<数据结构>还不会写单向链表?我手把手教你
文章目录
- 1.链表概况
-
- 1.1 链表的概念及结构
- 1.2 链表的分类
- 2. 单向链表的实现
-
- 2.1 SList.h(头文件的汇总,函数的声明)
- 2.2 SList.c(函数的具体实现逻辑)
-
- 2.2.1 打印链表
- 2.2.2 搞出一个新节点(为其他函数服务)
- 2.2.3 链表尾插
- 2.2.4 链表头插
- 2.2.5 链表尾删
- 2.2.6 链表头删
- 2.2.7 查找节点
- 2.2.8 在pos位置之前插入
- 2.2.9 在pos位置之后插入
- 2.2.10 删除pos位置
- 2.2.11 删除pos之后位置
- 2.2.12 链表销毁
1.链表概况
1.1 链表的概念及结构
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。

1.2 链表的分类
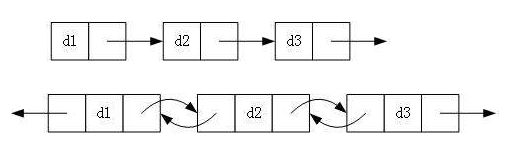
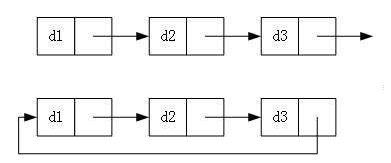
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构
-
单向或者双向
-
带头或者不带头

-
循环或者非循环
虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构
- 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
- 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们代码实现了就知道了
2. 单向链表的实现
单向链表结构

2.1 SList.h(头文件的汇总,函数的声明)
#pragma once
#include2.2 SList.c(函数的具体实现逻辑)
2.2.1 打印链表
//打印
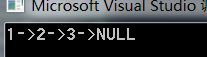
void SListPrint(SListNode* phead)
{
//assert(phead);//没必要断言,空链表也能打印
SListNode* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
//test.c
void TestSList1()
{
SListNode* slist;//结构体指针,用于存节点的地址
SListNode* n1 = (SListNode *)malloc(sizeof(SListNode));
SListNode* n2 = (SListNode*)malloc(sizeof(SListNode));
SListNode* n3 = (SListNode*)malloc(sizeof(SListNode));
n1->data = 1;
n2->data = 2;
n3->data = 3;
n1->next = n2;
n2->next = n3;
n3->next = NULL;
slist = n1;
SListPrint(slist);
}

2.2.2 搞出一个新节点(为其他函数服务)
//搞出一个新节点
SListNode* BuySListNode(SLTDataType x)
{
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));
if (newnode == NULL)
{
printf("malloc fail\n");
exit(-1);
}
else
{
newnode->data = x;
newnode->next = NULL;
}
return newnode;
}
2.2.3 链表尾插

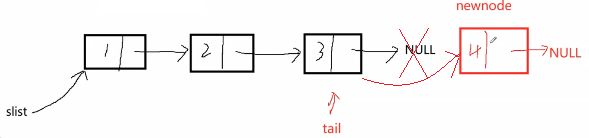
//尾插
void SListPushBack(SListNode** pphead,SLTDataType x)//会改变实参slist,要传二级指针
{
assert(pphead);//就算链表是空,它的二级指针也不为空
SListNode* newnode = BuySListNode(x);
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
//遍历找尾
SListNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}
void TestSList2()
{
SListNode* slist = NULL;
for (int i = 0; i < 6; i++)
{
SListPushBack(&slist,i);
}
SListPrint(slist);
}
2.2.4 链表头插

//头插
void SListPushFront(SListNode** pphead, SLTDataType x)
{
assert(pphead);//就算链表是空,它的二级指针也不为空
SListNode* newnode = BuySListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
void TestSList2()
{
SListNode* slist = NULL;
for (int i = 0; i < 6; i++)
{
SListPushFront(&slist,i);
}
SListPrint(slist);
}

2.2.5 链表尾删
方法1(用两个指针,分别找最后一个和倒数第二个):

方法2(直接找倒数第二个):

//尾删
void SListPopBack(SListNode** pphead)//如果只有一个节点但还要尾删,就会改变实参slist,建议传二级指针
{
assert(pphead);//就算链表是空,它的二级指针也不为空
//三种情况:
//1.空
//2.一个节点
//3.多个节点
if (*pphead == NULL)
{
return;
}
else if ((*pphead)->next == NULL)//优先级,记得加括号
{
free(*pphead);
*pphead = NULL;
}
//第一种写法(用两个指针,分别找最后一个和倒数第二个)
else
{
SListNode* prev = NULL;//找倒数第二个元素,用于将它指向NULL
SListNode* tail = *pphead;//找尾
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
tail = NULL;//习惯性free掉就将其置空
prev->next = NULL;
}
//方法二(直接找倒数第二个)
//else
//{
//SListNode* tail = *pphead;//找尾
//while (tail->next->next != NULL)
//{
// tail = tail->next;
//}
//free(tail->next);
//tail->next = NULL;
//}
}
2.2.6 链表头删

//头删
void SListPopFront(SListNode** pphead)
{
assert(pphead);
//1.空
//2.非空
if (*pphead == NULL)
{
return;
}
else
{
SListNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
}
2.2.7 查找节点
//查找
SListNode* SListFind(SListNode* phead, SLTDataType x)
{
SListNode* cur = phead;
while (phead != NULL)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
2.2.8 在pos位置之前插入

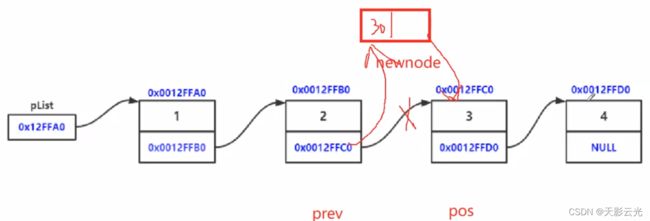
//在pos位置之前插入(一般跟find配合使用)
void SListInsert(SListNode** pphead, SListNode* pos, SLTDataType x)
{
assert(pphead);
assert(pos);//间接检测链表是否为空,因为空链表找不到pos
//1.pos是第一个节点(头插)
//2.pos不是第一个节点
if (pos == *pphead)
{
SListPushFront(pphead, x);
}
else
{
SListNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
SListNode* newnode = BuySListNode(x);
prev->next = newnode;
newnode->next = pos;
}
}
2.2.9 在pos位置之后插入
方法1:两个指针,先连接pos和newnode还是先连接newnode和next都行
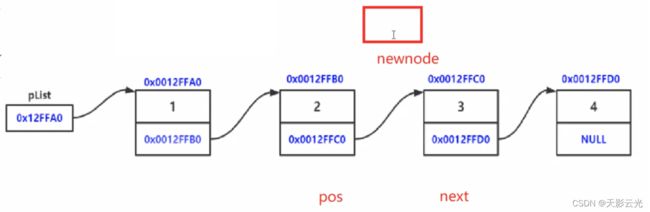
方法2:只有一个指针,一定要先通过pos连接newnode和下一个,再连接pos和newnode,否则会找不到下一个的地址。

//在pos位置之后插入
void SListInsertAfter(SListNode* pos, SLTDataType x)
{
assert(pos);
SListNode* newnode = BuySListNode(x);
SListNode* next = pos->next;
newnode->next = next;//顺序无所谓
pos->next = newnode;
//或者不定义next
//newnode->next = pos->next;
//pos->next = newnode;//顺序要定好,否则会找不到
}
2.2.10 删除pos位置

//删除pos位置
void SListErase(SListNode** pphead, SListNode* pos)
{
assert(pphead);
assert(pos);
if (pos == *pphead)
{
SListPopFront(pphead);
}
else
{
SListNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
pos = NULL;//好习惯
}
}
2.2.11 删除pos之后位置
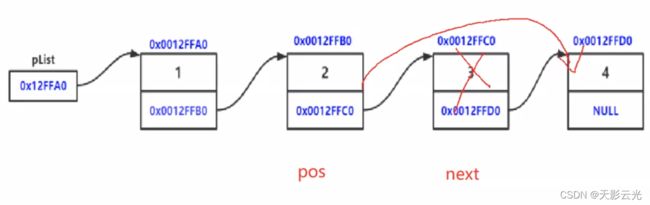
//删除pos之后位置
void SListEraseAfter(SListNode* pos)
{
assert(pos);
SListNode* next = pos->next;
if (next)//防止pos是最后一个元素
{
pos->next = next->next;
free(next);
next = NULL;
}
}
2.2.12 链表销毁
一个个找,一个个销毁,最终将slist置空。
//销毁
void SListDestroy(SListNode** pphead)
{
assert(pphead);
SListNode* cur = *pphead;
while (cur)
{
SListNode* next = cur->next;
free(cur);
cur = next;
}
*pphead = NULL;
}
总结:
单链表结构,适合头插头删。尾部或者中间某个位置插入删除不适合。
如果要使用链表单独存储数据,那我们之后会学的双向链表更合适。
单链表学习的意义:
- 单链表会作为我们之后学习复杂数据结构的子结构(图的邻接表、哈希桶)
- 单链表会出很多经典的练习题。
链表系列有很多重点内容,我会花不少时间来跟大家讲解链表,相信大家跟着练习的话编程严谨性会大大提升,加油哦!
CSDN社区 《创作达人》活动,只要参与其中并创作文章就有机会获得官方奖品:精品日历、新程序员杂志,快来参与吧!链接直达 https://bbs.csdn.net/topics/605272551