【C++】C++11新特性
委托构造函数
C++11 标准提出了委派构造函数新特性。利用这个特性,程序员可以将公有的类成员构造代码集中在某一个构造函数里,这个函数被称为目标构造函数。其他构造函数通过调用目标构造函数来实现类成员构造,这些构造函数被称为委派构造函数。在该新特性提出之前,构造函数是不能显式被调用的,委派构造函数打破了这一限制
class CGoods
{
public:
CGoods():CGoods("\0", 0, 0, 0) //: CGoods("\0", 0) {}
{ }
CGoods(string name, float price):CGoods(name, 0, price, 0) //
{ }
CGoods(string name, int amount, float price, float total)
:Name(name), Amount(amount), Price(price), Total(total)
{ }
private:
string Name;
int Amount;
float Price;
float Total;
};
总结:调用顺序。
一个委派构造函数可以是另一个委派构造函数的目标构造函数,委派构造函数和目标构造函数是相对而言的。目标构造函数是通过重载和类参数推导准则而选定的。
在委派过程中,当目标构造函数函数执行完毕后,委派构造函数继续执行它自己函数体内的语句
委派构造函数的异常处理
当目标构造函数抛出异常时,该异常会被委派构造函数中的 try 模块抓取到。并且在这种情况下,委派构造函数自己函数体内的代码就不会被执行了。
class CGoods
{
public:
CGoods() try
:CGoods("\0", 0) // 这就是委派构造函数的语法。
{
cout << "construct CGoods()" << endl;
}
catch (...)
{
cout << "CGoods() catch" << endl;
}
CGoods(string name, float price) try
:CGoods(name, 0, price, 0) // 这就是委派构造函数的语法。
{
cout << "construct CGoods(name,price)" << endl;
throw string("BadCGoods");
}
catch (...)
{
cout << "CGoods(name,price) catch "<< endl;
}
CGoods(string name, int amount, float price, float total) try
:Name(name), Amount(amount), Price(price), Total(total)
{
cout << "CGoods(name,amount,price,total)" << endl;
}
catch (...)
{
cout << "CGoods(string name, int amount, float price, float total) catch"<<endl;
}
~CGoods()
{
cout << "CGoods::~CGoods" << endl;
}
private:
string Name;
int Amount;
float Price;
float Total;
};
int main()
{
try
{
CGoods c1;
cout << "main body" << endl;
}
catch (...)
{
cout << "main catch" << endl;
}
return 0;
}
总结: 当委派构造函数抛出异常时,系统会自动调用目标构造函数内已经构造完成的对象的析构函数
委派构造函数和泛型编程
委派构造函数还有一个很实际的应用:它使得构造函数的泛型编程变得更加容易
template<class T>
class AddItem
{
public:
AddItem(int x, int y) :AddItem(x, y, 0) {}
AddItem(double x, double y) :AddItem(x, y, 0) {}
AddItem(const T& a, const T& b, int )
:vala(a), valb(b)
{
}
private:
T vala;
T valb;
};
总结: 目标构造函数为函数模板,它在被委派构造函数调用的时候才被实例化。这样的用法十分方便,程序员不需要再书写不同类型的目标构造函数了。
委派构造函数的使用限制
委派构造函数特性简单好用,但是在这个特性的使用中也需要注意以下的限制。
- 一个类中的构造函数可以形成一个委派链。但是程序员应该避免委派环的出现,编译将出错
- 一个构造函数不能在初始化列表中既初始化成员变量,又委派其他构造函数完成构造
缺省函数的控制,delete,default
C++编译器在编译时会对所编译的自己设计的类型添加缺省成员函数,如:构造,拷贝构造,赋值重载,析构, 移动构造,移动赋值重载,以及 operator& , operator&() const 函数;如果程序员自己加了, 编译器将不生成缺省函数。如果程序员自己没有添加, 编译器将生成缺省函数。 C++11 让程序员可以控制是否需要编译器生成这些缺省函数。
using namespace std;
class Int
{
private:
int value;
public:
Int() = default;
Int(int x) :value(x) {}
Int(const Int&) = default; // 缺省拷贝构造函数,按位拷贝
Int& operator=(const Int&) = delete; // 不容许编译器生成赋值重载
};
int main()
{
Int a;
return 0;
}
总结: explicit
C++中的默认函数与 default 和 delete 用法
类中的默认函数
1.默认构造函数
2.默认析构函数
3.拷贝构造函数
4.拷贝赋值函数
5.移动构造函数
6.移动拷贝函数
7.operator&, operator&() const;
类中自定义的操作符函数
1.operator&&
2.operator*
3.operator->
4.operator new
5.operator delete
问题: 不容许对象建立在 heap 中如何实现
初始化列表 std::initializer_list
源码
template <class _Elem>
class initializer_list
{
public:
using value_type = _Elem;
using reference = const _Elem&;
using const_reference = const _Elem&;
using size_type = size_t;
using iterator = const _Elem*;
using const_iterator = const _Elem*;
constexpr initializer_list() noexcept : _First(nullptr), _Last(nullptr) {}
constexpr initializer_list(const _Elem* _First_arg, const _Elem* _Last_arg) noexcept
: _First(_First_arg), _Last(_Last_arg) {}
constexpr const _Elem* begin() const noexcept
{
return _First;
}
constexpr const _Elem* end() const noexcept
{
return _Last;
}
constexpr size_t size() const noexcept {
return static_cast<size_t>(_Last - _First);
}
private:
const _Elem* _First;
const _Elem* _Last;
};
// FUNCTION TEMPLATE begin
template <class _Elem>
constexpr const _Elem* begin(initializer_list<_Elem> _Ilist) noexcept
{
return _Ilist.begin();
}
// FUNCTION TEMPLATE end
template <class _Elem>
constexpr const _Elem* end(initializer_list<_Elem> _Ilist) noexcept
{
return _Ilist.end();
}
int main()
{
std::vector<int> var = { 12,23,34,45,56 };
std::map<string, int> simap = { {"tulun",15},{"yhping",23},{"humin",18 } };
return 0;
}
initializer_list 当出现在以下两种情况的被自动构造
当初始化的时候使用的是大括号初始化,被自动构造。包括函数调用时和赋值。 当涉及到 for(initializer:
list) ,list 被自动构造成 initializer_list 对象,也就是说 initializer_list 对象只能用大括号{}初始化。
拷贝一个 initializer_list 对象并不会拷贝里面的元素。其实只是引用而已。 而且里面的元素全部都是 const
的
示例:
class Object
{
private:
int value;
public:
Object(int x = 0) :value(x) { cout << "construct object" << endl; }
Object(const Object& obj) :value(obj.value) { cout << "copy construct object" << endl; }
Object& operator=(const Object& obj)
{
value = obj.value;
cout << " = " << endl;
return *this;
}
~Object() { cout << "deconstruct object" << endl; }
Object(Object&& obj) :value(obj.value)
{
cout << "move copy construct object " << endl;
}
Object& operator=(const Object&& obj)
{
value = obj.value;
cout << " move = " << endl;
return *this;
}
};
int main()
{
std::list<Object> objlist ={ 12,23,34};
cout << "main end" << endl;
return 0;
}

右值引用
左值: 是指表达式结束后依然存在的持久对象
右值:是指表达式结束时就不再存在的临时对象。
区分左值与右值的便捷方法是:看能不能对表达式取地址, 如果能,则为左值,否则为右值。 所有的具名变量或对象都是左值,而右值不具名
在 C++11 中,右值由两个概念构成:
-
一个是纯右值(prvalue, PureRvalue) , 比如,非引用返回的临时变量、运算表达式产生的临时变量、原始字
量和 lambda 表达式等都是纯右值。int main() { int a=10; int &b=a; // ok int &c=10; //error, 10是纯右值,不能拿普通引用引用它,可以拿常引用引用它 const int &c =10; //ok,因为const做了这两件事:int tmp = 10; const int &c= 10; int && d=10; //ok,右值引用,可以把一个右值绑定到右值引用上,底层汇编指令类似于int tmp = 10; int &&d = tmp; //通过const方式不能改右值的值,通过&&右值引用是可以改右值的值的 } -
另一个则是将亡值(xvalue, expiring value), 而将亡值是 C++11 新增的,与右值引用相关的表达式,比如将
被移动的对象,T&&函数返回值,std::move 返回值和转换为 T&& 的类型的转换函数的返回值。
C++11 中所有的值必属于左值、将亡值、纯右值三者之一,将亡值和纯右值都属于右值。
C++11 增加了一个新的类型,称为右值引用(R-value reference), 标记为 T &&。
右值引用就是对一个右值进行引用的类型。因为右值不具有名字,所以我们只能通过引用的方式找到它。
无论声明左值引用还是右值引用都必须立即进行初始化,因为引用类型本身并不拥有所绑定对象的内存, 只是该对象的一个别名。 通过右值引用的声明,该右值又“重获新生” , 其生命周期与右值引用类型变量的生命周期一样,只要该变量还活着,该右值临时量将会一直存活下去。
临时对象示例如下:

重点: 右值引用绑定了右值, 让临时右值的生命周期延长了。我们可以利用这个特点做一些性能优化,即避
免临时对象的拷贝构造和析构
未定的引用类型
universal references
示例:
template<typename T>
class Test
{
public:
Test() {}
Test(Test<T> && rhs);
// 已经定义了一个特定的类型,没有类型推断
//&&是一个右值引用
};
template<typename T>
void fun(T && param) // 这里 T 的类型需要推导,所以 && 是一个 universal references
{
cout<<param<<endl;
}
template<class T>
void f(Test<T> &¶m) //已经定义了一个确定的类型,没有类型推断, &&是一个右值引用
{}
template<class T>
void f(const T && param) //&&是一个右值引用
{}
从这个例子可以看岀, param 有时是左值,有时是右值,因为在上面的例子中有&&
未定的引用类型是左值还是右值引用取决于它的初始化,如果&&被一个左值初始化,它就是一个左值;如果它被一个右值初始化,它就是一个右值
需要注意的是,只有当发生自动类型推断时(如函数模板的类型自动推导,或 auto 关键字), && 才是一个universal references
其实还有一条很关键的规则: universal references 仅仅在 T&&下发生,任何一点附加条件都会使之失效,
而变成一个普通的右值引用
由于存在 T&&这种未定的引用类型,当它作为参数时,有可能被一个左值引用或者右值引用的参数初始化,这时经过类型推导的 T&&类型,相比右值引用(&&)会发生类型的变化,这种变化被称为引用折叠。 C++11中的引用折叠规则如下:
- 所有的右值引用叠加到右值引用上仍然还是一个右值引用。
- 所有的其他引用类型之间的叠加都将变成左值引用
如果希望把一个左值赋给一个右值引用类型该怎么做呢?用 std::move:
int a=10;
int && b=std::move(a);
//std::move可以将一个左值转换为右值
&&的总结
左值和右值是独立于它们的类型的,右值引用类型可能是左值也可能是右值
auto&&或函数参数类型自动推导的 T&&是一个未定的引用类型,被称为 universal references,它可能是左值引用也可能是右值引用类型,取决于初始化的值类型
所有的右值引用叠加到右值引用上仍然是一个右值引用,其他引用折叠都为左值引用。当 T&&为模板参数时,输入左值,它会变成左值引用,而输入右值时则变为具名的右值引用。
编译器会将已命名的右值引用视为左值,而将未命名的右值引用视为右值
右值引用优化性能,避免深拷贝
std::move 语义:我们知道移动语义是通过右值引用来匹配临时值的,那么,普通的左值是否也能借助移动语义来优化性能呢,那该怎么做呢?事实上 c++11 为了解决这个问题, 提供了 std::move 方法来将左值转换为右值,从而方便应用移动语义。 move 是将对象的状态或者所有权从一个对象转移到另一个对象,只是转移,没有内存拷贝
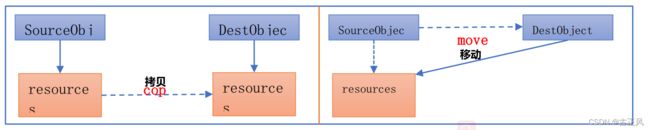
move 实际上并不能移动任何东西,它唯一的功能是将一个左值强制转换为一个右值引用,使我们可以通过右值引用使用该值,以用于移动语义。 强制转换为右值的目的是为了方便实现移动构造。
这种 move 语义是很有用的,比如一个对象中有一些指针资源或者动态数组,在对象的赋值或者拷贝时就不需要
拷贝这些资源了
move 只是转移了资源的控制权,本质上是将左值强制转换为右值引用,以用于 move 语义,避免含有资源的对象发生无谓的拷贝。 move 对于拥有形如对内存、文件句柄等资源的成员的对象有效。如果是一些基本类型,比如 int 和 char[ 10]数组等,如果使用 move,仍然会发生拷贝(因为没有对应的移动构造函数),所以说move 对于含资源的对象来说更有意义
move源码
template<class _Ty> inline
typename remove_reference<_Ty>::type&& move(_Ty&& _Arg)
{ // forward _Arg as movable
return ((typename remove_reference<_Ty>::type&&)_Arg);
}
template<class _Ty>
struct remove_reference
{ // remove reference
typedef _Ty type;
};
template<class _Ty>
struct remove_reference<_Ty&>
{ // remove reference
typedef _Ty type;
};
template<class _Ty>
struct remove_reference<_Ty&&>
{ // remove rvalue reference
typedef _Ty type;
};
forward 和完美转发
右值引用类型是独立于值的,一个右值引用参数作为函数的形参,在函数内部再转发该参数的时候它已经变成一个左值了,并不是它原来的类型了。 因此,我们需要一种方法能按照参数原来的类型转发到另一个函数,这种转发被称为完美转发。
完美转发(Perfect Forwarding),是指在函数模板中,完全依照模板的参数的类型(即保持参数的左值、右值特征),将参数传递给函数模板中调用的另外一个函数。 C++11 中提供了这样的一个函数std::forward,它是为转发而生的,不管参数是 T&&这种未定的引用还是明确的左值引用或者右值引用,它会按照参数本来的类型转发。
#include
TestForward(1):由于 1 是右值,所以未定的引用类型 T && v 被一个右值初始化后变成了一个右值引用,但是在 TestForward 函数体内部,调用 PrintT(v)时,v 又变成了一个左值(因为在 std::forward 里它已经变成了一个具名的变量,所以它是一个左值),因此, 示例测试结果第一个 PrintT 被调用,打印出“L_value: 1 ” 。
调用 PrintT(std::forward(v))时,由于 std::forward 会按参数原来的类型转发,因此,它还是一个右值(这里已经发生了类型推导,所以这里的 T&&不是一个未定的引用类型,会调用 void PrintT(T &&t)函数打印“R_value: 1” .调用 PrintT(std::move(v))是将 v 变成一个右值(v 本身也是右值),因此,它将输岀”R_value:1”
TestForward(x)未定的引用类型 T && v 被一个左值初始化后变成了一个左值引用,因此,在调用
PrintT(std::forward(v))时它会被转发到 void PrintT(T& t)
源码:
template <class _Ty>
constexpr _Ty&& forward( remove_reference<_Ty>& _Arg) noexcept
{ // forward an lvalue as either an lvalue or an rvalue
return static_cast<_Ty&&>(_Arg);
}
template <class _Ty>
constexpr _Ty&& forward(remove_reference<_Ty>&& _Arg) noexcept
{ // forward an rvalue as an rvalue
//static_assert(!is_lvalue_reference_v<_Ty>, "bad forward call");
return static_cast<_Ty&&>(_Arg);
}
类型推导,auto
C++11 引入了 auto 和 decltype 关键字实现类型推导,通过这两个关键字不仅能方便地获取复杂的类型,
而且还能简化书写,提高编码效率。
int main()
{
auto i = 0; // i 是 int
auto pi = new auto(1); // pi 是 int *
const auto* cp = &i, x = 10; // cp 是 const int *, x 是 const int
static auto dx = 0.0; // dx 是 double
auto int r = 0; // error;
auto p; // error;
}
总结: 使用 auto 声明的变量必须马上初始化,以让编译器推断出它的实际类型,并在编译时将 auto 占位符替换为真正的类型
在 C++11 标准中, auto 关键字不再表示存储类型指示符(storage-class-specifiers,如上文提到的 static,以
及 register, mutable 等),而是改成一个类型指示符(type-specifier) ,用来提示编译器对此类型的变量做类型的自动推导
decltype 关键字
decltype 关键字:用来在编译时推导出一个表达式的类型
decltype(表达式)
从格式上来看, decltype 很像 sizeof —用来推导表达式类型大小的操作符。类似于 sizeof, decltype 的推导过程是在编译期完成的,并且不会真正计算表达式的值

final与override
override 覆盖 , 如果使用override标记了某个函数,但该函数并没有覆盖已存在的虚函数,编译器将报错
class Object
{
public:
virtual void fun() const {}
};
class Base : public Object
{
public:
virtual void fun() const override {}// 明确告知是覆盖虚函数
};
final:当不希望某个类被继承,或不希望某个虚函数被重写,可以在类名和虚函数后添加 final 关键字,添加 final
关键字后被继承或重写,编译器会报错
lambda表达式
lambda 来源于函数式编程的概念,也是现代编程语言的一个特点
lambda 表达式有如下优点:
- 声明式编程风格:就地匿名定义目标函数或函数对象,不需要额外写一个命名函数或者函数对象。以更直接的方式去写程序,好的可读性和可维护性。
- 简洁:不需要额外再写一个函数或者函数对象,避免了代码膨胀和功能分散,让开发者更加集中精力在手边的问题,同时也获取了更高的生产率。
- 在需要的时间和地点实现功能闭包,使程序更灵活。
lambda 表达式的概念和基本用法
lambda 表达式定义了一个匿名函数,并且可以捕获一定范围内的变量。 lambda 表达式 的语法形式可简单
归纳如下:
[capture](params) opt->ret{body};
[捕获列表](参数表) 函数选项->返回值类型 {函数体};
其中: capture 是捕获列表; params 是参数表; opt 是函数选项; ret 是返回值类型; body 是函数体。
lambda 表达式可以通过捕获列表捕获一定范围内的变量:
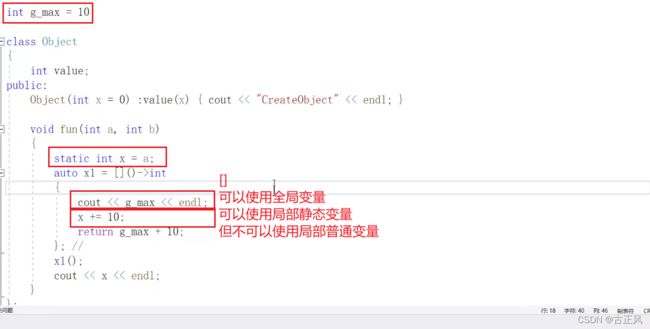
全局变量不受[]里面的东西影响:lambda就是匿名函数,函数都可以访问全局变量,那匿名函数当然也可以
- [ ]不捕获当前函数内部的任何变量,但可以使用全局变量
- [&]捕获外部作用域中所有变量,并作为引用在函数体中使用(按引用捕获)
- [=]捕获外部作用域中所有变量,并作为副本在函数体中使用(按值捕获)
- [=, &foo]按值捕获外部作用域中所有变量,并按引用捕获 foo 变量
- [bar]按值捕获 bar 变量,同时不捕获其他变量
- [this]捕获当前类中的 this 指针,让 lambda 表达式拥有和当前类成员函数同样的访问权限。如果已经使用了&或者=,就默认添加此选项。捕获 this 的目的是可以在 lamda 中使用当前类的成员函数和成员变量
示例:
int g_max = 10;
class Object
{
int value;
public:
Object(int x = 0) :value(x) { cout << "construct object" << this << endl; }
void func(int a, int b)
{ // error; 没有捕获外部变量
auto x1 = []()->int { return a; }; // error
//捕获外部作用域中所有变量,按值捕获(包括全局变量和 this 指针)
auto x2 = [=]()->int { int x = value; return x + a + g_max; };
//捕获外部作用域中所有变量,按引用捕获(包括全局变量和 this 指针)
auto x3 = [&]()->int { g_max = 100; value += 10; return g_max + value; };
//只是捕获 this 指针
auto x4 = [this](int c)->int { value += 100; return value + c; };
//只是捕获 this 指针,不捕获 a,b;
auto x5 = [this]()->void { value = a + b; }; // error;
// 只是捕获 this 指针 a,b;
auto x6 = [this, a, b]()->void { value = a + b; };
}
};
int main()
{
int x = 10, y = 20;
Object obj(10); // 诡异
obj.func(12, 23);
auto f1 = [] { return x; }; // error;
auto f2 = [&](int a)->void { obj.func(x, a + 10); };
auto f3 = [=, &x](int a)->void { x = a; };
return 0;
}
默认状态下 lambda 表达式无法修改通过复制方式捕获的外部变量。如果希望修改这些变量的话,我们需要使用引用方式进行捕获。
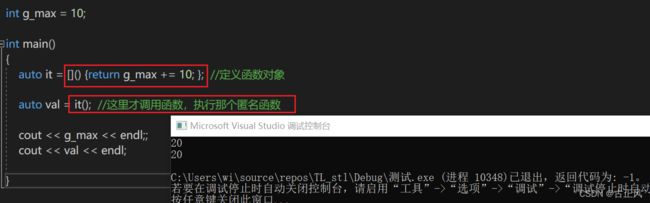
一个容易出错的细节是关于 lambda 表达式的延迟调用的
总结:
需要注意的一点是,被 mutable 修饰的 lambda 表达式就算没有参数也要写明参数列表。
lambda 表达式可以说是就地定义仿函数闭包的“语法糖”。它的捕获列表捕获住的任何外部变量,最终均会变为闭包类型的成员变量。而一个使用了成员变量的类的 operator(),如果能直接被转换为普通的函数指针,那么lambda 表达式本身的 this 指针就丢失掉了。而没有捕获任何外部变量的 lambda 表达式则不存在这个问题。
这里也可以很自然地解释为何按值捕获无法修改捕获的外部变量。因为按照 C++标准, lambda 表达式的
operator()默认是 const 的方法。一个 const 成员函数是无法修改成员变量的值的。而 mutable 的作用,就在于取消operator()的 const
需要注意的是,没有捕获变量的 lambda 表达式可以直接转换为函数指针,而有捕获变量的 lambda 表达式则不能转换为函数指针