PIL、CV2、numpy.darray、pyTorch图像数据接口之间相互转换总结
之前遇到PIL、CV2、MATLAB、pyTorch格式读入的图片,总是傻傻分不清,现在特地总结记录一下,希望帮助到有需求的人,同时担心自己忘记。
0 参考链接
0.1 https://blog.csdn.net/majinlei121/article/details/78933947 - Python-PIL 图像处理基本操作(一)
0.2 https://blog.csdn.net/NeXT_Voyager/article/details/105845733 - Python图像读取,图像的PIL.Image, numpy.darray, Tensor形式相互转换
0.3 https://blog.csdn.net/bl128ve900/article/details/93739325 - Pytorch Totensor 具体做了什么事情
0.4 https://blog.csdn.net/weixin_38533896/article/details/86028509 - Pytorch:transforms的二十二个方法
0.5 https://blog.csdn.net/qq_30401249/article/details/71530260 - caffe学习笔记(13):python cv2.imread()读取图片和matlab读取图像的区别
0.6 https://blog.csdn.net/weixin_30429201/article/details/94804138?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase - PyTorch载入图片后ToTensor解读(含PIL和OpenCV读取图片对比)
1 使用PIL读取图片
总结:PIL读入图片,通道默认为RGB顺序,读出的变量img类型为JPEG类型,size为(width,height),但是为彩色三通道图像。
# _*_ coding:utf-8 _*_
import torch
import torchvision
import torch.utils.data as Data
import cv2
from PIL import Image
import numpy as np
if __name__ == '__main__':
# 使用PIL读取图片
src_pic_path = 'C:\\Users\\pfm\\Desktop\\sz.jpg'
img = Image.open(src_pic_path)
#PIL图片格式
print(img.format) # 'JPEG'
# PIL图片的大小
print(img.size) # (width,height)
# PIL图片通道顺序
print(img.mode) # RGB
2 使用cv2读取图片
总结:cv2读入图片,通道默认顺序是BGR,读出的变量类型为numpy.ndarray,如果为彩色图读入,则尺寸为(height, weight, channel);如果以灰度图读入,则尺寸为(height,wdith)
# 首先以彩色图读入
img = cv2.imread(src_pic_path)
# cv2图片格式
print(type(img)) # numpy.ndarray 默认uint8
# cv2图片的尺寸
print(img.shape) # (height,width,channel) ,通道默认是BGR顺序
# 再则以灰度图读入
img = cv2.imread(src_pic_path,0)
# cv2灰度图图片格式
print(type(img)) # numpy.ndarray 默认uint8
# cv2灰度图片尺寸
print(img.shape) # (height,width)3 cv2和PIL读取图片格式对比
3.1 cv2.imread()返回numpy.darray,可直接用Image.fromarray()转换成PIL.Image,读取灰度图像的shape为(H,W),读取彩色图像的shape为(H,W,3)。
3.2 cv2写图像时,输入的灰度图像的shape可以为(H,W)或(H,W,1),输入的彩色图像的shape应该为(H,W,3);
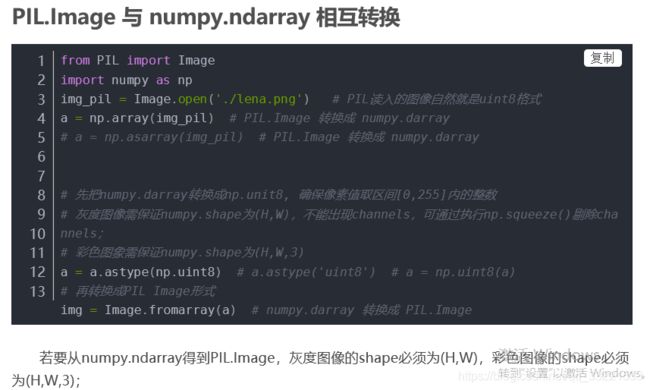
3.3 若要从numpy.ndarray得到PIL.Image,灰度图像的shape必须为(H,W),彩色图像的shape必须为(H,W,3);
3.4 另外,PIL图像在转换为numpy.ndarray后,格式为(h,w,c),像素顺序为RGB;
OpenCV在cv2.imread()后数据类型为numpy.ndarray,格式为(h,w,c),像素顺序为BGR。
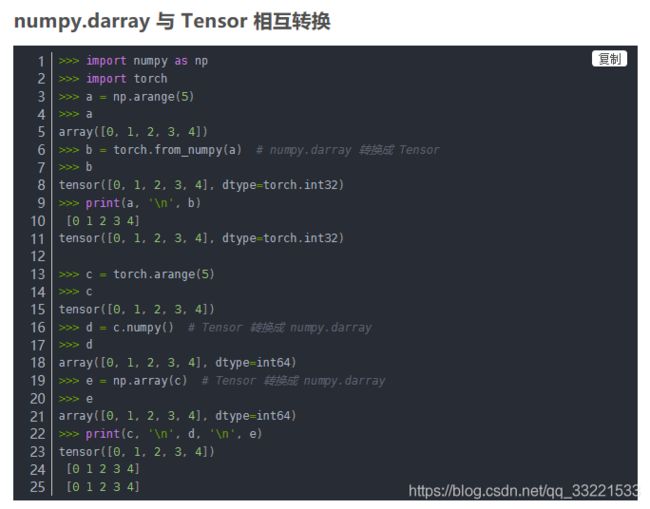
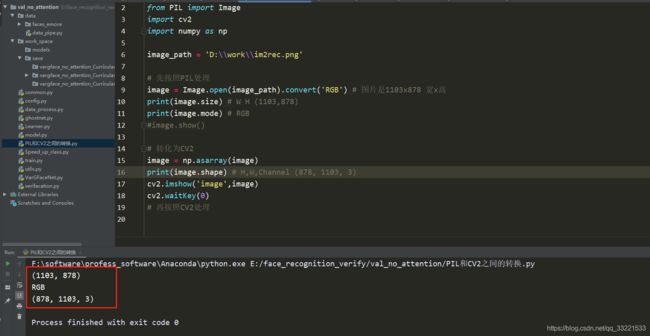
如下图所示,PIL经过np.asarray()之后转换为cv2格式的图片,由原来的(W,H)-> (H,W,Channel)
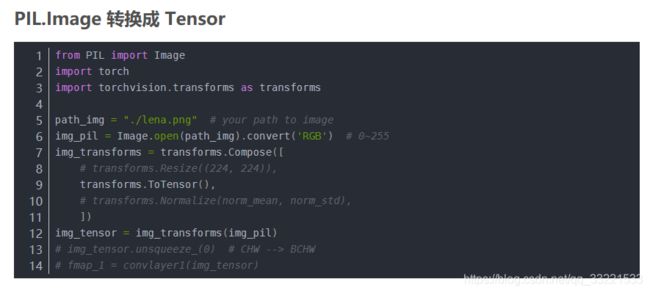 Tensor 转换成 PIL.Image
Tensor 转换成 PIL.Image
# 先把Tensor转换成numpy.darray,再把numpy.darray 转换成 PIL.Image
import numpy as np
import torch
import torchvision.transforms as transforms
from PIL import Image
from matplotlib import pyplot as plt
img_transforms = transforms.Compose([
# transforms.Resize((224, 224)),
transforms.ToTensor(),
# transforms.Normalize(norm_mean, norm_std),
])
def transform_invert(img_, transform_train):
"""
将data 进行反transfrom操作
:param img_: Tensor
:param transform_train: torchvision.transforms
:return: PIL image
"""
if 'Normalize' in str(transform_train):
norm_transform = list(filter(lambda x: isinstance(x, transforms.Normalize), transform_train.transforms))
mean = torch.tensor(norm_transform[0].mean, dtype=img_.dtype, device=img_.device)
std = torch.tensor(norm_transform[0].std, dtype=img_.dtype, device=img_.device)
img_.mul_(std[:, None, None]).add_(mean[:, None, None])
# img_ = img_.transpose(0, 2).transpose(0, 1) # C*H*W --> H*W*C
img_ = img_.permute(1, 2, 0) # C*H*W --> H*W*C
if 'ToTensor' in str(transform_train):
img_ = np.array(img_) # 先把Tensor转换成numpy.darray
img_ -= np.min(img_)
img_ /= np.max(img_)
img_ = img_ * 255
# 再把numpy.darray转换成PIL.Image
if img_.shape[2] == 3:
img_ = Image.fromarray(img_.astype('uint8')).convert('RGB')
elif img_.shape[2] == 1:
img_ = Image.fromarray(img_.astype('uint8').squeeze())
else:
raise Exception("Invalid img shape, expected 1 or 3 in axis 2, but got {}!".format(img_.shape[2]) )
return img_
# img_pil = Image.open('./lena.png').convert('RGB') # 彩色图像
img_pil = Image.open('./lena.png').convert('L') # 灰度图像
# plt.imshow(img_pil)
# plt.show()
img_tensor = img_transforms(img_pil)
img = transform_invert(img_tensor, img_transforms)
plt.imshow(img)
plt.show()
4 MATLAB读入图像
我们用matlab的imread读入图像,来演示图像通道顺序,通道顺序变换、维度变换。

可以看到matlab如何的图片返回的维度为HxWxC,且为RGB顺序,需要将其维度变换转化为(H,W,C,N)才能满足caffe或者pyTorch中对输入tensor的尺寸要求。