前言
Redis是一种key-value型的数据库,key和value都是使用对象表示。执行SET message HelloWorld时,key是一个包含了字符串message的对象,value是一个包含了字符串HelloWorld的对象。本篇文章将对Redis中的对象类型进行学习。
正文
一. Redis中的五种对象简介
Redis中的对象叫做redisObject,其结构如下所示。
typedef struct redisObject {
//对象类型
unsigned type:4;
//对象底层使用的编码
unsigned encoding:4;
//对象最后一次被使用的时间
unsigned lru:22;
//引用计数
int refcount;
//指向对象底层数据结构的指针
void *ptr;
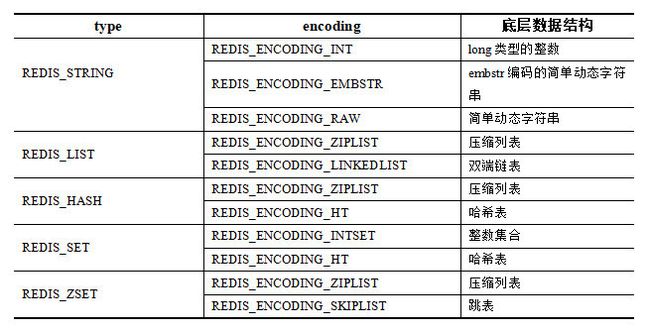
} robj;redisObject中的type字段表示当前对象的类型,type字段的取值共五种,表明Redis中共有五种对象,如下表所示。
| type | 说明 |
|---|---|
| REDIS_STRING | 字符串 |
| REDIS_LIST | 列表 |
| REDIS_HASH | 哈希 |
| REDIS_SET | 集合 |
| REDIS_ZSET | 有序集合 |
每种类型的Redis对象在不同情况下会由不同的底层数据结构实现。Redis对象底层数据结构共八种,如下表所示。
| encoding | 说明 |
|---|---|
| REDIS_ENCODING_INT | long类型的整数 |
| REDIS_ENCODING_EMBSTR | embstr编码的简单动态字符串 |
| REDIS_ENCODING_RAW | raw编码的简单动态字符串 |
| REDIS_ENCODING_HT | 字典 |
| REDIS_ENCODING_LINKEDLIST | 双端链表 |
| REDIS_ENCODING_ZIPLIST | 压缩列表 |
| REDIS_ENCODING_INTSET | 整数集合 |
| REDIS_ENCODING_SKIPLIST | 跳表 |
type和encoding的对应关系可以由下表表示。
二. 字符串对象
字符串对象与底层数据结构对应关系如下。
- 如果一个字符串内容可以转换为long类型,则该字符串对象的底层数据结构为long类型的整数;
- 如果字符串不能转换为long类型,并且字符串长度小于等于44字节,则该字符串对象的底层数据结构为embstr编码的简单动态字符串;
- 如果字符串长度大于等于45字节,则该字符串对象的底层数据结构为raw编码的简单动态字符串。
embstr编码在分配内存时只需要分配一次,在释放内存时也只需要释放一次,与之作为对比的raw需要两次。同时embstr编码的字符串使用连续内存,可以规避伪共享的发生从而可以更好的利用缓存优势。
三. 列表对象
列表对象与底层数据结构对应关系如下。
- 列表对象存储的元素长度小于64字节,元素个数小于512个,则该列表对象底层数据结构使用压缩列表;
- 其它情况,该列表对象底层数据结构使用双端链表。
下面对压缩列表进行分析。压缩列表是一种内存紧凑型的数据结构,由于使用连续的内存空间,可以规避伪共享的发生从而可以更好的利用缓存优势,压缩列表在元素长度不大或者元素个数不多时,会被列表对象采用为底层数据结构。压缩列表的示意图可以表示如下。
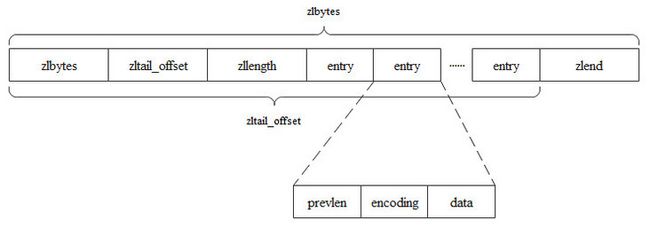
struct ziplist {
//整个压缩列表占用字节数
int32 zlbytes;
//最后一个entry距离压缩列表起始位置的字节数
int32 zltail_offset;
//entry个数
int16 zllength;
//entry数组
T[] entries;
//压缩列表的结束标志,0xFF
int8 zlend;
} 借助压缩列表的zlbytes,zltail_offset和zllength字段,定位到压缩列表的第一个entry和最后一个entry的时间复杂度是O(1),但是查找entry的时间复杂度是O(N),所以压缩列表的元素个数不宜太多。entry数据结构如下所示。
struct entry {
//前一个entry的字节
int prevlen;
//entry的内容的类型和长度
int encoding;
//entry的内容
optional byte[] content;
}entry中的prevlen字段和encoding字段都是可变长度,它们按照如下规则变化。
- 如果前一个entry的长度小于254字节,则prevlen字段长度为1字节;
- 如果前一个entry的长度大于等于254字节,则prevlen字段长度为5字节;
- 如果当前entry的内容是整数,则encoding字段长度为1字节;
- 如果当前entry的内容是字符串,则根据字符串的大小的不同,encoding字段长度为1字节,2字节或5字节。
插入数据时,根据插入数据的类型和大小的不同,prevlen字段和encoding字段会动态变化,这就是Redis使用压缩列表来节约空间的思想。但是相应的会发生如下的问题。
- 往压缩列表插入,更新和删除数据时,可能会导致某些entry的prevlen字段发生变化,极端情况下这个变化会向后逐级传递,造成压缩列表的级联更新;
- 压缩列表级联更新时,会多次重新分配内存,使得压缩列表的性能恶化。
因此鉴于压缩列表的特性,Redis中的列表对象在存储元素小于64字节,元素个数小于512个时才会使用压缩列表作为底层数据结构,为的就是避免级联更新的发生。
四. 哈希对象
哈希对象与底层数据结构对应关系如下。
- 哈希对象存储的元素的键和值的长度小于64字节,元素个数小于512时,该哈希对象底层数据结构使用压缩列表;
- 其它情况,该哈希对象底层数据结构使用字典。
下面对字典dict进行分析。字典数据结构定义如下。
typedef struct dict {
dictType *type;
//私有数据
void *privdata;
//哈希表
dictht ht[2];
//rehash时的索引
int trehashids;
} dict;Redis中的字典是基于哈希表实现,并且一个字典中持有两张哈希表。哈希表dictht数据结构定义如下。
typedef struct dictht {
//节点数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,计算索引
//sizemask = size - 1
unsigned long sizemask;
//哈希表当前节点数
unsigned long used;
} dictht;和Java中的HashMap类似,哈希表中有一个存储元素的节点数组,每个键值对会被封装成一个dictEntry节点然后添加到节点数组中。哈希表节点dictEntry数据结构定义如下。
typedef struct dictEntry {
//键
void *key;
//值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
//指向下一个节点
struct dictEntry *next;
} dictEntry;当存在哈希冲突时,会转变为链表以解决哈希冲突,dictEntry中的next字段指向链表的下一个节点。
那么基于上述数据结构,Redis中的字典可以用下图进行示意。

字典持有两张哈希表,分别为ht[0]和ht[1],在正常情况下,均会使用ht[0],ht[1]不会被分配内存空间。当字典需要扩容或者缩容时,会对字典中的键值对进行rehash操作,此时会使用到ht[1],具体规则如下。
- 先为ht[1]分配内存空间。如果是扩容,则ht[1]的size为大于等于
ht[0].used * 2且同时为2的幂次方的最小值,如果是缩容,则ht[1]的size为大于等于ht[0].used且同时为2的幂次方的最小值; - 将ht[0]中的键值对重新计算索引,然后存放到ht[1]中;
- ht[0]的所有键值对全部存放到ht[1]中后,释放ht[0]的内存空间,然后ht[1]变为ht[0]。
当字典中键值对特别多时,rehash会特别耗时,所以Redis采用一种渐进rehash的方式来完成扩缩容,字典中的trehashids字段用于记录当前已经rehash到的索引,Redis会逐步将ht[0]中的键值对rehash到ht[1]上,并更新trehashids字段,与此同时Redis也会正常提供缓存功能,且如果有新增的键值对,也会直接存放到ht[1]中,上述过程会持续到ht[0]上的键值对全部存放到ht[1],此时释放ht[0]的内存空间,然后ht[1]变为ht[0]。
五. 集合对象
集合对象与底层数据结构对应关系如下。
- 集合对象存储的元素都是整数值,元素个数不超过512个时,该集合对象底层数据结构使用整数集合;
- 其它情况,该集合对象底层数据结构使用字典。
六. 有序集合对象
有序集合对象与底层数据结构对应关系如下。
- 有序集合对象存储的元素长度小于64字节,元素个数小于128个时,该有序集合对象底层数据结构使用压缩列表;
- 其它情况,有序集合对象底层数据结构使用跳表。
关于跳表数据结构,将在后续的文章中学习。
总结
Redis中一共有五种对象类型,每种对象类型会根据元素类型,元素大小和元素数量的不同而采用不同的底层数据结构,所以能够搞明白Redis中的对象类型,也就搞明白了Redis中的数据结构。