随着信息技术的发展,人们对实时通信的需求不断增加,并逐渐成为工作生活中不可或缺的一部分。每年海量的音视频通话分钟数对互联网基础设施提出了巨大的挑战。尽管目前全球的互联网用户绝大多数均处于良好的网络状况,但仍有不少地区处于极差的网络条件下,除此之外,即使在网络良好区域,也仍会存在弱网现象。那么如何在有限的带宽下提供高质量的音频体验就成为了一个非常重要的研究方向。
在过去的几十年间,语音或音频的编码技术都涉及大量特定领域的知识,例如语音生成模型。近些年,随着深度学习类算法的快速发展,逐渐涌现出了多种基于神经网络的音频处理算法。阿里云视频云技术团队在综合分析了实际业务场景存在的共性问题的基础上,开始探索借助数据驱动的方式提高音频的编码效率,并提出了智能音频编解码器 AliIAC (Ali Intelligent Audio Codec),可以在有限的带宽条件下提供更高质量的音频通话体验。
什么是音频编解码器?
即使没有听说过音频编解码器这个概念,在日常生活中,也一定有使用到这项技术,从收看电视节目到使用移动手机打电话,从刷短视频到观看直播,都会涉及到音频编解码技术。
音频编码的目标是将输入音频信号压缩成比特流,其所占存储空间远小于输入的原始音频信号,然后在解码端通过接收到的比特流恢复出原始音频信号,同时希望重建的信号在主观听感上与原始信号尽可能相近,编码过程如下公式所示:
$$ \boldsymbol{h} \leftarrow \mathcal{F}_{\mathrm{enc}}(\boldsymbol{x}) $$
其中,\({x} \in \mathbb{R}^{T}\) 代表时域语音信号,长度为 \(T\),\(h\) 会进一步被转换为比特流 \( \tilde{\boldsymbol{h}} \in \mathbb{R}^{N} \),\( N \) 远小于 \(T\),解码过程如下公式所示:
$$ \boldsymbol{x} \approx \hat{\boldsymbol{x}} \leftarrow \mathcal{F}_{\mathrm{dec}}(\tilde{\boldsymbol{h}}) $$
传统的音频编解码器可以分为两大类:波形编解码器和参数编解码器(waveform codecs and parametric codecs)
波形编解码器
波形编解码器的重点是在解码器端产生输入音频样本的重建。
在大多数情况下,波形编解码器较依赖于变换编码技术,可以将输入的时域波形映射到时频域。然后,通过量化技术对变换系数进行量化,最后经过熵编码模块将其转化成可用于传输的比特流。在解码器端,通过相应的反变换来重建时域波形。
一般情况下,波形编解码器对待编码的音频的类型(如:语音、音乐等)做很少或不做任何假设,所以可以处理的音频范围很广泛。在中高比特率时这种方法可以产生非常高质量的音频,但在低比特率下往往会引入一些由编码引起的 artifacts,导致听感变差。
参数编解码器
参数编解码器的核心思想是通过对待编码的音频(如:语音)进行特定假设,并通过参数模型的形式将先验知识融合进编码的过程中。
编码器首先会估计模型的参数,然后经过量化模型进行进一步压缩,解码器则使用量化后的参数来驱动合成模式进行时域波形的重建。与波形编解码器不同的是,参数编解码器的目标不是在逐个样本的基础上获得高相似度的波形重建,而是生成在感知上与原始音频相近的音频。
传统音频编解码器面临的挑战
得益于 WebRTC 生态的蓬勃发展,opus 音频编解码器在业界被广泛使用,它着重于处理广泛的交互式音频应用场景,包括 VOIP (Voice over Internet Protocol)、视频会议、游戏内聊天,甚至远程现场音乐表演。
它由两种不同的编解码器构成,一个是用于语音的 SILK,另一个是用于音乐的 CELT。尽管 opus 及其他传统音频编解码器(如:EVS、AMR-WB、speex、MELP 等)都拥有着优异的效果,但在有限带宽条件下、信噪比低条件下和混响混音严重条件下均表现出了不同程度的局限性,无法应对当前复杂多变的应用场景,带来流畅清晰的音频通话体验。
AliIAC 智能音频编解码器
考虑到传统音频编解码在高码率下的优异表现及业内的主流地位,阿里云视频云音频技术团队提出了两款智能音频编解码器,E2E 版本和 Ex 版本。
其中,E2E 版本,可直接替换 opus 等传统编解码器模块,支持在 6kbps ~ 18kbps 下工作,对 16khz 音频进行编解码;Ex 版本则可在沿用传统编解码器的基础上,通过后处理的方式对 6kbps~8kbps 解码后的 16khz 音频进行修复增强,提升可懂度和音质。
算法原理
1、E2E 版本:是基于端到端的 encoder-decoder 模型,同时考虑了实际应用场景中会遇到的语音频谱损伤、存在混响及残留噪声等问题,结合 GAN 网络的训练策略,进一步提升解码后的音频质量;为了方便部署与使用,采用残差量化模块,支持单一模型可变比特率,范围在 6kbps ~ 18kbps。
2、Ex 版本:是针对被传统编解码器如:Opus, 在 6kbps ~ 8kbps 条件下解码后的音频,进行频率域修复 / 增强的深度模型。对 0 4kHz 频域进行幅度谱的损失补偿,在 48kHz 频域进行频谱的预测补偿,修复 / 增强后的音频在主观听感上(可懂度和音质)有明显提升。
算法性能

算法效果
场景一:真实场景有损频谱+混响情况
不同方法的频谱图对比:
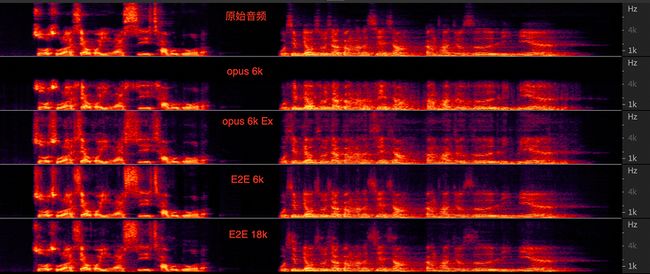
从主观听感和频谱图均可看出,opus 6k Ex、E2E 6k、E2E 18k 版本较opus 6k版本在效果上均有明显提升,其中 opus 6k Ex 和 E2E 6k 在前半段频谱明显有损伤的情况下解码后有些许杂音残留,E2E 18k 版本则基本接近原始音频。
场景二:真实场景带噪情况
不同方法的频谱图对比:

从主观听感和频谱图均可看出,opus 6k Ex、E2E 6k、E2E 18k 版本较 opus 6k 版本在效果上均有明显提升,且音色音调均与原始音频接近。
AliIAC智能音频编解码器将继续演进
AliIAC 作为阿里云视频云音频解决方案的一部分,旨在充分利用数据驱动的思想来提高音频的编码效率,使得可以在更低带宽代价的前提下获得更好的音频通话体验。
目前,AliIAC 还处于算力、码率与效果的平衡阶段,需要进一步去解决实时性与音频生成效果稳定性等问题,但在带宽受限条件下,AliIAC 相较传统音频编解码器已经表现出了优异的效果。其中,在大多数实际场景中,E2E 18kbps 的效果与 opus 24kbps 的效果持平,E2E 6kbps 的效果与 opus 12kbps 的效果持平,平均可以节省 25% ~ 50% 的带宽消耗;而 Ex 版本则可以在不额外消耗带宽资源的前提下,主观 MOS 分平均提升 0.2 ~0.4。在未来,阿里云视频云音频技术团队将继续探索基于深度学习 + 信号处理的音频技术,创造极致的音频体验。
「视频云技术」你最值得关注的音视频技术公众号,每周推送来自阿里云一线的实践技术文章,在这里与音视频领域一流工程师交流切磋。公众号后台回复【技术】可加入阿里云视频云产品技术交流群,和业内大咖一起探讨音视频技术,获取更多行业最新信息。