin
from app01 import models
admin.site.register(models.Book)
admin.site.register(models.Publish)
admin.site.register(models.Author)
admin.site.register(models.AuthorDetail)
4. 创建超级用户
python3.6 manage.py createsuperuser
Username (leave blank to use '13600'): root
Email address: 136@qq.com
Password: zxc123456
Password (again): zxc123456
Superuser created successfully.
5. 登入后台
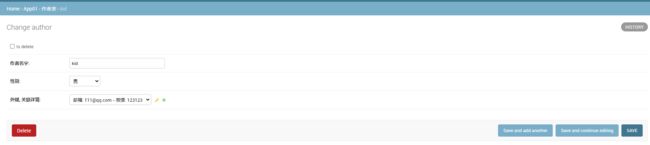
* 1. 为作者详情添加表数据

* 2. 为作者表添加数据
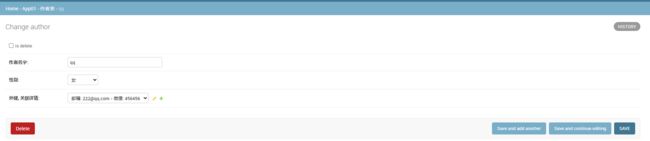
* 3. 为出版社添加数据

* 4. 为书籍表添加数据

6. 数据查询
* 1. 模型序列化器
from rest_framework import serializers
from app01 import models
class BookModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Book
fields = ('title', 'price', 'publish', 'author')
depth = 2
* 2. BooksAPI 视图类
from django.shortcuts import render
from rest_framework.generics import GenericAPIView
from app01 import models
from utils import serializers
from utils.response import CustomResponse
class BookAPI(GenericAPIView):
queryset = models.Book.objects.all()
serializer_class = serializers.BookModelSerializer
def get(self, request, *args, **kwargs):
pk = kwargs.get('pk')
if pk:
print(pk)
book_obj = self.get_object()
book_dict = self.get_serializer(instance=book_obj)
else:
book_obj = self.get_queryset().filter(is_delete=False)
book_dict = self.get_serializer(instance=book_obj, many=True)
return CustomResponse(data=book_dict.data)
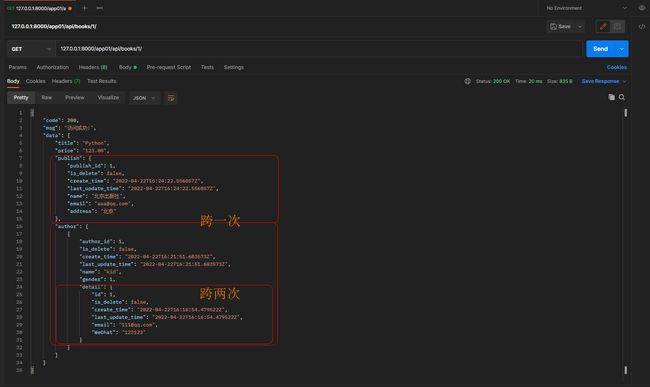
* 3. 单条数据查询, depth = 2
get请求: 127.0.0.1:8000/app01/api/books/1/
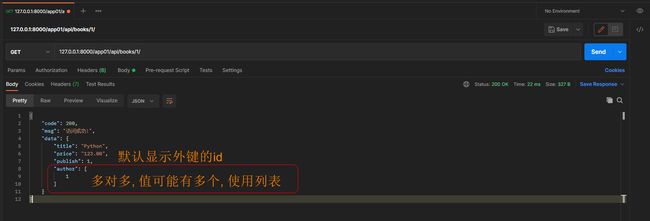
* 4. 单条数据查询, depth = 0
get请求: 127.0.0.1:8000/app01/api/books/1/
* 5. 在序列化器中设置想要展示的值, 方式1:
重写 publish字段的序列化, source = '表名.字段'
class BookModelSerializer(serializers.ModelSerializer):
publish = serializers.CharField(source='publish.name')
class Meta:
model = models.Book
fields = ('title', 'price', 'publish', 'author')
get请求: 127.0.0.1:8000/app01/api/books/1/

* 6. 在序列化器中设置想要展示的值, 方式2:
在表模型类中添加静态方法, fields = ['静态方法', ]
@property
def publish_name(self):
return self.publish.name
@property
def author_name_list(self):
authors = self.author.all()
return [author.name for author in authors]

* 7. 设置原来的外键为只些模式, 读出来也没有用, 在写入数据时使用. 需要使用.
class BookModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Book
fields = ('title', 'price', 'publish', 'publish_name', 'author', 'author_name_list')
depth = 0
extra_kwargs = {
'publish': {'write_only': True},
'publish_name': {'read_only': True},
'author': {'write_only': True},
'author_name_list': {'read_only': True},
}
get请求: 127.0.0.1:8000/app01/api/books/1/
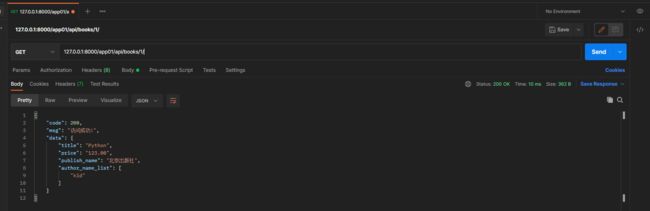
* 8. 查询所有数据
get请求: 127.0.0.1:8000/app01/api/books/
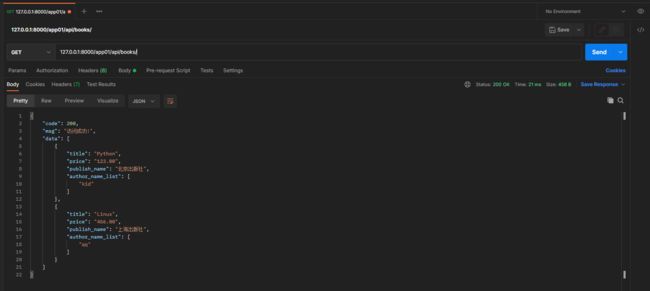
7. 新增数据
手动删除books表中的两条数据, 等下数据多了不好做实验.
* 1. 新增一条数据
post请求: 127.0.0.1:8000/app01/api/books/
携带的json数据:
{
"title": "Django",
"price": "123.00",
"publish": 1,
"author": [ 1, 2]
}
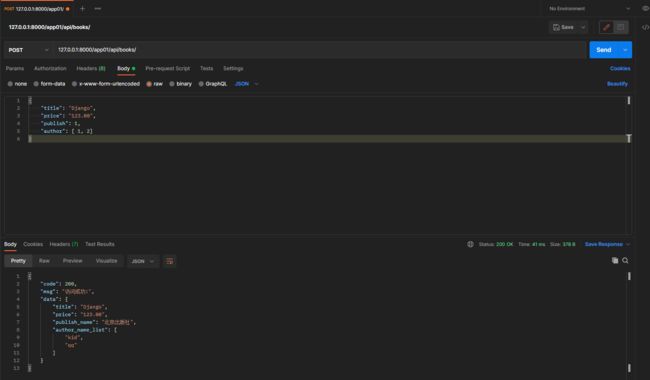
* 2. 批量增加数据
def post(self, request, *args, **kwargs):
if isinstance(request.data, dict):
book_obj = self.get_serializer(data=request.data)
else:
book_obj = self.get_serializer(data=request.data, many=True)
book_obj.is_valid(raise_exception=True)
book_obj.save()
return CustomResponse(data=book_obj.data)
self.get_serializer(data=request.data,)
对应的类型: <class 'utils.serializers.BookModelSerializer'>
self.get_serializer(data=request.data, many=True)
对应的类型: <class 'rest_framework.serializers.ListSerializer'>
from rest_framework.serializers import ListSerializer
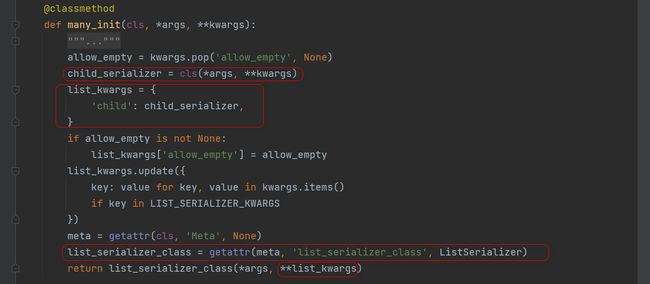
从序列化对象中, 获取list_serializer_class 属性的值, 如果获取不到就是用ListSerializer
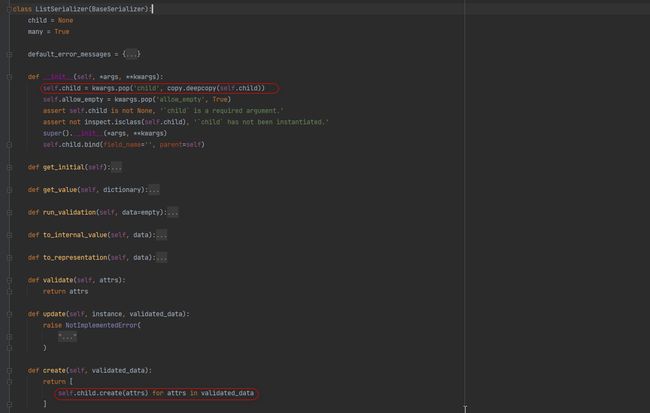
many不为True 使用的是 ModelSerializer的create()方法.
many为True ListSerializer 重复使用 ModelSerializer的create()方法创建数据.
ListSerializer 对象.create()
def create(self, validated_data):
return [
self.child.create(attrs) for attrs in validated_data
]
validated_data的数据:
[{'title': 'Python', 'price': '123.00',
'publish': <Publish: 北京出版社>, 'author': [<Author: 北京出版社>]},
{'title': 'Linux', 'price': '456.00',
'publish': <Publish: 上海出版社>, 'author': [<Author: 上海出版社>]}]
post请求: 127.0.0.1:8000/app01/api/books/
携带的json数据:
[{
"title": "Python",
"price": "123.00",
"publish": 1,
"author": [1]
},
{
"title": "Linux",
"price": "123.00",
"publish": 2,
"author": [2]
}]

8. 修改数据
* 1. 单条数据修改
def put(self, request, *args, **kwargs):
pk = kwargs.get('pk')
if pk:
book_obj = self.get_queryset().filter(pk=pk).first()
book_dic = self.get_serializer(instance=book_obj, data=request.data)
book_dic.is_valid(raise_exception=True)
book_dic.save()
return CustomResponse(data=book_dic.data)
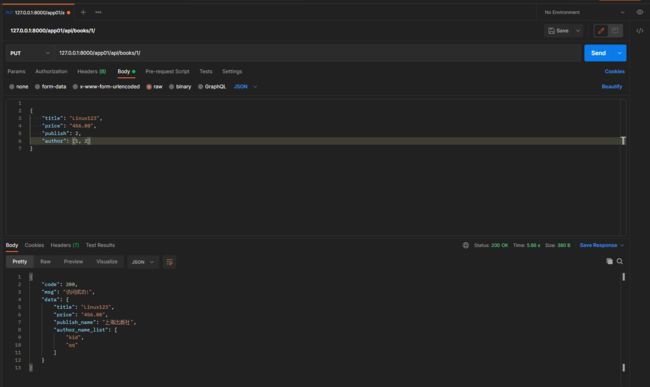
put请求: 127.0.0.1:8000/app01/api/books/1/
携带的json数据:
{
"title": "Linux123",
"price": "456.00",
"publish": 2,
"author": [1, 2]
}
* 2. 多条数据修改, 数据传入的格式是多条[{}, {}], 在使用序列化器之后many=True, 生成一个ListSerializer
对象. 改对象中作者只写了create方法, update没有写, 我们可以继承ListSerializer, 重新该方法.
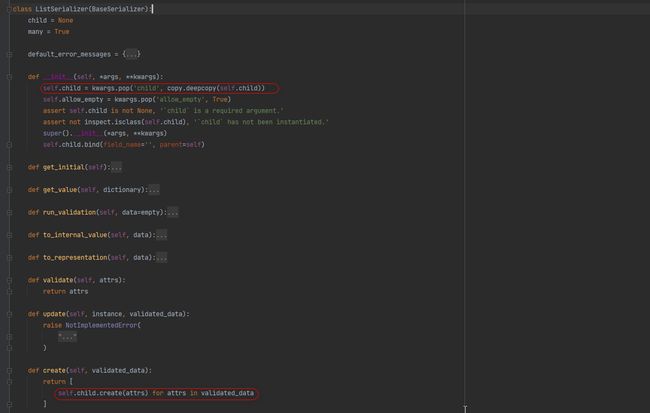
* 3. 继承ListSerializer重新update方法. 在自定义update方法中循环调用模型序列化类的update方法添加数据.
前端传递的数据需要携带主键.
from rest_framework import serializers
from app01 import models
class BookListSerializer(serializers.ListSerializer):
def update(self, instance, validate_value):
return [
self.child.update(instance[i], data) for i, data in enumerate(validate_value)
]
class BookModelSerializer(serializers.ModelSerializer):
class Meta:
list_serializer_class = BookListSerializer
model = models.Book
fields = ('title', 'price', 'publish', 'publish_name', 'author', 'author_name_list')
depth = 0
extra_kwargs = {
'publish': {'write_only': True},
'publish_name': {'read_only': True},
'author': {'write_only': True},
'author_name_list': {'read_only': True},
}
* 4. 批量修改代码
def put(self, request, *args, **kwargs):
pk = kwargs.get('pk')
if pk:
book_obj = self.get_queryset().filter(pk=pk).first()
book_dic = self.get_serializer(instance=book_obj, data=request.data)
else:
data_dict = []
obj_list = []
for items in request.data:
pk = items.pop('book_id')
book_obj = self.get_queryset().filter(pk=pk).first()
data_dict.append(items)
obj_list.append(book_obj)
book_dic = self.get_serializer(instance=obj_list, data=data_dict, many=True)
book_dic.is_valid(raise_exception=True)
"""
type(book_dic)
没有使用 many=True 序列化的是 模型序列化类.
调用轨迹 模型序列化类的父类的父类.save() 中self.update() self是 模型序列化类, 调用模型序列化类.update()方法
使用 many=True 序列化的是 ListSerializer类
调用轨迹 模型序列化类的父类的父类.save() 中self.update() self是 ListSerializer类, 调用ListSerializer类.update()方法
ListSerializer类.update()方法 中 在遍历调用 调用模型序列化类.update()方法, 自己控制好传入的值就好了...
"""
book_dic.save()
return CustomResponse(data=book_dic.data)
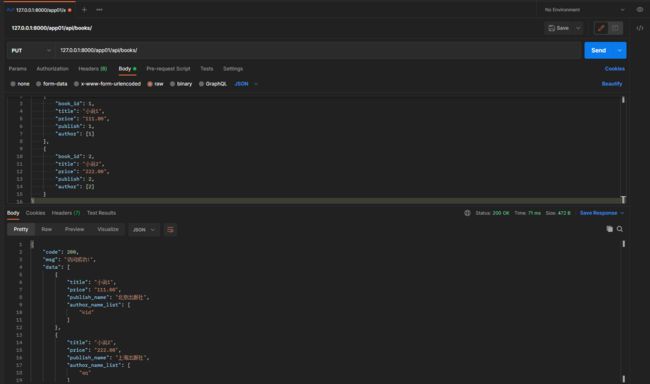
put请求: 127.0.0.1:8000/app01/api/books/
携带的json格式数据:
[
{
"book_id": 1,
"title": "小说1",
"price": "111.00",
"publish": 1,
"author": [1]
},
{
"book_id": 2,
"title": "小说2",
"price": "222.00",
"publish": 2,
"author": [2]
}
]
9. 删除数据
修改数据对象的is_delete字段, 不是真正的删除数据...
def delete(self, request, *args, **kwargs):
del_list = []
pk = kwargs.get('pk')
if pk:
del_list.append(pk)
else:
del_list = request.data.get('del_list')
num = self.get_queryset().filter(pk__in=del_list, is_delete=False).update(is_delete=True)
if num:
return CustomResponse(data=f'删除了{num}条数据')
return CustomResponse(data='没有删除数据, 删除的数据可能不存在, 或者已经被删除!')
* 1. 删除一条数据
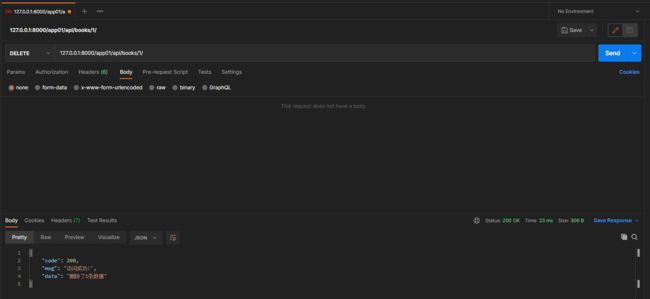
* 2. 批量删除数据
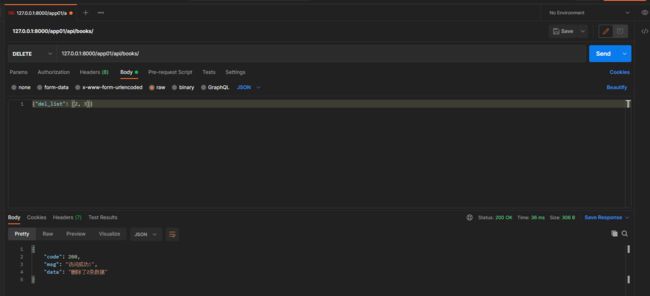
10. 局部修改
patch方法用来更新局部资源, 入数据有10个字段, 修改数据时自己只提供2个字段, 其他的字段信息都不提供.
put可以通通过修改一些参数来实现以上的功能, 就没必要在写patch请求方法了.
eg: 发送put请求, 序列化的字段就是必填的. 可以通过参数设置改字段不是必须填写的.
或者在使用模型序列化器时, 设置partial=True, 没有传递值的字段不是必填的.
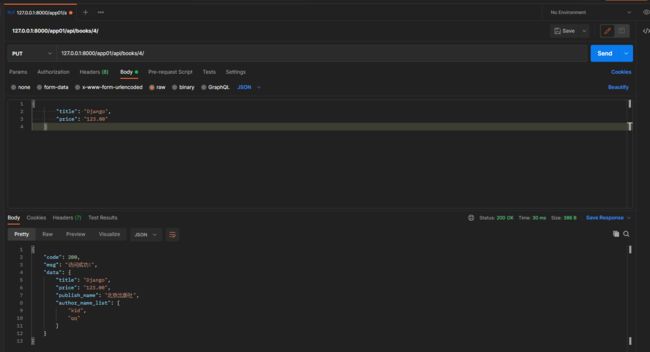
put请求: 127.0.0.1:8000/app01/api/books/4/
携带的json数据:
{
"title": "Django",
"price": "123.00"
}

book_dic = self.get_serializer(instance=book_obj, data=request.data, partial=True)
再次访问, 实现局部修改...
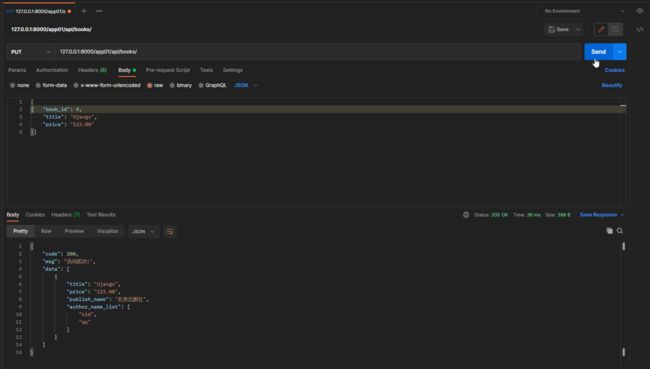
book_dic = self.get_serializer(instance=obj_list, data=data_dict, many=True, partial=True)
put请求: 127.0.0.1:8000/app01/api/books/
携带的json数据:
[
{ "book_id": 4,
"title": "Django",
"price": "123.00"
}]
11. 视图子类使用分页器
rest_framework 内置三种分页器
from rest_framework.pagination import PageNumberPagination, LimitOffsetPagination, CursorPagination
页码分页, 限制偏移分页, 光标分页
从视图子类开始不需要手定调用分类器的方法. 只需要配置好属性值即可使用.
在数据库中写入10条数据
post请求: 127.0.0.1:8000/app01/api/books/
携带的json数据:
[
{
"title": "小说1",
"price": "123.00",
"publish": 1,
"author": [
1
]
},
{
"title": "小说2",
"price": "123.00",
"publish": 1,
"author": [
1
]
},
{
"title": "小说3",
"price": "123.00",
"publish": 1,
"author": [
1
]
},
{
"title": "小说4",
"price": "123.00",
"publish": 1,
"author": [
1
]
},
{
"title": "小说5",
"price": "123.00",
"publish": 1,
"author": [
1
]
},
{
"title": "小说6",
"price": "123.00",
"publish": 1,
"author": [
1
]
},
{
"title": "小说7",
"price": "123.00",
"publish": 1,
"author": [
1
]
},
{
"title": "小说8",
"price": "123.00",
"publish": 1,
"author": [
1
]
},
{
"title": "小说9",
"price": "123.00",
"publish": 1,
"author": [
1
]
},
{
"title": "小说10",
"price": "123.00",
"publish": 1,
"author": [
1
]
}
]
11.1 页码分页
DEFAULT_PAGINATION_CLASS 的默认值为无, 默认使用PageNumberPagination页面分页.
1. 全局配置
在项目配置文件中设置.
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
'PAGE_SIZE': 2,
}

2. 局部配置
在需要设置页码的类中设置 pagination_class属性值.
from rest_framework.generics import ListAPIView
from rest_framework.pagination import PageNumberPagination
class BookListAPIView(ListAPIView):
queryset = models.Book.objects.all()
serializer_class = serializers.BookModelSerializer
pagination_class = PageNumberPagination
在项目配置文件中设置PAGE_SIZE属性.
REST_FRAMEWORK = {
'PAGE_SIZE': 2,
}
3. 重新页码分页
继承PageNumberPagination类, 在该类中定义配置数据. 可以局部使用, 也可以全局使用.
参数:
page_size 每页的数目
page_query_param 页数关键字名, 默认为'page'
page_size_query_param 每页数目关键字, 默认为None
max_page_size 每页最大的显示条数
url('^books2/', views.BookListAPIView.as_view()),
from rest_framework.generics import ListAPIView
from rest_framework.pagination import PageNumberPagination
class Pager(PageNumberPagination):
page_size = 2
page_query_param = 'aa'
page_size_query_param = 'size'
max_page_size = 5
class BookListAPIView(ListAPIView):
queryset = models.Book.objects.all()
serializer_class = serializers.BookModelSerializer
pagination_class = Pager
get请求: 127.0.0.1:8000/app01/api/books2/
每页的条数: page_size = 2
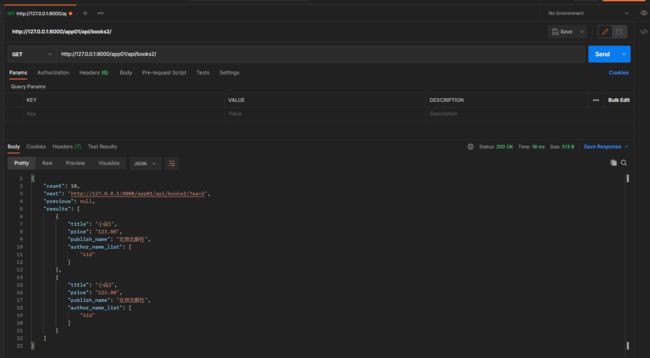
get请求: 127.0.0.1:8000/app01/api/books2/?size=3
每页的条数: size=3 ==> page_size = 3

get请求: 127.0.0.1:8000/app01/api/books2/?size=10
限制每页最大的显示条数: max_page_size = 5

11.2 偏移分页
继承LimitOffsetPagination类, 在该类中定义配置数据. 可以局部使用, 也可以全局使用.
参数:
default_limit 每页的偏移数, 偏移一位获取一条数据.
milit_query_pagam 指定每页偏移的关键字, 默认为limit.
offset_query_pagam 指定起始位的关键字, 默认为offset.
max_milit 最大偏移的位数
default_limit自己没有定义使用的配置文件的PAGE_SIZE.
from rest_framework.pagination import LimitOffsetPagination
class Offset(LimitOffsetPagination):
default_limit = 3
class BookListAPIView(ListAPIView):
queryset = models.Book.objects.all()
serializer_class = serializers.BookModelSerializer
pagination_class = Offset
max_limit = 5
第一页 127.0.0.1:8000/app01/api/books2/?limit=3
第二页 127.0.0.1:8000/app01/api/books2/?limit=3&offset=3 limit获取几条 offset 指定起始位
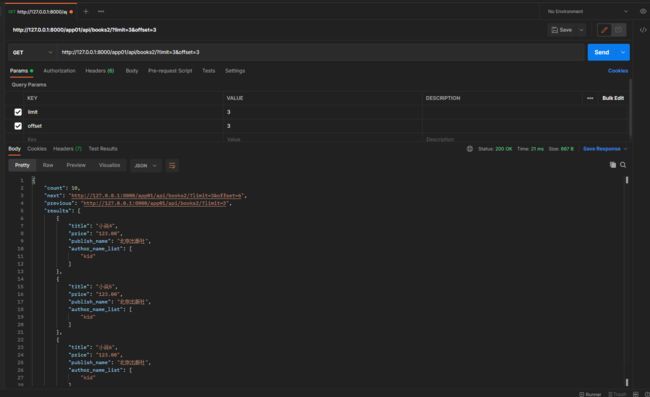
127.0.0.1:8000/app01/api/books2/?limit=3&offset=5
从第五条的后面开始向后面获取3条数据

127.0.0.1:8000/app01/api/books2/?limit=30&offset=1
limit=30
max_limit = 5 限制 limit最大的值为5

11.3 光标分页
前两种方法可以指定位置开始查, 查的时候需要将数据都读取,效率低. 光标分页只能点击上下翻页, 查询效率最高.
继承CursorPagination类, 在该类中定义配置数据. 可以局部使用, 也可以全局使用.
参数:
page_size: 每页展示的数目
cursor_query_param: 页码的关键字参数, 默认为 'cursor'
ordering: 排序中的字段, 默认 ordering = '-created', 以创建时间排序,
自己没有定义该属性会报错, 自己的表中没有改字段.
- 倒序, 在取值.
from rest_framework.pagination import CursorPagination
class Cursor(CursorPagination):
cursor_query_param = 'page'
page_size = 3
ordering = '-book_id'
class BookListAPIView(ListAPIView):
queryset = models.Book.objects.all()
serializer_class = serializers.BookModelSerializer
pagination_class = Cursor
get请求 127.0.0.1:8000/app01/api/books2/
ordering = '-book_id' 指定排序字段为book_id, -为倒序, 倒序之后取数据.
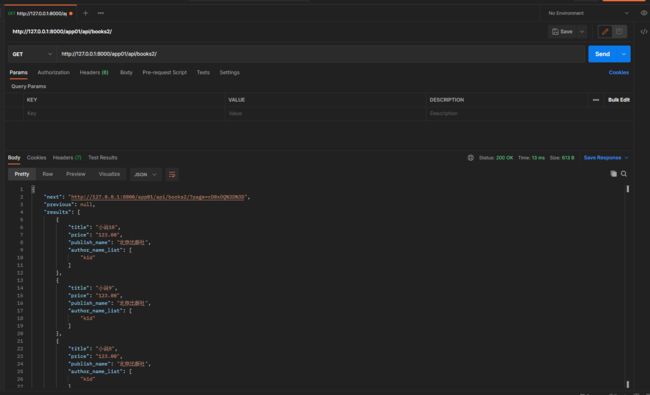
只能通过 next previous 翻页
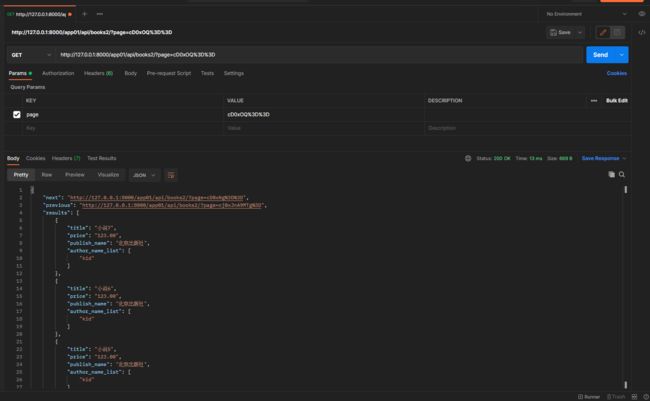
12. 视图基类使用分页器
从基础视图类需要手定调用分类器的方法. 使用方法按要求传递参数.
url('^books3/', views.BookAPIView.as_view()),
from rest_framework.pagination import PageNumberPagination
class Pager(PageNumberPagination):
page_size = 2
page_query_param = 'aa'
page_size_query_param = 'size'
max_page_size = 5
from rest_framework.views import APIView
class BookAPIView(APIView):
def get(self, request):
books_obj = models.Book.objects.all()
pager_obj = Pager()
books_obj_list = pager_obj.paginate_queryset(books_obj, request, self)
books_dic = serializers.BookModelSerializer(instance=books_obj_list, many=True)
next_link = pager_obj.get_next_link()
previous_link = pager_obj.get_previous_link()
page_link = {'next_link': next_link, 'previous_link': previous_link}
print(books_dic.data)
return CustomResponse(data=books_dic.data, page=page_link)
先对数据划分, 在对序列化数据. 上下页码通过自定义的Response组织放回.
get请求: 127.0.0.1:8000/app01/api/books3/?aa=2
