【文献阅读】VQA的综述:方法和数据集(Q. Wu等人,Computer Vision and Image Understanding,2017)
一、文章背景
文章题目:《Visual question answering: A survey of methods and datasets》
这篇文章算是早期比较经典的VQA综述之一了。作者是来自沈春华老师团队。
文章下载地址:https://www.sciencedirect.com/science/article/pii/S1077314217300772
文章引用格式:Q. Wu, D. Teney, P. Wang, et al. "Visual question answering: A survey of methods and datasets." Computer Vision and Image Understanding, vol, 163, pp: 21-40, 2017.
项目地址:无
二、文章导读
先看下文章的摘要:
Visual Question Answering (VQA) is a challenging task that has received increasing attention from both the computer vision and the natural language processing communities. Given an image and a question in natural language, it requires reasoning over visual elements of the image and general knowledge to infer the correct answer. In the first part of this survey, we examine the state of the art by comparing modern approaches to the problem. We classify methods by their mechanism to connect the visual and textual modalities. In particular, we examine the common approach of combining convolutional and recurrent neural networks to map images and questions to a common feature space. We also discuss memory-augmented and modular architectures that interface with structured knowledge bases. In the second part of this survey, we review the datasets available for training and evaluating VQA systems. The various datatsets contain questions at different levels of complexity, which require different capabilities and types of reasoning. We examine in depth the question/answer pairs from the Visual Genome project, and evaluate the relevance of the structured annotations of images with scene graphs for VQA. Finally, we discuss promising future directions for the field, in particular the connection to structured knowledge bases and the use of natural language processing models.
文章主要分了三部分,第一部分对现有的方法进行比较,根据他们的机制进行分类;第二部分是对数据集进行评价;第三部分是对未来的展望。
三、文章详细阅读
因为这篇文章比较早了,introduction部分的内容很多都有了新的发展,所以就直接介绍方法和数据集部分。
1. VQA的方法
所有的VQA方法可以按下表的方式分为4类:
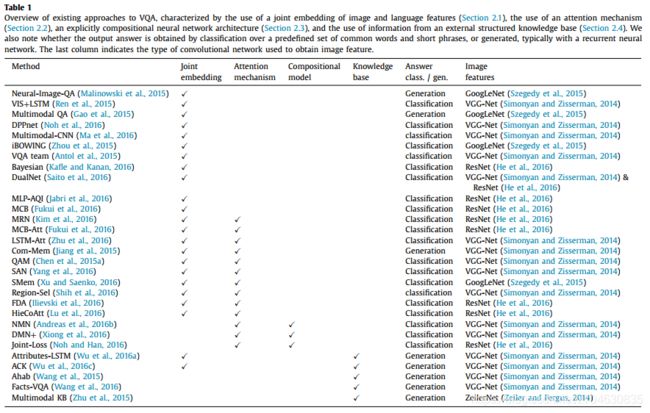
(1)联合嵌入法:Joint embedding approaches
动机:来源于深度学习的NLP的发展。相较于看图说话,VQA则多了一步在两个模态间的进一步推理过程。一般的,图像表示(image representations)用预训练的CNN模型,文本表示(Text representations)用预训练的词嵌入。词嵌入就是将单词映射到空间中,距离来度量语义相似度,然后将嵌入送到RNN中来处理语法和句子。
方法:Malinowski et al等人【1】提出了“Neural-Image-QA”模型。文本特征用加入了LSTM的RNN来处理,图像特征用预训练的CNN来处理,然后将两个特征同时输入到第一个编码器LSTM中,再将生成的向量输入到第二个解码器LSTM中,最后会生成一个变化长度的答案,每次迭代产生一个单词,知道产生

Gao et al等人【3】提出了“Multimodal QA”模型,用LSTM来编码问题和生成答案。首先,LSTM的编码器和解码器共享权重;其次,在每一步中,CNN提取的图像特征都先于问题传入到编码器。
Noh et al等人【4】用DPPnet来提取图像特征。这里采用了一个由GRU单元组成的parameter prediction network,来处理问题特征,同时用全连接层生成权值作为输出。
Fukui et al等人【5】提出了一个池化的方法来嵌入两个特征,称之为“Multimodal Compact Bilinear pooling(MCB)”。它随机投影图像特征和文本特征到高维空间,然后两个向量的卷积可以在傅里叶空间中相乘处理。另外还有Kim et al等人【6】使用MRN(multimodal residual learning framework多模态残差学习网络)来学习两种特征的联合表示。Saito et al等人【7】提出了“DualNet”来整合两种操作,即两个特征对应元素相加和相乘。
还有其他一些研究并没有用RNN来提取问题特征,比如Ma et al等人【8】用CNN提取两种特征,然后将其通过multimodal CNN层嵌入到相同的空间中。
性能及缺陷:联合嵌入法非常直接,是目前大多数VQA的基础,该方法目前还有很大的提升空间。
(2)注意力机制:Attention mechanisms
动机:上面提出的模型,在视觉特征输入这里,都是提取的全局特征作为输入,会产生一些无关或者噪声信息来影响输出,而attention机制就是利用局部特征来解决这个问题。
方法:Zhu et al等人【9】介绍了如何将注意力引入到LSTM当中。Chen et al等人【10】用了问题导向注意力映射“question-guided attention map”,它在图像的特征图中搜索与问题语义相对应的视觉特征。Yang et al等人【11】使用了叠加的注意力机制网络“stacked attention networks(SAN)”,来迭代推断答案。Xu et al等人【12】提出了“multi-hop image attention scheme”(SMem),先用单词导向的注意力,然后用问题导向注意力。Lu et al等人【13】提出了“hierarchical co-attention model” (HieCoAtt),结合图像和视觉注意力。Fukui et al等人【5】将注意力机制结合到了“Multimodal Compact Bilinear pooling”(MCB)中。
性能及缺陷:注意力机制能够改善提取全局特征的模型性能。最近的研究表明,注意力机制尽管能够提高VQA的总体精度,但是对于二值类问题却没有任何提升,一种假说是二值类问题需要更长的推理,这类问题的解决还需要进一步研究。
(3)合成模型:Compositional Models
这种方法是对不同模块的连接组合,优点是可以更好的进行监督。一方面,能够方便转换学习,另一方面能够使用深度监督“deep supervision”。这里主要讨论的合成模型有两个,一个是Neural Module Networks (NMN),另一个是Dynamic Memory Networks (DMN)。
Andreas et al等人【14】提出了Neural Module Networks (NMN),NMN的贡献在于对连续视觉特征使用了逻辑推理,而替代了离散或逻辑预测。模型的组成如下所示:

模型的输入和输出一共有三类:图像,图像注意力区域,标签。该方法比传统方法能更好的进行推理,处理更长的问题。但是局限性在于问题解析这里出现了瓶颈,此外,模块结合采用问题简化的方式,这就忽略了一些语法线索。
Xiong et al等人【15】将Dynamic Memory Networks (DMN)用于VQA,模型由四个独立的模块组成,输入模块(input module)将输入的数据转化为向量,问题模块(question module)使用GRU计算问题的向量表达,插入式记忆模块(episodic memory module)检索问题的答案,答案模块(answer module)预测模型输出。该模型相较于NMN模型,在二值类问题的结果上表现类似,在数学问题上表现稍差一些,但是其他类型的问题都能显著提高。
(4)使用外部知识的模型:Models using external knowledge bases
动机:VQA在理解图像内容时,经常需要一些非视觉的先验信息,涉及范围可以从常识到专题,目前已有的外部知识库包括:DBpedia、Freebase、YAGO、OpenIE、NELL、WebChild、ConceptNet。
方法:Wang et al等人【16】提出了基于DBpedia的VQA网络命名为“Ahab”,首先用CNN提取视觉概念,然后结合DBpedia中相似的概念,再学习image-question到queries的过程,通过总结查询结果来获得最终答案。还有一种基于该方法的改进模型,叫FVQA。Wu et al等人【17】提出了一种利用外部知识的联合嵌入法,首先用CNN提取图像的语义属性,然后从DBpedia检索相关属性的外部知识,将检索到的知识用Doc2Vec嵌入到词向量中,最后将词向量传入到LSTM网络,对问题进行解释并生成答案。
性能和缺陷:一个问题就是这些模型的问题类型都有限。
2. VQA的数据集
之前有过一篇文章专门介绍了VQA的数据集,然后我将这篇文章中的数据集全部补充了上去,具体参见:【数据集收集】用于视觉问答VQA常用的数据集。
3. VQA的展望
VQA模型目前的一些限制,比如多选问题,答案过短,问题类型较少等,还需要进一步克服。另外,目前现有的数据集大多是人工标注或者通过看图说话的方法半自动生成,同时施加一定的约束,比如限制图像区域,目标,问题类型等。这样收集数据会存在一些问题,首先是数据的复杂度的程度(level of complexity)和涉及到的事实数量(number of facts involved);其次是需要理解的视觉和文本数量之比;第三是外部先验知识数量。
外部知识(External knowledge):目前基于外部知识的VQA还有很多限制,比如只能处理一些类型的问题、问题编码过程中可能会产生无关信息。
文本的问答(Textual question answering):常用的方法有两种,一种是信息检索(information retrieval)、另外一种是外部知识语义解析(semantic parsing coupled with knowledge bases)。
四、小结
相关参考文献:
【1】M. Malinowski, M. Rohrbach, and M. Fritz. Ask Your Neurons: A Neural-based Approach to Answering Questions about Images. In Proc. IEEE Int. Conf. Comp. Vis., 2015
【2】M. Ren, R. Kiros, and R. Zemel. Image Question Answering: A Visual Semantic Embedding Model and a New Dataset. In Proc. Advances in Neural Inf. Process. Syst., 2015.
【3】H. Gao, J. Mao, J. Zhou, Z. Huang, L. Wang, and W. Xu. Are You Talking to a Machine? Dataset and Methods for Multilingual Image Question Answering. In Proc. Advances in Neural Inf. Process. Syst., 2015.
【4】H. Noh, P. H. Seo, and B. Han. Image Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2016
【5】A. Fukui, D. H. Park, D. Yang, A. Rohrbach, T. Darrell, and M. Rohrbach. Multimodal compact bilinear pooling for visual question answering and visual grounding. arXiv preprint arXiv:1606.01847, 2016
【6】J.-H. Kim, S.-W. Lee, D.-H. Kwak, M.-O. Heo, J. Kim, J.-W. Ha, and B.-T. Zhang. Multimodal residual learning for visual qa. arXiv preprint arXiv:1606.01455, 2016.
【7】K. Saito, A. Shin, Y. Ushiku, and T. Harada. Dualnet: Domain-invariant network for visual question answering. arXiv preprint arXiv:1606.06108, 2016
【8】L. Ma, Z. Lu, and H. Li. Learning to Answer Questions From Image using Convolutional Neural Network. In Proc. Conf. AAAI, 2016.
【9】Y. Zhu, O. Groth, M. Bernstein, and L. Fei-Fei. Visual7W: Grounded Question Answering in Images. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2016
【10】K. Chen, J. Wang, L.-C. Chen, H. Gao, W. Xu, and R. Nevatia. ABC-CNN: An Attention Based Convolutional Neural Network for Visual Question Answering. arXiv preprint arXiv:1511.05960, 2015
【11】Z. Yang, X. He, J. Gao, L. Deng, and A. Smola. Stacked Attention Networks for Image Question Answering. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2016
【12】H. Xu and K. Saenko. Ask, Attend and Answer: Exploring Question-Guided Spatial Attention for Visual Question Answering. arXiv preprint arXiv:1511.05234, 2015
【13】J. Lu, J. Yang, D. Batra, and D. Parikh. Hierarchical question-image co-attention for visual question answering. arXiv preprint arXiv:1606.00061, 2016
【14】J. Andreas, M. Rohrbach, T. Darrell, and D. Klein. Neural Module Networks. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2016
【15】C. Xiong, S. Merity, and R. Socher. Dynamic memory networks for visual and textual question answering. In Proc. Int. Conf. Mach. Learn., 2016.
【16】P. Wang, Q. Wu, C. Shen, A. v. d. Hengel, and A. Dick. Explicit knowledge-based reasoning for visual question answering. arXiv preprint arXiv:1511.02570, 2015
【17】Q. Wu, P. Wang, C. Shen, A. Dick, and A. v. d. Hengel. Ask Me Anything: Free-form Visual Question Answering Based on Knowledge from External Sources. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2016