SpringBoot 性能优化
1.服务监控
在开始对SpringBoot服务进行性能优化之前,我们需要做一些准备,把SpringBoot服务的一些数据暴露出来。
比如,你的服务用到了缓存,就需要把缓存命中率这些数据进行收集;用到了数据库连接池,就需要把连接池的参数给暴露出来。
我们这里采用的监控工具是Prometheus,它是一个是时序数据库,能够存储我们的指标。SpringBoot可以非常方便的接入到Prometheus中。
创建一个SpringBoot项目后,首先,加入maven依赖。
org.springframework.boot spring-boot-starter-actuator io.micrometer micrometer-registry-prometheus io.micrometer micrometer-core 然后,我们需要在application.properties配置文件中,开放相关的监控接口。management.endpoint.metrics.enabled=true
management.endpoints.web.exposure.include=*
management.endpoint.prometheus.enabled=true
management.metrics.export.prometheus.enabled=true
启动之后,我们就可以通过访问 http://localhost:8080/actuator/prometheus 来获取监控数据。

想要监控业务数据也是比较简单的。需要注入一个MeterRegistry实例即可。下面是一段示例代码:
@Autowired
MeterRegistry registry;
@GetMapping("/test")
@ResponseBody
public String test() {
registry.counter(“test”,
“from”, “127.0.0.1”,
“method”, “test”
).increment();
return "ok";
}
从监控连接中,我们可以找到刚刚添加的监控信息。
test_total{from=“127.0.0.1”,method=“test”,} 5.0
这里简单介绍一下流行的Prometheus监控体系,Prometheus使用拉的方式获取监控数据,这个暴露数据的过程可以交给功能更加齐全的telegraf组件。

如图,我们通常使用Grafana进行监控数据的展示,使用AlertManager组件进行提前预警。这一部分的搭建工作不是我们的重点,感兴趣的同学可自行研究。下图便是一张典型的监控图,可以看到Redis的缓存命中率等情况。

2.Java生成火焰图
火焰图是用来分析程序运行瓶颈的工具。在纵向,表示的是调用栈的深度;横向表明的是消耗的时间。所以格子的宽度越大,越说明它可能是一个瓶颈。
火焰图也可以用来分析Java应用。可以从github上下载async-profiler的压缩包 进行相关操作。
比如,我们把它解压到/root/目录。然后以javaagent的方式来启动Java应用。命令行如下:
java -agentpath:/root/build/libasyncProfiler.so=start,svg,file=profile.svg -jar spring-petclinic-2.3.1.BUILD-SNAPSHOT.jar
运行一段时间后,停止进程,可以看到在当前目录下,生成了profile.svg文件,这个文件是可以用浏览器打开的,一层层向下浏览,即可找到需要优化的目标。
3.Skywalking
对于一个web服务来说,最缓慢的地方就在于数据库操作。所以,使用本地缓存和分布式缓存优化,能够获得最大的性能提升。
对于如何定位到复杂分布式环境中的问题,我这里想要分享另外一个工具:Skywalking。
Skywalking是使用探针技术(JavaAgent)来实现的。通过在Java的启动参数中,加入javaagent的Jar包,即可将性能数据和调用链数据封装、发送到Skywalking的服务器。
下载相应的安装包(如果使用ES存储,需要下载专用的安装包),配置好存储之后,即可一键启动。
将agent的压缩包,解压到相应的目录。
tar xvf skywalking-agent.tar.gz -C /opt/
在业务启动参数中加入agent的包。比如,原来的启动命令是:
java -jar /opt/test-service/spring-boot-demo.jar --spring.profiles.active=dev
改造后的启动命令是:
java -javaagent:/opt/skywalking-agent/skywalking-agent.jar -Dskywalking.agent.service_name=the-demo-name -jar /opt/test-service/spring-boot-demo.ja --spring.profiles.active=dev
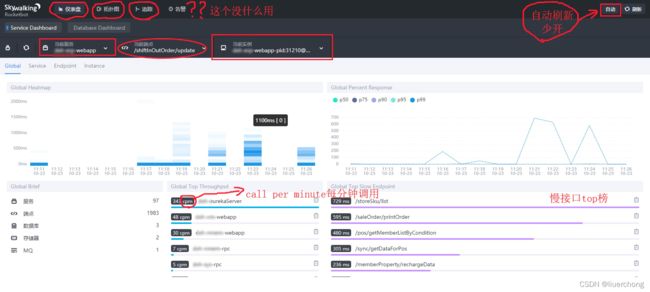
访问一些服务的链接,打开Skywalking的UI,即可看到下图的界面。我们可以从图中找到响应比较慢QPS又比较高的的接口,进行专项优化。
4.优化思路
对一个普通的Web服务来说,我们来看一下,要访问到具体的数据,都要经历哪些主要的环节。
如下图,在浏览器中输入相应的域名,需要通过DNS解析到具体的IP地址上。为了保证高可用,我们的服务一般都会部署多份,然后使用Nginx做反向代理和负载均衡。
Nginx根据资源的特性,会承担一部分动静分离的功能。其中,动态功能部分,会进入我们的SpringBoot服务。
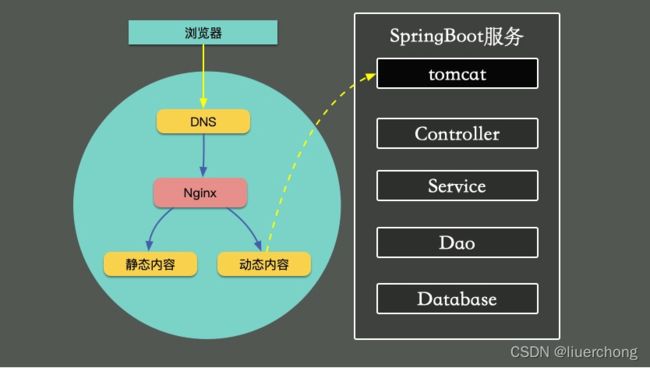
SpringBoot默认使用内嵌的tomcat作为Web容器,使用典型的MVC模式,最终访问到我们的数据。
5.HTTP优化
下面我们举例来看一下,哪些动作能够加快网页的获取。为了描述方便,我们仅讨论HTTP1.1协议的。
1.使用CDN加速文件获取
比较大的文件,尽量使用CDN(Content Delivery Network)分发。甚至是一些常用的前端脚本、样式、图片等,都可以放到CDN上。CDN通常能够加快这些文件的获取,网页加载也更加迅速。
2.合理设置Cache-Control值
浏览器会判断HTTP头Cache-Control的内容,用来决定是否使用浏览器缓存,这在管理一些静态文件的时候,非常有用。相同作用的头信息还有Expires。Cache-Control表示多久之后过期,Expires则表示什么时候过期。
这个参数可以在Nginx的配置文件中进行设置。
location ~* ^.+.(ico|gif|jpg|jpeg|png)$ {
# 缓存1年
add_header Cache-Control: no-cache, max-age=31536000;
}
3.减少单页面请求域名的数量
减少每个页面请求的域名数量,尽量保证在4个之内。这是因为,浏览器每次访问后端的资源,都需要先查询一次DNS,然后找到DNS对应的IP地址,再进行真正的调用。
DNS有多层缓存,比如浏览器会缓存一份、本地主机会缓存、ISP服务商缓存等。从DNS到IP地址的转变,通常会花费20-120ms的时间。减少域名的数量,可加快资源的获取。
4.开启gzip
开启gzip,可以先把内容压缩后,浏览器再进行解压。由于减少了传输的大小,会减少带宽的使用,提高传输效率。
在nginx中可以很容易的开启。配置如下:
gzip on;
gzip_min_length 1k;
gzip_buffers 4 16k;
gzip_comp_level 6;
gzip_http_version 1.1;
gzip_types text/plain application/javascript text/css;
5.对资源进行压缩
对JavaScript和CSS,甚至是HTML进行压缩。道理类似,现在流行的前后端分离模式,一般都是对这些资源进行压缩的。
6.使用keepalive
由于连接的创建和关闭,都需要耗费资源。用户访问我们的服务后,后续也会有更多的互动,所以保持长连接可以显著减少网络交互,提高性能。
nginx默认开启了对客户端的keep avlide支持。你可以通过下面两个参数来调整它的行为。
http {
keepalive_timeout 120s 120s;
keepalive_requests 10000;
}
nginx与后端upstream的长连接,需要手工开启,参考配置如下:
location ~ /{
proxy_pass http://backend;
proxy_http_version 1.1;
proxy_set_header Connection “”;
}
6.Tomcat优化
Tomcat本身的优化,也是非常重要的一环。
tomcat这只老猫为何能活过普通猫咪能活的年龄?这与它轻巧的构造有关,还与它卓越的性能有关。现在的tomcat,版本已经飙到10了!。
tomcat的配置参数奇多,但想要达到优化效果,我们并不需要全部关注。本文将详细介绍一些主要的配置参数,保证让你这只老猫跑的更快!
一般最常做的更改,就是修改服务器的端口,也就是server.xml里的Connector部分。典型如下图所示:

其实,大部分优化,也是在Connector标签之内,从端口、并发到线程,都可以在这里配置。
一. 3个参数搞定并发配置
作为一个能承接高并发互联网请求的Web容器,首当其冲的当然是海量请求的冲击。幸运的是Tomcat支持NIO,我们可以通过调整线程数和并发配置,让它表现出最佳的性能。
maxThreads – tomcat接收客户端请求的最大线程数,也就是同时处理任务的个数,它的默认大小为200;一般来说,在高并发的I/O密集型应用中,这个值设置为1000左右比较合理
maxConnections 这个参数是指在同一时间,tomcat能够接受的最大连接数。对于Java的阻塞式BIO,默认值是maxthreads的值;如果在BIO模式使用定制的Executor执行器,默认值将是执行器中maxThreads的值。对于Java 新的NIO模式,maxConnections 默认值是10000,所以这个参数我们一般保持不动即可
acceptCount – 当线程数量达到上面设置的值,所能接受的最大排队数量。超过了这个值,请求就会被拒绝。我一般会设置成和maxThreads设置成一样大的
简单说明一下上面三个参数的关系:
系统能够保持的连接数
maxConnections+acceptCount,区别是maxConnections中的连接可以被调度处理;acceptCount中的连接只能等待排队
系统能处理的请求数
maxThreads的大小,实际能够工作的线程数量。
幸福指数:maxThreads > maxConnections > acceptCount。
现在有些文章还充斥着maxProcessors和minProcessors。但这两个参数,从Tomcat5开始被deprecated,从6开始就彻底没了。
只能说你看到的这些文章,可能真的是不懂技术的运营发表的。
以8为代表,具体配置参数可以参见:
https://tomcat.apache.org/tomcat-8.0-doc/config/http.html
二、线程配置
在并发配置方面,可以看到我们只有minSpareThreads,但是却没有maxSpareThreads。这是因为,从Tomcat 6开始增加Executor 节点,这个参数已经没用了。
由于线程是一个池子,所以它的配置,满足池的一切特点。
参照:
https://tomcat.apache.org/tomcat-8.0-doc/config/executor.html
namePrefix – 每个新开线程的名称前缀
maxThreads – 线程池中的最大线程数
minSpareThreads – 一直处于活跃状态的线程数
maxIdleTime – 线程的空闲时间,在超过空闲时间时这些线程则会被销毁
threadPriority – 线程池中线程的优先级,默认为5
三、搞定JVM配置
tomcat是Java应用,所以JVM的配置同样会影响它的性能。比较重要的配置参数如下。
2.1、内存区域大小
首先要调整的,就是各个分区的大小,不过这也要分垃圾回收器,我们仅看一下一些全局的参数。
-XX:+UseG1GC 首先,要指定JVM使用的垃圾回收器。尽量不要靠默认值去保证,要显式的指定一个。
-Xmx 设置堆的最大值,一般为操作系统的2/3大小。
-Xms 设置堆的初始值,一般设置成和Xmx一样的大小来避免动态扩容。
-Xmn 年轻代大小,默认新生代占堆大小的1/3。高并发快消亡场景可适当加大这个区域。对半,或者更多,都是可以的。但是在G1下,就不用再设置这个值了,它会自动调整。
-XX:MaxMetaspaceSize 限制元空间的大小,一般256M足够。这一般和初始大小**-XX:MetaspaceSize设置成一样的。
-XX:MaxDirectMemorySize 设置直接内存的最大值,限制通过DirectByteBuffer申请的内存。
-XX:ReservedCodeCacheSize 设置JIT编译后的代码存放区大小,如果观察到这个值有限制,可以适当调大,一般够用。
-Xss 设置栈的大小,默认为1M,已经足够用了。
2.2、内存调优
-XX:+AlwaysPreTouch 启动时就把参数里说好了的内存全部初始化,启动时间会慢一些,但运行速度会增加。
-XX:SurvivorRatio 默认值为8。表示伊甸区和幸存区的比例。
-XX:MaxTenuringThreshold 这个值在CMS下默认为6,G1下默认为15。这个值和我们前面提到的对象提升有关,改动效果会比较明显。对象的年龄分布可以使用-XX:+PrintTenuringDistribution**打印,如果后面几代的大小总是差不多,证明过了某个年龄后的对象总能晋升到老生代,就可以把晋升阈值设小。
PretenureSizeThreshold 超过一定大小的对象,将直接在老年代分配。不过这个参数用的不是很多。
2.3、垃圾回收器优化
G1垃圾回收器
-XX:MaxGCPauseMillis 设置目标停顿时间,G1会尽力达成。
-XX:G1HeapRegionSize 设置小堆区大小。这个值为2的次幂,不要太大,也不要太小。如果是在不知道如何设置,保持默认。
-XX:InitiatingHeapOccupancyPercent 当整个堆内存使用达到一定比例(默认是45%),并发标记阶段就会被启动。
-XX:ConcGCThreads 并发垃圾收集器使用的线程数量。默认值随JVM运行的平台不同而不同。不建议修改。
四、其他重要配置
再看几个在Connector中配置的重要参数。
enableLookups – 调用request、getRemoteHost()执行DNS查询,以返回远程主机的主机名,如果设置为false,则直接返回IP地址。这个要根据需求来
URIEncoding – 用于解码URL的字符编码,没有指定默认值为ISO-8859-1
connectionTimeout – 连接的超时时间(以毫秒为单位)
redirectPort – 指定服务器正在处理http请求时收到了一个SSL传输请求后重定向的端口号
五、总结
tomcat是最常用的web容器,提供了数百个配置参数。但我们在平常的使用中,没必要把所有的参数都弄清楚,只关注最重要的就可以了。
7.自定义Web容器
如果你的项目并发量比较高,想要修改最大线程数、最大连接数等配置信息,可以通过自定义Web容器的方式,代码如下所示。
@SpringBootApplication(proxyBeanMethods = false)
public class App implements WebServerFactoryCustomizer {
public static void main(String[] args) {
SpringApplication.run(PetClinicApplication.class, args);
}
@Override
public void customize(ConfigurableServletWebServerFactory factory) {
TomcatServletWebServerFactory f = (TomcatServletWebServerFactory) factory;
f.setProtocol(“org.apache.coyote.http11.Http11Nio2Protocol”);
f.addConnectorCustomizers(c -> {
Http11NioProtocol protocol = (Http11NioProtocol) c.getProtocolHandler();
protocol.setMaxConnections(200);
protocol.setMaxThreads(200);
protocol.setSelectorTimeout(3000);
protocol.setSessionTimeout(3000);
protocol.setConnectionTimeout(3000);
});
}
}
注意上面的代码,我们设置了它的协议为org.apache.coyote.http11.Http11Nio2Protocol,意思就是开启了Nio2。这个参数在Tomcat8.0之后才有,开启之后会增加一部分性能。对比如下:
默认。
[root@localhost wrk2-master]# ./wrk -t2 -c100 -d30s -R2000 http://172.16.1.57:8080/owners?lastName=
Running 30s test @ http://172.16.1.57:8080/owners?lastName=
2 threads and 100 connections
Thread calibration: mean lat.: 4588.131ms, rate sampling interval: 16277ms
Thread calibration: mean lat.: 4647.927ms, rate sampling interval: 16285ms
Thread Stats Avg Stdev Max +/- Stdev
Latency 16.49s 4.98s 27.34s 63.90%
Req/Sec 106.50 1.50 108.00 100.00%
6471 requests in 30.03s, 39.31MB read
Socket errors: connect 0, read 0, write 0, timeout 60
Requests/sec: 215.51
Transfer/sec: 1.31MB
Nio2。
[root@localhost wrk2-master]# ./wrk -t2 -c100 -d30s -R2000 http://172.16.1.57:8080/owners?lastName=
Running 30s test @ http://172.16.1.57:8080/owners?lastName=
2 threads and 100 connections
Thread calibration: mean lat.: 4358.805ms, rate sampling interval: 15835ms
Thread calibration: mean lat.: 4622.087ms, rate sampling interval: 16293ms
Thread Stats Avg Stdev Max +/- Stdev
Latency 17.47s 4.98s 26.90s 57.69%
Req/Sec 125.50 2.50 128.00 100.00%
7469 requests in 30.04s, 45.38MB read
Socket errors: connect 0, read 0, write 0, timeout 4
Requests/sec: 248.64
Transfer/sec: 1.51MB
你甚至可以将tomcat替换成undertow。undertow也是一个Web容器,更加轻量级一些,占用的内容更少,启动的守护进程也更少,更改方式如下:
由于controller只是充当了一个类似功能组合和路由的角色,所以这部分对性能的影响就主要体现在数据集的大小上。如果结果集合非常大,JSON解析组件就要花费较多的时间进行解析。
大结果集不仅会影响解析时间,还会造成内存浪费。假如结果集在解析成JSON之前,占用的内存是10MB,那么在解析过程中,有可能会使用20M或者更多的内存去做这个工作。我见过很多案例,由于返回对象的嵌套层次太深、引用了不该引用的对象(比如非常大的byte[]对象),造成了内存使用的飙升。
所以,对于一般的服务,保持结果集的精简,是非常有必要的,这也是DTO(data transfer object)存在的必要。如果你的项目,返回的结果结构比较复杂,对结果集进行一次转换是非常有必要的。
另外,可以使用异步Servlet对Controller层进行优化。它的原理如下:Servlet 接收到请求之后,将请求转交给一个异步线程来执行业务处理,线程本身返回至容器,异步线程处理完业务以后,可以直接生成响应数据,或者将请求继续转发给其它 Servlet。
Service层
service层用于处理具体的业务,大部分功能需求都是在这里完成的。service层一般是使用单例模式(prototype),很少会保存状态,而且可以被controller复用。
service层的代码组织,对代码的可读性、性能影响都比较大。我们常说的设计模式,大多数都是针对于service层来说的。
这里要着重提到的一点,就是分布式事务。

如上图,四个操作分散在三个不同的资源中。要想达到一致性,需要三个不同的资源进行统一协调。它们底层的协议,以及实现方式,都是不一样的。那就无法通过Spring提供的Transaction注解来解决,需要借助外部的组件来完成。
很多人都体验过,加入了一些保证一致性的代码,一压测,性能掉的惊掉下巴。分布式事务是性能杀手,因为它要使用额外的步骤去保证一致性,常用的方法有:两阶段提交方案、TCC、本地消息表、MQ事务消息、分布式事务中间件等。

如上图,分布式事务要在改造成本、性能、实效等方面进行综合考虑。有一个介于分布式事务和非事务之间的名词,叫做柔性事务。柔性事务的理念是将业务逻辑和互斥操作,从资源层上移至业务层面。
关于传统事务和柔性事务,我们来简单比较一下。
ACID
关系数据库, 最大的特点就是事务处理, 即满足ACID。
原子性(Atomicity):事务中的操作要么都做,要么都不做。
一致性(Consistency):系统必须始终处在强一致状态下。
隔离性(Isolation):一个事务的执行不能被其他事务所干扰。
持续性(Durability):一个已提交的事务对数据库中数据的改变是永久性的。
BASE
BASE方法通过牺牲一致性和孤立性来提高可用性和系统性能。
BASE为Basically Available, Soft-state, Eventually consistent三者的缩写,其中BASE分别代表:
基本可用(Basically Available):系统能够基本运行、一直提供服务。
软状态(Soft-state):系统不要求一直保持强一致状态。
最终一致性(Eventual consistency):系统需要在某一时刻后达到一致性要求。
互联网业务,推荐使用补偿事务,完成最终一致性。比如,通过一系列的定时任务,完成对数据的修复。具体可以参照下面的文章。
常用的 分布式事务 都有哪些?我该用哪个?
Dao层
经过合理的数据缓存,我们都会尽量避免请求穿透到Dao层。除非你对ORM本身提供的缓存特性特别的熟悉,否则,都推荐你使用更加通用的方式去缓存数据。
Dao层,主要在于对ORM框架的使用上。比如,在JPA中,如果加了一对多或者多对多的映射关系,而又没有开启懒加载,级联查询的时候就容易造成深层次的检索,造成了内存开销大、执行缓慢的后果。
在一些数据量比较大的业务中,多采用分库分表的方式。在这些分库分表组件中,很多简单的查询语句,都会被重新解析后分散到各个节点进行运算,最后进行结果合并。
举个例子,select count(*) from a这句简单的count语句,就可能将请求路由到十几张表中去运算,最后在协调节点进行统计,执行效率是可想而知的。目前,分库分表中间件,比较有代表性的是驱动层的ShardingJdbc和代理层的MyCat,它们都有这样的问题。这些组件提供给使用者的视图是一致的,但我们在编码的时候,一定要注意这些区别。
End
下面我们来总结一下。
我们简单看了一下SpringBoot常见的优化思路。我们介绍了三个新的性能分析工具。一个是监控系统Prometheus,可以看到一些具体的指标大小;一个是火焰图,可以看到具体的代码热点;一个是Skywalking,可以分析分布式环境中的调用链。在对性能有疑惑的时候,我们都会采用类似于神农氏尝百草的方式,综合各种测评工具的结果进行分析。
SpringBoot自身的Web容器是Tomcat,那我们就可以通过对Tomcat的调优来获取性能提升。当然,对于服务上层的负载均衡Nginx,我们也提供了一系列的优化思路。
最后,我们看了在经典的MVC架构下,Controller、Service、Dao的一些优化方向,并着重看了Service层的分布式事务问题。
SpringBoot作为一个广泛应用的服务框架,在性能优化方面已经做了很多工作,选用了很多高速组件。比如,数据库连接池默认使用hikaricp,Redis缓存框架默认使用lettuce,本地缓存提供caffeine等。对于一个普通的于数据库交互的Web服务来说,缓存是最主要的优化手。