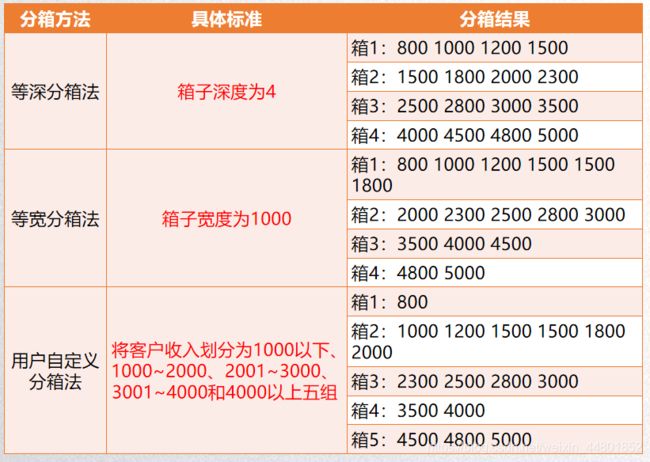
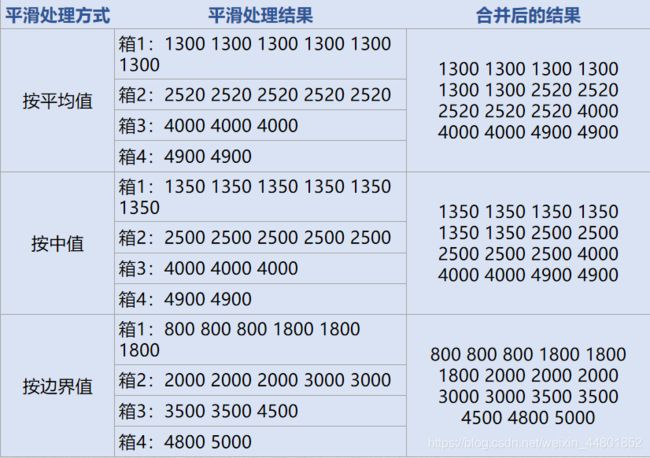
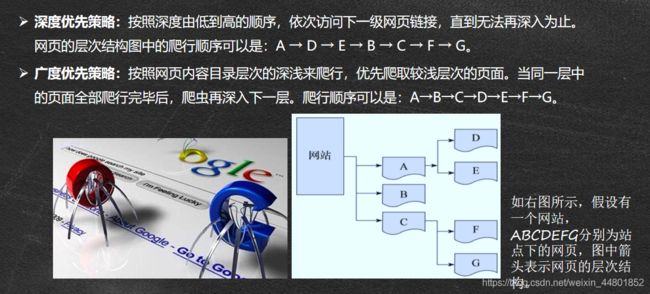
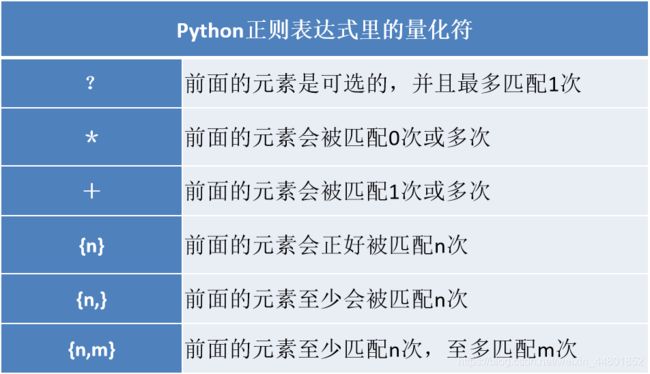
- python中plus_Python token.PLUS属性代码示例
#需要导入模块:importtoken[as别名]#或者:fromtokenimportPLUS[as别名]deftest_exact_type(self):self.assertExactTypeEqual('()',token.LPAR,token.RPAR)self.assertExactTypeEqual('[]',token.LSQB,token.RSQB)self.assertExac
- 三网BGP服务器——CDN加速的底层基石
群联云防护小杜
安全问题汇总服务器python运维游戏安全自动化网络
为什么跨网访问会成为业务性能杀手?场景痛点当电信用户访问联通机房的资源时,平均延迟高达120ms以上,而跨网丢包率可达15%。传统单线机房导致30%的用户体验直接下降。BGP协议的核心价值#三网路由优化模拟器(Python3)importrandomdefbgp_route_selection(user_isp,cdn_nodes):#用户ISP:1=电信2=移动3=联通#节点示例:{'node1
- Python入门--day04--Python 推导式、常见语句和内置函数总结
the time zips by
#Python基础python开发语言
文章目录前言一、推导式1.列表推导式2.集合推导式3.字典推导式4.生成器推导式二、常见语句1赋值语句2.控制语句2.1条件语句2.1.1if-elif-else2.1.2match-case2.2循环语句2.2.1for循环2.2.2while循环2.3循环控制语句2.3.1break2.3.2continue2.3.3pass3.range语句3.函数定义语句4.异常处理语句4.1try-ex
- 中国银联豪掷1亿采购海光C86架构服务器
信创新态势
海光芯片C86国产芯片海光信息
近日,中国银联国产服务器采购大单正式敲定,基于海光C86架构的服务器产品中标,项目金额超过1亿元。接下来,C86服务器将用于支撑中国银联的虚拟化、大数据、人工智能、研发测试等技术场景,进一步提升其业务处理能力、用户服务效率和信息安全水平。作为我国重要的银行卡组织和金融基础设施,中国银联在全球183个国家和地区设有银联受理网络,境内外成员机构超过2600家,是世界三大银行卡品牌之一。此次中国银联发力
- windows exe爬虫:exe抓包
程序猿阿三
爬虫项目实战exe抓包
不论任何爬虫,抓包是获取数据最直接和最方便的方式,这章节我们一起看一下windowsexe是如何拦截数据的。用mitmproxy/Charles/Fiddler或Wireshark拦截它的HTTP/HTTPS/TCP流量。如果是HTTPS,安装并信任代理的根证书。由于exe大部分可能走的是自定义应用层协议。在不知情所拦截应用使用的流量时,所以建议用Wireshark。本文利用python代码,实现
- PythonDay01
这里写目录标题一、注释1、单行注释2、多行注释二、定义变量1、要求2、代码三、关键字四、print函数五、基本数据类型1、整型2、字符串类型3、小数类型4、布尔类型5、空类型六、类型之间的相互转换1、从字符串转成int类型2、字符串转换成浮点型3、float转换成int4、丢失精度时不会去做四舍五入5、布尔类型七、字符串的常见操作1、split切分2、strip去除字符串两边的隐藏字符3、字符串的
- Python Day9
@浙大疏锦行PythonDay9.内容:热力图的绘制enumerate()方法子图的绘制代码:list_nums=[1,2,3,4,5,6]forindex,valinenumerate(list_nums):print(f"index={index},val={val}")forvalinlist_nums:print(f"val={val}")importpandasaspdimportmat
- 【医学影像】无痛安装mamba
周树皮
医学影像python
去年编辑的一个帖子。摆了一段时间后重新回归,发送一下作为状态分界线。很癫狂的体验,man,whatcanisay!issue查看我的狗急跳墙状态1.确定版本cudanvcc-Vpythonpython--versiontorchpipshowtorch2.下载对应版本wheelcausal-conv1d:https://github.com/Dao-AILab/causal-conv1d/rele
- macd的python代码同花顺_同花顺最牛MACD副图源码
再来一碗饭
DIFF:EMA(CLOSE,6)-EMA(CLOSE,16),ColorFFFF26;DEA:EMA(DIFF,5),Color8A15FF;MACD:=2*(DIFF-DEA);对DIFF:0-(EMA(CLOSE,6)-EMA(CLOSE,16));对DEA:0-(EMA(DIFF,5));对称:0-(2*(DIFF-DEA)),STICK,ColorFF6060,LINETHICK1;{D
- Mamba项目用户指南:高效管理Python环境的利器
左松钦Travis
Mamba项目用户指南:高效管理Python环境的利器mambaTheFastCross-PlatformPackageManager项目地址:https://gitcode.com/gh_mirrors/mam/mamba什么是Mamba?Mamba是一个基于Conda的CLI工具,专为高效管理Python环境而设计。它继承了Conda的所有优点,同时在性能上进行了显著优化,特别是在解决依赖关系
- 【亲测免费】 Mamba:快速跨平台的包管理器
林梦雅
Mamba:快速跨平台的包管理器项目基础介绍和主要编程语言Mamba是一个用C++重新实现的Conda包管理器。它旨在提供比传统Conda更快的包管理和依赖解析速度。Mamba的核心部分使用C++编写,以确保高效性和性能。同时,Mamba也使用了Python和其他一些辅助语言来实现其功能。项目核心功能Mamba的核心功能包括:快速依赖解析:利用libsolv库进行高效的依赖解析,这是RedHat、
- 全面探索Kafka:架构、应用与流处理
Kafka:企业级消息系统与流处理平台的深度解析ApacheKafka作为分布式流处理平台,广泛应用于大数据处理和实时分析领域。本文将基于其官方文档,详细探讨Kafka的核心功能、应用场景以及如何进行有效管理。背景简介Kafka作为高吞吐量的消息系统,支持企业级的发布-订阅模式。它能够处理大量实时数据,并支持高并发读写操作。本文将依据Kafka官方文档的内容,逐层深入,从入门到高级应用,帮助读者全
- Flink时间窗口详解
bxlj_jcj
Flinkflink大数据
一、引言在大数据流处理的领域中,Flink的时间窗口是一项极为关键的技术,想象一下,你要统计一个电商网站每小时的订单数量。由于订单数据是持续不断产生的,这就形成了一个无界数据流。如果没有时间窗口的概念,你就需要处理无穷无尽的数据,难以进行有效的统计分析。而时间窗口的作用,就是将这无界的数据流按照时间维度切割成一个个有限的“数据块”,方便我们对这些数据进行处理和分析。比如,我们可以定义一个1小时的时
- 探索实时流处理的未来:Kafka Streams 深度指南
秋或依
探索实时流处理的未来:KafkaStreams深度指南项目介绍欢迎进入KafkaStreams:实时流处理的世界!这不仅仅是一本书,更是一个通往流处理领域深层奥秘的门户。由PrashantPandey编著,这本书以ApacheKafka2.1中的KafkaStreams库为核心,为读者铺就了一条从理解基础概念到熟练掌握KafkaStreams编程的路径。无论是软件工程师、数据架构师,还是对大数据处
- Elasticsearch搜索引擎存储:从原理到实践的全景解析
Python×CATIA工业智造
搜索引擎elasticsearch大数据
引言在大数据时代,数据规模呈指数级增长,传统数据库的模糊查询、实时分析能力逐渐成为瓶颈。Elasticsearch(简称ES)凭借其分布式架构、实时搜索和灵活的数据分析能力,成为企业级搜索与存储的核心引擎。截至2025年,ES在全球日志分析、电商搜索、实时监控等场景的市场占有率超过60%。本文将从存储架构、核心技术、应用场景及优化策略四个维度,深入解析Elasticsearch的设计哲学与实践价值
- LeetCode第317题_离建筑物最近的距离
@蓝莓果粒茶
算法leetcodelinux算法c#学习pythonc++
LeetCode第317题:离建筑物最近的距离文章摘要本文详细解析LeetCode第317题"离建筑物最近的距离",这是一道图论和广度优先搜索的问题。文章提供了基于多源BFS的解法,包含C#、Python、C++三种语言实现,配有详细的算法分析和性能对比。适合想要提升图论算法能力的程序员。核心知识点:广度优先搜索、图论、矩阵遍历难度等级:困难推荐人群:具有图论基础,想要提升算法能力的程序员题目描述
- 学习笔记(33):matplotlib绘制简单图表-绘制混淆矩阵热图
宁儿数据安全
#机器学习学习笔记matplotlib
学习笔记(33):matplotlib绘制简单图表-绘制混淆矩阵热图一、绘制混淆矩阵热图代码解析1.1、导入必要的库importmatplotlib.pyplotaspltfromsklearn.metricsimportconfusion_matriximportseabornassnsmatplotlib.pyplot:Python中最常用的绘图库,用于创建各种图表confusion_matr
- Python 实战:构建本地多线程定时任务调度器
xiaocainiao881
python开发语言
引言在企业自动化流程、数据周期更新、本地脚本执行等场景中,定时任务调度器是不可或缺的一类工具。尽管Linux有crontab,Windows有任务计划,但它们不够灵活,缺乏图形界面,不适合动态启停、可视化控制等需求。本文将带你实现一个本地运行的多线程定时任务调度器,具备以下功能:一、项目功能说明1.1功能亮点多任务并行运行(非阻塞)每个任务支持独立间隔设置支持任务启动/停止/删除/修改支持即时日志
- 【python实战】不玩微博,一封邮件就能知道实时热榜,天秀吃瓜
一条coding
从实战学python人工智能pythonlinux爬虫
❤️欢迎订阅《从实战学python》专栏,用python实现办公自动化、数据可视化、人工智能等各个方向的实战案例,有趣又有用!❤️更多精品专栏简介点这里有的人金玉其表败絮其中,有的人却若彩虹般绚烂,怦然心动前言哈喽,大家好,我是一条。在生活中我是一个不太喜欢逛娱乐平台的人,抖音、快手、微博我手机里都没装,甚至微信朋友圈都不看,但是自从开始写博客,有些热度不得不蹭。所以就有了这样一个需求,能不能让微
- Python爬虫实战:基于最新技术的定时签到系统开发全解析
Python爬虫项目
2025年爬虫实战项目python爬虫开发语言人工智能自动化知识图谱
摘要本文详细介绍了如何使用Python开发一个功能完善的定时签到爬虫系统。文章从爬虫基础知识讲起,逐步深入到高级技巧,包括异步请求处理、浏览器自动化、验证码破解、分布式架构等最新技术。我们将通过一个完整的定时签到项目案例,展示如何构建一个稳定、高效且具有良好扩展性的爬虫系统。文中提供了大量可运行的代码示例,涵盖requests、aiohttp、selenium、playwright等多种技术方案,
- Python爬虫实战:使用最新技术爬取新华网新闻数据
Python爬虫项目
2025年爬虫实战项目python爬虫开发语言scrapy音视频
一、前言在当今信息爆炸的时代,网络爬虫技术已经成为获取互联网数据的重要手段。作为国内权威新闻媒体,新华网每天发布大量高质量的新闻内容,这些数据对于舆情分析、市场研究、自然语言处理等领域具有重要价值。本文将详细介绍如何使用Python最新技术构建一个高效、稳定的新华网新闻爬虫系统。二、爬虫技术选型2.1技术栈选择在构建新华网爬虫时,我们选择了以下技术栈:请求库:httpx(支持HTTP/2,异步请求
- Mac 电脑crontab执行定时任务【Python 实战】
qifengle2014
LinuxDockerJavaPython技术分享合集macospython开发语言
1、crontab-e编辑定时任务列表crontab-e查看当前定时任务列表,长按i编辑,编辑完之后按esc退出编辑,然后输入:wq保存并提出。如下:(base)charles@zl~%crontab-e5815***/Library/Frameworks/Python.framework/Versions/3.8/bin/python3/Users/charles/Documents/first
- python-pandas数据分析+案例分析
文章目录前言一、汽车销售数据可视化分析1.各年度汽车总销量及环比,各车类、级别车辆销量及环比2.车辆销售规模及环比、不同价位车销量及环比3.各车系、厂商、品牌车销量及环比,市占率及变化趋势4.品牌、车类、车型、级别的各top销量二、地质灾害航空公司客户价值分析1.原始数据存在少量的缺失值和异常值前言一、汽车销售数据可视化分析1.各年度汽车总销量及环比,各车类、级别车辆销量及环比importnump
- Windows系统python安装教程
I`m 程序媛
windowspython开发语言
一、准备工作访问Python官网:打开浏览器,进入Python官网。选择安装包:在官网的下载页面,根据自己的操作系统位数(32位或64位)选择对应的安装包。大多数现代电脑都是64位的,因此选择64-bit的安装包。建议选择“StableReleases”(稳定发布版本),这些版本已经经过测试,相对稳定。二、下载与安装下载Python安装包:点击选定的安装包链接,下载Python的安装程序。运行安装
- 【Kafka专栏 13】Kafka的消息确认机制:不是所有的“收到”都叫“确认”!
作者名称:夏之以寒作者简介:专注于Java和大数据领域,致力于探索技术的边界,分享前沿的实践和洞见文章专栏:夏之以寒-kafka专栏专栏介绍:本专栏旨在以浅显易懂的方式介绍Kafka的基本概念、核心组件和使用场景,一步步构建起消息队列和流处理的知识体系,无论是对分布式系统感兴趣,还是准备在大数据领域迈出第一步,本专栏都提供所需的一切资源、指导,以及相关面试题,立刻免费订阅,开启Kafka学习之旅!
- Ubuntu系统下pip install的accelerate包没有安装至conda环境下,而是错误放入.local文件中
服务器上跑模型时莫名报了一个没有‘torch’包的错误Traceback(mostrecentcalllast):File"/home/ubuntu/.local/bin/accelerate",line5,infromaccelerate.commands.accelerate_cliimportmainFile"/home/ubuntu/.local/lib/python3.10/site-p
- 数据分析案例-电脑笔记本价格数据可视化分析3
艾派森
数据分析信息可视化python数据分析数据挖掘电脑
♂️个人主页:@艾派森的个人主页✍作者简介:Python学习者希望大家多多支持,我们一起进步!如果文章对你有帮助的话,欢迎评论点赞收藏加关注+目录1.项目背景2.数据集介绍3.技术工具
- Python Code Acceleration(Python代码加速)
李伯爵的指间沙
Python
对于Python的代码执行效率较低的问题,参考博客:https://developer.51cto.com/art/201809/583695.htm进行相应的测试。参考代码如下:fromnumbaimportjitimporttimedeffoo(x,y):tt=time.time()s=0foriinrange(x,y):s+=iprint('Timeused:{}sec'.format(ti
- 2023年最新Python安装详细教程_python自定义安装
2401_89213215
python开发语言
1、选择python的稳定发布版本StableReleases点击进入windows操作系统对应的页面,显示python安装版本,这些python安装版本适合windows操作系统。图3-1python稳定与预发布版本图3-1左边是稳定发布版本StableReleases,右边是预发布版本Pre-releases,前者是经过测试,相对完善、稳定的版本,后者还处于测试中,可能不完善,因此,我们下载左
- 用Python做数据分析之数据统计
学掌门
Python数据分析大数据python数据分析人工智能
接下来说说数据统计部分,这里主要介绍数据采样,标准差,协方差和相关系数的使用方法。1、数据采样Excel的数据分析功能中提供了数据抽样的功能,如下图所示。Python通过sample函数完成数据采样。2、数据抽样Sample是进行数据采样的函数,设置n的数量就可以了。函数自动返回参与的结果。1#简单的数据采样2df_inner.sample(n=3)3、简单随机采样Weights参数是采样的权重,
- Enum 枚举
120153216
enum枚举
原文地址:http://www.cnblogs.com/Kavlez/p/4268601.html Enumeration
于Java 1.5增加的enum type...enum type是由一组固定的常量组成的类型,比如四个季节、扑克花色。在出现enum type之前,通常用一组int常量表示枚举类型。比如这样:
public static final int APPLE_FUJI = 0
- Java8简明教程
bijian1013
javajdk1.8
Java 8已于2014年3月18日正式发布了,新版本带来了诸多改进,包括Lambda表达式、Streams、日期时间API等等。本文就带你领略Java 8的全新特性。
一.允许在接口中有默认方法实现
Java 8 允许我们使用default关键字,为接口声明添
- Oracle表维护 快速备份删除数据
cuisuqiang
oracle索引快速备份删除
我知道oracle表分区,不过那是数据库设计阶段的事情,目前是远水解不了近渴。
当前的数据库表,要求保留一个月数据,且表存在大量录入更新,不存在程序删除。
为了解决频繁查询和更新的瓶颈,我在oracle内根据需要创建了索引。但是随着数据量的增加,一个半月数据就要超千万,此时就算有索引,对高并发的查询和更新来说,让然有所拖累。
为了解决这个问题,我一般一个月会进行一次数据库维护,主要工作就是备
- java多态内存分析
麦田的设计者
java内存分析多态原理接口和抽象类
“ 时针如果可以回头,熟悉那张脸,重温嬉戏这乐园,墙壁的松脱涂鸦已经褪色才明白存在的价值归于记忆。街角小店尚存在吗?这大时代会不会牵挂,过去现在花开怎么会等待。
但有种意外不管痛不痛都有伤害,光阴远远离开,那笑声徘徊与脑海。但这一秒可笑不再可爱,当天心
- Xshell实现Windows上传文件到Linux主机
被触发
windows
经常有这样的需求,我们在Windows下载的软件包,如何上传到远程Linux主机上?还有如何从Linux主机下载软件包到Windows下;之前我的做法现在看来好笨好繁琐,不过也达到了目的,笨人有本方法嘛;
我是怎么操作的:
1、打开一台本地Linux虚拟机,使用mount 挂载Windows的共享文件夹到Linux上,然后拷贝数据到Linux虚拟机里面;(经常第一步都不顺利,无法挂载Windo
- 类的加载ClassLoader
肆无忌惮_
ClassLoader
类加载器ClassLoader是用来将java的类加载到虚拟机中,类加载器负责读取class字节文件到内存中,并将它转为Class的对象(类对象),通过此实例的 newInstance()方法就可以创建出该类的一个对象。
其中重要的方法为findClass(String name)。
如何写一个自己的类加载器呢?
首先写一个便于测试的类Student
- html5写的玫瑰花
知了ing
html5
<html>
<head>
<title>I Love You!</title>
<meta charset="utf-8" />
</head>
<body>
<canvas id="c"></canvas>
- google的ConcurrentLinkedHashmap源代码解析
矮蛋蛋
LRU
原文地址:
http://janeky.iteye.com/blog/1534352
简述
ConcurrentLinkedHashMap 是google团队提供的一个容器。它有什么用呢?其实它本身是对
ConcurrentHashMap的封装,可以用来实现一个基于LRU策略的缓存。详细介绍可以参见
http://code.google.com/p/concurrentlinke
- webservice获取访问服务的ip地址
alleni123
webservice
1. 首先注入javax.xml.ws.WebServiceContext,
@Resource
private WebServiceContext context;
2. 在方法中获取交换请求的对象。
javax.xml.ws.handler.MessageContext mc=context.getMessageContext();
com.sun.net.http
- 菜鸟的java基础提升之道——————>是否值得拥有
百合不是茶
1,c++,java是面向对象编程的语言,将万事万物都看成是对象;java做一件事情关注的是人物,java是c++继承过来的,java没有直接更改地址的权限但是可以通过引用来传值操作地址,java也没有c++中繁琐的操作,java以其优越的可移植型,平台的安全型,高效性赢得了广泛的认同,全世界越来越多的人去学习java,我也是其中的一员
java组成:
- 通过修改Linux服务自动启动指定应用程序
bijian1013
linux
Linux中修改系统服务的命令是chkconfig (check config),命令的详细解释如下: chkconfig
功能说明:检查,设置系统的各种服务。
语 法:chkconfig [ -- add][ -- del][ -- list][系统服务] 或 chkconfig [ -- level <</SPAN>
- spring拦截器的一个简单实例
bijian1013
javaspring拦截器Interceptor
Purview接口
package aop;
public interface Purview {
void checkLogin();
}
Purview接口的实现类PurviesImpl.java
package aop;
public class PurviewImpl implements Purview {
public void check
- [Velocity二]自定义Velocity指令
bit1129
velocity
什么是Velocity指令
在Velocity中,#set,#if, #foreach, #elseif, #parse等,以#开头的称之为指令,Velocity内置的这些指令可以用来做赋值,条件判断,循环控制等脚本语言必备的逻辑控制等语句,Velocity的指令是可扩展的,即用户可以根据实际的需要自定义Velocity指令
自定义指令(Directive)的一般步骤
&nbs
- 【Hive十】Programming Hive学习笔记
bit1129
programming
第二章 Getting Started
1.Hive最大的局限性是什么?一是不支持行级别的增删改(insert, delete, update)二是查询性能非常差(基于Hadoop MapReduce),不适合延迟小的交互式任务三是不支持事务2. Hive MetaStore是干什么的?Hive persists table schemas and other system metadata.
- nginx有选择性进行限制
ronin47
nginx 动静 限制
http {
limit_conn_zone $binary_remote_addr zone=addr:10m;
limit_req_zone $binary_remote_addr zone=one:10m rate=5r/s;...
server {...
location ~.*\.(gif|png|css|js|icon)$ {
- java-4.-在二元树中找出和为某一值的所有路径 .
bylijinnan
java
/*
* 0.use a TwoWayLinkedList to store the path.when the node can't be path,you should/can delete it.
* 1.curSum==exceptedSum:if the lastNode is TreeNode,printPath();delete the node otherwise
- Netty学习笔记
bylijinnan
javanetty
本文是阅读以下两篇文章时:
http://seeallhearall.blogspot.com/2012/05/netty-tutorial-part-1-introduction-to.html
http://seeallhearall.blogspot.com/2012/06/netty-tutorial-part-15-on-channel.html
我的一些笔记
===
- js获取项目路径
cngolon
js
//js获取项目根路径,如: http://localhost:8083/uimcardprj
function getRootPath(){
//获取当前网址,如: http://localhost:8083/uimcardprj/share/meun.jsp
var curWwwPath=window.document.locati
- oracle 的性能优化
cuishikuan
oracleSQL Server
在网上搜索了一些Oracle性能优化的文章,为了更加深层次的巩固[边写边记],也为了可以随时查看,所以发表这篇文章。
1.ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前,那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾。(这点本人曾经做过实例验证过,的确如此哦!
- Shell变量和数组使用详解
daizj
linuxshell变量数组
Shell 变量
定义变量时,变量名不加美元符号($,PHP语言中变量需要),如:
your_name="w3cschool.cc"
注意,变量名和等号之间不能有空格,这可能和你熟悉的所有编程语言都不一样。同时,变量名的命名须遵循如下规则:
首个字符必须为字母(a-z,A-Z)。
中间不能有空格,可以使用下划线(_)。
不能使用标点符号。
不能使用ba
- 编程中的一些概念,KISS、DRY、MVC、OOP、REST
dcj3sjt126com
REST
KISS、DRY、MVC、OOP、REST (1)KISS是指Keep It Simple,Stupid(摘自wikipedia),指设计时要坚持简约原则,避免不必要的复杂化。 (2)DRY是指Don't Repeat Yourself(摘自wikipedia),特指在程序设计以及计算中避免重复代码,因为这样会降低灵活性、简洁性,并且可能导致代码之间的矛盾。 (3)OOP 即Object-Orie
- [Android]设置Activity为全屏显示的两种方法
dcj3sjt126com
Activity
1. 方法1:AndroidManifest.xml 里,Activity的 android:theme 指定为" @android:style/Theme.NoTitleBar.Fullscreen" 示例: <application
- solrcloud 部署方式比较
eksliang
solrCloud
solrcloud 的部署其实有两种方式可选,那么我们在实践开发中应该怎样选择呢? 第一种:当启动solr服务器时,内嵌的启动一个Zookeeper服务器,然后将这些内嵌的Zookeeper服务器组成一个集群。 第二种:将Zookeeper服务器独立的配置一个集群,然后将solr交给Zookeeper进行管理
谈谈第一种:每启动一个solr服务器就内嵌的启动一个Zoo
- Java synchronized关键字详解
gqdy365
synchronized
转载自:http://www.cnblogs.com/mengdd/archive/2013/02/16/2913806.html
多线程的同步机制对资源进行加锁,使得在同一个时间,只有一个线程可以进行操作,同步用以解决多个线程同时访问时可能出现的问题。
同步机制可以使用synchronized关键字实现。
当synchronized关键字修饰一个方法的时候,该方法叫做同步方法。
当s
- js实现登录时记住用户名
hw1287789687
记住我记住密码cookie记住用户名记住账号
在页面中如何获取cookie值呢?
如果是JSP的话,可以通过servlet的对象request 获取cookie,可以
参考:http://hw1287789687.iteye.com/blog/2050040
如果要求登录页面是html呢?html页面中如何获取cookie呢?
直接上代码了
页面:loginInput.html
代码:
<!DOCTYPE html PUB
- 开发者必备的 Chrome 扩展
justjavac
chrome
Firebug:不用多介绍了吧https://chrome.google.com/webstore/detail/bmagokdooijbeehmkpknfglimnifench
ChromeSnifferPlus:Chrome 探测器,可以探测正在使用的开源软件或者 js 类库https://chrome.google.com/webstore/detail/chrome-sniffer-pl
- 算法机试题
李亚飞
java算法机试题
在面试机试时,遇到一个算法题,当时没能写出来,最后是同学帮忙解决的。
这道题大致意思是:输入一个数,比如4,。这时会输出:
&n
- 正确配置Linux系统ulimit值
字符串
ulimit
在Linux下面部 署应用的时候,有时候会遇上Socket/File: Can’t open so many files的问题;这个值也会影响服务器的最大并发数,其实Linux是有文件句柄限制的,而且Linux默认不是很高,一般都是1024,生产服务器用 其实很容易就达到这个数量。下面说的是,如何通过正解配置来改正这个系统默认值。因为这个问题是我配置Nginx+php5时遇到了,所以我将这篇归纳进
- hibernate调用返回游标的存储过程
Supanccy2013
javaDAOoracleHibernatejdbc
注:原创作品,转载请注明出处。
上篇博文介绍的是hibernate调用返回单值的存储过程,本片博文说的是hibernate调用返回游标的存储过程。
此此扁博文的存储过程的功能相当于是jdbc调用select 的作用。
1,创建oracle中的包,并在该包中创建的游标类型。
---创建oracle的程
- Spring 4.2新特性-更简单的Application Event
wiselyman
application
1.1 Application Event
Spring 4.1的写法请参考10点睛Spring4.1-Application Event
请对比10点睛Spring4.1-Application Event
使用一个@EventListener取代了实现ApplicationListener接口,使耦合度降低;
1.2 示例
包依赖
<p