算法导论九大排序总结
转载来源:http://blog.csdn.net/xiazdong
http://www.cnblogs.com/eniac12/p/5329396.html(很好)
本文首先介绍了基于比较模型的排序算法,即最坏复杂度都在Ω(nlgn)的排序算法,接着介绍了一些线性时间排序算法,这些排序算法虽然都在线性时间,但是都是在对输入数组有一定的约束的前提下才行。
这篇文章参看了《算法导论》第2、3、4、6、7、8章而总结。
算法的由来:9世纪波斯数学家提出的:“al-Khowarizmi”
排序的定义:
输入:n个数:a1,a2,a3,...,an
输出:n个数的排列:a1',a2',a3',...,an',使得a1'<=a2'<=a3'<=...<=an'。
In-place sort(不占用额外内存或占用常数的内存):插入排序、选择排序、冒泡排序、堆排序、快速排序。
Out-place sort:归并排序、计数排序、基数排序、桶排序。
当需要对大量数据进行排序时,In-place sort就显示出优点,因为只需要占用常数的内存。
设想一下,如果要对10000个数据排序,如果使用了Out-place sort,则假设需要用200G的额外空间,则一台老式电脑会吃不消,但是如果使用In-place sort,则不需要花费额外内存。
stable sort:插入排序、冒泡排序、归并排序、计数排序、基数排序、桶排序。
unstable sort:选择排序(5 8 5 2 9)、快速排序、堆排序。
为何排序的稳定性很重要?
在初学排序时会觉得稳定性有这么重要吗?两个一样的元素的顺序有这么重要吗?其实很重要。在基数排序中显得尤为突出,如下:
算法导论习题8.3-2说:如果对于不稳定的算法进行改进,使得那些不稳定的算法也稳定?
其实很简单,只需要在每个输入元素加一个index,表示初始时的数组索引,当不稳定的算法排好序后,对于相同的元素对index排序即可。
基于比较的排序都是遵循“决策树模型”,而在决策树模型中,我们能证明给予比较的排序算法最坏情况下的运行时间为Ω(nlgn),证明的思路是因为将n个序列构成的决策树的叶子节点个数至少有n!,因此高度至少为nlgn。
线性时间排序虽然能够理想情况下能在线性时间排序,但是每个排序都需要对输入数组做一些假设,比如计数排序需要输入数组数字范围为[0,k]等。
在排序算法的正确性证明中介绍了”循环不变式“,他类似于数学归纳法,"初始"对应"n=1","保持"对应"假设n=k成立,当n=k+1时"。
一、插入排序
特点:stable sort、In-place sort
最优复杂度:当输入数组就是排好序的时候,复杂度为O(n),而快速排序在这种情况下会产生O(n^2)的复杂度。
最差复杂度:当输入数组为倒序时,复杂度为O(n^2)
插入排序比较适合用于“少量元素的数组”。
其实插入排序的复杂度和逆序对的个数一样,当数组倒序时,逆序对的个数为n(n-1)/2,因此插入排序复杂度为O(n^2)。
在算法导论2-4中有关于逆序对的介绍。
伪代码:
证明算法正确性:
循环不变式:在每次循环开始前,A[1...i-1]包含了原来的A[1...i-1]的元素,并且已排序。
初始:i=2,A[1...1]已排序,成立。
保持:在迭代开始前,A[1...i-1]已排序,而循环体的目的是将A[i]插入A[1...i-1]中,使得A[1...i]排序,因此在下一轮迭代开 始前,i++,因此现在A[1...i-1]排好序了,因此保持循环不变式。
终止:最后i=n+1,并且A[1...n]已排序,而A[1...n]就是整个数组,因此证毕。
而在算法导论2.3-6中还问是否能将伪代码第6-8行用二分法实现?
实际上是不能的。因为第6-8行并不是单纯的线性查找,而是还要移出一个空位让A[i]插入,因此就算二分查找用O(lgn)查到了插入的位置,但是还是要用O(n)的时间移出一个空位。
问:快速排序(不使用随机化)是否一定比插入排序快?
答:不一定,当输入数组已经排好序时,插入排序需要O(n)时间,而快速排序需要O(n^2)时间。
递归版插入排序
二、冒泡排序
特点:stable sort、In-place sort
思想:通过两两交换,像水中的泡泡一样,小的先冒出来,大的后冒出来。
最坏运行时间:O(n^2)
最佳运行时间:O(n^2)(当然,也可以进行改进使得最佳运行时间为O(n))
算法导论思考题2-2中介绍了冒泡排序。
伪代码:
证明算法正确性:
运用两次循环不变式,先证明第4-6行的内循环,再证明外循环。
内循环不变式:在每次循环开始前,A[j]是A[j...n]中最小的元素。
初始:j=n,因此A[n]是A[n...n]的最小元素。
保持:当循环开始时,已知A[j]是A[j...n]的最小元素,将A[j]与A[j-1]比较,并将较小者放在j-1位置,因此能够说明A[j-1]是A[j-1...n]的最小元素,因此循环不变式保持。
终止:j=i,已知A[i]是A[i...n]中最小的元素,证毕。
接下来证明外循环不变式:在每次循环之前,A[1...i-1]包含了A中最小的i-1个元素,且已排序:A[1]<=A[2]<=...<=A[i-1]。
初始:i=1,因此A[1..0]=空,因此成立。
保持:当循环开始时,已知A[1...i-1]是A中最小的i-1个元素,且A[1]<=A[2]<=...<=A[i-1],根据内循环不变式,终止时A[i]是A[i...n]中最小的元素,因此A[1...i]包含了A中最小的i个元素,且A[1]<=A[2]<=...<=A[i-1]<=A[i]
终止:i=n+1,已知A[1...n]是A中最小的n个元素,且A[1]<=A[2]<=...<=A[n],得证。
在算法导论思考题2-2中又问了”冒泡排序和插入排序哪个更快“呢?
一般的人回答:“差不多吧,因为渐近时间都是O(n^2)”。
但是事实上不是这样的,插入排序的速度直接是逆序对的个数,而冒泡排序中执行“交换“的次数是逆序对的个数,因此冒泡排序执行的时间至少是逆序对的个数,因此插入排序的执行时间至少比冒泡排序快。
递归版冒泡排序
改进版冒泡排序
最佳运行时间:O(n)
最坏运行时间:O(n^2)
三、选择排序
特性:In-place sort,unstable sort。
思想:每次找一个最小值。
最好情况时间:O(n^2)。
最坏情况时间:O(n^2)。
伪代码:
证明算法正确性:
循环不变式:A[1...i-1]包含了A中最小的i-1个元素,且已排序。
初始:i=1,A[1...0]=空,因此成立。
保持:在某次迭代开始之前,保持循环不变式,即A[1...i-1]包含了A中最小的i-1个元素,且已排序,则进入循环体后,程序从 A[i...n]中找出最小值放在A[i]处,因此A[1...i]包含了A中最小的i个元素,且已排序,而i++,因此下一次循环之前,保持 循环不变式:A[1..i-1]包含了A中最小的i-1个元素,且已排序。
终止:i=n,已知A[1...n-1]包含了A中最小的i-1个元素,且已排序,因此A[n]中的元素是最大的,因此A[1...n]已排序,证毕。
算法导论2.2-2中问了"为什么伪代码中第3行只有循环n-1次而不是n次"?
在循环不变式证明中也提到了,如果A[1...n-1]已排序,且包含了A中最小的n-1个元素,则A[n]肯定是最大的,因此肯定是已排序的。
递归版选择排序
递归式:
T(n)=T(n-1)+O(n)
=> T(n)=O(n^2)
四、归并排序
特点:stable sort、Out-place sort
思想:运用分治法思想解决排序问题。
最坏情况运行时间:O(nlgn)
最佳运行时间:O(nlgn)
分治法介绍:分治法就是将原问题分解为多个独立的子问题,且这些子问题的形式和原问题相似,只是规模上减少了,求解完子问题后合并结果构成原问题的解。
分治法通常有3步:Divide(分解子问题的步骤) 、 Conquer(递归解决子问题的步骤)、 Combine(子问题解求出来后合并成原问题解的步骤)。
假设Divide需要f(n)时间,Conquer分解为b个子问题,且子问题大小为a,Combine需要g(n)时间,则递归式为:
T(n)=bT(n/a)+f(n)+g(n)
算法导论思考题4-3(参数传递)能够很好的考察对于分治法的理解。
就如归并排序,Divide的步骤为m=(p+q)/2,因此为O(1),Combine步骤为merge()函数,Conquer步骤为分解为2个子问题,子问题大小为n/2,因此:
归并排序的递归式:T(n)=2T(n/2)+O(n)
而求解递归式的三种方法有:
(1)替换法:主要用于验证递归式的复杂度。
(2)递归树:能够大致估算递归式的复杂度,估算完后可以用替换法验证。
(3)主定理:用于解一些常见的递归式。
伪代码:
证明算法正确性:
其实我们只要证明merge()函数的正确性即可。
merge函数的主要步骤在第25~31行,可以看出是由一个循环构成。
循环不变式:每次循环之前,A[p...k-1]已排序,且L[i]和R[j]是L和R中剩下的元素中最小的两个元素。
初始:k=p,A[p...p-1]为空,因此已排序,成立。
保持:在第k次迭代之前,A[p...k-1]已经排序,而因为L[i]和R[j]是L和R中剩下的元素中最小的两个元素,因此只需要将L[i]和R[j]中最小的元素放到A[k]即可,在第k+1次迭代之前A[p...k]已排序,且L[i]和R[j]为剩下的最小的两个元素。
终止:k=q+1,且A[p...q]已排序,这就是我们想要的,因此证毕。
归并排序的例子:
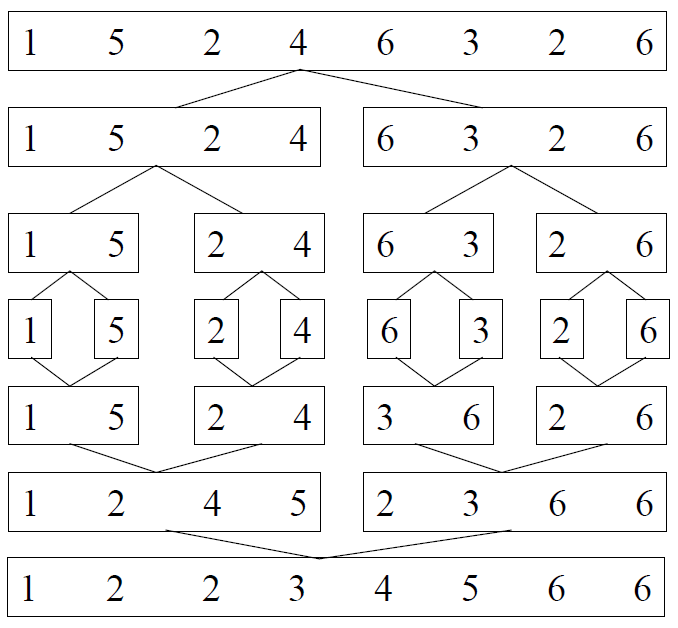
问:归并排序的缺点是什么?
答:他是Out-place sort,因此相比快排,需要很多额外的空间。
问:为什么归并排序比快速排序慢?
答:虽然渐近复杂度一样,但是归并排序的系数比快排大。
问:对于归并排序有什么改进?
答:就是在数组长度为k时,用插入排序,因为插入排序适合对小数组排序。在算法导论思考题2-1中介绍了。复杂度为O(nk+nlg(n/k)) ,当k=O(lgn)时,复杂度为O(nlgn)
五、快速排序
Tony Hoare爵士在1962年发明,被誉为“20世纪十大经典算法之一”。
算法导论中讲解的快速排序的PARTITION是Lomuto提出的,是对Hoare的算法进行一些改变的,而算法导论7-1介绍了Hoare的快排。
特性:unstable sort、In-place sort。
最坏运行时间:当输入数组已排序时,时间为O(n^2),当然可以通过随机化来改进(shuffle array 或者 randomized select pivot),使得期望运行时间为O(nlgn)。
最佳运行时间:O(nlgn)
快速排序的思想也是分治法。
当输入数组的所有元素都一样时,不管是快速排序还是随机化快速排序的复杂度都为O(n^2),而在算法导论第三版的思考题7-2中通过改变Partition函数,从而改进复杂度为O(n)。
注意:只要partition的划分比例是常数的,则快排的效率就是O(nlgn),比如当partition的划分比例为10000:1时(足够不平衡了),快排的效率还是O(nlgn)
“A killer adversary for quicksort”这篇文章很有趣的介绍了怎么样设计一个输入数组,使得quicksort运行时间为O(n^2)。
伪代码:
随机化partition的实现:
改进当所有元素相同时的效率的Partition实现:
证明算法正确性:
对partition函数证明循环不变式:A[p...i]的所有元素小于等于pivot,A[i+1...j-1]的所有元素大于pivot。
初始:i=p-1,j=p,因此A[p...p-1]=空,A[p...p-1]=空,因此成立。
保持:当循环开始前,已知A[p...i]的所有元素小于等于pivot,A[i+1...j-1]的所有元素大于pivot,在循环体中,
- 如果A[j]>pivot,那么不动,j++,此时A[p...i]的所有元素小于等于pivot,A[i+1...j-1]的所有元素大于pivot。
- 如果A[j]<=pivot,则i++,A[i+1]>pivot,将A[i+1]和A[j]交换后,A[P...i]保持所有元素小于等于pivot,而A[i+1...j-1]的所有元素大于pivot。
终止:j=r,因此A[p...i]的所有元素小于等于pivot,A[i+1...r-1]的所有元素大于pivot。
六、堆排序
1964年Williams提出。
特性:unstable sort、In-place sort。
最优时间:O(nlgn)
最差时间:O(nlgn)
此篇文章介绍了堆排序的最优时间和最差时间的证明:http://blog.csdn.net/xiazdong/article/details/8193625
思想:运用了最小堆、最大堆这个数据结构,而堆还能用于构建优先队列。
优先队列应用于进程间调度、任务调度等。
堆数据结构应用于Dijkstra、Prim算法。
证明算法正确性:
(1)证明build_max_heap的正确性:
循环不变式:每次循环开始前,A[i+1]、A[i+2]、...、A[n]分别为最大堆的根。
初始:i=floor(n/2),则A[i+1]、...、A[n]都是叶子,因此成立。
保持:每次迭代开始前,已知A[i+1]、A[i+2]、...、A[n]分别为最大堆的根,在循环体中,因为A[i]的孩子的子树都是最大堆,因此执行完MAX_HEAPIFY(A,i)后,A[i]也是最大堆的根,因此保持循环不变式。
终止:i=0,已知A[1]、...、A[n]都是最大堆的根,得到了A[1]是最大堆的根,因此证毕。
(2)证明heapsort的正确性:
循环不变式:每次迭代前,A[i+1]、...、A[n]包含了A中最大的n-i个元素,且A[i+1]<=A[i+2]<=...<=A[n],且A[1]是堆中最大的。
初始:i=n,A[n+1]...A[n]为空,成立。
保持:每次迭代开始前,A[i+1]、...、A[n]包含了A中最大的n-i个元素,且A[i+1]<=A[i+2]<=...<=A[n],循环体内将A[1]与A[i]交换,因为A[1]是堆中最大的,因此A[i]、...、A[n]包含了A中最大的n-i+1个元素且A[i]<=A[i+1]<=A[i+2]<=...<=A[n],因此保持循环不变式。
终止:i=1,已知A[2]、...、A[n]包含了A中最大的n-1个元素,且A[2]<=A[3]<=...<=A[n],因此A[1]<=A[2]<=A[3]<=...<=A[n],证毕。
七、计数排序
特性:stable sort、out-place sort。
最坏情况运行时间:O(n+k)
最好情况运行时间:O(n+k)
当k=O(n)时,计数排序时间为O(n)
伪代码:
八、基数排序
本文假定每位的排序是计数排序。
特性:stable sort、Out-place sort。
最坏情况运行时间:O((n+k)d)
最好情况运行时间:O((n+k)d)
当d为常数、k=O(n)时,效率为O(n)
我们也不一定要一位一位排序,我们可以多位多位排序,比如一共10位,我们可以先对低5位排序,再对高5位排序。
引理:假设n个b位数,将b位数分为多个单元,且每个单元为r位,那么基数排序的效率为O[(b/r)(n+2^r)]。
当b=O(nlgn),r=lgn时,基数排序效率O(n)
比如算法导论习题8.3-4:说明如何在O(n)时间内,对0~n^2-1之间的n个整数排序?
答案:将这些数化为2进制,位数为lg(n^2)=2lgn=O(lgn),因此利用引理,b=O(lgn),而我们设r=lgn,则基数排序可以在O(n)内排序。
基数排序的例子:
证明算法正确性:
通过循环不变式可证,证明略。
九、桶排序
假设输入数组的元素都在[0,1)之间。
特性: out-place sort、stable sort 。
最坏情况运行时间:当分布不均匀时,全部元素都分到一个桶中,则O(n^2),当然[算法导论8.4-2]也可以将插入排序换成堆排序、快速排序等,这样最坏情况就是O(nlgn)。
最好情况运行时间:O(n)
桶排序的例子:

伪代码:

证明算法正确性:
对于任意A[i]<=A[j],且A[i]落在B[a],A[j]落在B[b],我们可以看出a<=b,因此得证。