前言
损失函数在机器学习中用于表示预测值与真实值之间的差距。
一般而言,大多数机器学习模型都会通过一定的优化器来减小损失函数从而达到优化预测机器学习模型参数的目的。
哦豁,损失函数这么必要,那都存在什么损失函数呢?
一般常用的损失函数是均方差函数和交叉熵函数。
运算公式
1 均方差函数
均方差函数主要用于评估回归模型的使用效果,其概念相对简单,就是真实值与预测值差值的平方的均值,具体运算公式可以表达如下:
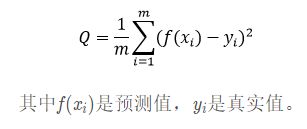
其中f(xi)是预测值,yi是真实值。在二维图像中,该函数代表每个散点到拟合曲线y轴距离的总和,非常直观。
2 交叉熵函数
出自信息论中的一个概念,原来的含义是用来估算平均编码长度的。在机器学习领域中,其常常作为分类问题的损失函数。

交叉熵函数是怎么工作的呢?假设在分类问题中,被预测的物体只有是或者不是,预测值常常不是1或者0这样绝对的预测结果,预测是常用的做法是将预测结果中大于0.5的当作1,小于0.5的当作0。
此时假设如果存在一个样本,预测值接近于0,实际值却是1,那么在交叉熵函数的前半部分:
![]()
其运算结果会远远小于0,取符号后会远远大于0,导致该模型的损失函数巨大。通过减小交叉熵函数可以使得模型的预测精度大大提升。
tensorflow中损失函数的表达
1 均方差函数
loss = tf.reduce_mean(tf.square(logits-labels)) loss = tf.reduce_mean(tf.square(tf.sub(logits, labels))) loss = tf.losses.mean_squared_error(logits,labels)
2 交叉熵函数
loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=y,logits=logits) #计算方式:对输入的logits先通过sigmoid函数计算,再计算它们的交叉熵 #但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出。 loss = tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=logits) #计算方式:对输入的logits先通过softmax函数计算,再计算它们的交叉熵, #但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出。
例子
1 均方差函数
这是一个一次函数拟合的例子。三个loss的意义相同。
import numpy as np
import tensorflow as tf
x_data = np.random.rand(100).astype(np.float32) #获取随机X值
y_data = x_data * 0.1 + 0.3 #计算对应y值
Weights = tf.Variable(tf.random_uniform([1],-1.0,1.0)) #random_uniform返回[m,n]大小的矩阵,产生于low和high之间,产生的值是均匀分布的。
Biaxs = tf.Variable(tf.zeros([1])) #生成0
y = Weights*x_data + Biaxs
loss = tf.losses.mean_squared_error(y_data,y) #计算平方差
#loss = tf.reduce_mean(tf.square(y_data-y))
#loss = tf.reduce_mean(tf.square(tf.sub(y_data,y)))
optimizer = tf.train.GradientDescentOptimizer(0.6) #梯度下降法
train = optimizer.minimize(loss)
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
for i in range(200):
sess.run(train)
if i % 20 == 0:
print(sess.run(Weights),sess.run(Biaxs))
输出结果为:
[0.10045234] [0.29975605]
[0.10010818] [0.2999417]
[0.10002586] [0.29998606]
[0.10000619] [0.29999667]
[0.10000149] [0.2999992]
2 交叉熵函数
这是一个Mnist手写体识别的例子。两个loss函数都可以进行交叉熵运算,在计算loss函数的时候中间经过的函数不同。
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data",one_hot = "true")
def add_layer(inputs,in_size,out_size,n_layer,activation_function = None):
layer_name = 'layer%s'%n_layer
with tf.name_scope(layer_name):
with tf.name_scope("Weights"):
Weights = tf.Variable(tf.random_normal([in_size,out_size]),name = "Weights")
tf.summary.histogram(layer_name+"/weights",Weights)
with tf.name_scope("biases"):
biases = tf.Variable(tf.zeros([1,out_size]) + 0.1,name = "biases")
tf.summary.histogram(layer_name+"/biases",biases)
with tf.name_scope("Wx_plus_b"):
Wx_plus_b = tf.matmul(inputs,Weights) + biases
tf.summary.histogram(layer_name+"/Wx_plus_b",Wx_plus_b)
if activation_function == None :
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
tf.summary.histogram(layer_name+"/outputs",outputs)
return outputs
def compute_accuracy(x_data,y_data):
global prediction
y_pre = sess.run(prediction,feed_dict={xs:x_data})
correct_prediction = tf.equal(tf.arg_max(y_data,1),tf.arg_max(y_pre,1)) #判断是否相等
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) #赋予float32数据类型,求平均。
result = sess.run(accuracy,feed_dict = {xs:batch_xs,ys:batch_ys}) #执行
return result
xs = tf.placeholder(tf.float32,[None,784])
ys = tf.placeholder(tf.float32,[None,10])
layer1 = add_layer(xs,784,150,"layer1",activation_function = tf.nn.tanh)
prediction = add_layer(layer1,150,10,"layer2")
#由于loss函数在运算的时候会自动进行softmax或者sigmoid函数的运算,所以不需要特殊激励函数。
with tf.name_scope("loss"):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=ys,logits = prediction),name = 'loss')
#loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=ys,logits = prediction),name = 'loss')
#label是标签,logits是预测值,交叉熵。
tf.summary.scalar("loss",loss)
train = tf.train.AdamOptimizer(4e-3).minimize(loss)
init = tf.initialize_all_variables()
merged = tf.summary.merge_all()
with tf.Session() as sess:
sess.run(init)
write = tf.summary.FileWriter("logs/",sess.graph)
for i in range(5001):
batch_xs,batch_ys = mnist.train.next_batch(100)
sess.run(train,feed_dict = {xs:batch_xs,ys:batch_ys})
if i % 1000 == 0:
print("训练%d次的识别率为:%f。"%((i+1),compute_accuracy(mnist.test.images,mnist.test.labels)))
result = sess.run(merged,feed_dict={xs:batch_xs,ys:batch_ys})
write.add_summary(result,i)
输出结果为
训练1次的识别率为:0.103100。
训练1001次的识别率为:0.900700。
训练2001次的识别率为:0.928100。
训练3001次的识别率为:0.938900。
训练4001次的识别率为:0.945600。
训练5001次的识别率为:0.952100。
以上就是python人工智能tensorflowf常见损失函数LOSS汇总的详细内容,更多关于tensorflowf损失函数LOSS的资料请关注脚本之家其它相关文章!