Python程序入口 __name__ == ‘__main__‘ 有重要功能(多线程)而非编程习惯
文章来源于互联网(https://jq.qq.com/?_wv=1027&k=rX9CWKg4)
在Python中,被称为「程序的入口」的 if name ==‘main’: 总是出现在各种示例代码中,有一种流传广泛的错误观点是「这只是Python的一种编码习惯」。事实上程序的入口非常有用,绝非可有可无,例如在Python自带的多线程库要求必须把主进程写在 if入口内部才能正常运行。
直接写在Python最左端没有缩进的代码,在这个 *.py 文件被直接运行、或者被调用时会被执行,只有写在 if name ==‘main’: if入口内部才不会在被调用时执行。Python用这个简单的方法来判断当前的模块是被直接运行还是被调用,这是很重要的功能,如:
- 我们可以把不想在被调用时执行的代码放在程序入口的if内部,比如自检程序。
- 我们还把多线程的主线程写在程序入口的if内部。只能这么做,避免自己调用自己时重复执行主进程,下面会详细解释。
因此,初学Python时,直接把主程序写在不需要缩进的位置,完全不写 if name ==‘main’: 当然可以。一个既没有写一个被调用的库的能力,也不一定要学多进程的新手,很容易错误地认为「程序的入口」没什么用。
类似的,还有被少数人误解的还有 Python的文件头:
#!/bin/bash/python3 # 这一句话用来在代码被执行时,主动说明该选哪个路径下的编译器
#!/bin/bash/python2 # 例如这一句就选了Python2,不过2020年Python2快要完成过渡使命了
2020年底,我在写Python多进程教程时,没有搜索到合适的文章解释“程序的入口 if name ==‘main’: 与多线程的必要联系”,反而看到了很多高赞的片面回答。无奈之下只能自己写。对于少数有基础的人,下面讲程序入口与多线程部分也值得一看。
目录
- 「程序的入口」是什么?
- 程序入口与自检程序
- 程序入口与多线程
更新日志
- 第一版 2021-01-01 我会把评论区的好问题更新到正文里
「程序的入口」是什么?
用很短的话就能解释,我认可菜鸟分析↓的回答 ,部分高赞答案写得啰嗦
name 是当前模块名,当模块被直接运行时模块名为 main 。这句话的意思就是,当模块被直接运行时,以下代码块将被运行,当模块是被导入时,代码块不被运行。
举例说明:当我在终端直接运行 python3 run1.py时,模块名被一律改为字符串__main__,当模块是被另一个 *.py程序导入(如在 *.py 中 import run1)而不是直接运行时,模块名是字符串run1。
在C语言和Java里也有类似的「程序入口」:
# Python的程序入口
if __name__ =='__main__': # 它对多进程非常重要
# 这里是主程序
# C语言的程序入口
void main(){
/* 这里是主程序 */
}
# Java的程序入口
public static void main(String[] args){
// 这里是主程序
}
检验一下自己:下面的程序会print出什么东西?
# 新建一个名为【run1.py】的文件,填入下方代码
# 然后在终端输入【python3 run1.py】并运行
print(__name__, 'run1-outside') # 它会print出【__main__ run1-outside】
if __name__ =='__main__':
print(__name__, 'run1-inside') # 它会print出【__main__ run1-inside】
再检验一下自己:
# 新建另一个名为【run2.py】的文件,填入下方代码,并放在与【run1.py】的相同目录下,
# 然后在终端输入【python3 run2.py】并运行。用run2 调用run1
import run1 # 这一行代码调用了外部的代码 run1,它只会print出:
# 【run1 run1-outside】 # 它只print出这一行东西,并且run1.py的【__main__】变成了【run1】
# 【run1 run1-inside】 # 写在run1【if】缩进里的东西都没有被执行
print(__name__, 'run2-outside') # 它会print出【__main__ run2-outside】
if __name__ =='__main__':
print(__name__, 'run2-inside') # 它会print出【__main__ run2-inside】
程序入口与自检程序
当一个开发者编写一个库时(例如把它命名为 utils.py),如
# 这个库(模块)被命名为 utils.py
class C1:
...
def func1():
...
c1 = C1() # 这是错误的做法,应该挪到 程序入口if内部
func1() # 这是错误的做法,应该挪到 程序入口if内部
if __name__ =='__main__':
c = C1()
func1()
当其他人只想调用 C1 或者 func1时,他在另一个Python文件中,用 import utils 导入 utils这个库时就不会运行程序入口if内部的任何代码了。
程序入口与多线程
实现多线程时,「程序入口」这个功能不可或缺。我需要同时运行多个 fun1,或者同时运行 fun1 fun2 … 如下:
def function1(id): # 这里是子进程
print(f'id {id}')
def run__process(): # 这里是主进程
from multiprocessing import Process
process = [mp.Process(target=function1, args=(1,)),
mp.Process(target=function1, args=(2,)), ]
[p.start() for p in process] # 开启了两个进程
[p.join() for p in process] # 等待两个进程依次结束
# run__mp() # 主线程不建议写在 if外部。由于这里的例子很简单,你强行这么做可能不会报错
if __name__ =='__main__':
run__mp() # 正确做法:主线程只能写在 if内部
当我运行上面这个程序,它的【name ==‘main’】,因此它会执行 【if】内的代码。这些代码会创建新的多个子进程,自己调用自己。在被调用的子进程中,它的【name】 不等于【main】,因此它只会执行被主进程分配的任务(比如fun1),而不会像主进程一样通过「程序入口」再调用别的进程(行此僭越之事)。这是一个非常重要的功能,这里讲的不仅是Python,其他成熟的编程语言也能用相似的方法。
RuntimeError: context has already been set(multiprocessing) #3492 PyTorch Issue
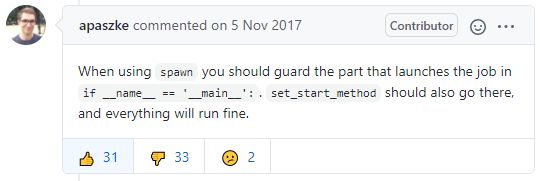
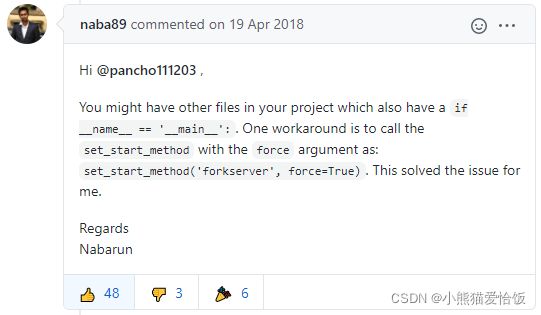
尽管有很多人点踩,但是这个分析是正确的。点踩的可能是其他原因引发了错误
尽管forkserver 依然不如 spawn更节省资源,但能解决问题也算不错了
由于我上面的例子过于简单(没有涉及进程通信、进程退出条件),如果你强行把主进程写在 if外部,也可能不会看到报错。这涉及很多因素,它与你使用的系统、子进程的创建方式(spwan、fork、forkserver、force=True/False)有关。我在这里只讲「程序的入口」,更多内容请移步
“ Compulsory usage of if name==“main” in windows while using multiprocessing - Stack Overflow ”
Tim Peters 与 David Heffernan 的回答都不错。
尽管Python的多进程已经做得挺不错了,希望随着以后版本的更新,多进程与「程序入口」的依赖关系应该能得到更好的解决。
使用PyTorch CUDA multiprocessing 的时候出现的错误 UserWarning: semaphore_tracker
(写于2021-03-03)
错误如下:
multiprocessing/semaphore_tracker.py:144:
UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown
len(cache))
Issue with multiprocessing semaphore tracking
相同问题描述:
“semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown len(cache)) #200”
解决方案:
Issue with multiprocessing semaphore tracking - sbelharbi 的解决方案
即在运行 .py 文件前,使用以下语句修改环境参数,忽略这个Warning 带来的程序暂停
export PYTHONWARNINGS='ignore:semaphore_tracker:UserWarning'
等同于在 .py 文件内部使用:
os.environ['PYTHONWARNINGS'] = 'ignore:semaphore_tracker:UserWarning'