大家好,我是咔咔 不期速成,日拱一卒
通过上期文章知道了在MySQL中存在三种join的算法,分别为NLJ、BNLJ、BNL,总结来说分为索引嵌套循环连接、缓存块嵌套循环连接、粗暴循环连接。
另外还知道了一个新的概念join_buffer,作用就是把关联表的数据全部读入join_buffer中,然后从join_buffer中一行一行的拿数据去被驱动表中查询。由于是在内存中获取数据,因此效率还是会有所提升。
同时在上期文章中遇到了一个陌生的概念hash_join,在上期中没有详细说明,本期会进行详述。

一、Multi-Range Read优化
在介绍本期主题时先来了解一个知识点Multi-Range Read,主要的作用是尽量让顺序读盘,在任何领域只要是有顺序的都会有一定的性能提升。
比如MySQL的索引,现在你应该知道索引天生具有有序性从而避免服务器对数据再次排序和建立临时表的问题。
接下来使用一个案例来实操一下这个优化是怎么做的
创建join_test1、join_test2两张表
CREATE TABLE `join_test1` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`a` int(11) unsigned NOT NULL,
`b` int(11) unsigned NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
CREATE TABLE `join_test2` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`a` int(11) unsigned NOT NULL,
`b` int(11) unsigned NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;给两张表添加一些数据,用于案例演示
drop procedure idata;
delimiter ;;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=1000)do
insert into join_test1 (a,b) values ( 1001-i, i);
set i=i+1;
end while;
set i=1;
while(i<=1000000)do
insert into join_test2 (a,b) values (i, i);
set i=i+1;
end while;
end;;
delimiter ;
call idata();表join_test1的字段a上存在索引的,那么在查询时就会使用该索引。
执行流程大致为获取到字段a所有的值,然后根据a的值一行一行的进行回表到主键索引上获取数据
现在的情况是如果随着a的值递增顺序查询的话,id的值就会变相的为倒叙,虽然看起来是根据主键ID连续倒叙的,但在生产环境下肯定不是连续的,就会造成随机访问,那就肯定会造成性能变差。
为什么说随机访问会影响性能?
MySQL的索引天生具有有序性,同时MySQL也同样借鉴了局部性原理,局部性原理是数据和程序都默认有聚集成群的倾向,在访问到一行数据后,会有极大可能性再次访问到这条数据或这条数据相邻的数据。
现在你应该知道了MySQL在读取数据时并不是只读查询的数据,默认会读取16kb的数据,这个值是根据innodb_page_size决定的。
因此顺序查询是非常快的,是因为不用每次都通过执行器获取数据,而是直接在内存中获取,但若访问变为随机性就会每次通过执行器进行获取数据,所以这才是性能变差的原因。
MRR的作用
说了这么多现在你应该知道了MRR的作用就是把查询变为主键ID的递增查询,对磁盘的读尽可能的接近顺序读,就可以提升性能。
因此,执行语句的执行流程就会变成这样
- 先根据索a,获取到所有满足条件的数据,并且将主键id的值放入read_rnd_buffer中
- 在read_rnd_buffer中把id的值进行正序排序
- 再根据排序后得主键ID值,依次到主键索引上获取数据,并返回结果集
如何开启read_rnd_buffer
read_rnd_buffer的大小是由read_rnd_buffer_size参数控制的,默认值为256kb,但你要知道的是对于MRR的优化在优化器的判断策略中会更倾向于不使用,如果要使用则需要进行配置修改即可。
set optimizer_switch="mrr_cost_based=off"mrr默认值
read_rnd_buffer存不下怎么办?
回忆下在上期中提到的join_buffer不够用是怎么处理的,会把上次读取的数据从buffer中清空,再放入剩下的数据,在MySQL中对于存储结果集的buffer内存不够情况下大多数都是这么处理的。
使用了read_rnd_buffer后的SQL执行流程就变成了这样

explain的结果显示

注意点
假设现在把查询范围扩大,看一下会有什么变化

可以看到当把范围扩大至接近全表数据时,会不再使用索引a从而进行了全表扫描,也就无法再使用mrr优化了
因此想要使用MRR进行提升性能是基于两个非常重要的点,一个是在索引上进行范围查询,另一个就是必须能使用上索引,当然这个索引要是范围查询的列
二、Nested-Loop Join优化
快一个月没更文了,对Nested-Loop Join的算法还能回忆多少,SQL的执行流程大致如下:

- 从join_test1表读取一行数据R
- 从R中取id字段到表join_test2去查找索引a,并通过主键ID获取到满足的行
- 取出join_test2中满足条件的行,跟R组成一行
- 重复前三个步骤,直到表join_test1满足条件的数据扫描结束
NLJ算法的逻辑就是从驱动表取一行数据后就直接到被驱动表中做join操作,对于驱动表来说就变成了每次都匹配一个值,这时就不满足MRR优化的条件了。
通过上期文章,现在你应该知道了join_buffer在BNL算法中的作用,但在NLJ算法中并没有使用。
那想办法把驱动表的数据批量传给被驱动表进行join操作不就行了?
没错,MySQL团队在5.6版本引入了此方案,在驱动表中取出一部分数据,放到临时内存,这个临时内存就是上期的join_buffer。
那么执行流程图就会变成这样
这里需要注意没有把索引a在read_rnd_buffer中的流程画出来,如果不理解就到上文去看那副图哈!

上图中,我们依然查询了1000条数据,那么join_buffer就会存着1000条数据,如果存不下就会分段进行,直到执行结束。
对于NLJ算法的优化官方也给起来了一个名为Batched Key Access
BKA算法的启用
既然要使用MRR优化,那就要开启MRR,开启MRR的同时还要开启batched_key_access=on即可
set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';三、Block Nested-Loop Join算法优化
非常简单的优化就是在被驱动表上添加索引,这时BNL的算法就自然而然的变为BKA算法了
select * from t1 join t2 on (t1.b=t2.b) where t2.b>=1 and t2.b<=2000;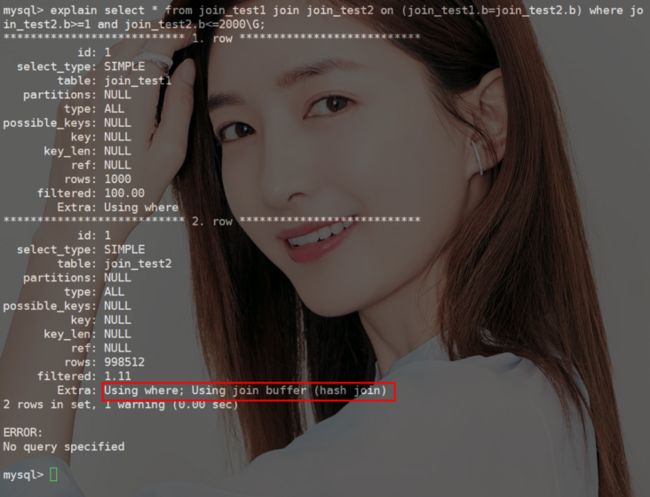
这条SQL在join_test2上只查询了2000行数据,如果你的MySQL机器对内存不那么看重的话直接给字段b加个索引即可。
反之,就需要另辟奇径了
再来复习下BNL算法的执行流程
- 取出join_test1的所有数据,存储join_buffer中
- 扫描join_test2用每行数据跟join_buffer中的数据进行对比,不满足跳过,满足存储结果集
由于被驱动表字段b是没有索引的,因此从join_buffer中读取出来的每条数据都要对join_test2进行全表扫描。
案例中join_test2表共100W数据,那么需要扫描的行数就是1000*100W = 10亿次,只需要2000条数据却要执行10亿次,这个性能可想而知。
这时,我们就可以使用奇径临时表来解决这个问题,实现思路大致如下
- 先把join_test2中满足条件的数据存放在临时表中tmp_join_test2中
- 此时临时表的数据只有条件范围的2000数据,因此是完全可以给字段b添加索引的
- 最后再让join_buffer跟tmp_join_test2做join操作
对应的SQL操作如下
create temporary table tmp_join_test2 (id int primary key, a int, b int, index(b))engine=innodb;
insert into tmp_join_test2 select * from join_test2 where b>=1 and b<=2000;
explain select * from join_test1 join tmp_join_test2 on (join_test1.b=tmp_join_test2.b);扫描行数
insert 是对表join_test2进行的全表扫描,此时扫描行数为100W行
join_test1进行全表扫描一次扫描行数为1000行
每次join操作是一条数据,共计1000次,扫描行数为1000行
使用了临时表后总体扫描行数从10亿次到了100W+2000次,执行查询的结果返回预计都不到一秒时间。
总结
不管是使用BKA算法还是使用临时表都有一个共同点,那就是让被驱动表上能用上索引来主动触发BKA算法,从而提升性能。
四、Hash join
大家还记得这幅图吧!上期文章中复现Block Nested-Loop Join算法呢!结果返回了一个hash_join,上期并没有说明。
因为hash_join算法是在MySQL8.0.18才有的

hash_join生效的前提是被驱动表join的字段没有索引,在MySQL8.0.18中还有一个约束就是条件对等,例如案例中的join_test1.b=tmp_join_test2.b
但在8.0.20中取消了条件对等的约束,并全面支持non-equi-join,Semijoin,Antijoin,Left outer join/Right outer join
其实hash_join算法的实现原理很简单
- 驱动表中的join字段进行计算hash值
- 在内存中创建一个hash_table,把驱动表所有的hash值存放进去
- 获取被驱动表中满足条件的数据,例如join_test2中的
select * from join_test2 where b>=1 and b<=20002000行数据 - 把这2000行数据,一行一行的跟hash_table中的数据进行对比,条件满足的数据作为结果集进行返回
可以看到hash_join算法的扫描行数跟临时表大差不差,那么为什么MySQL会默认使用hash_join这种算法呢?这个问题就要留给大家去深究了
五、总结
本期主要分享了NLJ、BNJ的算法优化
在这些优化中,hash_join在MySQL8.0.18中已经内置支持了,但低版本的还是默认为BKA算法
建议给被驱动表需要join字段加上索引,把BNL算法转为BKA或者hash_join算法
同时还给大家提供了一个临时表的方案,临时表在开发过程中是非常容易忽略的一个优化点,可以在适当的环境下学会使用临时表
推荐阅读
闯祸了,生成环境执行了DDL操作《死磕MySQL系列 十四》
坚持学习、坚持写作、坚持分享是咔咔从业以来所秉持的信念。愿文章在偌大的互联网上能给你带来一点帮助,我是咔咔,下期见。