Paper Reading - 综述系列 - Hyper-Parameter Optimization(上)
更多可见计算机视觉-Paper&Code - 知乎
自开发深度神经网络以来,几乎在日常生活的每个方面都给人类提供了比较理性的建议。但是,尽管取得了这一成就,神经网络的设计和训练仍然是具有很大挑战性和不可解释性,同时众多的超参数也着实让人头痛,因此被认为是在炼丹。
因此为了降低普通用户的技术门槛,自动超参数优化(HPO)已成为学术界和工业领域的热门话题。本文主要目的在回顾了有关 HPO 的最重要的主题。主要分为以下几个部分
- 模型训练和结构相关的关键超参数,并讨论了它们的重要性和定义值范的围
- HPO中主要的优化算法及其适用性,包括它们的效率和准确性
- HPO 的一些框架与工具包,比较它们对最先进搜索算法的支持
Paper
主要的超参数
学习率
学习率是正数,决定了随机梯度下降的步长,大多数情况下学习率需要手动调整。学习率可分为固定学习率和可变学习率,自适应的学习率能够根据模型的结构的性能进行调整,需要学习算法的支持。
Constant LR 最简单的方式,但训练快结束时,学习率可能相对过大,导致梯度震荡。一个改进方式是将初始LR设置为0.1,当随着训练延后,将lr设置为0.01
线性衰减(Linear LR decay)基于时间或者训练步数逐渐减小学习率,如下图
lr0和k分别表示初始学习率和衰减速率,都是超参数。如果t是训练时间,则学习率是连续下降的,如果t是迭代次数,那么学习率一般是分段下降,每若干个迭代下降一次。
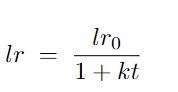

不同lr的曲线
指数衰减(Exponential decay)与线性衰减相比,在初始时衰减更剧烈而在接近收敛时衰减更缓慢,如下图
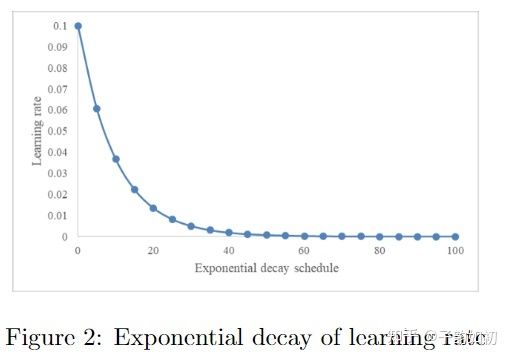
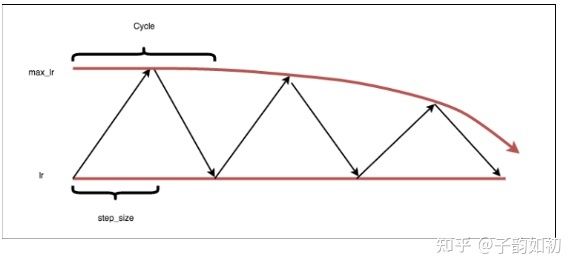
LR schedule 方法同样会有两个问题:1)一旦确定后,学习率就是一直单调下降的;2)如果是基于时间或者训练步数,那么模型中所有层都需要使用相同的学习率,这显然是不合理的,但是我们知道不同层的收敛速度,梯度回传的量级是不一样的。第一个问题可以通过自动超参数调优和循环cyclical LR方法解决,max lr逐渐衰减,如下图所示。第二个问题可以通过LARS(layer-wise adaptive rate scaling)解决,网络的每一层都拥有自己独立的学习率。
小学习率会导致收敛缓慢,但大学习率会导致无法收敛,导致梯度震荡,对于超参的选择,主要有以下几个方法
- 难以确定超参的重要性时,可以进行敏感性测试
- 初始的学习率可以相对较大,这能够使得模型更快收敛,到训练末期,lr可以较小,便于模型收敛到最佳
- 使用对数缩放更新学习率,因此指数衰减一般较好
- 但是第三点也不是常有效的,与数据集有关

优化器
更多可以参考子韵如初:Paper Reading - 综述系列 - 优化器SGD、AdaGrad 、RMSProp、ADAM
与优化器相关的超参数如下,mini-batch大小,momentum和beta。下面介绍最常用的优化器及其参数。
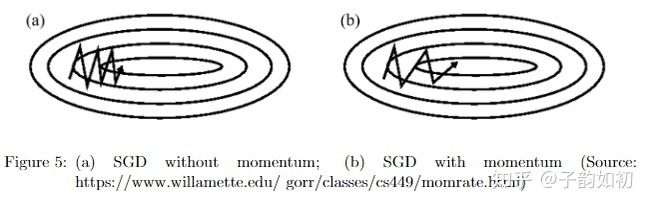
小批量梯度下降(mini-batch GD)与vanilla GD相比可以加速训练过程,与随机梯度下降相比能够减少噪声并易于收敛(因为每次梯度计算会取多个数据进行梯度平均)。mini-batch大小一般选择2的幂以便充分利用CPU/GPU的内存,不带动量的mini-batch GD收敛速度比较慢,而且容易发生震荡。
带动量的SGD可以解决震荡和收敛速度问题,它通过计算梯度的指数加权平均值来加速标准SGD,还通过为更新向量添加beta因子帮助代价函数朝正确方向下降:
其中,w是权重,β是参数,通常设置为0.9,0.99或0.999
Adam(Adaptive momentum estimation)作为带动量GD和RMSprop的结合,在RMSprop中增加了偏差校正和动量,在优化的后期略胜于RMSprop。通常Adam做为默认的优化器。但是他的参数量比其他优化器更多
搜索中常见的超参数
模型深度是一个影响最终输出的关键参数,越多的层数更有可能获得更复杂的特征和更好的性能。因此在不过拟合的情况下为神经网络增加更多层往往能够提高模型容量,获得更好的结果。越复杂越好用
模型宽度一般取值为Win表示输入层的神经元数目

正则化,weight decay通常用于减少神经网络的复杂性以避免过拟合,常见的L1、L2如图
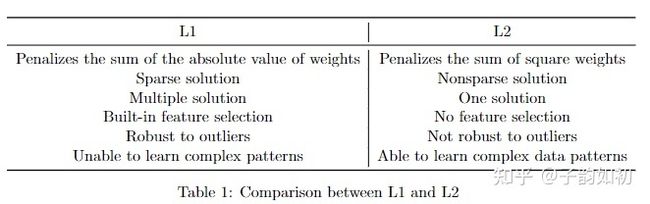
数据增强也是常用的正则化手段,通过创建假样本并加入到训练集中从而避免过拟合。Dropout由于BN的出现,渐渐被废弃了
激活函数为深度学习引入非线性,如果没有激活函数,神经网络可以被简化为线性回归模型。激活函数必须是可微的。目前比较流行的激活函数包括sigmoid、tanh、ReLU、Maxout和Swish
梯度爆炸和梯度消失,举个例子,w是所求的梯度,f代表激活函数,因此\f3/\f2就是对激活函数求导,如果此部分大于1,那么层数增多的时候,最终的求出的梯度更新将以指数形式增加,即梯度爆炸,如果此部分小于1,那么随着层数增多,求出的梯度更新信息将会以指数形式衰减,即梯度消失。不同的层学习的速度差异很大,靠近输出的层学习的情况很好,靠近输入的层学习的很慢,因为出现梯度小时的情况梯度回传回来到输入层基本为0了。
BN,同样因为反向传播式子中有w的存在,所以w的大小影响了梯度的消失和爆炸,就是通过对每一层的输出做scale和shift的方法,把每层神经网络任意神经元这个输入值的分布强行拉回到接近均值为0方差为1的标准正态分布,即严重偏离的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,使得让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。

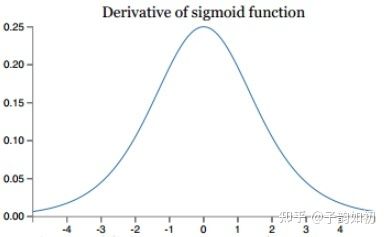
sigmoid的梯度
- Sigmoid,使用最广泛,但存在梯度消失问题,由于不是以0为中心,会导致反向传播时权重要么全正要么全负,使得优化困难。且梯度不可能超过0.25,经过链式求导之后,很容易发生梯度消失。Softmax和sigmod类似,但sigmoid通常应用于二元分类,而softmax用于多分类。此外,在构建网络时,sigmoid用作激活函数,而softmax通常用在输出层。
![]()
- Tanh,以0为中心,与sigmoid类似但导数梯度更陡峭。同样也有面临梯度消失问题
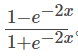
- ReLU,大道至简,ReLu是使用最广的激活函数,同时也有许多变体(leaky ReLU,PReLU,EIU和SeLU)。ReLU计算简单,而且能够解决梯度消失问题,但是输出仍不是以0为中心的,由于负数部分恒为0,会导致一些神经元失活,可以使用leaky ReLU替换解决梯度消失问题,保留一些负数梯度。
![]()
- leakrelu,几乎解决了relu的所有问题。一直有梯度,并且以0位中心


- Maxout,该函数位ReLU和leaky ReLU的泛化,实际上它也可以看作一层神经网络。Maxout是一个可学习的激活函数,解决了ReLU所有的问题,通常与dropout搭配使用,但也导致参数量增加。

- Mish用于yolov4中,ς(x) = ln(1+e^x),是一个softmax激活函数和。曲线与Swish比较相似

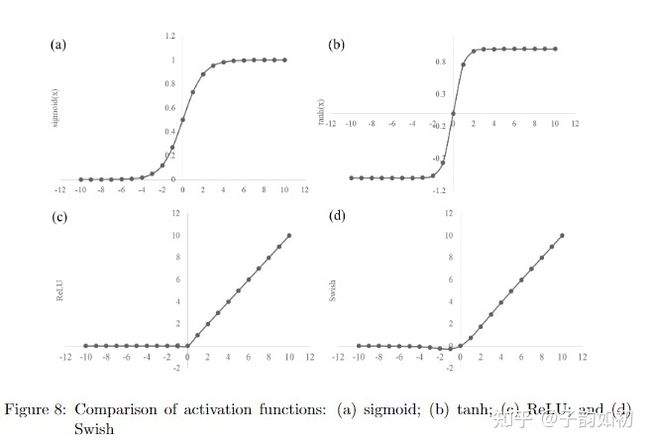
常见激活函数图
下一篇将会介绍现有的HPO SOTA算法