【python机器学习100天—2022年】Day1-数据预处理
大家好,我是ly甲烷,后端开发也有做算法的心呀 ,我们来学习python机器学习
github有37.1k star的机器学习100天原项目地址https://github.com/Avik-Jain/100-Days-Of-ML-Code
之前的机器学习100天有很多库或者函数已经不用了,还有刚入门机器学习可能很多函数或者设置搞不明白,
所以,从python基础无缝到机器学习的教程来了。博主亲自操作一遍过的记录,绝对细致。如果学不会可以评论区讨论,如果我懂,我会回复的。
今天是机器学习第一天——数据预处理
文章目录
- 前置知识
- 下载数据库
- 1.导入需要的库
- 2.导入数据集
-
- iloc用法
- 断点调试设置控制台
- 3.处理丢失的数据
- 4.解析分类数据
- 5.拆分数据集为训练集合和测试集合
- 6.特征标准化
- Day01完整代码
前置知识
python基础、
了解pandas、numpy
知道什么是机器学习
让我们正式开始新知识的学习吧
下载数据库
链接:https://pan.baidu.com/s/1Y2vZ5Rvn2PpRkj9XhnZrXQ?pwd=yyds
提取码:yyds
1.导入需要的库
import numpy as np
import pandas as pd
2.导入数据集
# 导入数据集
dataset = pd.read_csv(r'E:\workspace\python_workspace\datasets\Data.csv') # 加个r可以使用单斜杠
X = dataset.iloc[ : , :-1].values # 得到数据集所有行的除了最后一列的数据
Y = dataset.iloc[ : , 3].values # 得到数据集第三列的数据
dataset数据内容:
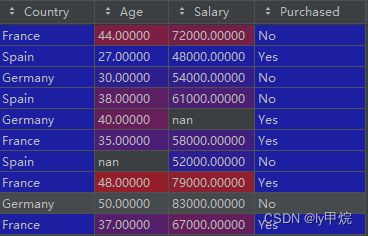
iloc用法
iloc[ : , : ] 第一个参数是行的范围,第二个参数是列的范围,具体如下所示:
# 行
data.iloc[0] # 数据第一行
data.iloc[1] # 数据第二行
data.iloc[-1] # 数据最后一行
# 列
data.iloc[:,0] # 数据第一列
data.iloc[:,1] # 数据第二列
data.iloc[:,-1] # 数据最后一列
# 同时选择多行多列
data.iloc[0:5] # 数据前五行 data.iloc[0:5]等同于data.iloc[:5]
data.iloc[:, 0:2] # 数据前两列
data.iloc[[0,3,6,24], [0,5,6]] # 第1、4、7、25行+第1、6、7列
data.iloc[0:5, 5:8] # 数据前5行和第6、7、8列
断点调试设置控制台
可以打断点调试,来观察数据。调试需要设置控制台
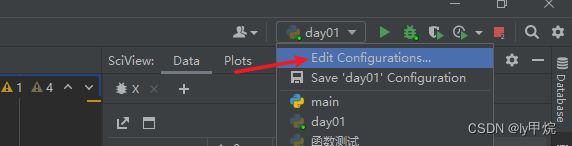

3.处理丢失的数据
这一步是将缺失的数据补齐
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan, strategy="mean") # 确实值处理对象,把缺失值由该列平均值填充
imputer = imputer.fit(X[:, 1:3]) # 先用fit()获取矩阵参数
X[:, 1:3] = imputer.transform(X[:, 1:3]) # 填补缺失值,一般使用该方法前要先用fit()方法对矩阵进行处理。
SimpleImputer 用法:https://blog.csdn.net/qq_43965708/article/details/115625768
4.解析分类数据
这一部是将数据标签化,有利于模型的建立
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer
# 解析分类数据
# LabelEncoder 将一列文本数据转化成数值。 例如,[red, blue, red, yellow] = [0,2,0,1]
labelencoder_X = LabelEncoder()
X[:, 0] = labelencoder_X.fit_transform(X[:, 0]) # X的第一列被转换成 数字标签
# 默认情况下,从数据集中删除任何未在“转换器”列表中指定的列;这可以通过设置“remainder”参数来改变。
# 设置remainder='passthrough'将意味着所有未在“转换器”列表中指定的列将不经转换直接通过,而不是被丢弃。
ct = ColumnTransformer([('encoder', OneHotEncoder(), [0])], remainder='passthrough') # ct转换器对象
X = ct.fit_transform(X) # X的第一列数据被转化成虚拟数据 【多列只有0和1的数据】
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y) # Y标签被转化成数字
注释应该还是比较详细的,如果不懂可以百度查查,或者看看下面两个文章
使用 SciKit 中的 ColumnTransformer 代替 LabelEncoding 和 OneHotEncoding 进行机器学习中的数据预处理
数据预处理之将类别数据数字化的方法 —— LabelEncoder VS OneHotEncoder
5.拆分数据集为训练集合和测试集合
# 20%作为测试集,random_state为固定值可以让结果重现
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
6.特征标准化
将特征标准化,为了将不同量纲的数据放一块,方便一起处理。
不然假设特征1是0~1区间变化,特征2是10-100变化。放一块后,特征1的变化就不重要了,这显然不行
# 6.特征标准化
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
Day01完整代码
import numpy as np
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 2.导入数据集
dataset = pd.read_csv(r'E:\workspace\python_workspace\datasets\Data.csv') # 加个r可以使用单斜杠
X = dataset.iloc[:, :-1].values # 得到数据集所有行的除了最后一列的数据
Y = dataset.iloc[:, 3].values # 得到数据集第三列的数据 【标签】
# 3.处理丢失数据
imputer = SimpleImputer(missing_values=np.nan, strategy="mean") # 确实值处理对象,把缺失值由该列平均值填充
imputer = imputer.fit(X[:, 1:3]) # 先用fit()获取矩阵参数
X[:, 1:3] = imputer.transform(X[:, 1:3]) # 填补缺失值,一般使用该方法前要先用fit()方法对矩阵进行处理。
# 4.解析分类数据
# LabelEncoder 将一列文本数据转化成数值。 例如,[red, blue, red, yellow] = [0,2,0,1]
labelencoder_X = LabelEncoder()
X[:, 0] = labelencoder_X.fit_transform(X[:, 0]) # X的第一列被转换成 数字标签
# 默认情况下,从数据集中删除任何未在“转换器”列表中指定的列;这可以通过设置“remainder”参数来改变。
# 设置remainder='passthrough'将意味着所有未在“转换器”列表中指定的列将不经转换直接通过,而不是被丢弃。
ct = ColumnTransformer([('encoder', OneHotEncoder(), [0])], remainder='passthrough') # ct转换器对象
X = ct.fit_transform(X) # X的第一列数据被转化成虚拟数据 【多列只有0和1的数据】
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y) # Y标签被转化成数字
# 5.拆分数据集为训练集合和测试集合
# 20%作为测试集,random_state为固定值可以让结果重现
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
# 6.特征标准化
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
今日总结:
导入数据集——补齐缺失的数据项——将原始的文本数据转化成数字特征或标签——数据分为训练集和测试集——将特征标准化
今天就到这里啦,如果不懂,可以调试调试,看看变量是怎么变的,有不足和错误的地方欢迎大家指正
大家可以在评论区留下足迹 ⭐️、留下遇到的问题哦。或者你也可以记录学习博客,留下你的博客地址
每天半小时让我们一起进步