浅谈TCP和UDP协议
目录
- TCP和UDP的区别
- UDP
-
- 特点:
- 使用场景
- UDP变形
-
- QUIC协议
- 直播中的帧
- 嵌入式
- TCP
-
- TCP三次握手
- TCP四次挥手
- TCP状态机
TCP和UDP的区别
我们大多数人的回答是,TCP是面向连接的,UDP是面向无连接的。
那么什么是面向连接,什么是面向无连接?,再互通之前,面向连接的协议会先建立连接,例如:TCP会三次握手, 而UDP不会。
所谓的建立连接,是为了在客户端和服务端维护连接,而建立一定的数据结构来维护双方交互的状态,用这样的数据结构来保证所谓的面向连接的特性。
例如:TCP提供可靠交付
- 无差错
- 不丢失
- 不重复
- 按序到达
而UDP更像,前面那讲提到过的,IP包,不保证不丢失,不保证按顺序到达
再比如,TCP面向字节流,发送没头没尾,IP包是一个一个的包,UDP继承了IP的特性,基于数据报,一个一个发,一个一个收
还有TCP是有拥塞控制的,可以根据情况调整自己的行为,看看是不是发快了,要不要发慢一点,UDP就不会,应用让我发,我就发,管它能不能接收
所以也可以说,TCP其实是有一个有状态服务,通俗的讲就是有脑子的,错一点都不行,而UDP是无状态服务,没有脑子,像发啥就发出去了
我们可以这样比喻,如果 MAC 层定义了本地局域网的传输行为,IP 层定义了整个网络端到端的传输行为,这两层基本定义了这样的基因:网络传输是以包为单位的,二层叫帧,网络层叫包,传输层叫段。我们笼统地称为包。包单独传输,自行选路,在不同的设备封装解封装,不保证到达。基于这个基因,生下来的孩子 UDP 完全继承了这些特性,几乎没有自己的思想。
UDP
特点:
- 沟通简单,没有大量的数据结构,处理逻辑,包头字段
- 可以传多个数据,也可以接收多个数据
- 不知道什么时候该进行发包的拥塞控制,无论网络丢包成啥样了,它该怎么发还怎么发
使用场景
第一,需要资源少,在网络情况比较好的内网,或者对于丢包不敏感的应用
DHCP 就是基于 UDP 协议的。一般的获取 IP 地址都是内网请求,而且一次获取不到 IP 又没事,过一会儿还有机会。我们讲过 PXE 可以在启动的时候自动安装操作系统,操作系统镜像的下载使用的 TFTP,这个也是基于 UDP 协议的。在还没有操作系统的时候,客户端拥有的资源很少,不适合维护一个复杂的状态机,而且因为是内网,一般也没啥问题。
第二,不需要一对一沟通,建立连接,而是可以广播的应用。
UDP 的不面向连接的功能,可以使得可以承载广播或者多播的协议。
第三,需要处理速度快,时延低,可以容忍少数丢包,但是要求即便网络拥塞,也毫不退缩,一往无前的时候。
UDP 简单、处理速度快,不像 TCP 那样,操这么多的心,各种重传啊,保证顺序啊,前面的不收到,后面的没法处理啊。不然等这些事情做完了,时延早就上去了。而 TCP 在网络不好出现丢包的时候,拥塞控制策略会主动的退缩,降低发送速度,这就相当于本来环境就差,还自断臂膀,用户本来就卡,这下更卡了。
当前很多应用都是要求低时延的,它们可不想用 TCP 如此复杂的机制,而是想根据自己的场景,实现自己的可靠和连接保证。例如,如果应用自己觉得,有的包丢了就丢了,没必要重传了,就可以算了,有的比较重要,则应用自己重传,而不依赖于 TCP。有的前面的包没到,后面的包到了,那就先给客户展示后面的嘛,干嘛非得等到齐了呢?如果网络不好,丢了包,那不能退缩啊,要尽快传啊,速度不能降下来啊,要挤占带宽,抢在客户失去耐心之前到达。
如果你实现的应用需要有自己的连接策略,可靠保证,时延要求,使用 UDP,然后再应用层实现这些是再好不过了。从而引出,UDP的变形
UDP变形
QUIC协议
QUIC(全称 Quick UDP Internet Connections,快速 UDP 互联网连接)是 Google 提出的一种基于 UDP 改进的通信协议,其目的是降低网络通信的延迟,提供更好的用户互动体验。
原来访问网页和手机 APP 都是基于 HTTP 协议的。HTTP 协议是基于 TCP 的,建立连接都需要多次交互,对于时延比较大的目前主流的移动互联网来讲,建立一次连接需要的时间会比较长,然而既然是移动中,TCP 可能还会断了重连,也是很耗时的。而且目前的 HTTP 协议,往往采取多个数据通道共享一个连接的情况,这样本来为了加快传输速度,但是 TCP 的严格顺序策略使得哪怕共享通道,前一个不来,后一个和前一个即便没关系,也要等着,时延也会加大。
QUIC 在应用层上,会自己实现快速连接建立、减少重传时延,自适应拥塞控制
直播中的帧
对于直播来讲,老的视频帧丢了其实也就丢了,就算再传过来用户也不在意了,他们要看新的了,如果老是没来就等着,卡顿了,新的也看不了,那就会丢失客户,所以直播,实时性比较比较重要,宁可丢包,也不要卡顿的。
对于视频播放来讲,有的包可以丢,有的包不能丢,因为视频的连续帧里面,有的帧重要,有的不重要,如果必须要丢包,隔几个帧丢一个,其实看视频的人不会感知,但是如果连续丢帧,就会感知了,因而在网络不好的情况下,应用希望选择性的丢帧。
还有就是在网络不好的时候,TCP协议会主动降低发送速度,这对本来当时就卡的看视频来讲是要命的,应该应用层马上重传,而不是主动让步。因而,很多直播应用,都基于 UDP 实现了自己的视频传输协议。
嵌入式
对于嵌入式来讲,他们本身可能就是一个内存非常小的芯片,维护TCP协议代价太大,如果是对实时性要求高的产品,那么TCP的哪些也导致延迟更大
TCP
TCP头的格式:
 首先是源端口和目标端口,数据要知道发给哪个应用,接下来是包的序号,为了解决乱序问题,还有就是确认序号发出去的包要有确认,不然怎么知道对方有没有收到,如果没有收到就要重新发送,这个主要解决丢包问题
首先是源端口和目标端口,数据要知道发给哪个应用,接下来是包的序号,为了解决乱序问题,还有就是确认序号发出去的包要有确认,不然怎么知道对方有没有收到,如果没有收到就要重新发送,这个主要解决丢包问题
TCP是靠谱的协议,但是这不能说明它面临的网络环境好。从 IP 层面来讲,如果网络状况的确那么差,是没有任何可靠性保证的,而作为 IP 的上一层 TCP 也无能为力,唯一能做的就是更加努力,不断重传,通过各种算法保证。也就是说,对于 TCP 来讲,IP 层你丢不丢包,我管不着,但是我在我的层面上,会努力保证可靠性。
**状态位:**例如:SYN是发起一个连接,ACK是回复,RST是重新连接,FIN是结束连接,TCP 是面向连接的,因而双方要维护连接的状态,这些带状态位的包的发送,会引起双方的状态变更。
TCP要做流量控制,通信双方各声明一个窗口,标识自己当前能够处理的能力,别发送的太快,也别发送的太慢
总结下来就这几个:
- 顺序问题
- 丢包问题
- 连接维护
- 流量控制
- 拥塞控制
TCP三次握手
指建立一个TCP连接时,需要客户端和服务器总共发送3个包
三次握手的目的是连接服务器指定端口,建立TCP连接,并同步连接双方的序列号和确认号并交换 TCP 窗口大小信息.在socket编程中,客户端执行connect()时。将触发三次握手。

请求 -> 应答 -> 应答之应答
那么我们再来讨论一下,为什么是三次握手,而不是俩次,或四次?
我们还是假设这个通路是非常不可靠的,A 要发起一个连接,当发了第一个请求杳无音信的时候,会有很多的可能性,比如第一个请求包丢了,再如没有丢,但是绕了弯路,超时了,还有 B 没有响应,不想和我连接。A 不能确认结果,于是再发,再发。终于,有一个请求包到了 B,但是请求包到了 B 的这个事情,目前 A 还是不知道的,A 还有可能再发。B 收到了请求包,就知道了 A 的存在,并且知道 A 要和它建立连接。如果 B 不乐意建立连接,则 A 会重试一阵后放弃,连接建立失败,没有问题;如果 B 是乐意建立连接的,则会发送应答包给 A。当然对于 B 来说,这个应答包也是一入网络深似海,不知道能不能到达 A。这个时候 B 自然不能认为连接是建立好了,因为应答包仍然会丢,会绕弯路,或者 A 已经挂了都有可能。而且这个时候 B 还能碰到一个诡异的现象就是,A 和 B 原来建立了连接,做了简单通信后,结束了连接。还记得吗?A 建立连接的时候,请求包重复发了几次,有的请求包绕了一大圈又回来了,B 会认为这也是一个正常的的请求的话,因此建立了连接,可以想象,这个连接不会进行下去,也没有个终结的时候,纯属单相思了。因而两次握手肯定不行。B 发送的应答可能会发送多次,但是只要一次到达 A,A 就认为连接已经建立了,因为对于 A 来讲,他的消息有去有回。A 会给 B 发送应答之应答,而 B 也在等这个消息,才能确认连接的建立,只有等到了这个消息,对于 B 来讲,才算它的消息有去有回。当然 A 发给 B 的应答之应答也会丢,也会绕路,甚至 B 挂了。按理来说,还应该有个应答之应答之应答,这样下去就没底了。所以四次握手是可以的,四十次都可以,关键四百次也不能保证就真的可靠了。只要双方的消息都有去有回,就基本可以了。好在大部分情况下,A 和 B 建立了连接之后,A 会马上发送数据的,一旦 A 发送数据,则很多问题都得到了解决。例如 A 发给 B 的应答丢了,当 A 后续发送的数据到达的时候,B 可以认为这个连接已经建立,或者 B 压根就挂了,A 发送的数据,会报错,说 B 不可达,A 就知道 B 出事情了。当然你可以说 A 比较坏,就是不发数据,建立连接后空着。我们在程序设计的时候,可以要求开启 keepalive 机制,即使没有真实的数据包,也有探活包。另外,你作为服务端 B 的程序设计者,对于 A这种长时间不发包的客户端,可以主动关闭,从而空出资源来给其他客户端使用。
三次握手确立俩件事情:
- 各自确认对方的存在
- 约定初始的数据包的序列号
TCP四次挥手
握手完了,AB说一句“拜拜了”,好聚好散,这也就是我们常说的四次挥手
A:B 啊,我不想玩了。
B:哦,你不想玩了啊,我知道了。
这个时候,还只是 A 不想玩了,也即 A 不会再发送数据,但是 B 能不能在 ACK 的时候,直接关闭呢?当然不可以了,很有可能 A 是发完了最后的数据就准备不玩了,但是 B 还没做完自己的事情,还是可以发送数据的,所以称为半关闭的状态。这个时候 A 可以选择不再接收数据了,也可以选择最后再接收一段数据,等待 B 也主动关闭。
B:A 啊,好吧,我也不玩了,拜拜。
A:好的,拜拜。
这是不是很诡异?,和平分手,一般是不存在的,
A 开始说“不玩了”,B 说“知道了”,这个回合,是没什么问题的,因为在此之前,双方还处于合作的状态,如果 A 说“不玩了”,没有收到回复,则 A 会重新发送“不玩了”。但是这个回合结束之后,就有可能出现异常情况了,因为已经有一方率先撕破脸。
一种情况是,A 说完“不玩了”之后,直接跑路,是会有问题的,因为 B 还没有发起结束,而如果 A 跑路,B 就算发起结束,也得不到回答,B 就不知道该怎么办了。另一种情况是,A 说完“不玩了”,B 直接跑路,也是有问题的,因为 A 不知道 B 是还有事情要处理,还是过一会儿会发送结束。
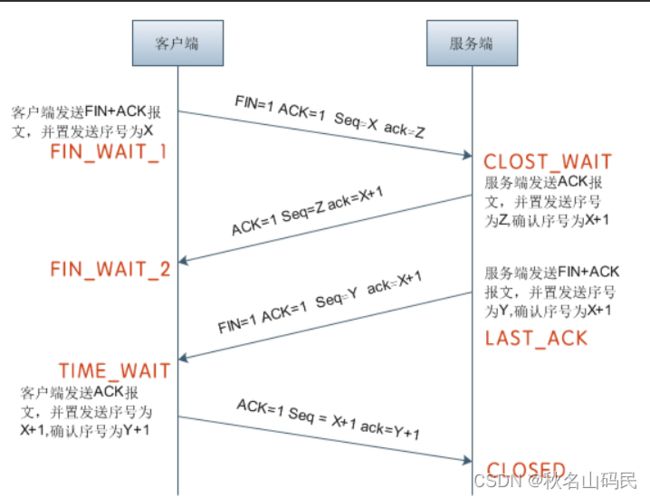
断开的时候,我们可以看到,当 A 说“不玩了”,就进入 FIN_WAIT_1 的状态,B 收到“A 不玩”的消息后,发送知道了,就进入 CLOSE_WAIT 的状态。
A 收到“B 说知道了”,就进入 FIN_WAIT_2 的状态,如果这个时候 B 直接跑路,则 A 将永远在这个状态。TCP 协议里面并没有对这个状态的处理,但是 Linux 有,可以调整 tcp_fin_timeout 这个参数,设置一个超时时间。
如果 B 没有跑路,发送了“B 也不玩了”的请求到达 A 时,A 发送“知道 B 也不玩了”的 ACK 后,从 FIN_WAIT_2 状态结束,按说 A 可以跑路了,但是最后的这个 ACK 万一 B 收不到呢?则 B 会重新发一个“B 不玩了”,这个时候 A 已经跑路了的话,B 就再也收不到 ACK 了,因而 TCP 协议要求 A 最后等待一段时间 TIME_WAIT,这个时间要足够长,长到如果 B 没收到 ACK 的话,“B 说不玩了”会重发的,A 会重新发一个 ACK 并且足够时间到达 B。
A 直接跑路还有一个问题是,A 的端口就直接空出来了,但是 B 不知道,B 原来发过的很多包很可能还在路上,如果 A 的端口被一个新的应用占用了,这个新的应用会收到上个连接中 B 发过来的包,虽然序列号是重新生成的,但是这里要上一个双保险,防止产生混乱,因而也需要等足够长的时间,等到原来 B 发送的所有的包都死翘翘,再空出端口来。
等待的时间设为 2MSL,MSL 是 Maximum Segment Lifetime,报文最大生存时间,它是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。因为 TCP 报文基于是 IP 协议的,而 IP 头中有一个 TTL 域,是 IP 数据报可以经过的最大路由数,每经过一个处理他的路由器此值就减 1,当此值为 0 则数据报将被丢弃,同时发送 ICMP 报文通知源主机。协议规定 MSL 为 2 分钟,实际应用中常用的是 30 秒,1 分钟和 2 分钟等。
还有一个异常情况就是,B 超过了 2MSL 的时间,依然没有收到它发的 FIN 的 ACK,怎么办呢?按照 TCP 的原理,B 当然还会重发 FIN,这个时候 A 再收到这个包之后,A 就表示,我已经在这里等了这么长时间了,已经仁至义尽了,之后的我就都不认了,于是就直接发送 RST,B 就知道 A 早就跑了。
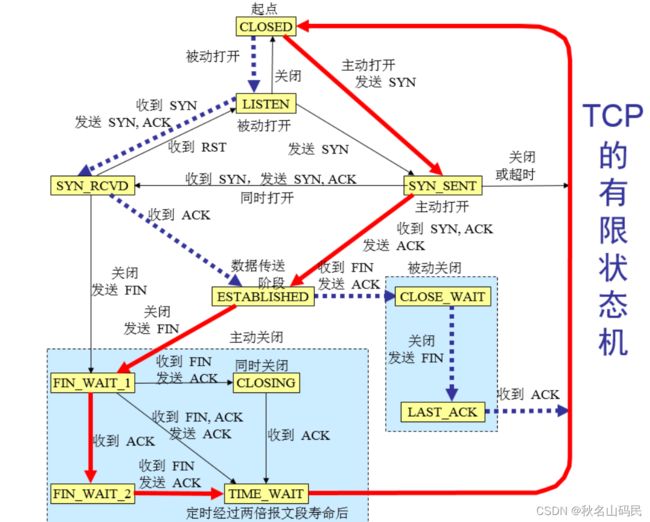
TCP状态机