MQSQL—DDL&DML
MQSQL—DDL&DML
OVERVIEW
- MQSQL—DDL&DML
-
-
- 一、DDL
-
- 1.table表创建:
- 2.table表的数据类型:
- 3.table表的删除:
- 4.约束constraint:
-
- unique非空约束:
- PK主键约束:
- FK外键约束:
- 二、DML
-
- 1.insert数据插入:
-
- (1)str_to_date函数:
- (2)date_format函数:
- (3)date与datetime的区别:
- (4)now函数获取当前系统时间:
- (5)insert插入多条记录:
- 2.update数据更新:
- 3.delete数据删除:
-
- (1)快速复制表
- (2)删除大表truncate:
- 三、TCL&其他
-
- 1.存储引擎:
-
- (1)指定存储引擎:
- (2)mysql支持的存储引擎:
- (3)常用存储引擎:
-
- <1>MyISAM
- <2>InnoDB
- <3>MEMORY
- 2.事务:
-
- (1)事务transaction的实现:
- (2)事务的4个ACID特性:
- (3)事务的4个隔离级别:
- 3.索引:
-
- (1)索引的创建与删除:
- (2)索引的失效情况:
- 4.视图:
-
- (1)视图的作用:
- (2)视图的创建与删除:
- 5.存储过程与函数:
-
- (1)存储过程的创建与调用:
- (2)变量的定义与赋值:
- (3)参数传递:
- (4)IF语句:
- (5)WHERE循环:
- (6)存储函数:
- 6.触发器:
-
- (1)创建触发器:
- (2)查看和删除触发器:
-
DDL语句包括create、drop、alter等、DML语句包括insert、delete、update等。
一、DDL
1.table表创建:
create table 表名(
字段名1 数据类型,
字段名2 数据类型,
字段名3 数据类型
);
注意:表名建议以
t_或者tbl_开始,增强可读性,使表名、字段名见名知意。
2.table表的数据类型:
| 数据类型 | 说明 |
|---|---|
| varchar | 可变长度字符串,根据实际的数据长度动态分配空间。分配速度慢,无空间浪费(max255) |
| char | 定长字符串,例如char(10)。分配速度快,可能空间浪费(max255) |
| int | 数字中的整数型,int(max11) |
| bigint | 数字中的长整型,long |
| float | 单精度浮点型 |
| double | 双精度浮点型 |
| date | 短日期 |
| datetime | 长日期 |
| clob | character large object,字符大对象,最多可以存储4G的字符串。存储一篇文章、简介说明 |
| blob | binary large object,用于存储图片、声音、视频等流媒体数据。需要使用IO流 |
3.table表的删除:
drop table [if exists] 表名;
4.约束constraint:
在创建表的时候,可以给表中的字段加上一些约束来保证该表中数据的完整性、有效性。
注意:约束的作用就是为了保证,表中的数据有效。
| 约束类型 | 说明 |
|---|---|
| not null | 非空约束 |
| unique | 唯一性约束 |
| primary key | 主键约束PK |
| foreign key | 外键约束FK |
| check | 检查约束(oracle支持) |
unique非空约束:
drop table if exists t_vip;
create table t_vip(
id int,
name varchar(255) unique,
email varchar(255) unique
);
drop table if exists t_vip;
create table t_vip(
id int,
name varchar(255),
email varchar(255),
unique(name, email)
);
注意:
- unique的第二种写法是将两个字段联合起来,具有唯一性。
- unique添加到列的后面则被称为列级约束,unique没有添加到列的后面则称为表级约束。(not null只有列级约束)
- 在mysql中如果一个字段同时被not null与unique约束,则该字段自动变成主键字段。(oracle不同)
PK主键约束:
多字段联和共同作为主键,即复合主键:
drop table if exists t_vip;
create table t_vip(
id int,
name varchar(255),
email varchar(255),
primary key(id, name)
);
注意:一张表中主键约束只能添加一个,主键只能有一个。主键不建议使用varchar类型,且一般都为数字(定长)。
FK外键约束:
create table t_student(
no int primary key auto_increment,
name varchar(255),
cno int,
foreign key(cno) references t_class(classno)
);
注意:外键约束引用的字段不一定是主键但具unique约束(具有唯一性),外键值可以为空。
二、DML
1.insert数据插入:
insert into 表名(字段1, 字段2, 字段3) values(数据值1, 数据值2, 数据值3);
注意:
- 数量要对应,数据类型要对应。
- 插入数据没有给其他字段指定值,则默认值为NULL
- 前面的字段名省略等于都写上了,数据值也需要写上。
(1)str_to_date函数:
str_to_date函数可以将字符串varchar类型转换成date类型,通常使用在插入insert方面(因为插入的时需要一个日期类型的数据)。
语法格式:str_to_date('字符串日期', '日期格式')
mysql日期格式:
| mysql日期格式 | 说明 |
|---|---|
| %Y | |
| %m | 月 |
| %d | 日 |
| %h | 时 |
| %i | 分 |
| %s | 秒 |
drop table if exists t_user;
create table t_user(
id int,
name varchar(32),
birth char(10)
);
drop table if exists t_user;
create table t_user(
id int,
name varchar(32),
birth date
);
注意:生日birth可以使用date类型,也可以使用char(10)类型(若为date类型,字符串需要转化为date),插入语句如下:
insert into t_user(id, name, birth) values(1, 'zhangsan', '01-10-1990');
insert into t_user(id, name, birth) values(1, 'zhangsan', str_to_date('01-10-1990', '%d-%m-%Y'));

注意:如果提供的日期字符串为
%Y-%m-%d,就不需要使用str_to_date函数了。
(2)date_format函数:
将date类型转换成具有一定格式的varchar类型,通常使用在查询日期并以特定格式展示的情况下。
语法格式:date_format(日期类型数据, '日期格式')
select id, name, birth from t_user;
select id, name, date_format(birth, '%m/%d/%Y') as birth from t_user;
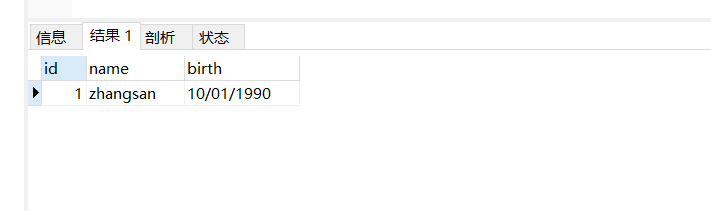
注意:sql语句进行了默认的日期格式化,将数据库中的date类型转换成varchar类型,并且采用的格式为mysql默认时期格式。
(3)date与datetime的区别:
date是短日期:只包含年月日信息,默认格式为%Y-%m-%d
datetime是长日期:包括年月日时分秒信息,默认格式为%Y-%m-%d %h:%i:%s
drop table if exists t_user;
create table t_user(
id int,
name varchar(32),
birth date,
create_time datetime
);
insert into t_user(id, name, birth, create_time) values(1, 'zhangsan', '1990-10-01', '2020-03-18 15:49:50');
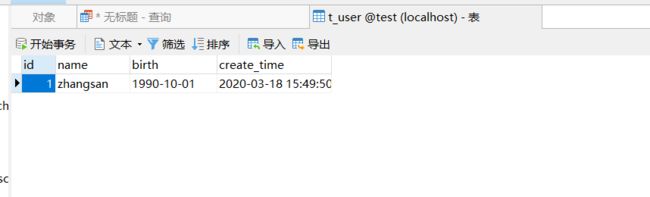
(4)now函数获取当前系统时间:
注意:now函数获取的时间具有时分秒和date
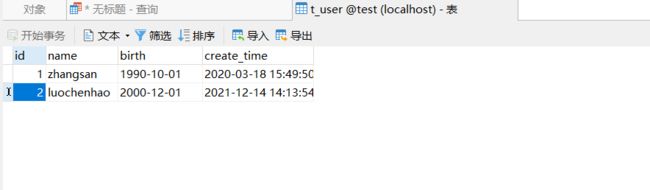
insert into t_user(id, name, birth, create_time) values(1, 'luochenhao', '2000-12-01', now());
(5)insert插入多条记录:
insert into 表名(字段1, 字段2...) values(), (), (), ();
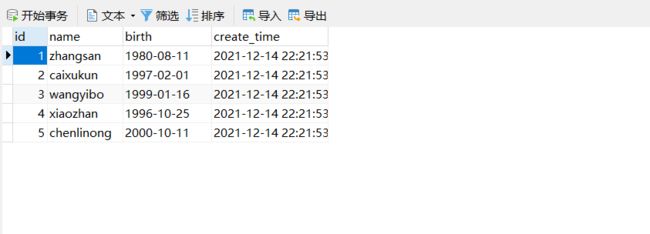
insert into t_user(id, name, birth, create_time) values
(1, 'zhangsan', '1980-8-11', now()),
(2, 'caixukun', '1997-2-1', now()),
(3, 'wangyibo', '1999-1-16', now()),
(4, 'xiaozhan', '1996-10-25', now()),
(5, 'chenlinong', '2000-10-11', now());
2.update数据更新:
法格式:
update
表名
set
字段1 = 值1, 字段2 = 值2, 字段3 = 值3...
where
条件;
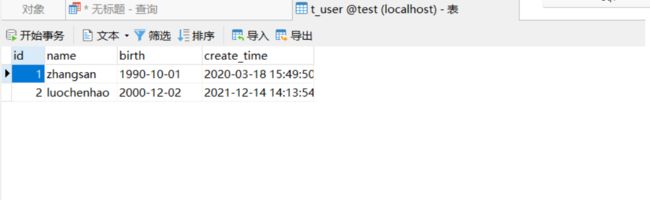
注意:如果没有where条件限制会直接导致所有数据全部更新。
update
t_user
set
name = 'luochenhao', birth = '2000-12-2'
where
id = 2;
3.delete数据删除:
语法格式:
delete from
表名
where
条件;
注意:如果没有where限制条件,整张表的数据会全部删除。
delete from
t_user
where
id = 2;

delete from t_user;

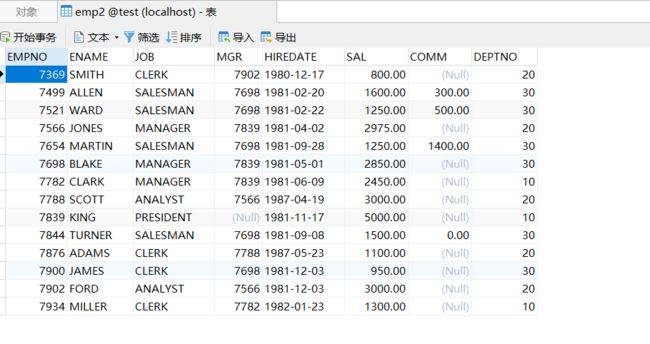
(1)快速复制表
create table emp2 as select * from emp;
(2)删除大表truncate:
- 使用delete删除表数据,不会删除释放硬盘上的真实存储空间。(删除效率低,但支持回滚,属于DML操作)
- 使用truncate语句删除数据的原理:物理删除。(删除效率高一次截断,但不支持回滚,属于DDL操作)
truncate table 表名;
三、TCL&其他
1.存储引擎:
存储引擎是mysql中特有的术语,本质上是一个表存储/组织数据的方式。不同的存储引擎,存储数据的方式不同。
(1)指定存储引擎:
可以在建表时为表指定存储引擎,在建表的小括号最后使用ENGINE关键字来指定存储引擎、CHARSET关键字来指定表的字符编码方式。
注意:mysql默认的存储引擎是
InnoDB,默认的字符编码方式是utf8。
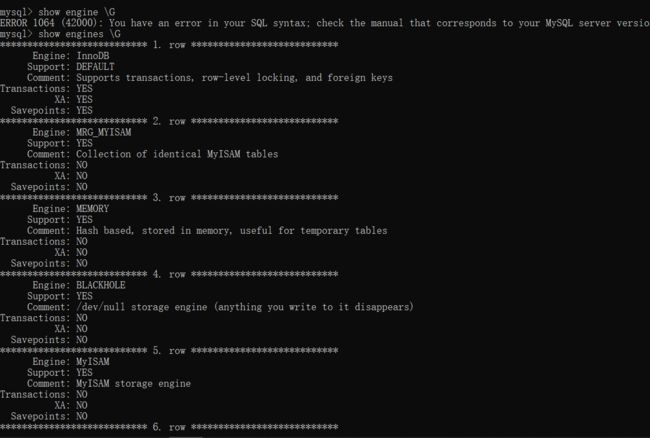
(2)mysql支持的存储引擎:
show engines \G
(3)常用存储引擎:
<1>MyISAM
该引擎下的table具有以下特征:
- 使用3个文件表示每个表(格式文件/定义frm、数据文件/内容MYD、索引文件MYI)
- 可被转换为压缩、只读表来节省存储空间
注意:对于一张table表,只要是主键、or 加有unique约束的字段上会自动创建索引。
<2>InnoDB
InnoDB是mysql默认的存储引擎,具有安全性高的特点:
- 每个InnoDB表在数据库目录中以
.frm格式文件表示 - InnoDB表空间tablespace被用于存储表的内容(表空间是一个逻辑名称,存储数据 + 索引)
- 提供一组用来记录事务性活动的日志文件
- 用COMMIT、SAVEPOINT以及ROLLBACK(回滚)支持事务处理
- 提供全ACID兼容
- 在MYSQL服务器崩溃后提供自动恢复
- 多版本和行级锁定
- 支持外键及引用的完整性,包括级联删除与更新
<3>MEMORY
使用memory存储引擎的表,其数据存储在内存中且行的长度固定。
- 在数据库目录中,每个表均以
.frm格式的文件表示 - 表数据及索引被存储在内存中(目的为查询更快)
- 表级锁机制
- 不能包含TEXT或BLOB字段
- MEMORY缺点:不安全,关机后数据消失。
2.事务:
一个事务就是一个完整的业务逻辑(多条DML语句),是一个最小的工作单元(不可再分)。
注意:只有DML语句才会有事务的概念,其他语句与事务无关(因为只有DML语句是在数据库中进行增、删、改的)
(1)事务transaction的实现:
注意:在事务的执行过程中,每一条DML的操作都会记录到事务型活动的日志文件中。mysql默认情况下的事务是自动提交的。
- 提交事务COMMIT:清空事务性活动的日志文件,将数据全部彻底持久化到数据库中,标志着事务全部的成功结束。
关闭mysql事务自动提交机制:
start transaction;
- 回滚事务ROLLBACK:将之前所有的DML操作撤销,并清空事务性活动的日志文件,标志着事务全部的失败结束。
(2)事务的4个ACID特性:
A:原子性,事务是最小的工作单元,不可再分
C:一致性,在同一个事务中,所有的操作必须同时成功 or 同时失败,以保证数据的一致性
I:隔离性,a事务与b事务之间具有一定的隔离
D:持久性,事务最终结束的一个保障
(3)事务的4个隔离级别:
事务之间的隔离级别从低到高有4个:
- 读未提交—read uncommitted:事务A可以读取到事务B未提交的数据,导致出现脏读(Dirty Read)现象。
- 读已提交—read committed:事务A只能读取到事务B提交之后的数据,解决了脏读现象但出现了不可重复读取数据问题。
- 可重复读—repeatable read:事务A开启之后,不管多久每一次在事务A中读取到的数据都是一致的,但会出现幻影读问题。
- 序列化/串行化—serializable:每一次读取到的数据都是真实的,并且是效率最低的。
注意:oracle中事务的默认级别为read committed,而mysql中事务的默认级别为repeated read。
| 事务隔离相关命令 | 说明 |
|---|---|
select @@tx_isolation; |
事务隔离级别 |
set global transaction isolation level read uncommitted; |
设置global transaction |
3.索引:
索引是在数据库的字段上添加的,是为了提高查询效率存在的一种机制。
在mysql数据库中索引也是需要排序的,底层是一个自平衡的二叉树,在mysql中索引是一个B-Tree的数据结构。
- 在任何数据库中主键上都会自动添加索引对象,id字段上自动有索引因为id是PK。
- 在mysql中,一个字段如果有unique约束则也会自动创建索引对象。
条件1:数据量庞大。
条件2:该字段进程出现在where的后面,以条件的形式存在。(即该字段经常被扫描)
条件3:该字段很少出现在DML操作中。(在DML操作之后,索引需要进行重新排序)
(1)索引的创建与删除:
为emp表的ename字段添加索引,并起名为emp_ename_index
create index emp_ename_index on emp(ename);
删除创建的索引:
drop index emp_ename_index on emp;
查看一个sql语句是否使用了索引进行检索:
explain (sql)
(2)索引的失效情况:
- 使用模糊查询索引失效
- 使用条件or进行查询时,需要两边都有索引才会使用索引
- 使用复合索引,没有使用左侧的列进行查找,导致索引失败
- 在where中索引列参加了运算,索引失效
- 在where中索引列使用了函数,索引失效
注意:索引是数据库优化的重要手段,优化优先考虑索引。
4.视图:
(1)视图的作用:
视图是一种虚拟存在的数据表,这个虚拟表在数据库中并不存在。
将一些较为复杂的查询语句的结果,封装到一个虚拟表中(视图),后期有相同需求时使用该视图即可(简化操作)。
注意:面向视图对象进行增删改查操作,对视图对象的操作可以导致原表被操作。
(2)视图的创建与删除:
create view emp_view as select * from emp;
drop view emp_view;
注意:只有DQL语句才能以view的形式创建。
5.存储过程与函数:
存储过程和函数是事先经过编译并存储在数据库中的一段SQL语句的集合。
注意:存储函数必须有返回值,而存储过程可以没有返回值。
(1)存储过程的创建与调用:
-- 修改结束分隔符
DELIMITER$
CREATE PROCEDURE test()
BEGIN
SQL语句列表;
END$
DELIMITER;
CALL 存储过程名称(实际参数);
SELECT * FROM mysql.proc WHERE db = '数据库名称';
(2)变量的定义与赋值:
DECLARE 变量名 数据类型 [DEFAULT 默认值];
SET 变量名 = 变量值;
SELECT
列名
INTO
变量名
FROM
表名
[WHERE 条件];
通过一条SELECT语句的查询结果给变量进行赋值。
(3)参数传递:
DELIMITER$
CREATE PROCEDURE 存储过程名称([IN|OUT|INOUT] 参数名 数据类型)
BEGIN
SQL语句列表;
END$
DELIMITER;
- IN:代表输入参数,由调用者传递实际参数
- OUT:代表输出参数,该参数可作为返回值
- INOUT:代表既可以作为输入参数、也可以作为输出参数
(4)IF语句:
IF 判断条件1 THEN 执行的sql语句1;
[ELSEIF 判断条件2 THEN 执行的sql语句2;]
...
[ELSE 执行的sql语句n;]
END IF;
案例5-1:输入总成绩变量代表学生成绩,输入分数描述变量代表学生成绩描述信息?
DELIMITER $
CREATE PROCEDURE gradeJudge(IN grade INT, OUT result VARCHAR(10))
BEGIN
# 对总成绩进行条件判断
IF grade >= 380 THEN
SET result = '学习优秀';
ELSEIF grade < 380 AND grade >= 320 THEN
SET result = '学习不错';
ELSE
SET result = '学习一般';
END IF;
END$
DELIMITER ;
# 调用存储过程
CALL gradeJudge(380, @result);
SELECT @result;

(5)WHERE循环:
初始化语句;
WHILE 条件判断语句 DO
循环体语句;
条件控制语句;
END WHILE;
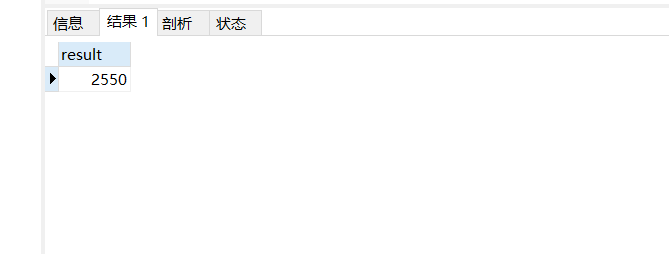
案例5-2:计算1-100之间的偶数和?
DELIMITER $
CREATE PROCEDURE evenSum()
BEGIN
# 求1-100之间的偶数和
DECLARE result INT DEFAULT 0;
DECLARE num INT DEFAULT 1;
WHILE num <= 100 DO
IF num % 2 = 0 THEN
SET result = result + num;
END IF;
SET num = num + 1;
END WHILE;
SELECT result;
END$
DELIMITER ;
# 调用存储过程
CALL evenSum();
(6)存储函数:
DELIMETER $
CREATE FUNCTION 函数名称(参数列表)
RETURNS 返回值类型
BEGIN
SQL语句列表;
RETURN 结果;
END$
DELIMITER ;
注意:存储函数与存储过程类似,不再赘述
案例5-3:获取学生表中成绩大于95分的学生数量?
DELIMETER $
CREATE FUNCTION countStudent()
RETURNS INT
BEGIN
DECLARE count INT;
SELECT COUNT(*) INTO count FROM student WHERE score > 95;
RETURN count;
END$
DELIMITER ;
# 调用存储过程
SELECT countStudent();
6.触发器:
触发器是与表有关的数据库对象,可以在insert、update、delete之前或之后触发并执行触发器中定义的SQL语句。
注意:这种特性可以协助应用系统在数据库端确保数据的完整性、日志文件、数据校验等操作。
可使用别名NEW与OLD来引用触发器中发生变化的内容记录:
| 触发器类型 | OLD | NEW |
|---|---|---|
| INSERT型触发器 | 无(插入前无数据) | NEW表示将要 or 已经新增的数据 |
| UPDATE型触发器 | OLD表示修改之前的数据 | NEW表示将要 or 已经修改后的数据 |
| DELETE型触发器 | OLD表示将要 or 已经删除的数据 | 无(删除后状态无数据) |
(1)创建触发器:
DELIMETER $
CREATE TRIGGER 触发器名称
BEFORE|AFTER INSERT|UPDATE|DELETE
ON 表名
FOR EACH ROW
BEGIN
触发器要执行的功能;
END$
DELIMITER ;
(2)查看和删除触发器:
查看触发器:
SHOW TRIGGERS;
删除触发器:
DROP TRIGGER 触发器名称;