Scikit-Learn & TensorFlow机器学习实用指南(一):机器学习概览
机器学习实用指南(一):机器学习概览
作者:LeonG
本文参考自:《Hands-On Machine Learning with Scikit-Learn & TensorFlow 机器学习实用指南》,感谢中文AI社区ApacheCN提供翻译。
1. 什么是机器学习?
对于一个问题,我们有很多的解决方法,但是对于同一类型的问题难道我们都要自己来手动解决吗?如果没有一套完整的解决方案,问题会变得很复杂,比如垃圾邮件分类问题。
人可以识别什么是垃圾邮件,所以我们为邮件编写一个分类规则,比如出现限时促销 、在线赌场等字样,我们就可以把它归为垃圾邮件,这种方法称为传统方法。
但是这样的结果就是:规则越来越复杂,错误率也很高,那有什么办法让计算机自己分析邮件呢?
机器学习可以解决上述问题
我们先来看一下专家是怎么定义机器学习的:
机器学习是通过编程让计算机从数据中进行学习的科学(和艺术)。
机器学习是让计算机具有学习的能力,无需进行明确编程。 —— 亚瑟·萨缪尔,1959
计算机程序利用经验 E 学习任务 T,性能是 P,如果针对任务 T 的性能 P 随着经验 E 不断增 长,则称为机器学习。 —— 汤姆·米切尔,1997
这是我个人的理解:计算机使用某种算法对已有的数据进行学习,并能够分析新的数据得出合适的结论。
假设有一道初中数学题,那么初中生是怎么解决这道题目的?我们看看他的学习方式:
先找来已经解决过的类似的题目,然后把这些题目做出来,边做边总结方法,最后用总结出来的方法解决未知的题目。
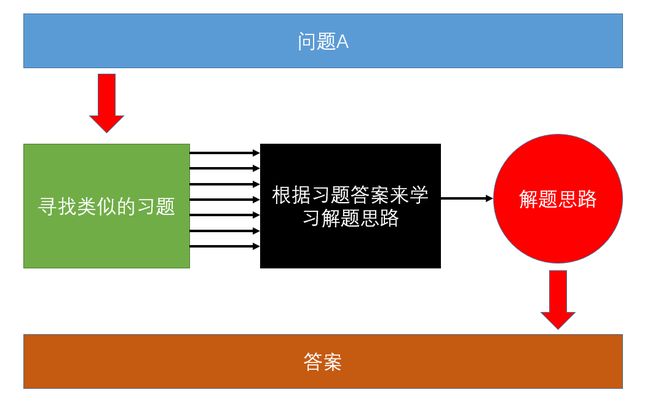
将上图类比到机器学习,红色箭头就是人类需要手动做的事情,寻找数据集,测试算法模型的准确度,而黑色箭头则是机器学习自动完成的部分,自动分析数据,自动优化算法模型。
再将这个例子和机器学习做一个类比:
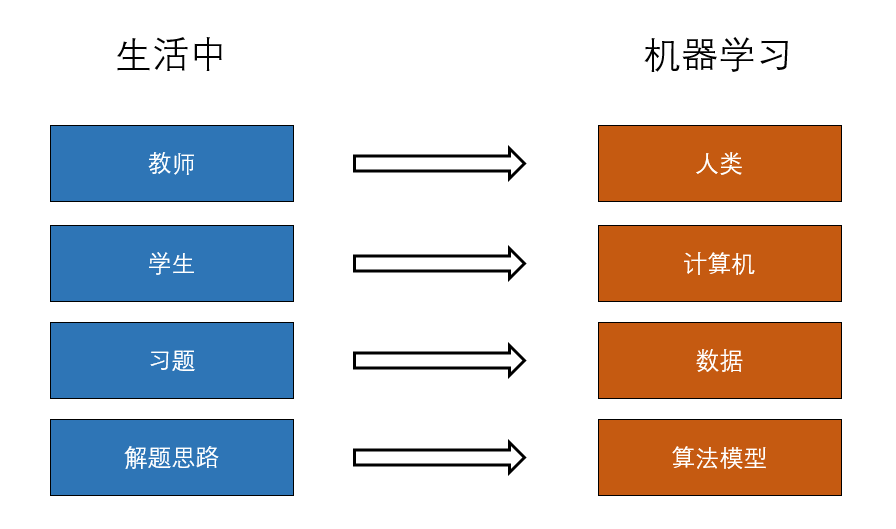
根据这两幅图,我们可以做出总结:
计算机通过数据来优化算法模型,优化后的算法模型用于解决新的实际问题。
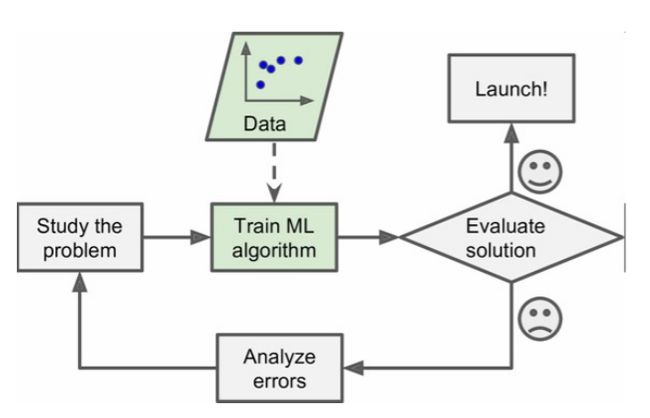
那么,对于机器学习来说,最重要的两个关键点就是: 数据 + 算法,机器学习和人类一样,既需要足够多的数据(知识),也需要良好的算法(学习方法)。
回到开头的问题,那么相较于传统的方法,机器学习的好处有哪些?
机器学习四大优势:
-
简化程序
机器学习省略了复杂的规则编写,只需要设计出合理的算法,并给出合适的数据集,机器学习就能提供一个效果很好的算法模型。
-
自主学习
机器学习可以自动的学习,通过不断的输入数据,调整自己的参数,这一切都不需要人手动干预。
-
泛化能力
传统的方法遇到了新的问题必须自己更新规则和计算方法,工作量很大。而机器学习可以自动学习新的规则。
-
数据挖掘
机器学习能够分析出数据对结果的影响,而且能将隐藏的联系展现出来,比如当地房价和政府对城市环保的投资力度有关。人很难分析出这种隐含的关系,而机器学习可以帮助我们。
2. 机器学习的类型
机器学习按照不同的标准可以分为很多种类,我们按照三种方式将其分类:
- 是否在人类监督下进行训练(监督,无监督,半监督和强化学习)
- 是否可以动态渐进学习(在线学习 vs 批量学习)
- 是否只是通过简单地比较新的数据点和已知的数据点,或者是在训练数据中进行模式识别,以建立一个预测模型,就像科学家所做的那样(基于实例学习 vs 基于模型学习)
根据是否在人类监督下进行训练的标准我们可以分为以下三种类型:
(1)监督学习
在监督学习的训练过程中,训练的数据都包含了标签,那什么是标签呢?
很好理解,我们还是拿初中生学习的例子来说。
如果把一本习题集比作我们要学习的数据,那么习题集后面的参考答案就是标签,它为我们做题目指引了方向,做错了就改正,做对了继续下一题,这种学习就是监督学习。
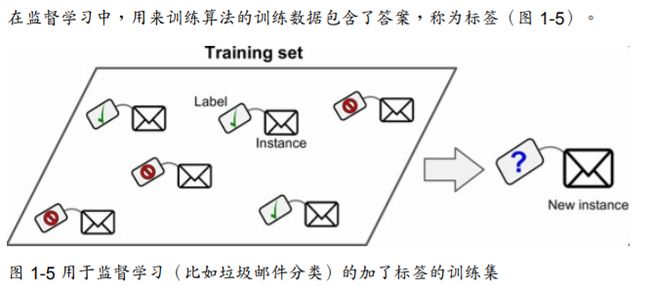
而监督学习一般又分为一下两类任务:
-
分类
顾名思义,就是通过学习已经分好的数据,对新的数据进行分类。比如垃圾邮件分类器,就是先输入带有是否为垃圾邮件标签的邮件,让计算机进行学习,再对没有分类的邮件进行判断。上面有示意图。
-
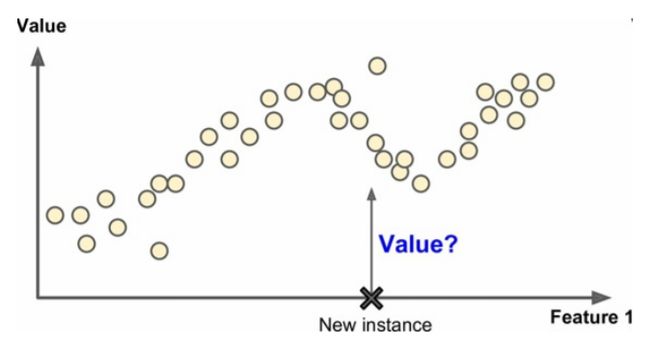
回归
回归就是预测目标数值,比如我想通过研究戴尔笔记本不同型号的配置,比如cpu、内存、显卡和它们定价之间的联系,然后来预测最新款的笔记本价格在什么范围内,这就是预测。
(2)无监督学习
加了一个“无”字,意思就是没有标签咯?没错,无监督学习就是使用不带标签的数据进行学习。
这就奇怪了,如果做题目没有答案给我参考,我怎么知道自己是不是做对了呢?
无监督学习中,数据是没有标签的或者是有一样的标签的。我们不知道数据的含义和作用,我们需要计算机自己进行分析和处理。
不用担心看不懂,来看看无监督学习的几个主要任务你就明白了。
-
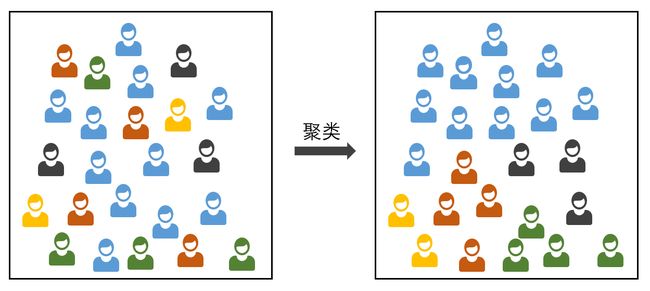
聚类
聚类就是将数据自动分离成几个部分,每个部分的内部都有相似之处。下面我们举一个简单的例子。
大家应该都喜欢看电影吧,一个人去看电影的孤独想必大家都不想体会。假定你是一个大学生,那怎么样才能在班上找到和自己兴趣相投的电影爱好者呢?
我们可以收集一份班上同学的电影爱好表,然后按照大家的爱好信息将类型相近的同学分为一组,这样我们就可以将所有的同学分成很多组,比如文艺片爱好者,动作片爱好者,科幻片爱好者。这就是一种聚类学习。
-
降维
降维就是剔除对数据影响较低的特征,优化数据的结构,减少数据的复杂度,还是举一个例子。
你还是一个爱看电影的大学生,但是马上要期末考了,不得不放下心爱的电影。由于你看电影上头,所有的科目都还没有复习,是不是要做一些取舍。
每一门课程对你来说重要程度肯定不一样。比如影视鉴赏选修课,这一门听学长说是稳过的,那我们就没必要将精力集中在这门课上,可以从复习计划中删除。而高等数学成绩直接影响了你整个大学生涯,所以我们要重视这门课。大学英语和专业英语是同类型课程,可以合并在一起学习。
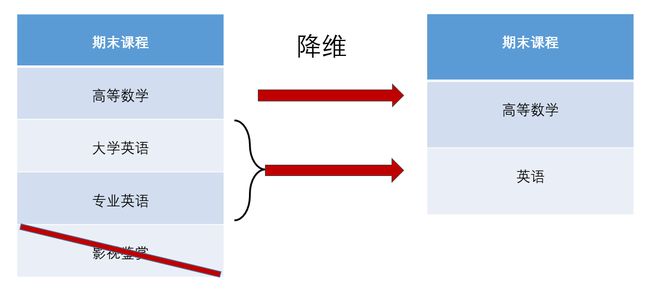
这就是一种降维方法,将数据中不同的特征进行一些处理,分析哪些特征对结果的影响最大, 剔除对结果影响不大的特征,或者是将若干个特征进行合并,以便我们的算法更集中的分析重要的数据。
提示:在用训练集训练机器学习算法(比如监督学习算法)时,最好对训练集进行降 维。这样可以运行的更快,占用的硬盘和内存空间更少,有些情况下性能也更好。
-
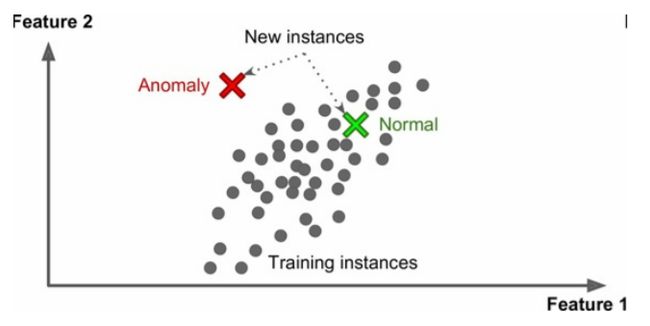
异常检测
我们常常使用无监督学习来分析数据里是否存在异常的数据,也就是不合群的数据。然后将这种数据剔除。
在正常的训练过程中,遇到一个新的数据,我们也可以判断这个数据是正常值还是异常值。
比如周末你闲赋在家,检查了自己保存的所有电影票根,发现只有万达影城的票特别贵,所以决定以后都不去万达影城了。这就是异常检测。
-
关联规则
最后,另一个常见的非监督任务是关联规则学习,它的目标是挖掘大量数据以找出数据特征之间的某些联系。
例如,寒假期间你在电影院打工,善于观察的你发现买了爆米花的人大概率也会买可乐,因此你推荐老板将爆米花和可乐做成套餐出售,这就是关联规则。
(3)半监督学习
一些算法可以处理部分带标签的训练数据,通常是大量不带标签数据加上小部分带标签数据。这称作半监督学习。
我们假设喜欢看电影的你,同时也爱收藏票根。有一次你在家整理电影票根,发现一部分票根上面的影城信息磨损了。我们按照小票的颜色和格式将不同的票根分类**(这一步是无监督学习的方法),然后再看每一类中没有磨损的票根上面的影城信息,就能推导出每张票来自哪个影城了。(这一步是监督学习的方法)**。
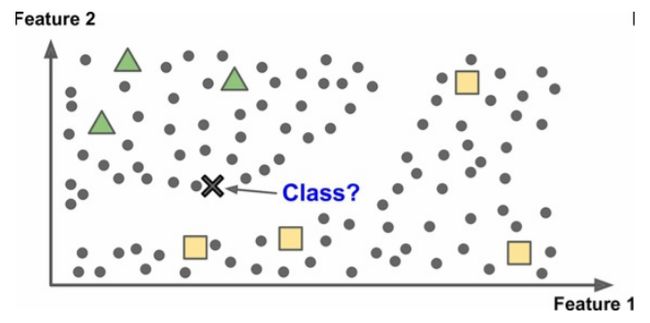
所以我们会发现:
多数半监督学习算法是非监督和监督算法的结合。
(4)强化学习
强化学习非常不同。学习系统在这里被称为智能体(agent),可以对环境进行观察,选择和执行动作,获得奖励或惩罚。然后它必须自己学习哪个是最佳方法(称为策略,policy),以得到长久的最大奖励。策略决定了智能体在给定情况下应该采取的行动。
AlphaGo就是强化学习的典型代表,它通过不断的试错,最后得出一套完整的围棋制胜策略,打败了人类的最高水平。
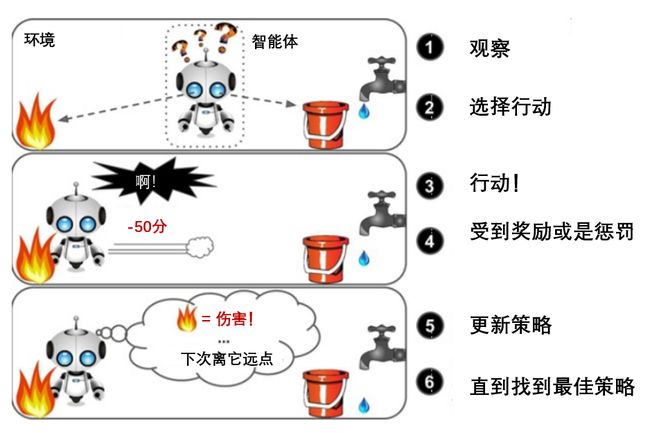
另一个用来分类机器学习的准则是,它是否能从导入的数据流中进行持续的学习。
(1)批量学习
批量学习是一次性将所有的数据进行学习,这样一般会占用很多的时间和计算资源,计算完了之后再开始使用。一般的学习方式都是批量学习,因为方法简单。
举个例子,初中数学书是人教版的,如果我们把人教版的书和习题全部学习一遍,再去考试,这就是批量学习,学习是一次性的。
假如考试范围不仅仅是人教版的,还有苏教版呢,那这个学生又要重新学习一遍苏教版的内容。
这就是批量学习的不足之处,,用全部数据训练需要大量计算资源(CPU、内存空间、磁盘空间、磁盘 I/O、网络 I/O等等)。如果你有大量数据,并让系统每天自动从头开始训练,就会开销很大。如果数据量巨大,甚至无法使用批量学习算法。最后,如果你的系统需要自动学习,但是资源有限(比如,一台智能手机或火星车),携带大量训练数据、每天花费数小时的大量资源进行训练是不实际的。
(2)增量学习
增量学习也叫在线学习,持续性学习,顾名思义,就是持续地输入数据,算法根据每次输入的数据进行相应的调整。每一个学习步骤都很快而且开销很小。所以系统可以动态的学习新的数据。
也可以当机器的内存存不下大量数据集时,用来训练系统(这称作核外学习,out-of-core learning)。算法加载部分的数据,用这些数据进行训练,重复这个过程,直到用所有数据都进行了训练。
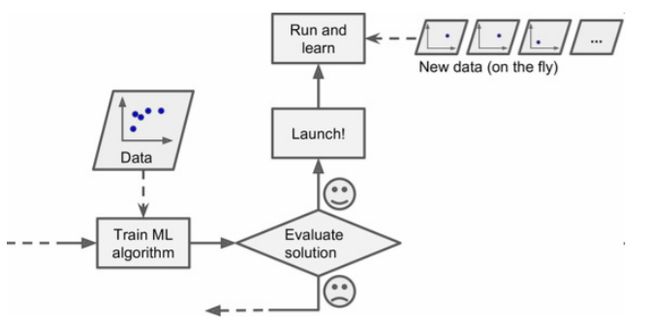
还有一种分类标准是判断它们是如何进行归纳推广的。分为基于实例的学习和基于模型的学习。
基于实例的学习是直接对数据进行记忆,然后用相似度的方式来推广至新的数据。比如K近邻、朴素贝叶斯。
基于模型的学习则是先选择合适的模型,再用数据对模型进行训练。比如多元线性回归、支持向量机、深度学习。
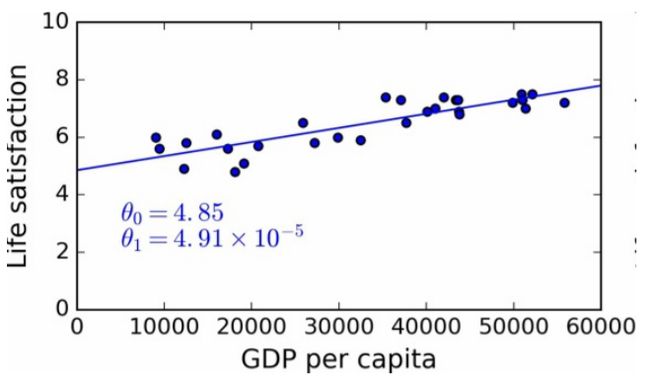
比如线性回归算法,就是先假定数据符合 f ( x ) = θ 0 + θ 1 × x f(x) = \theta_0+\theta_1×x f(x)=θ0+θ1×x这样一个线性的拟合函数。然后通过调整 θ 0 \theta_0 θ0和 θ 1 \theta_1 θ1的值,拟合训练数据:
3. 机器学习面临的主要问题
简单的来说,机器学习面临的主要问题来自两个方向,也就是机器学习最最重要的两个关键点:数据 + 算法
-
训练数据少
如果一个学生只学了几道题目就参加期末考试,那他可能会考得一塌糊涂,计算机也是这样,如果训练数据太少了,多数机器学习算法就无法正常工作。
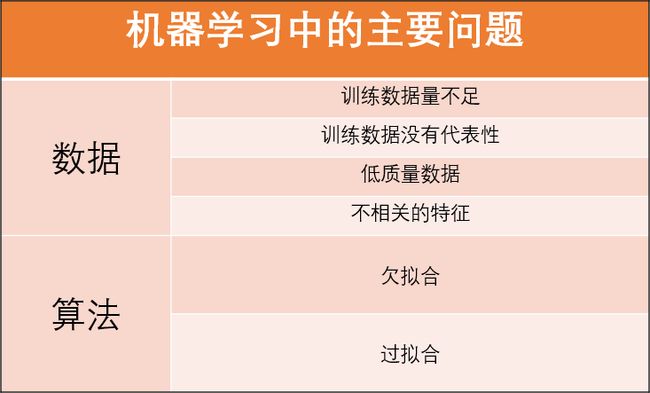
即便对于一些非常简单的问题,也需要数千的样本。而对于复杂的问题,比如图像、语音识别,则可能需要数百万的样本。
在2001年的一篇论文中,作者研究了不同算法在数据量级增加时表现出的性能,实验证明一旦有大量数据进行训练,不同算法之间的差异会大大减小。这就是传说中的天赋不够,努力来凑吧。
-
数据没有代表性
数据具有代表性是非常重要的。举个例子,如果很多人都跟你吐槽最近上映的一部电影很烂,你接收到的信息都是关于这部电影的缺点,那么你很有可能再还没有看之前就把这部电影判了死刑。
使用了没有代表性的训练集,我们就会得出与事实不太相符的结论。书上也举了一个很好的例子。
一个样本偏差的著名案例
也许关于样本偏差最有名的案例发生在 1936 年兰登和罗斯福的美国大选:《文学文摘》做了一个非常大的民调,给 1000 万人邮寄了调查信。
得到了 240 万回信,非常有信心地预测兰登会以 57% 赢得大选。然而,罗斯福赢得了 62% 的选票。
错误发生在《文学文摘》的取样方法:
首先,为了获取发信地址,《文学文摘》使用了电话黄页、杂志订阅用户、俱乐部会员等相似的列表。所有这些列表都偏向于富裕人群,他们都倾向于投票给共和党(即兰登)。
第二,只有 25% 的回答了调研。这就又一次引入了样本偏差,它排除了不关心政治的人、不喜欢《文学文摘》的人,和其它关键人群。这种特殊的样本偏差称作无应答偏差。
-
低质量数据
有的数据具有明显的异常或是缺失关键信息,那么这种数据就是低质量数据。系统检测出潜在的数据规律难度就会变大,性能就会降低。事实上这个问题很严重,所以实际工作中我们要花很多时间在数据清洗上。
-
不相关的特征
有的数据特征跟你的结论毫无关联,就需要剔除掉。
比如影响你期末成绩的课程有数学、英语、专业课,但是不应该包括你喜欢的游戏类型,如果你把你喜欢的游戏类型加进来一起分析,可能得不到任何正面的作用。
机器学习项目成功的关键之一是用好的特征进行训练。
现在数据造成的问题我们已经分析完了,再看看算法会导致的问题。
-
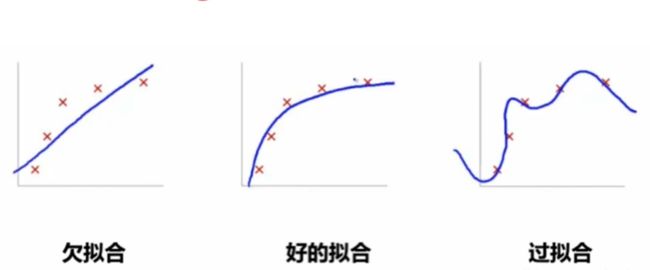
欠拟合训练数据
假如你的算法模型过于简单,那么就不能得到很好的拟合效果。
比如我们想研究每个月电影上映的数量。如果用一个线性的模型来拟合显然是不合适的,每个月上映的电影数量跟月份并不是简单的线性关系,这样就会出现欠拟合的现象。
解决这个问题的选项包括:
选择一个更强大的模型,带有更多参数
用更好的特征训练学习算法(特征工程)
减小对模型的限制
-
过拟合训练数据
相反,过拟合就是指由于训练数据包含抽样误差,训练时,复杂的模型将抽样误差也考虑在内,将抽样误差也进行了很好的拟合。
具体表现就是最终模型在训练集上效果好;在测试集上效果差。模型泛化能力弱。
用数学老师的一句话描述过拟合:
同样的题目教了无数遍,我换两个数字你们就不会做了??
可能的解决方案有:
简化模型,可以通过选择一个参数更少的模型(比如使用线性模型,而不是高阶多项式模型)、减少训练数据的属性数、或限制一下模型
收集更多的训练数据
减小训练数据的噪声(比如,修改数据错误和去除异常值)
4. 测试和确认
讲了这么多,那如何判断一个算法模型得出的结论是好还是坏呢?一种比较常见的方法是将数据分为训练集和测试集两个部分。
用训练集训练算法模型,再用测试集测试准确率。
还是以初中生学习作为例子,一本习题册分为10个部分,前8个部分作为学习部分,我们边做边对答案,然后总结解题的思路。后面2个部分作为测试,测试完之后的得分情况就代表自己对这种题目的掌握程度。
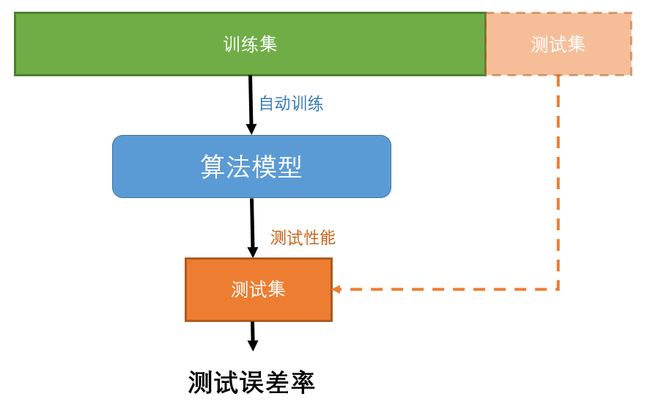
因此,评估一个模型很简单:只要使用测试集。现在假设你在两个模型之间犹豫不决(比如一个线性模型和一个多项式模型):如何做决定呢?一种方法是两个都训练,然后比较在测试集上的效果。
我们通过修改一些超参数(不能通过学习来自动调整的参数)来降低误差,但是这种方法在实际中的应用效果却并没有想象的那么好。
这是因为超参数都是基于测试集来调整的,就相当于把测试集当成了训练超参数的数据。这样对于新的数据效果不一定会更好。
解决办法是:
保留一个数据集作为验证集,在这些步骤做完之后再进行最终的验证。
类比到学习问题上就是对一本习题集进行反复学习,然后做很多的模拟测试来适应考试状态,最后进行一次考试,这样才能检测出你真实的学习水平。
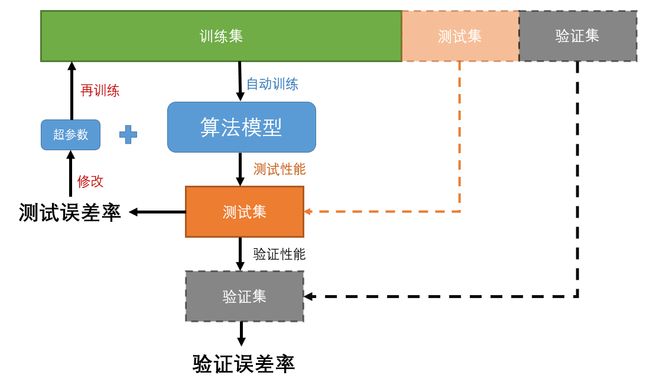
但是这种方法会减少训练集,有一种比较常用的方法是交叉验证法,这里不过多赘述,在后面的章节会学习到。
交叉验证法:训练集分成互补的子集,每个模型用不同的子集训练,再用剩下的子集验证。一旦确定模型类型和超参数,最终的模型使用这些超参数和全部的训练集进行训练,用测试集得到推广误差率。
最后解决一个许多新手都有的疑惑,机器学习发展了这么多年,有没有一种万能的算法能解决所有的学习问题?
这就好比问数学老师,有没有一种方法能解题思路能解开所有的数学题目?
答案是不能。在1996年的一篇著名论文中,David Wolpert证明没有一种机器学习算法能解决所有的问题,这称作没有免费午餐(NFL)公理。
对于一些数据集,最佳模型是线性模型,而对其它数据集则是神经网络。没有一个模型可以保证效果更好(如这个公理的名字所示)。所以机器学习首先面临的问题是:
到底选择哪一种机器学习算法得到的效果更佳?
欢迎来我的博客留言讨论,我的博客主页:LeonG的博客
本文参考自:《Hands-On Machine Learning with Scikit-Learn & TensorFlow机器学习实用指南》,感谢中文AI社区ApacheCN提供翻译。
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。