基于SVM的车辆标牌识别
基于SVM的车辆标牌识别
目录
- 基于SVM的车辆标牌识别
-
-
- 1. **开发与使用**
-
- 1.1 **开发环境**
- 2. **程序功能及实现方法**
-
- 2.1 **读入原图**
- 2.2 **图像预处理**
-
- 2.2.1 **图像去噪**
- 2.2.2 **图像灰度化**
- 2.2.3 **边缘检测**
- 2.2.4 **图像二值化**
- 2.2.5**闭操作**
- 2.3**车牌识别**
-
- 2.3.1 **车牌定位**
- 2.3.2**字符分割**
- 2.3.3 **字符识别**
- 3. **实验结果及分析**
-
- 3.1 **结果演示**
- 3.2 **结果分析**
-
话不多说,先附上源代码。
1. 开发与使用
1.1 开发环境
系统环境:Linux
开发语言:Python3 、PyQt5
编程环境:VsCode/PyCharm 、QtDesigner
其他所需:OpenCV 4.4.0 、Scikit-learn 0.23.2
2. 程序功能及实现方法
2.1 读入原图
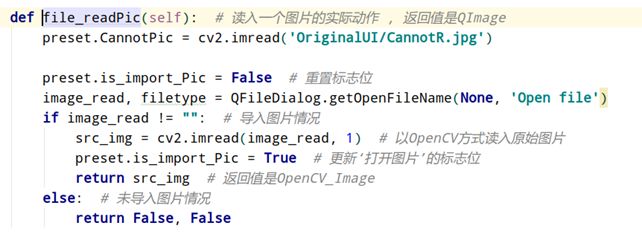
我们首先使用PyQt获取将要读取的文件的路径,接着使用OpenCV方式读入图片,也就是使用imread函数读入进来。读入的图片是以opencv的格式进行存储,读入图片的函数是直接嵌入到我们框架读入图片操作区域的。在读入图片以后会进行图片的备份,接着调用适配图像展示控件的大小的函数进行缩放大小的操作。保证最终显示的图片的尺寸与我们控件的大小相匹配。
2.2 图像预处理
2.2.1 图像去噪
去噪模块中,一共提供了6种去噪方法,分别为高斯滤波、中值滤波、均值滤波、方框滤波、双边滤波、非锐化滤波,调用OpenCV相应的API既可以实现,系统默认帮用户选择了均值滤波,用户也可以自己选择滤波方式,满足自己的需求。
2.2.2 图像灰度化
灰度化模块中,一共提供了5种灰度化方法,分别为默认灰度化、平均值法、最大值法、分量法、加权平均法,其中,默认灰度化直接调用OpenCV 的函数cvtColor即可实现,其他灰度化操作需要遍历图像,并进行运算才可得到,系统默认帮用户选择默认灰度化的方法,用户也可以自己选择灰度化方式,满足自己的需求。
2.2.3 边缘检测
在边缘检测这一部分,我们一共拥有4中边缘检测的方法。除了我们预设的方案外,便于用户进行选择特定场景下的解决方案。这四个边缘检测的方法分别是:Robert算法、Prewitt算子、Sobel算子和拉普拉斯算法。这些算法全部使用矩阵进行构造并实现。用户可以根据他们的实际情况选择合适的算法。

2.2.4 图像二值化
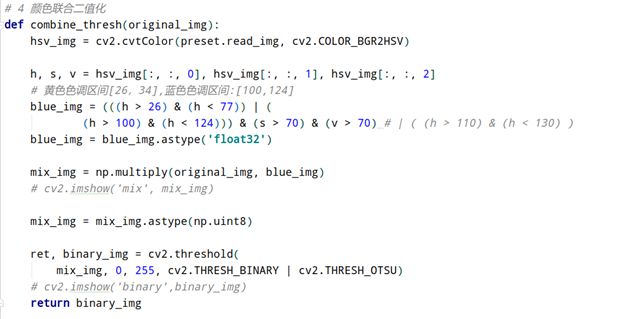
由于不同颜色的车牌可能需要的二值化方案不一致,我们一共提供了四种二值化的解决方法。其中手动二值化为了便于我们测试并不对用户进行公开,用户可以使用的二值化算法一共有:自适应二值化算法、OTSU二值化算法和我们的颜色联合二值化算法。其中颜色联合二值化算法针对黄色车牌和蓝色车牌进行专门的是配,使用HSV颜色模型去定位车牌的具体位置后调用相应的函数进行计算,使对于各种情况下的蓝色车牌的检测成功率更上了一个台阶。
2.2.5闭操作
对于闭操作我们参考了网上对于这一块参数的选择,并且摸索出了最佳的参数组合。使得我们在进行完闭操作之后对于车牌的部分可以较为清楚的看到其轮廓,对于别的部分则是黑的较多。这样可以为我们之后的字符定位提供更加精确的信息。

2.3车牌识别
2.3.1 车牌定位
车牌定位是对预处理后的图像信息进行进一步操作从而得到车牌图像的过程。对预处理后的图像使用findContours函数,找出所有可能为车牌的轮廓,使用minAreaRect函数得到所有轮廓的最小外接矩形。由于我国的车牌有着统一的规划标准,因此我们根据车牌的相关参数可以对疑似车牌的最小外接矩形,进行面积、比例、颜色的筛选进而得到一个更接近车牌的旋转矩阵。我们使用漫水填充法对得到的旋转矩阵进行进一步的颜色填充,若目标填充完成后的最小外接矩形的比例、面积、颜色仍符合车牌的规范则可以将其认定为车牌。
在定位的过程中使用漫水填充法的目的是为了进一步的确定车牌,细化车牌范围同时也能拍出一些非车牌的伪目标。在对车牌进行校正时根据几何关系求得车牌的实际四点坐标,通过透视变换进一步得到拉伸调整后图像,方便下一步字符分割。
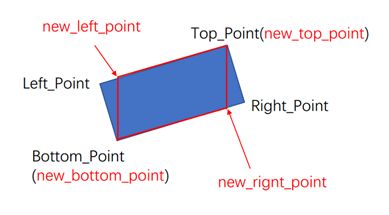
如图,坐标Left_Point、Right_Point、Top_Point、Bottom_Point为车牌最小外接矩形的四个顶点坐标,而实际车牌坐标为new_left_point、new_top_point、new_bottom_point、new_right_point。我们可以通过Bottom_Point与Right_Point两点确定一条直线方程,从而带入Top_Point的x坐标以得到new_right_point的y值坐标,此处认为new_right_point的x坐标与Top_Point的一致。其余四点坐标都可以以类似方法求得。得到车牌的实际四点坐标即可使用透视变换从而一定程度上的校正车牌。

2.3.2字符分割
字符分割是对车牌定位得到的车牌中的字符进行分割,得到一个图像只有一个字符的结果。在字符分割过程中对车牌中汉字后的"点"进行一定的判断从而剔除掉,得到符合车牌字符位数且只含汉字、字母、数字的图像。得到分割后的字符后便于下一步识别使用。

![]()
![]()
a.车牌图像 b.Y投影剔除边框后 c.X投影字符分割结果
将上一步得到的车牌进行二值化,字符部分的像素为255,背景为0。在字符分割过程中使用投影法,先进行Y轴投影,将所有的字符的水平像素个数投影到垂直方向,根据得到的投影像素个数数组,使用一定的阈值对车牌中的垂直区域进行分割。通过投影Y轴的方式可有效的将车牌的上下边框以及可能会有的"钉子"去掉。从而方便下一步的X轴投影。在进行X轴投影时,使用类似的方法对垂直方向上的所有像素投影个数至水平方向,从而确定出多个连续区域,这些个连续区域即为字符的水平区域,按照此区域即可分割出字符。
在进行字符分割时,对于汉字后"点"的处理,此处采用遍历所有字符,先对其宽度进行判断,若宽度符合字符宽度则进一步对其像素个数进行判断,若该字符的宽度、面积均不符合一个非"点"字符的要求则将该字符认为成"点"并从结果字符集中剔除。若此举仍未能剔除"点",出现结果字符比实际车牌的字符多一个时,对结果字符的宽度进行遍历去掉最小宽度的点即可。
由于字符分割过程中可能会出现左右结构的"川"、"浙"等左右结构的字符分割失败的情况,对X投影后的字符的可能取值范围进行遍历。规定好一个字符特定的宽度,遍历过程中如果发现单个字符宽度不符合目标字符宽度规定,将2个或3个字符合起来的宽度与一个字符的宽度进行比对,若相差不大则认定为一个字符,并对这2个或3个字符进行合并。

2.3.3 字符识别
OpenCV提供了matchTemplate函数,可以进行模板匹配,从而实现字符识别。但经尝试,该函数的识别正确率并不高,因此采用SVM(支持向量机)来实现字符识别。使用SVM进行识别时,需要先训练,后识别。
①训练部分
A. 训练需要到大量样本,因次事先在网上下载好样本。
B. 训练部分关键代码相关说明
训练前将样本集合中的图像导入,放入一个元组中,同时对应将标签存放在另一个元组中。训练时用到了Sklearn提供的三个关键函数:
SVC函数构造训练模型,函数参数中C为惩罚系数,C越大表示惩罚越多,即条件更苛刻,kernel为核函数,可选择linear、rbf等作为核函数,probability为bool型参数,决定是否启用概率估计,且必须在fit函数前启用,fit函数的运行速度也会随之变慢,其他参数可详查资料。
-
sklearn.svm.SVC(C=1,kernel=‘rbf’,degree=3,gamma=‘auto’,coef0=0.0,shrinking=True,probability=False,tol=0.001,cache_size=200,class_weight=None,verbose=False,max_iter=-1,decision_function_shape=None,random_state=None)
-
sklearn.cross_validation.cross_val_score(estimator,X,y=None,scoring=None,cv=None,n_jobs=1,verbose=0,fit_params= None, pre_dispatch=‘2*n_jobs’)
-
fit(x,y,batch_size=32,epochs=10,verbose=1,callbacks=None,validation_split=0.0,validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0)
Cross_val_score函数会将训练集划分成n份,其中n-1份用来训练,剩余一份用于测试。参数中estimator为模型,X为训练样本的元组(最开始已经得到),y为标签元组,cv为传入的折数,返回值为精确度。
fit函数是用来训练模型的函数,具体参数已经在定义SVC对象的时候给出了,这时候只需要给出数据集X和X对应的标签y即可。
需要注意的是,训练样本集合越大,则训练的时间会越长,训练过程中需要耐心等待。写代码时,在训练完成之后,记得将训练结果保存在文件中,可导入joblib包来辅助完成。


②识别部分
在将SVM用于实践前,应该先导入之前的训练结果,需要注意的是,如果别人需要使用改训练结果时,需要尽量保持同样的Scikit-learn版本,否则可能会产生不能使用的情况。
识别使用到的一个关键函数为predict函数,predict函数用作将训练好的分类器用于预测当前字符的标签,返回值即为标签值。此处需要注意的是,Sklearn提供了另外一种预测标签值的predict_proba函数,但是predict_probe函数的返回值为元组,元组内容为对各个类的样本预测的概率值集合,并按顺序排列,需要后续操作才可得到标签值。
实验代码中,识别字符的Distinguish函数入口参数为模型路径和一个存放分割好的字符的元组,出口参数为一个存放车牌内容的字符串。

3. 实验结果及分析
3.1 结果演示
①在项目文件夹中找到main.py文件,并运行main.py文件
②运行程序后进入主界面
③导入图像并选择所需的预处理方案
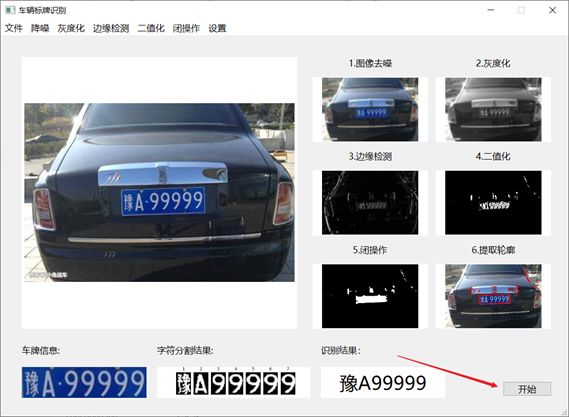
④点击"开始"按钮,即可识别出结果
3.2 结果分析
首先我们必须知道,即使是专业的小区门禁车牌识别系统,他们的识别距离根据相关的配套文档 也不过是3~4米开外的区间才能够进行有效的识别。对于这个区间的车辆经过摄像头的拍摄,其实车牌的倾斜角度并没有想象中的那么斜。这对现在的车牌矫正算法会产生相应的影响。
经过较为多的测试后发现,对于倾斜角度较为大的车牌,我们大系统虽然加上了矫正的函数,但是效果仍旧是不理想。不过我们在之前说过,这种角度的车牌照片一般是不会出现在真实的车牌识别系统中的。所以我们在这个里先不讨论这种情况。
对于正确拍摄的车牌,我们发现,"川"这类带有"欺骗性质"的非联通区域的字符极易对我们的系统产生干扰。不过经过我们使用更多的算法,包括使用面积进行更多的判断后使得这部分的检测成功率有了较大的提升。遗憾的是,这种车牌在陕西比较少见,所以我们只能在网上进行查找,导致无法进行更细致的检测。
对于某些车牌,比如绿色的车牌。在识别的准确度上会有所下降。原因初步分析可能是由于绿色的车牌是渐变色,导致二值化后的区域不完全包括车牌的全部部分。导致无法进行字符的分割,进而无法识别。
对于正常拍摄的车牌号码。我们同样使用面积进行过滤,去掉了最终的点。