【云原生实战】学习笔记(二)k8s(Kubernetes)实战入门
《云原生实战》是尚硅谷与KubeSphere官方联合打造的云原生系列课程之一
课程链接:
云原生Java架构师的第一课K8s+Docker+KubeSphere+DevOps_哔哩哔哩_bilibili
学习资料:
k8s 官网: Kubernetes 文档 | Kubernetes
云原生实战 · 语雀 (yuque.com)
学习内容:
云平台核心
Docker基础
Kubernetes实战入门
KubeSphere平台安装
KubeSphere可视化平台
KubeSphere实战
云原生DevOps基础与实战
微服务基础与实战
1、k8s基础概念
1、k8s是什么
k8s(Kubernetes )是一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。 Kubernetes 拥有一个庞大且快速增长的生态系统。Kubernetes 的服务、支持和工具广泛可用。
2、时光回溯
部署:
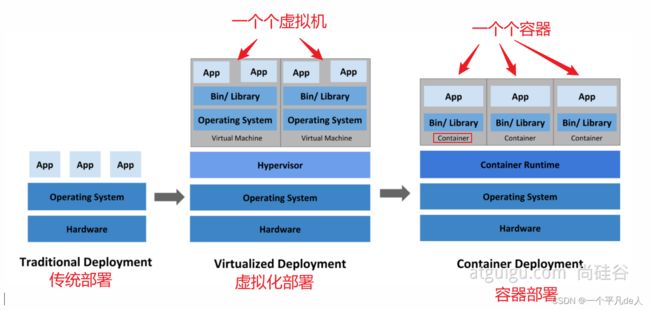
这么多容器这么管理呢?所以我们急需一个大规模容器编排(编组,排序,管理)系统,k8s可以解决。
为什么需要 Kubernetes,它能做什么?
容器是打包和运行应用程序的好方式。在生产环境中,你需要管理运行应用程序的容器,并确保不会停机。 例如,如果一个容器发生故障,则需要启动另一个容器。如果系统处理此行为,会不会更容易?
这就是 Kubernetes 来解决这些问题的方法! Kubernetes 为你提供了一个可弹性运行分布式系统的框架。 Kubernetes 会满足你的扩展要求、故障转移、部署模式等。Kubernetes 可以轻松管理系统的 Canary(金丝雀) 部署。
Kubernetes 为你提供:
-
服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址公开容器,如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。 -
存储编排
Kubernetes 允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。 -
自动部署和回滚
你可以使用 Kubernetes 描述已部署容器的所需状态,它可以以受控的速率将实际状态 更改为期望状态。例如,你可以自动化 Kubernetes 来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。 -
自动完成装箱计算
Kubernetes 允许你指定每个容器所需 CPU 和内存(RAM)。 当容器指定了资源请求时,Kubernetes 可以做出更好的决策来管理容器的资源。 -
自我修复
Kubernetes 重新启动失败的容器、替换容器、杀死不响应用户定义的 运行状况检查的容器,并且在准备好服务之前不将其通告给客户端。 -
密钥与配置管理
Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
工作方式
Kubernetes : N主节点+N工作节点; N>=1
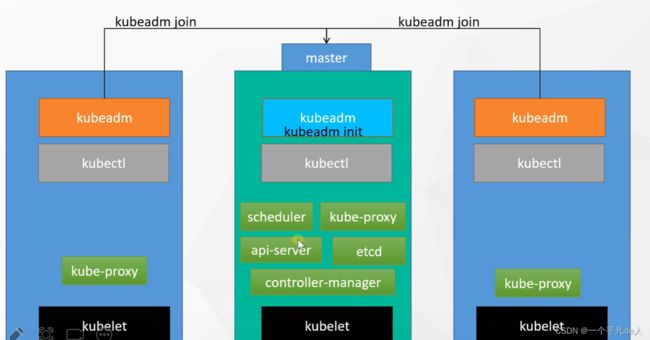
2、 组件架构
组件架构总图


2.1 控制平面的组件
控制平面(control Plane)
控制平面的组件对集群做出全局决策(比如调度),以及检测和响应集群事件(例如,当不满足部署的 replicas 字段时,启动新的 pod)。
控制平面组件可以在集群中的任何节点上运行。 然而,为了简单起见,设置脚本通常会在同一个计算机上启动所有控制平面组件, 并且不会在此计算机上运行用户容器。
控制平面的组件(api、etcd 、sched 、c-m、c-c-m)
-
api(kube-apiserver 、API 服务器)
API 服务器是 Kubernetes 控制面的组件, 该组件公开了 Kubernetes API。 API 服务器是 Kubernetes 控制面的前端。
Kubernetes API 服务器的主要实现是 kube-apiserver。 kube-apiserver 设计上考虑了水平伸缩,也就是说,它可通过部署多个实例进行伸缩。 你可以运行 kube-apiserver 的多个实例,并在这些实例之间平衡流量。
-
etcd (资料库)
etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。
您的 Kubernetes 集群的 etcd 数据库通常需要有个备份计划。要了解 etcd 更深层次的信息,请参考 etcd 文档。
-
sched (kube-schedulerv 、调度者)
负责监视新创建的、未指定运行节点(node)的 Pods,选择节点让 Pod 在上面运行。
调度决策考虑的因素包括单个 Pod 和 Pod 集合的资源需求、硬件/软件/策略约束、亲和性和反亲和性规范、数据位置、工作负载间的干扰和最后时限。
-
c-m (kube-controller-manager、决策者,控制器)
在主节点上运行 控制器 的组件。
从逻辑上讲,每个控制器都是一个单独的进程, 但是为了降低复杂性,它们都被编译到同一个可执行文件,并在一个进程中运行。
这些控制器包括:
- 节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应
- 任务控制器(Job controller): 监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
- 端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service 与 Pod)
- 服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌
-
c-c-m (cloud-controller-manager、外联部、云控制器管理器)
云控制器管理器是指嵌入特定云的控制逻辑的 控制平面组件。 云控制器管理器允许您链接集群到云提供商的应用编程接口中, 并把和该云平台交互的组件与只和您的集群交互的组件分离开。
c-c-m仅运行特定于云平台的控制回路。 如果你在自己的环境中运行 Kubernetes,或者在本地计算机中运行学习环境, 所部署的环境中不需要云控制器管理器。
与
kube-controller-manager类似, c-c-m将若干逻辑上独立的 控制回路组合到同一个可执行文件中,供你以同一进程的方式运行。 你可以对其执行水平扩容(运行不止一个副本)以提升性能或者增强容错能力。下面的控制器都包含对云平台驱动的依赖:
- 节点控制器(Node Controller): 用于在节点终止响应后检查云提供商以确定节点是否已被删除
- 路由控制器(Route Controller): 用于在底层云基础架构中设置路由
- 服务控制器(Service Controller): 用于创建、更新和删除云提供商负载均衡器
2.2 Node 组件
节点组件在每个节点上运行,维护运行的 Pod 并提供 Kubernetes 运行环境。一个节点(Node)看作一个厂区
-
kubelet(一个节点的领导(代理),厂长)
一个在集群中每个节点(node)上运行的代理。 它保证容器(containers)都 运行在 Pod 中。
kubelet 接收一组通过各类机制提供给它的 PodSpecs,确保这些 PodSpecs 中描述的容器处于运行状态且健康。 kubelet 不会管理不是由 Kubernetes 创建的容器。
-
kube-proxy (网络代理,一个厂区的门卫)
各个kube-proxy 互相同步信息,可互相查询。
kube-proxy 是集群中每个节点上运行的网络代理, 实现 Kubernetes 服务(Service) 概念的一部分。
kube-proxy 维护节点上的网络规则。这些网络规则允许从集群内部或外部的网络会话与 Pod 进行网络通信。
如果操作系统提供了数据包过滤层并可用的话,kube-proxy 会通过它来实现网络规则。否则, kube-proxy 仅转发流量本身
3、 kubeadm创建集群
请参照以前Docker安装。先提前为所有机器安装Docker
【狂神说】Docker 学习笔记【基础篇】_一个平凡de人的博客-CSDN博客
以下是在安装k8s的时候使用
$ yum install -y docker-ce-20.10.7 docker-ce-cli-20.10.7 containerd.io-1.4.6
虚拟机技巧:先搭建一台虚拟机安装公共环境(Docker 、k8s),再复制成其他两台虚拟机
集群环境图
3.1 安装kubeadm
前提条件
-
一台兼容的 Linux 主机。Kubernetes 项目为基于 Debian 和 Red Hat 的 Linux 发行版以及一些不提供包管理器的发行版提供通用的指令
-
每台机器 2 GB 或更多的 RAM (如果少于这个数字将会影响你应用的运行内存)
-
2 CPU 核或更多
-
集群中的所有机器的网络彼此均能相互连接(公网和内网都可以)
设置防火墙放行规则
-
节点之中不可以有重复的主机名、MAC 地址或 product_uuid。请参见这里了解更多详细信息。
设置不同hostname
-
开启机器上的某些端口。请参见这里 了解更多详细信息。
内网互信
-
禁用交换分区。为了保证 kubelet 正常工作,你 必须 禁用交换分区。
永久关闭
(本次使用的是虚拟机环境进行的实验)
基础环境
(所有机器执行操作)
1、各个机器设置自己的主机名
$ hostnamectl set-hostname mater
$ hostnamectl set-hostname node1
$ hostnamectl set-hostname node2
2、将 SELinux 设置为 permissive 模式(相当于将其禁用)
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
3、禁用交换分区Swap
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
4、允许 iptables 检查桥接流量
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
5、让以上的配置生效
sudo sysctl --system
安装 kubelet、kubeadm、kubectl
(所有机器执行操作)
kubectl 是供程序员使用的命令行,一般只安装在mater(总部)。
kubeadm 帮助程序员管理集群 (如设置主节点并创建主节点中的控制平面的组件)。
1、配置安装源
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
exclude=kubelet kubeadm kubectl
EOF
2、安装 kubelet、kubeadm、kubectl
sudo yum install -y kubelet-1.20.9 kubeadm-1.20.9 kubectl-1.20.9 --disableexcludes=kubernetes

3、启动 kubelet
sudo systemctl enable --now kubelet
4、查看kubelet 状态
systemctl status kubelet
kubelet 现在每隔几秒就会重启,因为它陷入了一个等待 kubeadm 指令的死循环(mater 厂长)
3.2 使用kubeadm引导集群
1、下载各个机器需要的镜像 (脚本循环pull(拉取))
sudo tee ./images.sh <<-'EOF'
#!/bin/bash
images=(
kube-apiserver:v1.20.9
kube-proxy:v1.20.9
kube-controller-manager:v1.20.9
kube-scheduler:v1.20.9
coredns:1.7.0
etcd:3.4.13-0
pause:3.2
)
for imageName in ${images[@]} ; do
docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/$imageName
done
EOF
2、执行下载
chmod +x ./images.sh && ./images.sh
3、查看下载的镜像
$ docekr images
(所有机器执行以上操作)
4、关闭并拷贝mater,新增node1、node2


主机ip 地址:mater (192.168.64.128)、node1(192.168.64.130)、node2(192.168.64.131)
5、所有机器添加master域名映射,以下ip需要修改为自己的
echo "192.168.64.128 cluster-endpoint" >> /etc/hosts
5、初始化主节点(仅操作mater),注意所有网络范围不重叠
kubeadm init \
--apiserver-advertise-address=192.168.64.128 \
--control-plane-endpoint=cluster-endpoint \
--image-repository registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images \
--kubernetes-version v1.20.9 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=172.31.0.0/16
--pod-network-cidr=172.31.0.0/16 非常重要,用于为pod分配ip地址
- 初始化主节点成功,同时给出一系列提示(接下来按提示操作)
# ...
# 【翻译】你的Kubernetes控制平面已经成功初始化
Your Kubernetes control-plane has initialized successfully!
# 【翻译】要开始使用集群,您需要作为普通用户运行以下操作
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 【翻译】或者,如果你是root用户,你可以运行:
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
# 【翻译】您现在应该向集群部署一个pod网络。
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
# 【翻译】现在,您可以通过复制证书颁发机构来加入任意数量的 控制平面节点(mater)和服务帐户密钥在每个节点上,然后以root身份运行以下命令:
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join cluster-endpoint:6443 --token f1jdd3.9z7z8niwd8cdz3p4 \
--discovery-token-ca-cert-hash sha256:fba337fd72305497e53064e1407872f4d9e8d39ed7a1f276bb4134e2d848ba9c \
--control-plane
# 然后,您(root)可以通过在每个工作节点上作为根节点运行以下命令来连接任意数量的工作节点(node)
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join cluster-endpoint:6443 --token f1jdd3.9z7z8niwd8cdz3p4 \
--discovery-token-ca-cert-hash sha256:fba337fd72305497e53064e1407872f4d9e8d39ed7a1f276bb4134e2d848ba9c
6、按照英文提示执行
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
7、查看集群所有节点
$ kubectl get nodes
[root@k8s-mater ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-mater NotReady control-plane,master 10m v1.20.9
根据提示继续
1、下载并安装网络组件
$ curl https://docs.projectcalico.org/manifests/calico.yaml -O
$ kubectl apply -f calico.yaml
2、修改 calico.yaml 配置,使网段同 --pod-network-cidr=172.31.0.0/16 一致,除非是192.168**就不用改
$ vim calico.yaml
?192.168 # vim工具搜索

3、常用命令
运行中的应用在docker里面叫容器,在k8s里面叫Pod
#查看集群所有节点
kubectl get nodes
#根据配置文件,给集群创建资源
kubectl apply -f xxxx.yaml
#查看集群部署了哪些应用?
docker ps
# 效果等于
kubectl get pods -A
4、查看mater状态,验证集群节点状态
[root@k8s-mater ~]# kubectl get pods -A
# RESTARTS:重新启动的次数
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-547686d897-k6zq4 1/1 Running 1 60m
kube-system calico-node-fbqx9 1/1 Running 1 60m
kube-system coredns-5897cd56c4-ntsv7 1/1 Running 1 81m
kube-system coredns-5897cd56c4-p9krt 1/1 Running 1 81m
kube-system etcd-k8s-mater 1/1 Running 1 81m
kube-system kube-apiserver-k8s-mater 1/1 Running 1 81m
kube-system kube-controller-manager-k8s-mater 1/1 Running 4 81m
kube-system kube-proxy-njvhf 1/1 Running 1 81m
kube-system kube-scheduler-k8s-mater 1/1 Running 4 81m
# 验证集群节点状态
[root@k8s-mater ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-mater Ready control-plane,master 81m v1.20.9
将node1、node2 进入工作节点
1、node1、node2执行(24小时有效)
kubeadm join cluster-endpoint:6443 --token f1jdd3.9z7z8niwd8cdz3p4 \
--discovery-token-ca-cert-hash sha256:fba337fd72305497e53064e1407872f4d9e8d39ed7a1f276bb4134e2d848ba9c
- 运行结果
# ...
# 【翻译】此节点已加入集群:
# 日志含义向apiserver发送证书签名请求并收到响应。
# * Kubelet被告知新的安全连接细节。
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
# 【翻译】在控制平面上运行'kubectl get nodes'查看该节点加入集群。
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
2、验证集群节点状态
$ kubectl get nodes
[root@k8s-mater ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-mater Ready control-plane,master 90m v1.20.9
node1 Ready <none> 2m47s v1.20.9
node2 Ready <none> 2m38s v1.20.9
k8s-集群自我修复能力测试
任意服务器挂了,重启后依旧可以用,高可用。
令牌过期怎么办
创建新令牌,再将node1、node2 进入工作节点
$ kubeadm token create --print-join-command
3.3 部署dashboard可视化界面
(mater上操作)
k8s-安装dashboard_kxq的博客-CSDN博客_k8s 安装dashboard
1、安装dashboard
dashboard是kubernetes官方提供的可视化界面 https://github.com/kubernetes/dashboard
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.3.1/aio/deploy/recommended.yaml
- 提示找不到地址
所以直接在github上找配置文件:https://github.com/kubernetes/dashboard/blob/master/aio/deploy/recommended.yaml
然后将recommended.yaml文件内容粘贴复制到本地
或者:K8S的配置文件/recommended.yaml · 一个平凡de人/存储文件 - 码云 - 开源中国 (gitee.com)
2、重新安装dashboard(根据配置文件,给集群创建资源)
$ kubectl apply -f recommended.yaml
3、查看任务是否完成
$ kubectl get pods -A
4、设置访问端口
$ kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard
提示: 进入文件将type: ClusterIP改为type: NodePort
- 找到端口30455(每个人的端口可能不同),端口是访问云操作台的,在安全组放行
kubectl get svc -A | grep kubernetes-dashboard
[root@k8s-mater Downloads]# kubectl get svc -A | grep kubernetes-dashboardkubernetes-dashboard dashboard-metrics-scraper ClusterIP 10.96.116.209 8000/TCP 22m
kubernetes-dashboard kubernetes-dashboard NodePort 10.96.78.49 <none> 443:30455/TCP 22m
5、访问: https://集群任意机器IP:端口 即可
windows上访问 https://192.168.64.130:30455

6、创建访问账号
- 准备一个yaml文件;
vim dash.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
- 应用 dash.yaml文件
$ kubectl apply -f dash.yaml
7、获取访问令牌
kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}"
eyJhbGciOiJSUzI1NiIsImtpZCI6ImJUQ01WMWRFSENKSmhTUVJuRThoMDZ2U0dZMEZqMEltQmJpX2JXdEtpRGMifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLTd4YjQ0Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiIzY2I2ZThhYi05NjY5LTQ0YjAtOGM3Ni03ZDBiOWM0NGUxNWQiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.MPICtJCDj53hrneIBrKkdztdrM_xYv9LTneC1tyM6SvR6X76iguKQKM3ak7brYSG_pntVUDsVMGipG-GXHb4LbQnX8qsPBqn8TULnrylpKUr1UcL9u9NpVUsf5_Cb5pcSKOHjnp4yGiFTsklnP0p0-a6YNjrKx4vVxbUgE03j_ZTLgAYcHaV6l2q8CtsUAbKEA1eECA5CZsrN3xVwD3b_gmlmt1YqphLnj2PFZfKx41wFEHC66chenZstcOdqeSAQmkvShyuzp3W9fiFmQk7DPAGYKKBloQhGLwl338i5jg3HunX-_EsxqgzpnqKbspjdwM3Qtz-4I6XFOn3SIC6bg
8、使用令牌访问
4、Kubernetes核心资源
资源创建方式
- 命令行
- YAML
Kubernetes核心资源
4.1 Namespace(名称空间)
Namespace(名称空间、命名空间)是用来对集群资源进行隔离划分。默认只隔离资源,不隔离网络

1、可视化界面查看命名空间

2、命令行查看命名空间
$ kubectl get namespace
# 或
$ kubectl get ns
[root@k8s-mater ~]# kubectl get namespace
NAME STATUS AGE
default Active 11h
kube-node-lease Active 11h
kube-public Active 11h
kube-system Active 11h
kubernetes-dashboard Active 9h
3、查看所有名称空间的pods信息
$ kubectl get pods -A
- 查看指定名称空间的pods信息
$ kubectl get pods -n kubernetes-dashboard
4、创建名称空间(使用命令行)
$ kubectl create ns hello
5、删除名称空间(使用yaml文件),连带名称空间下的资源一起删除
$ kubectl delete ns hello
6、创建名称空间(使用yaml文件)
- createns.yaml
apiVersion: v1 # 版本
kind: Namespace # 类型
metadata:
name: hello
- 应用yaml文件
$ kubectl apply -f createns.yaml
7、删除名称空间(使用yaml文件)
$ kubectl delete -f createns.yaml
4.2 Pod
4.2.1 Pod基础
k8s将容器先封装成Pod,再对pod进行操作,Pod是kubernetes中应用的最小单位。

Pod运行中的一组容器,一个pod里面可以运行单个容器或多个容器,建议是单个容器。

1、运行Pod
$ kubectl run 【Pod名称】 --image=【镜像名称】
[root@k8s-mater ~]$ kubectl run mynginx --image=nginx
pod/mynginx created
2、查看default名称空间的Pod
[root@k8s-mater ~]$ kubectl get pod
NAME READY STATUS RESTARTS AGE
mynginx 1/1 Running 0 2m23s
3、查看pod详细描述
$ kubectl describe pod 【Pod名称】
[root@k8s-mater ~]$ kubectl describe pod mynginx
Name: mynginx
Namespace: default # 所在名称空间
Priority: 0
Node: node2/192.168.64.131 # 运行节点为node2
Start Time: Fri, 11 Feb 2022 20:47:48 -0500
Labels: run=mynginx
Annotations: cni.projectcalico.org/containerID: 1385a3cd6d332c41ce6d538001af9044c091d76e54870cb1d13e5f69cb84ce80
cni.projectcalico.org/podIP: 172.31.104.4/32
cni.projectcalico.org/podIPs: 172.31.104.4/32
Status: Running
IP: 172.31.104.4 # ip地址[每个Pod - k8s都会分配一个ip]
IPs:
IP: 172.31.104.4
# ...
-
运行节点为node2,node2上执行
docker ps | grep mynginx和docker images | grep nginx发现只有node2有信息,只有node2下载了nginx的镜像
4、查看pod的ip
(集群中的任意一个机器以及任意的应用都能通过Pod分配的ip来访问这个Pod)(此时的pod还不被外部访问)
$ kubectl get pod -owide
[root@k8s-mater ~]$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mynginx 1/1 Running 0 7m27s 172.31.104.4 node2 <none> <none>
- 访问容器id,返回nginx的欢迎页
[root@k8s-mater ~]$ curl 172.31.104.4
# ...
<h1>Welcome to nginx!</h1>
# ...
5、 删除
$ kubectl delete pod 【Pod名称】
[root@k8s-mater ~]$ kubectl delete pod mynginx
pod "mynginx" deleted
6、查看Pod的运行日志
$ kubectl logs【Pod名称】
7、使用yaml文件(配置文件方式)创建pod
- creatpod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: mynginx
name: mynginx
namespace: default # 设置命名空间 (可视化操作时设置命名空间 或 切换的特定命名空间再创建)
spec:
containers:
- image: nginx
name: mynginx
- 应用yaml文件,创建pod
$ kubectl apply -f creatpod.yaml
- 应用yaml文件,删除pod
$ kubectl delete -f creatpod.yaml
8、进入pod(类似docker 进入容器)
$ kubectl exec -it mynginx -- /bin/bash
[root@k8s-mater Downloads]# kubectl exec -it mynginx -- /bin/bash
root@mynginx:/# ls
bin dev docker-entrypoint.sh home lib64 mnt proc run srv tmp var
boot docker-entrypoint.d etc lib media opt root sbin sys usr
root@mynginx:/# cd /usr/share/nginx/html
root@mynginx:/usr/share/nginx/html# ls
50x.html index.html
root@mynginx:/usr/share/nginx/html# echo "Hello k8s" > index.html
root@mynginx:/usr/share/nginx/html# exit
exit
[root@k8s-mater Downloads]# curl 172.31.104.6
Hello k8s
9、监控pod数量保护
每1秒自动执行一次kubectl get pod
$ watch -n 1 kubectl get pod
4.2.2 可视化操作与Pod细节
1、创建pod

namespace: default(yaml文件设置命名空间 可视化操作时设置命名空间 或 切换的特定命名空间再创建)


- 创建成功 (点击 mynginx 链接查看pod详情)

- 删除

2、进入pod

4.2.3 单个pod部署多个容器
1、creatpods.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: myapp
name: myapp
spec:
containers:
- image: nginx # 容器1
name: nginx
- image: tomcat:8.5.68 # 容器2
name: tomcat
2、应用
$ kubectl apply -f creatpods.yaml
3、查看创建
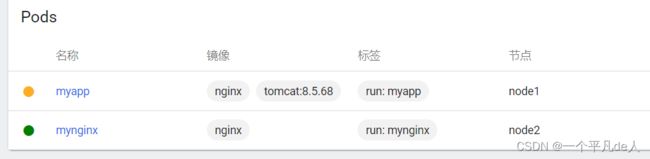
[root@k8s-mater Downloads]# kubectl get pod
NAME READY STATUS RESTARTS AGE
myapp 0/2 ContainerCreating 0 14s
mynginx 1/1 Running 0 56m
查看详细信息中,事件是实时滚动更新的
4、访问测试,nginx和tomcat共享存储空间
$ curl 172.31.166.132 # 返回nginx的欢迎信息
$ curl 172.31.166.132:8080 # 返回tomcat的欢迎信息
5、一个pod创建两个nginx容器的错误
- creatpods2.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: myapp2
name: myapp2
spec:
containers:
- image: nginx
name: nginx01
- image: nginx
name: nginx02
错误,因为nginx01占用了80端口,导致nginx02创建失败。
6、删除多个pod
$ kubectl delete myapp mynginx -n default
4.3 Deployment(部署)
(Deployment缩写:deploy)
Deployment 可以控制Pod,使Pod拥有多副本,自愈,扩缩容等能力
4.3.1 使Pod拥有自愈能力
1、普通新建pod(pod没有自愈能力)
$ kubectl run mynginx01 --image=nginx
- 一定所在node服务器崩溃或删除就没了
[root@k8s-mater Downloads]# kubectl run mynginx01 --image=nginx
pod/mynginx01 created
[root@k8s-mater Downloads]# kubectl get pods
NAME READY STATUS RESTARTS AGE
mynginx01 0/1 ContainerCreating 0 12s
[root@k8s-mater Downloads]# kubectl delete pods mynginx01
pod "mynginx01" deleted
[root@k8s-mater Downloads]# kubectl get pods
No resources found in default namespace.
2、Deployment 新建pod(pod拥有自愈能力)
$ kubectl create deployment mynginx02 --image=nginx
[root@k8s-mater Downloads]# kubectl create deployment mynginx02 --image=nginx
deployment.apps/mynginx02 created
[root@k8s-mater Downloads]# kubectl get pods
NAME READY STATUS RESTARTS AGE
mynginx02-587cfb5b64-frmq9 0/1 ContainerCreating 0 6s
[root@k8s-mater Downloads]# kubectl delete pods mynginx02-587cfb5b64-frmq9
pod "mynginx02-587cfb5b64-frmq9" deleted
[root@k8s-mater Downloads]# kubectl get pods
NAME READY STATUS RESTARTS AGE
mynginx02-587cfb5b64-w48z6 0/1 ContainerCreating 0 11s
没被删除,换个名字又卷土重来,使Pod拥有自愈能力。
3、删除拥有自愈能力的pod,方法是删除Deployment 部署
[root@k8s-mater Downloads]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
mynginx02 1/1 1 1 18m
[root@k8s-mater Downloads]# kubectl delete deployment mynginx02
deployment.apps "mynginx02" deleted
[root@k8s-mater Downloads]# kubectl get pods
No resources found in default namespace. # 删除成功
4.3.2 Deployment部署多副本
1、命令行方式创建Pod多副本,部署3份
$ kubectl create deployment my-dep --image=nginx --replicas=3
[root@k8s-mater ~]# kubectl create deployment my-dep --image=nginx --replicas=3
deployment.apps/my-dep created
[root@k8s-mater ~]# kubectl get deployment
# 名称 可用/总数 正在更新 可用的pod数量
NAME READY UP-TO-DATE AVAILABLE AGE
my-dep 2/3 3 2 32s
[root@k8s-mater ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
my-dep-5b7868d854-4b2rb 1/1 Running 0 38s
my-dep-5b7868d854-ffr7k 1/1 Running 0 38s
my-dep-5b7868d854-v4w7j 1/1 Running 0 38s

2、可视化创建Pod多副本

node2部署了3份pods,node1部署了2份pods,如果node1崩了,node1部署了2份pods会重新在其他正常运行的node工作节点上部署
[root@k8s-mater ~]# kubectl get pods -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-dep-01-686cfb7bf-55p99 1/1 Running 0 38s 172.31.104.13 node2 <none> <none>
my-dep-01-686cfb7bf-7qfvm 1/1 Running 0 38s 172.31.166.140 node1 <none> <none>
my-dep-01-686cfb7bf-qvbz8 1/1 Running 0 38s 172.31.166.139 node1 <none> <none>
my-dep-01-686cfb7bf-vdkw5 1/1 Running 0 38s 172.31.104.12 node2 <none> <none>
my-dep-01-686cfb7bf-zbc6c 1/1 Running 0 38s 172.31.104.14 node2 <none> <none>
3、配置文件方式创建Pod多副本
deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: my-dep-02
name: my-dep-02
spec:
replicas: 3
selector:
matchLabels:
app: my-dep-02
template:
metadata:
labels:
app: my-dep-02
spec:
containers:
- image: nginx
name: nginx
4.3.3 扩缩容
扩容:如 原本只有node1和node2部署了mynginx(pod) ,扩容让node3和node4也部署了mynginx;
缩容:如 原本只有node1和node2、node3、node4 部署了mynginx(pod) ,缩容让node3和node4不再部署mynginx。
动态扩缩容:让k8s自己判断什么时候进行扩缩容
方式一
1、扩容到5份
$ kubectl scale --replicas=5 deployment/my-dep-02
2、缩容到2份
$ kubectl scale --replicas=5 deployment/my-dep-02
命令相同,实则为调整pods数量。
方式二
编辑Deployment 配置文件,修改文件 replicas字段并保存
$ kubectl edit deployment my-dep-02


方式三
可视化操作扩缩容


4.4.4 自愈&故障转移
自愈 如 node1的 pods故障了,重启pods使其正常运行
故障转移 如: node1的 pods故障了,在其他node重新新建一份pods
自愈测试
1、监控pods
$ watch -n 1 kubectl get pods -o wide
Every 1.0s: kubectl get pods -o wide Sat Feb 12 05:06:27 2022
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-dep-02-7b9d6bb69c-6fvz7 1/1 Running 0 74m 172.31.166.144 node1 <none> <none>
my-dep-02-7b9d6bb69c-dhjgr 1/1 Running 0 94m 172.31.104.16 node2 <none> <none>
my-dep-02-7b9d6bb69c-hzs8f 1/1 Running 0 107m 172.31.104.15 node2 <none> <none>
2、在node1中查看pods 对应的容器并暂停容器模拟故障
[root@node1 ~]# docker ps | grep my-dep-02-7b9d6bb69c-6fvz7
1a0f48f741dd nginx "/docker-entrypoint.…" About an hour ago Up About an hour k8s_nginx_my-dep-02-7b9d6bb69c-6fvz7_default_ae7938d7-cadc-439e-8d55-d25bde42431f_0
784bd86ee511 registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/pause:3.2 "/pause" About an hour ago Up About an hour k8s_POD_my-dep-02-7b9d6bb69c-6fvz7_default_ae7938d7-cadc-439e-8d55-d25bde42431f_0
[root@node1 ~]# docker stop 1a0f48f741dd
3、查看监控

4、但几秒后又恢复如初,并显示重启了一次

故障转移测试
1、直接关闭node1机器

2、n分钟后(排除是因为网络故障而导致的失联),发现pods在node2机器中重新建立
3、监控打印pods状态变化过程
$ kubectl get pods -w
[root@k8s-mater ~]# kubectl get pods -w
NAME READY STATUS RESTARTS AGE
my-dep-02-7b9d6bb69c-6fvz7 1/1 Running 1 82m
my-dep-02-7b9d6bb69c-dhjgr 1/1 Running 0 102m
my-dep-02-7b9d6bb69c-hzs8f 1/1 Running 0 115m
my-dep-02-7b9d6bb69c-6fvz7 1/1 Terminating 1 86m
4.3.5 滚动更新
将一个pod集群在正常提供服务时从V1版本升级成 V2版本

1、更新my-dep02的pod的镜像版本,--record表示记录更新,
$ kubectl set image deployment/my-dep-02 nginx=nginx:1.16.1 --record
[root@k8s-mater ~]# kubectl set image deployment/my-dep-02 nginx=nginx:1.16.1 --record
deployment.apps/my-dep-02 image updated
过程是不断启动新的pod,然后去除旧的
$ kubectl rollout status deployment/my-dep-02
2、通过修改deployment配置文件实现更新
$ kubectl edit deployment/my-dep-02
4.3.6 版本回退
1、查看历史记录
$ kubectl rollout history deployment/my-dep-02
[root@k8s-mater ~]# kubectl rollout history deployment/my-dep-02
deployment.apps/my-dep-02
REVISION CHANGE-CAUSE
1 <none>
2 <none>
3 kubectl set image deployment/my-dep-02 nginx=nginx:1.16.1 --record=true
2、查看某个历史详情
$ kubectl rollout history deployment/my-dep-02 --revision=3
3、回滚到上次的版本
$ kubectl rollout undo deployment/my-dep-02
4、回滚到指定版本
$ kubectl rollout undo deployment/my-dep-02 --to-revision=1
[root@k8s-mater ~]# kubectl rollout undo deployment/my-dep-02 --to-revision=1
deployment.apps/my-dep-02 rolled back
5、查看deployment的配置文件来确定当前nginx的镜像版本
[root@k8s-mater ~]# kubectl get deployment/my-dep-02 -o yaml | grep image
f:imagePullPolicy: {}
f:image: {}
- image: nginx
imagePullPolicy: Always
4.3.7 Deployment等其他工作负载

工作中使用工作负载操作pod,使pod具有更强大的功能。
除了Deployment,k8s还有 StatefulSet 、DaemonSet 、Job 等 类型资源。我们都称为 工作负载。
有状态应用使用 StatefulSet 部署,无状态应用使用 Deployment 部署
官方文档:工作负载资源 | Kubernetes

有状态应用部署:如redis中的数据不能丢失,所以要采用有状态应用部署
5、服务网络
5.1 Service(服务)
(Service 缩写:svc)
以上内容的pod中的容器我们在外网都无法访问,使用Service来解决(–type=NodePort)。
Service是 将一组 Pods 公开为网络服务的抽象方法。

pod的服务发现和负载均衡
负载均衡:请求分摊到多个 操作单元上(pod)进行执行;
服务发现:服务发现是指使用一个注册中心来记录分布式系统中的全部服务的信息,以便其他服务能够快速的找到这些已注册的服务。
服务发现示列:如果其中一个pod崩了Service也能及时发现,不将请求转发到该pod上,但pod恢复后,请求又可以转发到该pod。
1、修改3个pod中nginx容器的欢迎页
cd /usr/share/nginx/html;echo "nginx-01" > index.html
cd /usr/share/nginx/html;echo "nginx-02" > index.html
cd /usr/share/nginx/html;echo "nginx-03" > index.html
cat index.html
2、测试
[root@k8s-mater ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-dep-02-7b9d6bb69c-7cw2q 1/1 Running 0 108m 172.31.166.150 node1 <none> <none>
my-dep-02-7b9d6bb69c-qgqrh 1/1 Running 0 109m 172.31.166.149 node1 <none> <none>
my-dep-02-7b9d6bb69c-wjwkt 1/1 Running 0 108m 172.31.166.151 node1 <none> <none>
[root@k8s-mater ~]# curl 172.31.166.150
nginx-02
[root@k8s-mater ~]# curl 172.31.166.149
nginx-03
[root@k8s-mater ~]# curl 172.31.166.151
nginx-01
3、暴露deployment的服务和端口,进行端口映射,创建出具有ip地址的Service (pod的集群)
$ kubectl expose deployment my-dep-02 --port=8000 --target-port=80
- 查看集群ip(集群ip的网段范围在 初始化主节点时的
--service-cidr=10.96.0.0/16配置了)
[root@k8s-mater ~]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 26h
my-dep-02 ClusterIP 10.96.171.182 <none> 8000/TCP 5m59s

- 访问集群访问(负载均衡,分摊请求的压力),k8s集群内都可访问(包括启动pod内部),但外网不行。
[root@k8s-mater ~]# curl 10.96.171.182:8000
nginx-02
[root@k8s-mater ~]# curl 10.96.171.182:8000
nginx-01
[root@k8s-mater ~]# curl 10.96.171.182:8000
nginx-03
4、查看pod的标签
$ kubectl get pod --show-labels
[root@k8s-mater ~]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
my-dep-02-7b9d6bb69c-7cw2q 1/1 Running 0 126m app=my-dep-02,pod-template-hash=7b9d6bb69c
my-dep-02-7b9d6bb69c-qgqrh 1/1 Running 0 126m app=my-dep-02,pod-template-hash=7b9d6bb69c
my-dep-02-7b9d6bb69c-wjwkt 1/1 Running 0 126m app=my-dep-02,pod-template-hash=7b9d6bb69c
- 使用标签检索Pod
$ kubectl get pod -l app=my-dep-02
[root@k8s-mater ~]# kubectl get pod -l app=my-dep-02
NAME READY STATUS RESTARTS AGE
my-dep-02-7b9d6bb69c-7cw2q 1/1 Running 0 112m
my-dep-02-7b9d6bb69c-qgqrh 1/1 Running 0 113m
my-dep-02-7b9d6bb69c-wjwkt 1/1 Running 0 112m
5、查看service/my-dep-02 的yaml配置文件
$ kubectl get service/my-dep-02 -o yaml
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2022-02-12T12:55:38Z"
labels:
app: my-dep-02
# ...
spec:
clusterIP: 10.96.171.182
clusterIPs:
- 10.96.171.182
ports:
- port: 8000
protocol: TCP
targetPort: 80
selector:
app: my-dep-02
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
6、在pod内部域名访问Service集群
域名构成规则: 服务名.名称空间.svc
如:my-dep-02.default.svc
- 新建pod进行测试
root@my-tomcat-5987455b6b-npkr6:/usr/local/tomcat# curl my-dep-02.default.svc:8000
nginx-03
root@my-tomcat-5987455b6b-npkr6:/usr/local/tomcat# curl my-dep-02.default.svc:8000
nginx-02
root@my-tomcat-5987455b6b-npkr6:/usr/local/tomcat# curl my-dep-02.default.svc:8000
nginx-03
root@my-tomcat-5987455b6b-npkr6:/usr/local/tomcat# curl my-dep-02.default.svc:8000
nginx-01
这里测试 curl my-dep-02:8000也可以(因为默认default,不加也行,要是别的空间,就必须跟上了)
root@my-tomcat-5987455b6b-npkr6:/usr/local/tomcat# curl my-dep-02:8000
nginx-03
root@my-tomcat-5987455b6b-npkr6:/usr/local/tomcat# curl my-dep-02:8000
nginx-02
root@my-tomcat-5987455b6b-npkr6:/usr/local/tomcat# curl my-dep-02:8000
nginx-02
7、删除Service
$ kubectl delete my-dep-02
ClusterIP
ClusterIP:集群ip,集群内访问
1、默认就是ClusterIP 等同于没有–type的
$ kubectl expose deployment my-dep-02 --port=8000 --target-port=80 --type=ClusterIP
NodePort
集群外可以访问
$ kubectl expose deployment my-dep-02 --port=8000 --target-port=80 --type=NodePort
1、查看服务
[root@k8s-mater ~]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 38h
my-dep-02 NodePort 10.96.241.166 <none> 8000:30670/TCP 57m
每个部署pod的机器都会开30670端口(NodePort范围在 30000-32767 之间)
2、集群内访问
[root@k8s-mater ~]# curl 10.96.241.166:8000
nginx-02
[root@k8s-mater ~]# curl 10.96.241.166:8000
nginx-01
[root@k8s-mater ~]# curl 10.96.241.166:8000
nginx-01
[root@k8s-mater ~]# curl 10.96.241.166:8000
nginx-03
3、集群外访问
ip+port映射: 集群外(mater、node1、node2的ip):30670 映射到 10.96.241.166:8000
如外网访问 http://192.168.64.128:30670/

5.2 Ingress(网关)
官网地址:https://kubernetes.github.io/ingress-nginx/
5.2.1 安装Ingress
Ingress:Service的统一网关入口(如百度的统一域名访问,统一Service层),Ingress是k8s机器集群的统一入口,请求流量先经过Ingress(入口)再进入集群内接受服务。
service是为一组pod服务提供一个统一集群内访问入口或外部访问的随机端口,而ingress做得是通过反射的形式对服务进行分发到对应的service上。
service一般是针对内部的,集群内部调用,而ingress应该是针对外部调用的
service只是开了端口,可以通过服务器IP:端口的方式去访问,但是服务器IP还是可变的,Ingress应该就是作为网关去转发
因为有很多服务,入口不统一,不方便管理
ingress rule相当于定义了路由规则,通过ingress controlle动态将各路由规则写到第三方的load balancer(比如nginx)
具体有第三方的load balancer做路由转发到对应的pods,ingress主要是实现动态将路由规则写到第三方的load balancer

安装Ingress
1、下载Ingress
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.47.0/deploy/static/provider/baremetal/deploy.yaml
2、修改配置文件中的镜像
vim deploy.yaml
#将image的值改为如下值:
registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/ingress-nginx-controller:v0.46.0
3、检查安装的结果
$ kubectl get pod,svc -n ingress-nginx
最后别忘记把svc暴露的端口要放行
4、如果下载不到,用以下文件
K8S的配置文件/deploy.yaml · 一个平凡de人/存储文件 - 码云 - 开源中国 (gitee.com)
5、应用 deploy.yaml
$ kubectl apply -f deploy.yaml
6、查看安装
[root@k8s-mater Downloads]# kubectl get pod -A | grep ingress
ingress-nginx ingress-nginx-admission-create-nnx47 0/1 Completed 0 68s
ingress-nginx ingress-nginx-admission-patch-r9xxb 0/1 Completed 0 68s
ingress-nginx ingress-nginx-controller-65bf56f7fc-njsmd 0/1 ContainerCreating 0 68s
新建了Service,以NodePort方式暴露了端口
[root@k8s-mater ~]# kubectl get service -A | grep ingress
ingress-nginx ingress-nginx-controller NodePort 10.96.105.233 <none> 80:30813/TCP,443:31761/TCP 27m
ingress-nginx ingress-nginx-controller-admission ClusterIP 10.96.129.25 <none> 443/TCP 27m
7、访问 服务器ip:30813 和 服务器ip:31761
映射:80:30813/TCP,443:31761/TCP
所有的服务器都开发了30813和31761的端口
- 端口30813 用于处理http请 (http的TCP端口是80)

端口31761用于处理https请求(https的TCP端口是443)

5.2.2 部署测试环境
Ingress就是用nginx作的

-
Ingresstest.yaml
K8S的配置文件/Ingresstest.yaml · 一个平凡de人/存储文件 - Gitee.com
-
应用配置文件,部署了2个Deployment,2个Service
$ kubectl apply -f Ingresstest.yaml
- 查看Swevice
[root@k8s-mater Downloads]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello-server ClusterIP 10.96.61.143 <none> 8000/TCP 2m48s
nginx-demo ClusterIP 10.96.252.133 <none> 8000/TCP 2m48s
# ...
[root@k8s-mater Downloads]# curl 10.96.61.143:8000
Hello World!
[root@k8s-mater Downloads]# curl 10.96.252.133
# ...
<h1>Welcome to nginx!</h1>
# ...
- 查看deployment
[root@k8s-mater Downloads]# kubectl get deployment -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
hello-server 2/2 2 2 3m47s hello-server registry.cn*** app=hello-server
nginx-demo 2/2 2 2 3m47s nginx nginx app=nginx-demo
- 查看pod
[root@k8s-mater Downloads]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
hello-server-6cbb679d85-pf7jx 1/1 Running 0 13m 172.31.166.158 node1 <none> <none>
hello-server-6cbb679d85-z7b65 1/1 Running 0 13m 172.31.166.159 node1 <none> <none>
nginx-demo-7d56b74b84-2xjh4 1/1 Running 0 13m 172.31.166.160 node1 <none> <none>
nginx-demo-7d56b74b84-hskdx 1/1 Running 0 13m 172.31.104.24 node2 <none> <none>
5.2.3 域名访问
1、目标
- 访问 hello.test.com 的请求由 hello-server (Service)集群处理
- 访问 demo.test.com 的请求由 nginx-demo (Service)集群处理
- Ingress(网关)根据请求的域名分配对应的Service去处理
2、配置文件:ingresscom.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress # 类型
metadata:
name: ingress-host-bar
spec:
ingressClassName: nginx
rules:
- host: "hello.test.com" #域名
http:
paths:
- pathType: Prefix # 前缀
path: "/"
backend:
service:
name: hello-server # Service 名称
port:
number: 8000 # 端口
- host: "demo.test.com"
http:
paths:
- pathType: Prefix
path: "/nginx" # 把请求会转给下面的service,下面的service一定要能处理这个路径,不能处理就是404
backend:
service:
name: nginx-demo # java,比如使用路径重写,去掉前缀nginx
port:
number: 8000
3、应用配置文件
$ kubectl apply -f ingresscom.yaml
[root@k8s-mater Downloads]# kubectl apply -f ingresscom.yaml
ingress.networking.k8s.io/ingress-host-bar created
4、查看网关(ingress)
[root@k8s-mater Downloads]# kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress-host-bar nginx hello.test.com,demo.test.com 192.168.64.130 80 30s

5、windows 配置域名映射(域名映射文件地址:C:\Windows\System32\drivers\etc)
192.168.64.128 hello.test.com
192.168.64.128 demo.test.com
或者使用utools 的hosts工具配置域名映射

映射:80:30813/TCP,443:31761/TCP
6、访问测试
- 访问 http://hello.test.com:30813/

- 访问 https://demo.test.com:31761/ ,nginx是由Ingress层返回的

- 访问 https://demo.test.com:31761/nginx ,nginx是由nginx-demo中的pod返回的

7、修改Ingress配置文件,将path: "/nginx"改成path: "/nginx.html"
$ kubectl edit ingress ingress-host-bar
8、nginx-demo中的pod的nginx容器内推荐nginx文件
cd /usr/share/nginx/html;echo "Hello nginx2
" > nginx.html;ls

5.2.4 路径重写
1、路径重写的环境搭建
- 修改配置文件 Ingresstest.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations: # 路径重写配置功能开启
nginx.ingress.kubernetes.io/rewrite-target: /$2
name: ingress-host-bar
spec:
ingressClassName: nginx
rules:
- host: "hello.test.com"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: hello-server
port:
number: 8000
- host: "demo.test.com"
http:
paths:
- pathType: Prefix
path: "/nginx(/|$)(.*)" # 配置忽略/nginx
backend:
service:
name: nginx-demo
port:
number: 8000
- 重新应用
$ kubectl apply -f Ingresstest.yaml
[root@k8s-mater Downloads]# kubectl apply -f Ingresstest.yaml
ingress.networking.k8s.io/ingress-host-bar configured
2、效果:
- 访问 https://demo.test.com:31761/nginx 相当于访问 https://demo.test.com:31761/

- 访问 https://demo.test.com:31761/nginx/ 也相当于访问 https://demo.test.com:31761/
- 访问 https://demo.test.com:31761/nginx/nginx.html 相当于访问 https://demo.test.com:31761/nginx.html

5.2.5 流量限制

1、配置文件:ingress-rule-2.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-limit-rate
annotations:
nginx.ingress.kubernetes.io/limit-rps: "1"
spec:
ingressClassName: nginx
rules:
- host: "limit.test.com"
http:
paths:
- pathType: Exact
path: "/"
backend:
service:
name: nginx-demo # 同样作用于nginx-demo (Service)
port:
number: 8000
2、应用
$ kubectl apply -f ingress-rule-2.yaml
[root@k8s-mater Downloads]# kubectl apply -f ingress-rule-2.yaml
ingress.networking.k8s.io/ingress-limit-rate created
3、windows 添加域名映射 192.168.64.128 limit.test.com
4、访问测试
-
正常访问返回nginx的欢迎页面
-
连续访问 http://limit.test.com:30813/ n次后(流量过大),返回503

6、存储抽象
docker有目录挂载的功能,但直接挂载,挂载目录繁多,难以管理,同时一旦发生故障转移,转移后的pod在容器挂载目录在
转移后的主机上不存在。
k8s的解决方案是,将服务器用于挂载目录组成存储层,存储层中的挂载目录由k8s统一管理,存储层使用技术可自定义(Glusterfs,NFS,CephFS等)。

存储层技术
1、NFS技术:每个服务器都备份

6.1 搭建NFS网络文件系统环境

1、所有服务器(节点)安装NFS工具
yum install -y nfs-utils
2、主节点(mater)操作
(1) 暴露目录,开发权限
echo "/nfs/data/ *(insecure,rw,sync,no_root_squash)" > /etc/exports
(2) 创建目录
mkdir -p /nfs/data
(3) 启动rpc远程绑定
systemctl enable rpcbind --now
(4) 启动服务
systemctl enable nfs-server --now
(5) 使配置生效
exportfs -r
(6) 查看配置
[root@k8s-mater ~]# exportfs
/nfs/data <world>
3、从节点(node1、node2)操作
(1) 显示可用挂载点 showmount -e 主节点ip
showmount -e 192.168.64.128
[root@node1 ~]# showmount -e 192.168.64.128
Export list for 192.168.64.128:
/nfs/data *
(2) 创建目录
mkdir -p /nfs/data
(3) 挂载 (执行以下命令挂载 nfs 服务器上的共享目录到本机路径 /nfs/data)
mount -t nfs 192.168.64.128:/nfs/data /nfs/data
(4)写入一个测试文件,>是覆盖写, >> 是追加
echo "hello nfs server" > /nfs/data/test.txt
(5)其他节点请看是否有测试文件,答案是有,文件数据并且同步更新
cat /nfs/data/test.txt
6.2 NFS(原生)方式数据挂载
1、创建目录(全部服务器)
mkdir /nfs/data/nginx-pv/
2、配置文件 mountnfs.yaml
容器路径 /usr/share/nginx/html 映射到 服务器路径 /nfs/data/nginx-pv
2个pod挂载同一路径
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-pv-demo
name: nginx-pv-demo
spec:
replicas: 2
selector:
matchLabels:
app: nginx-pv-demo
template:
metadata:
labels:
app: nginx-pv-demo
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
volumes:
- name: html
nfs:
server: 192.168.64.128
path: /nfs/data/nginx-pv/
3、应用配置文件
$ kubectl apply -f mountnfs.yaml
4、测试,挂载成功
[root@k8s-mater Downloads]# cd /nfs/data/nginx-pv/
[root@k8s-mater nginx-pv]# echo "Hello Mount" > index.html
root@nginx-pv-demo-fc6c6dd8d-smhzx:/# cd /usr/share/nginx/html
root@nginx-pv-demo-fc6c6dd8d-smhzx:/usr/share/nginx/html# ls
index.html
root@nginx-pv-demo-fc6c6dd8d-smhzx:/usr/share/nginx/html# cat index.html
Hello Mount
[root@k8s-mater nginx-pv]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-pv-demo-fc6c6dd8d-smhzx 1/1 Running 0 4m27s 172.31.166.166 node1 <none> <none>
nginx-pv-demo-fc6c6dd8d-vnwdc 1/1 Running 0 4m27s 172.31.166.165 node1 <none> <none>
[root@k8s-mater nginx-pv]# curl 172.31.166.166
Hello Mount
6.3 PV(持久卷)和PVC(持久卷申明)
NFS(原生)方式数据挂载存在一些问题:
- 目录要自己创建
- Deployment及其pod删除后,服务器目录数据依旧存在
- 挂载容量没有限制
PV&PVC
PV:持久卷(Persistent Volume),将应用需要持久化的数据保存到指定位置(存放持久化数据的目录就是持久卷)
PVC:持久卷申明(Persistent Volume Claim),申明需要使用的持久卷规格 (申请持久卷的申请书)
静态供应: 提取指定位置和空间大小
动态供应:位置和空间大小由pv自动创建
6.3.1 创建PV(持久卷)
1、创建pv池
nfs主节点(mater)操作
mkdir -p /nfs/data/01
mkdir -p /nfs/data/02
mkdir -p /nfs/data/03
2、创建三个 PV(持久卷)静态供应的方式,配置文件createPV.yaml
apiVersion: v1
kind: PersistentVolume # 类型
metadata:
name: pv01-10m # 名称
spec:
capacity:
storage: 10M # 持久卷空间大小
accessModes:
- ReadWriteMany # 多节点可读可写
storageClassName: nfs # 存储类名
nfs:
path: /nfs/data/01 # pc目录位置
server: 192.168.64.128
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv02-1gi
spec:
capacity:
storage: 1Gi # 持久卷空间大小
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/02 # pc目录位置
server: 192.168.64.128
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv03-3gi
spec:
capacity:
storage: 3Gi # 持久卷空间大小
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/03 # pc目录位置
server: 192.168.64.128
- 应用
$ kubectl apply -f createPV.yaml
[root@k8s-mater Downloads]# kubectl apply -f createPV.yaml
persistentvolume/pv01-10m created
persistentvolume/pv02-1gi created
persistentvolume/pv03-3gi created
3、查看PV
[root@k8s-mater Downloads]# kubectl get persistentvolume
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv01-10m 10M RWX Retain Available nfs 26s
pv02-1gi 1Gi RWX Retain Available nfs 26s
pv03-3gi 3Gi RWX Retain Available nfs 26s

6.3.1 PVC(持久卷申明)创建与绑定
1、创建PVC
(1) createPVC.yaml
kind: PersistentVolumeClaim # 类型
apiVersion: v1
metadata:
name: nginx-pvc # PVC名称
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 200Mi # 需要空间
storageClassName: nfs # 要对应PV的storageClassName
(2) 应用
[root@k8s-mater Downloads]# kubectl apply -f createPVC.yaml
persistentvolumeclaim/nginx-pvc created
(3) 查看PVC,挂载 pv02-1gi,挂载目录为 /nfs/data/02
[root@k8s-mater Downloads]# kubectl get persistentvolumeclaim
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
nginx-pvc Bound pv02-1gi 1Gi RWX nfs 17s

(4) 查看PC,状态Bound(绑定),说明已经被使用,绑定信息: default/nginx-pvc => 名称空间/PVC名称
(绑定空间选择最小且大小足够的)
[root@k8s-mater Downloads]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv01-10m 10M RWX Retain Available nfs 14m
# 状态Bound(绑定)
pv02-1gi 1Gi RWX Retain Bound default/nginx-pvc nfs 14m
pv03-3gi 3Gi RWX Retain Available nfs 14m
2、创建Deployment ,让Deployment中的Pod绑定PVC
(1) 配置文件 boundPVC.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-deploy-pvc # Deployment名称
name: nginx-deploy-pvc
spec:
replicas: 2 # pod数量
selector:
matchLabels:
app: nginx-deploy-pvc
template:
metadata:
labels:
app: nginx-deploy-pvc
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html # 挂载目录
volumes:
- name: html
persistentVolumeClaim:
claimName: nginx-pvc # pvc 的名称
(2)应用
[root@k8s-mater Downloads]# kubectl apply -f boundPVC.yaml
deployment.apps/nginx-deploy-pvc created
(3) 测试
- 向挂载目录
/nfs/data/02写入测试文件
[root@k8s-mater Downloads]# cd /nfs/data/02
[root@k8s-mater 02]# echo "boundPVC test nginx" > index.html
- 访问成功
[root@k8s-mater 02]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deploy-pvc-79fc8558c7-26grh 1/1 Running 0 15m 172.31.166.168 node1 <none> <none>
nginx-deploy-pvc-79fc8558c7-2gz4d 1/1 Running 0 15m 172.31.166.169 node1 <none> <none>
[root@k8s-mater 02]# curl 172.31.166.168
boundPVC test nginx
6.4 ConfigMap(配置集)
ConfigMap 缩写为cm
ConfigMap(配置集):用于配置文件挂载,抽取应用配置,并且可以自动更新。
以redis为示例
1、创建 redis.conf
appendonly yes
2、把之前的配置文件创建为配置集
创建配置,redis保存到 k8s的etcd(k8s资料库)
$ kubectl create configmap redis-conf --from-file=redis.conf
[root@k8s-mater Downloads]# kubectl create configmap redis-conf --from-file=redis.conf
configmap/redis-conf created
3、查看ConfigMap(配置集)
[root@k8s-mater Downloads]# kubectl get configmap
NAME DATA AGE
kube-root-ca.crt 1 2d14h
redis-conf 1 31s
4、查看 redis-conf(配置集)的配置文件
$ kubectl get configmap redis-conf -o yaml
[root@k8s-mater Downloads]#
apiVersion: v1
data: # data是所有真正的数据,key:默认是文件名 value:配置文件的内容
redis.conf: |
appendonly yes
kind: ConfigMap # 类型
metadata:
# ...
name: redis-conf
namespace: default
# ...
5、创建Pod
配置文件 cm01.yaml
apiVersion: v1
kind: Pod # 类型
metadata:
name: redis # pod名称
spec:
containers:
- name: redis
image: redis # 镜像
command:
- redis-server
- "/redis-master/redis.conf" #指的是redis容器内部的位置
ports:
- containerPort: 6379
volumeMounts: # 配置卷挂载
- mountPath: /data
name: data # 卷挂载名称 对应 下面的 挂载卷 data
- mountPath: /redis-master
name: config # 卷挂载名称 对应 下面的 挂载卷 config
volumes: # 挂载卷
- name: data
emptyDir: {}
- name: config
configMap: # 配置集
name: redis-conf
items:
- key: redis.conf
path: redis.conf
/redis-master 路径 挂载了 配置集 redis.conf
- 应用
$ kubectl apply -f cm01.yaml
6、检查默认配置
root@redis:/data# cat /redis-master/redis.conf
appendonly yes
7、修改 配置集redis.conf 的配置数据,增加 requirepass 123456
$ kubectl edit configmap redis-conf
8、检查配置是否更新,修改了cm,Pod里面的配置文件会跟着改变
root@redis:/data# cat /redis-master/redis.conf
appendonly yes
requirepass 123456
如果配置值未更改,因为需要重新启动 Pod 才能从关联的 ConfigMap 中获取更新的值。
原因:我们的Pod部署的中间件自己本身没有热更新能力
9、 进入pod内的Redis,查看配置
$ kubectl exec -it redis -- redis-cli
127.0.0.1:6379> CONFIG GET appendonly
1) "appendonly"
2) "yes"
127.0.0.1:6379> CONFIG GET requirepass
1) "requirepass"
2) ""
6.5 Secret保存敏感信息
Secret 对象类型用来保存敏感信息,例如密码、OAuth 令牌和 SSH 密钥。 将这些信息放在 secret 中比放在 Pod 的定义或者 容器镜像 中来说更加安全和灵活。原理同ConfigMap
1、Docker Hub 设置一个私有仓库dockerywl/mysql

2、使用私有仓库的镜像创建pod
配置文件 secret01.yaml
apiVersion: v1
kind: Pod
metadata:
name: private-nginx # pod 名称
spec:
containers:
- name: private-nginx
image: dockerywl/mysql # 私有镜像名称
3、应用
[root@k8s-mater Downloads]# kubectl apply -f secret01.yaml
pod/private-nginx created
# pull失败:不存在或可能需要'docker login': denied:请求的资源访问被拒绝
Failed to pull image "dockerywl/mysql": rpc error: code = Unknown desc = Error response from daemon: pull access denied for dockerywl/mysql, repository does not exist or may require 'docker login': denied: requested access to the resource is denied
4、创建 Secret
- 命令格式
kubectl create secret docker-registry 【Secret的名称】 \
--docker-server=【你的镜像仓库服务器】 \
--docker-username=【你的用户名】 \
--docker-password=【你的密码】 \
--docker-email=【你的邮箱地址】
5、查看Secret
[root@k8s-mater Downloads]# kubectl get secret
NAME TYPE DATA AGE
default-token-rhpvm kubernetes.io/service-account-token 3 2d16h
regcred kubernetes.io/dockerconfigjson 1 22s

6、查看对应的 Secret 的配置文件
$ kubectl get secret regcred -o yaml
data 的 docker配置信息已经被加密成密文
apiVersion: v1
data:
.dockerconfigjson: eyJhdXRocyI6eyJkb2NrZXJ5d2wiOnsidXNlcm5hbWUiOiJkb2NrZXJ5d2wiLCJwYXNzd29yZCI6ImExNzgyNzgwMDI2NSIsImVtYWlsIjoiaWRfMDcyMjE2NjZAcXEuY29tIiwiYXV0aCI6IlpHOWphMlZ5ZVhkc09tRXhOemd5Tnpnd01ESTJOUT09In19fQ==
kind: Secret # 类型
metadata:
# ...
name: regcred
namespace: default
# ...
7、修改配置文件 secret01.yaml,重新 pull 私有镜像
apiVersion: v1
kind: Pod
metadata:
name: private-mysql02
spec:
containers:
- name: private-mysql02
image: dockerywl/mysql
imagePullSecrets:
- name: regcred # 指定secret的名称
- 应用
[root@k8s-mater Downloads]# kubectl apply -f secret01.yaml
pod/private-mysql created
- pull 私有镜像成功,pod创建成功
9、 进入pod内的Redis,查看配置
$ kubectl exec -it redis -- redis-cli
127.0.0.1:6379> CONFIG GET appendonly
1) "appendonly"
2) "yes"
127.0.0.1:6379> CONFIG GET requirepass
1) "requirepass"
2) ""