【多任务】多任务学习在推荐算法中的应用
点击上方,选择星标,每天给你送干货!
文章作者:Alex-zhai
出品平台:DataFunTalk
导读:我们在优化推荐效果的时候,很多时候不仅仅需要关注 CTR 指标,同时还需要优化例如 CVR ( 转化率 )、视频播放时长、用户停留时长、用户翻页深度、关注率、点赞率这些指标。那么一种做法是对每个任务单独使用一个模型来优化,但是这样做的缺点显而易见,需要花费很多人力。其实很多任务之间都是存在关联性的,比如 CTR 和 CVR。那么能不能使用一个模型来同时优化两个或多个任务呢?其实这就是 Multi-task 多任务的定义。本文主要总结了近两年工业界关于 Multi-task 模型在推荐场景的一些应用和工作。
1. 阿里 ESMM
Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate
CVR 是指从点击到购买的转化,传统的 CVR 预估会存在两个问题:样本选择偏差和稀疏数据。

样本选择偏差是指模型用用户点击的样本来训练,但是预测却是用的整个样本空间。数据稀疏问题是指用户点击到购买的样本太少。因此阿里提出了 ESMM 模型来解决上述两个问题:主要借鉴多任务学习的思路,引入两个辅助的学习任务,分别用来拟合 pCTR 和 pCTCVR。
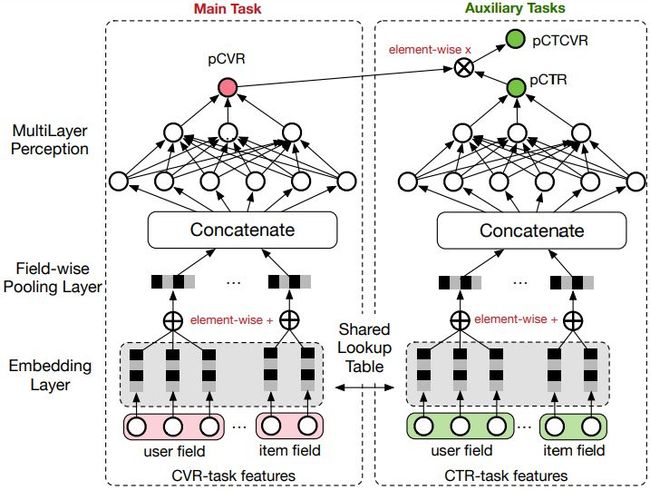
ESMM 模型由两个子网络组成,左边的子网络用来拟合 pCVR,右边的子网络用来拟合 pCTR,同时,两个子网络的输出相乘之后可以得到 pCTCVR。因此,该网络结构共有三个子任务,分别用于输出 pCTR、pCVR 和 pCTCVR。假设用 x 表示 feature ( 即 impression ),y 表示点击,z 表示转化,那么根据 pCTCVR = pCTR * pCVR,可以得到:
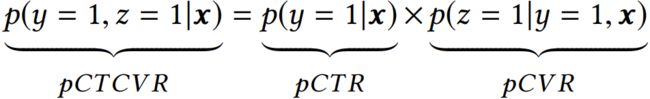
则 pCVR 的计算为:

由上面的式子可知,pCVR 可通过 pCTR 和 pCTCVR 推导出来,那么我们只需要关注 pCTR 和 pCTCVR 两个任务即可,并且 pCTR 和 pCTCVR 都可以从整个样本空间进行训练?为什么呢,因为对于 pCTR 来说可将有点击行为的曝光事件作为正样本,没有点击行为的曝光事件作为负样本,对于 PCTCVR 来说,将同时有点击行为和购买行为的曝光事件作为正样本,其他作为负样本。模型的 loss 函数:
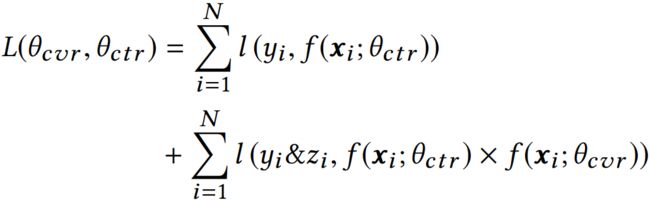
另外两个子网络的 embedding 层是共享的,由于 CTR 任务的训练样本量要远超过 CVR 任务的训练样本量,ESMM 模型中 embedding 层共享的机制能够使得 CVR 子任务也能够从只有展现没有点击的样本中学习,从而能够极缓解训练数据稀疏性问题。
2. 阿里 DUPN
Perceive Your Users in Depth: Learning Universal User Representations from Multiple E-commerce Tasks
多任务学习的优势:可共享一部分网络结构,比如多个任务共享一份 embedding 参数。学习的用户、商品向量表示可方便迁移到其它任务中。本文提出了一种多任务模型 DUPN:
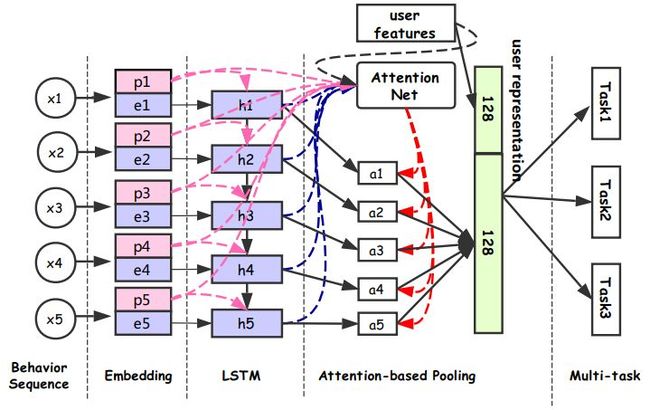
模型分为行为序列层、Embedding 层、LSTM 层、Attention 层、下游多任务层。
❶ 行为序列层:输入用户的行为序列 x = {x1,x2,...,xN},其中每个行为都有两部分组成,分别是 item 和 property 项。Item 包括商品 id 和一些 side-information 比如店铺 id、brand 等 ( 好多场景下都要带 side-information,这样更容易学习出商品的 embedding 表示 )。Property 项表示此次行为的属性,比如场景 ( 搜索、推荐等场景 ) 时间、类型 ( 点击、购买、加购等 )。
❷ Embedding 层:主要多 item 和 property 的特征做处理。
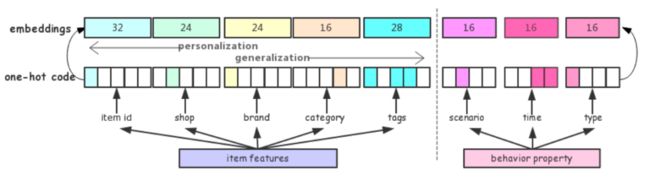
❸ LSTM 层:得到每一个行为的 Embedding 表示之后,首先通过一个 LSTM 层,把序列信息考虑进来。
❹ Attention 层:区分不同用户行为的重要程度,经过 attention 层得到128维向量,拼接上128维的用户向量,最终得到一个256维向量作为用户的表达。
❺ 下游多任务层:CTR、L2R ( Learning to Rank )、用户达人偏好 FIFP、用户购买力度量 PPP 等。
另外,文中也提到了两点多任务模型的使用技巧:
❶ 天级更新模型:随着时间和用户兴趣的变化,ID 特征的 Embedding 需要不断更新,但每次都全量训练模型的话,需要耗费很长的时间。通常的做法是每天使用前一天的数据做增量学习,这样一方面能使训练时间大幅下降;另一方面可以让模型更贴近近期数据。
❷ 模型拆分:由于 CTR 任务是 point-wise 的,如果有 1w 个物品的话,需要计算 1w 次结果,如果每次都调用整个模型的话,其耗费是十分巨大的。其实 user Reprentation 只需要计算一次就好。因此我们会将模型进行一个拆解,使得红色部分只计算一次,而蓝色部分可以反复调用红色部分的结果进行多次计算。
3. 美团 "猜你喜欢" 深度学习排序模型
根据业务目标,将点击率和下单率拆分出来,形成两个独立的训练目标,分别建立各自的 Loss Function,作为对模型训练的监督和指导。DNN 网络的前几层作为共享层,点击任务和下单任务共享其表达,并在 BP 阶段根据两个任务算出的梯度共同进行参数更新。网络在最后一个全连接层进行拆分,单独学习对应 Loss 的参数,从而更好地专注于拟合各自 Label 的分布。
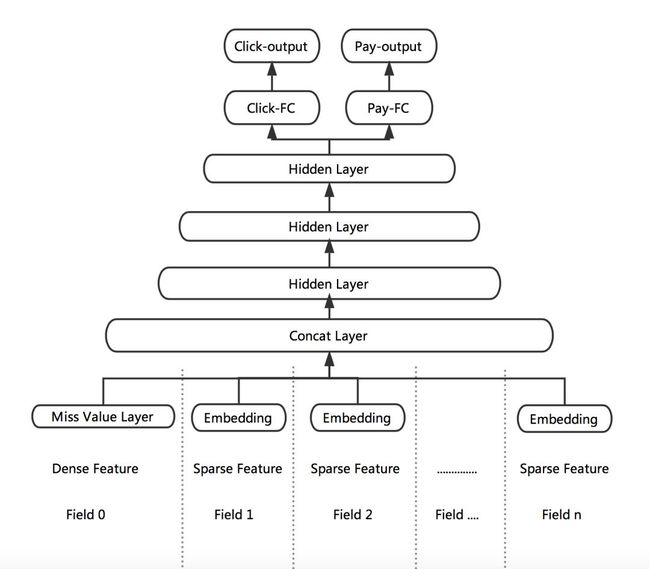
这里有两个技巧可借鉴下:
❶ Missing Value Layer:缺失的特征可根据对应特征的分布去自适应的学习出一个合理的取值。

❷ KL-divergence Bound:通过物理意义将有关系的 Label 关联起来,比如 p(点击) * p(转化) = p(下单)。加入一个 KL 散度的 Bound,使得预测出来的 p(点击) * p(转化) 更接近于 p(下单)。但由于 KL 散度是非对称的,即 KL(p||q) != KL(q||p),因此真正使用的时候,优化的是 KL(p||q) + KL(q||p)。
4. Google MMoE
Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
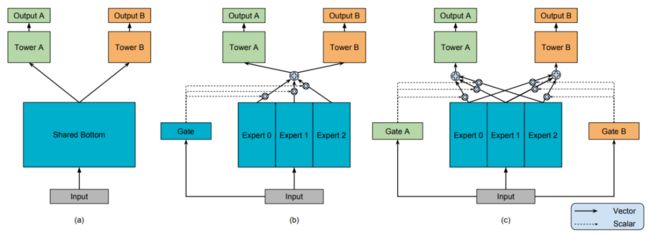
模型 (a) 最为常见,两个任务直接共享模型的 bottom 部分,只在最后处理时做区分,图 (a) 中使用了 Tower A 和 Tower B,然后分别接损失函数。
模型 (b) 是常见的多任务学习模型。将 input 分别输入给三个 Expert,但三个 Expert 并不共享参数。同时将 input 输出给 Gate,Gate 输出每个 Expert 被选择的概率,然后将三个 Expert 的输出加权求和,输出给 Tower。有点 attention 的感觉
模型 (c) 是作者新提出的方法,对于不同的任务,模型的权重选择是不同的,所以作者为每个任务都配备一个 Gate 模型。对于不同的任务,特定的 Gate k 的输出表示不同的 Expert 被选择的概率,将多个 Expert 加权求和,得到 fk(x) ,并输出给特定的 Tower 模型,用于最终的输出。
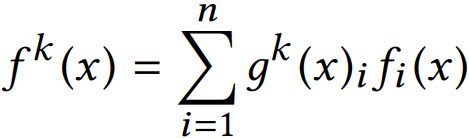
其中 g(x) 表示 gate 门的输出,为多层感知机模型,简单的线性变换加 softmax 层。
5. 阿里 ESM2
Conversion Rate Prediction via Post-Click Behaviour Modeling
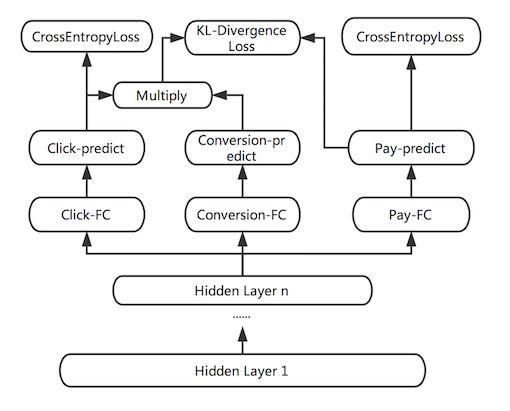
前面已经介绍过一种基于多任务学习的 CVR 预估模型 ESMM,但对于 CVR 预估来说,ESMM 模型仍面临一定的样本稀疏问题,因为 click 到 buy 的样本非常少。但其实一个用户在购买某个商品之前往往会有一些其他的行为,比如将商品加入购物车或者心愿单。如下图所示:
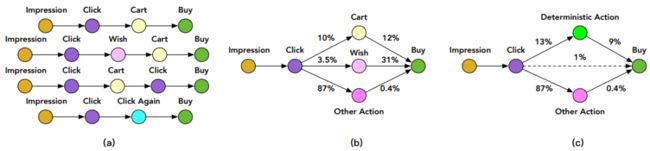
文中把加购物车或者心愿单的行为称作 Deterministic Action ( DAction ),表示购买目的很明确的一类行为。而其他对购买相关性不是很大的行为称作 Other Action ( OAction )。那原来的 Impression→Click→Buy 购物过程就变为:
Impression→Click→DAction/OAction→Buy 过程。
ESM2 模型结构:
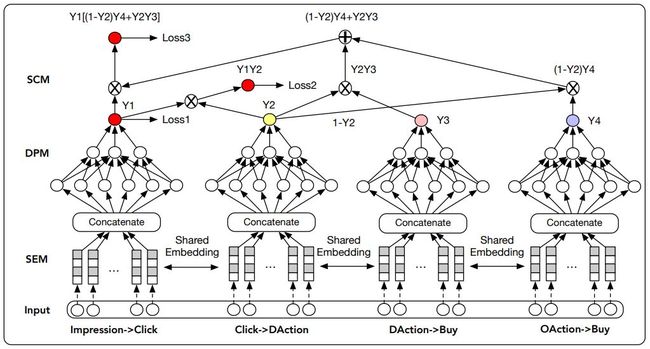
那么该模型的多个任务分别是:
❶ Y1:点击率
❷ Y2:点击到 DAction 的概率
❸ Y3:DAction 到购买的概率
❹ Y4:OAction 到购买的概率
并且从上图看出,模型共有3个 loss,计算过程分别是:
❶ pCTR:Impression→Click 的概率是第一个网络的输出。
❷ pCTAVR:Impression→Click→DAction 的概率,pCTAVR = Y1 * Y2,由前两个网络的输出结果相乘得到。
❸ pCTCVR:
Impression→Click→DAction/OAction→Buy 的概率,pCTCVR = CTR * CVR = Y1 * [(1 - Y2) * Y4 + Y2 * Y3],由四个网络的输出共同得到。其中 CVR=(1 - Y2) * Y4 + Y2 * Y3。是因为从点击到 DAction 和点击到 OAction 是对立事件。
随后通过三个 logloss 分别计算三部分的损失:
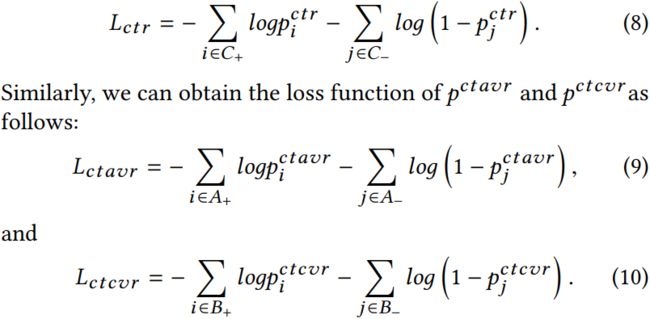
最终损失函数由三部分加权得到:
![]()
6. YouTube 多目标排序系统
Recommending What Video to Watch Next: A Multitask Ranking System
本文主要解决了视频推荐场景下普遍存在的两个问题:
❶ 视频推荐中的多任务目标。比如不仅需要预测用户是否会观看外,还希望去预测用户对于视频的评分,是否会关注该视频的上传者,否会分享到社交平台等。
❷ 偏置信息。比如用户是否会点击和观看某个视频,并不一定是因为他喜欢,可能仅仅是因为它排在推荐页的最前面,这会导致训练数据产生位置偏置的问题。
模型结构:
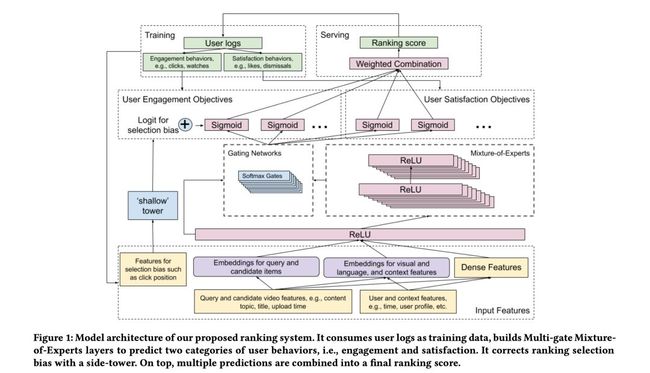
从上图可知,整个模型需要预测两大类目标,分别是:
❶ Engagement objectives:主要预测用户是否点击和观看视频的时长。其中通过二分类模型来预测用户的点击行为,而通过回归模型来预测用户观看视频的时长。
❷ Satisfaction objectives:主要预测用户在观看视频后的反馈。其中使用二分类模型来预测用户是否会点击喜欢该视频,而通过回归模型来预测用户对于视频的评分。
模型中有两个比较重要的结构:Multi-gate Mixture-of-Experts ( MMoE ) 和消除位置偏置的 shallow tower。
MMoE 的结构为:

Shallow tower 的结构为:

通过一个 shallow tower 来预测位置偏置信息,输入的特征主要是一些和位置偏置相关的特征,输出的是关于 selection bias 的 logits 值。然后将该输出值加到子任务模型中最后 sigmoid 层前,在预测阶段,则不需要考虑 shallow tower 的结果。值得注意的是,位置偏置信息主要体现在 CTR 预估中,而预测用户观看视频是否会点击喜欢或者用户对视频的评分这些任务,是不需要加入位置偏置信息的。
7. 知乎推荐页 Ranking 模型
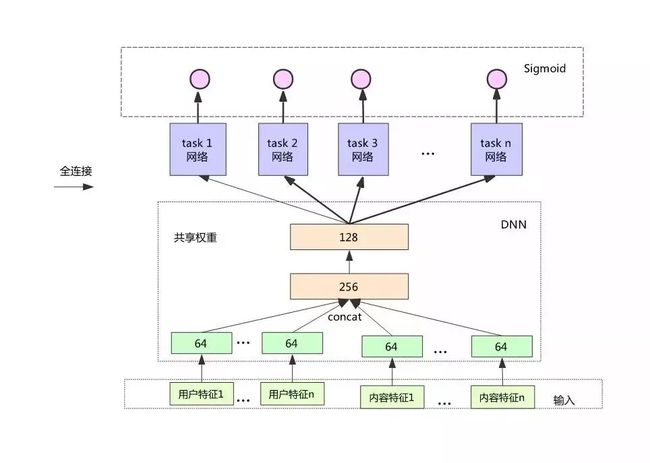
上图是知乎在推荐场景下使用的多目标模型,预测的任务包括点击率、收藏率、点赞率、评论率等,共 8 个目标。可以看出知乎的做法也是底层 embedding 和 DNN 前几层权重设置成共享。损失函数可设置成这几个 task 的简单线性加权和。上线后线上性能:点击率基本不变,而其他的几个指标,比如点赞,收藏大幅提升。
8. 美图推荐排序多任务
模型结构:

如上图,Multi-task NFwFM 模型的前几个隐层是共享的。在最后即将预估多个目标时通过全连接层进行拆分,各自学习对应任务的参数,从而专注地拟合各自任务。在线上预估时,因为模型尺寸没有变化,推理效率和线上的点击率预估模型一致。考虑到我们是在点击率任务的基础上同时优化关注转化率,融合公式上体现为优先按照点击率排序再按照曝光→关注的转化率排序。Multi-task NFwFM 已在美图秀秀社区首页 Feeds 推荐、相关推荐下滑流全量上线。首页 Feeds 点击率+1.93%,关注转化率+2.90%,相关推荐下滑流人均浏览时长+10.33%,关注转化率+9.30%。
9. 小结
当我们在推荐场景需要同时优化多个目标时,多任务学习就可以派上用场。那反过来思考一个问题,在什么样的情况下,多任务学习会没效果呢?其实也很容易想到,当多个任务的相关性没那么强时,这些任务之间就会相互扰乱,从而影响最后的效果。
最后总结下现在多任务学习模型的主要使用方式:
❶ 底层 embedding 和 mlp 参数共享,上层演化出各个任务的分支,最后 loss 函数是各个任务的简单加权和。
❷ 通过多任务之间的关系来建模出新的 loss 函数,比如阿里的 ESSM,ESSM2。
❸ 通过 Multi-gate Mixture-of-Experts ( MMoE ) 这种特殊的多任务结构来学习出不同任务的权重,比如 YouTube 的多任务模型。
参考链接:
https://arxiv.org/pdf/1804.07931.pdf
https://www.jianshu.com/p/35f00299c059
https://arxiv.org/pdf/1805.10727.pdf
https://www.jianshu.com/p/aba30d1726ae
https://tech.meituan.com/2018/03/29/recommend-dnn.html
https://zhuanlan.zhihu.com/p/70940522
https://arxiv.org/abs/1910.07099
https://www.jianshu.com/p/c06e9ed08dd1
https://www.jianshu.com/p/2f3dbbfc16a6
https://zhuanlan.zhihu.com/p/89401911
知乎推荐页 Ranking
原文链接:
https://zhuanlan.zhihu.com/p/78762586
https://zhuanlan.zhihu.com/p/91285359
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心![]() 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!